Beta——事后分析
事后总结
NameNotFound 团队
| 项目 | 内容 |
|---|---|
| 北航-2020-软件工程(春季学期) | 班级博客 |
| 要求 | Beta事后分析 |
| 课程目标 | 通过团队合作完成一个软件项目的开发 |
会议截图
一、设想和目标
软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述?
我们的软件要解决的是两个问题:
-
表单数据的生成
在各类表单识别和OCR服务的机器学习模型中,训练数据占据很重要的地位。而真实表单中数据往往涉及用户隐私,不能直接使用,因此需要花费大量的资金和人力伪造一些与真实表单各个字段值相近的“虚假”表单作为训练数据。我们希望能够设计一个表单数据自动化生成工具,它能根据用户提供的空白表单和表单中各个字段的生成要求,自动随机生成多个满足用户要求的标注好的高质量表单,作为训练数据以供各个表单识别项目开发者使用,从而节省花费在训练数据上的人力物力。
-
自动化处理大量表单
微软原项目Fott项目使用认知服务来识别表单。我们基于Alpha阶段的数据生成,进一步把模型训练和使用结合起来,使整个软件有一个完整的流程,即:上传->标注->数据生成->模型训练->表单处理。
基于以上的流程,我们的软件支持用户批量处理同类表单,解决手工处理的麻烦。同时,为了方便用户使用处理结果,我们对处理结果进行了整理,支持结果导出为Excel文件,并且设计了可视化展示的接口,方便用户直观的观察数据。
关于典型用户和典型场景的描述见Beta项目展示
我们达到目标了么(原计划的功能做到了几个? 按照原计划交付时间交付了么? 原计划达到的用户数量达到了么?)
原计划的功能如下:
| 功能 | 详细描述 |
|---|---|
| introduction页面 | 增加项目描述和使用方法 |
| train页面 | 支持对生成好的页面进行一键训练;支持将训练得到的结果进行处理,生成Excel文件 |
| data页面 | 支持数据可视化查看 |
| tag页面 | 支持错误画出的框的删除 |
| model页面 | 支持历史模型的显示 |
| new project | 支持用户选择项目类型(空白训练;五张训练;根据Excel信息批量生成表单等) |
原计划的功能除了model页面没有实现,其他的功能均已实现。model页面是因为我们发现这一功能没有需求,所以放弃了这一功能。
我们按照计划交付了软件,并且进行了稳步的测试。
原计划的用户数量并没有达到,可能是以下几个原因:
- 我们的软件对于大家来说需求不是很明显,所以可能大家尝试的意愿不高
- 考虑到临近烤漆,大家都在复习,我们的软件对于复习没有帮助,所以不使用很正常
- 软件本身还是不够吸引人
和上一个阶段相比,团队软件工程的质量提高了么? 在什么地方有提高,具体提高了多少,如何衡量的?
和上一个阶段相比,我们认为团队的软件工程质量有所提高。
- 项目的计划:我们在Beta阶段进行了更详细的规划,冲刺的任务也提前明确
- 项目管理:将issue和commit关联起来,PM进行代码复审
- 成员任务分工:前后端分离,每日例会更新明天的任务
- 文档管理:将说明文档和技术文档都维护在GitHub的wiki页面
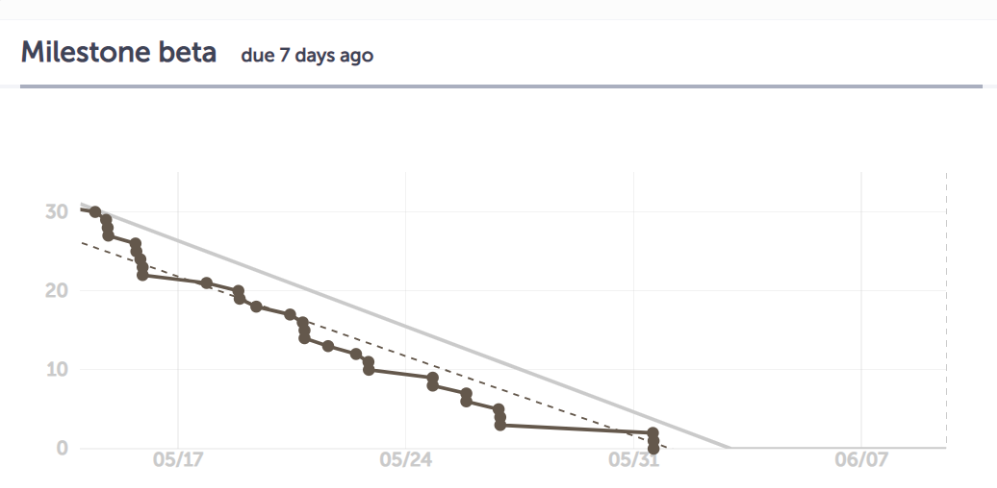
整个流程下来,我们的开发速度相比Alpha阶段有了很的提升,这一点在Beta阶段的燃尽图可以体现
燃尽图
用户量, 用户对重要功能的接受程度和我们事先的预想一致么? 我们离目标更近了么?
