《算法图解》——第五章 散列表
第五章 散列表
1 散列函数(散列映射、映射、字典、关联数组)
散列函数是这样的函数,即无论你给它什么数据,它都还你一个数字。即散列函数"将输入映射到数字"
散列函数必须满足一些要求:
①它必须是一致的。
②它应将不同的输入映射到不同的数字(后面有解释)。
一个🌰:首先,先创建一个空数组
在数组中存储商品的价格,下面来将苹果的价格加入到这个数组中。为此,将apple作为输入交给散列函数,散列函数输出为3,因此我们将苹果的价格储存到数组的索引3处。
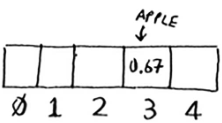 ,同理牛奶,输出为0,
,同理牛奶,输出为0,
不断将商品名称作为输入给散列函数,散列函数给出对应的索引值,将商品对应的价格放入索引值对应的数组位置。散列函数为何能如此准确的指出价格的存储位置呢?原因如下:
①散列函数总是将同样的输入映射到相同的索引。
②散列函数将不同的输入映射到不同的索引。
③散列函数知道数组有多大,只返回有效的索引。
散列表是一种包含额外逻辑的数据结果(散列函数),与数组和链表被直接映射到内存不同。python提供dict{}创建散列表(键值对)
练习
对于同样的输入,散列表必须返回同样的输出,这一点很重要。如果不是这样的,就无法找到你在散列表中添加的元素!请问下面哪些散列函数是一致的?
5.1 f(x) = 1(无论输入是什么,都返回1)
一致
5.2 f(x) = rand()(每次都返回一个随机数)
不一致
5.3 f(x) = next_empty_slot(返回散列表中下一个空位置的索引)
不一致
5.4 f(x) = len(x)(将字符串的长度用作索引)
一致
2 应用案例
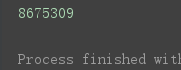
第一个🌰:将散列表用于查找(手机的电话薄功能)
phone_book = {} #与phone_book = dict()等效
phone_book["jenny"] = 8675309
phone_book["emergency"] = 911
print (phone_book["jenny"])
散列表被用于大海捞针式的查找。查找网址,将网址映射到IP地址,这个过程被称为DNS解析(DNS resolution),散列表是提供这种功能的方式之一。
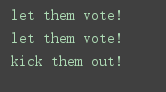
第二个🌰:防止重复(投票站)
voted = {}
def check_voter(name):
if voted.get(name):
print("kick them out!")
else:
voted[name] = True
print("let them vote!")
check_voter("tom")
check_voter("mike")
check_voter("mike")
第三个🌰:将散列表用作缓存(网站工作)
缓存的工作原理:网站将数据记住,而不再重新计算
缓存的优点:
①用户能够更快地看到网页
②需要做的工作更少
缓存是一种常用的加速方式,所有大型网站都使用缓存,而缓存的数据则存储在散列表中!Facebook不仅缓存主页,还缓存About页面、Contact页面、Terms and Conditions页面等众多
其他的页面。因此,它需要将页面URL映射到页面数据。
具体过程:
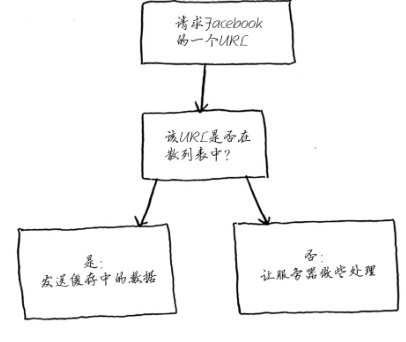
小结
这里总结一下,散列表适合用于:
模拟映射关系;
防止重复;
缓存/记住数据,以免服务器再通过处理来生成它们。
3 冲突(collision)
作者撒了一个善意的谎,散列函数总是将不同的键映射到数组的不同位置(作者搞事情= =!)
给两个键分配的位置相同就是冲突,如何处理?
