线性模型练习题
1. 学习理解如何用最小二乘法的矩阵公式来得到线性回归的解,并使用numpy库来实现该算法。
在研究一个问题时,从某种理论或假定出发,得到一个模型。根据这个模型,我们感兴趣的某个量有其理论值,同时可以对这个量进行实际观测,而得出其观测值。由于种种原因,如模型不完全正确以及观测有误差,理论值与观测值会有差距,这差距的平方和
可以作为理论与实测符合程度的度量。求和是针对若干次不同的观测,通常理论中含有未知参数或参数向量 \(\theta\)。最小二乘法(Least Squares Method,以下简记为 LSE)要求选择使 \(J(\theta)\) 达到最小的 \(\theta\) 值 \(\widehat{\theta}\),因此,LSE 的直接意义,是作为一种估计未知参数的方法。
寻找 \(\theta\) 有两种方法,一种是梯度下降法,是搜索算法,先给 \(\theta\) 赋个初值,然后再根据使 \(J(\theta)\) 更小的原则对 \(\theta\) 进行修改,直到\(\theta\)收敛,\(J(\theta)\) 达到最小,也就是不断尝试;另外一种是矩阵求导法,要使 \(J(\theta)\) 最小,就对 \(J(\theta)\) 求导,使导数等于 0,求得 \(\theta\)。
上一周介绍过梯度下降法,这里详细推导下最小二乘法的矩阵公式。
假定有 m 个例子的训练集 {\((x^{(i)},y^{(i)});i=1,...,m\)},x 是 n 维向量,是自变量,y 是实际观测值,是因变量,假定 y 是 x 的线性函数,h(x) 是对 y 的预测值。
x 和 \(\theta\) 都是长度为 n+1 的向量,其中 \(x_{0}=1\),\(\theta_{0}\) 是截距。
得到了参数 \(\theta\),就能根据 x 计算出 y 值。那么,怎么根据当前的训练数据集得到 \(\theta\) 呢? \(\theta\) 值肯定不是随便给,那要满足什么要求呢?
毫无疑问,要想准确预测新数据,得出的\(\theta\)最起码应该保证在训练集上预测准确些,怎么才算准确些呢?计算出的价格与真实的价格应尽量接近。计算价格和实际价格的差距以损失函数来表示。
我们最终选择的\(\theta\)要使\(J(\theta)\)最小,对\(\theta\)就这个要求 。
好,现在我们的目标就是要找到使\(J(\theta)\)最小的\(\theta\)。梯度下降法不说了,下面我们使用矩阵方法。
首先定义:
由 \(h_{\theta}(x^{(i)})=(x^{(i)})^{T}\theta\),计算预测值和实际值的差向量:
由 \(z^{T}z=\sum_{i} z^{2}_{i}\),得:
所以
然后就是求\(J(\theta)\)关于\(\theta\)的导数,并使其等于 0,最后就可以求出\(\theta\)。\(J(\theta)\) 求导过程如下。

上面的推导过程看着很复杂,但稍微耐心看下每一步,就会觉得顺理成章了。具体每一步的推导依据可参考机器学习课件第 11 页。
为最小化 \(J(\theta)\),我们置公式(6)为 0,得:
由此得
至此,求解完毕。
代码如下。
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.graphics.api as smg
import patsy
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy import stats
import seaborn as sns
先生成训练数据集。
np.random.seed(123456789)
N = 100
x1 = np.random.randn(N) # 自变量
x2 = np.random.randn(N)
def y_true(x1, x2):
return 1 + 2 * x1 + 3 * x2
ytrue = y_true(x1, x2)
y = ytrue + e
X = np.vstack([np.ones(N), x1, x2]).T
先用 numpy 自带的最小二乘法包 np.linalg.lstsq 求 \(\theta\)值。
beta, res, rank, sval = np.linalg.lstsq(X, y)
print beta
[ 0.86896993 1.98195932 2.96540985]
再使用我们上面的矩阵方法 \(\theta =(X^{T}X)^{-1}X^{T}\vec{y}\) 求解。
def matrixLSE(X, y): # 矩阵法求最小二乘
xtx = np.dot(X.T, X)
inverse = np.linalg.inv(xtx)
xxx = np.dot(inverse, X.T)
thetalse = np.dot(xxx, y)
return thetalse
thetalse = matrixLSE(X, y)
print thetalse
[ 0.86896993 1.98195932 2.96540985]
求出的 \(\theta\) 值跟 numpy.linalg.lstsq 求的解一样,说明我们的代码是正确的~
2. 使用pandas库中的函数下载上证综指和任一成份股票数据,计算日收益率,对这两组数据建立回归模型,将上证综指的收益率作为解释变量,说明这个模型的用处。
