1-Python - Python中的字节码
前言
这里以CPython为扯淡对象!
毋庸置疑,Python是解释性语言,因为我们常常这样解释:Python代码将被逐行解释并执行......这,确实忽略了一些细节...........
现在,温故知新,让我们再次从hello world出发,不忘初心!
def hello():
"""hello function"""
print('hello world', '你好')
当上述代码被执行时发生了什么?答案是什!么!都!没!发!生!因为函数只定义没调用嘛!那么如果有调用的话,会发生什么,你可能说,会执行一行打印........
字节码:bytecode
CPython解释器在内部会将Python源代码编译成字节码,并缓存在.pyc文件中,目的是当再次执行该文件时,直接读取.pyc文件会更快,这样可以避免从源码重新编译到字节码,当然,Python再找到符合文件后,检查此文件的时间戳,如果发现字节码文件(文件在导入时就被编译完成)比源代码文件时间戳早(比如你修改过原文件),那么就会重新生成字节码,否则就会跳过此步骤。如果,Python在搜索时只找到了字节码而没有找到源代码文件,那么就会直接执行字节码文件(如果没有印象,请回想在模块导入时发生了什么)。
然后,Python虚拟机执行字节码编译器发出的字节码。
现在,我们来研究字节码是什么鬼东西!
面向对象?面向栈!
CPython使用一个基于栈的虚拟机,也就是说,它完全是面向栈,这种数据结构的(想象出栈入栈)。
CPython使用3种类型的栈:
- 调用栈(call stack)。这是运行Python程序的主要结构,它为每个当前活动的函数调用,使用了一个东西
帧(frame),栈底是程序的入口点,每个函数调用推送一个新的帧到调用栈,当函数调用返回后,这个帧被销毁。 - 计算栈(evaluation stack,或称数据栈data stack)。在每个帧中,计算栈就是函数运行的地方,运行的代码大多数是由推入到这个栈中的东西组成的。在栈中操作它们,当函数被返回后,销毁它们。
- 块栈(block stack)。在每个帧中,块栈被Python用于跟踪某些类型的控制结构,如循环、
try/except块和with ... as ...块 ,这些控制结构全部被推入到块栈中,当退出这些控制结构式,块栈被销毁,这将帮助Python了解任意给定时刻哪个块是活动的,比如一个continue或者break语句,这些可能影响结果的块。
大多数Python字节码指令操作的是当前调用栈的计算栈,虽然还有些指令可以做其他的事情,比如跳转到指定指令,或者操作块栈。
代码对象
为了方便理解,现在强势插入(学习)一下代码对象这个鬼东西。
如果你要是不知道什么是代码对象,那么你对这个熟悉吗?
>>> def hello():
... print('hello world')
...
>>> hello.__code__
<code object hello at 0x00FA7A70, file "<stdin>", line 1>
这个code就是代码对象,表示已经编译的函数体。当然不仅仅是这些,代码对象表示可执行的Python代码或者字节码,代码对象和函数对象之间的区别在于函数对象包含对函数的全局变量(定义它的模块)的显式引用。而代码对象不包含上下文,默认参数值也存储在函数对象中,而不是存储在代码对象中(因为它们表示在运行时计算的值)。与函数对象不同,代码对象是不可变的,并且不包含(直接或间接)可变对象的引用。
你以为这就完了?__code__没那么简单:
def hello():
print('hello world')
print(hello.__code__) # <code object hello at 0x035B4F98, file "M:/demo/MyAI/AI/part2/demo.py", line 20>
print(hello.__code__.co_name) # hello
print(hello.__code__.co_argcount) # 0
print(hello.__code__.co_nlocals) # 0
print(hello.__code__.co_varnames) # ()
