1-Elasticsearch - 集群那点事儿
前言
接下来的演示,在本地需要一个新的集群,没有搭建好呢?来点击
空集群
现在,万事俱备,只欠东风。我们继续来探讨集群的内部细节。
当我们打开一个单独的节点node1,此时它还没有数据和索引。那么这个集群就是个空集群。

是的,一个集群下辖一个主节点,空白白的........
集群健康
我们通过kibana的监控来查看集群状态:
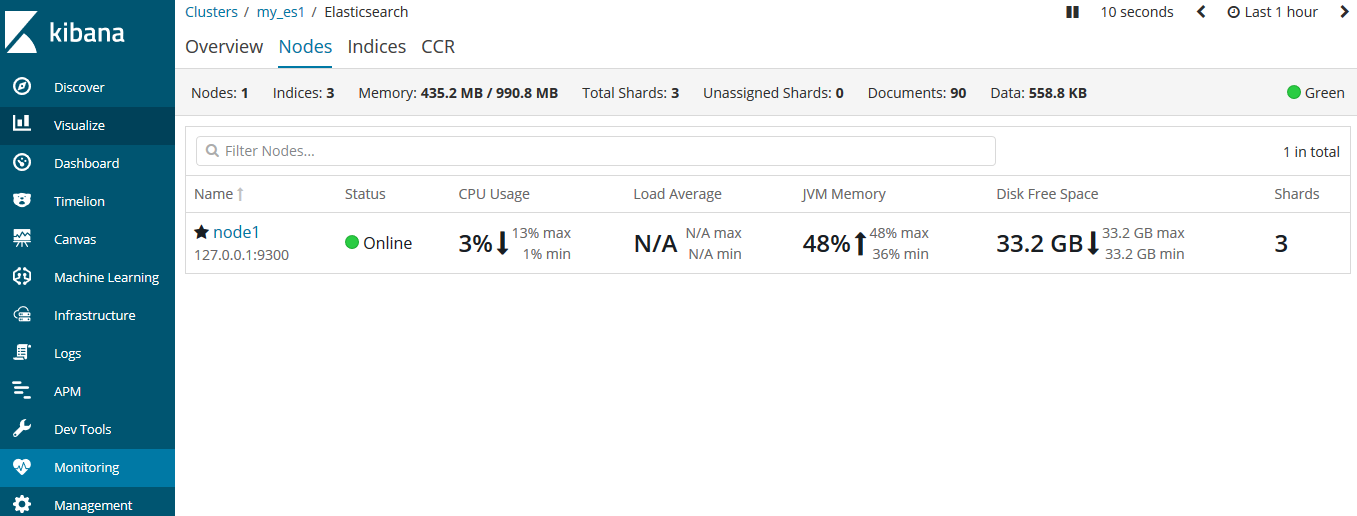
或者这么查询:
GET cluster/health # 在kibana的Dev Tools中查询
http://127.0.0.1:9200/_cluster/health?pretty # 浏览器中输入
返回结果如下:
{
"cluster_name" : "my_es1",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 3,
"active_shards" : 3,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
在返回的结果中,我们拿到了集群名称、状态信息、是否超时等信息。我们要对这个status保持关注。
status字段提供一个综合的指标来表示该集群的服务状况,它有三种不同的颜色代表不同的含义:
| 颜色 | 描述 |
|---|---|
| green | 所有主要分片和复制分片都可用 |
| yellow | 所有主要分片可用,但不是所有复制分片都可用 |
| red | 不是所有的主要分片都可用 |
我们将数据添加到elasticsearch中的索引中——一个存储关联数据的地方。实际上索引只是用来指向一个或者多个分片的逻辑命名空间。
