B站弹幕爬取 / jieba分词 - 全站第一的视频弹幕都在说什么?
前言
本次爬取的视频av号为75993929(11月21的b站榜首),讲的是关于动漫革命机,这是一部超魔幻现实主义动漫(滑稽),有兴趣的可以亲身去感受一下这部魔幻大作。
准备工作
- B站弹幕的爬取的接口
https://api.bilibili.com/x/v1/dm/list.so?oid=
打开开发者模式,其中的oid的值![在这里插入图片描述]()
- 获取视频发出以来的所有弹幕,构造URL
https://api.bilibili.com/x/v2/dm/history?type=1&oid=129995312&date=2019-11-17
![在这里插入图片描述]()
- 访问一下弹幕页面,发现弹幕都放在
标签中。
![在这里插入图片描述]()

代码
import requests
from pyquery import PyQuery as pq
import jieba
import pandas as pd
# 通过时间来获取弹幕信息需要登陆才行,所以带上登陆后的cookie。否则只能获取当日的一千条弹幕
headers={
"放入cookie"
}
word = []
def getInfo(date):
response = requests.get("https://api.bilibili.com/x/v2/dm/history?type=1&oid=129995312&date=2019-11-"+str(date), headers=headers)
# 解决中文乱码问题
response.encoding = response.apparent_encoding
doc = pq(response.content)
# 获取所有的d标签
result = doc("d")
for line in result:
word.append(line.text)
# 将弹幕信息保存到csv文件中去
def savaFile():
sr = pd.Series(word)
sr.to_csv("评革命机B站弹幕.csv", encoding='utf-8', index=None)
# 利用jieba库对弹幕内容进行分词
def seperate():
data = pd.read_csv(open("评革命机B站弹幕.csv", encoding='utf-8'))
# 传入自定义的字典,毕竟b站玩梗玩到飞起
jieba.load_userdict('dict.txt')
strs = ""
for i in data.values:
strs += "".join(i[0])
l = jieba.cut(strs, cut_all=True)
res = '/'.join(l)
# 保存到文件中去
with open("word.txt", 'w', encoding='utf-8') as f:
f.write(res)
# 分析词语出现的频率
def analyse():
res = set()
def dropNa(s):
return s and s.strip()
data = open("word.txt", encoding='utf-8').read()
data = data.split('/')
newdata = []
for i in data:
# 去除掉一些无用的
if '哈' in i or len(i) == 1 or '嘿' in i:
continue
newdata.append(i)
data = newdata
# 去除空串
data = list(filter(dropNa, data))
df = pd.Series(data)
# 统计出现频率同时写入文件中
df.value_counts().to_csv("弹幕TOP.csv")
for i in range(18, 22):
getInfo(i)
savaFile()
seperate()
analyse()
结果展示
大河内老师不愧是早稻田大学人类科学系的毕业的
这些弹幕突然就有内味了
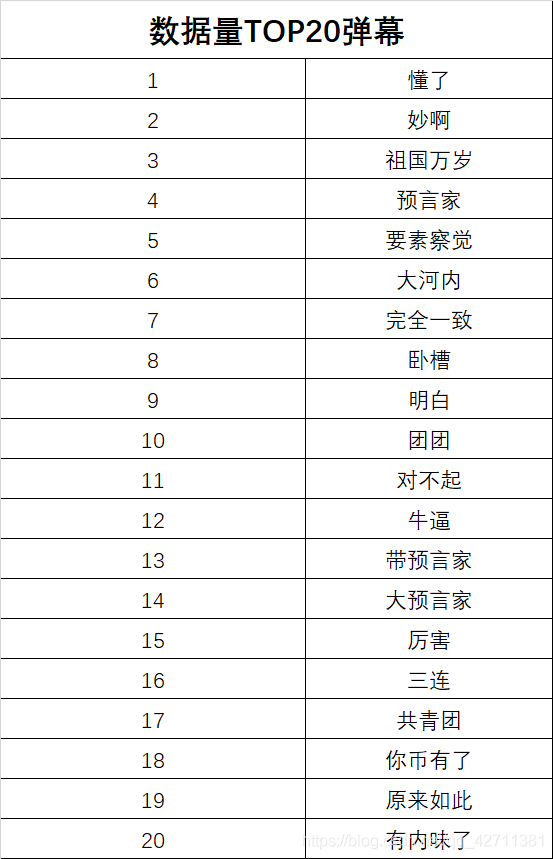
预知为何弹幕会呈现这种情况,详情请见这部动画曾因不切实际被人嘲讽,但6年后现实却打了所有人的脸! 【革命机】
存在的问题
- jieba分词的效果其实不太理想,希望未来能够找到改进方法。
- 本来想做成词云的,但是效果也不佳,待改进。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号