

python爬取豌豆荚中的详细信息并存储到SQL Server中
买了本书《精通Python网络爬虫》,看完了第6章,我感觉我好像可以干点什么;学的不多,其中的笔记我放到了GitHub上:https://github.com/NSGUF/PythonLeaning/blob/master/examle-urllib.py,因为我用的python3.0,所以,在爬取数据的时候只用到了一个包:urllib。该博文的源码:https://github.com/NSGUF/PythonLeaning/blob/master/APPInfo.py
思路:首先,如果进入了豌豆荚的首页可以看到,其图如图1,主要是分为安卓软件和安卓游戏,所以只需得到这里面所有的链接即可,如影音播放,系统工具等;
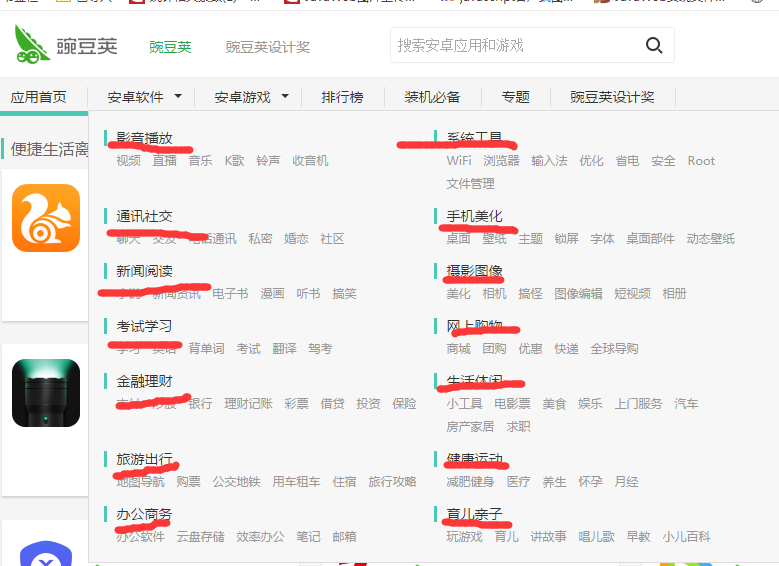
图1
当点击随意一个链接时,显示图2,如图可见,该页面会显示每个软件的基本信息,并且会链接到其详细信息上,这时,如果能获取到详细信息的链接就能得到所需的基本信息了;
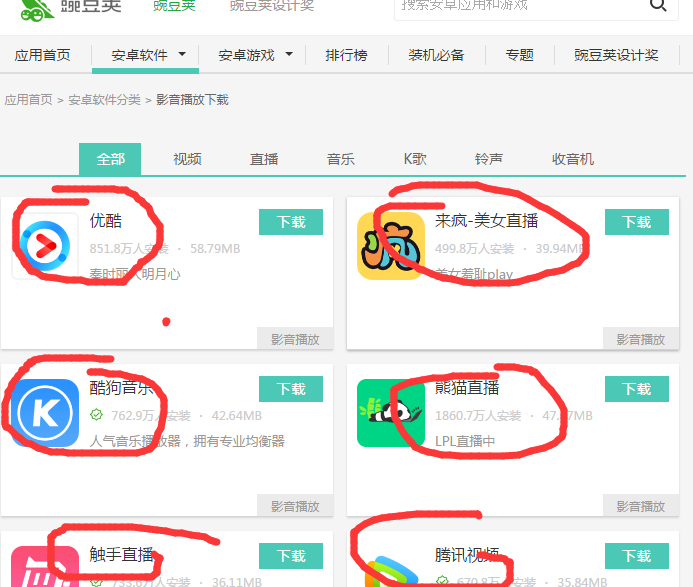
图2
由于该网站是分页的,所以必须得到页数,由图可见,每个页面的最大都是42,而具体却没有到42,所以后面会显示图4.没有更多内容了所以,可以循环42次;
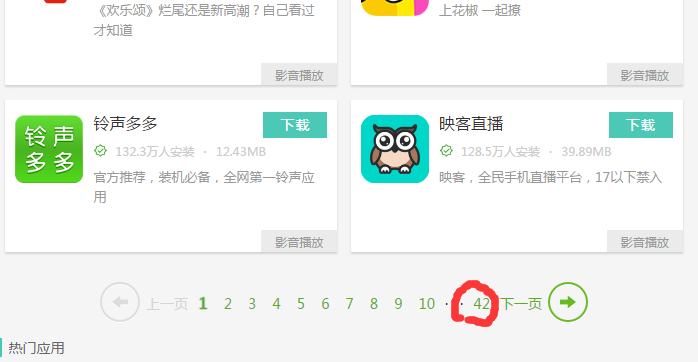
图3
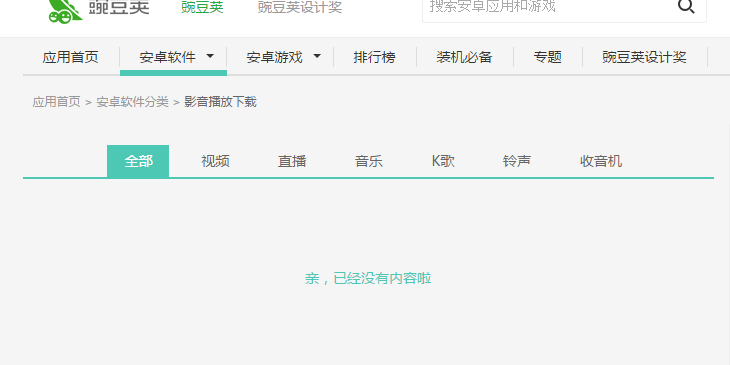
图4
综上所述:可得获取图1中画下划线的链接,同样包括安卓游戏中的该链接
def getAllLinks(url):#获取首页链接的所有子链接 html1=str(urllib.request.urlopen(url).read()) pat='<a class="cate-link" href="(http://.+?")>' allLink=re.compile(pat).findall(html1) allLinks=[] for link in allLink: allLinks.append(link.split('"')[0]) return allLinks
获取图2中圈起来的链接,因为其有页码,所以得加上页码
def getAllDescLinks(url,page):#获取子链接中所有app指向的链接 url=url+'/'+str(page) print(url) html1=str(urllib.request.urlopen(url).read().decode('utf-8')) pat2='<ul id="j-tag-list" class="app-box clearfix">[\s\S]*<div class="pagination">' allLink=str(re.compile(pat2).findall(html1)).strip('\n').replace(' ','').replace('\\n','').replace('\\t','') allLink=allLink.split('<divclass="icon-wrap"><ahref="') allLinks=[] for i in range(1,len(allLink)): allLinks.append(allLink[i].split('"><imgsrc')[0]) allLinks=list(set(allLinks)) return allLinks
获取详细信息中的信息:
def getAppName(html):#获取app名字 pat='<span class="title" itemprop="name">[\s\S]*</span>' string=str(re.compile(pat).findall(html)) name='' if string!='[]': name=string.split('>')[1].split('<')[0] return name def getDownNumber(html):#下载次数 pat='<i itemprop="interactionCount"[\s\S]*</i>' string=str(re.compile(pat).findall(html)) num='' if string!='[]': num=string.split('>')[1].split('<')[0] return num def getScore(html):#评分 pat='<span class="item love">[\s\S]*<i>[\s\S]*好评率</b>' string=str(re.compile(pat).findall(html)) score='' if string!