CS Academy Round#86 E.Growing Segment
题目链接
CsAcademy Round 86 E.Growing Segment
题目大意
在一根数轴上,你初始有一个长度为 \(len\) 的区间左端点在 \(0\) 的位置,有一系列点 \(X\),你需要挪动区间使其依次覆盖到 \(X\) 中的点,现在有 \(Q\) 次询问,每次给出 \(len\),求最少需要移动的距离。
\(1\leq|X|,Q\leq10^5\), \(0\leq len\leq10^9\), \(-10^9\leq X_i\leq 10^9\)
思路
我们直接观察样例:
输入(第一行 \(|X|\) 和 \(Q\) ,第二行 \(X\) ,第三行询问的 \(len\))
9 6
2 -3 -1 1 2 3 5 3 7
0 1 2 3 4 5
输出:
21
16
11
10
9
8
具体点,我们把图画出来:
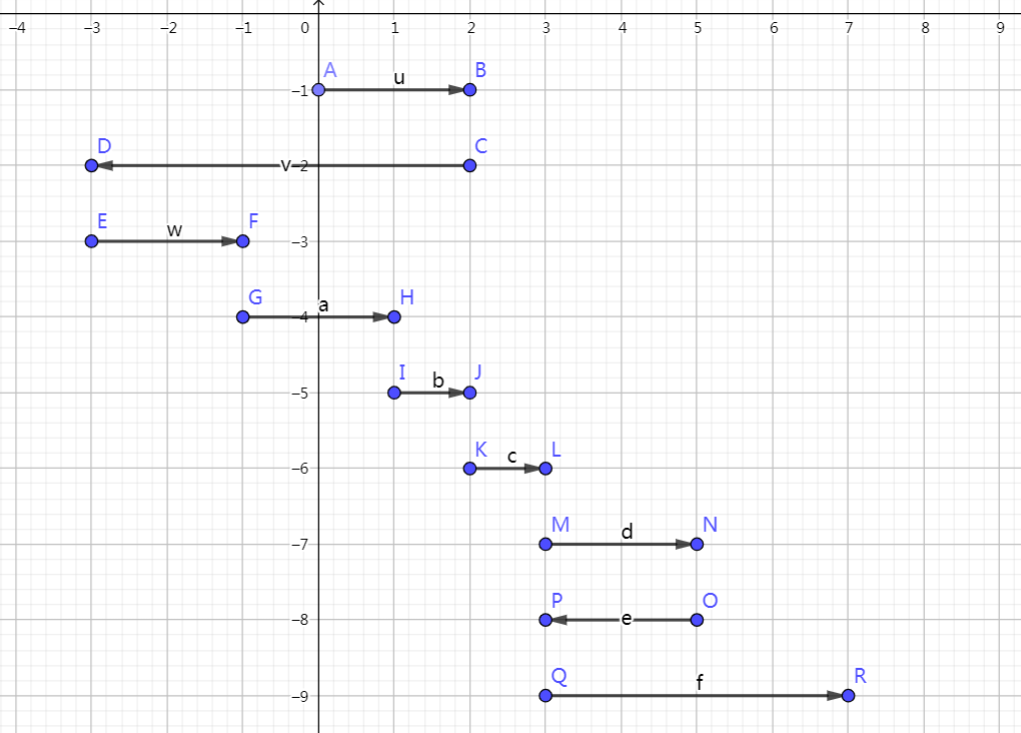
显然,其中有一些冗余的部分计算答案的时候可以直接合并的,经过精简化:
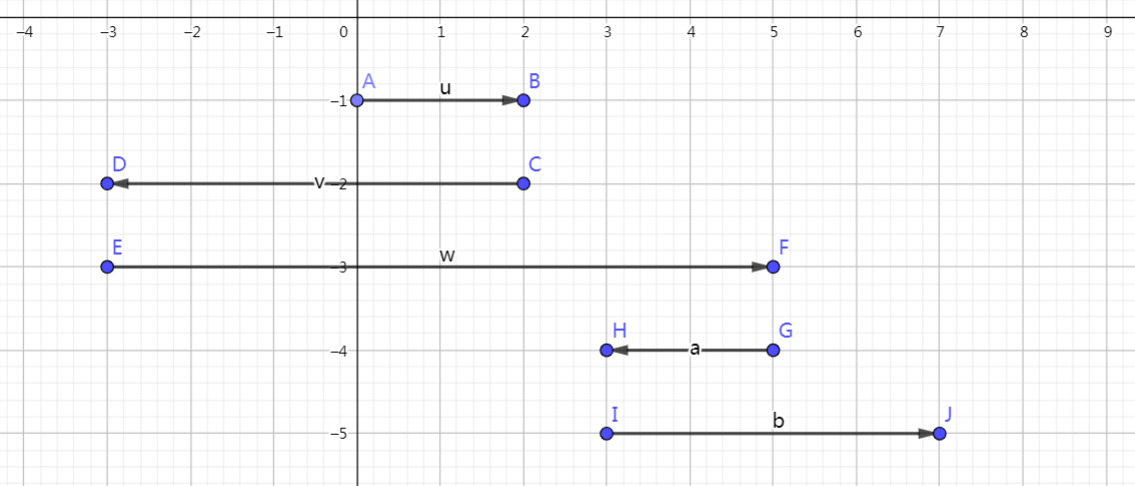
在草稿纸上,将 \(len\) 为不同值时的移动情况记录下来:
0 : +2 -5 +8 -2 +4
1 : +1 -4 +7 -1 +3
2 : 0 -3 +6 0 +2
3 : 0 -3 +5 0 +2
4 : 0 -3 +4 0 +2
5 : 0 -3 +3 0 +2
6 : 0 -3 +2 0 +2
7 : 0 -3 +1 0 +2
8 : 0 -3 0 0 +2
9 : 0 -3 0 0 +1
10: 0 -3 0 0 0
结合这张表,可以发现这样的规律:
- 每个方向的移动距离随着 \(len\) 的增加等速减小
- 一个方向的移动是否会变化取决于前面移动的状态,跳过中间的所有 \(0\) 的地方,若前面那个非零的位置和当前位置同奇偶,那么当前移动就被 “冻结” 了,否则当前移动的距离会正常减小。
规律很好解释,第一条显然,第二条是两种移动是否拥有同方向端点导致的,比如上表中的第 \(3\) 个移动和第 \(5\) 个移动,它们在 \(len\in[2,8]\) 时端点都在右侧,分别是 \(F\) 和 \(J\),端点相对位置不变,那么移动距离当然也就不变了.
