理解k8s架构设计原则和对象使用
- 一、核心技术概念和API对象
- 二、Kubernetes 分层
- 三、核心对象间的关系图
- 四、对象的概念
- 五、理解控制器原理:控制器的工作流程
- 六、informer的内部机制
- 七、控制器的协同(联动)工作原理
- 八、架构优势及架构原则
- 九、组件探索
- 9.1 深入理解 Kubernetes API Server 的实现机制
- 9.2 Controller Manager
- 9.4 Scheduler
- 9.5 kubelet
- 9.6 kubectl、kubeconfig与apiserver关系
- 9.7 etcd存储
- 9.8 kube-proxy
一、核心技术概念和API对象
- API 对象是 Kubernetes 集群中的管理操作单元;
- Kubernetes 集群系统每支持一项新功能引入一项新技术,一定会新引入对应的 API对象,支持对该功能的管理操作;
- 例如副本集 Replica Set 对应的 API对象是RS:
- 深入理解Kubernetes对象的通用设计:
TypeMeta.
G(roup)
K(ind)
V(ersion
Metadata
Namespace
Name
Labels &Annotation
Finalizers
ResourceVersion
SelftLink
Spec和Status
【Finalizers作用】
在 Kubernetes 中,Finalizers 是用于管理资源(例如对象、Pod、Service 等)生命周期的一种机制。具体来说,Finalizers 的作用主要包括以下几个方面:
(1)资源删除保护:
当资源(例如 Pod、Service、ConfigMap 等)需要被删除时,Kubernetes 不会立即删除该资源,而是先将其标记为 "Terminating" 状态,并在其 metadata.finalizers 字段中添加一个或多个 Finalizers。这个标记和 Finalizers 的存在防止了资源的误删除。
(2)异步删除处理:
通过 Finalizers 机制,Kubernetes 可以执行一些异步的、在资源删除之前需要完成的清理工作。这可以包括调用外部系统的 API、执行脚本或清理与资源关联的其他资源。
(3)删除前处理:
在资源被真正删除之前,Finalizers 提供了一个机会来执行一些清理或处理操作。只有在这些操作完成后,资源才会被最终删除。
(4)删除确认:
在资源上添加 Finalizers 后,只有当这些 Finalizers 被显式移除后,Kubernetes 才会最终删除该资源。这为管理员提供了对删除操作的确认机制,确保资源不会被轻易删除。
在资源被创建时,Finalizers 字段通常是空的。当资源需要删除时,Finalizers 字段会被更新,包含一个或多个 Finalizers 的标识符。Kubernetes 控制器会监视这些资源,检查是否可以安全地删除它们。一旦资源可以删除,并且 Finalizers 中的所有清理工作都已完成,Kubernetes 将删除该资源,并将 Finalizers 字段清空。
总体而言,Finalizers 提供了一种确保在删除资源时执行必要清理步骤的机制,以及一种在删除前确认的方式,以防止误删除。
【ResourceVersion作用】
在 Kubernetes 中,ResourceVersion 是用于实现资源的乐观并发控制的一个重要字段。它的主要作用包括:
(1)乐观并发控制:
ResourceVersion 用于实现乐观并发控制,确保在对资源进行更新时,操作是基于当前已知的最新版本进行的。每个 Kubernetes 资源(如 Pod、Service、ConfigMap 等)都有一个与之相关的 ResourceVersion。
(2)版本比较:
当客户端(如 kubectl)向 Kubernetes API 发送更新请求时,请求中包含了资源的当前 ResourceVersion。服务器会比较客户端提供的版本号与当前服务器上存储的版本号是否匹配,如果匹配则表示资源是最新的,允许更新操作。如果不匹配,则表示其他操作可能已经修改了资源,更新操作将被拒绝。
(3)避免冲突:
通过使用 ResourceVersion,Kubernetes 可以避免并发更新导致的冲突。如果多个客户端同时尝试更新同一个资源,只有最先到达的请求能够成功,后续请求将由于版本不匹配而被拒绝。
(4)触发器:
当资源被修改时,ResourceVersion 的变化可以作为触发器,帮助监视器或控制器等组件检测到资源的变更。这对于构建反应式系统和实现自动化控制很有用。
在 Kubernetes API 中,ResourceVersion 是由服务器自动维护的,客户端通常无需手动管理。每次对资源进行更新时,ResourceVersion 都会递增。客户端只需要在进行更新请求时提供当前已知的 ResourceVersion,而无需关心它如何生成或变化。
总体而言,ResourceVersion 在 Kubernetes 中是一个关键的机制,确保对资源的并发修改是有序的、基于最新状态的,并帮助系统进行版本管理和冲突解决。
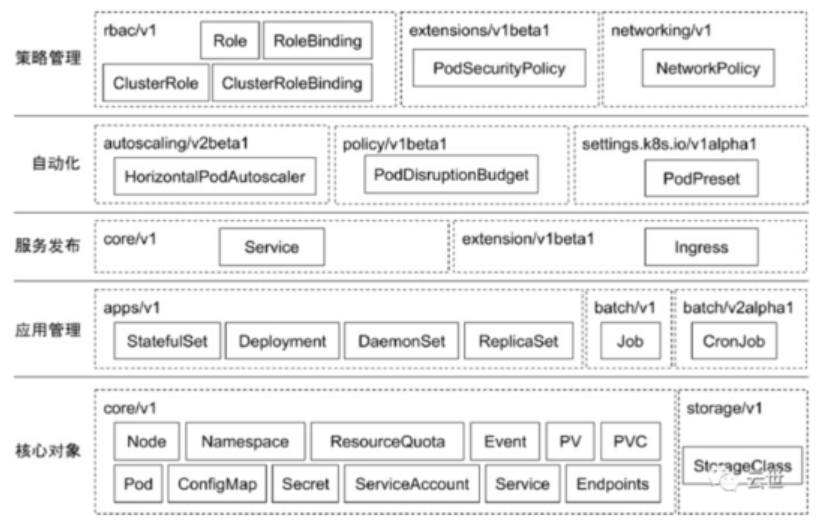
二、Kubernetes 分层
2.1 对象及其分组
2.2 分层架构
- 核心层(Nucleus layer):Kubernetes 最核心的功能,对外提供 API 构建高层的应用,对内提供插件式应用执行环境。
- 应用层(Application layer):部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS 解析等)。
- 管理层(Governance layer):系统度量(如基础设施、容器和网络的度量)、自动化(如自动扩展、动态 Provision 等)、策略管理(RBAC、Quota、PSP、NetworkPolicy 等)。
- 接口层(interface layer):Kubectl 命令行工具、客户端 SDK 以及集群联邦。
- 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴:
Kubernetes 外部(on top):日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS 应用、ChatOps 等;
Kubernetes 内部(Underneath):CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等。
三、核心对象间的关系图
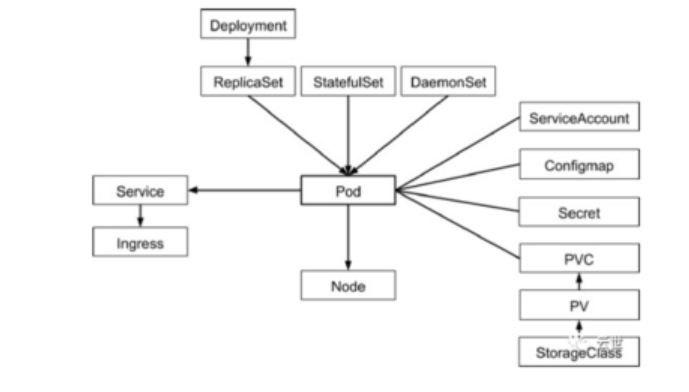
四、对象的概念
4.1 namespace
Namespace 是对一组资源和对象的抽象集合,比如可以用来将系统内部的对象划分为不同的项目组或用户组。从Namespace划分的维度看,Kubernetes 对象分为两类
(1)Non-namespaced object:就是全局对象,这些对象不与任何 Namespace 绑定,属于集群范围的对象,如 Node,PersistVolume,ClusterRole
(2)Namespaced object: 与具体 Namespace 绑定对象,如Pod,Service。
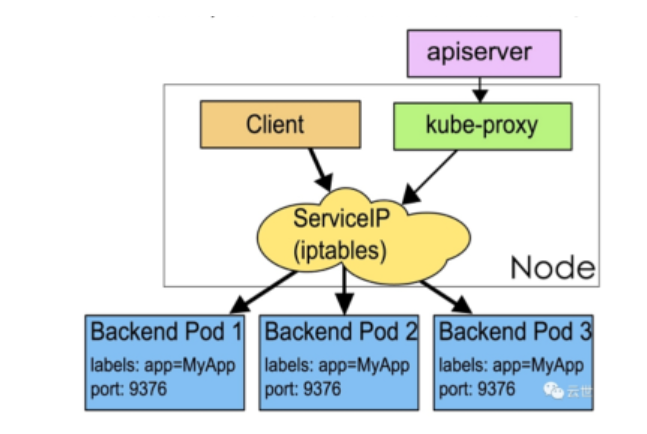
4.2 Service
(1)Service是应用服务的抽象,通过labels为应用提供负载均衡和服务发现。
(2)匹配labels的PodIP 和端口列表组成 endpoints,由Kube-proxy负责将服务IP负载均衡到这些endpoints 上。
(3)每个默认类型 Service 都会自动分配一个cluster IP(仅在集群内部可访问的虚拟地址)和DNS名,其他容器可以通过该地址或DNS来访问服务,而不需要了解后端容器的运行。
4.3 ReplicaSet
Pod指的是具体的应用实例,隶属于某个副本集
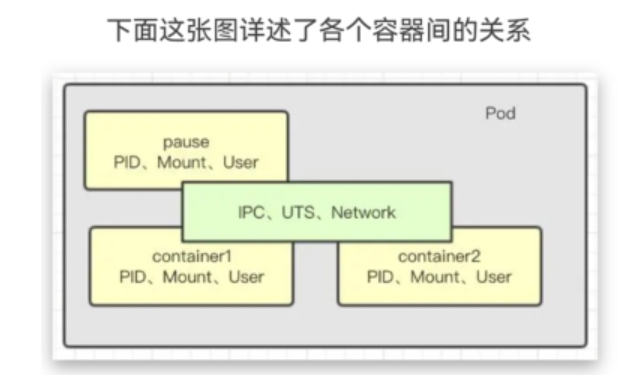
在k8s中,Pod是一个容器集合,相当于一组docker,同一pod内所有容器使用IPC相互通信,因为它们共享了IPC,UTS,Network。
五、理解控制器原理:控制器的工作流程
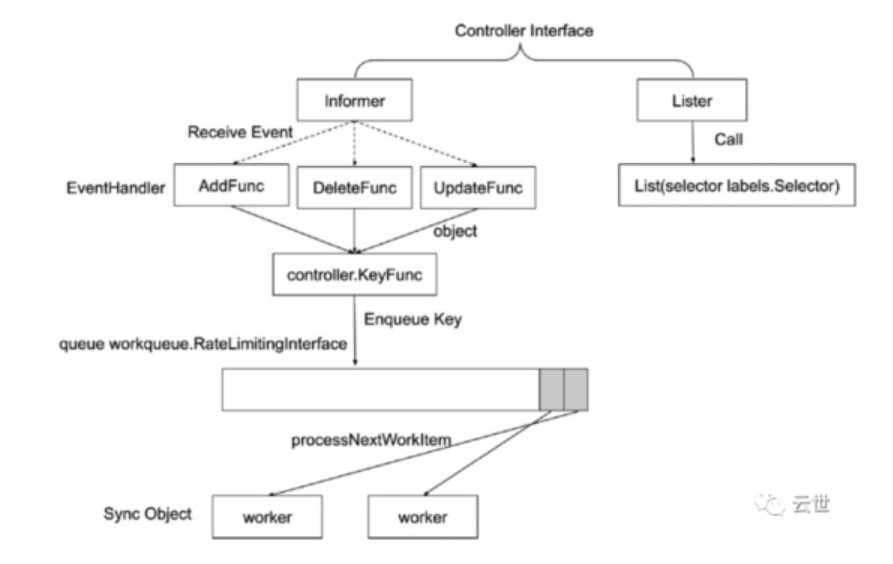
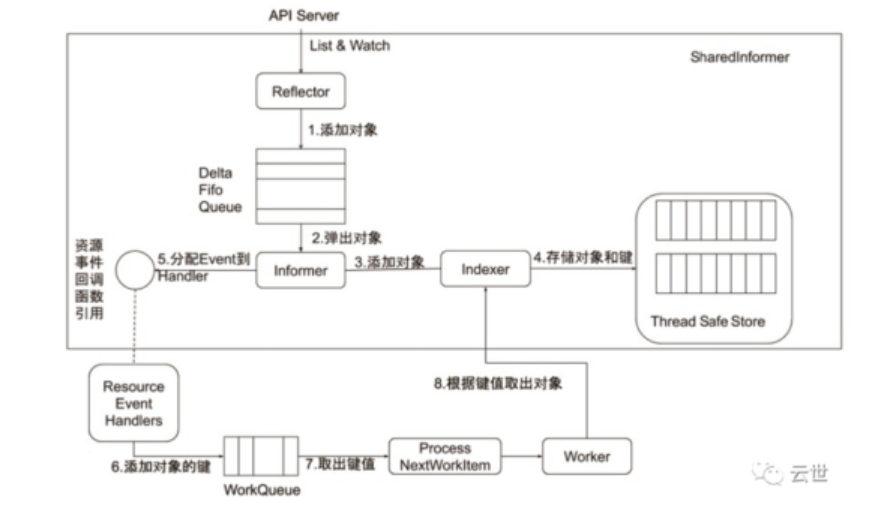
六、informer的内部机制
七、控制器的协同(联动)工作原理
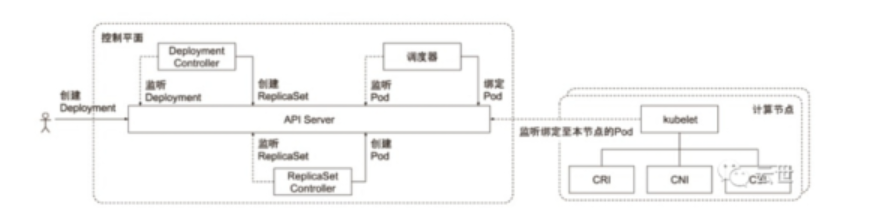
Kubernetes 控制器的联动机制是指不同类型的控制器之间的协同工作和相互作用,以确保集群中的各种资源状态处于期望的状态。Kubernetes 控制器是一类特殊的控制循环,它们负责监控集群中的资源对象,以及根据实际状态和期望状态之间的差异来采取相应的操作。
以下是 Kubernetes 控制器的联动机制的主要方面:
- 声明式配置: Kubernetes 使用声明式配置模型,用户通过 YAML 文件定义他们期望的应用程序状态。控制器负责确保实际状态与声明的状态保持一致。