一个分片是一个最小级别的工作单元。它只是保存了索引中所有数据的一部分。我们可以把分片想象成容器,文档就存储在分片中,然后分片被分配到你的集群节点上。当我们扩容或缩小集群时,elasticsearch会自动在节点间迁移分片,以保持集群的平衡。
分片又可以分为主分片(primary shard)和复制分片(replica shard)。我们索引的每个文档都是一个单独的主分片,主分片的数量决定了索引最多能存储多少数据。
而复制分片只是主分片的一个副本,它用来防止硬件故障导致的数据丢失,同时可以提供读请求。
当索引创建完成后,主分片的数量级就固定了,但是复制分片的数量可以随时调整。
添加索引
了解了集群中的索引和分片。我们就来为空集群创建一个索引(在kibana中):
PUT /blogs
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
上例中,我们为blogs节点分配了3个分片(默认是5个)和1个复制分片(每个主分片默认都有一个复制分片)。

现在三个分片都被分配到节点1中了。我们来查看一下集群的健康状态:
{
"cluster_name" : "my_es1",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 6,
"active_shards" : 6,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 3,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 66.66666666666666
}
此时的集群健康状态是yellow,表示所有的主分片都正常,集群可以正常的处理请求。只是复制分片还没有全部可用,此时复制分片处于unassigned状态,它们还没分配给节点。因为没有必要在同一个节点上保存相同的数据副本。只要这个节点挂了,那么数据副本也都丢了。
在kibana中看更直观一些:
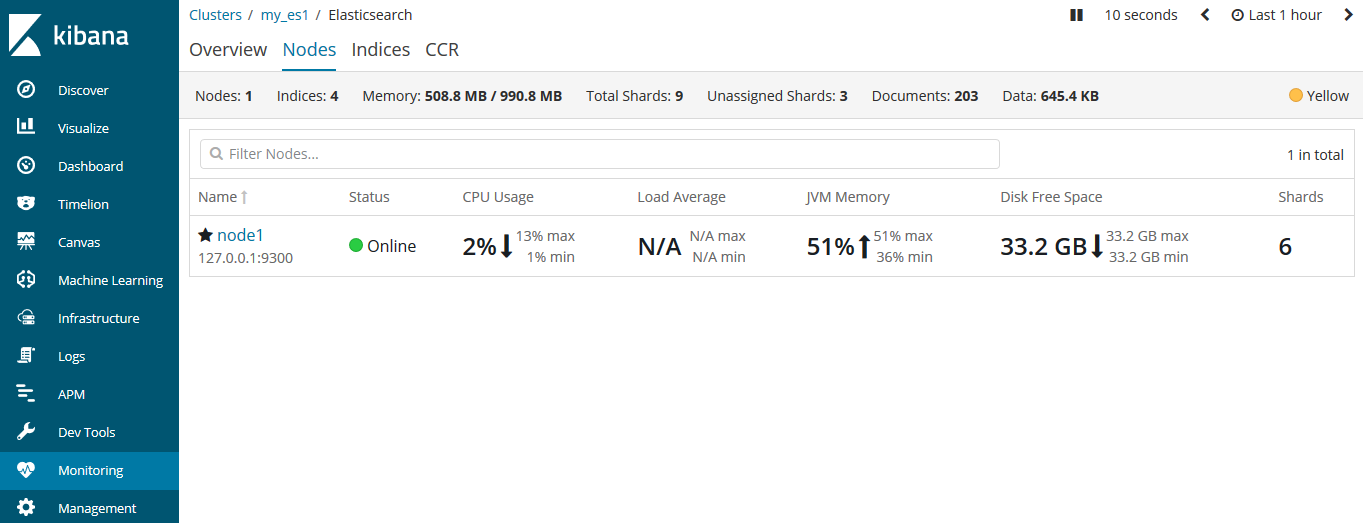
现在集群工作正常,比如我们为blogs索引添加一条数据:
PUT /blogs/doc/1
{
"title": "es集群"
}
GET /blogs/_search
{
"query": {
"match_all": {}
}
}
添加和查询都没问题。现在一切看起来非常的完美。但虽然集群的功能完备,但是存在因硬件故障导致数据丢失的风险。
添加更多的节点
我们为这个集群添加一个新的节点,来承担数据丢失的风险。启动我们的集群中的node2节点。启动后,我们就可以在kibana中来检测这两个节点。
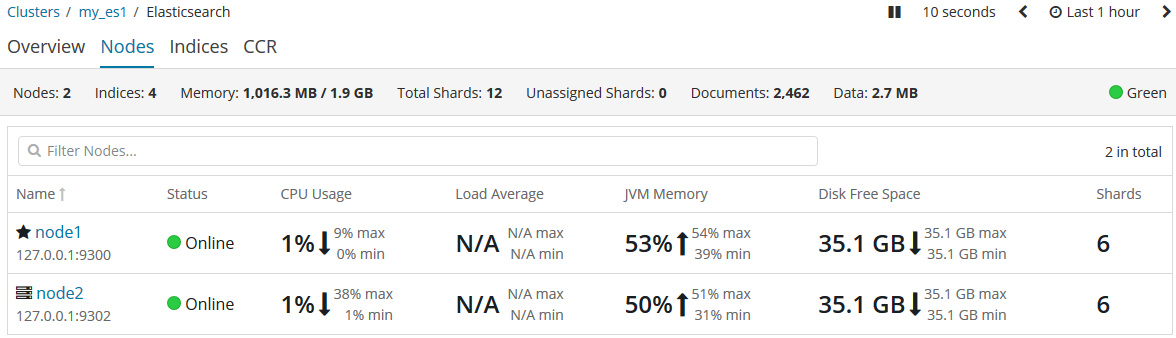
当第二个节点加入到集群后,三个复制分片也已经被分配,这意味着,当在集群中有任意一个节点挂掉依然可以保证数据的完整性。
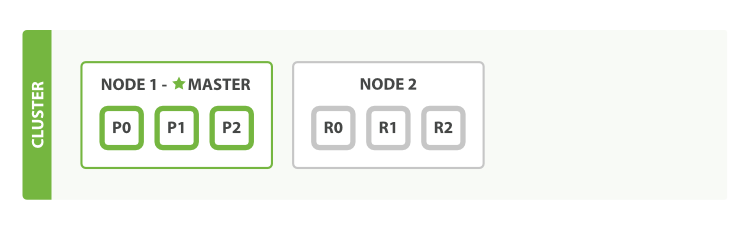
其实,当第二个节点再加入到集群中时,文档的索引将首先被存储在主分片中,然后并发复制到对应的复制节点上。这可以确保我们的数据在主节点和复制节点上都可以被检索。
再来看集群的健康状态:
{
"cluster_name" : "my_es1",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 2,
"number_of_data_nodes" : 2,
"active_primary_shards" : 6,
