1-Redis5 - Cluster
一切都要从分布式存储开始
无论是单节点还是主从复制到sentinel,都会遇到数据瓶颈。当数据量达到上限怎么办?
我们肯定就要想着对数据进行分布式存储。

顺序分区和hash分区
分区通常分为顺序分区和hash分区:

哈希分布特点:
- 数据分散度高、键值分布与业务无关、无法顺序访问等。
- 相关产品:一致性哈希Memcache、Redis等其它缓存产品。
顺序分布:
- 数据相对集中、容易造成数据倾斜,业务相关性高、可顺序操作、支持批量操作。
- 相关产品:BigTable、HBase等。
哈希分布常见分区算法
节点取余算法
- 优点就是比较简单,客户端直接进行哈希+取余就可以了。
- 问题也是有的,例如我们增加一台服务器,对同一个key进行hash取余时,除数从3变成4,那么结果就是存储位置发生改变,也就是说,当服务器数量发生改变时,所有缓存在一定时间内是失效的,当应用无法从缓存中获取数据时,则会向后端服务器请求数据;同理,假设突然有一台缓存服务器出现了故障,那么我们则需要将故障机器移除,那么缓存服务器数量从3台变为2台,同样会导致大量缓存在同一时间失效,造成了缓存的雪崩,后端服务器将会承受巨大的压力,整个系统很有可能被压垮。为了解决这种情况,就有了一致性哈希算法。
- 迁移数据量和添加节点数有关,建议翻倍扩容。

一致性哈希算法
参考:
一致性哈希算法在 1997 年由麻省理工学院提出,是一种特殊的哈希算法,在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求的服务器之间的映射关系;
一致性哈希解决了简单哈希算法在分布式哈希表(Distributed Hash Table,DHT)中存在的动态伸缩等问题;
一致性hash算法本质上也是一种取模算法;不过,不同于上边按服务器数量取模,一致性hash是对固定值232取模。(IPv4地址是由32位2进制数组成,所以用232可以保证每个IP地址会有唯一的映射;)
我们可以将这232个值抽象成一个圆环,圆环的正上方的点代表0,顺时针排列,以此类推:1、2、3…直到232-1,而这个由2的32次方个点组成的圆环统称为hash环;
具体步骤如下:
- 一致性哈希算法将整个哈希值空间按照顺时针方向组织成一个虚拟的圆环,称为 Hash 环。
- 接着将各个服务器使用 Hash 函数进行哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,从而确定每台机器在哈希环上的位置。
- 最后使用算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针寻找,找到的第一个遇到的服务器就是其应该定位到的服务器。

一致性哈希算法的优缺点
前面提到,如果简单对服务器数量进行取模,那么当服务器数量发生变化时,会产生缓存的雪崩,从而很有可能导致系统崩溃,而使用一致性哈希算法就可以很好的解决这个问题,因为一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,只有部分缓存会失效,不至于将所有压力都在同一时间集中到后端服务器上,具有较好的容错性和可扩展性。
总之,一致性哈希算法,在这里主要是优化了哈希之后的取余过程。
节点伸缩时,仍然会有数据迁移的情况出现,当然相对于节点取余的方式好了很多。
而且当节点越多,数据分布越均匀,所以,一致性哈希适合于节点很多的情况。
哈希环倾斜与虚拟节点
一致性哈希算法在服务节点太少的情况下,容易因为节点分部不均匀而造成数据倾斜问题,也就是被缓存的对象大部分集中缓存在某一台服务器上,从而出现数据分布不均匀的情况,这种情况就称为 hash 环的倾斜。
hash 环的倾斜在极端情况下,仍然有可能引起系统的崩溃,为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点,一个实际物理节点可以对应多个虚拟节点,虚拟节点越多,hash环上的节点就越多,缓存被均匀分布的概率就越大,hash环倾斜所带来的影响就越小,同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射。
hash槽分区算法
参考:
而Redis的集群,没有采用上面的hash取余算法和一致性哈希算法,而是采用哈希槽(hash slot)进行对数据进行分区。
哈希槽这里要理解两个概念:
-
哈希算法,Redis集群的哈希算法并不是简单的hash算法,而是采用的是CRC16算法。
- 循环冗余校验(英语:Cyclic redundancy check,通称“CRC”)是一种根据网络数据包或电脑文件等数据产生简短固定位数校验码的一种散列函数,主要用来检测或校验数据传输或者保存后可能出现的错误。
- 根据生成的长度(bit)来算,有CRC8/CRC16/CRC32。CRC16算法是一种高效的哈希算法,具有计算速度快、冲突率低等优点,Redis在hash计算时采用的hash算法就是CRC16算法。
-
slot槽位,Redis集群中,一共会虚拟出16384(0-16383)个槽位来存储数据集,这16384个槽位平均的映射到各个节点上。
- 为啥要设置214个槽位,也就是16384个槽位?理论上crc16算法可以得到216个数值,其数值范围在0-65535之间,取模运算key的时候,应该是crc16(key)%65535,但是却设计为crc16(key)%16384,原因是Redis集群在设计的时候做了空间上的权衡,觉得节点最多不可能超过1000个,同时为了保证节点之间通信效率,所以采用了2^14。
- Redis集群的槽位空间,用户可以手动进行微调,比如性能好的机器多分配几个,性能差的机器少分配几个,这都是可以通过命令来处理的,当然了,Redis集群允许我们调整,但不允许我们大幅度调整,各节点的槽位误差不能超过2%。

家常唠完,我们开始上菜吧!
关于集群
redis3版本才开始支持集群,主要解决sentinel的不足:
- 主库写入压力太大
- 资源利用率不高
- 连接过程繁琐等问题
通过集群方案,解决了redis写操作无法负载均衡,以及存储能力收到单机限制的问题,实现了较为完善的高可用方案。
集群的重要概念
-
Redis集群,⽆论有⼏个节点,⼀共只有16384个槽位。
-
所有的槽都必须被正确分配,哪怕有1个槽不正常,整个集群都不可⽤
-
每个节点的槽的顺序不重要,重要的是槽的数量
-
HASH算法⾜够平均,⾜够随机
-
每个槽被分配到数据的概率是⼤致相当的
-
集群的⾼可⽤依赖于主从复制
-
集群节点之间槽位的数量允许在2%的误差范围内
-
集群通讯会使⽤基础端⼝号+10000的端⼝,⾃动创建的,不是配置⽂件配置的,⽣产要注意的是防⽕墙注意要放开此端⼝。
部署规划
首先,的确可以一台机器上进行配置redis集群,只要按照端口区分就好了,本质上就是按照端口区分,多跑几个redis实例的事儿。但是,这完全没有意义,你部署到一个服务器上,集群部署的再牛逼,遇到服务器宕机,也都白瞎.......
所以,本次部署将采用4台服务器来演示集群的部署以及其他操作和验证。
环境
win11
vmware workstation 16 pro
centos7.9
4C2G
4台
xshell7免费版
redis5.0.7
[root@cs ~]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
架构图
4台服务器上,每台服务器一主一从共8个redis实例;另外,所有的主从节点都不能是同一台服务器,防止某个服务器宕机,主从一起挂掉,从而出现丢数据的情况。