from datetime import datetime
from pandas_datareader import data, wb # 需要先安装 pandas_datareader
获取上证综指数据。
start = datetime(2015, 6, 3)
end = datetime(2016, 6, 3)
Shanghai = data.DataReader("000001.SS", 'yahoo', start, end) # 000001.SS 表示上证综指,返回 DataFrame
Shanghai.head() # 纵轴是日期,横轴是开盘价、最高价、最低价、收盘价、成交量、复权收盘。因上证综指并非具体某支股票,所以交易量为 0。
Shanghai = Shanghai.drop('Open',axis=1)
Shanghai = Shanghai.drop('High',axis=1)
Shanghai = Shanghai.drop('Low',axis=1)
Shanghai = Shanghai.drop('Volume',axis=1)
Shanghai = Shanghai.drop('Adj Close',axis=1)
Shanghai["retRate"] = (Shanghai.Close-Shanghai.Close.shift(1))/Shanghai.Close.shift(1) # 日收益率,当然在做实证时都用对数收益率
Shanghai = Shanghai.ix[1:]
Shanghai.head()
| Close | retRate | |
|---|---|---|
| Date | ||
| 2015-06-04 | 4947.10 | 0.007560 |
| 2015-06-05 | 5023.10 | 0.015363 |
| 2015-06-08 | 5131.88 | 0.021656 |
| 2015-06-09 | 5113.53 | -0.003576 |
| 2015-06-10 | 5106.04 | -0.001465 |
获取宇通客车的数据。
start = datetime(2015, 6, 3)
end = datetime(2016, 6, 3)
Yutong = data.DataReader("600066.SS", 'yahoo', start, end) # 宇通客车,返回 DataFrame
Yutong.head() # 纵轴是日期,横轴是开盘价、最高价、最低价、收盘价、成交量、复权收盘。因上证综指并非具体某支股票,所以交易量为 0。
Yutong = Yutong.drop('Open',axis=1)
Yutong = Yutong.drop('High',axis=1)
Yutong = Yutong.drop('Low',axis=1)
Yutong = Yutong.drop('Volume',axis=1)
Yutong = Yutong.drop('Adj Close',axis=1)
Yutong["retRate"] = (Yutong.Close-Yutong.Close.shift(1))/Yutong.Close.shift(1) # 日收益率,当然在做实证时都用对数收益率
Yutong = Yutong.ix[1:]
Yutong.head()
| Close | retRate | |
|---|---|---|
| Date | ||
| 2015-06-04 | 23.17 | -0.022775 |
| 2015-06-05 | 23.41 | 0.010358 |
| 2015-06-08 | 23.11 | -0.012815 |
| 2015-06-09 | 23.07 | -0.001731 |
| 2015-06-10 | 22.83 | -0.010403 |
使用上面介绍的 smf.ols 做线性回归。
x = Shanghai["retRate"].values
y = Yutong.ix[Shanghai.index].retRate.values
data = pd.DataFrame({"x": x, "y": y})
model = smf.ols("y ~ x", data) # 这里没有写截距,截距是默认存在的
result = model.fit()
print(result.summary())
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.542
Model: OLS Adj. R-squared: 0.540
Method: Least Squares F-statistic: 270.3
Date: Sat, 18 Jun 2016 Prob (F-statistic): 1.38e-40
Time: 14:54:28 Log-Likelihood: 578.89
No. Observations: 230 AIC: -1154.
Df Residuals: 228 BIC: -1147.
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [95.0% Conf. Int.]
