Pandas 练习题
1. 使用 pandas 中的函数,下载上证综指过去一段时间的数据,进行数据探索。
上证综指,全称是上海证券综合指数,是以上证所挂牌上市的全部股票为计算范围,以发行量为权数的加权综合股价指数。这一指数自1991年7月15日起开始实时发布,基日定为1990年12月19日,基日指数定为100点。
以上证综指等为核心的上证指数体系,科学表征上海证券市场层次丰富、行业广泛、品种拓展的市场结构和变化特征,便于市场参与者的多维度分析,增强样本企业知名度,引导市场资金的合理配置。
因为上综指包括全部上海证券交易所的股票,而且它编制时间很长,所以在股民中影响较大。大盘一般就是指上证综合指数。
Pandas 提供了远程访问财经数据的多个网络源接口,包括:
- Yahoo! Finance
- Google Finance
- St.Louis FED (FRED)
- Kenneth French’s data library
- World Bank
- Google Analytics
这里我们选择雅虎财经。先载入要用到的包。
!pip install pandas_datareader
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from datetime import datetime
from pandas_datareader import data, wb # 需要先安装 pandas_datareader
数据获取
下载上证综指 2015 年 1 月 1 日到 2016 年 5 月 27 日的数据。沪市股票为「股票代码.ss」,深市股票为「股票代码.sz」。如上证指数为「000001.ss」,深证指数为「399001.sz」。
start = datetime(2015, 1, 1)
end = datetime(2016, 5, 27)
sc = data.DataReader("000001.SS", 'yahoo', start, end) # 000001.SS 表示上证综指,返回 DataFrame
sc.head() # 纵轴是日期,横轴是开盘价、最高价、最低价、收盘价、成交量、复权收盘价。因上证综指并非具体某支股票,所以交易量为 0。
| Open | High | Low | Close | Volume | Adj Close | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2015-01-05 | 3350.52 | 3350.52 | 3350.52 | 3350.52 | 0 | 3350.52 |
| 2015-01-06 | 3351.45 | 3351.45 | 3351.45 | 3351.45 | 0 | 3351.45 |
| 2015-01-07 | 3373.95 | 3373.95 | 3373.95 | 3373.95 | 0 | 3373.95 |
| 2015-01-08 | 3293.46 | 3293.46 | 3293.46 | 3293.46 | 0 | 3293.46 |
| 2015-01-09 | 3285.41 | 3285.41 | 3285.41 | 3285.41 | 0 | 3285.41 |
sc.info() # 数据质量很好,没有空值
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 326 entries, 2015-01-05 to 2016-05-27
Data columns (total 6 columns):
Open 326 non-null float64
High 326 non-null float64
Low 326 non-null float64
Close 326 non-null float64
Volume 326 non-null int64
Adj Close 326 non-null float64
dtypes: float64(5), int64(1)
memory usage: 17.8 KB
sc.describe() # 数据概览,共有 326 个上证综指的股价数据
| Open | High | Low | Close | Volume | Adj Close | |
|---|---|---|---|---|---|---|
| count | 326.000000 | 326.000000 | 326.000000 | 326.000000 | 326.0 | 326.000000 |
| mean | 3505.384049 | 3505.384049 | 3505.384049 | 3505.384049 | 0.0 | 3505.384049 |
| std | 591.216168 | 591.216168 | 591.216168 | 591.216168 | 0.0 | 591.216168 |
| min | 2655.660000 | 2655.660000 | 2655.660000 | 2655.660000 | 0.0 | 2655.660000 |
| 25% | 3019.815000 | 3019.815000 | 3019.815000 | 3019.815000 | 0.0 | 3019.815000 |