我们前期把4个服务器上的集群所需的8个redis都要安装好,然后我们先用三个服务器6个实例进行部署集群,等到了集群扩容和收缩的时候,再用上后两台redis。
端口规划
每台服务器上的主节点都是6380端口,从节点都是6381端口。
目录规划
具体的安装细节,参考前面讲redis安装部分,本次8台redis的安装,也都是基于最开始将的redis安装那里的目录规划上来的。
/opt/redis{6380,6381}/{conf,logs,pid} # 主节点是redis6380,从节点是redis6381,里面的conf,logs,pid分别是配置目录,日志目录,pid目录
/data/redis{6380,6381} # 主从节点的数据目录
# 配置主从节点的systemctl管理
/usr/lib/systemd/system/redis-master.service
/usr/lib/systemd/system/redis-slave.service
手动部署集群的流程
- 把各自服务器的redis实例安装好。
- 配置集群发现,也就是让各个服务器上的Redis实例相互认知一下,知道大家都在一个群里。
- 手动配置槽位,一共有16384个槽位,将来所有的写入都会根据算法随机写入到各个槽位中。
- 在手动的构建集群中的各节点的主从复制关系。
经过上面几个步骤,基本上就把集群搭建起来了。
手动搭建集群
保证你的各台服务器都:
# 关闭防火墙和下载一些可能用到的工具
systemctl stop firewalld.service
systemctl disable firewalld.service
systemctl status firewalld.service
sed -i.ori 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/selinux/config
yum update -y
yum -y install gcc automake autoconf libtool make
yum -y install net-tools vim wget lrzsz
1. redis实例部署
流程,我们先安装好一台redis实例,然后把其相关的目录文件都发到其它服务器行,然后稍微修改下配置,就能快速完成部署。
db01服务器部署redis
本小节的操作,都在db01上执行。
1. 先搞ssh认证,方便后面传输
# 一路回车
ssh-keygen
# 将公钥拷贝到其它三台服务器,按照提示输入yes和目标服务器的密码
ssh-copy-id 192.168.10.151
ssh-copy-id 192.168.10.152
ssh-copy-id 192.168.10.153
2. 安装Redis,参考之前讲的Redis安装章节
参考:https://www.cnblogs.com/Neeo/articles/17609004.html#redis507-for-centos79
此时这个实例监听6379,但我们不用它。
3. 配置6380,6381两个实例
# 可以先杀掉所有的redis实例
pkill -9 redis
# 1. 创建目录
mkdir -p /opt/redis{6380,6381}/{conf,logs,pid}
mkdir -p /data/redis{6380,6381}
# 2. 生成主节点配置文件
cat >/opt/redis6380/conf/redis6380.conf <<EOF
# 注意,bind后面先跟本机ip就行了,这样集群发现时,能根据服务器ip进行发现,不要跟127.0.0.1了
bind $(ifconfig ens33|awk 'NR==2{print $2}')
port 6380
daemonize yes
pidfile "/opt/redis6380/pid/redis6380.pid"
logfile "/opt/redis6380/logs/redis6380.log"
dbfilename "redis6380.rdb"
dir "/data/redis6380/"
save 900 1
save 300 10
save 60 10000
appendonly yes
appendfilename "redis6380.aof"
appendfsync everysec
cluster-enabled yes
cluster-config-file nodes6380.conf
cluster-node-timeout 15000
EOF
# 3. 复制主节点的配置文件到从节点,并更改端口号
cp /opt/redis6380/conf/redis6380.conf /opt/redis6381/conf/redis6381.conf
sed -i 's#6380#6381#g' /opt/redis6381/conf/redis6381.conf
# 4. 更改授权为Redis
# 添加用户报错也正常,因为我这台测试机器,添加过这个用户和组,
# -u和-g选项表示同时添加具有特定UID和GID的用户
# -M创建一个没有主目录的用户
# -s表示当前创建的当前用户无法用来登录系统
# chown -R redis:redis表示指定目录以及内部的文件所有用户属组归于redis:redis
# groupdel redis
# cat /etc/group |grep redis
groupadd redis -g 1000
# userdel redis
# cat /etc/passwd |grep redis
useradd redis -u 1000 -g 1000 -M -s /sbin/nologin
chown -R redis:redis /opt/redis*
chown -R redis:redis /data/redis*
# 5. 生成主节点的systemd启动文件
cat >/usr/lib/systemd/system/redis-master.service<<EOF
[Unit]
Description=Redis persistent key-value database
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
ExecStart=/usr/local/bin/redis-server /opt/redis6380/conf/redis6380.conf --supervised systemd
ExecStop=/usr/local/bin/redis-cli -h $(ifconfig ens33|awk 'NR==2{print $2}') -p 6380 shutdown
Type=notify
User=redis
Group=redis
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
[Install]
WantedBy=multi-user.target
EOF
# 6. 复制master节点的启动⽂件给slave节点并修改端⼝号
cp /usr/lib/systemd/system/redis-master.service /usr/lib/systemd/system/redis-slave.service
sed -i 's#6380#6381#g' /usr/lib/systemd/system/redis-slave.service
# 7. 重载systemd相关文件,并启动集群节点
systemctl daemon-reload
# Redis是6379的
systemctl start redis
# redis-master是将来在集群中充当主节点的
systemctl start redis-master
# redis-slave是将来在集群中充当从节点的
systemctl start redis-slave
ps -ef|grep redis
# 8. 把创建好的⽬录和启动⽂件发送给db02、db03、db04
rsync -avz /opt/redis638* 192.168.10.151:/opt/
rsync -avz /opt/redis638* 192.168.10.152:/opt/
rsync -avz /opt/redis638* 192.168.10.153:/opt/
rsync -avz /usr/local/bin/redis* 192.168.10.151:/usr/local/bin/
rsync -avz /usr/local/bin/redis* 192.168.10.152:/usr/local/bin/
rsync -avz /usr/local/bin/redis* 192.168.10.153:/usr/local/bin/
rsync -avz /usr/lib/systemd/system/redis*.service 192.168.10.151:/usr/lib/systemd/system/
rsync -avz /usr/lib/systemd/system/redis*.service 192.168.10.152:/usr/lib/systemd/system/
rsync -avz /usr/lib/systemd/system/redis*.service 192.168.10.153:/usr/lib/systemd/system/
先测下db01的三个节点有没有问题:
ps -ef|grep redis
redis-cli -h 192.168.10.150 -p 6379 ping
redis-cli -h 192.168.10.150 -p 6380 ping
redis-cli -h 192.168.10.150 -p 6381 ping
# 6379是咱们原来Redis,集群搭建和学习各种套路先不用它
# 6380和6381才是集群中用到的
[root@cs ~]# ps -ef|grep redis
redis 2727 1 0 03:16 ? 00:00:00 /usr/local/bin/redis-server 192.168.10.150:6379
redis 2737 1 0 03:16 ? 00:00:00 /usr/local/bin/redis-server 192.168.10.150:6380 [cluster]
redis 2747 1 0 03:16 ? 00:00:00 /usr/local/bin/redis-server 192.168.10.150:6381 [cluster]
root 2772 1669 0 03:16 pts/0 00:00:00 grep --color=auto redis
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6379 ping
PONG
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 ping
PONG
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6381 ping
PONG
没啥问题!!!这是好的开始啊!集群部署的步骤完成了三分之一了........
现在,我们搞好了db01的Redis实例之后,也把Redis相关的文件,也一并发给了db02、db03、db04这是三个节点了,接下里,我们需要在这三个节点上稍微修改下配置就可以了。
db02快速部署Redis
替换db01发送过来的⽂件并修改IP地址:
# 如果是新的虚拟机,你需要提前做一下这些操作,注意,我这是测试环境,就直接把防火墙关了
systemctl stop firewalld.service
systemctl disable firewalld.service
systemctl status firewalld.service
sed -i.ori 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/selinux/config
yum update -y
yum -y install gcc automake autoconf libtool make
yum install -y vim wget net-tools
# 下面才是正菜
find /opt/redis638* -type f -name "*.conf"|xargs sed -i "/bind/s#150#151#g"
sed -i 's#150#151#g' /usr/lib/systemd/system/redis-*.service
mkdir -p /data/redis{6380,6381}
groupadd redis -g 1000
useradd redis -u 1000 -g 1000 -M -s /sbin/nologin
chown -R redis:redis /opt/redis*
chown -R redis:redis /data/redis*
systemctl daemon-reload
systemctl start redis-master
systemctl start redis-slave
ps -ef|grep redis
redis-cli -h 192.168.10.151 -p 6380 ping
redis-cli -h 192.168.10.151 -p 6381 ping
db03快速部署Redis
替换db01发送过来的⽂件并修改IP地址:
# 如果是新的虚拟机,你需要提前做一下这些操作,注意,我这是测试环境,就直接把防火墙关了
systemctl stop firewalld.service
systemctl disable firewalld.service
systemctl status firewalld.service
sed -i.ori 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/selinux/config
yum update -y
yum -y install gcc automake autoconf libtool make
yum install -y vim wget net-tools
# 下面才是正菜
find /opt/redis638* -type f -name "*.conf"|xargs sed -i "/bind/s#150#152#g"
sed -i 's#150#152#g' /usr/lib/systemd/system/redis-*.service
mkdir -p /data/redis{6380,6381}
groupadd redis -g 1000
useradd redis -u 1000 -g 1000 -M -s /sbin/nologin
chown -R redis:redis /opt/redis*
chown -R redis:redis /data/redis*
systemctl daemon-reload
systemctl start redis-master
systemctl start redis-slave
ps -ef|grep redis
redis-cli -h 192.168.10.152 -p 6380 ping
redis-cli -h 192.168.10.152 -p 6381 ping
db04快速部署Redis
替换db01发送过来的⽂件并修改IP地址:
# 如果是新的虚拟机,你需要提前做一下这些操作,注意,我这是测试环境,就直接把防火墙关了
systemctl stop firewalld.service
systemctl disable firewalld.service
systemctl status firewalld.service
sed -i.ori 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/selinux/config
yum update -y
yum -y install gcc automake autoconf libtool make
yum install -y vim wget net-tools
# 下面才是正菜
find /opt/redis638* -type f -name "*.conf"|xargs sed -i "/bind/s#150#153#g"
sed -i 's#150#153#g' /usr/lib/systemd/system/redis-*.service
mkdir -p /data/redis{6380,6381}
groupadd redis -g 1000
useradd redis -u 1000 -g 1000 -M -s /sbin/nologin
chown -R redis:redis /opt/redis*
chown -R redis:redis /data/redis*
systemctl daemon-reload
systemctl start redis-master
systemctl start redis-slave
ps -ef|grep redis
redis-cli -h 192.168.10.153 -p 6380 ping
redis-cli -h 192.168.10.153 -p 6381 ping
最终测试
如果你的上面几个步骤都没问题,则你可以在任意终端执行:
# db01的两个节点测试
redis-cli -h 192.168.10.150 -p 6380 PING
redis-cli -h 192.168.10.150 -p 6381 PING
# db02的两个节点测试
redis-cli -h 192.168.10.151 -p 6380 PING
redis-cli -h 192.168.10.151 -p 6381 PING
# db03的两个节点测试
redis-cli -h 192.168.10.152 -p 6380 PING
redis-cli -h 192.168.10.152 -p 6381 PING
# db04的两个节点测试
redis-cli -h 192.168.10.153 -p 6380 PING
redis-cli -h 192.168.10.153 -p 6381 PING
[root@cs ~]# # db01的两个节点测试
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 PING
PONG
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6381 PING
PONG
[root@cs ~]# # db02的两个节点测试
[root@cs ~]# redis-cli -h 192.168.10.151 -p 6380 PING
PONG
[root@cs ~]# redis-cli -h 192.168.10.151 -p 6381 PING
PONG
[root@cs ~]# # db03的两个节点测试
[root@cs ~]# redis-cli -h 192.168.10.152 -p 6380 PING
PONG
[root@cs ~]# redis-cli -h 192.168.10.152 -p 6381 PING
PONG
[root@cs ~]# # db04的两个节点测试
[root@cs ~]# redis-cli -h 192.168.10.153 -p 6380 PING
PONG
[root@cs ~]# redis-cli -h 192.168.10.153 -p 6381 PING
PONG
都返回PONG肯定都是没问题的。
现在,所有的4个服务器的redis部署完毕,且运行正常。
注意,现在的确是4台服务器上的redis都没问题,这里要说明的是:
- db01节点上的6379节点暂时不用,也不加集群。
- db04节点暂时也不用,等演示集群扩容和收缩时再用。
2. 配置集群发现
配置集群发现的命令是:
CLUSTER MEET 目标服务器的IP 目标服务器的端口
集群中,所有配置信息都是共享的,每个redis实例关于集群的配置文件,都在各自的数据目录中,比如db01的,你可以在这个目录找到:
[root@cs ~]# ls /data/redis6380/
nodes6380.conf redis6380.aof
[root@cs ~]# ls /data/redis6381/
nodes6381.conf redis6381.aof
[root@cs ~]# cat /data/redis6380/nodes6380.conf
54f258ed6c07aee2b9c5c1206fcc44e1a743f94e :0@0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
其它节点关于集群的配置文件以此类推,不在多表。
另外,集群的配置信息都是集群自己维护的,我们知道该文件在哪就行了,不要自己尝试修改这个文件。
我们来配置集群发现吧,也因为集群信息共享,我们对于集群的操作在哪台服务器上操作都是可以的。
# 通过一个节点,不断的meet其它的节点,就能把"所有好友邀请进群"
redis-cli -h 192.168.10.150 -p 6380 CLUSTER MEET 192.168.10.150 6381
redis-cli -h 192.168.10.150 -p 6380 CLUSTER MEET 192.168.10.151 6380
redis-cli -h 192.168.10.150 -p 6380 CLUSTER MEET 192.168.10.151 6381
redis-cli -h 192.168.10.150 -p 6380 CLUSTER MEET 192.168.10.152 6380
redis-cli -h 192.168.10.150 -p 6380 CLUSTER MEET 192.168.10.152 6381
# 查看集群各节点信息
redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER MEET 192.168.10.151 6380
OK
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER MEET 192.168.10.151 6381
OK
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER MEET 192.168.10.152 6380
OK
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER MEET 192.168.10.152 6381
OK
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380@16380 myself,master - 0 1691546523000 1 connected
967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381@16381 master - 0 1691546525000 3 connected
428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381@16381 master - 0 1691546525618 6 connected
a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380@16380 master - 0 1691546526640 2 connected
e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380@16380 master - 0 1691546524598 0 connected
4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381@16381 master - 0 1691546524000 7 connected
3. 分配槽位
正常的分配槽位
虽然现在都进行了发现,相互认识了,但现在集群状态仍然是有问题的,因为还没有分配槽位:
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER INFO
cluster_state:fail # fail,集群状态是fail的,不正常的
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:0
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_ping_sent:732
cluster_stats_messages_pong_sent:627
cluster_stats_messages_meet_sent:5
cluster_stats_messages_sent:1364
cluster_stats_messages_ping_received:627
cluster_stats_messages_pong_received:609
cluster_stats_messages_received:1236
那我们来分配槽位吧。
槽位规划
首先,我们分配槽位,应该只分配给主节点,这里做个约定,每台服务器的6380端口的节点,我们认为它是主节点;每台服务器的6381端口的节点,我们认为它是从节点。
所以,我们分配槽位时,也都分配给各个主节点就行了,这么算来,我们把16384个槽位平均分配给3台6380的节点。
# 首先,正常的除以3是除不尽的
>>> 16384 / 3
5461.333333333333
# 那么,针对除不尽这种情况,集群允许我们槽位可以不用绝对平均,你少俩槽位,我多俩槽位,是没问题的,所以槽位规划如下:
db01:6380 5461 0-5460
db02:6380 5461 5461-10921
db03:6380 5462 10922-16383
>>> 5461 + 5461 + 5462
16384
分配槽位
任意节点执行:
redis-cli -h 192.168.10.150 -p 6380 CLUSTER ADDSLOTS {0..5460}
redis-cli -h 192.168.10.151 -p 6380 CLUSTER ADDSLOTS {5461..10921}
redis-cli -h 192.168.10.152 -p 6380 CLUSTER ADDSLOTS {10922..16383}
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER ADDSLOTS {0..5460}
OK
[root@cs ~]# redis-cli -h 192.168.10.151 -p 6380 CLUSTER ADDSLOTS {5461..10921}
OK
[root@cs ~]# redis-cli -h 192.168.10.152 -p 6380 CLUSTER ADDSLOTS {10922..16383}
OK
我们此时再来看下集群状态:
redis-cli -h 192.168.10.150 -p 6380 CLUSTER INFO
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER INFO
cluster_state:ok # ok啦
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_ping_sent:1351
cluster_stats_messages_pong_sent:1274
cluster_stats_messages_meet_sent:5
cluster_stats_messages_sent:2630
cluster_stats_messages_ping_received:1274
cluster_stats_messages_pong_received:1228
cluster_stats_messages_received:2502
再看各节点的情况,跟未分配槽位时也不一样了。
# 未分配槽位的节点情况,都不带槽位范围
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380@16380 myself,master - 0 1691546523000 1 connected
967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381@16381 master - 0 1691546525000 3 connected
428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381@16381 master - 0 1691546525618 6 connected
a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380@16380 master - 0 1691546526640 2 connected
e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380@16380 master - 0 1691546524598 0 connected
4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381@16381 master - 0 1691546524000 7 connected
# 分配好了槽位之后,分配的几个主节点的后面都有自己的槽位范围
[root@cs ~]# redis-cli -h 192.168.10.151 -p 6380 CLUSTER NODES
967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381@16381 master - 0 1691546718886 3 connected
a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380@16380 myself,master - 0 1691546718000 2 connected 5461-10921
24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380@16380 master - 0 1691546716848 1 connected 0-5460
e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380@16380 master - 0 1691546715000 0 connected 10922-16383
4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381@16381 master - 0 1691546716000 7 connected
428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381@16381 master - 0 1691546717869 6 connected
分配槽位失败
我这边分配槽位是正常的,但有的同学会碰到偶然的情况,那就是分配失败,尤其是分配10920和10921的槽位时,会提示下面的情况:
[root@cs ~]# redis-cli -h 192.168.10.151 -p 6380 CLUSTER ADDSLOTS {5461..10921}
(error) ERR Invalid or out of range slot
我找了个截图:

如果你是报了这个错误,那么你可以这么解决,单独处理这俩槽位:
# 先添加到10920,再单独添加10921
[root@cs ~]# redis-cli -h 192.168.10.151 -p 6380 CLUSTER ADDSLOTS {5461..10920}
[root@cs ~]# redis-cli -h 192.168.10.151 -p 6380 CLUSTER ADDSLOTS 10921
剩余的正常处理就行。
4. 手动建立主从复制关系(易错步骤)
这一步是很关键的一步,因为很麻烦,一不小心就会搞错,所以,请务必小心。
经过配了那么多次的主从关系,我总结了建立主从复制关系的流程,按照流程走,相对简单些:
- 先获取集群节点信息,将结果拷贝到一个文本文件中。
- 在文本文件中,过滤出来我们需要的节点信息,其它信息删掉即可。
- 画出主从关系图。
- 根据图和过滤出来的节点信息,进行真正的建立主从复制关系。
- 检查确认是否建立成功。
1. 获取集群节点信息
redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380@16380 myself,master - 0 1691546777000 1 connected 0-5460
967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381@16381 master - 0 1691546776000 3 connected
428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381@16381 master - 0 1691546778093 6 connected
a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380@16380 master - 0 1691546777073 2 connected 5461-10921
e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380@16380 master - 0 1691546775027 0 connected 10922-16383
4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381@16381 master - 0 1691546776050 7 connected
2. 从上面的节点信息中,提取我们需要的关键数据
将上面的数据整理后,变成这样的:
# 即把我们规定的所有的6381从节点的信息过滤掉,只保留主节点的ID和IP地址,我这里也加上端口号
24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380
a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380
e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380
3. 画图,注意,从节点不要复制同一个服务器上的主节点,应该交叉复制

