
Java之基本数据类型
本文章分为四个部分:
1、基本数据类型的介绍
2、类型转换
3、装箱和拆箱
4、有道练习
5、增:编码的那点事儿
--------------------------------------基本数据类型的介绍--------------------------------------
Java有8种基本数据类型,其中有4种整型、2种浮点类型、1种用于表示Unicode编码的字符单元的字符类型char和1种用于表示真值的boolean类型。
|
类型 |
boolean |
char |
byte |
short |
int |
long |
float |
double |
|
存储需求(字节) |
1 |
2 |
1 |
2 |
4 |
8 |
4 |
8 |
1、boolean类型的取值范围有两个,true和false,用来判断逻辑条件。
并且整型值和布尔值之间不能进行相互转换。
2、char类型原本用于表示单个字符,不过现在有些Unicole字符可以用一个char值描述,另外一些Unicole字符可以用两个char值。
char类型的字面量值要用单引号括起来。
而且Unicode转义序列会在解析代码之前得到处理。
3、整型用于表示没有小数部分的数值,它允许是负数。
Java提供了4种整型:byte、short、int、long。
Java中是没有任何无符号(unsigned)形式的int、short、long或者byte类型的。
而且如果要表示长整形数据(long),后者要加上后缀L或者l。如果要表示二进制数,则加上前缀0B或者0b;如果要表示八进制数,则加上前缀0;如果要表示十六进制数,则加上前缀0X或者0x。
注意,byte的取值范围是:-128~127。
4、浮点类型用于表示有小数部分的数值。
在Java中有两种浮点类型 。
double表示这种类型的数据精度是float类型的两倍(双精度),绝大部分应用程序都采用double类型。
float类型的数值有一个后缀F或者f,没有后缀F的浮点数值默认为double类型。
可以用十六进制表示浮点数值。例如0.125=2-3可以表示为0x1.0p-3,在16进制表示法中,使用p表示指数,而不是e,而且尾数采用16进制,指数采用10进制。指数的基数是2,而不是10。
所有的浮点数值计算都遵循IEEE754规范,用于表示溢出和出错情况的三个特殊的浮点数值:正无穷大、负无穷大和NaN。
如果在数值计算中不允许有任何舍入误差,这个使用就应该使用BigDecimal类了。
--------------------------------------类型转换--------------------------------------
类型转换可分为两种,一种是自动类型转换、另一种是强制类型转换。
自动类型转换
自动类型转换我们可以比拟为是“一人得道鸡犬升天”。
假如我们在对两个数值进行二元操作,假如a是short类型的数值,b是int类型的数值,那么在进行计算的时候,a就会被转换为int类型,所以得到的结果也是int类型的数据。
sum = a+b;
所以我们可以知道,自动类型转换的方向是从低到高的,类似于:
byte->short->int->long
char->int->long
float->double
在这里,可能会有一个疑问,为什么short和char要分开出来写呢?它们不都是2个字节的吗?
原因是,short类型是有带符号的类型,也就是说它有一个符号位,但是char没有符号位,也就是说char和short类型虽然所占的内存大小一样,但是所表示的范围是不一样的(char的表示范围是0~2^16 - 1 (0 to 65535),short的表示范围是 -2^15 to 2^15 - 1 (−32,768 to 32,767))。
强制类型转换
强制类型转换就有点像是去菜市场菜贩子会“抹零头”那样,在Java中允许进行可能会丢失一些信息的类型转换,而这种情况就需要通过强制类型转换来实现。
强制类型转换的语法格式是在圆括号中给出想要转换的目标类型,后面紧跟待转换的变量名。如:
double d = 2.3333;
int i = (int)d;
不过如果试图将一个数值从一种类型强制转换成另一种类型,而又超出了目标类型的表示范围,结果就会截断成一个完全不同的值。
像是不要转成boolean类型或者是byte类型。
--------------------------------------装箱和拆箱--------------------------------------
装箱和拆箱
装箱和拆箱是一对相对的概念。
装箱就是指把基本类型用它们相应的引用类型包装起来,使其具有对象的性质。
拆箱就是把引用类型的对象简化成值类型的数据。
举个栗子:
Integer i = 10; //装箱
int n = i; //拆箱
用javap -v反编译一下就知道这两条语句对应的是不是装箱和拆箱了。
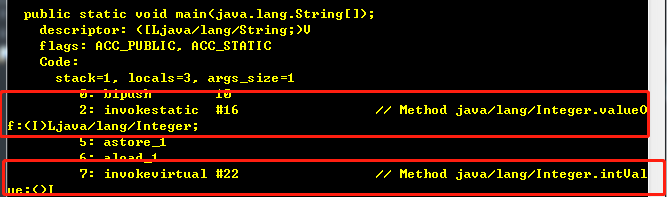
然后我们分别看一下,Integer.valueOf方法和Integer.intValue方法的源码:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
public int intValue() {
return value;
}
装箱的这个过程是不是有点熟悉?详情可以看一下我之前写的这篇笔记:https://www.cnblogs.com/NYfor2018/p/9482390.html
而拆箱的过程是简洁不加修饰,我们可以看到它的返回值直接就是int。
但,是不是那八种基本类型的装箱过程都是相似的呢?不是的,但是它们是跟前面的八种基本数据类型的分类情况是类似的,也就是Integer、Short、Long、Byte的装箱过程,Double和Float的装箱过程、Boolean的装箱过程和Character的装箱过程的分别类似的。
下面祭上源码:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
public static Long valueOf(long l) {
final int offset = 128;
if (l >= -128 && l <= 127) { // will cache
return LongCache.cache[(int)l + offset];
}
return new Long(l);
}
public static Short valueOf(short s) {
final int offset = 128;
int sAsInt = s;
if (sAsInt >= -128 && sAsInt <= 127) { // must cache
return ShortCache.cache[sAsInt + offset];
}
return new Short(s);
}
public static Byte valueOf(byte b) {
final int offset = 128;
return ByteCache.cache[(int)b + offset];
}
public static Double valueOf(double d) {
return new Double(d);
}
public static Float valueOf(float f) {
return new Float(f);
}
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}
public static Character valueOf(char c) {
if (c <= 127) { // must cache
return CharacterCache.cache[(int)c];
}
return new Character(c);
}
所以,在做有关于同种数据类型但是数值不一样的面试题的时候,要对症下药。
有关于基本数据类型的面试题可以看这篇文章,写的很不错:https://blog.csdn.net/u010539271/article/details/69668807
-------------------------------------有道面试题-------------------------------------
byte b1=1,b2=2,b3,b6; final byte b4=4,b5=6; b6=b4+b5; b3=(b1+b2);
System.out.println(b3+b6);
问题:这代码片段编译之后会出现什么情况?
答案:语句:b3=b1+b2编译出错
因为b4和b5已经声明是一个final常量了,所以它在进行运算的时候不会因为要运算而自动转化成int类型(int类型转换成byte需要强制转换,),因此会编译错误。
但是因为b4和b5在进行运算的时候不会自动转换成int类型,所以在进行b6=b4+b5语句的时候不会出现错误。
-------------------------------------编码那点事儿-------------------------------------
值得回去再看看的文章:
https://www.cnblogs.com/lslk89/p/6898526.html
https://www.cnblogs.com/deepblue775737449/p/7604738.html
https://www.cnblogs.com/web21/p/6092414.html
https://blog.csdn.net/guxiaonuan/article/details/78678043
参考:
《Java核心技术I》
https://www.cnblogs.com/dolphin0520/p/3780005.html
https://blog.csdn.net/u010539271/article/details/69668807

 浙公网安备 33010602011771号
浙公网安备 33010602011771号