# 20192324夏馨 2019-2020-2 《Python程序设计》实验四报告
课程:《python程序设计》
班级:1923
姓名:夏馨
学号:20192324
实验教师:王志强
实验日期:2020年6月12日
必修/选修:公选课
1 实验内容
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
2 实验过程
源代码:
请求的url地址
url = 'https://qxs.la/177913/'
伪造请求头, 模拟浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'
}
请求网页
rsp = requests.get(url=url, headers=headers)
soup = BeautifulSoup(rsp.text, 'lxml')
打开文件准备写入
file = open('雪鹰领主.txt', 'w', encoding='utf-8')
解析所有子链接
links = soup.select('.chapters .chapter a')
for link in links:
href = 'https://qxs.la' + link.get('href')
title = link.get('title')
print(title)
print(href)
while True:
try:
# 请求每章的详情页
desc = requests.get(url=href, headers=headers, timeout=5)
if desc.status_code == 200:
break
except Exception as e:
# print(e)
pass
d_soup = BeautifulSoup(desc.text, 'lxml')
获取content标签
content = d_soup.select_one('#content')
去除多余的标签
[s.extract() for s in content("div")]
获取文本内容
content = content.text
file.write(title + '\n' + content + '\n')
time.sleep(0.2)
break
关闭文件写入
file.close()
进入网页
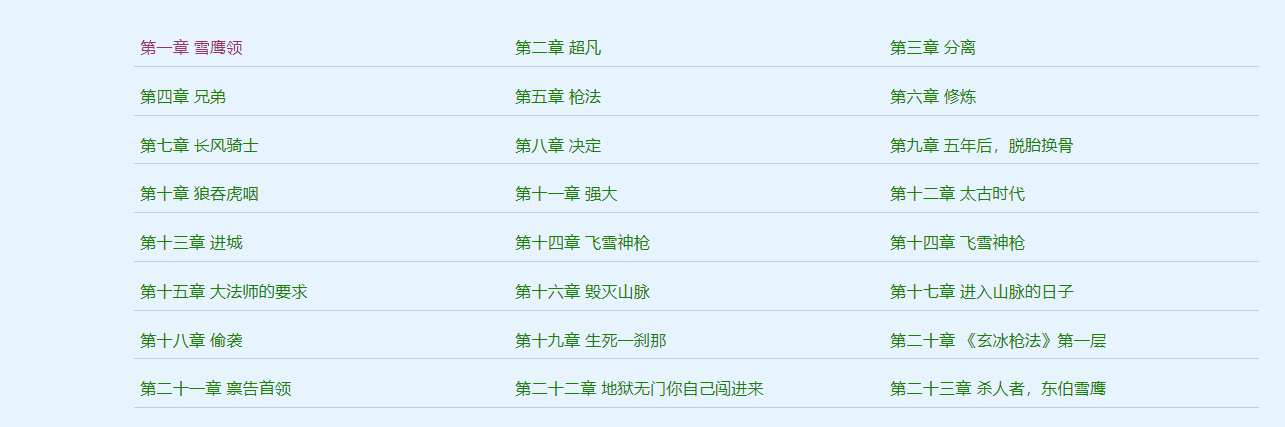
获取所有章节信息,找到网页中的数据

伪造headers,模拟浏览器发起请求网页数据

每个章节连接获取后,循环请求每个章节连接,请求详情页数据
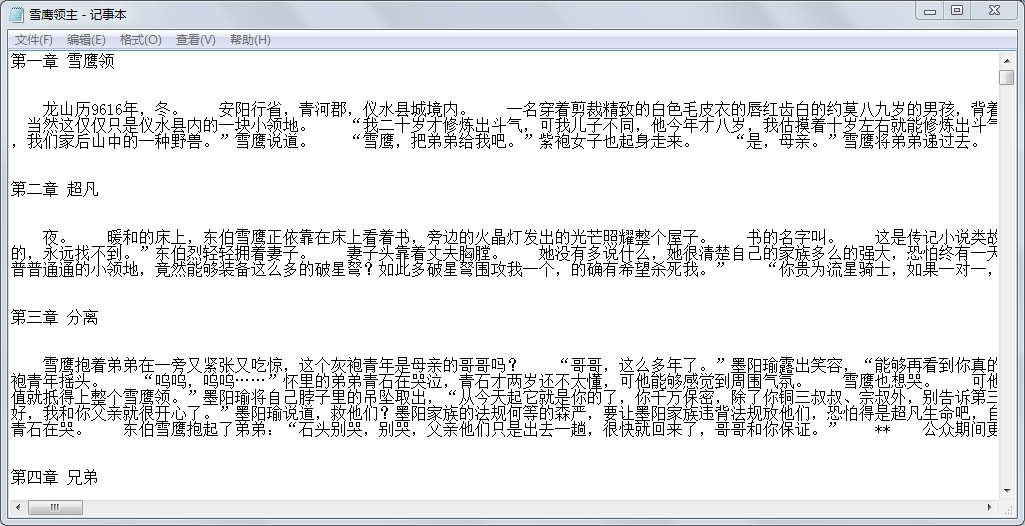
发现详情页具体在id为content的div下

获取数据后,写入到文本文档中
3 实验过程中遇到的问题及解决过程
问题1:对爬虫技术不熟悉导致无从下手
问题1解决方案:仔细学习课程所发的资源并自己在网络上查看相关知识
问题2:请求详情页时,出现困难
问题2解决方案:发现详情页具体在id为contect的div下
其他(感悟、思考等)
1.经过一个学期的学习,我发现编程并不像我原本想象的那样,像动画影视作品一样具象的有趣,它所呈现给我们的,更多是冷冰冰的代码及逻辑,但真正热爱编程的人却能从中找到字里行间的趣味性,并利用这些冷冰冰的代码,去实现各种缤纷绚丽的实际功能。
2.在学习python的过程中,我们也在同步学习c语言,让我直观地感受到了什么是面向对象的编程语言,而什么是面向过程的编程语言。在学习两门编程语言的过程中,我能感受到,python比c语言对新手更友好,也更强大,但在往后的学习中,我两门语言都不会放弃学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号