------------------------------------------------------------------------------
Intercept 0.0011 0.001 0.845 0.399 -0.001 0.004
x 0.8362 0.051 16.442 0.000 0.736 0.936
==============================================================================
Omnibus: 24.051 Durbin-Watson: 1.863
Prob(Omnibus): 0.000 Jarque-Bera (JB): 42.013
Skew: 0.578 Prob(JB): 7.53e-10
Kurtosis: 4.746 Cond. No. 39.3
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
看自变量的 P 值,Intercept 可以去除,只由 x 预测。
R-squared 只有 0.542,数据的拟合不够好,说明用上证综指预测宇通客车的日收益率不靠谱。
线性回归,是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。线性回归假设特征和结果满足线性关系。线性关系的表达能力非常强大,每个特征对结果的影响强弱可以由前面的参数体现,而且每个特征变量可以首先映射到一个函数,然后再参与线性计算。这样就可以表达特征与结果之间的非线性关系。
3. 在kaggle网站上找到titanic数据,并使用 logistic 回归来建模,研究分析每个因素对应生存的重要性。
数据包含的字段如下:
- PassengerID
- Survived(存活与否)
- Pclass(客舱等级)
- Name(姓名)
- Sex(性别)
- Age(年龄)
- SibSp(亲戚和配偶在船数量)
- Parch(父母孩子的在船数量)
- Ticket(票编号)
- Fare(价格)
- Cabin(客舱位置)
- Embarked(上船的港口编号)
数据读取
input_df = pd.read_csv('Data/train.csv', header=0)
input_df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
数据预处理
input_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
可以看到 Age、Cabin、Embarked 几个字段有空值,填充下。其中客舱位置 Cabin 空值最多,没什么用,干脆去掉。
input_df = input_df.drop('Cabin', axis=1) # 去除没用的字段客舱位置,空值还多
input_df.ix[input_df['Age'].isnull(),'Age'] = input_df['Age'].median() # 年龄取个中间值
input_df.ix[input_df['Embarked'].isnull(),'Embarked'] = input_df['Embarked'].mode().values # 上船的港口编号
Name 也是一个没用的字段,不信什么名字能影响生死。当然有人会说,有些姓名是贵族才有的,那还有价格 Fare 和客舱等级 Pclass 体现呢,从名字来识别身份判断存亡最不靠谱,去掉。
input_df = input_df.drop('Name', axis=1)
票编号 Ticket 也去掉,跟名字 Name 一样没用。
input_df = input_df.drop('Ticket', axis=1)
input_df.Embarked.unique() # 上船的港口编号,没用的字段,果断去掉
array(['S', 'C', 'Q'], dtype=object)
input_df = input_df.drop('Embarked', axis=1)
input_df = input_df.drop('PassengerId', axis=1)
input_df.Sex = input_df.Sex.map({"male": 1, "female": 0}) # 做个映射
input_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 7 columns):
Survived 891 non-null int64
Pclass 891 non-null int64
Sex 891 non-null int64
Age 891 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Fare 891 non-null float64
dtypes: float64(2), int64(5)
memory usage: 48.8 KB
input_df.head()
| Survived | Pclass | Sex | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 1 | 22.0 | 1 | 0 | 7.2500 |
| 1 | 1 | 1 | 0 | 38.0 | 1 | 0 | 71.2833 |
| 2 | 1 | 3 | 0 | 26.0 | 0 | 0 | 7.9250 |
| 3 | 1 | 1 | 0 | 35.0 | 1 | 0 | 53.1000 |
| 4 | 0 | 3 | 1 | 35.0 | 0 | 0 | 8.0500 |
因为逻辑回归建模时,需要输入的特征都是数值型特征,通常会先对类目型的特征因子化。
dummies_Sex = pd.get_dummies(input_df['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(input_df['Pclass'], prefix= 'Pclass')
input_df = pd.concat([input_df, dummies_Sex, dummies_Pclass], axis=1)
input_df.drop(['Pclass','Sex'], axis=1, inplace=True)
input_df.head()
| Survived | Age | SibSp | Parch | Fare | Sex_0 | Sex_1 | Pclass_1 | Pclass_2 | Pclass_3 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 22.0 | 1 | 0 | 7.2500 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 |
| 1 | 1 | 38.0 | 1 | 0 | 71.2833 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 2 | 1 | 26.0 | 0 | 0 | 7.9250 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 3 | 1 | 35.0 | 1 | 0 | 53.1000 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 4 | 0 | 35.0 | 0 | 0 | 8.0500 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 |