print(hello.__code__.co_cellvars) # ()
print(hello.__code__.co_freevars) # ()
print(hello.__code__.co_code) # b't\x00d\x01\x83\x01\x01\x00d\x00S\x00'
print(hello.__code__.co_consts) # (None, 'hello world')
print(hello.__code__.co_names) # ('print',)
print(hello.__code__.co_filename) # M:/demo/MyAI/AI/part2/demo.py
print(hello.__code__.co_firstlineno) # 20
print(hello.__code__.co_lnotab) # b'\x00\x01'
print(hello.__code__.co_stacksize) # 2
print(hello.__code__.co_flags) # 67
代码对象还包括一些特殊的只读属性:
- co_name给出函数名称。
- co_argcount是位置参数的数量,包括具有默认值的参数。
- co_nlocals是函数使用的局部变量数,包括参数。
- co_varnames是一个包含局部变量名称的元组,以参数名称开头。
- co_cellvars是一个元组,包含嵌套函数引用的局部变量的名称。
- co_freevars是一个包含自由变量名称的的元组。
- co_code是表示字节码指令序列的字符串。
- co_consts是一个包含字节码使用的文字的元组。如果代码对象表示函数,则co_consts的第一项是函数的文档字符串,如果文档字符串未定义,则是None。
- co_names是一个包含字节码使用的名称的元组。
- co_filename是编译代码的文件名。
- co_firstlineno是函数的第一个行号。
- co_lnotab是一个字符串,用于编码从字节码偏移到行号的映射(更详细的信息参考解释的源代码)。
- co_stacksize是所需的堆栈大小(包括局部变量)。
- co_flags是一个整数,作为编码解释器的标志使用。以下标志位定义为co_flags:0x04如果函数使用arguments语法接受任意数量的位置参数,则设置位; 0x08如果函数使用keywords语法接受任意关键字参数,则设置 bit 。
现在,大致理解了代码对象是什么鬼东西,我们继续往下走。
字节码如何工作
结合代码对象和栈相关的知识,我们来研究字节码是如何在栈内工作的。
要想理解这些东西,我们还需要借助Python标准库中的dis模块,dis模块通过反汇编支持CPython字节码的分析,该模块作为输入的CPython字节码在文件中定义,Include/opcode.h并由编译器和解释器使用。
我们如何使用呢?一般,通过dis.dis()将反汇编一个函数、方法、类或者模块编译过的Python代码对象、字符串包含的源代码,显示出一个人类可读的版本。
另外就是dis.distb(),我们可以给这个方法传递一个Python追溯对象,或者在发生预期外情况是调用它,然后它将在发生预期外情况时反汇编调用栈上最顶端的函数,并显示它的字节码,以及插入一个指向到引发意外情况的指令的指针。
需要注意的是:在版本3.6中更改,为每条指令使用2个字节。以前字节数因指令而异。
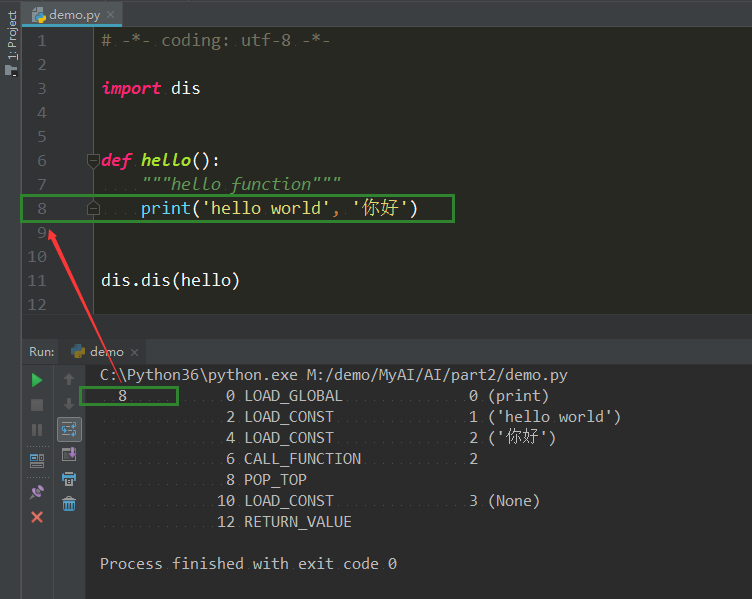
扯了半天,来个示例玩玩:
def hello():
"""hello function"""
print('hello world', '你好')
dis.dis(hello)
"""dis.dis(hello)输出结果
8 0 LOAD_GLOBAL 0 (print)
2 LOAD_CONST 1 ('hello world')
4 LOAD_CONST 2 ('你好')
6 CALL_FUNCTION 2
8 POP_TOP
10 LOAD_CONST 3 (None)
12 RETURN_VALUE
"""