- 自动修复: 控制器周期性地检查资源的状态,并尝试将其调整为期望的状态。这种自动修复机制确保了应用程序的高可用性和稳定性。
- 控制器之间的协同: 不同类型的控制器之间存在一定的协同工作。例如,Deployment 控制器负责确保应用程序的副本数,而 Service 控制器负责确保服务的稳定性。它们协同工作以实现整体系统的一致性。
- 资源依赖关系: 某些控制器的操作可能依赖于其他资源的状态。例如,一个 StatefulSet 控制器可能需要等待相关的 PersistentVolumeClaim 资源准备就绪,然后才能正确创建 Pod。
- 事件和触发机制: 控制器通过监视事件(例如,资源的创建、更新、删除)来感知集群状态的变化。这些事件触发控制器执行适当的操作,以确保系统的一致性。
- 自定义控制器: Kubernetes 允许用户创建自定义控制器,以满足特定需求。这些自定义控制器可以与内置控制器协同工作,扩展集群的功能。
总体而言,Kubernetes 控制器的联动机制确保了在复杂的分布式系统中,各种资源能够协同工作,自动适应变化,并保持用户定义的期望状态。这种机制使得 Kubernetes 成为一个高度可扩展、弹性和自管理的容器编排平台。
八、架构优势及架构原则
优势:
- 可扩展性: Kubernetes 架构具有高度的可扩展性,可以轻松地扩展到大规模集群,处理数千个节点和数百万个容器。
- 自我修复: Kubernetes 采用声明式配置模型,通过控制器实时监测资源状态,并自动修复不一致的状态,确保系统的高可用性。
- 弹性和自适应: Kubernetes 可以根据工作负载的需求自动扩展或缩减容器实例的数量,以适应变化的负载。
- 服务发现与负载均衡: Kubernetes 提供了内置的服务发现和负载均衡机制,简化了服务之间的通信和协同工作。
- 多云平台支持: Kubernetes 的设计使其能够在多云环境中运行,支持跨多个云服务提供商的容器工作负载。
- 自动部署和滚动更新: Kubernetes 支持自动部署和滚动更新,通过逐步替换旧版本的容器实例来保证应用程序的无缝升级。
- 资源管理: Kubernetes 提供了强大的资源管理和配额机制,确保应用程序能够按照期望的方式使用集群资源。
- 可插拔架构: Kubernetes 架构是高度可插拔的,支持各种插件和扩展,使得用户能够根据需要进行定制和扩展。
架构原则:
- 声明式配置: Kubernetes 采用声明式配置模型,用户通过 YAML 文件描述期望的系统状态,而不是编写详细的操作步骤。这种原则使得系统更加可维护和容易理解。
- 控制循环: Kubernetes 控制器是基于控制循环的,通过不断地监测和调谐系统状态,确保实际状态与期望状态一致。
- 微服务架构: Kubernetes 的设计鼓励微服务架构,通过将应用程序拆分成小而独立的服务,提高了应用程序的可维护性和可扩展性。
- 容器编排: Kubernetes 的主要目标是容器编排,使得用户能够高效地管理和编排容器化的应用程序。
- API 抽象: Kubernetes 提供了丰富的 API 抽象,将底层基础设施的复杂性隐藏起来,为用户提供简单而一致的接口。
- 弹性和自适应: Kubernetes 架构支持自动伸缩和适应变化的工作负载,确保系统在负载波动时保持高可用性和性能。
- 分布式设计: Kubernetes 是一个分布式系统,通过分布式设计来实现高可用性、容错性和可扩展性。
综合来看,Kubernetes 的架构优势和原则使其成为一个灵活、可扩展、弹性且易于管理的容器编排平台,适用于各种规模和类型的应用程序。
九、组件探索
9.1 深入理解 Kubernetes API Server 的实现机制
参考地址:https://blog.csdn.net/qq_36963950/article/details/129759150
-
提供其他模块之间的数据交互和通信的枢纽(其他模块通过 APIServer 查询或修改数据,
只有 APIServer 才直接操作 etcd)提供其他模块之间的数据交互和通信的枢纽(其他模块通过 APIServer 查询或修改数据,只有 APIServer 才直接操作 etcd) -
APIServer
提供 etcd 数据缓存以减少集群对 etcd 的访问。
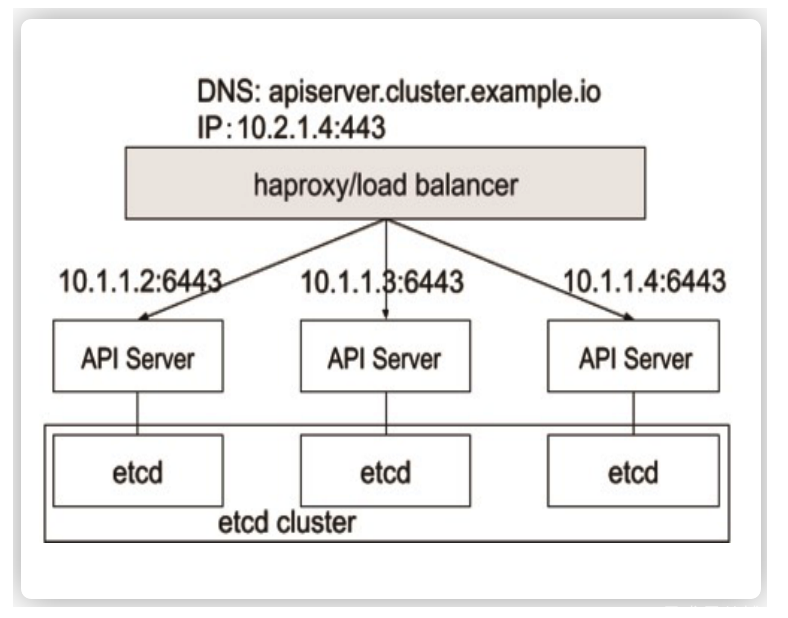
kube-apiserver作为整个Kubernetes集群操作etcd的唯一入口,负责Kubernetes各资源的认证&鉴权,校验以及CRUD等操作,提供RESTful APIs,供其它组件调用:
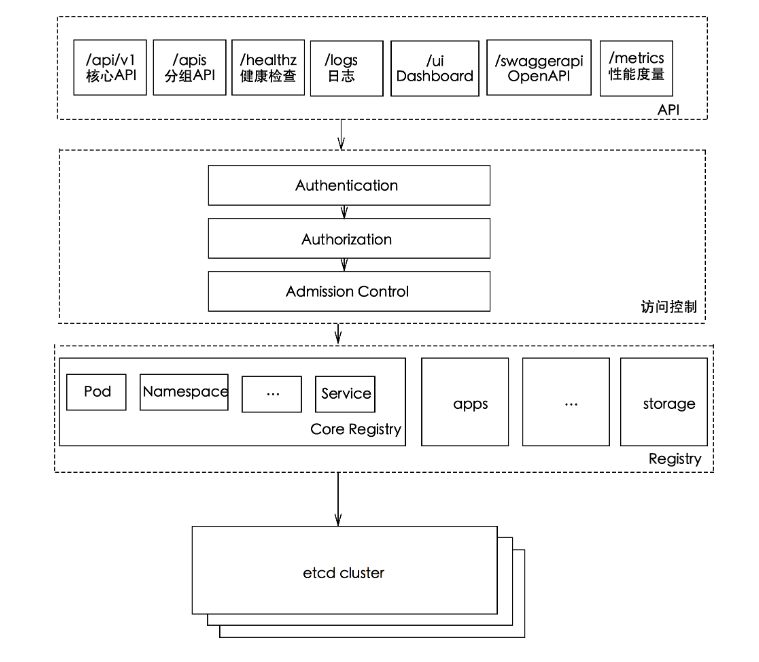
/api/v1 核心API 常用的API资源
/apis 分组API 常用的API资源
/healthz 健康检查接口
/logs 获取日志
/ui dashboard
/swaggerapi OpenAPI
/metrics 性能度量
-
aggregatorServer:负责处理
apiregistration.k8s.io组下的APIService资源请求,同时将来自用户的请求拦截转发给aggregated server(AA) -
kubeAPIServer:负责对请求的一些通用处理,包括:认证、鉴权以及各个内建资源(pod, deployment,service and etc)的REST服务等
-
apiExtensionsServer:负责CustomResourceDefinition(CRD)apiResources以及apiVersions的注册,同时处理CRD以及相应CustomResource(CR)的REST请求(如果对应CR不能被处理的话则会返回404),也是apiserver Delegation的最后一环
-
bootstrap-controller:主要负责Kubernetes default apiserver service的创建以及管理。
9.1.1 API Server 的概念和组件
API Server由3个HTTP Server组成:
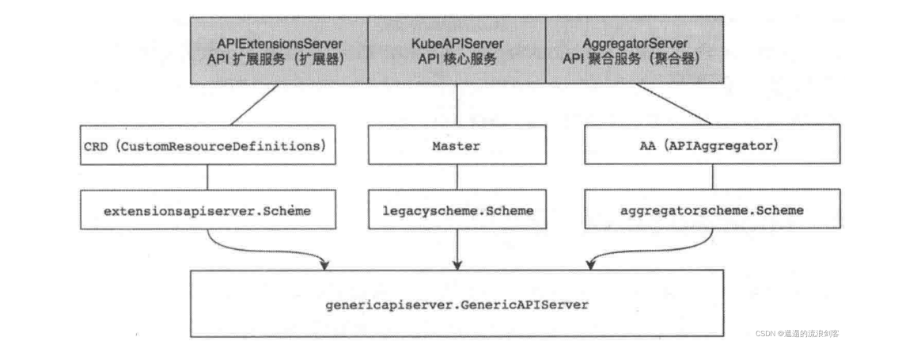
-
AggregatorServer:暴露的功能类似于一个七层负载均衡,将来自用户的请求拦截转发给其他服务器,并且负责整个APIServer的Discovery功能
-
KubeAPIServer:负责处理Kubernetes内建资源的REST请求
-
APIExtensionsServer:负责处理CustomResourceDefinition(CRD)和CustomResource(CR)的REST请求
-
RESTful API: Kubernetes API Server 实现了一个 RESTful 风格的 API,提供对集群资源的增、删、改、查等操作。API 的设计遵循 RESTful 架构原则,资源通过唯一的 URL 进行访问,使用标准的 HTTP 方法(GET、POST、PUT、DELETE)进行操作。
-
etcd 存储: Kubernetes 中采用 etcd 作为后端存储,用于存储集群的配置信息、状态以及资源对象的持久化数据。API Server 通过 etcd 提供的 HTTP/gRPC 接口与 etcd 通信,将资源对象的配置和状态信息存储在 etcd 中。
-
资源对象(Resource Object): Kubernetes 中的所有操作都是围绕资源对象展开的,例如 Pod、Service、Deployment 等。API Server 负责对这些资源对象的 CRUD 操作。资源对象的定义通过 API Server 提供的 OpenAPI 规范进行描述。
-
API Server 认证和授权: API Server 负责对请求进行认证和授权。认证(Authentication)涉及验证请求的发起者身份,而授权(Authorization)则确定该用户是否有权限执行特定的操作。Kubernetes 使用各种认证方式,如证书、Token、OIDC 等,并通过 RBAC(Role-Based Access Control)进行授权。
-
准入控制(Admission Control): API Server 实现了准入控制机制,用于在资源对象被存储到 etcd 之前对其进行验证和修改。准入控制插件可以实施自定义策略,如资源配额、标签规范等。
-
Watch 机制: API Server 支持 Watch 机制,允许客户端订阅资源对象的变更事件。通过 Watch,客户端可以实时获取资源对象的变更通知。
-
API Server 的扩展和插件: Kubernetes 提供了对 API Server 进行扩展的机制,如自定义资源定义(CRD)和自定义 API Server。这使得用户能够根据需要添加新的资源类型和 API。
-
版本控制和演进: Kubernetes API Server 通过版本控制机制来支持集群的升级和演进。不同版本的 API 通过 API Group 和版本号进行区分,保证了对旧版本 API 的向后兼容性。
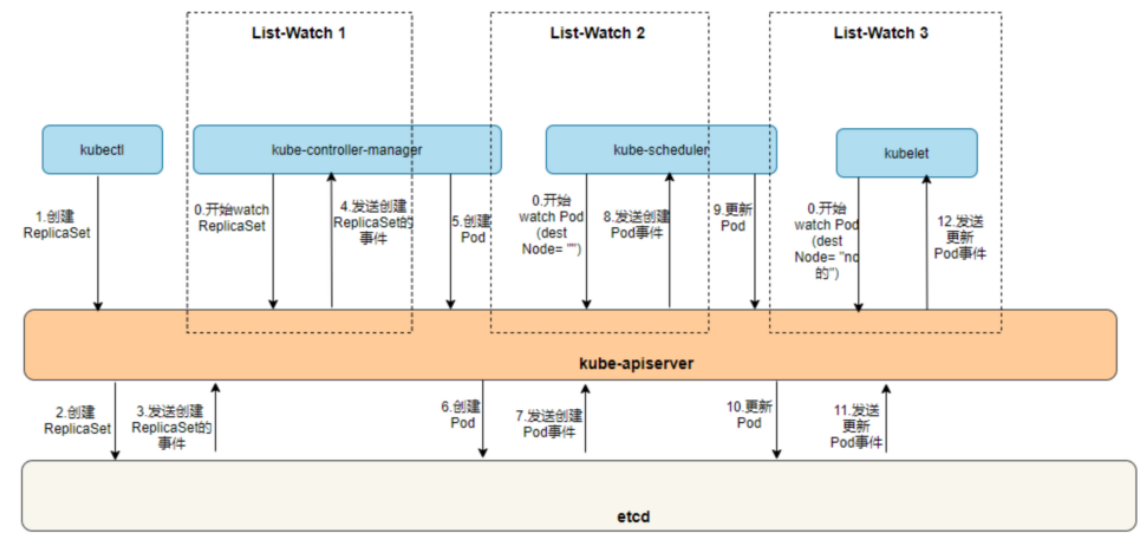
9.1.2 API Server 的 List-Watch 机制
Kubernetes API Server 使用了一种 List-Watch 机制来实现资源对象的监控和更新**。该机制可以用来实现对 Kubernetes 资源对象的实时监控,从而支持实时状态查询和事件响应。
