搜广推05-文本匹配入门一些
文本匹配
语义解析:有用吗?
一. 定义&背景
- 一些定义
1.1研究两段文本之间关系的问题都可以看做是文本匹配;
1.2当使用文本语义监督训练时,就是 语义相似性匹配问题。 如果使用 行为标签去监督训练,就成了行为相关性匹配问题。
1.3 语义相关性,比如搜索,查询词和文档如果关键字不一样,但两者是多词一义,则模型不理解语义,做语义上的匹配解决不了问题。 在推荐中,商品可以由一个向量来刻画,用户也可以由一系列交互过的商品来表达,两者之间做一些语义上的匹配,能推荐出一些有新意的商品,增加推荐多样性。而传统的方法比如CF,CB等,无法学习得到这种用户和商品的相对间接的联系。
适用场景:阅读理解,QA,搜索,语义蕴含,推荐,广告等。
信息检索: 查询和文档的匹配
问答系统:问题和候选答案的匹配
对话系统:对话和回复的匹配
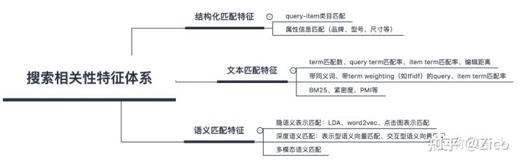
一、相似度计算&复述识别(textual similarity¶phrase identification)
这个可以说是文本匹配最典型最经典的场景了,也就是判断两段文本是不是表达了同样的语义,即是否构成复述(paraphrase)关系。有的数据集是给出相似度等级,等级越高越相似(这种更合理一些),有的是直接给出0/1匹配标签。这一类场景一般建模成分类问题。
代表性数据集:
• SemEval STS Task:从2012年开始每年都举办的经典NLP比赛。这个评测将两段文本的相似度程度表示为0.0~5.0,越靠近0.0表示这两段文本越不相关,越靠近5.0表示越相似。使用皮尔逊相关系数(Pearson Correlation)来作为评测指标。链接[2]
• Quora Question Pairs (QQP):这个数据集是Quora发布的。相比STS,这个数据集规模明显大,包含400K个question-question pairs,标签为0/1,代表两个问句的意思是否相同。既然建模成了分类任务,自然可以使用准确率acc和f1这种常用的分类评价指标啦。(知乎什么时候release一个HuQP数据集( ̄∇ ̄))链接[3]
• MSRP/MRPC:这是一个更标准的复述识别数据集。在QQP数据集中文本都是来自用户提问的问题,而MRPC里的句子则是来源于新闻语料。不过MRPC规模则要小得多,只有5800个样本(毕竟是2005年release的数据集,而且人工标注,所以可以理解╮( ̄▽ ̄"")╭)。跟QQP一样,MRPC一般也用acc或f1这种分类指标评估。链接[4]
• PPDB:这个paraphrase数据集是通过一种ranking方法来远程监督[]做出来的,所以规模比较大。文本粒度包含lexical level(单词对)、phrase level(短语对)和syntactic level(带句法分析标签)。而且不仅包含英文语料,还有法语、德语、西班牙语等15种语言(为什么没有中文!)。语料库规模从S号、M号一直到XXXL号让用户选择性下载也是很搞笑了,其中短语级就有7000多万,句子级则有2亿多。由于语料规模太大,标注质量还可以,因此甚至可以拿来训练词向量[5]。链接[6]
二、问答匹配(answer selection)
问答匹配问题虽然可以跟复述识别一样强行建模成分类问题,但是实际场景往往是从若干候选中找出正确答案,而且相关的数据集也往往通过一个匹配正例+若干负例的方式构建,因此往往建模成ranking问题。
在学习方法上,不仅可以使用分类的方法来做(在ranking问题中叫pointwise learning),还可以使用其他learning-to-rank的学习方法,如pairwise learning(”同question的一对正负样本”作为一个训练样本)和listwise learning(”同question的全部样本排好序“作为一个训练样本) 。因此,相应的评价指标也多使用MAP、MRR这种ranking相关的指标。
注意:这并不代表pointwise matching这种分类做法就一定表现更弱,详情见相关papers
代表性数据集如:
• TrecQA:包含56k的问答对(但是只有1K多的问题,负样本超级多),不过原始的数据集略dirty,包含一些无答案样本和只有正样本以及只有负样本的样本(什么鬼句子),所以做research的话注意一下,有些paper是用的clean版本(滤掉上述三类样本),有的是原始版本,一个数据集强行变成了两个track。链接[7]