"active_shards" : 12,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
此时的集群状态是green,这就表明6个分片都可用了。
目前为止,我们的集群不仅是功能完备,而且是高可用的了。
继续扩展
随着应用需求的增长,我们需要启动更多的节点,现在让我们启动node3和node4。
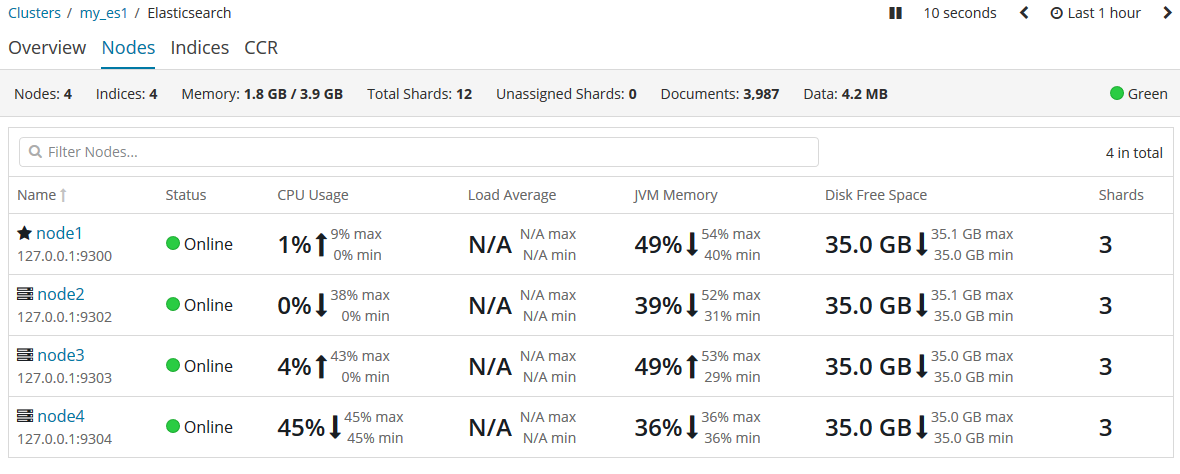
越来越多的节点意味着分片将获得更多的硬件资源,包括CPU、RAM、I/O。
我们可以使用命令来查看当前集群的信息:
GET _cluster/state/master_node,nodes?pretty # 返回所有节点
GET _cluster/state/master_node,node?pretty # 返回当前主节点的信息
GET _nodes # 返回所有节点列表
当老大(主节点)挂了怎么办
有一天,我们的主节点挂掉了,比如小黑不小心踢掉了其中一个主机的电源插头,恰好,这个主机的es实例是主节点node1。相当于小黑亲手干掉了集群中的老大!此时会发生什么?
首先,我们由于是通过kibana来监控集群的,而kibana在启动的时候默认寻找的是9200端口,也就是老大node1,但这家伙刚被我们干掉,所以,kibana先挂掉了。现在我们先把kibana的配置文件把端口临时改为(提醒自己一会演示完别忘了改回来!)9202端口(你集群的其他的示例端口)。然后重启kibana服务。再访问监控:
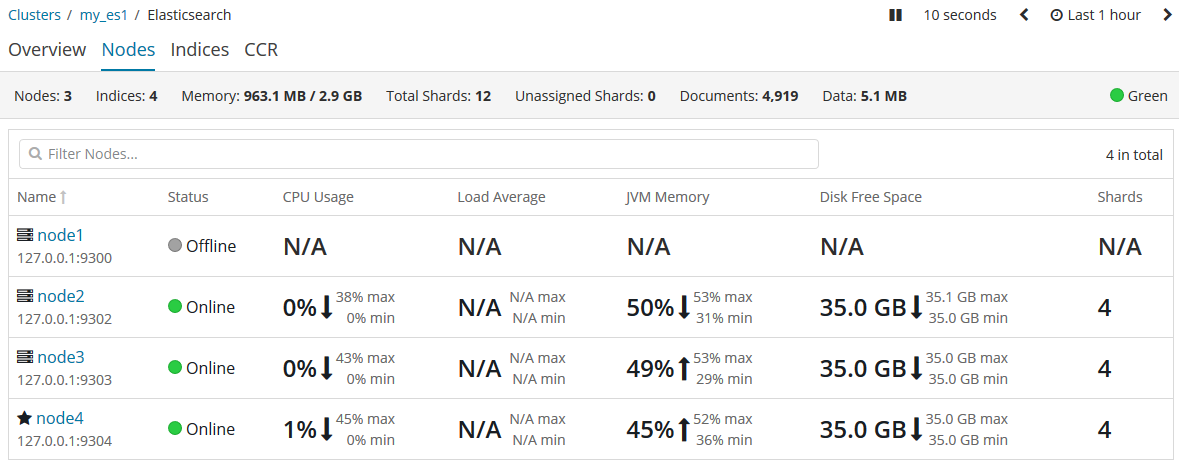
可以看到,老大node1提示离线状态,而老大则换成了node4。这其中到底发生了什么呢?
