1-Django - ORM进阶
多个字段同时ForeignKey到另一张表
python3.10 + django3.2
遇到一个如下的表结构设计,也就是一张表中,有多个字段需要同时关联到另一张表。
from django.db import models
class UserInfo(models.Model):
name = models.CharField(max_length=32)
def __str__(self):
return self.name
class Message(models.Model):
from_msg = models.ForeignKey(to='UserInfo', on_delete=models.SET_NULL, null=True)
to_msg = models.ForeignKey(to='UserInfo', on_delete=models.SET_NULL, null=True)
然后你执行数据库迁移动作的时候,会发现报错:
(base) C:\about_auth>python manage.py makemigrations
省略一些报错,主要看下面的报错信息
SystemCheckError: System check identified some issues:
ERRORS:
app01.Message.from_msg: (fields.E304) Reverse accessor for 'app01.Message.from_msg' clashes with reverse accessor for 'app01.Message.to_msg'.
HINT: Add or change a related_name argument to the definition for 'app01.Message.from_msg' or 'app01.Message.to_msg'.
app01.Message.from_msg: (fields.E320) Field specifies on_delete=SET_NULL, but cannot be null.
HINT: Set null=True argument on the field, or change the on_delete rule.
app01.Message.to_msg: (fields.E304) Reverse accessor for 'app01.Message.to_msg' clashes with reverse accessor for 'app01.Message.from_msg'.
HINT: Add or change a related_name argument to the definition for 'app01.Message.to_msg' or 'app01.Message.from_msg'.
app01.Message.to_msg: (fields.E320) Field specifies on_delete=SET_NULL, but cannot be null.
HINT: Set null=True argument on the field, or change the on_delete rule.
报错是反向关联的报错,提示添加related_name参数来区分两个字段,什么意思呢?
通常在如下外键关联中,message表只有from_msg字段关联了userinfo表,那么Django在内部会为这两个message和userinfo表建立ForeignKey的反向关联关系,比如通过userinfo表查询某个用户所有的message表中的所有from_msg字段的记录,那么就是通过表名小写_set的形式来完成的。
from django.db import models
class UserInfo(models.Model):
name = models.CharField(max_length=32)
def __str__(self):
return self.name
class Message(models.Model):
msg = models.CharField(max_length=32)
from_msg = models.ForeignKey(to='UserInfo', on_delete=models.SET_NULL, null=True, )
# to_msg = models.ForeignKey(to='UserInfo', on_delete=models.SET_NULL)
def __str__(self):
return self.msg
那么我们在做相关的查询时是这样的,此时两张表的数据长这样:
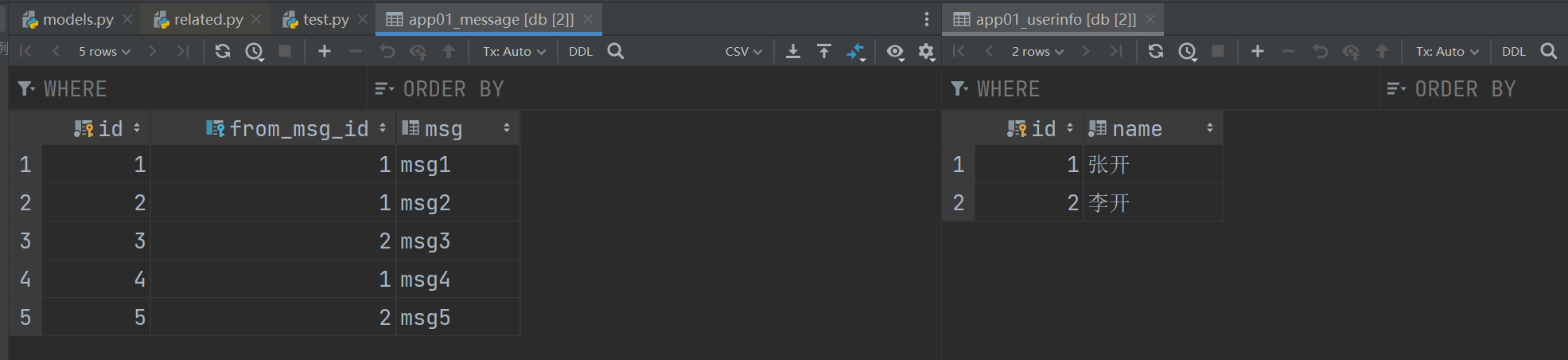
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "about_auth.settings") # about_auth:项目名称
django.setup()
from app01.models import UserInfo, Message
def foo():
# 正向查询,通过消息表查询关联的用户对象
msg = Message.objects.get(id=1)
print(msg.from_msg) # 张开
# 反向查询,通过表名小写_set来找到与userinfo表中id为1的用户关联的所有的from_msg的消息
# 如果message表中同时有两个字段from_msg和to_msg字段都是默认关联了userinfo表,那么在userinfo表在反向查询时,通过表名小写_set的方式就无法
# 区分到底该返回是from_msg的消息还是to_msg的消息,所以,在执行数据库迁移命令时,报错提示你为from_msg和to_msg这两个字段都指定下related_name来进行区分
# 好方便将来通过userinfo表在反向查询时知道你要的是from_msg的消息还是to_msg的消息
user = UserInfo.objects.get(id=1)