• WikiQA:这也是个小数据集,是微软从bing搜索query和wiki中构建的。包含10K的问答对(1K多的问题),样本正负比总算正常了些。链接[8],paper[9]
• QNLI:总算有大规模数据集了,这个是从SQuAD数据集改造出来的,把context中包含answer span的句子作为匹配正例,其他作为匹配负例,于是就有了接近600K的问答对(包含接近100K的问题)。链接[10]
三、对话匹配(response selection)
对话匹配可以看做是进阶版本的问答匹配:1.引入了历史对话。2.response回复空间比问题答案大很多。
代表数据集:
UDC:Ubuntu Dialogue Corpus是对话匹配任务最最经典的数据集,包含1000K的多轮对话(对话session),每个session平均有8轮对话,不仅规模大而且质量很高,所以近些年的对话匹配工作基本都在这上面玩。链接[11],paper[12]
Douban Conversation Corpus:硬要给UDC挑毛病的话,就是UDC是在ubuntu技术论坛这种限定域上做出来的数据集,所以对话topic是非常专的。所以@吴俣 大佬release了这个开放域对话匹配的数据集,而且由于是中文的,所以case study的过程非常享受。链接[13],paper[14]
四、自然语言推理/文本蕴含识别(NLI/Textual Entailment)
NLI,或者说RTE任务的目的就是判断文本A与文本B是否构成语义上的推理/蕴含关系:即,给定一个描述「前提」的句子A和一个描述「假设」的句子B,若句子A描述的前提下,若句子B为真,那么就说文本A蕴含了B,或者说A可以推理出B;若B为假,就说文本A与B互相矛盾;若无法根据A得出B是真还是假,则说A与B互相独立。
显然该任务可以看作是一个3-way classification的任务,自然可以使用分类任务的训练方法和相关评价指标。当然也有一些早期的数据集只判断文本蕴含与否,这里就不贴这些数据集了。
代表性数据集:
• SNLI:Stanford Natural Language Inference数据集是NLP深度学习时代的标志性数据集之一,2015年的时候发布的,57万样本纯手写和手工标注,可以说业界良心了,成为了当时NLP领域非常稀有的深度学习方法试验场
• MNLI:Multi-Genre Natural Language Inference数据集跟SNLI类似,可以看做SNLI的升级版,包含了不同风格的文本(口语和书面语),包含433k的句子对,链接[17]
• XNLI:全称是Cross-lingual Natural Language Inference。看名字也能猜到这个是个多语言的数据集,XNLI是在MNLI的基础上将一些样本翻译成了另外14种语言(包括中文)。链接[18]
五、信息检索中的匹配
除了上述4个场景之外,还有 query-title匹配、query-doc匹配等信息检索场景下的文本匹配问答。
信息检索场景下,一般先通过检索方法召回相关性,再对相关项进行rerank. 更重要的是reranking,reranking问题就不能仅仅依赖文本这一个维度的特征了,而且相对来说判断两个文本的语义匹配有多深以及关系有多微妙就没有那么重要了。
q-a, q-r,和NLI相关的方法在理论上可以套用在query-title 问题上。 但是 query-doc问题则更多是一个检索问题。
DSSM:CIKM2013 | Learning Deep Structured Semantic Models for Web Search using Clickthrough DataCDSSM:WWW2014 | Learning Semantic Representations Using Convolutional Neural Networks for Web Search
HCAN:EMNLP2019 | Bridging the Gap between Relevance Matching and Semantic Matching for Short Text Similarity Modeling
2 应用场景: 从大量的数据库中,选取与用户输入内容最匹配的文本
搜索引擎、智能问答、知识检索、对话系统、query-doc搜索、QA系统、文本匹配、意图识别、情感识别。
六、机器阅读理解