| 50% | 3365.290000 | 3365.290000 | 3365.290000 | 3365.290000 | 0.0 | 3365.290000 |
| 75% | 3792.875000 | 3792.875000 | 3792.875000 | 3792.875000 | 0.0 | 3792.875000 |
| max | 5166.350000 | 5166.350000 | 5166.350000 | 5166.350000 | 0.0 | 5166.350000 |
如果觉得在线获取数据的方式不保险,也可直接在浏览器地址栏输入网址下载 csv 文件,如 http://table.finance.yahoo.com/table.csv?s=000001.SS ,然后再读取到 DataFrame,设置 Date 为 index,并过滤,一样的效果。
sc1 = pd.read_csv('000001ss.csv') # 000001ss.csv 包含了上证综指从 1990-12-19 至今的数据
sc1 = sc1.set_index("Date") # 用 Date 来作为索引
sc1 = sc1.sort_index() # 根据 Date 来排序
sc1 = sc1["2015-01-01":"2016-05-27"] # 根据日期过滤
print(sc1.head())
print(sc1.describe()) # 可以看到跟上面在线读取的 sc 效果等同
Open High Low Close Volume Adj Close
Date
2015-01-05 3350.52 3350.52 3350.52 3350.52 0 3350.52
2015-01-06 3351.45 3351.45 3351.45 3351.45 0 3351.45
2015-01-07 3373.95 3373.95 3373.95 3373.95 0 3373.95
2015-01-08 3293.46 3293.46 3293.46 3293.46 0 3293.46
2015-01-09 3285.41 3285.41 3285.41 3285.41 0 3285.41
Open High Low Close Volume Adj Close
count 326.000000 326.000000 326.000000 326.000000 326.0 326.000000
mean 3505.384049 3505.384049 3505.384049 3505.384049 0.0 3505.384049
std 591.216168 591.216168 591.216168 591.216168 0.0 591.216168
min 2655.660000 2655.660000 2655.660000 2655.660000 0.0 2655.660000
25% 3019.815000 3019.815000 3019.815000 3019.815000 0.0 3019.815000
50% 3365.290000 3365.290000 3365.290000 3365.290000 0.0 3365.290000
75% 3792.875000 3792.875000 3792.875000 3792.875000 0.0 3792.875000
max 5166.350000 5166.350000 5166.350000 5166.350000 0.0 5166.350000
数据清理
上证综指并非具体股票,所以交易量 Volume 为 0,在对上证综指的分析中,该字段无效,所以先删除该数据。
sc = sc.drop('Volume',axis=1)
sc.head(2)
| Open | High | Low | Close | Adj Close | |
|---|---|---|---|---|---|
| Date | |||||
| 2015-01-05 | 3350.52 | 3350.52 | 3350.52 | 3350.52 | 3350.52 |
| 2015-01-06 | 3351.45 | 3351.45 | 3351.45 | 3351.45 | 3351.45 |
数据探索
绘图,看下上证综指这一年多的变化。
fig, ax = plt.subplots(1, 1, figsize=(12, 4))
sc.plot(ax=ax) # sc 有 5 列数据,自动使用 5 种不同的颜色画 5 条 line
fig.tight_layout();
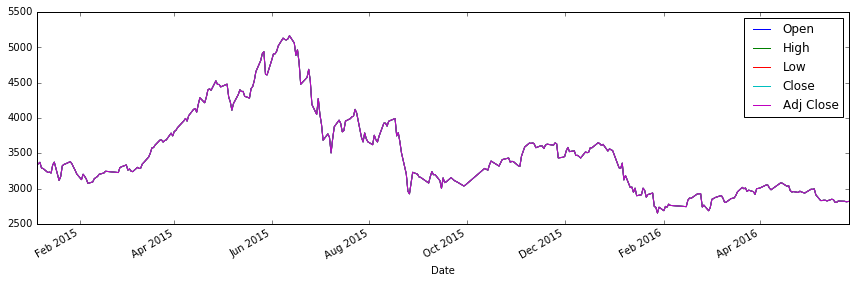
从上图的大盘走势可看出,股市在去年上半年的一连串上涨,及下半年的一连串暴跌,股市低迷持续至今。相信炒股的朋友对去年的股市印象深刻。
计算涨跌额,涨跌额是指当日股票价格与前一日收盘价格相比的涨跌数值。
change = sc.Close.diff()
change.iloc[0] = 0
sc['Change'] = change
sc.head(3)
| Open | High | Low | Close | Adj Close | Change | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2015-01-05 | 3350.52 | 3350.52 | 3350.52 | 3350.52 | 3350.52 | 0.00 |
