

基于BERT Adapter的词汇增强型中文序列标注模型
©原创作者 | 疯狂的Max
论文Lexicon Enhanced Chinese Sequence Labelling Using BERT Adapter 解读
01 背景与动机
近年来,多项研究致力于将词汇信息融入中文预训练模型中以提升命名实体识别、分词和词性标注等序列标注类任务的效果。
但其中的大多数方法为都是直接在预训练模型中加入浅层的且随机初始化的序列层,其局限性在于不能在BERT模型的底部的层中加入词汇信息,导致BERT的表征能力得不到充分利用。
因此,本文作者提出Lexicon Enhanced BERT (LEBERT) ,该模型在BERT底部的层中加入一个Lexicon Adapter层来融合文本的词汇特征。实验结果表明该模型在序列标注类任务的10个数据集上的表现超越了业界现有的其他模型。
由于中文词汇没有明显的分界,所以中文的序列标注任务相较英文难度更大,虽然预训练模型在序列标注任务上的表现超越了传统的如LSTM,CRF等模型,但由于其仍是基于单个字符的,因此可以很自然的想到在这个基础上引入词汇的信息,更有助于提升模型效果。
目前可以将相关的改进方向分成两类:
一类是通过在character-level的序列编码器上融入词语的信息,这样可以显性的对词汇特征建模,也可以看做是通过改进模型结构来融入离散的结构化的外部知识;
另一类则是将词汇信息融入到预训练模型的embedding中去,而这两类方法是互补的。
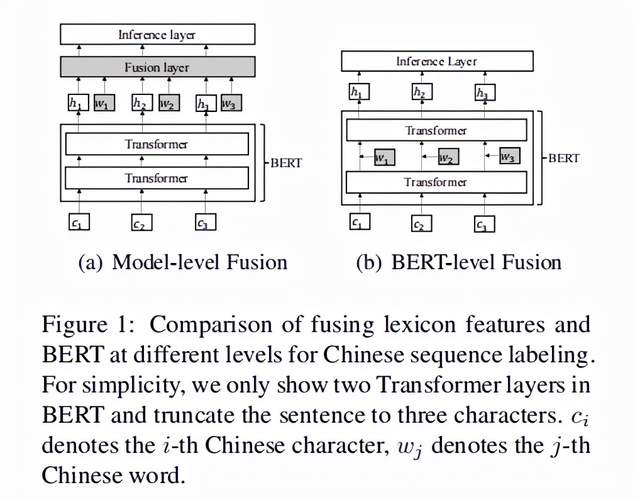
最近的研究更多的考虑将词汇特征和BERT结合起来,主要的思想就是把BERT获取到上下文表征和词汇特征融合起来,一起进入一个神经网络的序列标注模型,作者定义为Model-level fusion,如下图Figure 1(a)所示。
然而这种方法并没有充分利用BERT的表征能力,因为词语特征没能融入到BERT模型的底层。
