《数学之美》——第二章 个人笔记
第二章 自然语言处理——从规则到统计
这一章开头这句话:字母,文字,数字是信息编码的不同单位。任何一种语言都是一种编码的方式,而语言的语法规则是编解码的算法。我们表达一个意思要通过语言表达出来,就是用这种语言的编码方式表示出来,结果就输出一串文字。别人懂这门语言的编码方式,就会理解。这里说的输出一串文字,可以是字母,数字(计算机理解),和开头说的信息编码的不同单位是符合的,就很好理解了。这就是语言的数学本质。
⭐①计算机能处理自然语言
⭐②它处理自然语言的方法和人类一样
1 机器智能
有意思的词:‘鸟飞派’:看看鸟是怎么飞的,就能模仿鸟造出飞机,而不需要了解空气动力学。
下图是前人对自然语言处理的想法(走的弯路)
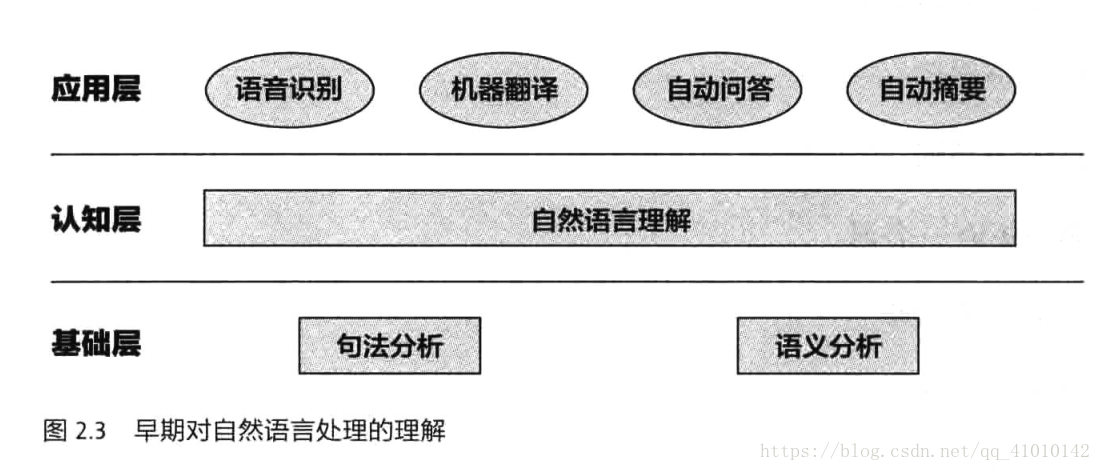
单纯基于文法规则的分析器是处理不了复杂的语句的,里面有两个不可逾越的坎儿:
①文法规则的数量太庞大,无法构建;写到后面还会出现矛盾
②描述自然语言的文法和计算机高级程序语言的文法是不同的,计算机难以解析。作者在这里提到了自然语言在演变过程中产生了词义和上下文相关的特性;对于上下文无关文法,算法的复杂度是语句长度的二次方,而对于有关文法,则是六次方。
2 从规则到统计
有趣的例子:The pan is in the box ,The box is in the pen 。这个栗子说明了语义的难处理。再有统计语言学的出现,不久后NLP从规则到统计。
PS:文中有一段讲斯伯格特对未来研究方向的判断,总让我觉得大牛都是开挂的。还有传统捍卫者的武器就是基于统计的方法只能处理浅层的NLP问题。
3 小结
基于统计的NLP方法,在数学模型上和通信是相通的,甚至就是相同的。因此,在数学意义上NLP又和语言的初衷——通信联系在一起了。(这里基于统计的方法是让计算机能够处理NL)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号