='[]': score=string.split('i')[2].split('>')[1].split('<')[0] return score def getIconLink(html):#app中icom的图片链接 pat='<div class="app-icon"[\s\S]*</div>' image=str(re.compile(pat).findall(html)) img='' if image!='[]': img='http://'+str(image).split('http://')[1].split('.png')[0]+'.png' return img def getVersion(html):#版本 pat='版本</dt>[\s\S]*<dt>要求' version=str(re.compile(pat).findall(html)) if version!='[]': version=version.split(' ')[1].split('</dd>')[0] return version def getSize(html):#大小 pat='大小</dt>[\s\S]*<dt>分类' size=str(re.compile(pat).findall(html)) if size!='[]': size=size.split('<dd>')[1].split('<meta')[0].strip('\n').replace(' ','').replace('\\n','')#strip删除本身的换行,删除中文的空格,删除\n字符 return size def getImages(html):#所有截屏的链接 pat='<div data-length="5" class="overview">[\s\S]*</div>' images1=str(re.compile(pat).findall(html)) pat1='http://[\s\S]*.jpg' images=[] images1=str(re.compile(pat1).findall(images1)) if images1!='[]': images1=images1.split('http://') for i in range(1,len(images1)): images.append(images1[i].split('.jpg')[0]+'.jpg') return images def getAbstract(html):#简介 pat='<div data-originheight="100" class="con" itemprop="description">[\s\S]*<div class="change-info">' abstract=str(re.compile(pat).findall(html)) if abstract=='[]': pat='<div data-originheight="100" class="con" itemprop="description">[\s\S]*<div class="all-version">' abstract=str(re.compile(pat).findall(html)) if abstract!='[]': abstract=abstract.split('description">')[1].split('</div>')[0].replace('<br>','').replace('<br />','')#strip删除本身的换行,删除中文的空格,删除\n字符 return abstract def getUpdateTime(html):#更新时间 pat='<time id="baidu_time" itemprop="datePublished"[\s\S]*</time>' updateTime=str(re.compile(pat).findall(html)) if updateTime!='[]': updateTime=updateTime.split('>')[1].split('<')[0] return updateTime def getUpdateCon(html):#更新内容 pat='<div class="change-info">[\s\S]*<div class="all-version">' update=str(re.compile(pat).findall(html)) if update!='[]': update=update.split('"con">')[1].split('</div>')[0].replace('<br>','').replace('<br />','')#strip删除本身的换行,删除中文的空格,删除\n字符 return update def getCompany(html):#开发公司 pat='<span class="dev-sites" itemprop="name">[\s\S]*</span>' com=str(re.compile(pat).findall(html)) if com!