从用户的反馈来看,用户对于功能的整体还是比较满意,主要的问题可能是软件的使用速度存在一定的问题。这一点在项目展示进行了解释。
有什么经验教训? 如果历史重来一遍,我们会做什么改进?
如果重来,我们会选择自己构建后端服务器,而不是使用Azure的服务。因为Azure的服务在中国还是有一定的延迟。
二、计划
是否有充足的时间来做计划?
我们在Beta阶段是有比较充足的时间进行计划,包括功能以及项目管理等,也正是因为计划较为完善,所以开发速度有了很大的提升。
团队在计划阶段是如何解决同事们对于计划的不同意见的?
我们会就目前的技术和资源来衡量不同的意见,如果资源和技术可以满足,且时间允许,那么我们会投票接受意见。
如果是成员之间的意见不同,我们也是综合所有人的意见来衡量是否采纳。
你原计划的工作是否最后都做完了? 如果有没做完的,为什么?
原计划的工作基本都做完了,有一项 model页面 的计划并没有实现,这个是因为我们在开发阶段发现这一功能不视用于需求的,没有特别大的意义,所以没有实现。
有没有发现你做了一些事后看来没必要或没多大价值的事?
这个暂时没有,因为我们会在每日例会进行灵活的调整,没有做可能没有价值的任务。
是否每一项任务都有清楚定义和衡量的交付件?
是的,我们把所有的issue和commit都联合起来,在每日例会也详细描述了每个人每天的工作。
是否项目的整个过程都按照计划进行,项目出了什么意外?有什么风险是当时没有估计到的,为什么没有估计到?
整个过程基本都是按照计划来的,期间遇到过服务器无法正常使用,这个是因为微软的Azure服务存在一些小问题,是一开始没有预估到的。因为Alpha阶段没有遇到类似的问题,所以没有预估到这一问题。
在计划中有没有留下缓冲区,缓冲区有作用么?
计划中有留有一定的缓冲区。缓冲区是为了防止因为各种问题导致的项目进度推迟,实际的项目过程,缓冲区还是起到了一定的作用,我们本来计划的开发完成时间是早于冲刺结束时间的,结果是正好完成。这期间是服务器和技术都遇到了一些小问题。
将来的计划会做什么修改?
缓冲区确实应该在计划中考虑,以防出现意外情况导致项目进度被搁置;
如果按照当前计划无法在时间点完成,那么加班是有必要的。
我们学到了什么? 如果历史重来一遍,我们会做什么改进?
我们会在计划阶段进一步明确每个人的分工,并且让大家明白彼此工作之间的联系,结合结对开发的模式,两两组队开发。出现问题,PM尽快调控解决。
三、资源
我们有足够的资源来完成各项任务么?
资源方面,我们的服务器是zyc同学提供的,基本可以满足我们的项目需求;唯一的问题是账号资源,因为微软的Azure服务需要使用Visa卡才可以注册账号使用,我们只有一个账号,因此很多的功能其实都是进行了修改才能够让更多的人使用,尤其是认知服务的免费版本有次数限制,导致我们无法进行大规模的测试。
各项任务所需的时间和其他资源是如何估计的,精度如何?