Age 和Fare 两个属性幅度变化太大了吧,对于逻辑回归与梯度下降来说,各属性值之间scale差距太大,将对收敛速度造成严重损害,甚至不收敛。这里用scikit-learn 里面的 preprocessing 模块对这两个属性做一个缩放 scaling ,所谓 scaling,其实就是将一些变化幅度较大的特征化到[-1,1]之内。
import warnings
warnings.filterwarnings("ignore") # 屏蔽掉讨厌的警告
import sklearn.preprocessing as preprocessing
scaler = preprocessing.StandardScaler()
age_scale_param = scaler.fit(input_df['Age'])
input_df['Age_scaled'] = scaler.fit_transform(input_df['Age'], age_scale_param)
fare_scale_param = scaler.fit(input_df['Fare'])
input_df['Fare_scaled'] = scaler.fit_transform(input_df['Fare'], fare_scale_param)
input_df.head()
| Survived | Age | SibSp | Parch | Fare | Sex_0 | Sex_1 | Pclass_1 | Pclass_2 | Pclass_3 | Age_scaled | Fare_scaled | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 22.0 | 1 | 0 | 7.2500 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | -0.565736 | -0.502445 |
| 1 | 1 | 38.0 | 1 | 0 | 71.2833 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.663861 | 0.786845 |
| 2 | 1 | 26.0 | 0 | 0 | 7.9250 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | -0.258337 | -0.488854 |
| 3 | 1 | 35.0 | 1 | 0 | 53.1000 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.433312 | 0.420730 |
| 4 | 0 | 35.0 | 0 | 0 | 8.0500 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.433312 | -0.486337 |
逻辑回归
使用 statsmodels.formula.api 的 logit 接口进行逻辑斯特回归。
model = smf.logit("Survived ~ Pclass_1 + Pclass_2 + Pclass_1 + Sex_0 + Sex_1 + Age_scaled + SibSp + Parch + Fare_scaled", data=input_df)
result = model.fit() # 内部使用极大似然估计,所以会有结果返回,表示成功收敛
print(result.summary())
Optimization terminated successfully.
Current function value: 0.442813
Iterations 8
Logit Regression Results
==============================================================================
Dep. Variable: Survived No. Observations: 891
Model: Logit Df Residuals: 883
Method: MLE Df Model: 7
Date: Mon, 20 Jun 2016 Pseudo R-squ.: 0.3350
Time: 02:03:31 Log-Likelihood: -394.55
converged: True LL-Null: -593.33
LLR p-value: 7.950e-82
===============================================================================
coef std err z P>|z| [95.0% Conf. Int.]
-------------------------------------------------------------------------------
Intercept -0.5152 7.34e+06 -7.02e-08 1.000 -1.44e+07 1.44e+07
Pclass_1 2.1519 0.290 7.420 0.000 1.584 2.720
Pclass_2 1.1400 0.228 5.006 0.000 0.694 1.586
Sex_0 1.1216 7.34e+06 1.53e-07 1.000 -1.44e+07 1.44e+07
Sex_1 -1.6368 7.34e+06 -2.23e-07 1.000 -1.44e+07 1.44e+07
Age_scaled -0.5096 0.102 -4.997 0.000 -0.709 -0.310
SibSp -0.3481 0.109 -3.192 0.001 -0.562 -0.134
Parch -0.1084 0.117 -0.923 0.356 -0.339 0.122
Fare_scaled 0.1499 0.122 1.234 0.217 -0.088 0.388
===============================================================================
伪 R 方 Pseudo R-squ. 只有 0.3350,效果不行。
看各自变量的 P 值,客舱等级 Pclass、年龄 Age 和 亲戚和配偶在船数量 SibSp 要影响要显著些。性别 Sex 竟然没影响,不是女士优先吗?价格 Fare 和 父母孩子的在船数量 Parch 的影响可以忽略。
用这个 model 做下预测。
读取 test.csv,和 train.csv 做一样的预处理。
testAll_df = pd.read_csv('Data/test.csv', header=0)
test_df = testAll_df.drop('Cabin', axis=1) # 去除没用的字段客舱位置,空值还多
test_df.ix[test_df['Age'].isnull(),'Age'] = test_df['Age'].median() # 年龄取个中间值
test_df.ix[test_df['Fare'].isnull(),'Fare'] = test_df['Fare'].median() # 票价取个中间值
test_df.ix[test_df['Embarked'].isnull(),'Embarked'] = test_df['Embarked'].mode().values # 上船的港口编号
test_df = test_df.drop('Name', axis=1)
test_df = test_df.drop('Ticket', axis=1)
test_df = test_df.drop('Embarked', axis=1)