4. 根据画的图和拿到的节点关系,执行建立主从关系的命令
# 集群中建立主从关系的命令是,某个从节点通过CLUSTER REPLICATE,指向主节点的ID,这样就建立了二者的主从关系
redis-cli -h 192.168.10.150 -p 6381 CLUSTER REPLICATE a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f
redis-cli -h 192.168.10.151 -p 6381 CLUSTER REPLICATE e827ae7807b2f04c77702e325db3eb311403b3bb
redis-cli -h 192.168.10.152 -p 6381 CLUSTER REPLICATE 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6381 CLUSTER REPLICATE a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f
OK
[root@cs ~]# redis-cli -h 192.168.10.151 -p 6381 CLUSTER REPLICATE e827ae7807b2f04c77702e325db3eb311403b3bb
OK
[root@cs ~]# redis-cli -h 192.168.10.152 -p 6381 CLUSTER REPLICATE 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6
OK
如果大家一不小心,复制粘贴错了,建立失败了,不要慌,CLUSTER REPLICATE命令可以反复执行的,构建失败了,就把错误的命令调整好,再重新执行就完了。
当然了,生产环境,还是希望一次就能建立成功, 避免不必要的资源浪费。因为主从复制关系建立,会产生主从数据的同步,生产中,主节点的数据量很大的话,来回执行这个命令,太耗费资源了。
5. 确认是否建立成功
redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
redis-cli -h 192.168.10.150 -p 6380 CLUSTER INFO
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380@16380 myself,master - 0 1691547015000 1 connected 0-5460
967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381@16381 slave 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 0 1691547017000 3 connected # 152的6381指向150的6380,建立成功
428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381@16381 slave a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 0 1691547018195 6 connected # 150的6381指向151的6380,建立成功
a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380@16380 master - 0 1691547017170 2 connected 5461-10921
e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380@16380 master - 0 1691547017000 0 connected 10922-16383
4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381@16381 slave e827ae7807b2f04c77702e325db3eb311403b3bb 0 1691547014091 7 connected # 151的6381指向152的6380,建立成功
# 集群状态也是没问题的
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER INFO
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:7
cluster_my_epoch:1
cluster_stats_messages_ping_sent:1427
cluster_stats_messages_pong_sent:1190
cluster_stats_messages_meet_sent:5
cluster_stats_messages_sent:2622
cluster_stats_messages_ping_received:1190
cluster_stats_messages_pong_received:1196
cluster_stats_messages_received:2386
至此,手动部署redis集群完毕。
5. 往集群插入数据
ask路由
首先,所有的数据插入操作,都要通过主节点来完成,从节点只负责同步数据和查询。
-c参数不能忘
往集群插入数据就不能在像原来单节点插入数据一样了:
redis-cli -h 192.168.10.150 -p 6380 set k1 v1
redis-cli -h 192.168.10.151 -p 6380 set k1 v11
redis-cli -h 192.168.10.152 -p 6380 set k1 v111
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 set k1 v1
(error) MOVED 12706 192.168.10.152:6380
[root@cs ~]# redis-cli -h 192.168.10.151 -p 6380 set k1 v11
(error) MOVED 12706 192.168.10.152:6380
[root@cs ~]# redis-cli -h 192.168.10.152 -p 6380 set k1 v111
OK
可以看到,从150,151节点插入数据,都报错了,而且提醒说,应该将set命令移动到152节点执行,而事实上也只有152节点插入成功了。
同样的,查询时,也是提醒将命令移动到152节点执行,并且也只有152节点执行成功了。
redis-cli -h 192.168.10.150 -p 6380 get k1
redis-cli -h 192.168.10.151 -p 6380 get k1
redis-cli -h 192.168.10.152 -p 6380 get k1
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 get k1
(error) MOVED 12706 192.168.10.152:6380
[root@cs ~]# redis-cli -h 192.168.10.151 -p 6380 get k1
(error) MOVED 12706 192.168.10.152:6380
[root@cs ~]# redis-cli -h 192.168.10.152 -p 6380 get k1
"v111"
其原因就是集群的写入和查询操作也要经过算法计算出来它在哪个槽位上,然后再去对应的槽位所在的节点上执行具体的命令,我们上面的演示,跳过了这一步,所以报错并提醒了。
怎么解决呢,这里就要提一个知识点了,那就是ASK路由了。理解起来也比较简单,看图:

那就简单了,我们加上这个-c参数就行了。
redis-cli -h 192.168.10.150 -p 6380 -c get k1
redis-cli -h 192.168.10.151 -p 6380 -c get k1
redis-cli -h 192.168.10.152 -p 6380 -c get k1
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 -c get k1
"v111"
[root@cs ~]# redis-cli -h 192.168.10.151 -p 6380 -c get k1
"v111"
[root@cs ~]# redis-cli -h 192.168.10.152 -p 6380 -c get k1
"v111"
确认插入的数据是否平均分配
我们多往集群中插入一些数据,看一下是否被平均的分配到了不同的主节点上了。
1. 批量插入数据
首先,此时集群我已经将各个节点的key都删除了,保持集群数据为空。
注意,dbsize只能返回指定主节点的key的数量,而是返回整个集群的key的数量。想要看整个集群中每个主节点中key的数量,可以用--cluster info命令,后面会用到。
redis-cli -c -h 192.168.10.150 -p 6380 FLUSHALL
redis-cli -c -h 192.168.10.151 -p 6380 FLUSHALL
redis-cli -c -h 192.168.10.152 -p 6380 FLUSHALL
redis-cli -c -h 192.168.10.150 -p 6380 DBSIZE
redis-cli -c -h 192.168.10.151 -p 6380 DBSIZE
redis-cli -c -h 192.168.10.152 -p 6380 DBSIZE
[root@cs ~]# redis-cli -c -h 192.168.10.150 -p 6380 FLUSHALL
OK
[root@cs ~]# redis-cli -c -h 192.168.10.151 -p 6380 FLUSHALL
OK
[root@cs ~]# redis-cli -c -h 192.168.10.152 -p 6380 FLUSHALL
OK
[root@cs ~]# redis-cli -c -h 192.168.10.150 -p 6380 DBSIZE
(integer) 0
[root@cs ~]# redis-cli -c -h 192.168.10.151 -p 6380 DBSIZE
(integer) 0
[root@cs ~]# redis-cli -c -h 192.168.10.152 -p 6380 DBSIZE
(integer) 0
2. 批量插入数据
往空集群中插入一千(你也可以搞成一万或者更多)条数据:
for i in {1..1000};do redis-cli -c -h 192.168.10.150 -p 6380 set k_${i} v_${i}&& echo "${i} is ok";done
3. 看看各个主节点的key的数量是不是相对平均
redis-cli -c -h 192.168.10.150 -p 6380 DBSIZE
redis-cli -c -h 192.168.10.151 -p 6380 DBSIZE
redis-cli -c -h 192.168.10.152 -p 6380 DBSIZE
[root@cs ~]# redis-cli -c -h 192.168.10.150 -p 6380 DBSIZE
(integer) 339
[root@cs ~]# redis-cli -c -h 192.168.10.151 -p 6380 DBSIZE
(integer) 326
[root@cs ~]# redis-cli -c -h 192.168.10.152 -p 6380 DBSIZE
(integer) 335
还是相对平均的。
也可以用rebalance来看下提示,说是不需要重新分配,各主节点的槽位数量误差在2.00%范围内,这都是允许的。
redis-cli --cluster rebalance 192.168.10.150:6380
[root@cs ~]# redis-cli --cluster rebalance 192.168.10.150:6380
>>> Performing Cluster Check (using node 192.168.10.150:6380)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
*** No rebalancing needed! All nodes are within the 2.00% threshold.
也可以通过另一个命令,检查集群状态:
redis-cli --cluster info 192.168.10.150:6380
[root@cs ~]# redis-cli --cluster info 192.168.10.150:6380
192.168.10.150:6380 (24476f40...) -> 339 keys | 5461 slots | 1 slaves.
192.168.10.151:6380 (a8b02756...) -> 326 keys | 5461 slots | 1 slaves.
192.168.10.152:6380 (e827ae78...) -> 335 keys | 5462 slots | 1 slaves.
[OK] 1000 keys in 3 masters.
0.06 keys per slot on average.
返回了三个主节点上,每个主节点的槽位数量和key的数量,以及每个主节点的slave的数量。
现在整个集群都是正常的,可用的。
自动部署集群
经过前面收到部署的过程,我们对部署中的细节有了清晰的认知,但也能感觉到部署过程的繁琐,一不小心就可能出错。
那么既然能手动搞的,我们就会想到搞个工具自动帮我们做这些事情不就完了吗!答案是真的可以通过工具来完成自动部署集群。
redis-trib.rb:是在redis3.x版本时所用的一种部署redis集群的工具,用redis-trib.rb创建集群之前需要配置ruby环境,新版本的redis-cli可以直接创建集群环境而不用配置ruby环境。redis-cli:,redis-cli是redis4.x及更高版本所支持创建集群的工具,在redis3.x版本时redis-cli只是一个客户端连接管理工具。redis-cli比redis-trib.rb多了一个可以认证集群密码的功能,后者创建的集群不能对有密码的集群节点进行很好的管理,所以后来官方直接废弃了这个工具。
有了自动化的个工具,我们集群部署流程,就剩下了:
- 各个服务器上的Redis实例还是需要手动来做的。
- 使用自动化工具部署Redis集群。
接下来演示下这两个工具的用法。
通过rubygems完成集群自动部署
PS:这里我只列出在Redis3.x时集群部署的步骤,这里用的redis5.x版本,如果使用这个工具创建集群,就会提示你改用redis-cli工具创建集群。
所以,看我给你演示一下效果。
1. 下载工具
注意,这个工具你可以安装到每个服务器上,也可以只安装到某个服务器上就行了。我这里以db01服务器来演示。
# 下载安装
yum install -y rubygems
gem sources -a http://mirrors.aliyun.com/rubygems/
gem sources --remove http://rubygems.org/
gem install redis -v 3.3.3
# 安装完成之后,在redis的安装目录的src中,就有了一个redis-trib.rb文件,我们通过这个脚本来自动部署redis集群
[root@cs ~]# ls /opt/redis-5.0.7/src/*.rb
/opt/redis-5.0.7/src/redis-trib.rb
2. 还原集群状态
由于我之前手动部署的集群还是完整的,现在要把集群还原到原点,如果你是干净的,可以不用跟着做这一步。
如果集群中有数据的话,请注意备份,因为还原集群要进行reset,而进行reset时,各个主节点中不能有数据,不然你就会遇到这样的提示,从节点reset成功,主节点提醒我们master nodes containing keys,导致主节点reset失败。
redis-cli -c -h 192.168.10.150 -p 6380 CLUSTER RESET
redis-cli -c -h 192.168.10.151 -p 6380 CLUSTER RESET
redis-cli -c -h 192.168.10.152 -p 6380 CLUSTER RESET
redis-cli -c -h 192.168.10.150 -p 6381 CLUSTER RESET
redis-cli -c -h 192.168.10.151 -p 6381 CLUSTER RESET
redis-cli -c -h 192.168.10.152 -p 6381 CLUSTER RESET
[root@cs ~]# redis-cli -c -h 192.168.10.150 -p 6380 CLUSTER RESET
(error) ERR CLUSTER RESET can't be called with master nodes containing keys
[root@cs ~]# redis-cli -c -h 192.168.10.151 -p 6380 CLUSTER RESET
(error) ERR CLUSTER RESET can't be called with master nodes containing keys
[root@cs ~]# redis-cli -c -h 192.168.10.152 -p 6380 CLUSTER RESET
(error) ERR CLUSTER RESET can't be called with master nodes containing keys
[root@cs ~]# redis-cli -c -h 192.168.10.150 -p 6381 CLUSTER RESET
OK
[root@cs ~]# redis-cli -c -h 192.168.10.151 -p 6381 CLUSTER RESET
OK
[root@cs ~]# redis-cli -c -h 192.168.10.152 -p 6381 CLUSTER RESET
OK
所以,我需要把主节点的数据清空再执行reset:
# 1. 清空集群数据
redis-cli -c -h 192.168.10.150 -p 6380 FLUSHALL
redis-cli -c -h 192.168.10.151 -p 6380 FLUSHALL
redis-cli -c -h 192.168.10.152 -p 6380 FLUSHALL
redis-cli -c -h 192.168.10.150 -p 6380 DBSIZE
redis-cli -c -h 192.168.10.151 -p 6380 DBSIZE
redis-cli -c -h 192.168.10.152 -p 6380 DBSIZE
[root@cs ~]# redis-cli -c -h 192.168.10.150 -p 6380 FLUSHALL
OK
[root@cs ~]# redis-cli -c -h 192.168.10.151 -p 6380 FLUSHALL
OK
[root@cs ~]# redis-cli -c -h 192.168.10.152 -p 6380 FLUSHALL
OK
[root@cs ~]# redis-cli -c -h 192.168.10.150 -p 6380 DBSIZE
(integer) 0
[root@cs ~]# redis-cli -c -h 192.168.10.151 -p 6380 DBSIZE
(integer) 0
[root@cs ~]# redis-cli -c -h 192.168.10.152 -p 6380 DBSIZE
(integer) 0
# 2. 所有节点都进行CLUSTER RESET
redis-cli -c -h 192.168.10.150 -p 6380 CLUSTER RESET
redis-cli -c -h 192.168.10.151 -p 6380 CLUSTER RESET
redis-cli -c -h 192.168.10.152 -p 6380 CLUSTER RESET
redis-cli -c -h 192.168.10.150 -p 6381 CLUSTER RESET
redis-cli -c -h 192.168.10.151 -p 6381 CLUSTER RESET
redis-cli -c -h 192.168.10.152 -p 6381 CLUSTER RESET
[root@cs ~]# redis-cli -c -h 192.168.10.150 -p 6380 CLUSTER RESET
OK
[root@cs ~]# redis-cli -c -h 192.168.10.151 -p 6380 CLUSTER RESET
OK
[root@cs ~]# redis-cli -c -h 192.168.10.152 -p 6380 CLUSTER RESET
OK
[root@cs ~]# redis-cli -c -h 192.168.10.150 -p 6381 CLUSTER RESET
OK
[root@cs ~]# redis-cli -c -h 192.168.10.151 -p 6381 CLUSTER RESET
OK
[root@cs ~]# redis-cli -c -h 192.168.10.152 -p 6381 CLUSTER RESET
OK
3. 使用工具快速进行自动化集群部署
cd /opt/redis-5.0.7/src
./redis-trib.rb create --replicas 1 192.168.10.150:6380 192.168.10.151:6380 192.168.10.152:6380 192.168.10.150:6381 192.168.10.151:6381 192.168.10.152:6381
# --replicas 1 这个1表示一个主节点有一个从节点
# 然后一共6个节点,我们把作为主节点的三个节点放在前面,作为从节点的三个节点放到后面,这个自动化工具就会自动帮我们建立主从关系,且主从节点不会复制同一个服务器上的主节点
但现在,我们在Redis5.x版本中用的话,会提示:
[root@cs ~]# cd /opt/redis-5.0.7/src
[root@cs src]# ./redis-trib.rb create --replicas 1 192.168.10.150:6380 192.168.10.151:6380 192.168.10.152:6380 192.168.10.150:6381 192.168.10.151:6381 192.168.10.152:6381
WARNING: redis-trib.rb is not longer available!
You should use redis-cli instead.
All commands and features belonging to redis-trib.rb have been moved to redis-cli.
In order to use them you should call redis-cli with the --cluster
option followed by the subcommand name, arguments and options.
Use the following syntax:
redis-cli --cluster SUBCOMMAND [ARGUMENTS] [OPTIONS]
Example:
redis-cli --cluster create 192.168.10.150:6380 192.168.10.151:6380 192.168.10.152:6380 192.168.10.150:6381 192.168.10.151:6381 192.168.10.152:6381 --cluster-replicas 1
To get help about all subcommands, type:
redis-cli --cluster help
好吧,所有属于redis-trib的命令和功能。都已经被移动到了redis-cli中了,甚至命令都给你弄好了:
redis-cli --cluster create 192.168.10.150:6380 192.168.10.151:6380 192.168.10.152:6380 192.168.10.150:6381 192.168.10.151:6381 192.168.10.152:6381 --cluster-replicas 1
通过redis-cli完成集群自动部署
1. 还原集群状态
# 注意,我们只需要对此时集群中的所有的主节点执行flushall的命令进行清空主节点的数据,而不需要对从节点进行清空数据。因为从节点是只读的节点,不允许flushall的动作。
redis-cli -c -h 192.168.10.150 -p 6380 FLUSHALL
redis-cli -c -h 192.168.10.151 -p 6380 FLUSHALL
redis-cli -c -h 192.168.10.152 -p 6380 FLUSHALL
redis-cli -c -h 192.168.10.150 -p 6380 DBSIZE
redis-cli -c -h 192.168.10.151 -p 6380 DBSIZE
redis-cli -c -h 192.168.10.152 -p 6380 DBSIZE
redis-cli -c -h 192.168.10.150 -p 6380 CLUSTER RESET
redis-cli -c -h 192.168.10.151 -p 6380 CLUSTER RESET
redis-cli -c -h 192.168.10.152 -p 6380 CLUSTER RESET
redis-cli -c -h 192.168.10.150 -p 6381 CLUSTER RESET
redis-cli -c -h 192.168.10.151 -p 6381 CLUSTER RESET
redis-cli -c -h 192.168.10.152 -p 6381 CLUSTER RESET
[root@cs src]# redis-cli -c -h 192.168.10.150 -p 6380 FLUSHALL
OK
[root@cs src]# redis-cli -c -h 192.168.10.151 -p 6380 FLUSHALL
OK
[root@cs src]# redis-cli -c -h 192.168.10.152 -p 6380 FLUSHALL
OK
[root@cs src]# redis-cli -c -h 192.168.10.150 -p 6380 DBSIZE
(integer) 0
[root@cs src]# redis-cli -c -h 192.168.10.151 -p 6380 DBSIZE
(integer) 0
[root@cs src]# redis-cli -c -h 192.168.10.152 -p 6380 DBSIZE
(integer) 0
[root@cs src]# redis-cli -c -h 192.168.10.150 -p 6380 CLUSTER RESET
OK
[root@cs src]# redis-cli -c -h 192.168.10.151 -p 6380 CLUSTER RESET
OK
[root@cs src]# redis-cli -c -h 192.168.10.152 -p 6380 CLUSTER RESET
OK
[root@cs src]# redis-cli -c -h 192.168.10.150 -p 6381 CLUSTER RESET
OK
[root@cs src]# redis-cli -c -h 192.168.10.151 -p 6381 CLUSTER RESET
OK
[root@cs src]# redis-cli -c -h 192.168.10.152 -p 6381 CLUSTER RESET
OK
2. 快速部署集群
# 这个命令还有个交互,提示你输入yes
redis-cli --cluster create 192.168.10.150:6380 192.168.10.151:6380 192.168.10.152:6380 192.168.10.150:6381 192.168.10.151:6381 192.168.10.152:6381 --cluster-replicas 1
# 我们改造下命令,连交互输入的yes都不要了
echo "yes"|redis-cli --cluster create 192.168.10.150:6380 192.168.10.151:6380 192.168.10.152:6380 192.168.10.150:6381 192.168.10.151:6381 192.168.10.152:6381 --cluster-replicas 1
[root@cs src]# redis-cli --cluster create --cluster-replicas 1 192.168.10.150:6380 192.168.10.151:6380 192.168.10.152:6380 192.168.10.150:6381 192.168.10.151:6381 192.168.10.152:6381
>>> Performing hash slots allocation on 6 nodes...
# 这里提示三个主节点的槽位分布
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
# 这里告诉我们主从复制关系
Adding replica 192.168.10.151:6381 to 192.168.10.150:6380
Adding replica 192.168.10.152:6381 to 192.168.10.151:6380
Adding replica 192.168.10.150:6381 to 192.168.10.152:6380
M: 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380
slots:[0-5460] (5461 slots) master
M: a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380
slots:[5461-10922] (5462 slots) master
M: e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380
slots:[10923-16383] (5461 slots) master
S: 428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381
replicates e827ae7807b2f04c77702e325db3eb311403b3bb
S: 4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381
replicates 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6
S: 967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381
replicates a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f
Can I set the above configuration? (type 'yes' to accept): yes # 还是有个交互的,我们按照提示输入 yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
...
>>> Performing Cluster Check (using node 192.168.10.150:6380)
M: 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381
slots: (0 slots) slave
replicates a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f
S: 428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381
slots: (0 slots) slave
replicates e827ae7807b2f04c77702e325db3eb311403b3bb
M: a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381
slots: (0 slots) slave
replicates 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6
M: e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
ok,没有什么报错。
3. 确认集群状态
我们来看下集群状态:
for i in {1..10000};do redis-cli -c -h 192.168.10.150 -p 6380 set k_${i} v_${i}&& echo "${i} is ok";done
redis-cli --cluster info 192.168.10.150:6380
redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
[root@cs src]# redis-cli --cluster info 192.168.10.150:6380
192.168.10.150:6380 (24476f40...) -> 3343 keys | 5461 slots | 1 slaves.
192.168.10.151:6380 (a8b02756...) -> 3316 keys | 5462 slots | 1 slaves.
192.168.10.152:6380 (e827ae78...) -> 3341 keys | 5461 slots | 1 slaves.
[OK] 10000 keys in 3 masters.
0.61 keys per slot on average.
[root@cs src]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380@16380 myself,master - 0 1691551074000 1 connected 0-5460
967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381@16381 slave a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 0 1691551076646 8 connected
428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381@16381 slave e827ae7807b2f04c77702e325db3eb311403b3bb 0 1691551073583 6 connected
a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380@16380 master - 0 1691551075623 2 connected 5461-10922
4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381@16381 slave 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 0 1691551076000 7 connected
e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380@16380 master - 0 1691551074000 3 connected 10923-16383
没得问题!!!!
集群收缩与扩容
集群扩容与收缩
扩容:也就是像现有集群中加入新的节点。
收缩:也就是将现有的主节点下线。
道理挺简单,就是操作起来有点麻烦,因为要手动处理槽位关系。关于槽位,一定要牢记,无论集群有多少个节点,槽位数量是固定不变的16384个。
那你想要扩容,就要从新计算,扩容后的主节点的数量有多少?平均每个主节点应该分到多少个槽位?以及,现有的每个主节点应该向新加入的主节点分配多少槽位?这都是我们需要在下手之前进行计算好的。