| 2015-01-06 | 3351.45 | 3351.45 | 3351.45 | 3351.45 | 3351.45 | 0.93 |
| 2015-01-07 | 3373.95 | 3373.95 | 3373.95 | 3373.95 | 3373.95 | 22.50 |
pd.set_option('display.mpl_style', 'default')
fig, ax = plt.subplots(1, 1, figsize=(12, 4))
sc.Change.plot(ax=ax, kind='line', title='Rise and fall');
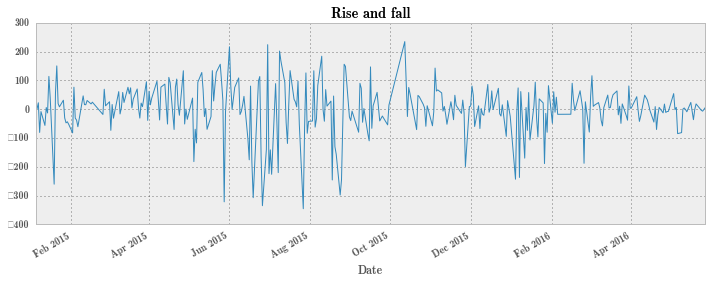
可以看出,上证综指在 6 月到 9 月间的剧烈波动。
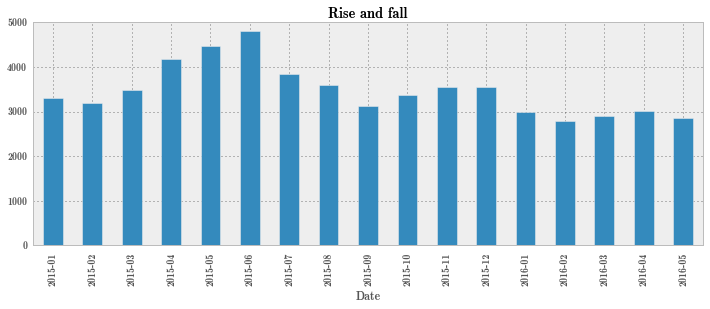
再来看下上证综指随月份的变化。
sc_month = sc.Close.to_period("M").groupby(level=0).mean()
sc_month.head()
Date
2015-01 3293.873000
2015-02 3186.547333
2015-03 3483.941364
2015-04 4186.230952
2015-05 4467.845000
Freq: M, Name: Close, dtype: float64
pd.set_option('display.mpl_style', 'default')
fig, ax = plt.subplots(1, 1, figsize=(12, 4))
sc_month.plot(ax=ax, kind='bar', title='Rise and fall');
** 2. 将中国地震台网最近一周的地震数据抓取下来,分析你感兴趣的分析点。 **
Pandas 提供了 pandas.read_html 函数会读取 HTML tables 到 DataFrame 对象的 list 中。
使用 pandas.read_html 抓取数据之前,需要先安装 html5lib、lxml 和 beautifulsoup。前两个使用 pip install 安装即可,而 beautifulsoup 的安装如 @lyltj2010 同学所说需要指定版本:pip install beautifulsoup4==4.0.5,如果已经安装了其它版本,先 pip uninstall beautifulsoup4 卸载再重新安装。
抓取数据
import pandas as pd
url = 'http://data.earthquake.cn/datashare/globeEarthquake_csn.html'
eqs = pd.read_html(io=url,header=0,encoding='gb2312') # encoding 是通过查看网页源代码中的 charset 值得到
eqs[4].head() # 该页面有 4 个大 table,但只有第 4 个才是我们需要的地震数据表格
| 发震日期 | 发震时刻 | 纬度(°) | 经度(°) | 深度(km) | 震级 | 事件类型 | 参考地点 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2016-05-29 | 10:14:37.7 | 31.5 | 104.3 | 13 | Ms4.3 | 天然地震 | 四川绵阳市安县 |
| 1 | 2016-05-28 | 17:47:00.9 | -56.2 | -27.1 | 70 | Ms7.2 | 天然地震 | 南桑威奇群岛地区 |
| 2 | 2016-05-28 | 17:39:03.8 | 27.5 | 85.1 | 8 | Ms4.2 | 天然地震 | 尼泊尔 |
| 3 | 2016-05-28 | 13:38:49.0 | -22.0 | -178.2 | 400 | Ms6.5 | 天然地震 | 斐济群岛地区 |
| 4 | 2016-05-28 | 03:08:14.1 | 36.3 | 78.0 | 91 | Ms3.2 | 天然地震 | 新疆和田地区皮山县 |
上面抓取数据的代码很简洁,但需要查看网页源代码才能得到编码的做法使得代码不够通用,毕竟换个页面又要去查看页面 charset,@lyltj2010 同学提供的代码就很通用,非常值得学习。
url = 'http://data.earthquake.cn/datashare/globeEarthquake_csn.html'
html = requests.get(url)
html.encoding = html.apparent_encoding
html_text = html.text
dfs = pd.read_html(html_text,header=0) # 返回的是一个 list,list里是表格
dfs[4].head()
| 发震日期 | 发震时刻 | 纬度(°) | 经度(°) | 深度(km) | 震级 | 事件类型 | 参考地点 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2016-05-28 | 17:47:00.9 | -56.20 | -27.10 | 70 | Ms7.2 | 天然地震 | 南桑威奇群岛地区 |