做匹配的话,相关的代表性工作如BiDAF、DrQA等最好打卡一下的。
BiDAF:ICLR2017 | Bidirectional Attention Flow for Machine Comprehension
DrQA:ACL2017 | Reading Wikipedia to Answer Open-Domain Questions
注意:虽然基于表示的文本匹配方法(一般为Siamese网络结构)与基于交互的匹配方法(一般使用花式的attention完成交互)纷争数年,不过最终文本匹配问题还是被BERT及其后辈们终结了。因此下面两节请带着缅怀历史的心情来打卡,不必纠结paper的细节,大体知道剧情就好。
打卡的Siamese结构(基于表示)
这种结构就是本文开头提到的,首先对两段文本分别进行encoding进而得到各自的向量表示,然后通过相似度计算函数或相关结构来得到最终的匹配关系。
在baseline阶段提到的SiameseCNN和SiameseLSTM的基础上,这个方向往下做无非就是两个方向:
- 加强encoder,得到更好的文本表示
- 加强相似度计算的函数建模
对于第一个方向,无非就是使用更深更强大的Encoder,代表性打卡工作如
InferSent:EMNLP2017 | Supervised Learning of Universal Sentence Representations from Natural Language Inference Data
ps:虽然这篇paper的真正目的是迁移学习
SSE:EMNLP2017 | Shortcut-Stacked Sentence Encoders for Multi-Domain Inference
对于第二个方向,则是使用更花哨的相似度计算函数或更花哨的用于学习相似度函数的网络结构,可打卡的工作如
SiamCNN:ASRU2015 | Applying deep learning to answer selection: A study and an open taskSiamLSTM:AAAI2016 | Siamese Recurrent Architectures for Learning Sentence SimilarityMulti-view:2016 EMNLP | Multi-view Response Selection for Human-Computer Conversation
显而易见,这个方向可玩性不强(虽然容易work但是paper写出来不够炫酷),所以不要问为什么只更新到了2017年,因为2016年attention就遍地开花了,自然大家基本都跑去赶潮做花式交互结构了。
打卡的花式attention结构(基于交互)
顾名思义,这种思路就是首先通过attention为代表的结构来对两段文本进行不同粒度的交互(词级、短语级等),然后将各个粒度的匹配结果通过一种结构来聚合起来,作为一个超级特征向量进而得到最终的匹配关系。
显然这种思路下,除了让文本对的交互更花哨以外,就是考虑让模型变得更深(从而建模更高level的匹配关系)。
不过个人经验来说,这种思路下虽然可以玩的花样很多,一些论文argue的点也看似有一些道理,不过实际很多模型都是在廖廖一两个数据集上疯(暴)狂(力)改(搜)进(索)各种structure才把分数刷上去的,导致这种structure看似在某个场景甚至仅仅是某些数据集上work,实际上这个structure可能仅仅迎合了特定数据分布或特定场景的一些特性,导致很多工作放到一个新场景下就效果翻车了,甚至努力调参都调不动太多。
因此在BERT之前这类论文提出的模型虽然看起来高大上,不过可能换个数据集后还不如稍微调调参拍拍脑袋的SiameseCNN好用。所以在刷这类论文时,千万不要被蜜汁花哨的模型结构迷惑了双眼噢~相关工作很多,从中挑选了几篇比较有代表性或比较有信息量或容易阅读的。
MatchCNN:AAAI2016 | Text Matching as Image Recognition
DecAtt:EMNLP2016 | A Decomposable Attention Model for Natural Language Inference
CompAgg:ICLR2017 | A COMPARE-AGGREGATE MODEL FOR MATCHING TEXT SEQUENCES
ESIM:ACL2017 | Enhanced LSTM for Natural Language Inference