='[]': com=com.split('"name">')[1].split('<')[0]#strip删除本身的换行,删除中文的空格,删除\n字符 return com def getClass(html):#所属分类 pat='<dd class="tag-box">[\s\S]*<dt>TAG</dt>' classfy1=str(re.compile(pat).findall(html)) classfy=[] if classfy1!='[]': classfy1=classfy1.split('appTag">') for i in range(1,len(classfy1)): classfy.append(classfy1[i].split('<')[0]) return classfy def getTag(html):#标有的Tag pat='<div class="side-tags clearfix">[\s\S]*<dt>更新</dt>' tag1=str(re.compile(pat).findall(html)) tag=[] if tag1!='[]': tag1=tag1.strip('\n').replace(' ','').replace('\\n','').split('</a>') for i in range(0,len(tag1)-1): tag.append(tag1[i].replace('<divclass="side-tagsclearfix">','').replace('<divclass="tag-box">','').replace('</div>','').split('>')[1]) return tag def getDownLink(html):#下载链接 pat='<div class="qr-info">[\s\S]*<div class="num-list">' link=str(re.compile(pat).findall(html)) if link!='[]': link=link.split('href="http://')[1].split('" rel="nofollow"')[0] return link def getComment(html):#评论内容(只包含10条,因为网页只显示有限) pat='<ul class="comments-list">[\s\S]*<div class="hot-tags">' comm=str(re.compile(pat).findall(html)) comms='' eval_descs=[] if comm!='[]': comms=comm.strip('\n').replace(' ','').replace('\\n','').split('<liclass="normal-li">') for i in range(1,len(comms)-1): userName=comms[i].split('name">')[1].split('<')[0] time=comms[i].split('</span><span>')[1].split('<')[0] evalDesc=comms[i].split('content"><span>')[1].split('<')[0] eval_desc={'userName':userName,'time':time,'evalDesc':evalDesc} eval_descs.append(eval_desc) # comm=comm.split('href="http://')[1].split('" rel="nofollow"')[0] return eval_descs
将信息插入SQL数据库,这里注意execute后面用的占位符是?,之前我看了很多其他的资料,用的是%s,报错了,最无语的是报错居然还乱码了。
def insertAllInfo(name,num,icon,score,appversion,size,images,abstract,updateTime,updateCon,com,classfy,tag,downLink,comm):#插入SQL数据库 import pyodbc conn = pyodbc.connect('DRIVER={SQL Server};SERVER=127.0.0.1,1433;DATABASE=Test;UID=sa;PWD=123') #连接之后需要先建立cursor: cursor = conn.cursor() try: cursor = conn.cursor() cursor.execute('insert into tb_wandoujia(name,num,icon,score,appversion,size,images,abstract,updateTime,updateCon,com,classfy,tag,downLink,comm) values(?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)',(name,num,icon,score,appversion,size,images,abstract,updateTime,updateCon,com,classfy,tag,downLink,comm)) conn.commit()# 不执行不能插入数据 print('成功') except Exception as e: print(str(e)) finally: conn.close()