test_df.Sex = test_df.Sex.map({"male": 1, "female": 0}) # 做个映射
dummies_Sex = pd.get_dummies(test_df['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(test_df['Pclass'], prefix= 'Pclass')
test_df = pd.concat([test_df, dummies_Sex, dummies_Pclass], axis=1)
test_df.drop(['Pclass','Sex'], axis=1, inplace=True)
import warnings
warnings.filterwarnings("ignore") # 屏蔽掉讨厌的警告
import sklearn.preprocessing as preprocessing
scaler = preprocessing.StandardScaler()
age_scale_param = scaler.fit(test_df['Age'])
test_df['Age_scaled'] = scaler.fit_transform(test_df['Age'], age_scale_param)
fare_scale_param = scaler.fit(test_df['Fare'])
test_df['Fare_scaled'] = scaler.fit_transform(test_df['Fare'], fare_scale_param)
test_df.head()
| PassengerId | Age | SibSp | Parch | Fare | Sex_0 | Sex_1 | Pclass_1 | Pclass_2 | Pclass_3 | Age_scaled | Fare_scaled | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 34.5 | 0 | 0 | 7.8292 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.386231 | -0.497413 |
| 1 | 893 | 47.0 | 1 | 0 | 7.0000 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.371370 | -0.512278 |
| 2 | 894 | 62.0 | 0 | 0 | 9.6875 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 2.553537 | -0.464100 |
| 3 | 895 | 27.0 | 0 | 0 | 8.6625 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | -0.204852 | -0.482475 |
| 4 | 896 | 22.0 | 1 | 1 | 12.2875 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | -0.598908 | -0.417492 |
predictions = result.predict(test_df)
Survivedresult = pd.DataFrame({'PassengerId':testAll_df['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
Survivedresult.to_csv("Data/logistic_regression_predictions.csv", index=False)
最后在 Kaggle 的 Make a submission 页面,提交上结果。
4. 搜集某个城市过去1个月的PM2.5小时级数据,根据时间序列预测方法,来预测未来三天的PM2.5情况。
# 数据读取并清理
def readpmfile(filepath):
beijing_aq = pd.read_csv(filepath, header=0) # header 指明用作列名的行号
beijing_pm25 = beijing_aq.ix[beijing_aq['type']=='PM2.5',[0,1,3]] # 抽取 PM2.5 数据子集,就选东四的 PM2.5 数据
beijing_pm25.rename(columns={"东四": "Dongsi"}, inplace=True) # 列重命名
beijing_pm25['datetime'] = pd.to_datetime(beijing_pm25.date, format='%Y%m%d')
beijing_pm25.index = range(24) # 修改索引,以便后面把 datetime 加上 hour
length = beijing_pm25.shape[0] # 获取数据个数
for i in range(0, length): # 因为 datetime.timedelta 不能接受 Series 参数,所以只能一个一个加
beijing_pm25.ix[i,'datetime'] = beijing_pm25.ix[i,'datetime'] + datetime.timedelta(hours = beijing_pm25.ix[i,'hour'])
beijing_pm25 = beijing_pm25.drop(['date','hour'], axis = 1) # 丢掉这两个已经没用的字段
beijing_pm25 = beijing_pm25.set_index("datetime") # 用 datetime 来作为索引
return beijing_pm25
import datetime
beijing_pm = pd.DataFrame() # 每次先清空,免得多次执行造成重复加载
starttime= datetime.datetime(2016, 5, 1) # 读取从 5 月 1 日开始的 34 天数据,5 月 31 天,6 月 3 天
for i in range(0, 34): # 每天一个 pm2.5 数据文件,文件需要一个一个读取
curtime = starttime + datetime.timedelta(days = i)
filepath = 'Data/beijing_20160101-20160611/'
filename = 'beijing_all_' + curtime.strftime('%Y%m%d') + '.csv'
beijing_pm25 = readpmfile(filepath + filename)
beijing_pm = pd.concat([beijing_pm, beijing_pm25])
beijing_pm.info() # 每天 24 条 pm2.5 数据,34 天,应有 24*34=816 条数据,这里只有 792 条是非空的
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 816 entries, 2016-05-01 00:00:00 to 2016-06-03 23:00:00
Data columns (total 1 columns):
Dongsi 792 non-null float64
dtypes: float64(1)
memory usage: 12.8 KB
处理缺失数据,注意这里不能把数据删除,要填充,否则后面 predict 会出问题。血的教训,切记~!