| 1 | 2016-05-28 | 17:39:03.8 | 27.50 | 85.10 | 8 | Ms4.2 | 天然地震 | 尼泊尔 |
| 2 | 2016-05-28 | 13:38:49.0 | -22.00 | -178.20 | 400 | Ms6.5 | 天然地震 | 斐济群岛地区 |
| 3 | 2016-05-28 | 03:08:14.1 | 36.30 | 78.00 | 91 | Ms3.2 | 天然地震 | 新疆和田地区皮山县 |
| 4 | 2016-05-27 | 23:06:33.2 | 39.85 | 98.82 | 15 | ML1.2 | 天然地震 | 甘肃酒泉 |
eq = eqs[4]
type(eq) # 地震数据表格转成了一个 DataFrame
pandas.core.frame.DataFrame
数据整理
eq.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 932 entries, 0 to 931
Data columns (total 8 columns):
发震日期 932 non-null object
发震时刻 932 non-null object
纬度(°) 932 non-null float64
经度(°) 932 non-null float64
深度(km) 932 non-null int64
震级 932 non-null object
事件类型 932 non-null object
参考地点 932 non-null object
dtypes: float64(2), int64(1), object(5)
memory usage: 58.3+ KB
可以看到,数据比较干净,没有 null 数据。为方便操作,先修改列名为英文单词。
eq.columns=['Date','Time','Latitude','Longitude','Depth','Magnitude','EventType','Place'] # 修改列名
eq.head()
| Date | Time | Latitude | Longitude | Depth | Magnitude | EventType | Place | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2016-05-29 | 10:14:37.7 | 31.5 | 104.3 | 13 | Ms4.3 | 天然地震 | 四川绵阳市安县 |
| 1 | 2016-05-28 | 17:47:00.9 | -56.2 | -27.1 | 70 | Ms7.2 | 天然地震 | 南桑威奇群岛地区 |
| 2 | 2016-05-28 | 17:39:03.8 | 27.5 | 85.1 | 8 | Ms4.2 | 天然地震 | 尼泊尔 |
| 3 | 2016-05-28 | 13:38:49.0 | -22.0 | -178.2 | 400 | Ms6.5 | 天然地震 | 斐济群岛地区 |
| 4 | 2016-05-28 | 03:08:14.1 | 36.3 | 78.0 | 91 | Ms3.2 | 天然地震 | 新疆和田地区皮山县 |
把发震日期和发震时刻合并转成 datetime 格式,并设为 index。
# 清理时间数据,把时间转换成datetime64认可的形式
eq['Time'] = eq['Time'].map(lambda x : x[0:8])
eq['Datetime'] = eq['Date']+' '+eq['Time']
eq.head()
| Date | Time | Latitude | Longitude | Depth | Magnitude | EventType | Place | Datetime | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2016-05-29 | 10:14:37 | 31.5 | 104.3 | 13 | Ms4.3 | 天然地震 | 四川绵阳市安县 | 2016-05-29 10:14:37 |
| 1 | 2016-05-28 | 17:47:00 | -56.2 | -27.1 | 70 | Ms7.2 | 天然地震 | 南桑威奇群岛地区 | 2016-05-28 17:47:00 |
| 2 | 2016-05-28 | 17:39:03 | 27.5 | 85.1 | 8 | Ms4.2 | 天然地震 | 尼泊尔 | 2016-05-28 17:39:03 |
| 3 | 2016-05-28 | 13:38:49 | -22.0 | -178.2 | 400 | Ms6.5 | 天然地震 | 斐济群岛地区 | 2016-05-28 13:38:49 |
| 4 | 2016-05-28 | 03:08:14 | 36.3 | 78.0 | 91 | Ms3.2 | 天然地震 | 新疆和田地区皮山县 | 2016-05-28 03:08:14 |
eq.Datetime = pd.to_datetime(eq.Datetime) # to_datetime 方法可以解析多种不同的日期表示形式
eq.Datetime[0] # 转换成功
Timestamp('2016-05-29 10:14:37')