print(user.message_set.all()) # <QuerySet [<Message: msg1>, <Message: msg2>, <Message: msg4>]>
if __name__ == '__main__':
foo()
所以,我们现在加上related_name参数,然后再执行数据库迁移命令就不报错了。
from django.db import models
class UserInfo(models.Model):
name = models.CharField(max_length=32)
def __str__(self):
return self.name
class Message(models.Model):
msg = models.CharField(max_length=32)
from_msg = models.ForeignKey(to='UserInfo', on_delete=models.SET_NULL, null=True, related_name="message_from")
to_msg = models.ForeignKey(to='UserInfo', on_delete=models.SET_NULL, null=True, related_name="message_to")
def __str__(self):
return self.msg
来看,现在的查询应该怎么写,当然此时的两张表的数据是这样的:
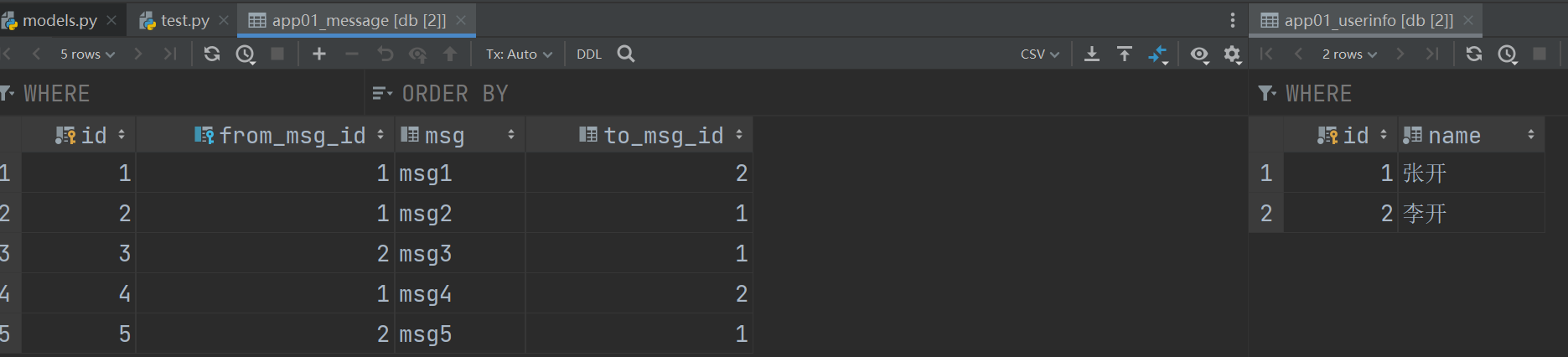
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "about_auth.settings") # about_auth:项目名称
django.setup()
from app01.models import UserInfo, Message
def foo():
# 正向查询,通过消息表查询关联的用户对象
msg = Message.objects.get(id=1)
print(msg.from_msg) # 张开
print(msg.to_msg) # 李开
# 反向查询,就要通过related_name来找到与userinfo表中id为1的用户关联的所有的from_msg和to_msg的消息了
user = UserInfo.objects.get(id=1)
print(user.message_from.all()) # <QuerySet [<Message: msg1>, <Message: msg2>, <Message: msg4>]>
print(user.message_to.all()) # <QuerySet [<Message: msg2>, <Message: msg3>, <Message: msg5>]>
if __name__ == '__main__':
foo()
获取模型类的字段名和verbose_name
python3.9 + django3.2
有时候,我们不但要获取模型类对象的字段的值,也要后去字段名,或者是verbose_name,那么就可以这么做:
# 模型类
from django.db import models
class Company(models.Model):
""" 供应商表 """
name = models.CharField(max_length=64, verbose_name='企业简称')
mobile = models.CharField(max_length=11, verbose_name='手机号')
password = models.CharField(max_length=32, verbose_name='密码')
# 在视图中可以这么做
for i in models.Company._meta.fields:
# 可以打印下 i.__dict__ 能拿到的数据,从这个 i.__dict__ 中都可以看到
print(i.attname, i.verbose_name)
"""
id ID
name 企业简称
mobile 手机号
password 密码
"""
orm索引相关设置
from django.db import models
class UserInfo(models.Model):
# 设置主键
id = models.IntegerField(primary_key=True, verbose_name='id')
# 添加普通索引,法1,直接使用db_index参数指定
k1 = models.CharField(db_index=True, max_length=32, verbose_name='k1')
k2 = models.CharField(db_index=True, unique=True, max_length=32, verbose_name='k2')
k3 = models.CharField(max_length=32, verbose_name='k3')
k4 = models.CharField(max_length=32, verbose_name='k4')
k5 = models.CharField(max_length=32, verbose_name='k5')
k6 = models.CharField(max_length=32, verbose_name='k6')
k7 = models.CharField(max_length=32, verbose_name='k7')
k8 = models.CharField(max_length=32, verbose_name='k8')
class Meta:
db_table = "userinfo"
# 法2:添加一个或多个普通索引
indexes = (
models.Index(fields=['k3'], name='idx_k3'), # 普通索引
models.Index(fields=['k4'], name='idx_k4') # 普通索引
)