基于以上描述的现有研究的局限,同时受到BERT Adapter[2]的启发,本文作者提出LEBERT,直接在BERT的Transformer层之间加入额外的层,也就是作者定义的lexicon adapter来融入词汇信息,作者定义为BERT-level fusion,如下图Figure 1(b)所示。
具体来说,需要先将中文句子转换为char-words对的序列进入模型,lexicon adapter通过char-to-word的双线性注意力机制来动态的获取每个字符的最相关的词语。
这个lexicon adapter设置在BERT里的相邻层之间,使得词汇特征和BERT的表征可以在BERT模型中得到充分的交互。
不同于BERT Adapter在fine-tune的时候固定了BERT模型的参数只更新adapter的参数,LEBERT将两者同时更新。
02 模型方法
LEBERT相较BERT主要有两点不同:
一是LEBERT通过将中文句子转换为char-words对序列,把字符和词汇特征都作为输入喂进模型;
二是LEBERT在Transformer层之间加入了lexicon adapter,使得词汇知识更有效的融入BERT模型。
1.字符-词语对序列
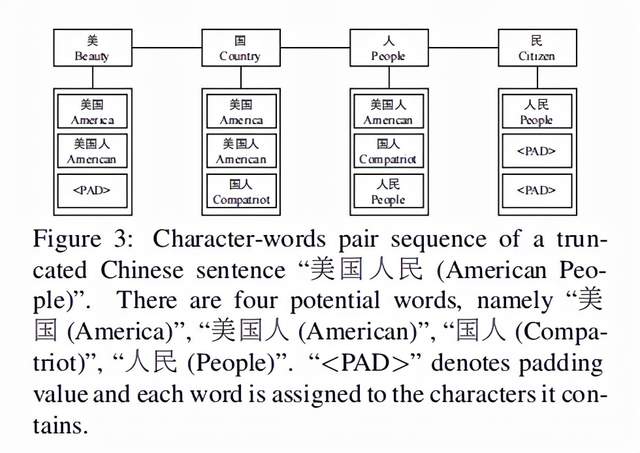
对于每一个输入的句子,先找出潜在的所有可能的句子中包含的词汇,然后将每个字符与对齐所有可能的词汇。
比如“美国人民”这个句子,所有可能的词汇有“美国”,“美国人”,“国人”,“人民”,每个字符对应其所在所有可能的词汇,数量不足的用补齐,如下图Figure 3所示:
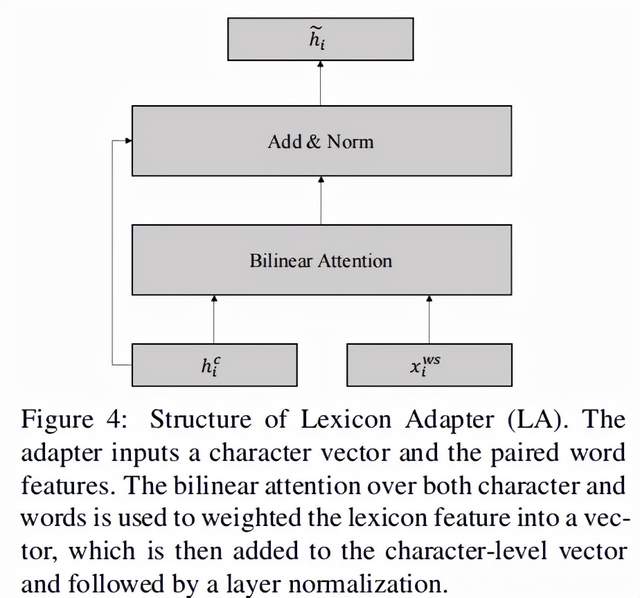
2.lexicon adapter结构
把输入的句子转换成char-words pair sequence之后,句子中的每个位置都包含了其对应的字符特征和词汇特征。

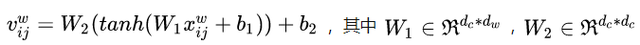

以上整个计算过程可以参见下图 Figure 4:
3.LEBERT模型整体框架
