
在阿里云上搭建 Spark 实验平台
之前在自己的笔记本上运行 Python 代码,有些要运行一天多,一关机就前功尽弃,很不方便,所以才有租用阿里云服务器的想法,用了同学租的一台用了两天又觉得不够使,索性就自己租了三台,配置如下,三台一共约 320 块。
CPU: 1核
内存: 2048 MB
操作系统: Ubuntu 14.04 64位
带宽计费方式: 按固定带宽
当前使用带宽: 1Mbps
实例规格: ecs.s1.small
实例规格族: 标准型 s1
我们使用开源免费软件 PuTTY 连接到三台服务器上进行 Spark 的配置。
1、修改主机名
用 vi 打开 etc/hostname,三台服务器的主机名依次修改为 master、slave1 和 slave2。
# vi /etc/hostname
2、配置 hosts 文档
# vi /etc/hosts
在 hosts 文件中添加三台服务器的 IP 地址和对应的主机名。
120.56.121.132 master
120.35.219.36 slave1
120.45.201.137 slave2
配置之后 ping 一下用户名看是否生效
# ping master # ping slave1 # ping slave2
3、关闭防火墙
# sudo ufw disable
4、配置 SSH 无密码通信
# sudo apt-get install openssh-server # sudo apt-get update # ssh-keygen -t rsa -P "" //提示选择目录时,按 Enter 键,那么 id_rsa 和 id_rsa.pub 会生成到 root/.ssh 目录下。在根目录下使用 ls -a 命令可以看到该目录。
在三台服务器上执行:cd root/.ssh,cat id_rsa.pub>>authorized_keys,将 id_rsa.pub 追加到 authorized_keys。
将 slave1 和 slave2 的 id_rsa.pub 拷贝到 master(传输文件可用 scp),并将其内容追加到 master 的 root/.ssh/authorized_keys 中。同理,将 slave1 和 master 的 id_rsa.pub 追加到 slave2 的 authorized_keys,将 slave2 和 master 的 id_rsa.pub 追加到 slave1 的 authorized_keys。
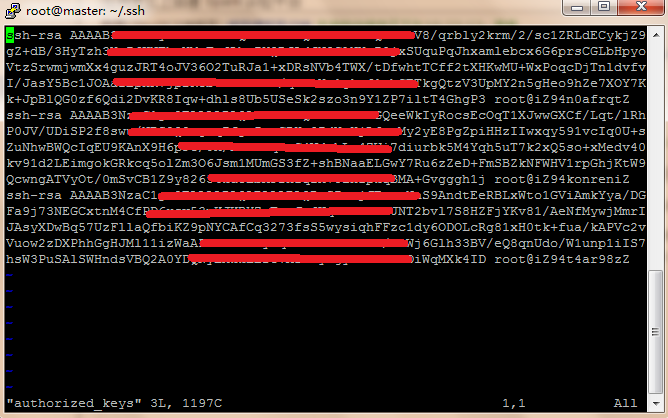
验证SSH无密码通信
ssh master
ssh slave1
ssh slave2
5、安装 JDK
在 JDK 官网下载 jdk-8u77-linux-x64.tar.gz。在 windows 7 下使用 Xftp 把该 JDK 文件传到三台云服务器的 /usr/local/java 下,解压。
# cd /usr/local/java # sudo tar xzvf jdk-8u77-linux-x64.tar.gz
然后,编辑 ~/.bashrc 文件,在文件最后添加:
export JAVA_HOME=/usr/local/java/jdk1.8.0_77 export JRE_HOME=/usr/local/java/jdk1.8.0_77/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$JAVA_HOME:$PATH export JDK_HOME=/usr/local/java/jdk1.8.0_77