# 联合索引(不唯一)
index_together = (('k5', 'k6'),)
# 联合唯一索引
unique_together = (('k7', 'k8'),)
"""
[blog]>show index from userinfo;
+----------+------------+------------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+----------+------------+------------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| userinfo | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | |
| userinfo | 0 | k2 | 1 | k2 | A | 0 | NULL | NULL | | BTREE | | |
| userinfo | 0 | userinfo_k7_k8_6559a20b_uniq | 1 | k7 | A | 0 | NULL | NULL | | BTREE | | |
| userinfo | 0 | userinfo_k7_k8_6559a20b_uniq | 2 | k8 | A | 0 | NULL | NULL | | BTREE | | |
| userinfo | 1 | api_userinfo_k1_ff046809 | 1 | k1 | A | 0 | NULL | NULL | | BTREE | | |
| userinfo | 1 | userinfo_k5_k6_aeb2c21d_idx | 1 | k5 | A | 0 | NULL | NULL | | BTREE | | |
| userinfo | 1 | userinfo_k5_k6_aeb2c21d_idx | 2 | k6 | A | 0 | NULL | NULL | | BTREE | | |
| userinfo | 1 | idx_k3 | 1 | k3 | A | 0 | NULL | NULL | | BTREE | | |
| userinfo | 1 | idx_k4 | 1 | k4 | A | 0 | NULL | NULL | | BTREE | | |
+----------+------------+------------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
9 rows in set (0.00 sec)
"""
如上面所示,我们可以在orm中设置主键索引、普通索引、唯一索引、联合索引、联合唯一索引。
注意:
- 在Meta中,设置的普通索引可以自定义索引名称,其它的索引名字,我还没研究怎么自定义,不过使用倒是没啥。
- Non_unique:0表示具有唯一约束。
参考:
- https://blog.csdn.net/m0_47202787/article/details/106223336
- https://www.cnblogs.com/fivenian/p/15002831.html
- https://www.cnblogs.com/gwklan/p/11140079.html
only/defer
django3.2 + python3.9 + mysql5.7
先来表结构:
from django.db import models
class UserType(models.Model):
identify = models.CharField(max_length=32, verbose_name='用户类型')
class Meta:
db_table = 'usertype'
class UserDetail(models.Model):
phone = models.CharField(max_length=11, default='18211101111')
class Meta:
db_table = 'userdetail'
class UserInfo(models.Model):
name = models.CharField(max_length=32, verbose_name='用户姓名')
pwd = models.CharField(max_length=32, verbose_name='用户密码')
ud = models.OneToOneField(to='UserDetail', verbose_name='用户详情', on_delete=models.CASCADE)
ut = models.ForeignKey(to='UserType', verbose_name='用户类型', on_delete=models.CASCADE)
class Meta:
db_table = 'userinfo'
再来看only和defer怎么用:
from django.shortcuts import render
from api import models
def index(request):
# 直接点all(),相当于 select * from userinfo;
# 使用only相当于 select name from userinfo;
# 所以,如果查询只需要某个字段时,就可以通过使用only来提高查询速度
# 甚至可以给该字段建立索引,使其查询速度更快
# only的语法,就是以逗号分隔你要查询的指定字段 only('field1', 'fields2')
user_list = models.UserInfo.objects.all().only('name')
print(user_list.query)
for i in user_list:
# 注意,只需要name字段,你就不要再点其他的字段了
# print(i.name)
# 如果你点了其他字段,那还不如不用only,因为点哪个字段都需要再查询一次
# print(i.name, i.pwd)
"""