迁移中可能会遇到的问题,也是我们需要提前了解和做好预案的:
Q:迁移槽位时,该槽位的数据会不会迁移过去?
A:会的,并且有可能会出现迁移数据出现中断的的情况。
Q:迁移过程集群的读写受影响吗?
A:不会,迁移过程读写能够正常读写,但由于仍然会消耗性能,所以建议迁移动作放到业务不繁忙时进行。
集群扩容
1. 准备新的服务器,并且在新的服务器上,安装好Redis实例,并且启动它。
首先,准备好一台新的服务器,我这里用上咱们最开始的一台服务器,db04,且环境都是好的。
systemctl start redis-master
systemctl start redis-slave
ps -ef|grep redis
[root@cs ~]# systemctl start redis-master
[root@cs ~]# systemctl start redis-slave
[root@cs ~]# ps -ef|grep redis
redis 70739 1 0 16:24 ? 00:00:00 /usr/local/bin/redis-server 192.168.10.153:6380 [cluster]
redis 70749 1 0 16:24 ? 00:00:00 /usr/local/bin/redis-server 192.168.10.153:6381 [cluster]
root 70754 70714 0 16:24 pts/0 00:00:00 grep --color=auto redis
2. 邀请进群
# 通过150节点,将153节点的两个小伙伴拉进群
redis-cli -h 192.168.10.150 -p 6380 CLUSTER MEET 192.168.10.153 6380
redis-cli -h 192.168.10.150 -p 6380 CLUSTER MEET 192.168.10.153 6381
redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER MEET 192.168.10.153 6380
OK
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER MEET 192.168.10.153 6381
OK
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380@16380 myself,master - 0 1691569492000 1 connected 0-5460
967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381@16381 slave a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 0 1691569492119 8 connected
428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381@16381 slave e827ae7807b2f04c77702e325db3eb311403b3bb 0 1691569493140 6 connected
1ad2341ae07cc084c75c1130ff2b9936d3bea7b7 192.168.10.153:6381@16381 master - 0 1691569492329 0 connected # 此时处于进群了,但还没有分配槽位,也没配置主从关系,所以都是master
a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380@16380 master - 0 1691569491102 2 connected 5461-10922
4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381@16381 slave 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 0 1691569492000 7 connected
e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380@16380 master - 0 1691569489059 3 connected 10923-16383
8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae 192.168.10.153:6380@16380 master - 0 1691569492329 0 connected # 此时处于进群了,但还没有分配槽位,也没配置主从关系,所以都是master
3. 分配槽位
分配槽位这里,有两种方式,一种麻烦,一种简单,我都演示下。
先说复杂的done的用法:
# 通过任意节点,向集群发送reshard命令,开始进行分配槽位的动作,我们将会进行4次交互
redis-cli --cluster reshard 192.168.10.150:6380
# 第一次交互:因为接下来的步骤是每个主节点都要向新节点分配部分槽位,那么这里第一次交互就问我们新节点分配槽位的总数是多少?填写4096
How many slots do you want to move (from 1 to 16384)? 4096
# 第二次交互:问我们接受主节点的ID?我们需要填写新节点153的6380的ID,因为其它节点的槽位分配给它嘛
What is the receiving node ID? 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae
# 第三次交互:这一步有点麻烦,人家给你两个选择:
# 1. 填写all,然后回车,集群内部会计算出来每个主节点应该分配出来多少槽位给新节点,这一切都是自动的
# 2. 直接写每个主节点的ID,你要写所有的主节点的ID,然后输入done,表示填写的这些主节点分配出来槽位给新节点
# Source node #1: db01的6380节点的ID
# Source node #2: db02的6380节点的ID
# Source node #3: db03的6380节点的ID
# Source node #4: done
How many slots do you want to move (from 1 to 16384)? 4096
What is the receiving node ID? 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6
Source node #2: a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f
Source node #3: e827ae7807b2f04c77702e325db3eb311403b3bb
Source node #4: done
# 第四次交互:最终确认,输入yes就真正的开始了,如果你想反悔,这里输入no,或者ctrl+c反悔退出交互
Do you want to proceed with the proposed reshard plan (yes/no)? 我这里直接ctrl+c退出交互,因为我要演示第二种all的用法
过程:
[root@cs ~]# redis-cli --cluster reshard 192.168.10.150:6380
>>> Performing Cluster Check (using node 192.168.10.150:6380)
M: 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381
slots: (0 slots) slave
replicates a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f
S: 428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381
slots: (0 slots) slave
replicates e827ae7807b2f04c77702e325db3eb311403b3bb
M: 1ad2341ae07cc084c75c1130ff2b9936d3bea7b7 192.168.10.153:6381
slots: (0 slots) master
M: a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381
slots: (0 slots) slave
replicates 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6
M: e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae 192.168.10.153:6380
slots: (0 slots) master
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 4096
What is the receiving node ID? 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6
Source node #2: a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f
Source node #3: e827ae7807b2f04c77702e325db3eb311403b3bb
Source node #4: done
......省略......
Moving slot 12283 from e827ae7807b2f04c77702e325db3eb311403b3bb
Moving slot 12284 from e827ae7807b2f04c77702e325db3eb311403b3bb
Moving slot 12285 from e827ae7807b2f04c77702e325db3eb311403b3bb
Moving slot 12286 from e827ae7807b2f04c77702e325db3eb311403b3bb
Moving slot 12287 from e827ae7807b2f04c77702e325db3eb311403b3bb
......省略......
Do you want to proceed with the proposed reshard plan (yes/no)? 我这里直接ctrl+c退出交互,因为我要演示第二种all的用法
好吧,我们用all,比较简单:
# 为了验证分配槽位的过程中,不影响集群的读写,你可以分别在另外两个终端,进行读写测试
# 151的终端测试写
for i in {1..10000};do redis-cli -c -h 192.168.10.151 -p 6380 set k_${i} v_${i} && echo ${i} is ok;sleep 0.2;done
# 152的终端测试读
for i in {1..10000};do redis-cli -c -h 192.168.10.152 -p 6380 get k_${i};sleep 0.2;done
# 上面两个读写让它运行着,我们在150终端进行分配槽位
redis-cli --cluster reshard 192.168.10.150:6380
[root@cs ~]# redis-cli --cluster reshard 192.168.10.150:6380
>>> Performing Cluster Check (using node 192.168.10.150:6380)
M: 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381
slots: (0 slots) slave
replicates a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f
S: 428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381
slots: (0 slots) slave
replicates e827ae7807b2f04c77702e325db3eb311403b3bb
M: 1ad2341ae07cc084c75c1130ff2b9936d3bea7b7 192.168.10.153:6381
slots: (0 slots) master
M: a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381
slots: (0 slots) slave
replicates 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6
M: e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae 192.168.10.153:6380
slots: (0 slots) master
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 4096 # 第一次交互,输入4096
What is the receiving node ID? 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae # 第二次交互,输入153这个新节点的ID,在上面能找到,注意别复制粘贴错了
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: all # 第三次交互,直接输入all,然后回车
......省略......
Moving slot 12283 from e827ae7807b2f04c77702e325db3eb311403b3bb
Moving slot 12284 from e827ae7807b2f04c77702e325db3eb311403b3bb
Moving slot 12285 from e827ae7807b2f04c77702e325db3eb311403b3bb
Moving slot 12286 from e827ae7807b2f04c77702e325db3eb311403b3bb
Moving slot 12287 from e827ae7807b2f04c77702e325db3eb311403b3bb
......省略......
Do you want to proceed with the proposed reshard plan (yes/no)? yes # 第四次交互,直接输入yes,然后回车
......省略......
Moving slot 12286 from 192.168.10.152:6380 to 192.168.10.153:6380:
Moving slot 12287 from 192.168.10.152:6380 to 192.168.10.153:6380: .
......省略......
[root@cs ~]# # 没有啥报错,基本说明槽位分配成功了
4. 确认分配成功
redis-cli -h 192.168.10.150 -p 6380 CLUSTER INFO
redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
redis-cli --cluster info 192.168.10.150:6380
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER INFO
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:8
cluster_size:4
cluster_current_epoch:10
cluster_my_epoch:1
cluster_stats_messages_ping_sent:23726
cluster_stats_messages_pong_sent:23230
cluster_stats_messages_meet_sent:7
cluster_stats_messages_update_sent:7
cluster_stats_messages_sent:46970
cluster_stats_messages_ping_received:23225
cluster_stats_messages_pong_received:23497
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:46727
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380@16380 myself,master - 0 1691571239000 1 connected 1365-5460
967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381@16381 slave a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 0 1691571237000 8 connected
428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381@16381 slave e827ae7807b2f04c77702e325db3eb311403b3bb 0 1691571238000 6 connected
1ad2341ae07cc084c75c1130ff2b9936d3bea7b7 192.168.10.153:6381@16381 master - 0 1691571238000 9 connected
a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380@16380 master - 0 1691571238422 2 connected 6827-10922
4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381@16381 slave 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 0 1691571240474 7 connected
e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380@16380 master - 0 1691571239448 3 connected 12288-16383
8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae 192.168.10.153:6380@16380 master - 0 1691571236000 10 connected 0-1364 5461-6826 10923-12287
[root@cs ~]# redis-cli --cluster info 192.168.10.150:6380
192.168.10.150:6380 (24476f40...) -> 2498 keys | 4096 slots | 1 slaves.
192.168.10.153:6381 (1ad2341a...) -> 0 keys | 0 slots | 0 slaves. # 153的从节点,现在还没有进行主从复制关联,所以,还是这个状态
192.168.10.151:6380 (a8b02756...) -> 2486 keys | 4096 slots | 1 slaves.
192.168.10.152:6380 (e827ae78...) -> 2501 keys | 4096 slots | 1 slaves.
192.168.10.153:6380 (8fa4d787...) -> 2515 keys | 4096 slots | 0 slaves. # 153主节点有了4096个槽位,现在有2515个key
[OK] 10000 keys in 5 masters.
0.61 keys per slot on average.
5. 把153服务器的从节点也整上主从复制关系
但注意,我们此时多了个一个服务器,就要从新调整下主从复制关系了。

当然了,这只是示意图,而我们此时的真实的主从关系肯定不是最开始这样的了,因为我们在前面自动部署集群章节,自动部署时,集群内部建立的主从关系肯定和我们的有所出入,这里,我直接都把所有的从节点的主从关系,调整到和上图右侧示例一样的效果。
只不过,生产中,你只需要调整涉及到的节点就行了,我这里测试环境下,key也不多,直接都重构了,也没事。
# 过程省略,不会的复习前面手动建立主从复制关系章节
redis-cli -h 192.168.10.150 -p 6381 CLUSTER REPLICATE a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f
redis-cli -h 192.168.10.151 -p 6381 CLUSTER REPLICATE e827ae7807b2f04c77702e325db3eb311403b3bb
redis-cli -h 192.168.10.152 -p 6381 CLUSTER REPLICATE 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae
redis-cli -h 192.168.10.153 -p 6381 CLUSTER REPLICATE 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6
redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
redis-cli --cluster info 192.168.10.150:6380
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6381 CLUSTER REPLICATE a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f
OK
[root@cs ~]# redis-cli -h 192.168.10.151 -p 6381 CLUSTER REPLICATE e827ae7807b2f04c77702e325db3eb311403b3bb
OK
[root@cs ~]# redis-cli -h 192.168.10.152 -p 6381 CLUSTER REPLICATE 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae
OK
[root@cs ~]# redis-cli -h 192.168.10.153 -p 6381 CLUSTER REPLICATE 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6
OK
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380@16380 myself,master - 0 1691572832000 1 connected 1365-5460
967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381@16381 slave 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae 0 1691572834409 10 connected # 152的从复制153的主
428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381@16381 slave a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 0 1691572833000 6 connected # 150的从复制151的主
1ad2341ae07cc084c75c1130ff2b9936d3bea7b7 192.168.10.153:6381@16381 slave 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 0 1691572830324 9 connected # 153的从复制150的主
a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380@16380 master - 0 1691572835000 2 connected 6827-10922
4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381@16381 slave e827ae7807b2f04c77702e325db3eb311403b3bb 0 1691572831000 7 connected # 151的从复制152的主,都符合预期
e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380@16380 master - 0 1691572833387 3 connected 12288-16383
8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae 192.168.10.153:6380@16380 master - 0 1691572835436 10 connected 0-1364 5461-6826 10923-12287
[root@cs ~]# redis-cli --cluster info 192.168.10.150:6380
192.168.10.150:6380 (24476f40...) -> 2498 keys | 4096 slots | 1 slaves.
192.168.10.151:6380 (a8b02756...) -> 2486 keys | 4096 slots | 1 slaves.
192.168.10.152:6380 (e827ae78...) -> 2501 keys | 4096 slots | 1 slaves.
192.168.10.153:6380 (8fa4d787...) -> 2515 keys | 4096 slots | 1 slaves. # 这几个也都正常,nice
[OK] 10000 keys in 4 masters.
0.61 keys per slot on average.
一切符合预期!!!
集群收缩
好吧,又要进行一顿槽位迁移的动作了.........