2018 COLING | Neural Network Models for Paraphrase Identification, Semantic Textual Similarity, Natural Language Inference, and Question Answering
ps:这篇paper其实可以看做是对前面各模型的实验和分析大总结
DAM:ACL2018 | Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network
HCAN:EMNLP2019 | Bridging the Gap between Relevance Matching and Semantic Matching for Short Text Similarity Modeling
此外,这里尤其要注意一下模型对称性的问题,像文本相似度计算/q-q匹配/title-title匹配这类场景下的匹配是对称的,即match(a,b)=match(b,a),但是模型不对称后,就会让模型自己额外的学习这个先验知识,除非数据集很大,或者已经预训练过了,否则效果很容易翻车。当然了,也有一些tricks可以强行使用不对称模型,即在这类场景下对每个样本都跑一遍match(a,b)和match(b,a)然后取平均,不过相比天然对称的模型效果如何就要看各位炼丹师的水平啦
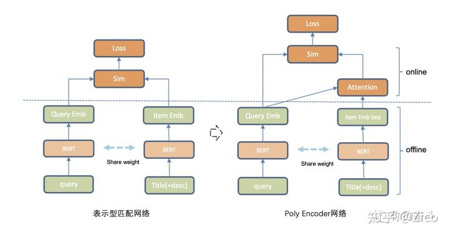
为了兼顾效率和准确率,也有很多折中的方法,例如:PolyEncoder、DeFormer等等后融合(later fusion)方法,另一种常用策略则是 模型蒸馏,如对BERT模型瘦身的DistillBert、TinyBert等
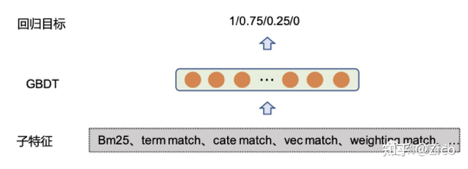
特征融合:
在上述相关性特征基础上,对众多特征进行融合往往可以进一步提升相关性指标,融合模型则采用惊呆你的LR/GBDT/NN 模型即可。 此外特征融合模型的训练一般使用人工标注的训练数据,同时为了标注方便可将相关性目标分为不同档。如在4档模式下,在训练阶段,四个档位分为 1,0.75,0.25,0. 模型则通过回归或分类的方式对分位进行拟合。由于该部分策略是对子特征的Ensemble,因此不需要多训练数据,万级别可以满足需求。
关于相关性任务中: 问题定位: 技术现状分析、问题现状分析
训练数据:高置信样本挖掘、定制化负样本构造
多因子融合:相关性因子、成交效率因子
3 分类
根据文本长度不同:分为3类
A. 短文本-短文本匹配: 网页搜索,计算query与 网页title的匹配程度,召回和排序中都用。
B. 短文本-长文本匹配:搜索引擎、智能问答、知识检索,计算query和整个页面文本内容之间的相似度。
C. 长文本-长文本匹配: 推荐系统, 例如新闻推荐,由长文本推荐长文本。
评估方法:
MAP、MRR方法
二、研究思路
第一种: 孪生网络:双塔采用相同编码器,完了直接算相似度。
第二种:匹配融合:前半与孪生网络相同,然后接 一种或多种注意力机制进行信息交互,最后聚合为一个向量,通过MLP获得短文本的相似度。
第三种:预训练模型:cls+MLP
-
单语义模型: 通过神经网络给两个句子分别编码,然后计算句子之间的相似度,最经典的代表是2013年微软提出的DSSM[1]。
-
多语义模型,改善了单语义模型单一粒度的问题,将整个文本分为不同级别的表达方式,例如词、短语、句子,也会考虑到句子的局部结构[2],编码表达信息比单语义模型更加丰富。
-
匹配矩阵模型,借用了图像的矩阵表示方式[3],将文本匹配的交互方式定义为匹配矩阵,因此可将匹配精细到两两词,甚至两两字母之间。
-
句子交互模型,主要包括表征层和交互层,应用注意力(attention)机制来挖掘句子内和句子间内容的联系,从而得到更好的效果[4]。
模型部分:
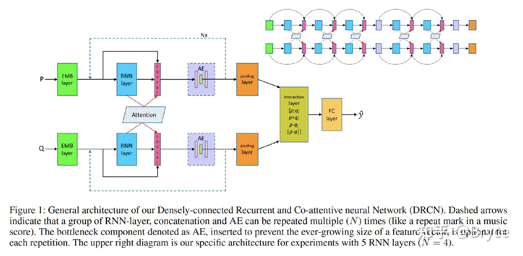
DRCN:笔记[阅读笔记] 句子语义匹配模型——DRCN - 知乎 (zhihu.com)
AAAI2019 Semantic sentence matching with densely-connected recurrent and co-attentive information。
ARC-2: query-doc 三个词卷积,变成二维map.
