Beta-Scum meeting 2
Scrum meeting 2
5.15
会议截图:
会议记录
GitHub分支链接
| 成员 | 已完成 | 准备进行 |
|---|---|---|
| zyc | 项目选择类型,tag页面删除框,优化提示,删除项目API对接 | 完善前端工作 |
| lzh | train页面,tag页面优化(本地开发) | 训练 |
| ly | 后端删除API,后端上传PDF文件修改 | 实现 |
| dxy | PDF文件替换 | 新功能实现 |
| wyk | Json转换为excel | 可视化数据 |
| llj | 调研实体识别API用法 | python实现API调用 |
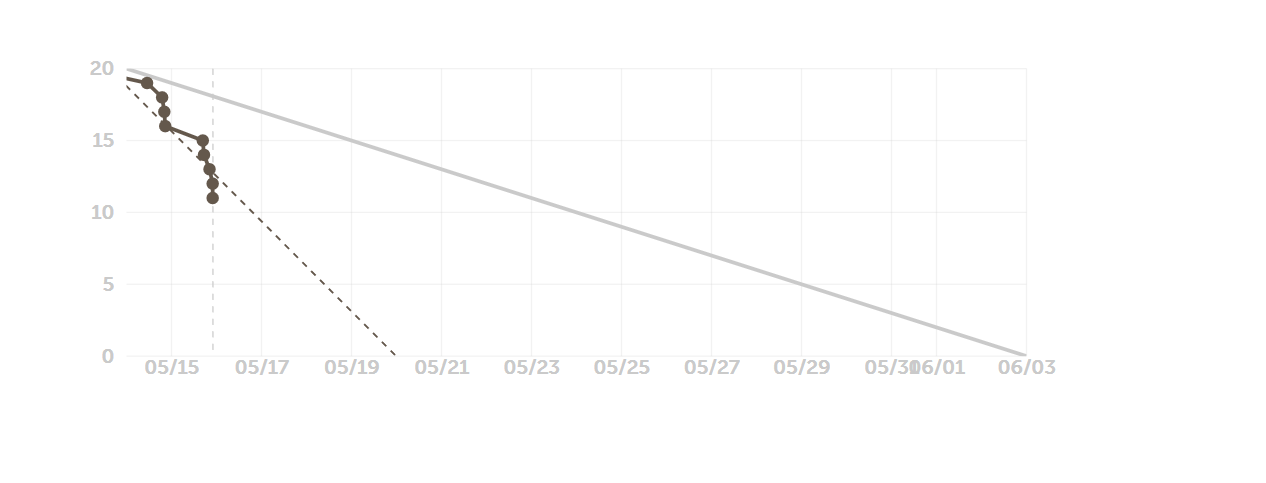
燃尽图
遇到的问题
-
前端的训练模块逻辑还不完整,需要修改生成的数据来适配
-
对用户上传的文档,如何实现实体识别?目前主要的问题是如何确定字段的组合以及位置,其中位置信息可以通过tables睡醒或者boundingbox属性来间接获得。字段的组合是主要问题,有两种思路:
- 用户标注一个范围框,这样根据范围组合识别,极大程度提高识别率
- 后端自动组合识别,猜测用户需要的字段,进行实体识别
-
可视化展示如何做?
- 地点数据分布图
- 年龄
- ...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号