在 Kubernetes 中,每一个 API Server 实例都维护着一个 etcd 集群的连接,通过该连接可以与 etcd 存储中心进行数据交互。当一个客户端向 API Server 发送一个资源对象的请求时,API Server 会首先查询 etcd 存储中心,以获取当前资源对象的状态。如果客户端需要实时监控资源对象的状态,则 API Server 将会启用 List-Watch 机制,将监控请求注册到 etcd 存储中心中,并返回一个带有当前资源对象状态的响应。随着 etcd 存储中心中的资源对象状态发生变化,API Server 将会自动通知客户端,客户端可以通过 Watch 事件机制获取这些状态变化的通知。
我们以一个 Pod 完整的调度过程,来说明一下 API Server 的 List-Watch 机制。
9.1.3 理解 API Server 缓存的工作机制
Kubernetes API Server 缓存的工作机制是为了提高对集群状态的访问效率,减轻 API Server 的负载,并降低对 etcd 存储的访问频率。以下是 API Server 缓存的主要工作机制:
- 缓存的建立: API Server 在启动时会向 etcd 发送一系列的 List 请求,获取所有的资源对象的初始状态。这些状态会被缓存在 API Server 中的本地内存中,形成缓存。
- Watch 机制: 除了初始建立缓存之外,API Server 还通过使用 Watch 机制来保持与 etcd 存储中的集群状态的实时同步。Watch 允许 API Server 订阅 etcd 存储中的资源对象的变更事件。当 etcd 中的数据发生变化时,Watch 会将变更的事件通知到 API Server,API Server 在收到通知后会更新本地的缓存。
- 缓存的更新: 缓存的更新是通过 Watch 机制实现的。当 API Server 接收到 etcd 发送的变更通知时,它会根据通知的内容更新本地缓存中相应资源对象的状态。这样,API Server 中的缓存总是保持与 etcd 存储中的最新状态一致。
- 缓存的利用: 当客户端发起请求时,API Server 首先会检查本地缓存,如果请求的资源对象在缓存中存在且未过期,API Server 将直接返回缓存中的数据,而不必去访问 etcd 存储。这样可以显著减轻对 etcd 的访问压力,提高 API Server 的响应速度。
- 缓存的失效和刷新: 为了保持缓存的实时性,API Server 会定期刷新缓存,或者在接收到 etcd 的 TTL(Time-To-Live)通知时进行刷新。失效的缓存会在下一次请求时被重新从 etcd 中获取最新的数据。
通过这样的缓存机制,API Server 在大多数情况下能够高效地处理客户端的请求,避免频繁地向 etcd 存储发起请求,提高了系统的性能和可伸缩性。但需要注意,由于缓存的存在,API Server 返回的数据可能不是实时的,因此在某些场景下需要谨慎使用。
9.1.4 掌握生产系统中 API Server 的常用配置
以下是 kube-apiserver 的一些常用配置项,每一项都附带一个简单的配置案例:
(1)--advertise-address: 指定 kube-apiserver 用于公告服务的 IP 地址。
yamlCopy code
--advertise-address=192.168.10.100
(2)--secure-port: 指定 kube-apiserver 使用的安全端口。
yamlCopy code
--secure-port=6443
(3)--etcd-servers: 指定 etcd 集群的地址,kube-apiserver 与 etcd 通信。
yamlCopy code
--etcd-servers=https://etcd-server-1:2379,https://etcd-server-2:2379
(4)--service-cluster-ip-range: 指定 Service 的 IP 地址范围。
yamlCopy code
--service-cluster-ip-range=10.96.0.0/12
(5)--kubelet-client-certificate 和 --kubelet-client-key: 指定 kube-apiserver 与 kubelet 通信时使用的客户端证书和密钥。
yamlCopy code--kubelet-client-certificate=/etc/kubernetes/pki/apiserver-kubelet-client.crt
--kubelet-client-key=/etc/kubernetes/pki/apiserver-kubelet-client.key
(6)--authorization-mode: 指定 kube-apiserver 使用的授权模式。
yamlCopy code
--authorization-mode=Node,RBAC
(7)--client-ca-file: 指定用于验证客户端的 CA 证书。
yamlCopy code
--client-ca-file=/etc/kubernetes/pki/ca.crt
(8)--tls-cert-file 和 --tls-private-key-file: 指定 kube-apiserver 使用的 TLS 证书和私钥。
yamlCopy code--tls-cert-file=/etc/kubernetes/pki/apiserver.crt
--tls-private-key-file=/etc/kubernetes/pki/apiserver.key
(9)--enable-admission-plugins: 指定启用的 Admission 控制插件。
yamlCopy code
--enable-admission-plugins=NodeRestriction,PodSecurityPolicy
(10)--insecure-port 和 --insecure-bind-address: 指定 kube-apiserver 启用的非安全端口和绑定地址。注意:不建议在生产环境中使用非安全端口。
yamlCopy code--insecure-port=8080
--insecure-bind-address=0.0.0.0
这只是一小部分 kube-apiserver 的配置选项,具体的配置需求会根据集群的要求和安全策略而有所不同。在生产环境中,请确保仔细了解每个配置项的含义和影响,并根据最佳实践进行配置。
9.1.5 理解 internalVersion、externalVersion 和 storageVersion
API Server 使用了三个不同的“版本”概念:
(1)internalVersion(内部版本):
- 内部使用: 这是 Kubernetes 内部使用的版本。当 API Server 处理集群中的对象时,它使用内部版本来了解对象的结构和如何处理它们。
(2)externalVersion(外部版本): - 与用户交互: 这是与用户和外部系统交互时使用的版本。当你使用 kubectl 或其他工具与 Kubernetes 通信时,你使用的就是外部版本。
(3)storageVersion(存储版本): - 在存储中的版本: 这是 API 对象在集群存储中的版本。它帮助 Kubernetes 在不同的时间点存储和检索对象,即使对象定义发生变化。
原理解释:
- 内部版本(internalVersion) 是 Kubernetes 内部用于处理对象的“内部语言”,类似于对象的内部数据结构。
- 外部版本(externalVersion) 是与用户和外部系统通信时使用的“外部语言”,使得用户能够方便地与 Kubernetes 交互。
- 存储版本(storageVersion) 确保 Kubernetes 能够正确地存储和检索对象,即使对象定义在时间上发生了变化。
这三个版本(internalVersion、externalVersion、storageVersion)在 Kubernetes 中的使用环节分别是:
(1)internalVersion(内部版本):
- 使用环节: 在 Kubernetes 内部处理 API 对象时使用。
- 具体场景: 当 Kubernetes 在集群内部进行对象的创建、更新、删除等操作时,它使用的是内部版本。这个版本定义了对象的内部结构和处理规则,是 Kubernetes 运行时内部使用的“语言”。
(2)externalVersion(外部版本):
- 使用环节: 与用户和外部系统进行交互时使用。
- 具体场景: 当用户通过 kubectl 或其他工具与 Kubernetes 通信时,他们使用的是外部版本。这个版本定义了用户友好的接口,使得用户能够方便地与集群交互,而不需要深入了解集群的内部实现细节。
(3)storageVersion(存储版本):
- 使用环节: 在 API 对象在存储中进行持久化存储和检索时使用。
- 具体场景: 当 Kubernetes 将 API 对象存储到持久化存储系统(如 etcd)中,以及从存储中检索对象时,使用的是存储版本。这个版本确保 Kubernetes 可以正确地存储和检索对象,即使对象定义发生变化。
