


处理某地方日报的反爬机制走过的弯路
众所周知,人生苦短,我用Python。而学习网站的数据,最简单的写法应该是这样的:
import requests res = requests.get(url)
因为最近学习上有需要地方日报的数据,网上已经有大佬写出了爬取某乎日报、某民日报的文章了,因为是学习比较大的网站,所以需要模仿浏览器访问的方式:
import requests import bs4 import os import datetime import time headers = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36' } r = requests.get(url,headers=headers)
但是当本人去学习其他网站的数据时,发现爬不下来东西,直接请求的数据是这样的:
<html> <head> <script language="javascript">setTimeout("try{setCookie();}catch(error){};location.replace(location.href.split(\"#\")[0])",2000);</script> <script type="text/javascript" src="http://10.69.69.82:80/usershare/flash.js"></script> <script type="text/javascript">var ret=getIPs(function(ip){rtcsetcookie(ip)});checkflash(ret)</script> </head> <body> <object classid="clsid:d27cdb6e-ae6d-11cf-96b8-444553540000" codebase="http://fpdownload.macromedia.com/pub/shockwave/cabs/flash/swflash.cab#version=7,0,0,0" width="0" height="0" id="m" align="center"> <param name="allowScriptAccess" value="always"/><param name="movie" value="http://10.69.69.82:80/usershare/1.swf"/><param name="quality" value="high" /> <embed src="http://10.69.69.82:80/usershare/1.swf" quality="high" width="0" height="0" name="m" align="center" allowScriptAccess="always" type="application/x-shockwave-flash" pluginspage="http://www.macromedia.com/go/getflashplayer"/></object> </body> </html>
介是啥玩意儿?因为本人只是因学习需要所以才学的Python,此前一直是用Java的,前端知识也只是略有了解,翻了一下资料,觉得应该是碰上反爬机制了,于是走了各种弯路(下面会介绍的,本段暂不提及),直到翻到了某地方网页,看到请求时候有两个一模一样的网址和请求体:

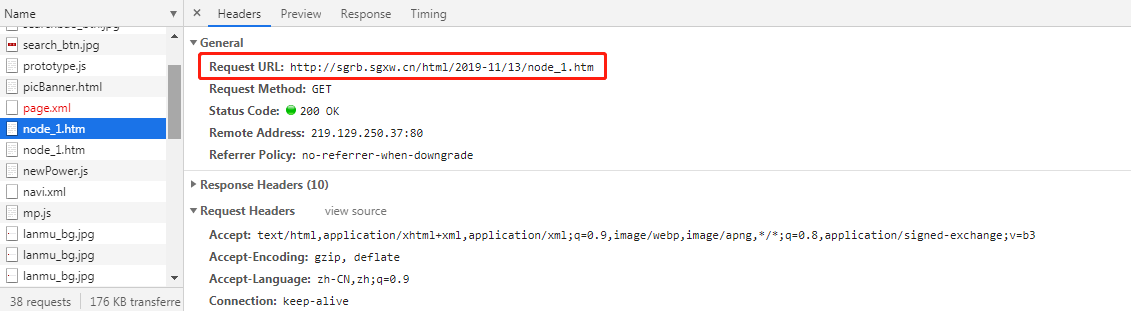
猜想应该是两次请求,一个是防我这种学习其他网址的小菜鸡,另一个是真正获取到东西的网址。据本人这几天的排查(刚开始不知道这个怎么解决,柿子要挑软的捏嘛),一般地方报纸有三种,A是一次请求就可以拿到数据的,B是两次请求就可以拿到数据的,C是直接像图片的那种(可以参考东莞日报http://epaper.timedg.com/)。
对于报纸B,可以使用以下方法:
res = requests.get(url)
res = requests.get(url)
对,就是这样,惊不惊喜?第一次请求到的是门神,第二次才是内容。但是这个方法放在连续请求,效率就非常低了,所以在此推荐使用selenium半自动请求来实现访问。但是要注意浏览器的版本。
而对于C报纸,它的版面(对于本菜鸡来说)是爬不了数据的,所以曲线救国,点开这个地方:

打开F12,就可以看到以下喜闻乐见的内容啦~
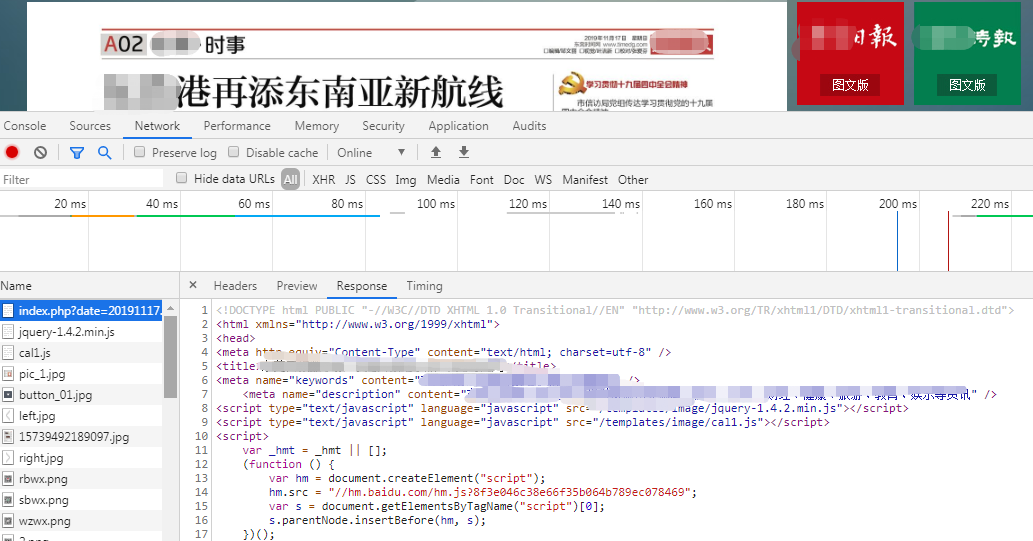
蹡蹡,这样一般的地方报纸就可以多多学习啦~
接下来是走过的弯路(微笑):
① 一般的数据学习最好少用代理服务器(如果是大佬当我没说哈),因为其实成型了的代理服务器一般网站会实时更新反爬机制,像是PySocks(不排除我用不好的情况哈),最好是拿到一批代理ip来模仿浏览器操作。
② 有种反爬机制是重定向,这个需要看<meta>标签里面是否有rediect这关键词。
③ 如果是ajax之类动态加载的网页,可以使用selenium来做,这个需要注意浏览器的版本
④ 取之有道,咱们也只是抱着学习的目的,别没事儿给别人找麻烦,在白天浏览人数多的时候去爬,搞到服务器负担大甚至跪了,给管理员添堵。要不慢慢爬,或者半夜来爬,不然ip进小黑屋就没办法了......