print(hello.__code__.co_names) # ('print',)
print(hello.__code__.co_consts) # ('hello function', 'hello world', '你好', None)
print(hello.__code__.co_argcount) # 0
- LOAD_GLOBAL(namei),将全局命名加载co_names[namei]到堆栈中。其中
namei是代码对象属性中的name索引。 - LOAD_CONST(consti),推co_consts[consti]到堆栈上。
- CALL_FUNCTION(argc),使用位置参数调用可调用对象。 argc表示位置参数的数量。堆栈的顶部包含位置参数,最右侧的参数位于顶部。参数下面是一个可调用的对象。 CALL_FUNCTION将所有参数和可调用对象弹出堆栈,使用这些参数调用可调用对象,并推送可调用对象返回的返回值。版本3.6中更改:此操作码仅用于具有位置参数的调用。
- POP_TOP,删除堆栈顶部(TOS)项。
- RETURN_VALUE,返回TOS到函数的调用者。
首先说dis.dis(hello)输出结果,左上角的8表示print这一行代码所在文件的行数(下图为证),然后:
- 指令
0:LOAD_GLOBAL(namei)从元组(print)索引0的print推入栈(调用栈,这部分不理解的话需要参考前文的栈相关的内容)中。 - 指令
2 4:其中有两个位置参数LOAD_CONST,LOAD_CONST 1是1 ('hello world'),LOAD_CONST 2是2 ('你好')。 - 指令
6:CALL_FUNCTION表示Python需要从栈顶弹出2个位置参数供print函数调用,其实说白了就是print函数调用就是开了一个新的帧,print函数在新的帧内运行,需要的参数由CALL_FUNCTION给。 - 指令
8:当新的帧内的字节码执行完了,就从栈顶删除。 - 指令
10:LOAD_CONST将print函数调用返回值推入最开始的调用栈。可以看到元组的索引0的位置是None,因为在Python中函数调用默认有返回值,如果没有显示的返回值,就隐式的返回一个值——None。 - 指令
12,RETURN_VALUE将新帧(这个帧执行完毕就销毁了)的执行结果返回给调用栈。
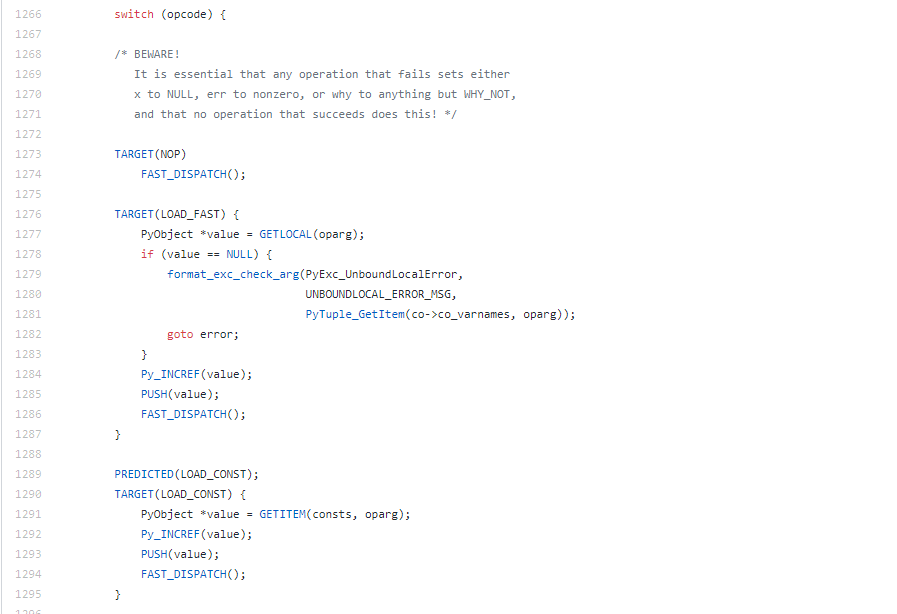
在Github上,我们可以查看Python的源码,这里以Python 3.6.4 发行版为例,在Python/ceval.c文件中,字节码指令由第1266行的swith语句来处理.....
字节码有啥用处
说了一大推,我想你肯定想问,这鬼东西辣么复杂,有啥实际价值?
首先,理解了Python的运行模式可以帮助我们更好的理解代码,如果我们能预料到我们的源代码将被转换成什么样的字节码,那么就可以做一些针对性的优化。
再者,理解字节码可以帮助我们很好地回答一些问题:为什么某些结构要比其他的结构性能更高。再我们知道字节码是如何运行的之后。我们就可以很容易的回答这些问题。
>>> import dis
>>> dis.dis("[]")
1 0 BUILD_LIST 0
2 RETURN_VALUE
>>> dis.dis("list()")
1 0 LOAD_NAME 0 (list)
2 CALL_FUNCTION 0
4 RETURN_VALUE
>>> >>> dis.dis("{}")
1 0 BUILD_MAP 0
2 RETURN_VALUE
>>> dis.dis("dist()")
1 0 LOAD_NAME 0 (dist)
2 CALL_FUNCTION 0
4 RETURN_VALUE
这个时候看上面的代码,是不是就容易很多了。
最后,通过字节码我们了解了面向栈的编程方式,以及这种编程方式是如何运作的。拓展我们的视野。
see also:
代码对象 | dis | Data model | Python 字节码介绍
本文借鉴以上链接中的内容,水平有限,不足之处,欢迎斧正,that's all

 浙公网安备 33010602011771号
浙公网安备 33010602011771号