9.1.6 conversion(版本转换)
作用:
- 版本转换: 允许 Kubernetes 在不同 API 版本之间进行对象的转换。这是因为 Kubernetes 集群中可能存在多个 API 版本,例如 v1 和 v1beta1,Conversion 机制确保在这些版本之间平稳地转换 API 对象。
- API 对象演进: 提供了一种机制,支持 API 对象的演进。当需要对 API 对象的定义进行更改时,Conversion 机制确保这些变化不会中断现有对象的使用,使得集群可以逐步接受新的对象定义。
案例:
- 版本升级: 在升级 Kubernetes 集群的过程中,可能需要将旧版本的 API 对象转换为新版本,以适应集群的升级。
- 对象结构变更: 当需要向 API 对象引入新的字段、属性或修改现有结构时,Conversion 机制允许逐渐将现有对象转换为新的结构,而不破坏现有的服务和应用。
管理员关注的问题:
- 兼容性: 在升级集群或修改 API 对象定义时,管理员需要确保新版本与旧版本之间有良好的兼容性,以避免引入不必要的中断。
- 数据一致性: Conversion 过程中需要注意数据的一致性,确保对象的转换不会导致数据丢失或不一致的情况。
- 监控和日志: 管理员需要监控 API Server 的性能和健康状况,同时查看 Conversion 过程的日志,以及时发现和解决问题。
- 测试和回滚: 在进行重大版本变更之前,进行充分的测试,确保 Conversion 机制正常工作。同时,准备好回滚计划,以防出现问题。
9.1.7 api-server监控关注点
(1)健康检查(Health Checks):
确保 API Server 的健康检查端点(例如 /healthz)正常响应。这可以通过定期发送 HTTP GET 请求并检查返回状态码来实现。
(2)性能指标(Performance Metrics):
监控 API Server 的性能指标,包括请求延迟、处理请求的吞吐量、HTTP 状态码分布等。Prometheus 是一个流行的监控系统,可以用于收集和查询这些指标。
(3)日志和审计(Logs and Auditing):
分析 API Server 的日志以检测潜在问题,并确保审计日志记录启用,以便跟踪对集群的操作和事件。
(4)连接数和并发请求(Connection Count and Concurrent Requests):
监控 API Server 的连接数和并发请求,以确保它能够处理集群中可能的高负载情况。
(5)错误率和异常(Error Rate and Exceptions):
追踪 API Server 处理请求时的错误率,以及任何异常情况的发生。这可以帮助及早发现问题并进行故障排除。
(6)权限和访问控制(Authorization and Access Control):
检查 API Server 的 RBAC 规则和其他访问控制配置,确保它们符合预期,并避免潜在的安全风险。
(7)集群事件(Cluster Events):
监控集群事件,包括节点的加入和退出、Pod 的调度和删除等,以确保集群状态的稳定性。
(8)API Server 高可用性(API Server High Availability):
确保 API Server 的高可用性,监控活跃和备用节点的状态,以及任何切换发生的情况。
(9)版本和安全补丁(Version and Security Patches):
确保 API Server 使用的 Kubernetes 版本是最新的,并及时应用安全补丁以防止已知的漏洞。
(10)资源利用率(Resource Utilization):
监控 API Server 的资源利用率,包括 CPU、内存和存储,以确保足够的资源可用于其正常运行。
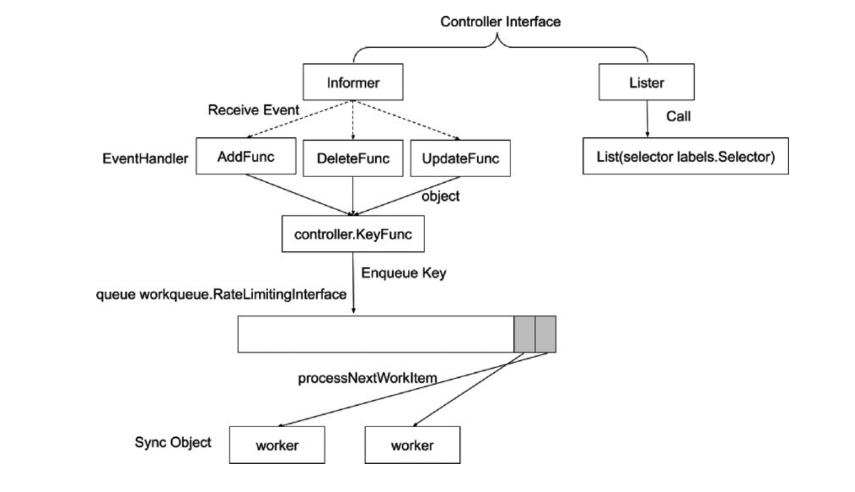
9.1.8 Informer的内部机制(管理和跟踪 API 对象)
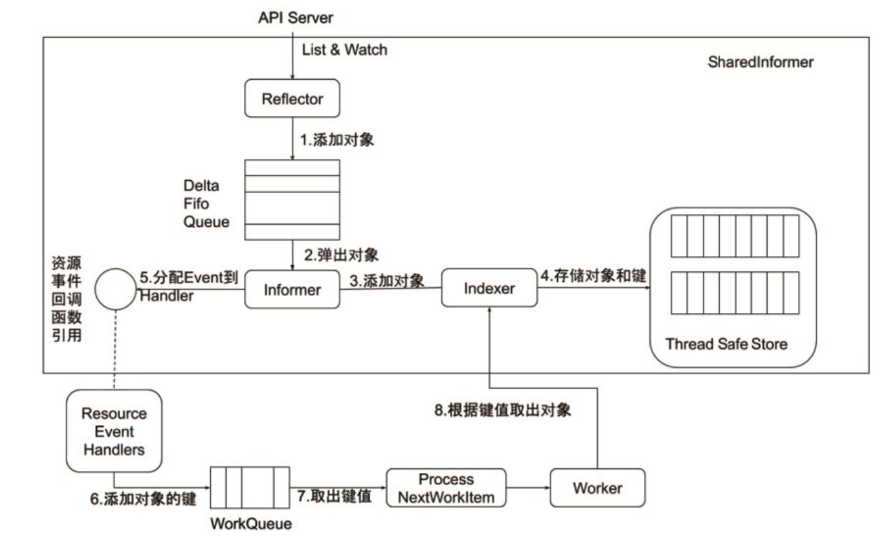
在 Kubernetes 中,Lister 和 Informer 是用于管理和跟踪 API 对象的两个关键概念,它们通常用于开发控制器(Controller)或其他需要实时监控集群状态的组件。下面是对这两个概念的理解,以及原理和案例分析:
9.1.8.1 Lister(列表器)
原理解释:
- Lister 是一个用于缓存 Kubernetes 集群中 API 对象的工具。它通过调用 Kubernetes API Server 来获取对象的列表,并将这些对象的信息缓存在本地。当控制器或其他组件需要访问对象时,它可以直接从本地缓存中获取,而不必每次都向 API Server 发送请求。
案例分析:
- 假设你开发了一个控制器,需要监控 Pod 对象。使用 Lister,你可以定期从 API Server 获取 Pod 列表并缓存到本地。当控制器需要检查 Pod 的状态时,可以直接从 Lister 缓存中获取,而不必每次都向 API Server 请求。
9.1.8.2 Informer(通知器)
原理解释:
- Informer 是在 Lister 的基础上构建的更高级别的工具,它除了缓存对象列表外,还能够实时监听对象的变更。当对象在集群中发生变化时,Informer 可以接收到通知,并自动更新本地缓存。这使得你可以更及时地获取对象的最新状态。
案例分析:
- 使用 Informer,你可以创建一个实时监控 Pod 变化的组件。当 Pod 被创建、更新或删除时,Informer 可以即时通知你,并更新本地缓存。这使得你的控制器或应用程序可以更实时地响应集群中的变化。
9.1.8.3 综合案例
假设你的应用需要实时监控集群中的 Service 对象,并在 Service 发生变化时执行一些操作。你可以使用 Lister 和 Informer 的组合:
(1)Lister:
- 定期从 API Server 获取 Service 列表,并将其缓存到本地 List 中。
(2)Informer:
- 创建一个 Informer,监听 Service 对象的变更。
- 当 Service 对象在集群中被创建、更新或删除时,Informer 可以接收到通知,并自动更新 List 中的对应条目。
(3)应用程序逻辑:
- 你的应用程序可以从 List 中直接获取 Service 列表,以获取当前的状态。
- 同时,通过监听 Informer 的事件,你的应用程序可以及时响应 Service 对象的变更。
总结:
Lister 和 Informer 提供了在 Kubernetes 中高效管理和跟踪 API 对象的机制。它们减少了频繁向 API Server 发送请求的开销,同时通过本地缓存和实时通知机制,使得开发者能够更方便地编写控制器或其他需要实时监控集群状态的组件。
对于二次开发者(开发自定义控制器、操作符等)来说,使用 Lister 和 Informer 取决于具体的业务场景和需求:
- Lister: 如果在应用中只需要定期获取 API 对象列表而不需要实时感知对象的变更,那么使用 Lister 可能就足够了。Lister 提供了一个本地缓存,可以更高效地检索对象信息。
- Informer: 如果应用需要实时感知和响应 API 对象的变更,比如在对象创建、更新或删除时立即执行某些操作,那么使用 Informer 是更合适的选择。Informer 提供了一种机制,通过事件通知及时了解对象的变更。
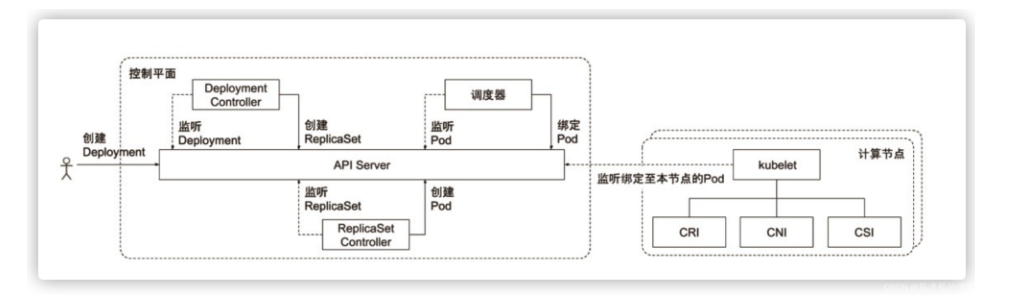
控制器与其他组件协同工作原理:
9.1.9 掌握基于 API Server Webhook 的整合方案
基于 API Server Webhook 的整合方案是一种强大的 Kubernetes 扩展机制,它允许你在 API Server 处理请求之前或之后执行自定义的逻辑。这种机制可以用于鉴权、准入控制以及其他一些自定义扩展。下面是基于 API Server Webhook 的整合方案的基本原理和步骤:
基本原理:
- Admission Controller: API Server Webhook 通常作为 Admission Controller 的一部分。Admission Controller 是 Kubernetes API 请求处理流程中的一个组件,用于在对象被存储到 etcd 之前或之后执行自定义逻辑。
- Webhook 注册: Webhook 需要在 Kubernetes API Server 中注册。这通常包括 Webhook 的地址(Endpoint)、证书等信息。API Server 将请求转发到注册的 Webhook 服务。
- Webhook 逻辑: Webhook 服务接收到 API 请求后,执行自定义的逻辑,例如鉴权、准入控制等。Webhook 可以拒绝请求、修改请求内容或执行其他操作。
- 响应 API Server: Webhook 将处理结果响应给 API Server。如果是准入控制,API Server 根据 Webhook 的响应来决定是否接受或拒绝请求。
Webhook 逻辑实现:
(1)Webhook 逻辑是指你自己实现的处理请求的代码,通常是一个独立的服务,可以使用任何支持 HTTP 协议的框架。这个服务应该能够接收来自 Kubernetes API Server 的请求,并根据业务逻辑进行处理。