#beijing_pm = beijing_pm.dropna() # 缺失数据直接过滤掉
beijing_pm = beijing_pm.fillna(method = 'pad') # 用前一个数据代替NaN
beijing_pm.head()
| Dongsi | |
|---|---|
| datetime | |
| 2016-05-01 00:00:00 | 213.0 |
| 2016-05-01 01:00:00 | 202.0 |
| 2016-05-01 02:00:00 | 172.0 |
| 2016-05-01 03:00:00 | 172.0 |
| 2016-05-01 04:00:00 | 172.0 |
pm_May = beijing_pm[beijing_pm.index.month == 5] # 取 5 月份的 PM2.5 数据做训练
pm_June = beijing_pm[beijing_pm.index.month == 6] # 预测 6 月份的 PM2.5 含量
pm_May.plot(figsize=(12, 4)); # 看看 5 月份的数据
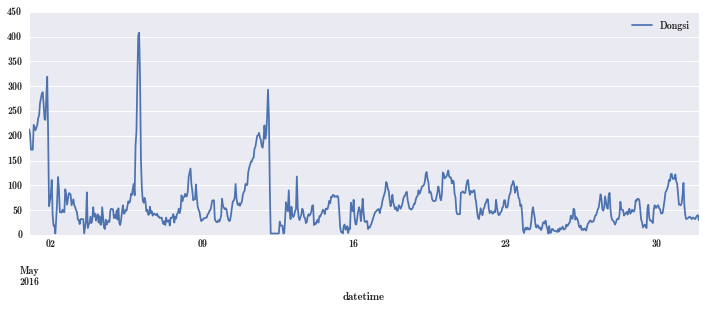
可见 PM2.5 数据还是有明显的规律,有规律才可以建模型。规律体现在什么地方,画个散点图,看一定时间前后的 PM2.5 有没有相关性。
plt.scatter(pm_May[1:], pm_May[:-1]); # 滞后一小时,看前一小时的 PM2.5 数据对后一小时有没有影响
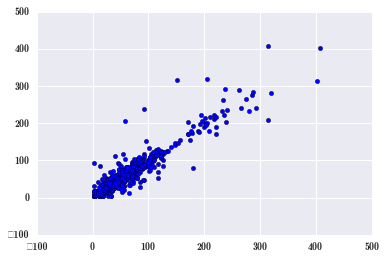
从图中看,是呈线性相关的,可见一个小时还是有一定影响的。滞后项的相关性称为自相关,自己的历史数据会影响后来的数据,这种规律称为自相关。
plt.scatter(pm_May[2:], pm_May[:-2]); # 间隔两小时还有没有影响
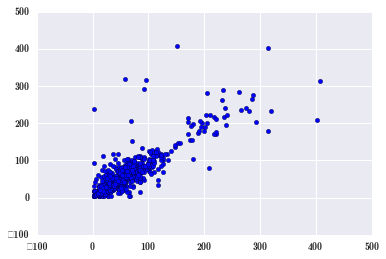
影响比一个小时弱点,很容易理解。
再来相邻两天的数据有没有相关性。
plt.scatter(pm_May[24:], pm_May[:-24]); # 滞后 24 小时
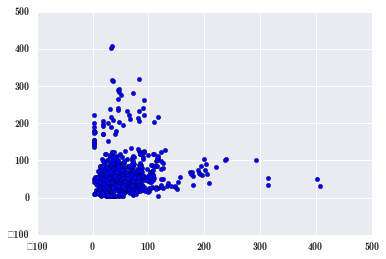
影响不太明显了。
一般来说,自相关就是越近的数据影响越大。可以画相关系数图。建模时要把这种自相关性去掉,使用差分来去掉,第二张图就使用了差分,差分之后,自相关性有所减弱,第三张图是差分的差分,第四张图是三阶差分,差分阶次越高,自相关性就越小。
fig, axes = plt.subplots(1, 4, figsize=(12, 3))
smg.tsa.plot_acf(pm_May.Dongsi, lags=24, ax=axes[0]) # 时间序列子模块,自相关,今天的跟历史 24 个小时的相关性