eq = eq.drop('Date',axis=1) # 可以去除掉 Date 和 Time 列了
eq = eq.drop('Time',axis=1)
eq = eq.set_index("Datetime") # 设置 Datetime 为 index
eq = eq.sort_index() # 根据 Datetime 来排序
eq.head()
| Latitude | Longitude | Depth | Magnitude | EventType | Place | |
|---|---|---|---|---|---|---|
| Datetime | ||||||
| 2016-05-23 00:24:16 | 27.12 | 102.96 | 6 | ML2.1 | 天然地震 | 云南巧家 |
| 2016-05-23 00:43:46 | 35.69 | 111.40 | 13 | ML1.5 | 天然地震 | 山西侯马 |
| 2016-05-23 00:48:15 | 30.35 | 102.93 | 14 | ML1.0 | 天然地震 | 四川宝兴 |
| 2016-05-23 00:50:55 | 26.08 | 99.56 | 10 | ML0.6 | 天然地震 | 云南洱源 |
| 2016-05-23 01:11:00 | 23.24 | 117.27 | 13 | ML1.0 | 天然地震 | 广东南澳海域 |
参考地点 Place 的具体地址并不重要,经纬度已经能够给出详细信息,不过 Place 的省份信息可以用来统计最近一周各省的地震频次。所以这里对 Place 字段做下处理。
eq['Place'] = eq['Place'].map(lambda x : x[0:2])
eq.head()
| Latitude | Longitude | Depth | Magnitude | EventType | Place | |
|---|---|---|---|---|---|---|
| Datetime | ||||||
| 2016-05-23 00:24:16 | 27.12 | 102.96 | 6 | ML2.1 | 天然地震 | 云南 |
| 2016-05-23 00:43:46 | 35.69 | 111.40 | 13 | ML1.5 | 天然地震 | 山西 |
| 2016-05-23 00:48:15 | 30.35 | 102.93 | 14 | ML1.0 | 天然地震 | 四川 |
| 2016-05-23 00:50:55 | 26.08 | 99.56 | 10 | ML0.6 | 天然地震 | 云南 |
| 2016-05-23 01:11:00 | 23.24 | 117.27 | 13 | ML1.0 | 天然地震 | 广东 |
这样数据看起来就清爽多了。数据清理并非一步到位,在数据探索阶段也会根据需要随时对数据进行处理。现在就进入数据探索分析阶段。
数据探索分析
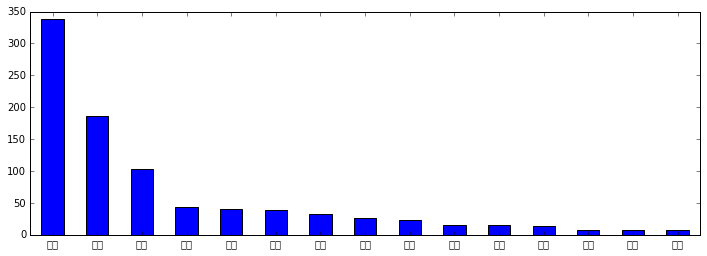
先来看下最近一周各省的地震频次。
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 1, figsize=(12, 4))
provinces = eq.Place.value_counts() # 计算各省的地震频次
provinces[0:15].plot(ax=ax, rot=0, kind='bar'); # 只看前 10 频繁的省份
图画出来了,但 x 轴的标签却是方块,因为 Matplotlib 默认不支持中文,所以这里需要一些额外设置。我用的这台机器是 ubuntu,先确认系统拥有的中文字体文件:
!fc-list :lang=zh
/usr/share/fonts/X11/misc/18x18ja.pcf.gz: Fixed:style=ja
/usr/share/fonts/truetype/droid/DroidSansFallbackFull.ttf: Droid Sans Fallback:style=Regular
/usr/share/fonts/X11/misc/18x18ko.pcf.gz: Fixed:style=ko
从中选择 Droid Sans Fallback 字体,在 python 脚本中手动加载中文字体。
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from matplotlib.ticker import MultipleLocator, FormatStrFormatter
font = FontProperties(fname='/usr/share/fonts/truetype/droid/DroidSansFallbackFull.ttf') # 加载系统拥有的 Droid Sans Fallback 字体
fig, ax = plt.subplots(1, 1, figsize=(12, 4))
provinces = eq.Place.value_counts() # 计算各省的地震频次
provinces[0:15].plot(ax=ax, rot=0, kind='bar') # 只看前 10 频繁的省份
for label in ax.get_xticklabels():
label.set_fontproperties(font)