SELECT `userinfo`.`id`, `userinfo`.`pwd` FROM `userinfo` WHERE `userinfo`.`id` = 3
"""
# defer跟only用法一致,但作用相反,defer中填写你要排除的字段
user_list = models.UserInfo.objects.all().defer('pwd', 'ut')
print(user_list.query)
for i in user_list:
# 注意,如果不点那些排除的字段,就不需要再次查询
print(i.name, i.pwd)
# 如果你点了排除的字段,那么点哪个字段都需要再查询一次
"""
SELECT `userinfo`.`id`, `userinfo`.`pwd` FROM `userinfo` WHERE `userinfo`.`id` = 3
"""
return render(request, 'index.html', {"user_list": user_list})
return render(request, 'index.html', {"user_list": user_list})
那你可能会问,这需求我们可以通过values或者value_list达到,为啥要用onlyhedefer啊。区别就在于查询的结果对象不一样。
# 你要按照列表套元组或者套字典的方式取值
user_list = models.UserInfo.objects.all().values() # [{}, {}, {}]
user_list = models.UserInfo.objects.all().values_list() # [(), (), ()]
# 而用only或者defer,你就可以以对象的方式点字段了,总之,具体看需求吧
user_list = models.UserInfo.objects.all().defer("name") # [obj, obj, obj]
user_list = models.UserInfo.objects.all().only("name") # [obj, obj, obj]
related_name/related_query_name
django3.2 + python3.9 + mysql5.7
在外键关联关系中,我们知道,反向查询使用的是表名小写_set来实现,那么related_name的功能就是可以自定义这个表名小写_set。
而related_query_name,在Django3.2文档中,是这样写的:
https://docs.djangoproject.com/zh-hans/3.2/ref/models/fields/#django.db.models.ForeignKey.related_query_name
ForeignKey.related_query_name是目标模型中反向过滤器的名称。如果设置了,它默认为 related_name 或 default_related_name 的值,否则默认为模型的名称。
所以,这里主要演示related_name的用法。
有这样的表结构:
from django.db import models
class KT1(models.Model):
title = models.CharField(max_length=32)
def __str__(self):
return self.title
class Meta:
db_table = 'kt1'
class KT2(models.Model):
title = models.CharField(max_length=32)
def __str__(self):
return self.title
class Meta:
db_table = 'kt2'
class KT3(models.Model):
title = models.CharField(max_length=32)
def __str__(self):
return self.title
class Meta:
db_table = 'kt3'
class UserInfo(models.Model):
name = models.CharField(max_length=32, verbose_name='用户姓名')
pwd = models.CharField(max_length=32, verbose_name='用户密码')
k1 = models.ForeignKey(to='KT1', verbose_name='K1', on_delete=models.CASCADE)
k2 = models.ForeignKey(to='KT2', verbose_name='K2', on_delete=models.CASCADE, related_query_name='k2',
related_name='k2')
k3 = models.ForeignKey(to='KT3', verbose_name='K3', on_delete=models.CASCADE, related_name='k3')
def __str__(self):
return self.name
class Meta:
db_table = 'userinfo'
related_name的用法:
from django.shortcuts import render
from api import models
def index(request):
# # 正向查询,跟 related_query_name 和 related_name 没啥关系,还按照对象点字段进行跨表查询
user_obj = models.UserInfo.objects.get(id=1)
print(user_obj.k1.title) # k11
# # 反向查询,按照原来的用法,是表名小写加下划线set.all
kt1_obj = models.KT1.objects.first()
print(kt1_obj.userinfo_set.all())
"""
<QuerySet [<UserInfo: user1>, <UserInfo: user2>]>
"""
