
【Coursera Machine Learning】线性回归问题的梯度下降算法
引入
梯度下降算法可以用于在线性回归(及以外)问题中帮助我们求出最小的代价函数。
基本步骤:先初始化,一般选择同时初始化为0。然后持续改变来减少代价函数,直到最小值,或者是局部最小值。
假设我们把下图现象成想象成一座山,想象你站在红色的山顶上,该用什么步伐和方向才能最快下山。如果你的起点偏移一点,你可能就会走截然不同的另外一条路,获得非常不同的局部最优解,这是梯度下降算法的特点之一。
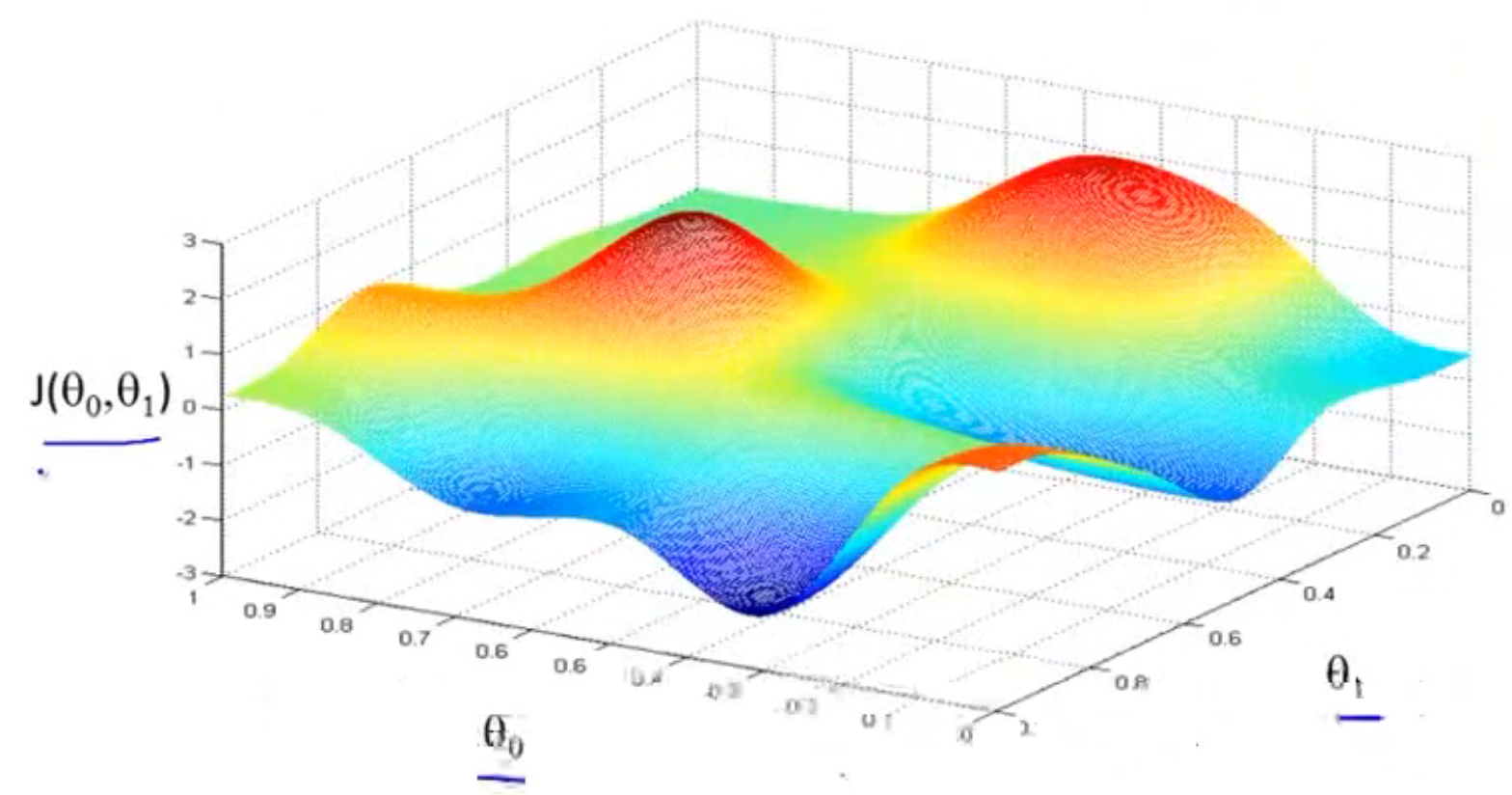
定义
重复以下,直到收敛:
赋值公式的解释
Learning Rate的含义
如果设置太小,向顶点靠拢的速度会很慢。
但反之如果太大,梯度下降法可能会掠过最低点,甚至最终无法收敛,甚至发散
偏导数项的含义
前面说过关于单个变量,比如的图像,是一条曲线,那么导数项的含义就是关于为特定值时曲线的切线的斜率,将它带到公式里能让的值向函数顶点(最低点),也就是我们要找的答案靠拢。
现在将代价函数公式代入梯度下降算法公式里,偏导数项就变成了以下形式:
再将带入,得:
如果θ一上来就在最低点会发生什么:如果上来就在最低点,那么导数项的斜率就是0,于是θ不会再有改变,维持在最低点。
于是可以分别求出和的偏导数项:
:
:
这两个微分项其实就是代价函数的斜率,我们要在梯度下降算法中做的就是将上面两条式子反复重复直到收敛为止
使用梯度下降算法时,代价函数一定会是一个凸函数,所以最后结果一定能收敛到全局最优解。
分类:
机器学习&深度学习



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App