数据库创建代码如下:
create database Test CREATE TABLE [dbo].[tb_wandoujia]( [Id] [int] IDENTITY(1,1) NOT NULL, [name] [varchar](100) NULL, [num] [varchar](100) NULL, [icon] [varchar](200) NULL, [score] [varchar](10) NULL, [appversion] [varchar](20) NULL, [size] [varchar](20) NULL, [images] [varchar](2000) NULL, [abstract] [varchar](2000) NULL, [updateTime] [varchar](20) NULL, [updateCon] [varchar](2000) NULL, [com] [varchar](50) NULL, [classfy] [varchar](200) NULL, [tag] [varchar](300) NULL, [downLink] [varchar](200) NULL, [comm] [varchar](5000) NULL, PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO SET ANSI_PADDING OFF GO
调用获取所有信息、打印并插入数据库:
def getAllInfo(url):#获取所有信息 html1=str(urllib.request.urlopen(url).read().decode('utf-8')) name=getAppName(html1) print('名称:',name) if name=='': return num=str(getDownNumber(html1)) print('下载次数:',num) icon=str(getIconLink(html1)) print('log链接:',icon) score=str(getScore(html1)) print('评分:',score) version=str(getVersion(html1)) print('版本:',version) size=str(getSize(html1)) print('大小:',size) images=str(getImages(html1)) print('截图:',images) abstract=str(getAbstract(html1)) print("简介:",abstract) updateTime=str(getUpdateTime(html1)) print('更新时间:',updateTime) updateCon=str(getUpdateCon(html1)) print('更新内容:',updateCon) com=str(getCompany(html1)) print('公司:',com) classfy=str(getClass(html1)) print('分类:',classfy) tag=str(getTag(html1)) print('Tag:',tag) downLink=str(getDownLink(html1)) print('下载链接:',downLink) comm=str(getComment(html1)) print('评价:',comm) if name!='': insertAllInfo(name,num,icon,score,version,size,images,abstract,updateTime,updateCon,com,classfy,tag,downLink,comm)
最后,循环调用,获取全部的信息:
for link in getAllLinks(url): print(link) for i in range(1,42):#由于豌豆荚给的最大是42页,所以这里用42,反正如果没有42,也会很快 print(i) for descLink in getAllDescLinks(link,i): print(descLink) getAllInfo(descLink)
最后打印的结果如下图:
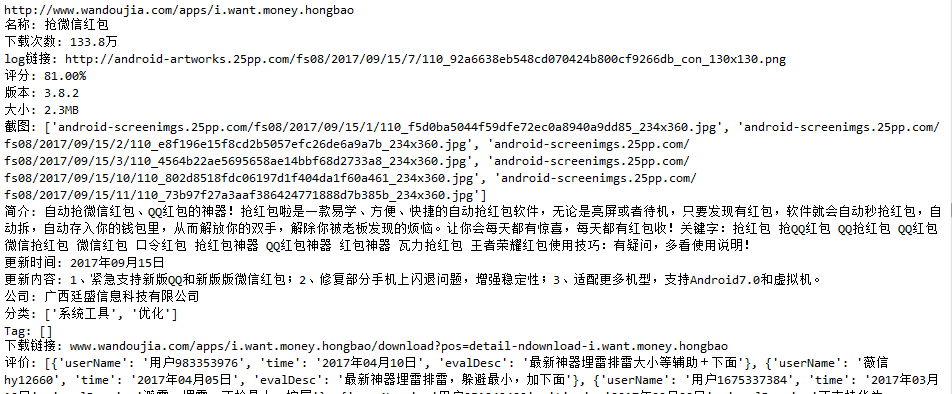
存储到sql数据库的图片如下:
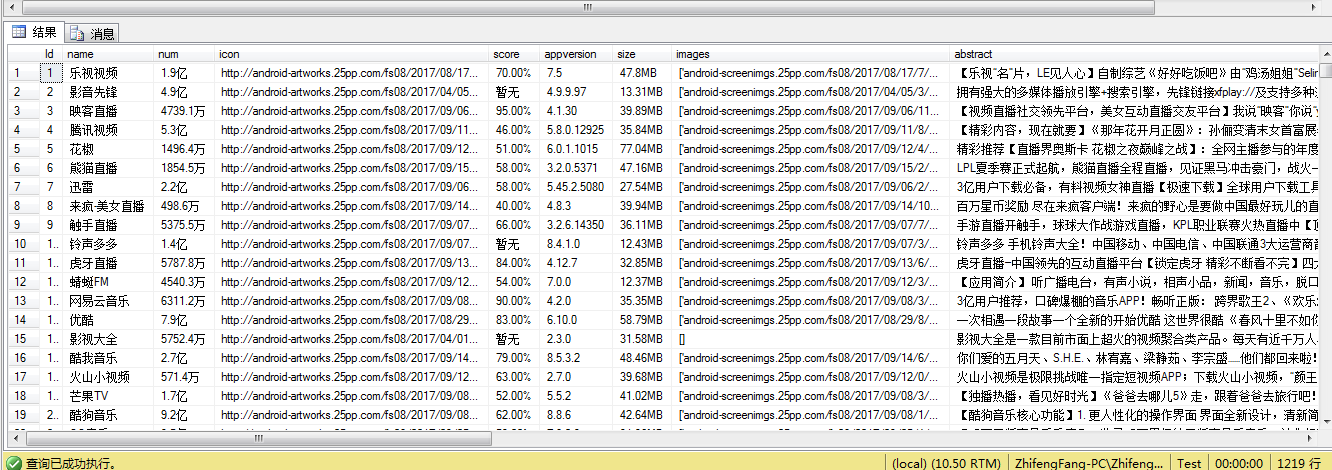
文章来源:NSGUF,欢迎分享,转载请保留出处