(2)注册到 API Server:
将你的 Webhook 服务的信息注册到 Kubernetes API Server,这样 API Server 在处理相关请求时会将请求转发到你的 Webhook 服务。注册通常涉及到创建 ValidatingWebhookConfiguration 或 MutatingWebhookConfiguration 对象,并将其应用到 Kubernetes 集群中。
(3)处理逻辑流程:
当有相关操作发生(比如创建或更新 Pod 对象)时,API Server 将请求发送到已注册的 Webhook 服务。你的 Webhook 服务接收到请求后,执行自定义的逻辑,可以进行鉴权、准入控制等操作。
(4)响应 API Server:
Webhook 服务处理完请求后,需要向 API Server 发送响应,告诉 API Server 请求是否被接受或拒绝。API Server 根据 Webhook 的响应来决定是否继续处理请求。
9.1.9.1 简化的 ValidatingWebhookConfiguration案例(注册)
场景:
假设我们有一个业务需求:在 Kubernetes 中,只允许在命名空间(Namespace)为 example 的情况下创建和更新 Pod 对象。为了实现这一需求,我们可以使用 ValidatingWebhook 来拦截这些请求并执行自定义的鉴权逻辑。
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingWebhookConfiguration
metadata:
name: example-webhook
webhooks:
- name: webhook.example.com
clientConfig:
service:
name: example-webhook-svc
namespace: default
path: "/"
caBundle: <CA_BUNDLE>
rules:
- operations: [ "CREATE", "UPDATE" ]
apiGroups: [ "" ]
apiVersions: [ "v1" ]
resources: [ "pods" ]
namespaceSelector:
matchExpressions:
- key: example-namespace
operator: In
values: ["true"]
Webhook 逻辑示例:
假设我们使用一个简单的 Webhook 服务(以 Flask 框架为例):
from flask import Flask, request, abort
app = Flask(__name__)
@app.route("/", methods=["POST"])
def validate_pod():
admission_review = request.get_json()
namespace = admission_review["request"]["namespace"]
operation = admission_review["request"]["operation"]
resource = admission_review["request"]["resource"]
if namespace == "example" and operation in ["CREATE", "UPDATE"] and resource == "pods":
# 鉴权通过,允许请求
return {"response": {"allowed": True}}
# 鉴权失败,拒绝请求
return {"response": {"allowed": False, "status": {"reason": "Namespace not allowed"}}}
if __name__ == "__main__":
app.run(host="0.0.0.0", port=80)
在这个示例中,Webhook 服务接收到 Pod 对象的创建或更新请求后,检查请求的命名空间是否为 example,如果是,则允许请求;否则,拒绝请求并返回相应的拒绝原因。
9.19.10 基于鉴权准入打造多租户k8s平台思路
(1)理解 Kubernetes 认证和鉴权机制
-
案例:
-
认证配置:
- 部署 Kubernetes 集群时,使用
--authentication-token-webhook标志启用令牌认证。 - 配置 kube-apiserver 的
--token-auth-file选项,指向一个文件,该文件包含用户令牌和与之关联的用户身份信息。
- 部署 Kubernetes 集群时,使用
-
鉴权配置:
-
启用 RBAC(Role-Based Access Control):
yamlCopy codeapiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: tenant-admin rules: - apiGroups: [""] resources: ["pods", "deployments"] verbs: ["get", "list", "create", "update", "delete"] -
创建角色绑定:
yamlCopy codeapiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: tenant-admin-binding subjects: - kind: User name: "user@example.com" apiGroup: rbac.authorization.k8s.io roleRef: kind: ClusterRole name: tenant-admin apiGroup: rbac.authorization.k8s.io
-
-
(2)整合企业认证系统
-
案例:
-
ldap配置:
-
在 kube-apiserver 中配置 ldap:
1. # sudo nano /etc/kubernetes/manifests/kube-apiserver.yaml 2. 添加 LDAP 配置,在 spec.containers.command 部分添加如下 LDAP 配置: apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: component: kube-apiserver tier: control-plane name: kube-apiserver namespace: kube-system spec: containers: - command: - kube-apiserver - --oidc-issuer-url=https://ldap-server.com # 替换为你的 LDAP 服务器的 URL - --oidc-client-id=your-client-id # 替换为你的 LDAP 客户端 ID - --oidc-username-claim=username # 替换为 LDAP 提供者返回的用户标识字段 # 其他参数... image: k8s.gcr.io/kube-apiserver:v1.17.3 # ... -------------------------------------------------------------------------- # 对接sso配置 apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: component: kube-apiserver tier: control-plane name: kube-apiserver namespace: kube-system spec: containers: - command: - kube-apiserver - --oidc-issuer-url=https://sso-provider.com # 替换为你的 SSO 提供者的 OIDC 端点 - --oidc-client-id=your-client-id # 替换为你在 SSO 中创建的 OIDC 客户端 ID - --oidc-client-secret=your-client-secret # 替换为你在 SSO 中创建的 OIDC 客户端密钥 # 其他参数... image: k8s.gcr.io/kube-apiserver:v1.17.3 # ...
确保替换
--oidc-issuer-url、--oidc-client-id和--oidc-username-claim中的值为你 LDAP 服务器的实际信息。- 保存配置文件与重新加载 kube-apiserver
sudo systemctl restart kubelet -
-
(3) 配置 RBAC 规则
- 案例:
- RBAC 规则配置:
- 为每个租户创建独立的角色和角色绑定,限制其访问权限。
- 在
Role和RoleBinding中定义规则,确保只有授权的用户可以执行特定的操作。
- RBAC 规则配置:
(4)使用命名空间进行隔离
- 案例:
- 命名空间配置:
- 为每个租户创建独立的命名空间,例如
tenant-1,tenant-2。 - 使用 NamespaceQuota 特性限制每个命名空间的资源使用量。
- 为每个租户创建独立的命名空间,例如
- 命名空间配置:
(5)Webhook 鉴权
- 案例:
- Webhook 服务配置:
- 部署 Webhook 服务,接收来自 kube-apiserver 的请求。
- 实现鉴权逻辑,例如检查请求的源命名空间是否在白名单中。
- 将 Webhook 配置添加到 kube-apiserver 中。
- Webhook 服务配置:
(6) 网络策略和 Pod 安全策略
- 案例:
- 网络策略配置:
- 使用 Network Policies 限制 Pod 之间的通信。
- 例如,阻止来自其他命名空间的流量访问某个 Pod。
- Pod 安全策略配置:
- 配置 PodSecurityPolicy,限制容器的权限,确保安全标准得到满足。
- 网络策略配置:
(7)使用自定义资源定义(CRD)
-
案例:
-
CRD 定义和控制器配置
-
定义一个 Custom Resource Definition(CRD)表示租户:
xxxxxxxxxx yamlCopy codeapiVersion: apiextensions.k8s.io/v1kind: CustomResourceDefinitionmetadata: name: tenants.example.comspec: group: example.com names: kind: Tenant plural: tenants singular: tenant scope: Namespaced versions: - name: v1 served: true storage: true schema: openAPIV3Schema: type: object properties: name: type: string -
编写一个控制器(Controller)监控这个 CRD,根据变更动态地管理租户相关的配置。
-
-
(8) 监控和审计
-
案例:
-
Prometheus 和 Grafana 集成:
-
部署 Prometheus 和 Grafana,监控 Kubernetes 的性能和安全指标。
yamlCopy codeapiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: kube-apiserver namespace: monitoring spec: selector: matchLabels: component: apiserver endpoints: - port: https path: /metrics
-
-
审计日志配置:
-
配置 kube-apiserver 以生成审计事件:
yamlCopy codeapiVersion: v1 kind: ConfigMap metadata: name: audit-policy namespace: kube-system data: audit.yaml: | apiVersion: audit.k8s.io/v1 kind: Policy rules: - level: Metadata -
将审计日志导入到集中的日志系统进行分析和审计。
-
-
(9) 教育和培训
-
案例:
-
团队培训计划
-
制定培训计划,覆盖 Kubernetes 安全最佳实践、RBAC 规则设置等。
plaintextCopy code# RBAC Training Agenda 1. Introduction to RBAC in Kubernetes 2. Creating Roles and RoleBindings 3. RBAC Best Practices 4. Advanced RBAC Configurations 5. Hands-on Labs
-
-
沙箱环境:
-
创建一个沙箱环境,供团队成员练习和测试安全措施。
shellCopy code# Create a RBAC Sandbox Namespace kubectl create namespace rbac-sandbox # Apply RBAC Policies for Sandbox kubectl apply -f rbac-policies.yaml -n rbac-sandbox
-
-
这应该更全面地满足你的需求,每一点都包含详细的解释和案例。如果还有其他需要进一步解释的地方,请告诉我。
9.2 Controller Manager
- Controller Manager 是 集群的大脑,是确保整个集群动起来的关键;
- 作用是确保 Kubernetes 遵循声明式系统规范,确保系统的真实状态(Actual State)与用户定义的期望状态(Desired State)一致;
- Controller Manager 是多个控制器的组合,每个 Controller 事实上都是一个control loop,负责侦听其管控的对象,当对象发生变更时完成配置;
- Controller 配置失败通常会触发自动重试,整个集群会在控制器不断重试(Rate Limit Queue)的机制下确保 最终一致性( Eventual Consistency)
参考分类介绍:https://www.jianshu.com/p/491603f8ce98
9.4 Scheduler
Scheduler是一种特殊的 Controller,工作原理与其他控制器无差别。
Scheduler 的职责:监控当前集群所有未调度的 Pod,并且获取当前集群所有节点的健康状况和资源使用情况,为待调度 Pod 选择最佳计算节点,完成调度。
调度阶段分为:
- Predict:过滤不能满足业务需求的节点,如资源不足、端口冲突等。
- Priority:按既定要素将满足调度需求的节点评分,选择最佳节点。
- Bind:将计算节点与 Pod 绑定,完成调度。

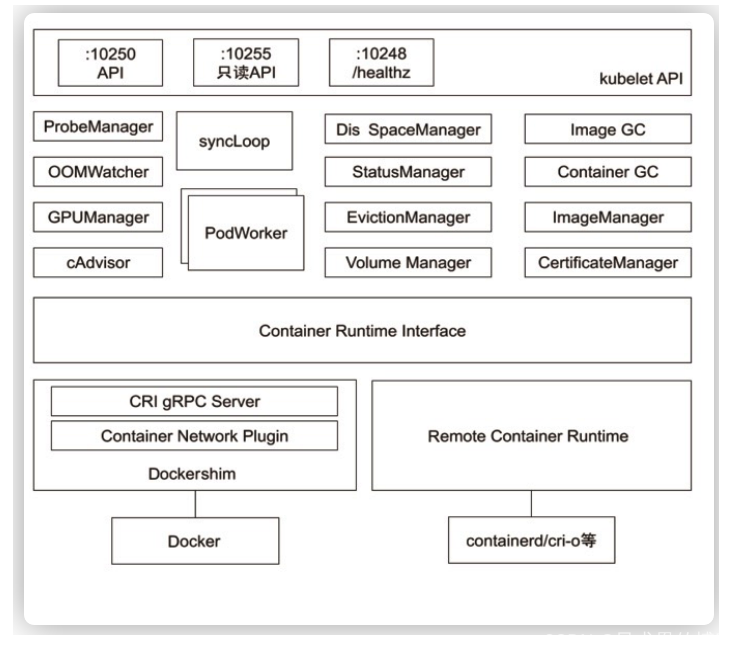
9.5 kubelet
Kubernetes 的初始化系统(init system)
• 从不同源获取 Pod 清单,并按需求启停 Pod 的核心组件:
• Pod 清单可从本地文件目录,给定的 HTTPServer 或 Kube-APIServer 等源头获取;
• Kubelet 将运行时,网络和存储抽象成了 CRI,CNI,CSI
Kubelet 是 Kubernetes 中的一个关键组件,负责管理节点上的容器。在 Kubernetes 中,容器运行时(Container Runtime)、网络插件(Container Network Interface,CNI)和存储插件(Container Storage Interface,CSI)被抽象成了三个独立的接口,分别是 CRI、CNI 和 CSI。
(1)CRI(Container Runtime Interface)容器运行时接口: CRI 是一个用于连接 Kubelet 和容器运行时的接口。它定义了 Kubelet 如何与容器运行时进行通信,以便创建、销毁和管理容器。通过使用 CRI,Kubernetes 不再依赖于特定的容器运行时,而可以支持多种容器运行时,如 Docker、Containerd、CRI-O 等。
(2)CNI(Container Network Interface)容器网络接口: CNI 定义了容器如何与网络进行交互的标准接口。它使得 Kubernetes 中的 Pod 能够通过网络进行通信。CNI 插件负责配置 Pod 中的容器网络,实现容器之间的通信以及与外部网络的连接。Kubelet 使用 CNI 接口来调用相应的网络插件,从而实现网络的配置和管理。
(3)CSI(Container Storage Interface)容器存储接口: CSI 定义了容器如何与存储进行交互的标准接口。它使得容器可以访问持久化存储,并允许管理员使用不同的存储后端。Kubelet 使用 CSI 接口来调用相应的存储插件,从而实现容器与持久化存储的集成。
总的来说,这三个接口的抽象使得 Kubernetes 在容器运行时、网络和存储方面变得更加灵活和可扩展。通过定义清晰的接口,Kubernetes 可以支持不同的实现,使得用户能够选择最适合其需求的容器运行时、网络和存储解决方案。
9.5.1 深入理解 Kubelet如何运行你的 Pod(CRI、CNI、CSI)
总体来说,Kubelet 在运行 Pod 时的流程如下:
(1)Pod 配置加载: Kubelet 从 API Server 获取 Pod 的配置信息。
(2)CRI 接口调用: Kubelet 通过 CRI 与容器运行时交互,发出容器的创建和管理命令。
(3)CNI 接口调用: Kubelet 通过 CNI 与网络插件交互,配置容器间的网络连接。
(4)CSI 接口调用: 如果 Pod 需要持久化存储,Kubelet 通过 CSI 与存储驱动程序交互,为容器提供存储卷。
(5)容器监控: Kubelet 负责监控容器的运行状态,并在需要时进行重新启动或删除。
这些抽象层使得 Kubelet 能够与各种容器运行时、网络插件和存储系统进行集成,为 Pod 提供一致的运行环境。理解这些概念有助于更深入地了解 Kubelet 如何管理和运行你的 Pod。