集群收缩的流程
- 计算要迁移出来的槽位,分配给集群的其它主节点,各自分多少?
- 执行迁移,每次只能从要下线的节点往其中一个主节点进行迁移槽位,所以,有多少主节点,你就要把迁移动作执行多少轮。
- 迁移成功,把主节点所在的服务器给它下线,如果此时该服务器上还有从节点,那么一并都给下线了。
- 调整此时集群的主从关系。
什么槽位计算什么的,不在赘述,这里直接上代码。
1. 执行集群收缩的命令
这就有点操蛋了, 因为每次接下来的操作要重复执行三轮,因为每次只能从下线节点往一个目标节点迁移槽位,而不能同时往多个目标节点迁移槽位。
# 通过任意节点,向集群发送reshard命令,开始进行分配槽位的动作,我们将会进行4次交互
redis-cli --cluster reshard 192.168.10.150:6380
# 下面的交互要执行三轮,而每轮又有四个交互
# 1366 + 1365 + 1365 = 4096
# 第一次交互:从要下线的节点迁移出多少个槽位?我第一次按照习惯往150节点迁移,应该迁移的槽位数量是1366,所以填写1366
How many slots do you want to move (from 1 to 16384)? 1366
# 第二次交互:槽位要迁移到哪个目标节点,我们这里应该填写150节点的ID
What is the receiving node ID?
# 第三次交互:哪些节点需要迁移出1366个槽位?而我们只有153节点需要下线,所以这一轮只能填写一个153节点的ID即可
# Source node #1: db03的6380节点的ID
# Source node #2: done
# 第四次交互:最终确认,输入yes就真正的开始了,如果你想反悔,这里输入no,我这里输入yes
Do you want to proceed with the proposed reshard plan (yes/no)? yes
# 如果不报错:
# 第一轮向150的6380节点迁移1366个槽位结束
# 第二轮应该向151的6380节点迁移1365个槽位
# 第三轮应该向152的6380节点迁移1365个槽位
过程:
# 第一轮
[root@cs ~]# redis-cli --cluster reshard 192.168.10.150:6380 # 每次都可以通过任意主节点访问到集群执行reshard命令
>>> Performing Cluster Check (using node 192.168.10.150:6380)
M: 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380
slots:[1365-5460] (4096 slots) master
1 additional replica(s)
S: 967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381
slots: (0 slots) slave
replicates 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae
S: 428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381
slots: (0 slots) slave
replicates a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f
S: 1ad2341ae07cc084c75c1130ff2b9936d3bea7b7 192.168.10.153:6381
slots: (0 slots) slave
replicates 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6
M: a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380
slots:[6827-10922] (4096 slots) master
1 additional replica(s)
S: 4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381
slots: (0 slots) slave
replicates e827ae7807b2f04c77702e325db3eb311403b3bb
M: e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380
slots:[12288-16383] (4096 slots) master
1 additional replica(s)
M: 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae 192.168.10.153:6380
slots:[0-1364],[5461-6826],[10923-12287] (4096 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 1366 # 向目标节点迁移多少个槽位
What is the receiving node ID? 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 # 填写目标节点的ID,我先向150的主节点迁移,所以填写的是150的ID
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae # 哪个节点向150节点迁移数据,就填写谁,所以这里填写153主节点的ID
Source node #2: done # 填写done
......省略......
Moving slot 1363 from 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae
Moving slot 1364 from 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae
Moving slot 5461 from 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae
......省略......
Do you want to proceed with the proposed reshard plan (yes/no)? yes # 第四次交互,直接输入yes,然后回车
......省略......
Moving slot 1364 from 192.168.10.153:6380 to 192.168.10.150:6380: .
Moving slot 5461 from 192.168.10.153:6380 to 192.168.10.150:6380:
......省略......
[root@cs ~]# # 没有啥报错,基本说明槽位分配成功了
# 第二轮
[root@cs ~]# redis-cli --cluster reshard 192.168.10.150:6380 # 每次都可以通过任意主节点访问到集群执行reshard命令
......省略......
How many slots do you want to move (from 1 to 16384)? 1365 # 向目标节点迁移多少个槽位
What is the receiving node ID? a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f # 该向151节点迁移槽位了,所以这里填写151主节点的ID
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae # 哪个节点向150节点迁移数据,就填写谁,所以这里填写153主节点的ID
Source node #2: done
......省略......
Moving slot 1363 from 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae
Moving slot 1364 from 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae
Moving slot 5461 from 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae
......省略......
Do you want to proceed with the proposed reshard plan (yes/no)? yes # 第四次交互,直接输入yes,然后回车
......省略......
Moving slot 1364 from 192.168.10.153:6380 to 192.168.10.150:6380: .
Moving slot 5461 from 192.168.10.153:6380 to 192.168.10.150:6380:
......省略......
[root@cs ~]# # 没有啥报错,基本说明槽位分配成功了
# 第三轮
[root@cs ~]# redis-cli --cluster reshard 192.168.10.150:6380 # 每次都可以通过任意主节点访问到集群执行reshard命令
......省略......
How many slots do you want to move (from 1 to 16384)? 1365 # 向目标节点迁移多少个槽位
What is the receiving node ID? e827ae7807b2f04c77702e325db3eb311403b3bb # 该向152节点迁移槽位了,所以这里填写151主节点的ID
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae # 哪个节点向150节点迁移数据,就填写谁,所以这里填写153主节点的ID
Source node #2: done
......省略......
Moving slot 1363 from 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae
Moving slot 1364 from 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae
Moving slot 5461 from 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae
......省略......
Do you want to proceed with the proposed reshard plan (yes/no)? yes # 第四次交互,直接输入yes,然后回车
......省略......
Moving slot 1364 from 192.168.10.153:6380 to 192.168.10.150:6380: .
Moving slot 5461 from 192.168.10.153:6380 to 192.168.10.150:6380:
......省略......
[root@cs ~]# # 没有啥报错,基本说明槽位分配成功了
2. 确认迁移成功
redis-cli -h 192.168.10.150 -p 6380 CLUSTER INFO
redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
redis-cli --cluster info 192.168.10.150:6380
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER INFO
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:8
cluster_size:3
cluster_current_epoch:13
cluster_my_epoch:11
cluster_stats_messages_ping_sent:28556
cluster_stats_messages_pong_sent:27895
cluster_stats_messages_meet_sent:7
cluster_stats_messages_update_sent:14
cluster_stats_messages_sent:56472
cluster_stats_messages_ping_received:27890
cluster_stats_messages_pong_received:28327
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:56222
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380@16380 myself,master - 0 1691576093000 11 connected 0-5461
967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381@16381 slave e827ae7807b2f04c77702e325db3eb311403b3bb 0 1691576096472 13 connected
428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381@16381 slave a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 0 1691576097490 12 connected
1ad2341ae07cc084c75c1130ff2b9936d3bea7b7 192.168.10.153:6381@16381 slave 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 0 1691576093000 11 connected
a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380@16380 master - 0 1691576095000 12 connected 5462-10922
4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381@16381 slave e827ae7807b2f04c77702e325db3eb311403b3bb 0 1691576093000 13 connected
e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380@16380 master - 0 1691576097000 13 connected 10923-16383
8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae 192.168.10.153:6380@16380 master - 0 1691576095000 10 connected
[root@cs ~]# redis-cli --cluster info 192.168.10.150:6380
192.168.10.150:6380 (24476f40...) -> 3343 keys | 5462 slots | 1 slaves.
192.168.10.151:6380 (a8b02756...) -> 3316 keys | 5461 slots | 1 slaves.
192.168.10.152:6380 (e827ae78...) -> 3341 keys | 5461 slots | 2 slaves.
192.168.10.153:6380 (8fa4d787...) -> 0 keys | 0 slots | 0 slaves. # 可以看到153的主节点啥都没了,干干净净
[OK] 10000 keys in 4 masters.
0.61 keys per slot on average.
3. 让该下线的节点,下线吧
# 主节点的槽位移走了,从节点就可以直接下线了
# 下线命令是--cluster del-node后面 是要下线节点的IP和端口,再跟上要下线节点的ID
redis-cli --cluster del-node 192.168.10.153:6380 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae
redis-cli --cluster del-node 192.168.10.153:6381 1ad2341ae07cc084c75c1130ff2b9936d3bea7b7
redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
redis-cli --cluster info 192.168.10.150:6380
[root@cs ~]# redis-cli --cluster del-node 192.168.10.153:6380 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae
>>> Removing node 8fa4d787dcccf9ece2880e7e20848dc6ce67e7ae from cluster 192.168.10.153:6380
>>> Sending CLUSTER FORGET messages to the cluster... # 直接移出节点,并将该节点直接停机
>>> SHUTDOWN the node.
[root@cs ~]# redis-cli --cluster del-node 192.168.10.153:6381 1ad2341ae07cc084c75c1130ff2b9936d3bea7b7
>>> Removing node 1ad2341ae07cc084c75c1130ff2b9936d3bea7b7 from cluster 192.168.10.153:6381
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380@16380 myself,master - 0 1691576658000 11 connected 0-5461
967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381@16381 slave e827ae7807b2f04c77702e325db3eb311403b3bb 0 1691576657814 13 connected
428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381@16381 slave a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 0 1691576658838 12 connected
a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380@16380 master - 0 1691576659865 12 connected 5462-10922
4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381@16381 slave e827ae7807b2f04c77702e325db3eb311403b3bb 0 1691576655000 13 connected
e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380@16380 master - 0 1691576656787 13 connected 10923-16383
[root@cs ~]# redis-cli --cluster info 192.168.10.150:6380
192.168.10.150:6380 (24476f40...) -> 3343 keys | 5462 slots | 0 slaves. # 150的主节点,没有从节点,因为之前的153从节点下线了
192.168.10.151:6380 (a8b02756...) -> 3316 keys | 5461 slots | 1 slaves.
192.168.10.152:6380 (e827ae78...) -> 3341 keys | 5461 slots | 2 slaves. # 152的主节点有俩从节点,这都是需要我们在处理完下线之后,从新调整的。
[OK] 10000 keys in 3 masters.
0.61 keys per slot on average.
现在,db04节点上的两个redis实例,就真正的退群成功了,你再启动之后,集群也不会识别到了。当然,想要再加回来,就要从新执行一遍集群扩容的命令了。
稳住,还有个问题呢,集群中是有两个节点成功下线了,但此时此刻,剩余的集群的主从状态还是有问题的,此时集群的主从关系是这样的:

那就按图调整吧:
redis-cli -h 192.168.10.152 -p 6381 CLUSTER REPLICATE 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6
redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
redis-cli --cluster info 192.168.10.150:6380
模拟集群故障
再来看下如果集群遇到宕机集群是否能够继续处理业务。
为了方便演示,我们从新恢复下集群,包括主从复制关系。
redis-cli -c -h 192.168.10.150 -p 6380 FLUSHALL
redis-cli -c -h 192.168.10.151 -p 6380 FLUSHALL
redis-cli -c -h 192.168.10.152 -p 6380 FLUSHALL
redis-cli -c -h 192.168.10.150 -p 6380 DBSIZE
redis-cli -c -h 192.168.10.151 -p 6380 DBSIZE
redis-cli -c -h 192.168.10.152 -p 6380 DBSIZE
redis-cli -c -h 192.168.10.150 -p 6380 CLUSTER RESET
redis-cli -c -h 192.168.10.151 -p 6380 CLUSTER RESET
redis-cli -c -h 192.168.10.152 -p 6380 CLUSTER RESET
redis-cli -c -h 192.168.10.150 -p 6381 CLUSTER RESET
redis-cli -c -h 192.168.10.151 -p 6381 CLUSTER RESET
redis-cli -c -h 192.168.10.152 -p 6381 CLUSTER RESET
echo "yes"|redis-cli --cluster create 192.168.10.150:6380 192.168.10.151:6380 192.168.10.152:6380 192.168.10.150:6381 192.168.10.151:6381 192.168.10.152:6381 --cluster-replicas 1
# 从新按照最开始的样式调整主从关系 150从->151主;151从->152主;152从->150主
redis-cli -h 192.168.10.150 -p 6381 CLUSTER REPLICATE a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f
redis-cli -h 192.168.10.151 -p 6381 CLUSTER REPLICATE e827ae7807b2f04c77702e325db3eb311403b3bb
redis-cli -h 192.168.10.152 -p 6381 CLUSTER REPLICATE 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6
redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
for i in {1..10000};do redis-cli -c -h 192.168.10.150 -p 6380 set k_${i} v_${i} && echo ${i} is ok;done
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380@16380 master - 0 1691663242607 17 connected 10923-16383
24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380@16380 myself,master - 0 1691663242000 11 connected 0-5460
967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381@16381 slave 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 0 1691663243628 16 connected
428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381@16381 slave a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 0 1691663242000 12 connected
4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381@16381 slave e827ae7807b2f04c77702e325db3eb311403b3bb 0 1691663243000 17 connected
a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380@16380 master - 0 1691663241000 12 connected 5461-10922
ok,符合预期了。
服务器宕机处理
此时此刻,我这边可用的集群包含db01、db02、db03三个可用节点。
redis-cli --cluster info 192.168.10.150:6380
# 注意观察此时key的分布
[root@cs ~]# redis-cli --cluster info 192.168.10.150:6380
192.168.10.150:6380 (24476f40...) -> 3343 keys | 5461 slots | 1 slaves.
192.168.10.152:6380 (e827ae78...) -> 3341 keys | 5461 slots | 1 slaves.
192.168.10.151:6380 (a8b02756...) -> 3316 keys | 5462 slots | 1 slaves.
[OK] 10000 keys in 3 masters.
0.61 keys per slot on average.
我们模拟一个服务器宕机的故障及恢复操作。
首先,db01负责写:
for i in {1..10000};do redis-cli -c -h 192.168.10.150 -p 6380 set k_${i} v_${i} && echo ${i} is ok;sleep 0.5;done
db02负责读:
for i in {1..10000};do redis-cli -c -h 192.168.10.151 -p 6380 get k_${i};sleep 0.5;done
db03直接关机:
reboot now
效果就是经过集群停止业务二十秒左右,又可以正常的提供服务了,此时观察集群情况:
redis-cli -h 192.168.10.150 -p 6380 CLUSTER INFO
redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
redis-cli --cluster info 192.168.10.150:6380
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER INFO
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:20
cluster_my_epoch:11
cluster_stats_messages_ping_sent:4422
cluster_stats_messages_pong_sent:731
cluster_stats_messages_fail_sent:16
cluster_stats_messages_auth-ack_sent:2
cluster_stats_messages_sent:5171
cluster_stats_messages_ping_received:721
cluster_stats_messages_pong_received:800
cluster_stats_messages_meet_received:10
cluster_stats_messages_fail_received:6
cluster_stats_messages_auth-req_received:3
cluster_stats_messages_received:1540
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380@16380 master,fail - 1691663710876 1691663708000 17 disconnected
24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380@16380 myself,master - 0 1691663776000 11 connected 0-5460
967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381@16381 slave,fail 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 1691663710876 1691663708633 16 disconnected
428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381@16381 slave a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 0 1691663777984 17 connected
4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381@16381 master - 0 1691663780024 20 connected 10923-16383
a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380@16380 master - 0 1691663779005 12 connected 5461-10922
[root@cs ~]# redis-cli --cluster info 192.168.10.150:6380
Could not connect to Redis at 192.168.10.152:6380: Connection refused
Could not connect to Redis at 192.168.10.152:6381: Connection refused
192.168.10.150:6380 (24476f40...) -> 3343 keys | 5461 slots | 0 slaves.
192.168.10.151:6381 (4f15e5e2...) -> 3341 keys | 5461 slots | 0 slaves.
192.168.10.151:6380 (a8b02756...) -> 3316 keys | 5462 slots | 1 slaves.
[OK] 10000 keys in 3 masters.
0.61 keys per slot on average.
集群状态是ok的,但db03的主从节点都提示disconnected,这很正常,因为宕机了嘛。
此时的集群主从情况是这样的:

此时此刻的主从关系,我们先不调整,我们先去启动宕机节点。
故障恢复
# db3服务器重启之后,手动先启动主节点,再启动从节点,注意,启动主从节点的顺序
systemctl start redis-master
systemctl start redis-slave
ps -ef|grep redis
[root@cs ~]# systemctl start redis-master
[root@cs ~]# systemctl start redis-slave
[root@cs ~]# ps -ef|grep redis
redis 1641 1 0 05:47 ? 00:00:00 /usr/local/bin/redis-server 192.168.10.152:6380 [cluster]
redis 1652 1 1 05:47 ? 00:00:00 /usr/local/bin/redis-server 192.168.10.152:6381 [cluster]
root 1657 1613 0 05:47 pts/0 00:00:00 grep --color=auto redis
此时,任意节点查看集群状态:
redis-cli -h 192.168.10.150 -p 6380 CLUSTER INFO
redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
redis-cli --cluster info 192.168.10.150:6380
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER INFO
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:20
cluster_my_epoch:11
cluster_stats_messages_ping_sent:19064
cluster_stats_messages_pong_sent:1293
cluster_stats_messages_fail_sent:16
cluster_stats_messages_auth-ack_sent:2
cluster_stats_messages_sent:20375
cluster_stats_messages_ping_received:1283
cluster_stats_messages_pong_received:1487
cluster_stats_messages_meet_received:10
cluster_stats_messages_fail_received:6
cluster_stats_messages_auth-req_received:3
cluster_stats_messages_received:2789
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380@16380 slave 4f15e5e2310d87089b92ab7b24960c950b30d195 0 1691664530121 20 connected
24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380@16380 myself,master - 0 1691664531000 11 connected 0-5460
967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381@16381 slave 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 0 1691664531144 16 connected
428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381@16381 slave a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 0 1691664532167 17 connected
4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381@16381 master - 0 1691664529000 20 connected 10923-16383
a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380@16380 master - 0 1691664529097 12 connected 5461-10922
[root@cs ~]# redis-cli --cluster info 192.168.10.150:6380
192.168.10.150:6380 (24476f40...) -> 3343 keys | 5461 slots | 1 slaves.
192.168.10.151:6381 (4f15e5e2...) -> 3341 keys | 5461 slots | 1 slaves.
192.168.10.151:6380 (a8b02756...) -> 3316 keys | 5462 slots | 1 slaves.
[OK] 10000 keys in 3 masters.
0.61 keys per slot on average.
集群状态正常,数据也没丢失,就是主从关系需要手动调整下:

根据上图整理后的主从关系图,我们需要做:
- 只需要将152的6380节点和151的6381节点进行主从关系互换就可以了。
我们有个命令可以直接进行主从关系互换:
# 注意这个CLUSTER FAILOVER命令使用时,是这样的,你想让谁的主从关系互换,就去从节点执行CLUSTER FAILOVER,然后从就变成主,主就变成从了
# 任意终端执行:
redis-cli -c -h 192.168.10.152 -p 6380 CLUSTER FAILOVER
redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
[root@cs ~]# redis-cli -c -h 192.168.10.152 -p 6380 CLUSTER FAILOVER
OK
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6380 CLUSTER NODES
e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380@16380 master - 0 1691665372760 21 connected 10923-16383 # 152的6380节点变成了主节点
24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380@16380 myself,master - 0 1691665371000 11 connected 0-5460
967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381@16381 slave 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 0 1691665371738 16 connected
428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381@16381 slave a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 0 1691665370000 17 connected
4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381@16381 slave e827ae7807b2f04c77702e325db3eb311403b3bb 0 1691665370715 21 connected #151的6381节点变成了从节点
a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380@16380 master - 0 1691665371000 12 connected 5461-10922
ok了,此时集群状态ok,主从关系也都正常了。
集群自动化,免交互的操作
在前面的操作中,我们有很多步骤都是手动完成的,这可能能帮助我们更深刻的理解集群,但操作起来的确也有点不太方便。
所以,我们这里在再来说说更自动的化的一些操作:
- 自动部署集群
- 自动扩容和收缩
自动部署集群
这个其实之前讲过了,就一个命令:
# 这俩命令用哪个都行
echo "yes"|redis-cli --cluster create 192.168.10.150:6380 192.168.10.151:6380 192.168.10.152:6380 192.168.10.150:6381 192.168.10.151:6381 192.168.10.152:6381 --cluster-replicas 1
redis-cli --cluster create 192.168.10.150:6380 192.168.10.151:6380 192.168.10.152:6380 192.168.10.150:6381 192.168.10.151:6381 192.168.10.152:6381 --cluster-replicas 1 --cluster-yes
# --cluster-replicas 1 表示一个主节点有一个从节点
# --cluster-yes 表示有交互的提示中,自动输入yes
自动扩容集群
集群添加主节点
通过add-node来添加节点,注意,这里只是将新节点添加到集群中,身份是master身份,但没有分配槽位,所以到了集群中,也是不负责具体业务,想要处理业务,就需要我们手动分配槽位了。
所以,这里实际上我们做两步操作。
第一步:将节点加入集群中。
# 添加主节点,192.168.10.153:6380是要添加的节点,后面的192.168.10.150:6380是已经在集群中的节点
redis-cli --cluster add-node 192.168.10.153:6380 192.168.10.150:6380
# 这一步只是将新节点加入集群,分配槽位啥的,都没有,还需要手动做
# 如果这个新节点是从来没有加入过集群,直接执行命令就可以了,如果这个节点曾经有过加入集群的经历,可能就会报错
# 如果报错,就参考本篇博客的最后一部分,就是常见报错中的这个报错解决办法:[ERR] Node 192.168.10.153:6380 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.,链接:https://www.cnblogs.com/Neeo/articles/10840096.html#err-node-192168101536380-is-not-empty-either-the-node-already-knows-other-nodes-check-with-cluster-nodes-or-contains-some-key-in-database-0
[root@cs ~]# redis-cli --cluster info 192.168.10.150:6380
192.168.10.153:6380 (7cf4fade...) -> 0 keys | 0 slots | 0 slaves. # 可以看到这个新节点压根没有槽位
192.168.10.151:6381 (4f15e5e2...) -> 0 keys | 5461 slots | 1 slaves.
192.168.10.151:6380 (a8b02756...) -> 0 keys | 5462 slots | 1 slaves.
192.168.10.152:6380 (e827ae78...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 0 keys in 4 masters.
0.00 keys per slot on average.
第二步:为刚进入集群的主节点分配槽位:
# 先看下shell脚本能不能获取到新节点的ID
echo $(redis-cli -c -h 192.168.10.153 -p 6380 cluster nodes|awk '/153:6380/{print $1}')
[root@cs ~]# echo $(redis-cli -c -h 192.168.10.153 -p 6380 cluster nodes|awk '/153:6380/{print $1}')
4d37fc13e16282788199d5d641628aff339802ec
# 能行再往下执行这个命令,二选一就行了,一个是自己填写新节点的ID,一个是shell获取
redis-cli --cluster reshard 192.168.10.153:6380 --cluster-from all --cluster-slots 4096 --cluster-yes --cluster-to 4d37fc13e16282788199d5d641628aff339802ec
redis-cli --cluster reshard 192.168.10.153:6380 --cluster-from all --cluster-slots 4096 --cluster-yes --cluster-to $(redis-cli -c -h 192.168.10.153 -p 6380 cluster nodes|awk '/153:6380/{print $1}')
# --cluster reshard 重新分配槽位,我们之前执行的是redis-cli --cluster reshard 192.168.10.153:6380 这个命令就是重新分配槽位,然后有四次交互动作,而下面的几个参数就是代替那四个交互的操作
# --cluster-from all 表示从集群中现有的有槽位的主节点给指定主节点分配槽位
# --cluster-to 表示把槽位分配给新的主节点,这里用shell脚本个过滤出来的那个主节点的ID,当然,你可以自己手动写,不用shell
# --cluster-slots 4096 表示要总共要往新节点迁移的槽位总数
# --cluster-yes 在迁移槽位过程中免交互输入yes
[root@cs ~]# redis-cli --cluster info 192.168.10.150:6380
192.168.10.153:6380 (4d37fc13...) -> 0 keys | 4096 slots | 0 slaves.
192.168.10.151:6381 (4f15e5e2...) -> 0 keys | 4096 slots | 1 slaves.
192.168.10.151:6380 (a8b02756...) -> 0 keys | 4096 slots | 1 slaves.
192.168.10.152:6380 (e827ae78...) -> 0 keys | 4096 slots | 1 slaves.
[OK] 0 keys in 4 masters.
0.00 keys per slot on average.
集群添加从节点,并且同时向指定主节点建立主从关系
原来的动作是先邀请进群,再建立主从关系:
redis-cli -h 192.168.10.150 -p 6380 CLUSTER MEET 192.168.10.153 6381
redis-cli -h 192.168.10.153 -p 6381 CLUSTER REPLICATE $(redis-cli -c -h 192.168.10.150 -p 6380 cluster nodes|awk '/153:6380/{print $1}')
现在,你可以这么做了:
# 添加从节点同时和集群中的主节点建立主从关系
redis-cli --cluster add-node 192.168.10.153:6381 192.168.10.150:6380 --cluster-slave --cluster-master-id $(redis-cli -c -h 192.168.10.150 -p 6380 cluster nodes|awk '/150:6380/{print $1}')
# --cluster add-node 192.168.10.153:6381 192.168.10.150:6380 # 通过集群中的6380节点邀请153的6381节点进群
# --cluster-slave 标记当前节点是从节点
# --cluster-slave --cluster-master-id # 指定该节点的主节点的ID,
# 注意,一定要要确认要绑定主节点是主节点,不然会添加节点成功,主从关系绑定失败,而且,还会报错:Node 192.168.10.153:6381 replied with error:ERR I can only replicate a master, not a replica.
# 最终导致添加的节点变成了没有槽位的主节点了
如果报错添加从节点报错:
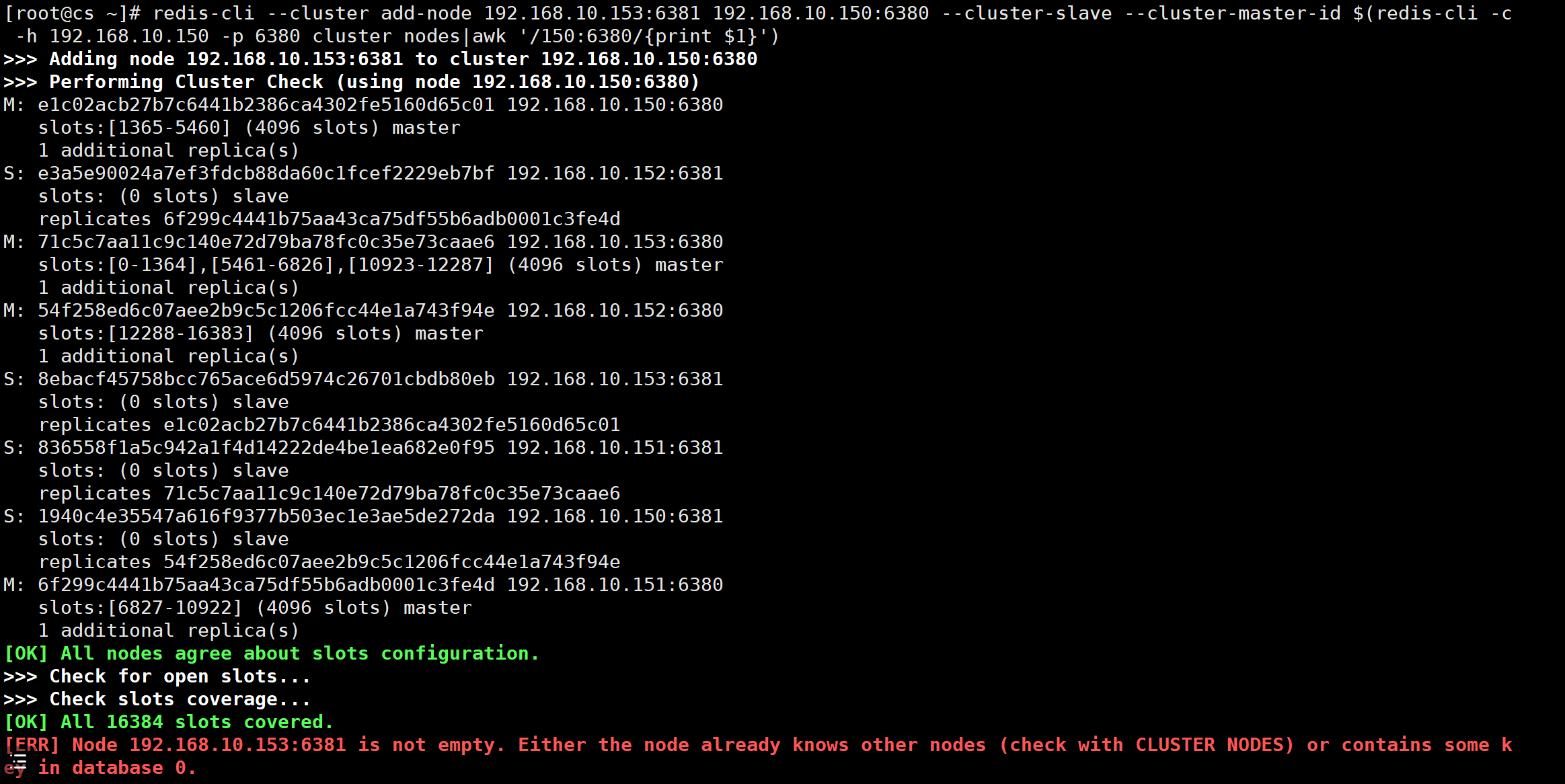
自动收缩集群
下线节点:不需要重新分配槽位的
如果当前节点是主节点,但没有分配槽位的,或者当前节点是从节点的,可以直接通过下面的命令进行下线操作:
# 下线命令 具体命令 要下线的节点 要下线的节点的ID
redis-cli --cluster del-node 192.168.10.153:6381 03ff463e91f0c42188d5d8e09a36a72794f2602c
# 增加了shell脚本获取节点ID
redis-cli --cluster del-node 192.168.10.153:6381 $(redis-cli -c -h 192.168.10.153 -p 6381 cluster nodes|awk '/153:6381/{print $1}')
# 最终要执行的命令
echo $(redis-cli -c -h 192.168.10.153 -p 6380 cluster nodes|awk '/153:6380/{print $1}')
redis-cli --cluster del-node 192.168.10.153:6381 $(redis-cli -c -h 192.168.10.153 -p 6381 cluster nodes|awk '/153:6381/{print $1}')
[root@cs ~]# echo $(redis-cli -c -h 192.168.10.153 -p 6380 cluster nodes|awk '/153:6380/{print $1}')
71c5c7aa11c9c140e72d79ba78fc0c35e73caae6
[root@cs ~]# redis-cli --cluster del-node 192.168.10.153:6381 $(redis-cli -c -h 192.168.10.153 -p 6381 cluster nodes|awk '/153:6381/{print $1}')
>>> Removing node 03ff463e91f0c42188d5d8e09a36a72794f2602c from cluster 192.168.10.153:6381
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.
下线节点:需要从新分配槽位的
如果要下线的节点是有槽位的,那么下线流程肯定是先把槽位移走,再进行下线操作。
# 1. 把槽位迁移走,自动完成
# 具体命令,通过填写将153的6380的ID,将该节点的槽位平均分配给当前集群中的其它主节点
redis-cli --cluster rebalance 192.168.10.150:6380 --cluster-weight 71c5c7aa11c9c140e72d79ba78fc0c35e73caae6=0
redis-cli --cluster rebalance 192.168.10.150:6380 --cluster-weight $(redis-cli -c -h 192.168.10.153 -p 6380 cluster nodes|awk '/153:6380/{print $1}')=0
# --cluster rebalance # 从新分配槽位
# --cluster-weight # 自动的执行将下线节点的槽位,移动到其它的主节点上,执行效果如下:
# Moving 1366 slots from 192.168.10.153:6380 to 192.168.10.150:6380
# Moving 1365 slots from 192.168.10.153:6380 to 192.168.10.151:6380
# Moving 1365 slots from 192.168.10.153:6380 to 192.168.10.152:6380
# 2. 下线节点
# 下线命令 要下线的节点的IP和端口 要下线节点的ID
redis-cli --cluster del-node 192.168.10.153:6380 $(redis-cli -c -h 192.168.10.153 -p 6380 cluster nodes|awk '/153:6380/{print $1}')
集群中的数据迁移
redis中数据迁移这里可以分为:
- 单节点→ 单节点。
- 单节点→ 集群。
- 集群→ 单节点。
- 集群→ 集群。
单节点→ 单节点
单节点到单节点是最简单的,可以选择直接通过rdb文件进行恢复。
也可以通过三方工具进行迁移。
单节点→ 集群
可以通过redis-cli相关命令来完成;也可以通过三方工具进行迁移。
集群→ 单节点
可以通过三方工具来完成。
另一种思路就是就将集群中的槽位分配到一个节点上,然后在这个节点上进行save之后,把rdb文件拷贝走,在单节点进行恢复,然后再恢复集群槽位。
集群→ 集群
可以通过三方工具来完成。
另一种思路就是两个集群架构、槽位一模一样,数据迁移时,首先关闭两个集群,然后将对应节点的数据移动到另一个集群中的对应节点中。所有的节点都这么搞,然后另一个集群重新启动主节点进行数据恢复。
总之,集群间的迁移,优先推荐使用三方工具。
而三方工具:
- Redis-Migrate-Tool(RMT),是唯品会开源的redis数据迁移工具,主要用于异构redis集群间的数据在线迁移,即数据迁移过程中源集群仍可以正常接受业务读写请求,无业务中断服务时间。项目地址:https://github.com/JokerQueue/redis-migrate-tool
- redis-shake,是阿里云开源的用于 Redis 数据迁移和过滤的工具,项目地址:https://github.com/tair-opensource/RedisShake
接下来,演示下redis-cli相关命令来完成单节点迁移数据到集群的操作。
相关命令参数
# 将外部192.168.10.150:6379节点的数据,迁移到集群中,这里import后面可以写任意的集群节点
redis-cli --cluster import 192.168.10.150:6380 --cluster-from 192.168.10.150:6379 --cluster-replace --cluster-copy
# import 192.168.10.150:6380 # 可以是集群的任意节点
# --cluster-from 192.168.10.150:6379 # 表示从外部哪个实例迁移数据
# --cluster-replace # 添加replace参数,迁移时会覆盖掉同名的key,如果不添加该参数,迁移遇到同名的key会提示冲突,当然如果新集群,没数据,不加这个参数也没事
# Migrating k_324 to 192.168.10.151:6380: Source 192.168.10.150:6379 replied with error:ERR Target instance replied with error: BUSYKEY Target key name already exists.
# --cluster-copy # 迁移命令不加copy参数,相当于是mv动作,迁移完毕,自己的也没了,加了copy就相当于cp操作了
举例
确保150的6379节点开启了持久化:
dir "/data/redis6379/"
dbfilename redis.rdb
save 900 1
save 300 10
save 60 10000
rdbcompression yes
rdbchecksum yes
appendonly yes
appendfsync everysec
appendfilename "redis.aof"
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
no-appendfsync-on-rewrite yes
然后执行命令,迁移到集群中。
for i in {1..1000};do redis-cli -c -h 192.168.10.150 -p 6379 set k_${i} v_${i} && echo ${i} is ok;done
redis-cli -h 192.168.10.150 -p 6379 BGSAVE
ll /data/redis6379/
redis-cli -h 192.168.10.150 -p 6379 dbsize
redis-cli --cluster import 192.168.10.150:6380 --cluster-from 192.168.10.150:6379 --cluster-replace --cluster-copy
ll /data/redis6379/
redis-cli -c -h 192.168.10.150 -p 6380 get k_1
redis-cli --cluster info 192.168.10.150:6380
[root@cs ~]# for i in {1..1000};do redis-cli -c -h 192.168.10.150 -p 6379 set k_${i} v_${i} && echo ${i} is ok;done
......省略......
Migrating k_518 to 192.168.10.152:6380: OK
Migrating k_753 to 192.168.10.151:6380: OK
......省略......
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6379 BGSAVE
Background saving started
[root@cs ~]# ll /data/redis6379/
total 52
-rw-r--r-- 1 redis redis 34809 Aug 11 14:32 redis.aof
-rw-r--r-- 1 redis redis 12884 Aug 11 14:48 redis.rdb
[root@cs ~]# redis-cli -h 192.168.10.150 -p 6379 dbsize
(integer) 1000
[root@cs ~]# ll /data/redis6379/
total 52
-rw-r--r-- 1 redis redis 34809 Aug 11 14:32 redis.aof
-rw-r--r-- 1 redis redis 12884 Aug 11 14:48 redis.rdb
[root@cs ~]# redis-cli -c -h 192.168.10.150 -p 6380 get k_1
"v_1"
[root@cs ~]# redis-cli --cluster info 192.168.10.150:6380
192.168.10.150:6380 (24476f40...) -> 339 keys | 5462 slots | 1 slaves.
192.168.10.151:6380 (a8b02756...) -> 326 keys | 5461 slots | 1 slaves.
192.168.10.152:6380 (e827ae78...) -> 335 keys | 5461 slots | 2 slaves.
[OK] 1000 keys in 3 masters.
0.06 keys per slot on average.
性能测试
redis的benchmark是当我们安装完redis之后官方自带的一个测试组件redis-benchmark,通过这个组件,我们可以针对redis制定相应的测试规则,确认Redis是否满足业务需求。
redis-benchmark 语法介绍:
redis-benchmark --help
Usage: redis-benchmark [-h <host>] [-p <port>] [-c <clients>] [-n <requests>] [-k <boolean>]
-h <hostname> 指定redis测试服务器
-p <port> 指定redis服务的端口
-s <socket> 指定redis socket文件
-a <password> 指定redis密码
-c <clients> 指定测试的并行数
-n <requests> 指定测试的请求数量
-d <size> SET/GET 命令的值bytes单位 默认是2
--dbnum <db> 指定redis的某个数据库,默认是0数据库
-k <boolean> 指定是否保持连接 1是保持连接 0是重新连接,默认为 1
-r <keyspacelen> 指定get/set的随机值的范围。
-P <numreq> 管道请求测试,默认0没有管道测试
-e 如果有错误,输出到标准输出上。
-q 静默模式,只显示query/秒的值
--csv 指定输出结果到csv文件中
-l 指定是否一直运行test
-t <tests> 指定需要测试的命令,以逗号分隔,
redis-benchmark -n 10000 -q
redis-benchmark -h 192.168.10.150 -p 6380 -n 10000 -c 20 -t get
redis-benchmark -h 192.168.10.150 -p 6379 -n 10000 -c 20 -t get
常见问题
所有数据都分配到一个节点上了
这种情况,请确认手动分配槽时,是否都分配正确了。
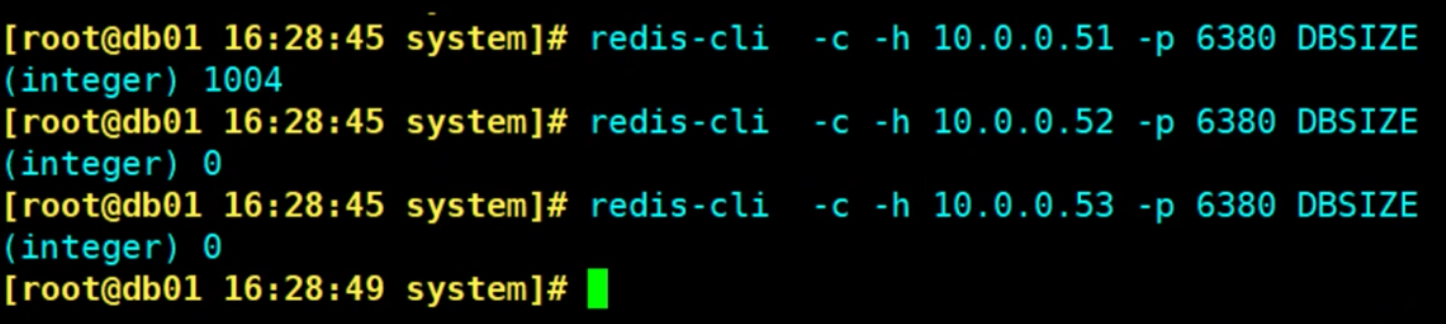
通过cluster nodes命令可以确认下,槽位分配都分配到一个节点上了,所以出现的上述问题。