# # related_query_name 的用法,跟 related_name 用法一样,无需多表
# PS: 之前版本貌似有说 related_query_name 单独用的话,代替的是 表名,但无法替代_set
# 即,查询是这样的 kt2_obj.k2_set.all() 但我测试失败了....
kt2_obj = models.KT2.objects.get(id=1)
print(kt2_obj.k2.all())
"""
<QuerySet [<UserInfo: user1>, <UserInfo: user2>]>
"""
# # related_name 的用法
kt3_obj = models.KT3.objects.get(id=1)
print(kt3_obj.k3.all())
"""
<QuerySet [<UserInfo: user1>, <UserInfo: user2>]>
"""
return render(request, 'index.html')
注意:
related_name的主要目的就是为了替代原来的表名小写_set,所以,如果字段中指定了related_name,你就不要再用表名小写_set这种查询方式了,用了会报错,因为表名小写_set被related_name替代了,而官档解释为重写。
官档:https://docs.djangoproject.com/zh-hans/3.2/topics/db/queries/#following-relationships-backward
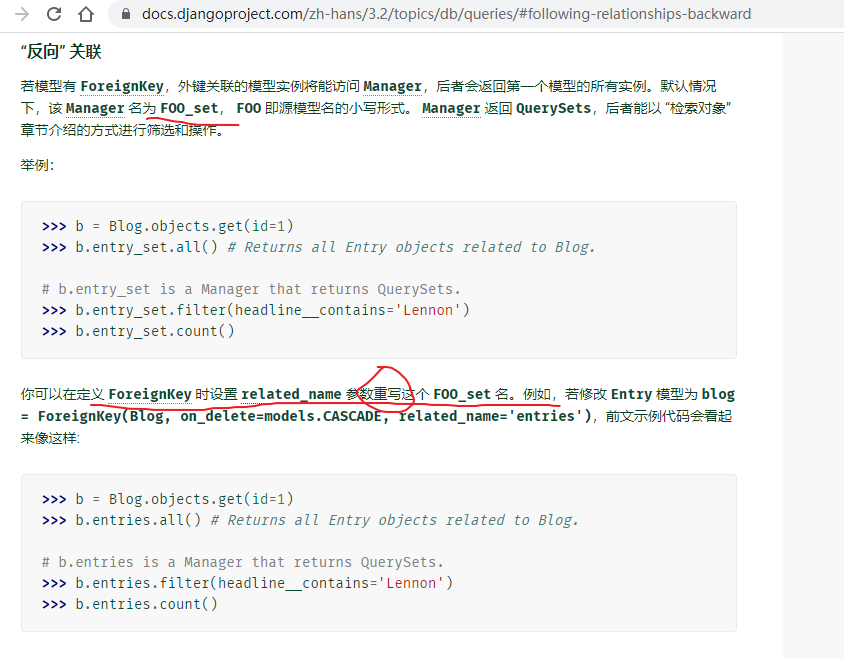
related_name适用于一对一、一对多、多对多外键关联字段中。- 注意,
related_name在一个数据库中应该是唯一的,如果在一个表中或者当前数据库中出现其它相同的related_name值,会报错类似于这样的错误HINT: Add or change a related_name argument to the definition for 'app01.User2.k2' or 'app01.User1.k2' .。那么related_name命名时,一般都是表名小写_related_name值,或者更复杂的可以带上app的名字app名字_表名小写_related_name值加一区分,保证唯一。
参考:
- https://www.cnblogs.com/wupeiqi/articles/6216618.html
- https://blog.csdn.net/weixin_45154837/article/details/99892994
- https://docs.djangoproject.com/zh-hans/3.2/ref/models/fields/#django.db.models.ForeignKey.related_name
- https://docs.djangoproject.com/zh-hans/3.2/topics/db/queries/#many-to-many-relationships
- https://docs.djangoproject.com/zh-hans/3.2/ref/models/fields/#django.db.models.ForeignKey.related_name
select_related/prefetch_related
django3.2 + python3.9 + mysql5.7
首先上表结构,还有提前插入好的数据:
from django.db import models
class UserType(models.Model):
identify = models.CharField(max_length=32, verbose_name='用户类型')
class Meta:
db_table = 'usertype'
class UserDetail(models.Model):
phone = models.CharField(max_length=11, default='18211101111')
class Meta:
db_table = 'userdetail'
class UserInfo(models.Model):
name = models.CharField(max_length=32, verbose_name='用户姓名')
pwd = models.CharField(max_length=32, verbose_name='用户密码')
ud = models.OneToOneField(to='UserDetail', verbose_name='用户详情', on_delete=models.CASCADE)
ut = models.ForeignKey(to='UserType', verbose_name='用户类型', on_delete=models.CASCADE)
class Meta:
db_table = 'userinfo'
"""
[api]>select * from userdetail;
+----+-------------+
| id | phone |
+----+-------------+
| 1 | 18211101111 |
| 2 | 18211101111 |
| 3 | 18211101111 |
| 4 | 18211101111 |
+----+-------------+
4 rows in set (0.00 sec)
[api]>select * from usertype;
+----+----------+
| id | identify |
+----+----------+
| 1 | vip1 |
| 2 | vip2 |
| 3 | vip3 |
+----+----------+
3 rows in set (0.00 sec)
[api]>select * from userinfo;