• 负责汇报当前节点的资源信息和健康状态;
• 负责 Pod 的健康检查和状态汇报。
9.5.1.1 POD创建过程
(1)kubectl将YAML发送到API
(2)Pod存储在etcd 中
(3)调度程序分配一个节点(此时Pod配置清单文件存储在 etcd 中,节点内并没有该 pod
(4)kubelet开始创建Pod
(5)kubelet将创建容器的委托委派给CRI
(6)kubelet代表将容器连接到CNI的网络
(7)CNI分配一个IP地址
(8)检查探针
(9)kubelet将IP地址报告给控制平面
(10)此时Pod就已经创建完成了,除非Pod是服务的一部分,否则Kubernetes会在此处停止。如果Pod属于服务,Kubernetes会创建一个端点endpoint-它连接Pod的IP地址和端口(targetPort)。将端点endpoint添加到端点(对象object)。
9.5.1.2 POD销毁过程
(1)用户删除 Pod 或应用更新:
用户通过 kubectl delete 或其他手段删除 Pod,或者进行应用程序的更新。
(2)API Server 接收删除请求:
API Server 接收到删除请求后,更新 Pod 对象的状态,并将删除事件通知给其他相关组件。
(3)Termination Grace Period(可选):
如果 Pod 中的容器定义了 Termination Grace Period(优雅终止期),Kubelet 将发送信号给容器,告知其开始关闭准备。
(4)Cordon 和 Drain(可选):
在进行节点维护或缩容时,可能会使用 kubectl cordon 和 kubectl drain 等命令,确保节点上的 Pod 能够安全地迁移或终止。
(5)容器终止:
Kubelet 收到删除事件后,停止容器运行时,结束 Pod 中的容器实例。
(6)CNI 回收网络:
如果使用了网络插件,CNI 可能会回收 Pod 使用的网络资源。
(7)CSI 回收存储(可选):
如果使用了存储插件,CSI 可能会回收 Pod 使用的存储资源。
(8)Pod 状态更新:
API Server 更新 Pod 的状态,将其标记为 Terminating。
(9)Pod 最终删除:
一旦所有容器和资源被清理,API Server 最终删除 Pod 对象。
9.5.1.3 Pod的生命周期
(1)Pending(等待中):
Pod被创建但还未被调度到节点上运行。
可能在下载容器镜像或等待其他资源的创建阶段。
初始化容器可能在这个阶段执行,完成一些预处理工作。
(2)Running(运行中):
Pod已被调度并在节点上运行。
Pod中的容器正在执行,可能包括应用程序的启动和请求处理。
同时,初始化容器可能完成它们的任务。
(3)Succeeded(成功):
Pod中的所有容器已成功完成任务并正常退出。
适用于批处理任务等,成功完成后进入此状态。
(4)Failed(失败):
Pod中的容器发生错误或非正常退出。
例如,容器内部发生错误或依赖资源无法访问。
这可能触发重启策略,导致Pod重新进入Running状态或继续失败。
(5)Unknown(未知):
Pod的状态无法确定,可能是由于与Pod所在节点的通信问题。
这可能发生在节点失联或调度程序无法与节点通信的情况下。
常见的状态变迁情况:
-
创建Pod,进入Pending状态,等待调度。
-
被调度后,进入Running状态,容器开始执行。
-
如果所有容器成功完成,Pod进入Succeeded状态。
-
如果容器发生错误,Pod进入Failed状态。
-
节点通信问题可能导致进入Unknown状态。
其他考虑因素:
- 初始化容器(Init Containers): 在Pod中定义的初始化容器可能在Pending阶段执行,完成一些初始化任务。
- 探针(Probes): 定义在Pod中的探针可用于监测容器的运行状况,影响状态变迁。
- PreStart 和 PostStop 钩子: 这些钩子可以影响容器的启动和停止过程,对Pod的生命周期产生影响。
- 删除(Termination): Pod被删除时,其状态会相应地变化,包括执行prestop钩子。
- 总的来说,Pod的生命周期是一个动态的过程,受到多种因素的影响,包括容器的运行状况、资源可用性、节点通信等。探针
9.5.2 全方位的 CSI 一站式解决方案:Rook
.io/docs/rook/latest-release/Getting-Started/intro/
9.6 kubectl、kubeconfig与apiserver关系
- kubectl 是一个 Kubernetes 的命令行工具,它允许Kubernetes 用户以命令行的方式与 Kubernetes交互,其默认读取配置文件 ~/.kube/config。
- kubectl 会将接收到的用户请求转化为 rest 调用以rest client 的形式与 apiserver 通讯,具体过程可以通过-v 9查看。
kubectl get pods lxcfs-zgdhn -v 9
- apiserver 的地址,用户信息等配置在 kubeconfig。
9.7 etcd存储
Raft 是一种分布式一致性协议,用于在一个分布式系统中维护一致的日志副本。在 Kubernetes 中,etcd 是一个高可用的分布式键值存储系统,它使用 Raft 协议来确保数据的一致性和高可用性。
以下是 Raft 协议的基本工作机制和 etcd 的实现原理:
9.7.1 Raft 协议的工作机制
etcd 是基于 raft算法的分布式键值数据库,生来就为集群化而设计的,由于Raft算法在做决策时需要超半数节点的投票,所以etcd集群一般推荐奇数节点,如3、5或者7个节点构成一个集群。
(1)Leader 选举
- Raft 将节点分为 Leader、Follower 和 Candidate 三种状态。在初始阶段,所有节点都是 Follower。当一个节点超时未收到来自 Leader 的消息时,它会变为 Candidate,并发起一次选举。节点会向其他节点发送选举请求,并通过投票来选出新的 Leader。
(2)日志复制
- Leader 负责接收客户端的写请求,并将这些请求追加到自己的日志中。一旦 Leader 确认一条日志条目已经被大多数节点复制,它将通知其他节点复制该日志。其他节点接收到 Leader 的消息后,复制相同的日志,确保所有节点的日志保持一致。
(3)一致性检查
- Raft 协议通过维护一个递增的 commitIndex 来保证节点之间的一致性。Leader 在提交一条日志条目时,会将 commitIndex 递增,并通知其他节点。其他节点只有在复制了这个 commitIndex 对应的日志后,才会应用该日志到自己的状态机中。
[etcd 的一致性协议依赖两个时间参数]
–heartbeat-interval:心跳间隔,即 leader 通知member 并保证自己 leader 地位的心跳,默认是 100ms,这个应该设置为节点间的 RTT 时间。
–election-timeout:选举超时时间,即 member 多久没有收到 leader 的回应,就开始自己竞选 leader,默认超时时间为 1s
(4)Leader 保持心跳
- Leader 定期向所有节点发送心跳消息,以维持其领导地位。如果一个 Follower 超过一定时间没有收到 Leader 的消息,它将发起一次新的选举。
9.7.2 etcd 的实现原理
(1) 数据存储
- etcd 是一个分布式键值存储系统,用于存储配置信息、元数据等。每个节点都存储相同的数据副本,确保数据的一致性。Raft 协议用于管理数据的复制和一致性。
除了网络延迟,磁盘 IO 也严重影响 etcd 的稳定性, etcd需要持久化数据,对磁盘速度很敏感,强烈建议对 ETCD 的数据挂 SSD。
(2) Leader 选举和日志复制
- etcd 的每个节点运行 Raft 协议,负责数据的复制和一致性。当一个节点启动时,它会尝试成为 Raft 集群的 Leader,并负责处理客户端请求和复制数据。
(3) Watch 机制
- etcd 支持 Watch 机制,允许客户端注册对数据变更的监听。当数据发生变更时,etcd 将通知相关的客户端,使其能够实时获取系统状态的变化。
(4) 分布式事务
- etcd 提供了分布式事务支持,允许客户端在多个数据项上执行原子性操作。这通过 Raft 协议的一致性保证来实现。
(5) 高可用性
- etcd 的多节点部署确保了高可用性。Raft 协议的 Leader 选举和数据复制机制使得即使其中一个节点发生故障,系统仍然能够正常运行。
9.7.3 etcd监控关注点
在 Kubernetes 集群中,etcd 的监控是确保集群正常运行和及时发现问题的重要方面。以下是监控 etcd 时需要关注的主要关键点:
(1)节点健康状况:
确保 etcd 集群中的每个节点都处于健康状态。监控节点的 CPU 使用率、内存使用率、磁盘使用率以及网络状况,及时发现潜在的硬件或网络问题。
(2)集群状态和成员数:
监控 etcd 集群的状态,确保集群正常运行。关注集群的成员数,以及是否有成员在变化(加入或退出)。可以使用 etcdctl 或 Kubernetes API 查询集群状态。
(3)选举状态:
在 etcd 集群中,Leader 负责协调写入操作。监控选举状态,确保 Leader 能够稳定地选出并保持稳定。Leader 的频繁变化可能是集群问题的一个迹象。
(4)请求延迟和吞吐量:
监控 etcd 请求的延迟和吞吐量。确保请求在合理的时间内得到处理,并且 etcd 能够处理集群中的负载。使用 Prometheus 等监控工具来收集和分析这些指标。
(5)写入和快照:
关注 etcd 的写入操作和快照生成。写入操作应该在集群中均匀分布,而快照生成不应该影响正常的 etcd 操作。监控写入操作的数量、速率以及快照生成的频率。
(6)存储使用情况:
监控 etcd 存储的使用情况,包括数据和日志的存储。避免存储满了导致 etcd 无法正常工作。设置适当的存储配额,避免 etcd 存储占用过多空间。
(7)TLS 握手和认证:
监控 etcd 的 TLS 握手过程,确保加密通信正常。此外,关注 etcd 的认证和授权过程,确保只有授权的实体能够访问 etcd。
(8)事件和告警:
设置适当的事件和告警规则,以便及时发现并响应 etcd 中的问题。通过 Prometheus、Grafana 等工具建立可视化的监控仪表板。
(9)版本兼容性:
监控 etcd 版本与 Kubernetes 版本的兼容性。确保 etcd 的版本与 Kubernetes 的版本相匹配,以避免出现不兼容性问题。
9.7.3 配置优化
(1)调整存储性能:
配置 etcd 存储性能参数,包括 --quota-backend-bytes 和 --max-request-bytes。这些参数可以根据集群的规模和负载进行调整,以提高存储性能。
(2)调整选举和心跳参数:
优化 etcd 的选举参数,如 --election-timeout 和 --heartbeat-interval。合理的选举和心跳参数能够提高 etcd 集群的稳定性。
(3)启用快照压缩:
启用 etcd 的快照压缩功能,可以减小快照文件的大小,减少磁盘空间的占用。配置 --snapshot-count 参数以控制快照的数量,并定期运行 etcd 自带的快照压缩工具。
(4)合理配置监控参数:
配置 etcd 的监控参数,如 --enable-metrics。这些参数可以启用 etcd 的监控指标,便于集成监控工具(如 Prometheus)进行性能分析。
(5)配置 TLS 加密:
配置 etcd 的 TLS 加密参数,包括 --cert-file、--key-file、--client-cert-auth。确保 etcd 之间的通信是加密的,提高集群的安全性。
(6)合理配置日志级别:
根据需求配置 etcd 的日志级别,通过 --log-level 参数。在生产环境中,选择适当的日志级别可以平衡信息的详细程度和性能开销。
(7)分离数据和日志目录:
将 etcd 的数据目录和日志目录分开,确保 etcd 的数据存储在持久化的磁盘上,减少日志对数据写入性能的影响。配置 --data-dir 和 --wal-dir 参数。
(8)配置定期备份:
配置 etcd 的定期备份,以确保在数据丢失或损坏时能够快速恢复。使用 etcdctl snapshot 命令进行备份,并将备份文件存储在安全的位置。
(9)配置节点数:
根据集群规模和性能需求,配置合适数量的 etcd 节点。使用奇数个节点,确保在出现故障时仍能够维持多数派投票。
(10)合理调整 API Server 参数:
如果集群中还有其他组件与 etcd 交互,确保调整相关组件的参数,如 Kubernetes API Server 的 --etcd-servers 和 --etcd-cafile。
(10)合理设置资源配额:
根据集群的硬件配置和负载情况,设置 etcd 的资源配额,以确保 etcd 进程有足够的资源支持。
版本兼容性:
确保 etcd 的版本与 Kubernetes 的版本兼容。查看 Kubernetes 文档以获取推荐的 etcd 版本。
9.7.4 etcdctl工具安装
# 下载 etcdctl 工具
wget https://github.com/etcd-io/etcd/releases/download/v3.5.0/etcd-v3.5.0-linux-amd64.tar.gz
# 解压缩
tar xzvf etcd-v3.5.0-linux-amd64.tar.gz
# 移动可执行文件到 /usr/local/bin
sudo mv etcd-v3.5.0-linux-amd64/etcdctl /usr/local/bin/
export ETCDCTL_API=3 # 设置 etcdctl 使用 API 版本 3
export ETCDCTL_ENDPOINTS=http://localhost:2379 # 设置 etcd 的地址,确保与实际地址匹配
- 读写端口为:
2379, 数据同步端口:2380
9.7.5 etcd 容灾备份
(1)数据备份:
- 定期快照备份: 使用 etcdctl 工具进行定期快照备份,可以通过执行
etcdctl snapshot save命令来创建 etcd 数据的快照。备份的频率可以根据实际需求来调整。
# etcdctl snapshot save /path/to/snapshot.db
- 恢复备份: 在需要时,可以使用 etcdctl 进行备份的恢复。执行
etcdctl snapshot restore命令将 etcd 数据恢复到先前的状态。
# etcdctl snapshot restore /path/to/snapshot.db --data-dir /var/lib/etcd
(2)集群高可用性:
- 奇数个节点: 部署奇数个 etcd 节点以确保在出现故障时能够维持多数派投票。奇数节点的 etcd 集群更容易实现高可用性。
- 节点分布: 将 etcd 节点分布在不同的物理节点或云区域,以防止单点故障。
- 监控和自动化: 使用监控工具(如 Prometheus)监控 etcd 集群的状态,并配置自动化的故障转移机制。当节点出现故障时,自动将工作负载转移到其他健康节点。
(3)TLS 加密和认证:
- 启用 TLS 加密: 配置 etcd 集群的 TLS 加密,确保 etcd 节点之间的通信是加密的,提高安全性。
- 认证机制: 使用 etcd 的认证机制,配置
--client-cert-auth参数,以确保只有经过认证的实体能够访问 etcd 集群。
(4)备份存储位置:
- 安全存储备份: 将 etcd 数据的备份存储在安全的位置,远离集群本身。可以将备份存储在独立的服务器、云存储或其他安全位置。
(5)监控和告警:
- 设置监控和告警: 使用监控工具(如 Prometheus)设置监控和告警规则,及时发现 etcd 集群中的问题。这包括节点的健康状况、集群状态、选举状态等。
(6)版本兼容性:
- 保持版本一致性: 确保 etcd 的版本与 Kubernetes 的版本兼容。在进行版本升级之前,测试新版本并确保与集群中的其他组件兼容。
官网推荐工具:mirror-maker
参考文档:https://www.cnblogs.com/yuhaohao/p/12893061.html
9.7.6 etcd operator
etcd-operator的设计是基于k8s的API Extension机制来进行拓展的,它为用户设计了一个类似于Deployment的Controller,只不过这个Controller是用来专门管理etcd这一服务的。
参考部署文档: https://www.27ka.cn/120523.html
9.7.7 etcd监控关键点
etcd 默认以/metrics的 path 暴露了监控数据,数据为 prometheus 标准格式。
通过 metric 数据可以配置出如下面板,一般我们关心的数据,或者说需要配置报警的内容:
- 是否有 leader:集群就不可用了
- leader 更换次数:一定时间内频率过高一般是有问题,且leader 更换会影响到上层服务
- rpc 请求速率:即 qps,可以评估当前负载
- db 总大小:用于评估数据量、压缩策略等
- 磁盘读写延迟:这个很关键,延迟过高会导致集群出现问题
9.8 kube-proxy
Kube-Proxy是Kubernetes集群中的一部分,负责实现服务的网络代理和负载均衡。
9.8.1 服务发布方式
Kube-Proxy通过三种方式发布服务:
- 用户空间代理(User Space): 将服务IP和端口映射到本地的用户空间代理程序,由代理程序负责实现负载均衡。
- IPVS代理(IPVS mode): 使用Linux内核提供的IPVS模块进行负载均衡。
- Iptables代理(iptables mode): 通过Iptables规则实现负载均衡,适用于较小规模的集群。
9.9.2 服务发布流程
- Endpoint刷新: Kube-Proxy会监控Service和Endpoint的变化,定期刷新负载均衡规则。
- 流量转发: 根据Service的类型,Kube-Proxy将流量转发到后端Pod,实现服务的高可用和负载均衡。
- Session Affinity: 可配置会话亲和性,确保一定时间内的请求都被发送到相同的Pod。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号