解决办法就是从新分配槽位。
[ERR] Node 192.168.10.153:6380 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
redis5.0.7 + centos7.9 + vmware16pro
在使用命令添加节点的时候,提示要添加的节点不是空的:
[root@cs ~]# redis-cli --cluster add-node 192.168.10.153:6380 192.168.10.150:6380
>>> Adding node 192.168.10.153:6380 to cluster 192.168.10.150:6380
>>> Performing Cluster Check (using node 192.168.10.150:6380)
M: 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6 192.168.10.150:6380
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: e827ae7807b2f04c77702e325db3eb311403b3bb 192.168.10.152:6380
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 967340547d63fd4f09e870b1494b6de720f9d6f4 192.168.10.152:6381
slots: (0 slots) slave
replicates a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f
S: 428e2b4090819ae5d181f435461c0970172d748c 192.168.10.150:6381
slots: (0 slots) slave
replicates e827ae7807b2f04c77702e325db3eb311403b3bb
S: 4f15e5e2310d87089b92ab7b24960c950b30d195 192.168.10.151:6381
slots: (0 slots) slave
replicates 24476f40244ca37b1c42eb3ba62e39a7ee9e95d6
M: a8b027568d5dfc6e14560ede0d6b5ce45f04ed6f 192.168.10.151:6380
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
[ERR] Node 192.168.10.153:6380 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
解决办法:
- 停掉这个要加入集群的节点。
- 删除要添加节点的那三个文件
nodes6380.conf、redis6380.aof、redis6380.rdb。 - 重启这个要加入集群的节点。
- 重新尝试命令,将新节点加入集群就好了。
[root@cs ~]# redis-cli --cluster add-node 192.168.10.153:6380 192.168.10.150:6380
......省略......
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
[ERR] Node 192.168.10.153:6380 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
[root@cs ~]#
[root@cs ~]#
[root@cs ~]# systemctl stop redis-master
[root@cs ~]# rm -rf /data/redis6380/*
[root@cs ~]# systemctl start redis-master
[root@cs ~]# redis-cli --cluster add-node 192.168.10.153:6380 192.168.10.150:6380
>>> Adding node 192.168.10.153:6380 to cluster 192.168.10.150:6380
......省略......
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 192.168.10.153:6380 to make it join the cluster.
[OK] New node added correctly.
如果执行上面的步骤还是不行的话,你可以尝试下面的步骤,注意备份数据!
- 停止集群,先停从节点,再停主节点。
- 删除要添加节点的那三个文件
nodes6380.conf、redis6380.aof、redis6380.rdb。 - 重启集群,先启主节点,再启动从节点。
- 重新尝试命令,将新节点加入集群就好了。
参考:https://blog.csdn.net/HeyShHeyou/article/details/108937649

 浙公网安备 33010602011771号
浙公网安备 33010602011771号