
爬虫爬取
from bs4 import BeautifulSoup
import requests
import xlwt
def getHouseList(url):
house = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER'}
# get从网页获取信息
res = requests.get(url, headers=headers)
# 解析内容
soup = BeautifulSoup(res.content, 'html.parser')
# 房源title
housename_divs = soup.find_all('div', class_='title')
for housename_div in housename_divs:
housename_as = housename_div.find_all('a')
for housename_a in housename_as:
housename = []
# 标题
housename.append(housename_a.get_text())
# 超链接
housename.append(housename_a.get('href'))
house.append(housename)
huseinfo_divs = soup.find_all('div', class_='houseInfo')
for i in range(len(huseinfo_divs)):
info = huseinfo_divs[i].get_text()
infos = info.split('|')
# 小区名称
house[i].append(infos[0])
# 户型
house[i].append(infos[1])
# 平米
house[i].append(infos[2])
# 查询总价
house_prices = soup.find_all('div', class_='totalPrice')
for i in range(len(house_prices)):
# 价格
price = house_prices[i].get_text()
house[i].append(price)
return house
# 爬取房屋详细信息:所在区域、套内面积
def houseinfo(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER'}
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.content, 'html.parser')
msg = []
# 所在区域
areainfos = soup.find_all('span', class_='info')
for areainfo in areainfos:
# 只需要获取第一个a标签的内容即可
area = areainfo.find('a')
if (not area):
continue
hrefStr = area['href']
if (hrefStr.startswith('javascript')):
continue
msg.append(area.get_text())
break
# 根据房屋户型计算套内面积
infolist = soup.find_all('div', id='infoList')
num = []
for info in infolist:
cols = info.find_all('div', class_='col')
for i in cols:
pingmi = i.get_text()
try:
a = float(pingmi[:-2])
num.append(a)
except ValueError:
continue
msg.append(sum(num))
return msg
# 将房源信息写入excel文件
def writeExcel(excelPath, houses):
workbook = xlwt.Workbook()
# 获取第一个sheet页
sheet = workbook.add_sheet('git')
row0 = ['标题', '链接地址', '户型', '面积', '朝向', '总价', '所属区域', '套内面积']
for i in range(0, len(row0)):
sheet.write(0, i, row0[i])
for i in range(0, len(houses)):
house = houses[i]
print(house)
for j in range(0, len(house)):
sheet.write(i + 1, j, house[j])
workbook.save(excelPath)
# 主函数
def main():
data = []
for i in range(1, 5):
print('-----分隔符', i, '-------')
if i == 1:
url = 'https://sjz.lianjia.com/ershoufang/l2rs%E5%92%8C%E5%B9%B3%E4%B8%96%E5%AE%B6/'
else:
url = 'https://sjz.lianjia.com/ershoufang/pg' + str(i) + 'l2rs%E5%92%8C%E5%B9%B3%E4%B8%96%E5%AE%B6/'
houses = getHouseList(url)
for house in houses:
link = house[1]
if (not link or not link.startswith('http')):
continue
mianji = houseinfo(link)
# 将套内面积、所在区域增加到房源信息
house.extend(mianji)
data.extend(houses)
writeExcel('d:/house.xls', data)
if __name__ == '__main__':
main()
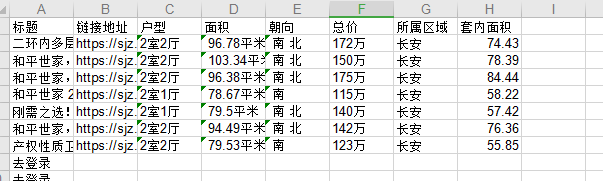
获取某个小区的房源信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号