smg.tsa.plot_acf(pm_May.Dongsi.diff().dropna(), lags=24, ax=axes[1]) # 每个条状是个相关系数
smg.tsa.plot_acf(pm_May.Dongsi.diff().diff().dropna(), lags=24, ax=axes[2])
smg.tsa.plot_acf(pm_May.Dongsi.diff().diff().diff().dropna(), lags=24, ax=axes[3])
fig.tight_layout()
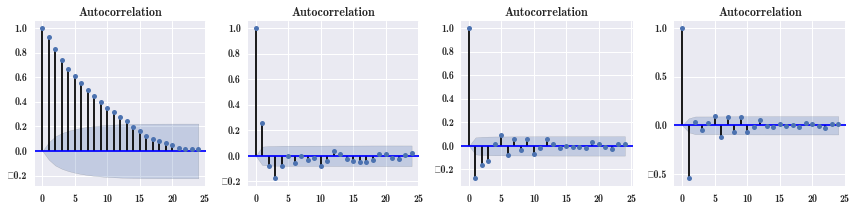
使用自回归模型 sm.tsa.AR 来做时间序列预测。
model = sm.tsa.AR(pm_May.Dongsi) # AR 模型就是自回归模型
result = model.fit(24) #认为过去 24 小时都会影响现在时间点的 PM2.5 浓度
sm.stats.durbin_watson(result.resid) # 把残差拿出来检验下
1.9984097620329431
残差是不应该有自回归的,把残差拿出来检验下,在 2 附近,意味着没有自回归。
fig, ax = plt.subplots(1, 1, figsize=(8, 3))
smg.tsa.plot_acf(result.resid, lags=24, ax=ax) # 画残差自相关性图
fig.tight_layout()
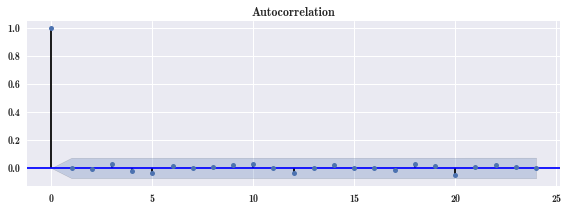
残差没有自相关性。
下面做预测,预测 6 月份头三天的 PM2.5 数据。
fig, ax = plt.subplots(1, 1, figsize=(12, 4))
ax.plot(pm_May.index.values[-72:], pm_May.Dongsi.values[-72:], label="train data")
ax.plot(pm_June.index.values, pm_June.Dongsi.values, label="actual outcome")
ax.plot(pd.date_range("2016-06-01", "2016-06-04", freq="H").values,
result.predict("2016-06-01", "2016-06-04"), label="predicted outcome")
ax.legend()
fig.tight_layout()
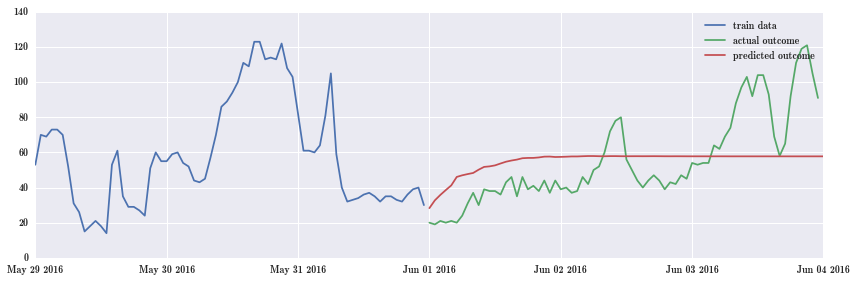
绿色是 6 月份真实值,红色是预测值。预测效果太差了!有待仔细检查。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号