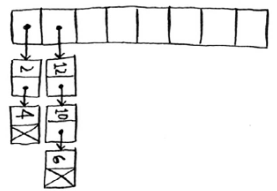
很简单,如果两个键映射到了同一个位置,就在这个位置储存一个链表。
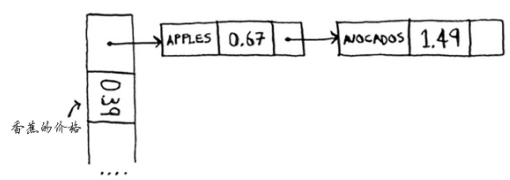
如上图,香蕉很快可以查到价格,对于苹果和鳄梨来说速度会慢点,因为还要在链表中查找,如果链表很短,没什么,如果很长(一个指向下一个),该怎么办?
如下图:
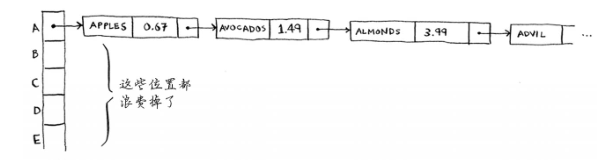
除了第一个位置外,整个散列表是空的,而第一个位置包含一个很长的列表!这样,同样很糟糕!这里有两个关于散列表的经验教训:
①散列函数很重要。前面的散列函数将所有的键都映射到一个位置,而最理想的情况是,散列函数将键均匀地映射到散列表的不同位置
②如果散列表存储的链表很长,散列表的速度将急剧下降。但是你第一个条件做到就不会出现第二条。
4 性能
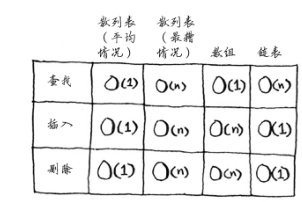
在平均情况下,散列表执行各种操作的时间都为O(1),O(1)被称为常量时间。

一条水平线这意味着无论散列表包含一个元素还是10亿个元素,从其中获取数据所需的时间都相同。与之前的数组中获取一个元素一样,所需的时间是固定:不管数组多大,从中获得一个元素所需的时间都是一样的。散列表同数组和链表比较一下:
因此,要避免最糟的情况,就要避免冲突,要做到:
①较低的填装因子
②良好的散列函数
5 填装因子
散列表的填装因子很容易计算:散列表包含的元素数/位置总数。下图的填装因子是2/5 = 0.4
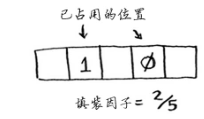
填装因子大于1意味着商品数量超过了数组的位置数。
一旦填装因子开始增加,就要在散列表中添加位置,这叫调整长度(resizing),通常将数组增长一倍。
一个不错的经验规则:当大于0.7时,就要调整散列表的长度。
6 良好的散列函数
好的与糟糕的对比:
练习
散列函数的结果必须是均匀分布的,这很重要。它们的映射范围必须尽可能大。最糟糕的散列函数莫过于将所有输入都映射到散列表的同一个位置。假设你有四个处理字符串的散列函数。
A. 不管输入是什么,都返回1
B. 将字符串的长度用作索引。
C. 将字符串的第一个字符用作索引。即将所有以a打头的字符串都映射到散列表的同一个位置,以此类推。
D. 将每个字符都映射到一个素数:a = 2,b = 3,c = 5,d = 7,e = 11,等等。对于给定的字符串,这个散列函数将其中每个字符对应的素数相加,再计算结果除以散列表长度的余数。例如,如果散列表的长度为10,字符串为 bag ,则索引为(3 + 2 + 17) % 10 = 22 % 10 = 2。在下面的每个示例中,上述哪个散列函数可实现均匀分布?假设散列表的长度为10。
5.5 将姓名和电话号码分别作为键和值的电话簿,其中联系人姓名为Esther、Ben、Bob和Dan。C和D可以
5.6 电池尺寸到功率的映射,其中电池尺寸为A、AA、AAA和AAAA。B和D可以
5.7 书名到作者的映射,其中书名分别为Maus、Fun Home和Watchmen。B、C和D可以
7 小结
你可以结合散列函数和数组来创建散列表。
冲突很糟糕,你应使用可以最大限度减少冲突的散列函数。
散列表的查找、插入和删除速度都非常快。
散列表适合用于模拟映射关系。
一旦填装因子超过0.7,就该调整散列表的长度。
散列表可用于缓存数据(例如,在Web服务器上)。
散列表非常适合用于防止重复。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号