任务的时间基本上是按照每个任务1-2天,然后在每日例会上进行调整;
除了几个维护的任务,开发任务基本上是在估计时间内的,还是比较准确。
测试的时间,人力和软件/硬件资源是否足够? 对于那些不需要编程的资源 (美工设计/文案)是否低估难度?
测试的时间较为充足,因为我们按照预期完成了开发。
人力资源和硬件资源足够。
一定程度上低估了难度,尤其是文档和博客等,需要描述的很多,耗费的时间很大。
你有没有感到你做的事情可以让别人来做?
Beta阶段我是转为了PM,整个流程下来,感觉PM首先要对项目有一个整体的了解,以及明确项目的方向,合理的分工,推进项目进度。这一工作,其他成员应该也可以胜任,只是需要花费一些时间熟悉。
有什么经验教训? 如果历史重来一遍,我们会做什么改进?
可能我们会选择采用自己搭建服务器的方式来构建前后端,这样消耗的资源也差不多,但是软件的整体性会更好,性能会有很大的改善。
四、变更管理
每个相关的员工都及时知道了变更的消息?
我们会在交流群及时通知各种消息,然后GitHub上也会对push等由邮件提醒。
我们采用了什么办法决定“推迟”和“必须实现”的功能?
民主集中制?😜
就是大家开会讨论某些功能是可以推迟的,某些功能是必须的,不能推迟。
这个我们在计划阶段就大概有个明确,所以实现的过程中很轻松的可以选择。
项目的出口条件(Exit Criteria – 什么叫“做好了”)有清晰的定义么?
由以下三部分组成:
- Beta阶段新功能实现
- 表单识别模型的训练
- 自动化训练模型
- 表单预测
- 表单预测结果自动化处理
- 数据结果可视化展示
- Alpha阶段功能完善
- 标注页面数据同步问题
- Introduction页面
- 回归测试+测试矩阵
对于可能的变更是否能制定应急计划?
我们认为是可以制定计划的,从我们Beta阶段的开发来看,中间是有进行过调整,修改计划。
一个团队的开发总是会遇到这种紧急情况,所以缓冲区是很有必要的。
员工是否能够有效地处理意料之外的工作请求?
经过Beta阶段的开发,我们有信息确认可以处理意料之外的工作请求。
我们学到了什么? 如果历史重来一遍,我们会做什么改进?
这方面可能暂时没有改进的地方。
五、设计/实现
设计工作在什么时候,由谁来完成的?是合适的时间,合适的人么?
设计工作是在每个阶段的开始一周。
由全部成员一起商讨,并且听取了zx老师的意见。
是合适的时间,而且借鉴了zx老师的意见,大家共同决定的软件方向,是合适的。
设计工作有没有碰到模棱两可的情况,团队是如何解决的?
有的,在解决自动识别的问题上,一开始遇到了很大的问题,不知道如何处理,甚至一度停滞,后来是我们连着两天开会,讨论这个问题,商讨了一个初步的解决方案,最后不断完善。
团队是否运用单元测试(unit test),测试驱动的开发(TDD)、UML, 或者其他工具来帮助设计和实现?这些工具有效么? 比较项目开始的 UML 文档和现在的状态有什么区别?这些区别如何产生的?是否要更新 UML 文档?
后端的开发时基于TDD进行的,采用Postman来进行测试,促进开发。TDD的开发很有效,个人感觉在一定程度上保证了代码逻辑的正确性以及快速开发。
前端进行单元测试。保证了函数的基本功能正确性。
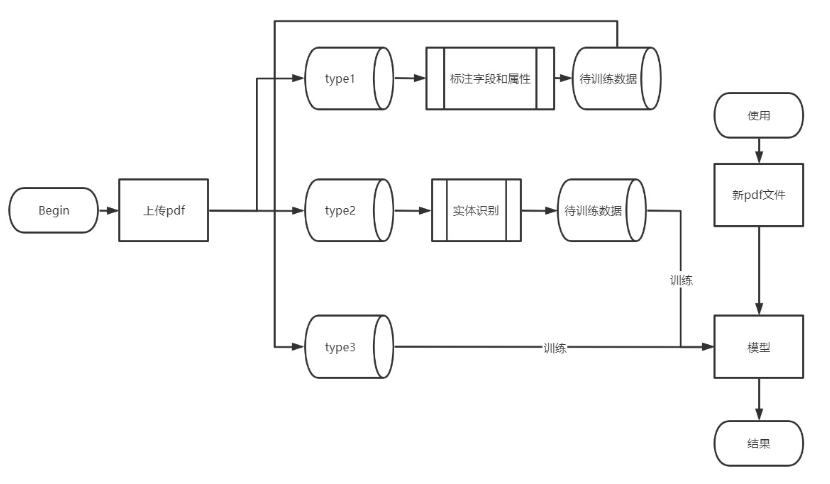
UML图在Beta阶段的开发过程中逐渐更新,最终确定为如下:
什么功能产生的Bug最多,为什么?在发布之后发现了什么重要的bug? 为什么我们在设计/开发的时候没有想到这些情况?
