LOJ#2369. 「BalticOI 2008」魔法石
题目链接
题目大意
一个字符串由 \(X\) 和 \(I\) 组成,定义两个串是相同的当且仅当一个串可以通过翻转(头尾倒过来)另一个串得到,我们取字典序较小的那个作为该串的表达方式,求在长度为 \(n\) 的串中,满足「 \(X\) 和 \(I\) 相邻的地方数量 \(\leq k\) 」的字典序第 \(i\) 大的串。
\(0\leq k<n\leq 60\), \(0<i<10^{18}\)
思路
\(O(n^2k)\) 做法
按照传统数位 \(dp\) 的思路,我们从前往后一位位填,考虑当前我们已经固定了前 \(i\) 的取值,那么现在要求的就是剩下的位置能和前面组成多少种合法的字符串。
每个合法的串都要满足其翻转后的字典序 \(\geq\) 当前字典序,翻转这个操作有一个特殊的边界,那就是中点,我们按照中点将串拆开成 \(s_1\) 和 \(s_2\),根据需要,\(s_2\) 这个串是从后往前读取的。显然对串的限制相当于要求 \(s1 \leq s2\)(字典序比较),那么就考虑两个串从前往后填(相当于原串从两端开始填),只需保证字典序大小关系即可。
具体来说,设 \(dp_{i,j,a,b,e}\) 表示当前考虑到了 \(s1\) 和 \(s2\) 的第 \(i\) 位,存在恰好 \(j\) 个 \(X\) 和 \(I\) 相邻的位置,\(s_1\) 这次填的字母是 \(a\;(0/1)\),\(s_2\) 这次填的字母是 \(b\;(0/1)\),\([s_1<s_2]=e\) 时的方案数,然后转移的时候枚举下一位填什么,判断合法以及注意填最中间几位的特殊情况即可。
每次 \(dp\) 是 \(O(nk)\) 的,每填一位做 \(O(1)\) 次 \(dp\),总时间复杂度 \(O(n^2k)\)。
Code
#include<iostream>
#include<cstring>
#define mem(a,b) memset(a, b, sizeof(a))
#define rep(i,a,b) for(int i = (a); i <= (b); i++)
#define per(i,b,a) for(int i = (b); i >= (a); i--)
#define N 66
#define ll long long
using namespace std;
ll dp[N][N][2][2][2], rnk;
int p[N], n, k;
ll cal(){
mem(dp, 0);
if(~p[n]){
if(p[n] < p[1]) return 0;
dp[1][0][p[1]][p[n]][p[n]>p[1]] = 1;
}
else rep(i,p[1],1) dp[1][0][p[1]][i][i > p[1]] = 1;
rep(i,1,(n+1)/2-1) rep(j,0,n-1){
int sa = (~p[i+1] ? p[i+1] : 0), sb = (~p[n-i] ? p[n-i] : 0);
rep(a,sa, (~p[i+1]?sa:1)) rep(b,sb, (~p[n-i]?sb:1)){
if((n&1) && i == (n+1)/2-1 && a != b) continue;
int ex = ((i == (n+1)/2-1) && (a^b));
rep(c,0,1) rep(d,0,1) rep(e,0,1) if(dp[i][j][c][d][e])
if(b >= a || e) dp[i+1][j+(a^c)+(b^d)+ex][a][b][e|(b>a)] += dp[i][j][c][d][e];
}
}
ll ans = 0;
rep(a,0,1) rep(b,0,1) rep(c,0,1) rep(j,0,k)
ans += dp[(n+1)/2][j][a][b][c];
return ans;
}
int main(){
cin>>n>>k>>rnk;
mem(p, -1);
rep(i,1,n){
p[i] = 0;
ll I = cal();
if(rnk > I){
rnk -= I, p[i] = 1;
ll X = cal();
if(X < rnk) return puts("NO SUCH STONE"), 0;
}
}
rep(i,1,n) cout<< (p[i] ? 'X' : 'I');
cout<<endl;
return 0;
}
\(O(nk)\) 做法
考虑做 \(O(1)\) 遍 \(dp\) 获得所有填字母所需要的信息。
按照朴素的想法,我们先设 \(dp_{i,j,a,b}\) 表示长为 \(i\),\(X\) 和 \(I\) 相邻的位置数量恰好为 \(j\),头部为 \(a\),尾部为 \(b\) 的合法字符串数量,在转移的时候可以发现,当 \(a=0,b=1\) 时,\([i+1,j-1]\) 里的东西是可以随便填的,因为这破坏不了字典序大小关系,那么就另设 \(f_{i,j,a,b}\) 为去除字典序限制后的串的数量,转移(写下标上太小了看不见):
然而你会发现有了这个 \(dp\) 你并不能愉快地去填字符,为了计算前 \(i\) 位确定后剩下的方案数,我们还需要更多的信息,观察我们现在填的状态:
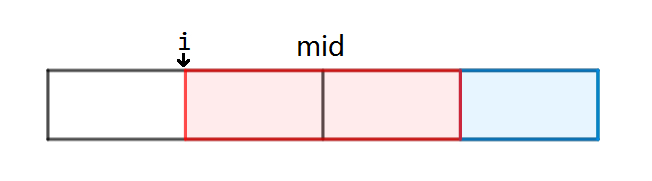
当我们蓝色区域填的和前 \(i\) 个字符完全对称时,红色区域自身就需要是一个合法字符串,\(dp\) 包含了这部分信息,如果蓝色区域翻转后的字典序大于前 \(i\) 个字符组成的串,那么红色区域可以随便填,\(f\) 包含了这部分信息,现在我们还需要知道有多少种方案可以使得蓝色区域翻转后字典序大于已填区域。这是 \(i\) 在中点之前的情况,当 \(i\) 在中点之后时,可以发现所需要的信息与这个蓝色区域方案数是一个东西。
于是设 \(g_{i,j,a,b}\) 表示填到第 \(i\) 位,在蓝色区域中有 \(j\) 个 \(X\) 与 \(I\) 相邻的地方,区域头部第一个字符为 \(a\),当前翻转后字典序是大于 \((b=1)\) 还是等于 \((b=0)\) 前 \(i\) 个字符的字典序,在此情况下满足条件的蓝色区域方案数。\(g\) 需要当前 \(i\) 个字符的信息,所以边填前 \(mid\) 位边转移,\(id\) 为第 \(i\) 位填的字符:
有了这些东西就可以开始填了,注意这里我们要把先前的 \(dp\) 和 \(g\) 前缀和处理一下,将「 恰好有 \(j\) 个 \(X\) 和 \(I\) 相邻的位置」变成「 至多有 \(j\) 个 \(X\) 和 \(I\) 相邻的位置」,由于后面我们要进行准确的计数,\(f\) 不做前缀和处理。在每一位上,我们计算填 \(I\) 和填 \(X\) 之后的方案数,根据对称性这里只讨论填 \(I\) 的情况。
对于前 \(mid\) 位,一种方案是蓝色区域和已填的完全对称,直接用 \(dp\) 中所记录的信息,剩下的方案里,枚举红色区域中 \(X\) 和 \(I\) 相邻的位置数量,剩下的给蓝色区域,两者方案相乘后记录到总方案数中(实际实现时要格外注意决策对 \(j\) 的各种影响):
对于后 \(mid\) 位,直接利用 \(g\) 去计算总方案数,这里需要注意取等的情况,在填的时候,我们动态记录当前 \(mid\) 到 \(i\) 这一段的字典序和前面对应的区域的字典序大小关系,如果比前面小了,就不能取 \(g\) 中相等的方案数,否则便可以。
若某一时刻两种填法方案数之和小于当前所需排名则无解,可以发现这里所有步骤都是 \(O(nk)\) 的,所以总时间复杂度 \(O(nk)\)。
Code
此做法的缺点在于细节比较多,有点难写难调。
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#define mem(a,b) memset(a, b, sizeof(a))
#define rep(i,a,b) for(int i = (a); i <= (b); i++)
#define per(i,b,a) for(int i = (b); i >= (a); i--)
#define ll long long
#define N 66
using namespace std;
ll dp[N][N][2][2], f[N][N][2][2], g[N][N][2][2], gs[N][N][2][2], rnk;
int n, k;
int main(){
cin>>n>>k>>rnk;
rep(i,1,2) rep(a,0,1) rep(b,0,1){
if(i == 1 && a != b) continue;
if(a <= b) dp[i][a^b][a][b] = 1;
f[i][a^b][a][b] = 1;
}
rep(i,1,n) rep(j,0,n){
rep(a,0,1) rep(b,0,1){
if(dp[i][j][a][b])
rep(c,0,1) dp[i+2][j+(a^c)+(b^c)][c][c] += dp[i][j][a][b];
rep(c,0,1) rep(d,0,1) f[i+2][j+(a^c)+(b^d)][c][d] += f[i][j][a][b];
dp[i+2][j+a+(b^1)][0][1] += f[i][j][a][b];
}
rep(a,0,1) rep(b,a,1) if(j)
dp[i][j][a][b] += dp[i][j-1][a][b];
}
string s = "";
char ch[2] = {'I', 'X'};
int lst = -1, used = 0;
rep(i,1,(n+1)/2){
int mid = n-2*i+2;
ll I = dp[mid][k-2*(used+(lst==1))][0][0] + dp[mid][k-(2*used+(lst==1||lst==0))][0][1];
ll X = dp[mid][k-2*(used+(lst==0))][1][1];
int lftI = k-used - (lst == 1), lftX = k-used - (lst == 0);
rep(j,0,k-used){
if(j <= lftI){
rep(a,0,1) rep(b,0,1) if(lftI-j-(a^b) >= 0)
I += f[mid][j][0][a] * gs[i-1][lftI-j-(a^b)][b][1];
}
if(j <= lftX){
rep(a,0,1) rep(b,0,1) if(lftX-j-(a^b) >= 0)
X += f[mid][j][1][a] * gs[i-1][lftX-j-(a^b)][b][1];
}
}
int id = (rnk > I);
s.push_back(ch[id]);
if(id && (rnk -= I) > X) return puts("NO SUCH STONE"), 0;
if(i != 1 && id != lst) used++;
lst = id;
if(i == 1){
if(id == 1) g[1][0][1][0] = 1;
else g[1][0][0][0] = g[1][0][1][1] = 1;
} else rep(j,0,n-1) rep(a,0,1){
rep(c,id,1) g[i][j+(c^a)][c][c>id] += g[i-1][j][a][0];
rep(c,0,1) g[i][j+(c^a)][c][1] += g[i-1][j][a][1];
}
rep(j,0,n-1) rep(a,0,1) rep(b,0,1){
gs[i][j][a][b] = g[i][j][a][b];
if(j) gs[i][j][a][b] += gs[i][j-1][a][b];
}
}
k -= used;
int geq = 1;
per(i,n/2,1){
ll I = 0, X = 0;
rep(a,geq<1,1){
I += gs[i][k-(lst==1)][0][a];
X += gs[i][k-(lst==0)][1][a];
}
if(rnk > I+X) return puts("NO SUCH STONE"), 0;
int id = (rnk > I);
if(id) rnk -= I;
s.push_back(ch[id]);
if(lst != id) k--;
lst = id;
if(id < (s[i-1] != 'I')) geq = 0;
if(id > (s[i-1] != 'I')) geq = 2;
}
cout<<s<<endl;
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号