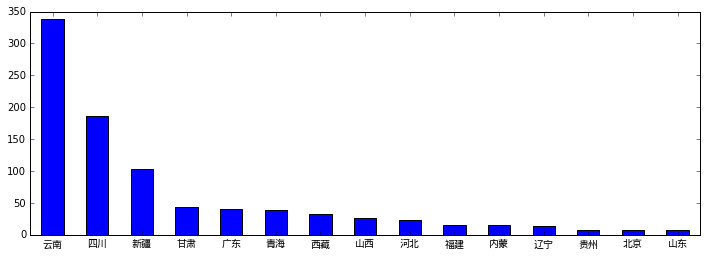
可以看出云南是地震大省,接着就是四川、新疆。这几个省都处于几个地震带上,所以地震比较频繁。
再来看下每天的频次统计。
fig, ax = plt.subplots(1, 1, figsize=(12, 4))
days = eq.index.to_period("D").value_counts()
days.plot(ax=ax, rot=0, kind='bar')
<matplotlib.axes._subplots.AxesSubplot at 0x7f6e0e74dd10>
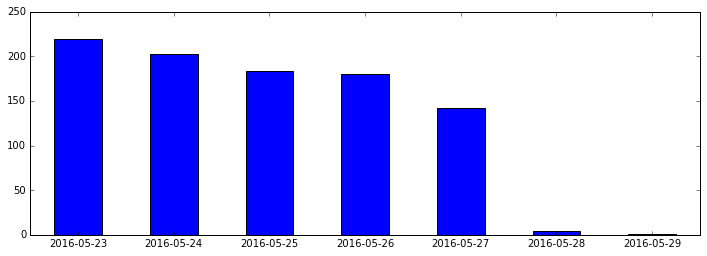
上图显示地震次数这七天是递减的,当然这不能说明任何问题,这七天在以往所有的日子里仅属于个案,还有可能是最近的地震还没来得及更新。
下面来绘制地震分布图,对最近的地震情况做一个更全面、直观的展现。
首先要安装 basemap。basemap 的官方安装文档看得我头皮发麻,安装这么麻烦,总觉得哪不对劲。pip install basemap 也不管用。后来看有人建议用 sudo apt-get install python-mpltoolkits.basemap 来安装,安装是成功了,但在使用时还是提示找不到 basemap……。后来找到了答案,就是执行下面的命令,因为我用的是 Anaconda,需执行 conda 命令来安装 basemap。
conda install basemap
from mpl_toolkits.basemap import Basemap
import numpy as np
Ms = eq.Magnitude.map(lambda x: not x.startswith('Ms')) # boolean Series
eq = eq[Ms]
import re
get_num = lambda x: float(re.findall('\d+\.\d+', x)[0])
temp = eq['Magnitude'].map(get_num)
eq.loc[:,('mag_num')] = temp
# 左下角
llcrnrlon, llcrnrlat = eq['Longitude'].min(), eq['Latitude'].min()
# 右上角
urcrnrlon, urcrnrlat = eq['Longitude'].max(), eq['Latitude'].max()
lons, lats = list(eq['Longitude']), list(eq['Latitude'])
lons1, lats1 = eq_map(lons, lats)
mags = eq['mag_num']
fig = plt.figure(figsize=(12,12))
ax = plt.subplot(1,1,1)
eq_map = Basemap(projection='merc', resolution = 'l', area_thresh = 1000.0,
lat_0=0, lon_0=120,
llcrnrlon=llcrnrlon-5, llcrnrlat=llcrnrlat-8,
urcrnrlon=urcrnrlon+10, urcrnrlat=urcrnrlat+3)
eq_map.drawmapboundary(fill_color='lightblue')
eq_map.drawcountries()
eq_map.drawcoastlines()
# 如不设置zorder=0,画图内容将无法显示
eq_map.fillcontinents(color='ivory',lake_color='lightslategrey',zorder=0)
eq_map.scatter(lons1, lats1,s=mags*50, c='Red',marker="o", alpha=0.7) # 画散点图
plt.title("Earthquake Info of China in near week", size=20)
plt.legend()
plt.show()
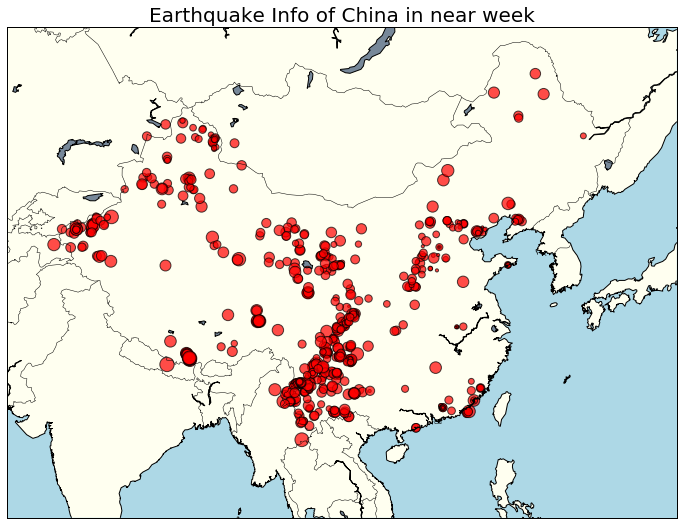
3. 基于 QQ 群的数据(qqdata.csv),分析你感兴趣的分析点。
读取数据
chats = pd.read_csv("qqdata.csv") #先读取 csv 文件到 DataFrame,默认文件中列之间用逗号分隔
chats.head() # 看头几行
| id | time | |
|---|---|---|
| 0 | 8cha0 | 2011/7/8 12:11:13 |
| 1 | 2cha061 | 2011/7/8 12:11:49 |
| 2 | 6cha437 | 2011/7/8 12:13:36 |
| 3 | 7cha1 | 2011/7/8 12:16:01 |
| 4 | 7cha1 | 2011/7/8 12:16:05 |
数据整理
chats.time = pd.to_datetime(chats.time) # to_datetime 方法可以解析多种不同的日期表示形式
chats = chats.set_index("time") # 设置 Datetime 为 index
chats = chats.sort_index() # 根据 Datetime 来排序
