

摘要:  NBI大数据可视化分析平台作为新一代自助式、探索式分析工具,在产品设计理念上始终从用户的角度出发,一直围绕简单、易用,强调交互分析为目的的新型产品。我们将数据分析的各环节(数据准备、自服务数据建模、探索式分析、权限管控)融入到系统当中,让企业有序的、安全的管理数据和分析数据。 阅读全文
NBI大数据可视化分析平台作为新一代自助式、探索式分析工具,在产品设计理念上始终从用户的角度出发,一直围绕简单、易用,强调交互分析为目的的新型产品。我们将数据分析的各环节(数据准备、自服务数据建模、探索式分析、权限管控)融入到系统当中,让企业有序的、安全的管理数据和分析数据。 阅读全文
NBI大数据可视化分析平台作为新一代自助式、探索式分析工具,在产品设计理念上始终从用户的角度出发,一直围绕简单、易用,强调交互分析为目的的新型产品。我们将数据分析的各环节(数据准备、自服务数据建模、探索式分析、权限管控)融入到系统当中,让企业有序的、安全的管理数据和分析数据。 阅读全文
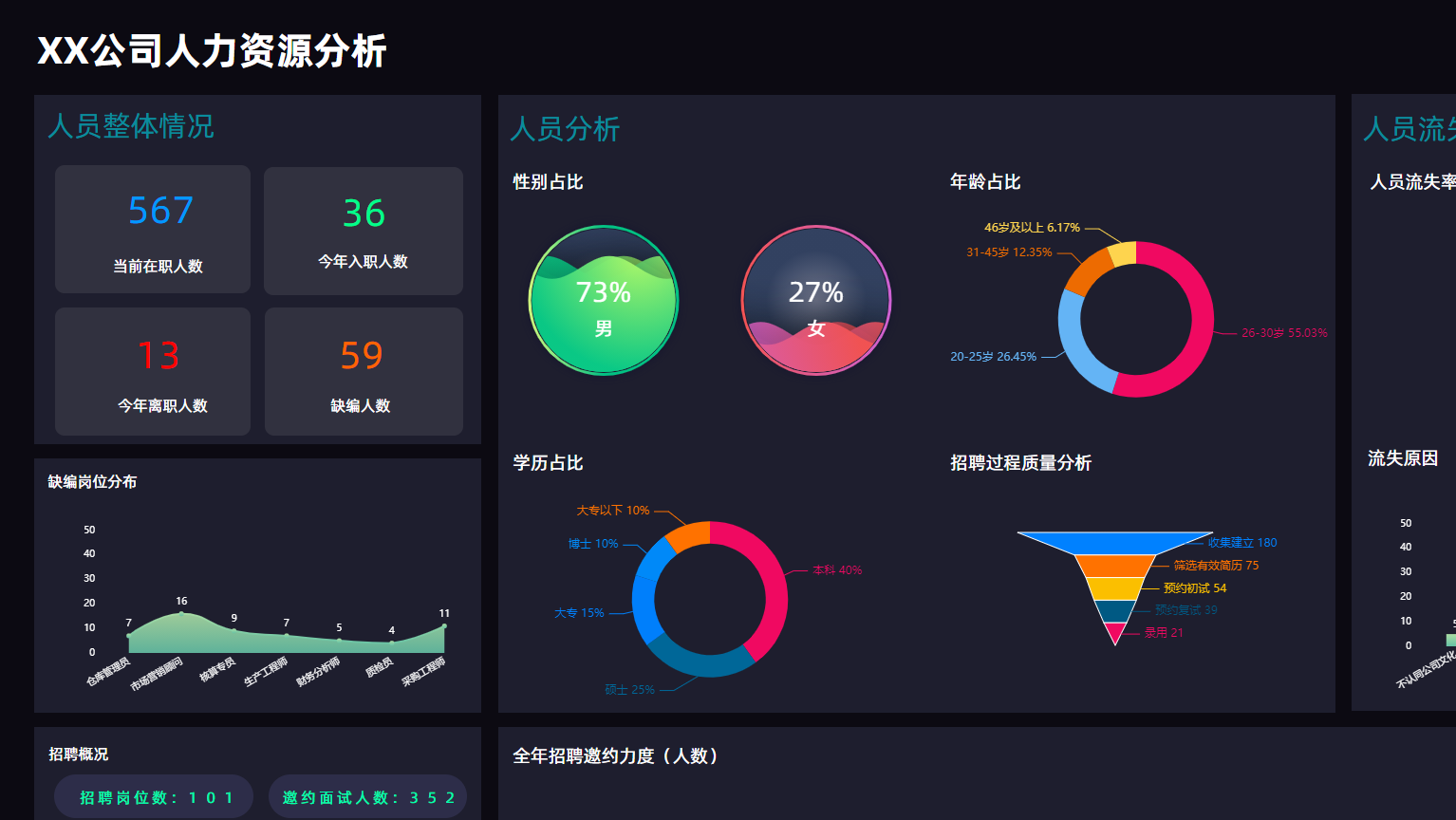 随着国内信息化的快速发展,各行各业的信息化建设程度越来越高,随之而来对信息化和智能化提出了更高的要求,从信息化的管理阶段上升到以数据驱动,数据洞察,数据价值为核心的层面,那么在现阶段我相信大数据、可视化、数据大屏等行业名词大家不再陌生,这些技术或产品也在逐步渗透到各行业中,为行业赋能。基于一个高速发展的社会组织里面,一切以快为胜,我们一直在思考如何让每一家企业采用极低的成本,极快的速度,极其简单的方式实现数据洞察,数据应用呢,这个是我今天想要和大家分享的内容。