+----+-----------+-----+-------+-------+
| id | name | pwd | ud_id | ut_id |
+----+-----------+-----+-------+-------+
| 1 | zhangkai1 | 123 | 1 | 1 |
| 2 | zhangkai2 | 123 | 2 | 1 |
| 3 | zhangkai3 | 123 | 3 | 2 |
| 4 | zhangkai4 | 123 | 4 | 3 |
+----+-----------+-----+-------+-------+
4 rows in set (0.00 sec)
"""
一般的,我们在查询时,写成:
from django.shortcuts import render
from api import models
def index(request):
# 查询所有用户信息是一次查询
# user_list就是 [obj, obj, obj]
# user_list = models.UserInfo.objects.all()
# for i in user_list:
# # 如果有外键字段,那么每行数据在获取对应的外键字段时,都要重新执行一次sql获取到值
# # 如下面的操作,name,pwd都在userinfo表上,直接能取出来
# # 但 i.ud.phone, i.ut.identify 这两个外键的值,都需要分别再查一次
# # 这就意味着,每行记录都要多两个查询,性能非常低下
# print(i.name, i.pwd, i.ud.phone, i.ut.identify)
# 解决办法1,最简单的就是使用values,这样会进行连表操作,相当于就一次查询,将我们需要的值都查出来了
# user_list就是 [{}, {}, {}] 后续要按照字典取值,而不是对象取值了
# user_list = models.UserInfo.objects.all().values('name', 'pwd', 'ud__phone', 'ut__identify')
# for i in user_list:
# print(i["name"], i['pwd'], i['ud__phone'], i['ut__identify'])
# # 解决办法2,使用select_related,它会主动帮我们进行连表
# # select_related('外键1', '外键2', '外键n')
# # 注意,select_related只适用于 ForeignKey 和 OneToOneField 这两种外键
# # select_related 问题也是有的, 就是不适用于跨多张表,因为连表本身就耗性能,连表越多,越慢
# # user_list就是 [obj, obj, obj]
# user_list = models.UserInfo.objects.all().select_related('ud', 'ut')
# print(user_list.query)
# """
# SELECT `userinfo`.`id`, `userinfo`.`name`, `userinfo`.`pwd`, `userinfo`.`ud_id`, `userinfo`.`ut_id`, `userdetail`.`id`, `userdetail`.`phone`, `usertype`.`id`, `usertype`.`identify` FROM `userinfo` INNER JOIN `userdetail` ON (`userinfo`.`ud_id` = `userdetail`.`id`) INNER JOIN `usertype` ON (`userinfo`.`ut_id` = `usertype`.`id`)
# """
# for i in user_list:
# # 对于外键字段,你直接点就可以,不会再查了
# print(i.name, i.pwd, i.ud.phone, i.ut.identify)
# # 解决办法3,使用 prefetch_related,它不会主动帮我们进行连表,而是有需要的连表获取数据的时候,主动查询一次数据
user_list = models.UserInfo.objects.all().prefetch_related('ud', 'ut')
# prefetch_related做的事就是 先从userinfo表中获取所有的ut_id和 ud_id
# 然后进行如下面所示的两个in查询,当你点的时候,返回对应的字段值,避免了连表查询
# 所以,prefetch_related指定一个外键,就多一次查询,当然它只适用于 ForeignKey 和 OneToOneField 这两种外键
# prefetch_related 相对于select_related来说,算是个折衷方案,不主动连表,需要的外键字段时,多个查询
print(user_list.query)
"""
SELECT `userinfo`.`id`, `userinfo`.`name`, `userinfo`.`pwd`, `userinfo`.`ud_id`, `userinfo`.`ut_id` FROM `userinfo`
SELECT `usertype`.`id`, `usertype`.`identify` FROM `usertype` WHERE `usertype`.`id` IN (1, 2, 3)
SELECT `userdetail`.`id`, `userdetail`.`phone` FROM `userdetail` WHERE `userdetail`.`id` IN (1, 2, 3, 4)
"""
# for i in user_list:
# # 对于外键字段,你直接点就可以,不会再查了
# print(i.name, i.pwd, i.ud.phone, i.ut.identify)
return render(request, 'index.html', {"user_list": user_list})