前端的tag页面,因为这一块涉及到数据同步,我们一开始没有重视这个问题,导致出现了很多的BUG。
发布后没有遇到重大的BUG。
代码复审(Code Review)是如何进行的,是否严格执行了代码规范?
前端是成员之间互相审查,之后合并分支,后端是PM审查,整理到代码中。这里并没有使用GitHub的pr,需要改进。
我们严格遵守了代码规范,前端遵守tslint,后端遵守pylint。
我们学到了什么? 如果历史重来一遍,我们会做什么改进?
我们会用GitHub的PR来进一步管理项目。
六、测试/发布
团队是否有一个测试计划?为什么没有?
有的,在开发阶段,没开发一个功能,都会去进行测试,完全开发完成后进行了验收测试。
是否进行了正式的验收测试?
有的,场景测试+回归测试+单元测试
见测试报告
团队是否有测试工具来帮助测试?
- 前端:一套自动化测试框架,支持TypeScript,React,可以生成覆盖率报告。
- 后端:Postman,TDD开发,支持自动化测试。
团队是如何测量并跟踪软件的效能(Performance)的?压力测试(Stress Test)呢? 从软件实际运行的结果来看,这些测试工作有用么?应该有哪些改进?
因为适用了Azure服务,微软的Azure面板提供了函数的检测,资源的使用情况,以及运行反馈,这样我们就可以监测软件的运行效能。
我们在发布前有进行压力测试,但是因为认知服务的资源问题,压力测试不算是很强力。
从实际的表现来看,我们也是发现了以下问题,比如tag页面的同步问题,以及创建项目时可能会出错。
改进的话,压力测试应该更强一点(资源允许的话)。
在发布的过程中发现了哪些意外问题?
发布后,服务器出现了不能使用的情况,是因为Azure服务发生了意外,不过这一问题很快解决了。
我们学到了什么? 如果重来一遍,我们会做什么改进?
重视单元测试,回归测试。整体的测试也是必不可少的。压力测试对于软件实际运行的效果很重要。
七、团队的角色,管理,合作
团队的每个角色是如何确定的,是不是人尽其才?
Beta阶段的定位基本上维持了Alpha阶段的分工,新成员顶替转会的成员的工作,负责前端的开发。目前来看应该算是人尽其才。
团队成员之间有互相帮助么?
有的,我在开发后端的服务器时,遇到了临时文件访问的问题,研究了很久没有解决,后来经过大佬的指导成功解决了此问题。
当出现项目管理、合作方面的问题时,团队成员如何解决问题?
我们会商讨这一任务是谁负责的,然后看能否解决,如果不能就让其他成员提供帮助,尽快解决。
每个成员明确公开地表示对成员帮助的感谢 :
| 成员 | 被感谢者 | 事情 |
|---|---|---|
| ly | 其他成员 | 感谢zyc帮助我解决内存访问的问题;感谢其他成员的辛苦付出! |
| zyc | ly,其他成员 | 感谢PM ly辛苦的推进项目,感谢所有成员的合作 |
| lzh | ly,zyc | 重点感谢pm小哥ly,他为项目整体设计规划和文档鞠躬尽瘁;以及前端伙伴zyc |
| dxy | ly,zyc | 感谢ly的帮助,和我讨论拼接字符的处理问题;感谢zyc的帮助,提供服务器 |
| wyk | 其他成员 | 作为前PM感谢大家的辛苦付出! |
| llj | 其他成员 | 感谢PM高效推进前后端对接,感谢大家的努力,有幸和大家一起见证了这个项目的成长👍 |
八、总结
你觉得团队目前的状态属于 CMM/CMMI 中的哪个档次?