chats.head()
| id | |
|---|---|
| time | |
| 2011-07-08 12:11:13 | 8cha0 |
| 2011-07-08 12:11:49 | 2cha061 |
| 2011-07-08 12:13:36 | 6cha437 |
| 2011-07-08 12:16:01 | 7cha1 |
| 2011-07-08 12:16:05 | 7cha1 |
chats.tail()
| id | |
|---|---|
| time | |
| 2012-11-30 18:26:58 | acha@vip.qq.co |
| 2012-11-30 18:27:27 | 6cha437 |
| 2012-11-30 18:27:43 | 6cha437 |
| 2012-11-30 18:28:24 | 7cha1 |
| 2012-11-30 18:28:28 | 7cha1 |
chats.info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 11562 entries, 2011-07-08 12:11:13 to 2012-11-30 18:28:28
Data columns (total 1 columns):
id 11562 non-null object
dtypes: object(1)
memory usage: 180.7+ KB
可以看出,这个文件是从 2011 年 7 月 8 日中午 12 点到 2012 年 11 月 30 日傍晚 18 点半的一个群聊天记录文件,共有 11562 次发言,为保护隐私,这里没有聊天内容,只有聊天时间和聊天人,聊天人基本上都是做了处理,已经看不出真实名称。
数据探索分析
先来看下这一年多来都有谁在聊天,以及发言次数。
person_count = chats.id.value_counts() # 对 id 进行频次统计
person_count.describe()
count 144.000000
mean 80.291667
std 207.400659
min 1.000000
25% 2.750000
50% 10.000000
75% 56.500000
max 1511.000000
Name: id, dtype: float64
由上可见,这一年多来该群共有 144 人参与聊天,平均每人发言 80 次,最多的一个人发言 1511 次,最少的一个发言才 1 次,发言次数排最中间的人发言才 10 次,可见该群的聊天全员参与度不高,还是少数人在发言。
群活跃度随时间变化
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
# sr = pd.Series(chats.index.strftime('%Y-%m-%d')).value_counts() # 把聊天时间转成日期,即去掉具体时间,然后统计日期频次
sr = chats.resample('D').count() # 将数据聚合到规整的低频率,被称为降采样
fig, ax = plt.subplots(1, 1, figsize=(12, 4))
sr.plot(ax=ax, kind='line'); #
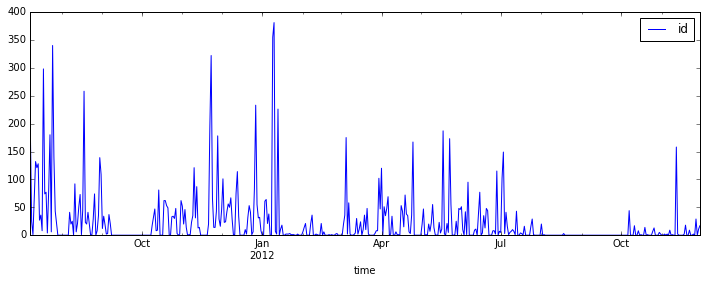
从上图可以看到几个聊天的高峰期。
前 15 大话唠
fig, ax = plt.subplots(1, 1, figsize=(12, 4))
person_count[0:15].plot(ax=ax, rot=90, kind='bar'); # 前 15 大话唠
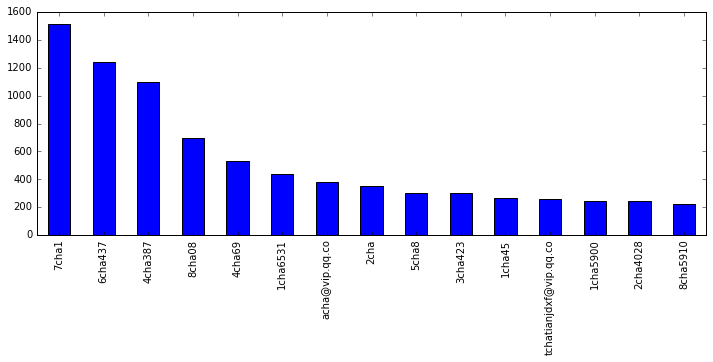
现在谁是话唠一目了然。
聊天兴致在一天中的分布
hours = pd.Series(chats.index.hour) # 从聊天时间中取出小时
hours_counts = hours.value_counts() # 统计每小时的发言频数,这里返回的 hours_counts 中只有有聊天的小时
hours_counts = hours_counts.sort_index() # 对小时排序
hc = pd.Series(np.zeros(24).astype('Int32').tolist()) # 这里生成了一天 24 个小时,为了显示完整的一天
hc[hours_counts.index]= hours_counts # 把有聊天记录的小时频数覆盖新生成的 Series
fig, ax = plt.subplots(1, 1, figsize=(12, 4))
hc.plot(ax=ax, rot=0, kind='bar'); # 画出完整的一天中的聊天频数
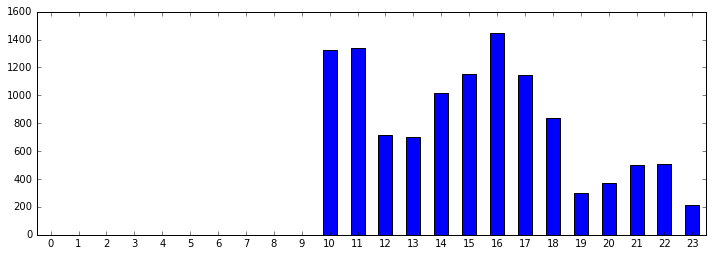
从上图可以看到该群聊天兴致在一天中的分布,聊天兴致最高的是上午 10、11 点和下午 16 点,在这两个小时达到顶峰,上午可能是快到饭点了,就聊兴大发,下午可能是 16 点工作累了,中途聊天休息下,然后又继续工作了。早上 8、9 点竟然没有人聊天,个人认为可能是数据有缺失,或者确实大家刚上班在认真工作。
聊天兴致在一星期中的分布
weeks = pd.Series(chats.index.weekday) # 聊天时间转为星期