参考:https://blog.csdn.net/weixin_42134789/article/details/100571539
数据迁移
Python2.7 + django1.11
这里我只是从这个电脑的sqlite3导出到另一台电脑的相同项目的sqlite3,没有跨不同的数据库来测试:
# 导出数据
# 不指定appname时,默认所有的app
python manage.py dumpdata [appname] > db.json # db.json这个名字自定义
# 导入数据
python manage.py loaddata db.json
判断字段的类型
有的时候,要根据字段的不同,来进行不同的操作,比如如何判断字段是ForeignKey类还是ManyToManyField类型?
from django.db.models import ForeignKey, ManyToManyRel, OneToOneField
# 然后就可以通过isinstance来判断了
if isinstance("表中要判断的字段", ForeignKey):
print("field_object types ForeignKey")
elif isinstance("表中要判断的字段", ManyToManyField):
print("field_object types ManyToManyField")
# 更多的
from web.models import PaymentRecord
for item in PaymentRecord._meta.fields: # 循环模型类中所有的字段
if isinstance(item, ForeignKey):
print("ForeignKey", item)
if isinstance(item, ManyToManyRel):
print("ManyToManyRel", item)
if isinstance(item, OneToOneField):
print("OneToOneField", item)
print(item, item.choices) # 对于有choices值的字段,都会打印出来对应的列表,否则就会打印出来空列表
模型类中choices属性的处理
如果一个用户表中有性别选项,那么就可以在字段中指定一个choices属性,它对应一个元组套元组或者,列表套元组的数据结构。
class Author(models.Model):
user = models.CharField(max_length=32, verbose_name='用户名')
gender = models.IntegerField(choices=(
(1, "男"),
(2, "女"),
), default=1, verbose_name='性别')
def __str__(self):
return self.user
取值的话:
author_obj = Author.objects.first()
print(author_obj.gender) # 2
# 注意,只有字段中有choices参数时,才能get_gender_display
print(author_obj.get_gender_display()) # 女
参考:https://docs.djangoproject.com/zh-hans/4.0/ref/models/fields/
获取关联数据
https://github.com/jazzband/django-smart-selects/pull/218

ORM操作视图
django3.2+python3.9+mysql5.7
这里来简单的说下,如果MySQL中有视图的话,我们该如何通过orm来操作它。
我们来写个示例看下。
首先搞个Django项目,在app的models.py中创建模型类:
from django.db import models
class TestUserDetail(models.Model):
address = models.CharField(max_length=32, verbose_name='地址')
phone = models.CharField(max_length=32, verbose_name='手机号')
class Meta:
db_table = 'testuserdetail'
class TestUserInfo(models.Model):
id = models.IntegerField(primary_key=True)
name = models.CharField(max_length=32, verbose_name='姓名')
pwd = models.CharField(max_length=32, verbose_name='密码')
class Meta:
db_table = 'testuser'
然后执行数据库迁移,并且添加上几条记录:
# 1. 执行数据库迁移命令
python manage.py makemigrations
python manage.py migrate
# 2. 通过mysql的客户端,像两张表插入一些测试数据
insert into testuser(name, pwd) values("王开", "123"), ("赵开", "123"), ("李开", "123"), ("钱开", "123");
insert into testuserdetail(address, phone) values("北京", "18211111111"), ("上海", "18211111111"), ("广州", "18211111111"), ("深圳", "18211111111");
接下来,我们通过MySQL客户端写个简单的视图。
[t2]>-- 创建视图