然后我们就可以得到这题的做法了。
把询问中的 \(len\) 按从小到大排序,先预处理出最开始(即 \(len=0\))的移动情况,把它们丢进小根堆。用链表维护每一个移动的上一个非零移动是谁,\(frozen\) 记录该移动是否处于 “冻结” 状态,\(delta\) 记录当前有多少移动的距离是在减少中的。
我们处理一个 \(len\) 的时候将在此之前距离会归零的移动从小根堆里拿出来,若它处于 “冻结” 或不是最新的状态就continue ,否则把此移动归零之后,更新链表,根据奇偶性把后面的那个移动 “冻结” 或 “解冻”,“冻结” 的时候要记录一下目前移动距离还剩多少,“解冻” 时更新其归零的时间,然后插入到小根堆里。\(delta\) 实时更新,并根据时间维护移动距离总和。
时间复杂度:\(O(nlogn)\) (\(n\) 指 \(|X|\) )
实现细节
- 初始时区间左端点在 \(0\) 的位置,需将这个也视为一次移动,如果第一次移动是往左边走,那么该移动一开始就处于 ”冻结” 状态。
- 注意相邻的几个移动同时归零的情况,处理不好的话链表的状态会出现问题。
- 链表的右边是边界的时候不要更新 \(delta\) 。
- 注意开 long long。
Code
54ms 的最优解 \(QAQ\)
其实大众主要的做法是维护点是否对答案有贡献,做法大同小异,如 atatmoir 的code,但是常数好像没这个小,不过本人的做法细节多是真的。
#include<iostream>
#include<algorithm>
#include<queue>
#include<vector>
#include<cstdio>
#define rep(i,a,b) for(int i = (a); i <= (b); i++)
#define per(i,b,a) for(int i = (b); i >= (a); i--)
#define N 100100
#define ll long long
#define PLL pair<ll, ll>
#define fr first
#define sc second
using namespace std;
inline int read(){
int s = 0, w = 1;
char ch = getchar();
while(ch < '0' || ch > '9'){if(ch == '-') w = -1; ch = getchar();}
while(ch >= '0' && ch <= '9') s = (s<<3)+(s<<1)+(ch^48), ch = getchar();
return s*w;
}
ll X[N], n, q;
ll a[N], cnt, ans[N];
PLL len[N];
priority_queue<PLL, vector<PLL>, greater<PLL> > change;
bool frozen[N];
struct node{
ll pre, nxt;
}mov[N];
int main(){
cin>>n>>q;
rep(i,1,n) X[i] = read();
rep(i,1,q) len[i].fr = read(), len[i].sc = i;
sort(len+1, len+1+q);
ll tot = 0;
ll pos = 0, st = 0;
rep(i,1,n){
while(i < n && ((X[i+1]-X[i] >= 0)^(X[i]-pos >= 0)) == 0) i++;
if(cnt == 0 && X[i]-pos < 0) cnt = st = 1, frozen[cnt+1] = true;
a[++cnt] = abs(pos-X[i]), change.push({a[cnt], cnt}), tot += a[cnt];
pos = X[i], mov[cnt] = {cnt-1, cnt+1};
}
ll delta = cnt-2*st, lst = 0;
rep(i,1,q){
while(!change.empty() && change.top().fr < len[i].fr){
PLL cur = change.top(); change.pop();
ll id = cur.sc;
if((frozen[id] && a[id]) || cur.fr != a[cur.sc]) continue;
tot -= (cur.fr-lst) * delta;
delta--, a[id] = 0;
ll nxt = mov[id].nxt;
if(nxt <= cnt) if((mov[nxt].pre^nxt)&1) delta--;
mov[nxt].pre = mov[id].pre;
mov[mov[id].pre].nxt = nxt;
if(nxt <= cnt){
if((mov[nxt].pre^nxt)&1){
delta++;
if(frozen[nxt]) a[nxt] += cur.fr, frozen[nxt] = false;
change.push({a[nxt], nxt});
}
else frozen[nxt] = true, a[nxt] -= cur.fr;
}
lst = cur.fr;
}
tot -= (len[i].fr-lst)*delta, lst = len[i].fr;
ans[len[i].sc] = tot;
}
rep(i,1,q) printf("%lld\n", ans[i]);
return 0;
}
教训:拍错还是要拍小数据!不少错解在大随机数据上的表现是可以相当优秀的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号