weeks_counts = weeks.value_counts() # 统计一星期中每天的发言频数
weeks_counts = weeks_counts.sort_index() # 从周一到周日
weeks_counts = pd.Series(weeks_counts, index=[1, 2, 3, 4, 5, 6, 7]) # 因为原 weeks_counts 中是从 0 到 6,其实应是星期一到星期天
fig, ax = plt.subplots(1, 1, figsize=(12, 4))
weeks_counts.plot(ax=ax, rot=0, kind='bar'); # 画出完整的一天中的聊天频数
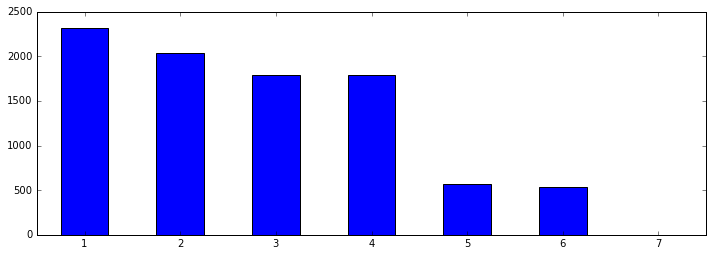
可以看出,该群的聊天兴致从周一到周日是逐日下降的,周一最精神,周二周三略冷却,周四保持,周五周六话就比较少。
寻找聊友
所谓聊友,就是经常在一块聊天的人。这里我们定义 1 分钟之内的聊天算一个对话,聊友就是对话次数比较多的人。
perids = chats.id.value_counts() # 统计 id 频次
percount = perids.count() # id 个数
perarr = np.zeros((percount, percount)).astype('Int32') # 生成个长宽都为 id 个数的矩阵
perdf = pd.DataFrame(perarr, columns=perids.index.values.tolist(), index=perids.index.values.tolist()) # 矩阵生成数据框
# 这里 perdf 是个人物数据框,存储的是任意两个人的对话次数
chatcount = chats.count().id # 聊天记录数
interval = 1 # 如果间隔小于 1 分钟,就认为是一次对话
for i in range(1, chatcount): # 遍历所有的发言
diffseconds = (chats.index[i]-chats.index[i-1]).seconds; # 计算每次发言跟上一个发言的间隔,这里只能取秒数,再除以 60 就有分钟了
diffminutes = diffseconds/60;
if(diffminutes<interval): # 对话间隔小于 1 分钟的则认为这两个人有 1 次对话
perdf[chats.id[i]][chats.id[i-1]]+=1 # 对话次数加 1
perdf[chats.id[i-1]][chats.id[i]]+=1
perdf.head() # 每个 id 跟其它 id 的对话次数就都存在这个数据框里了
| 7cha1 | 6cha437 | 4cha387 | 8cha08 | 4cha69 | 1cha6531 | acha@vip.qq.co | 2cha | 5cha8 | 3cha423 | ... | wchajbewwtkbx@qq.co | 3cha2320 | 2cha4365 | 8cha2638 | wchaaster@socd.ne | )chailed (104: Connection reset by pee | 4cha9992 | nchaquzhgx@qq.co | 1cha76447 | 6cha555 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 7cha1 | 1214 | 286 | 237 | 34 | 65 | 33 | 75 | 74 | 84 | 40 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6cha437 | 286 | 568 | 238 | 32 | 90 | 24 | 59 | 18 | 22 | 54 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 4cha387 | 237 | 238 | 492 | 22 | 38 | 4 | 33 | 41 | 16 | 25 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 8cha08 | 34 | 32 | 22 | 364 | 98 | 106 | 42 | 65 | 4 | 13 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4cha69 | 65 | 90 | 38 | 98 | 158 | 21 | 25 | 7 | 15 | 25 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 144 columns
比如我们要查看该群第一话唠(该文中话唠仅指发言次数多,并无贬义)的十大聊友。
perdf['7cha1'].sort_values(ascending=False)[1:11]
6cha437 286
4cha387 237
5cha8 84
acha@vip.qq.co 75
2cha 74
4cha69 65
1cha5900 42
3cha423 40
2cha4028 34
8cha08 34
Name: 7cha1, dtype: int32

 浙公网安备 33010602011771号
浙公网安备 33010602011771号