MatchPyramid: query -doc 两两计算,得到匹配矩阵,再操作图像算法。
MatchRNN: 复杂,神经网络的动态规划
MV-LSTM: 交互产生图像矩阵三中方式,然后 k-max_pooling
aNMM:基于value的共享权重。
三、数据集
3.1 几个数据集供参考:
PI、SSEI、STS 英文:MSRP、SICK、SNLI、STS、Quora QP、MultiNLI
PI、SSEI、STS 中文:LCQMC、BQ corpus
IR-QA 英文:wikiQA、insuranceQA
其中,
PI:paraphrase identification,是判断一文本是否另一文本的复述;
STS:semantic text similarity,是计算两文本在语义层面的相似性;
SSEI:sentence semantic equivalent identification,是判断两文本在语义层面是否一致;
IR-QA:是给定一个 query,直接从一堆 answer 中寻找最匹配的,省略了 FAQ 中 question-answer pair 的 question 中转。
• SNLI:570K条人工标注的英文句子对,label有三个:矛盾、中立和支持
• MultiNLI:433K个句子对,与SNLI相似,但是SNLI中对应的句子都用同一种表达方式,但是MultiNLI涵盖了口头和书面语表达,可能表示形式会不同(Mismatched)
• Quora 400k个问题对,每个问题和答案有一个二值的label表示他们是否匹配
• WikiQA是问题是相对应的句子的数据集,相对比较小。
3.2 训练标签
文本匹配的监督方式多种多样,一般标签形式可以分成下述三种形式:
• pointwise,M 通常为 1,标签形式为 0 或 1,标签 0 表示 query 与该 doc 不匹配,标签 1 表示匹配。 M 也可大于 1 ,此时,一组数据中只有一个 1 其余全为 0,表示这 M 个 doc 中只有这一个与 query 匹配,其余全都不匹配。
• pairwise,M 通常为 2,标签形式为 0 或 1 ,标签 0 表示 query 与第一个 doc 比与第二个 doc 更匹配,标签 1 表示 query 与第二个 doc 比与第一个 doc 更匹配,当然也可以反之。
• listwise,M 通常大于等于 2,标签形式为 1 到 M 的正整数,标签 m 表示 query 与该 doc 的匹配度在该组里位列第 m 位。实际多采用 pointwise 或者 pairwise 方式。
四、未来工作
4.1 挑战:
-
匹配对象差异巨大
实际问题中文本匹配的两个对象往往长度差异巨大,比如搜索场景的query-doc匹配,QA系统的问题答案匹配,标签系统的文章-标签匹配等,都是至少有匹配一方是极短文本,展示的语义并不完整,这种情况下进行文本匹配操作会带来各种各样的问题,需要根据实际问题来解决。 -
优质训练样本难大量获取
-
文本匹配的层次性
文本是以层次化的方式组织起来的,词语组成短语,短语组成句子,句子组成段落,段落组成篇章。这种特性使得 在做文本匹配的时候需要考虑不同层次的匹配信息,按照层次的方式组织文本匹配信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号