[t2]>create view testuserinfodetail as select name, pwd, address, phone from testuser left join testuserdetail on testuser.id=testuserdetail.id;
[t2]>-- 查一下视图,结果是有的
[t2]>select * from testuserinfodetail;
+------+-----+---------+-------------+
| name | pwd | address | phone |
+------+-----+---------+-------------+
| 王开 | 123 | 北京 | 18211111111 |
| 赵开 | 123 | 上海 | 18211111111 |
| 李开 | 123 | 广州 | 18211111111 |
| 钱开 | 123 | 深圳 | 18211111111 |
+------+-----+---------+-------------+
4 rows in set (0.00 sec)
接下来,就看看咱们在ROM中怎么操作这个testuserinfodetail视图了。
首先在app的models.py中创建创建一个表:
validate_unique
python3.9 + django3.2
这个validate_unique方法,是一个模型类对象的方法,在save时,如果模型类中有唯一约束的字段,已经存在相同的值,validate_unique方法会抛出一个错误。
models.py:
from django.db import models
class TestDemo(models.Model):
name = models.CharField(max_length=32, unique=True) # 具有唯一约束的字段
address = models.CharField(max_length=32, verbose_name='出版社地址')
views.py:
from django.shortcuts import render, HttpResponse
from django.core.exceptions import ValidationError
from .models import TestDemo
def index(request):
user_list = (
{"name": "张开", "address": "北京"},
{"name": "张开1", "address": "北京1"}, # 前面两条能正常插入
{"name": "张开1", "address": "北京1"}, # 这一个会报错,因为name值已经存在了
)
for item in user_list:
try:
obj = TestDemo(**item)
obj.validate_unique() # 如果表中的唯一字段已经存在了相同的值,这里抛出ValidationError
obj.save()
except ValidationError as e:
print('unique约束报错', e)
return HttpResponse("ok")
auto_now/auto_now_add
django3.2 + python3.9
官档:https://docs.djangoproject.com/zh-hans/4.1/ref/models/fields/#datefield
首先,auto_now和auto_now_add是互斥的,这两个参数在使用时,只能二选一
from django.db import models
class Order(models.Model):
title = models.CharField(max_length=32, verbose_name='订单名称')
create_date = models.DateTimeField(auto_now=True, auto_now_add=True, verbose_name='创建时间')
# 如上示例,如果你同时使用这两个参数,则执行数据库迁移的命令时,将报错。
(base) D:\downloads\demo>python manage.py makemigrations
SystemCheckError: System check identified some issues:
ERRORS:
api.Order.create_date: (fields.E160) The options auto_now, auto_now_add, and default are mutually exclusive.
Only one of these options may be present.
我们接下来,分开来讲这两个参数的细节。
auto_now
auto_now是Python中datetime.date实例对象。
每次以save的形式保存对象时,该字段都会设置为当前保存的时间。也就是每次保存,当前字段值都会更新到当前时间。
注意,create创建一条记录时,这个auto_now是生效的。也就是该字段值是创建时的时间。但是update的话,如果不给auto_now字段手动传值,那么是不生效的。这点是要着重注意的。当然了如果使用save的方式创建记录或者更新记录,auto_now字段都是生效的。
该字段的默认表单部件是一个 DateInput。在admin后台管理中增加了一个 JavaScript 日历,以及“今天”的快捷方式。包含一个额外的 invalid_date 错误信息键。
auto_now_add
这个参数跟auto_now意思一样,区别就是只有第一次创建记录时,才生效,后续更新,无论是save方式还是update方式,都不生效。
欢迎斧正,that's all

 浙公网安备 33010602011771号
浙公网安备 33010602011771号