我们目前应该是属于可重复级向已定义级过渡的阶段。
你觉得团队目前处于 萌芽/磨合/规范/创造 阶段的哪一个阶段?
我们目前处于规范的阶段,成员之间磨合的应该算是可以,主要是处于规范阶段。
你觉得团队在这个里程碑相比前一个里程碑有什么改进?
- 团队磨合:磨合得更好,整个团队的开发速度有了进一步的提升
- 项目管理:项目管理更加规范
- 交流沟通:成员之间交流更加频繁,相互之间能够理解
你觉得目前最需要改进的一个方面是什么?
应该是软件的代码管理方面,大家还是有些不适应使用GitHub,比如说Pull&Request的使用、commit的规范等等。
对照敏捷开发的原则, 你觉得你们小组做得最好的是哪几个原则? 请列出具体的事例。
敏捷开发原则7:可用的软件是衡量项目进展的主要指标。
- 我们在Beta阶段的目的就是把软件的完整性实现,成为一个可用的表单识别功能,而不仅仅是数据生成。
敏捷开发原则10:简明为本——它是极力简化不必要的工作量的技艺。
- 我们在开发的过程发现model页面并没有想象的那么有用,所以选择暂时简化,等之后再说。
- 我们在考虑如何实现自动处理时,选择先实现一个简化的版本,再根据需求逐步更迭优化。
敏捷开发原则12:时时总结如何提高团队效率并付诸行动。
- 我们会在每日例会上反思最近的不足,在后续的工作中改进。一开始有成员在GitHub规范上出现了问题,后续进一步加强了规范的遵守。
正如我们前面提到的, 软件的质量 = 程序的质量 + 软件工程的质量,那团队在下一阶段应该如何提高软件工程的质量呢?
代码管理的质量具体应该如何提高? 代码复审和代码规范的质量应该如何提高?
利用GitHub来进行代码管理。准备合理利用pull&request机制来进行代码复审,代码规范方面继续遵守之前的约定,同时写好文档和注释。
整个程序的架构如何具体提高? 如何通过重构等方法提高质量,如何衡量质量的提高?
前端可以把没有使用到的框架删除,后端迁移到自己的服务器上构建。
通过测试软件的使用速度以及流畅性来衡量性能的提高。
其它软件工具的应用,应该如何提高?
考虑到后续可能要把后端移植到服务器上,需要使用一些自动化测试用的软件。
项目管理有哪些具体的提高?
项目管理,我们考虑是否可以采用轮换的PM,来让大家都对项目有一个深刻的了解。
项目跟踪用户数据方面,计划要提高什么地方?例如你们是如何知道每日/周活跃用户等数据的?
用户数据方面,我们可以通过后端的控制台得知用户的数据以及每日/每周活跃用户。
这方面暂时的想法是开放一个反馈通道,收集用户的意见来进行调整。
直接利用用户的数据可能无法得到有效的信息。
项目文档的质量如何提高?
考虑使用自动化文档工具,规范代码书写,自动生成API文档。
软件的使用文档也需要进一步更新,争取做到简洁明了。
对于人的领导和管理, 有什么具体可以改进的地方? 请看《构建之法》关于PM、绩效考核的章节, 或者 《人件》等参考书
作为PM,我发现在最后整理的时候,绩效的考核有时很难量化,这一点在算团队成员贡献分的时候遇到了,可以进一步改进的点是可以把工作进一步的记录明确(可以使用任务管理工具并且与GitHub的issue同步),并且成员之间协定好不同任务的分数比重,最终计算的时候直接通过公式进行计算。
对于软件工程的理论,规律有什么心得体会或不同意见? 请看阅读作业。
理论方面看书的时候总是以为看懂了,但在开发过程中感觉很多地方还是做的不到位,回过头看,才能明白一些。比如说,我们在推广的是时候发现用户群体有一些不太适配学生,导致较难推广,这一点在计划阶段应该更认真的考虑,以及进行一些修正,可能就会好一些。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号