我们杀掉了老大主节点。但是一个集群必须有一个主节点才能使其功能正常,所以,集群做的第一件事就是在小弟们(各节点)中选举出一个新的老大(主节点)。
当原来的老大被干掉后,它节点内的主分片也都没了,但还好,其他的节点还存着副本。所以新官上任三把火的头一把火就是把分布在别的节点上复制分片升级为主分片,这个过程是非常快的。当然,它身为新的主节点还要做些别的事情。它将临时管理集群级别的一些变更,例如新建或删除索引、增加或移除节点等。主节点不参与文档级别的变更或搜索,这意味着在流量增长的时候,该主节点不会成为集群的瓶颈。
但不幸的的是,原主节点在被小黑杀掉扔下悬崖后,幸运地挂在了树上而逃过一死(故障解决,重启node1),它就回来了。你就会在kibana中发现:
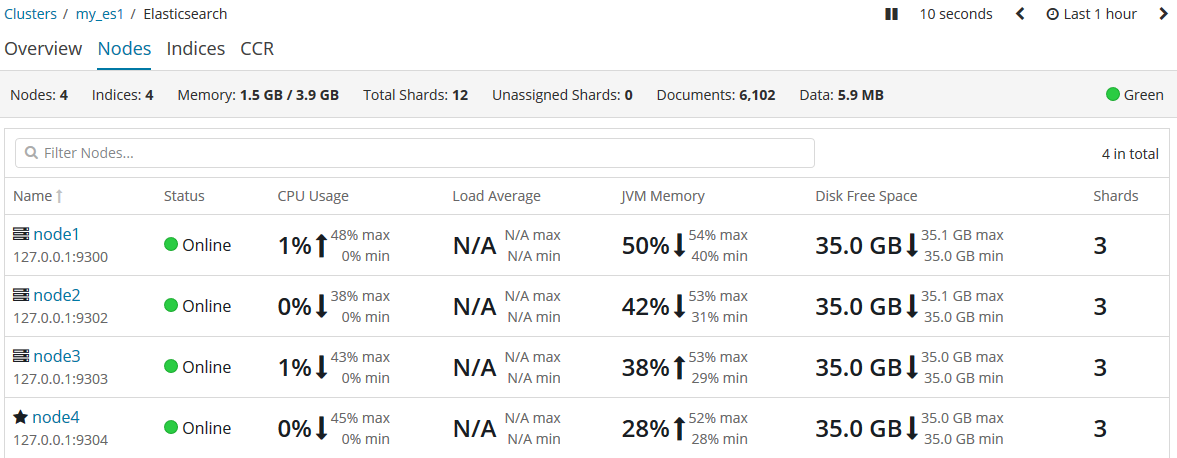
虽然胡汉三又回来了,但是只能做个小弟了。主节点依然被node4牢牢把握。
成为主节点的资格
之前当主节点node1被干掉后,为什么node4被选举出来,这其中是否存在着py交易暂且不提。但能说的是,集群下的各节点都有资格被选举为主节点。所以node4上位后,就在思考,要把这资格收回来,怎么做呢?其实在配置文件中可以体现:
node.master: false # 该节点是否可以被选举为主节点,默认为true
node.data: true # 该节点是否有存储权限,默认为true
我们通过node.master来设置哪个节点有资格称为主节点。
停用节点
很多时候,我们需要维护的时候,就需要关闭某个节点,那怎么做呢?
PUT /_cluster/settings
{
"transient": {
"cluster.routing.allocation.exclude._ip": "192.168.1.1"
}
}
一旦执行上述命令,elasticsearch将该节点上的全部分片转移到其他的节点上。并且这个设置是暂时的,集群重启后就不再有效。
see also:[Elasticsearch权威指南(中文版)](https://es.xiaoleilu.com/020_Distributed_Cluster/05_Empty_cluster.html) 欢迎斧正,that's all

 浙公网安备 33010602011771号
浙公网安备 33010602011771号