正如前文描述,lexicon adapter是加在BERT的两个Transformer层之间的,本质可以看做是Lexicon Adapter 和BERT的组合。可以直观的表示为下图,即在第k和k+1层之间加入了lexicon adapter:
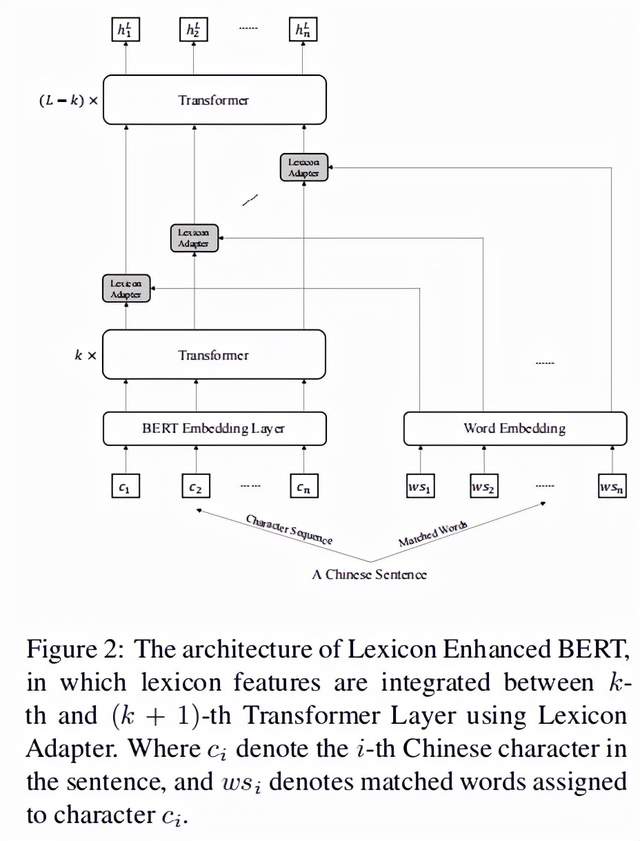
4.训练过程和解码过程
考虑到序列标注任务的前后依赖性,LEBERT在最终的输出层上加了一个线性变换层和CRF层来进行标签解码。
03 实验结果分析
1.实验结果
作者将LEBERT与4种baseline模型和6种前沿的运用了词汇增强的模型进行了比较,4种baseline模型分别是BERT,BERT+word(在BERT预训练时直接拼接词向量的基线模型),ERNIE[3],ZEN[4],另外6种模型见下表前6行。
结果表明,在NER,分词和词性标注三种类型的序列标注任务上,LEBERT效果都是最好的。实验结果具体如下面三个表所示:
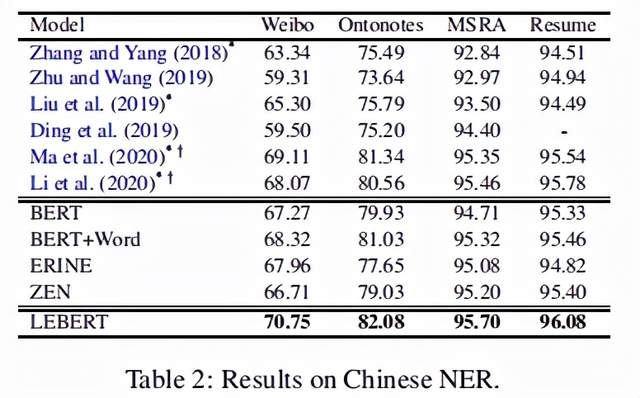
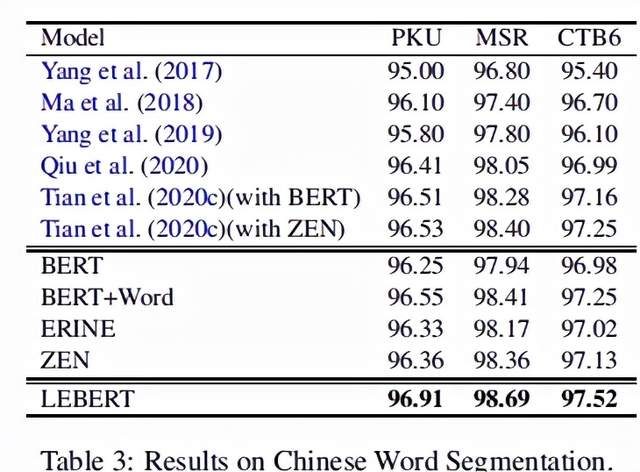
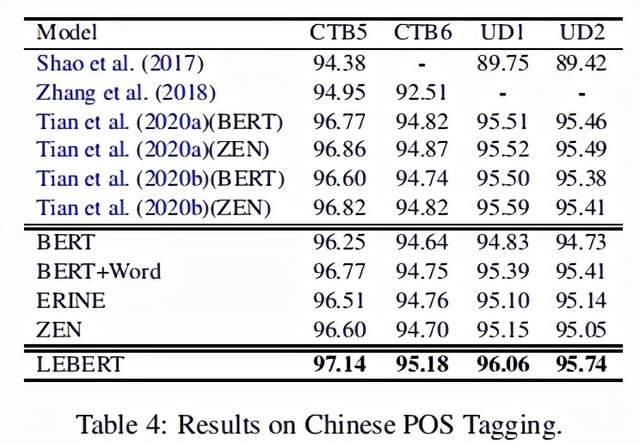
2.分析与讨论
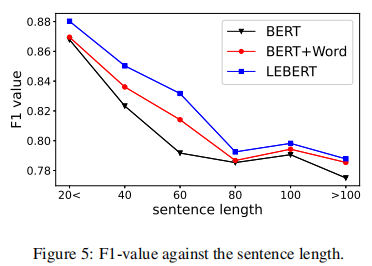
句子长度:无论是BERT,BERT+word这两个基线模型,还是LEBERT都会随着输入句子长度的增长效果有所下降。这是因为随着更长的句子意味着更复杂的语义,模型的学习难度变大。
但是从下图的比对结果来看LEBERT相较另外两个极限模型,随着句子长度的增加,模型鲁棒性更强,也由此证明了LEBERT更充分的利用到了词汇信息。
不同层添加lexicon adapter:作者实验了只添加一层lexicon adapter在BERT层的不同位置,和在不同位置添加多层lexicon adapter,以及在每一层都添加lexicon adapter的效果,结果如下表所示:
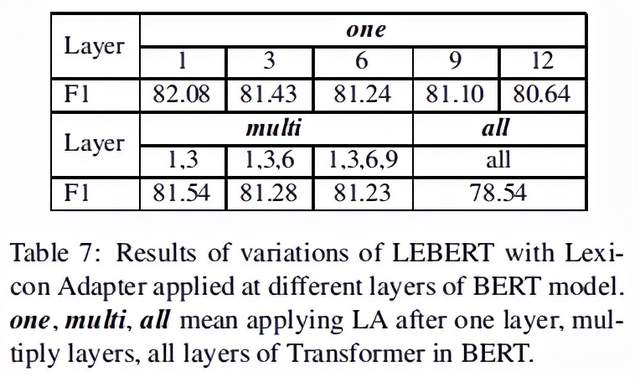
f以上结果表明,在越底层添加lexicon adapter效果越好,添加多层反而导致过拟合。
04 结论和研究思考
LEBERT与传统的在BERT模型之上添加模型结果以融合词汇知识的模型改进方法不同,通过改造BERT模型内部结构,实现深层次的词汇信息融合。
个人认为这种融合方式也可以扩展到词汇增强以外的外部知识融入的研究。
毕竟词汇也可以看做一种外部知识,与之相关的序列标注任务使用LEBERT都有所提升的话,同理推断,将一些知识图谱的知识通过这种方式进行融合,也可以以提高与知识图谱相关的下游任务的效果。
参考文献
[1]中文NER最新屠榜力作——LEBERT
https://zhuanlan.zhihu.com/p/374720213
[2] Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-effificient transfer learning for NLP. In Proceedings of the 36th International Conference on Machine Learning.
[3] Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, and Hua Wu. 2019a. Ernie: Enhanced representation through knowledge integration. arXiv preprint arXiv:1904.09223.
[4] Shizhe Diao, Jiaxin Bai, Yan Song, Tong Zhang, and Yonggang Wang. 2020. ZEN: Pre-training Chinesetext encoder enhanced by n-gram representations. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 4729–4740, Online. Association for Computational Linguistics.