为了使修改生效,执行:
# source ~/.bashrc
检验 JDK 是否安装成功
# java -version
6、安装 Scala
下载 scala-2.11.8.tgz,解压到 /usr/local 文件夹,并将文件夹改名为 scala。
# tar xvzf scala-2.11.8.tgz # ln -s scala-2.11.8 scala
打开 ~/.bashrc,添加
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
7、安装 Spark
下载 spark-1.6.1-bin-hadoop2.6.tgz,解压到 /usr/local 文件夹,并将文件夹改名为 spark。
# tar xvzf spark-1.6.1-bin-hadoop2.6.tgz # ln -s spark-1.6.1-bin-hadoop2.6 spark
修改配置文件 /usr/local/spark/conf 中:
# mv spark-env.template spark-env.sh # mv log4j.properties.template log4j.properties # mv slaves.template slaves
在 spark-env.sh 结尾添加
export SCALA_HOME=/usr/local/scala
修改 slaves 文件
master
slave1
slave2
打开 ~/.bashrc,添加
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
为了使 .bashrc 修改生效,执行:
# source ~/.bashrc
8、启动 Spark 集群
# start-all.sh //因为上面的 .bashrc 文件中配置了 usr/local/spark/sbin 路径,所以这里可直接执行
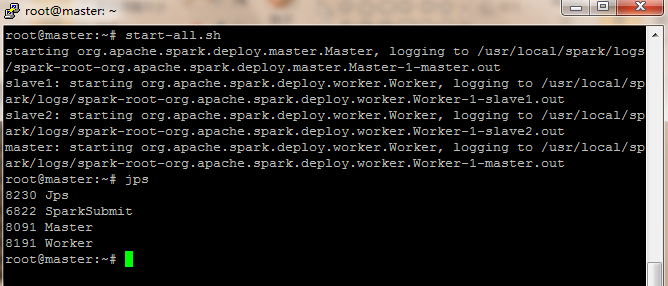
输入 # jps 命令看 master 下是否出现 master 和 worker,在 slave 节点下是否出现 worker,出现则说明 Spark 集群启动成功。


9、运行 Spark 实例
# run-example SparkPi 10
然后出来一大串的运行信息,其中有运行结果。
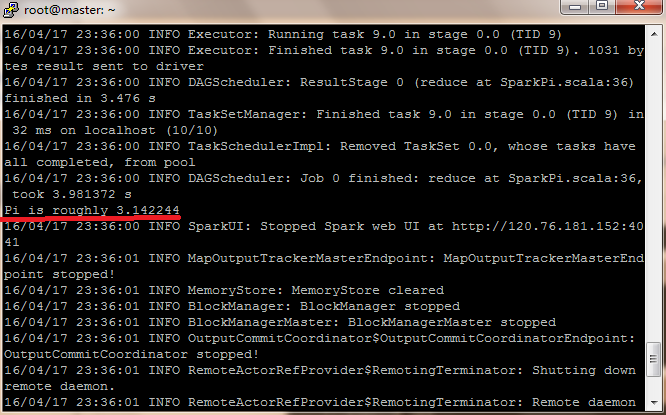
10、调整日志级别
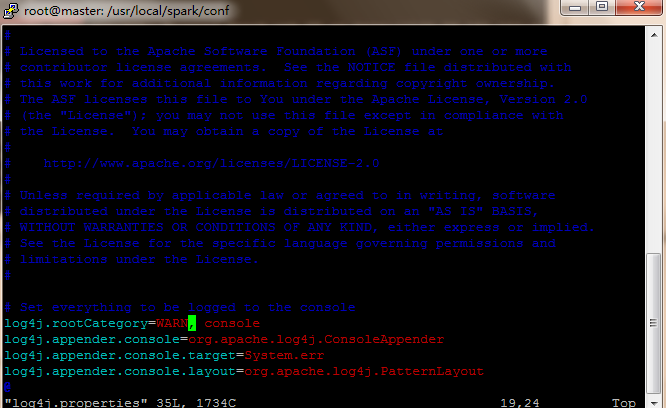
为了减少信息干扰,可以调整日志级别,修改 spark/conf/log4j.properties,把 log4j.rootCategory=INFO,console 改为 log4j.rootCategory=WARN,console
然后再运行
# run-example SparkPi 10
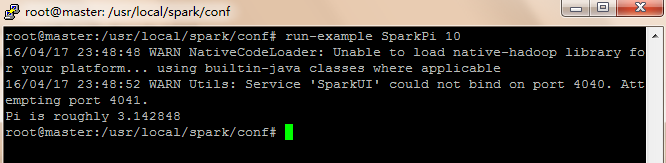
可以看到结果清爽多了。
但对于初学者来说,INFO 也是很有参考价值的,所以,建议把日志级别调整为 INFO。
完毕。
参考资料:
1、http://www.mak-blog.com/spark-on-yarn-setup-multinode.html
2、张丹阳, 曹维焯, 薛志云,等. 阿里云实现Spark的分布式计算[J]. 福建电脑, 2015(2):23-24.