我们先来了解一下数据分析的几个步骤:(1)数据获取;(2)数据整理;(3)数据建模;(4)数据应用;大致分为上面几个步骤,数据获取、整理(ETL)部分不是今天的重点,所以不在这里展开讲,那么数据应用需要做哪些事情呢?大致分为三个步骤:
随着国内信息化的快速发展,各行各业的信息化建设程度越来越高,随之而来对信息化和智能化提出了更高的要求,从信息化的管理阶段上升到以数据驱动,数据洞察,数据价值为核心的层面,那么在现阶段我相信大数据、可视化、数据大屏等行业名词大家不再陌生,这些技术或产品也在逐步渗透到各行业中,为行业赋能。基于一个高速发展的社会组织里面,一切以快为胜,我们一直在思考如何让每一家企业采用极低的成本,极快的速度,极其简单的方式实现数据洞察,数据应用呢,这个是我今天想要和大家分享的内容。
我们先来了解一下数据分析的几个步骤:(1)数据获取;(2)数据整理;(3)数据建模;(4)数据应用;大致分为上面几个步骤,数据获取、整理(ETL)部分不是今天的重点,所以不在这里展开讲,那么数据应用需要做哪些事情呢?大致分为三个步骤: 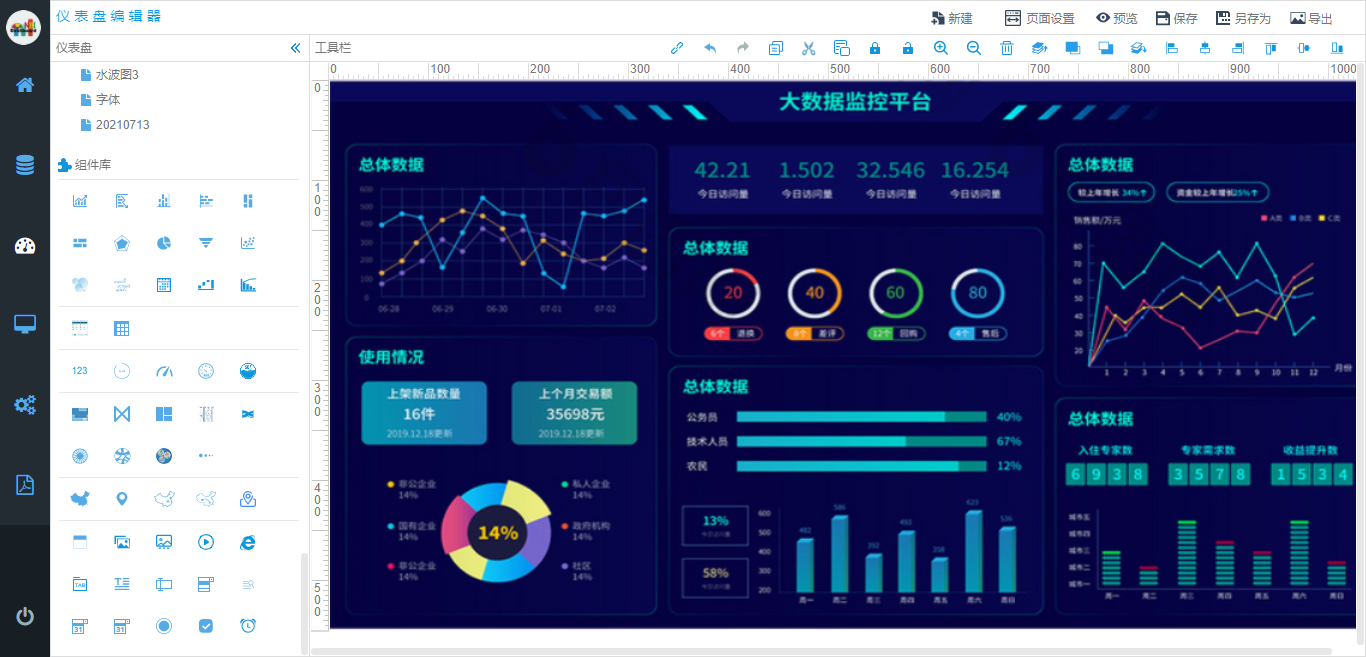 ClickHouse是一款MPP架构的列式存储数据库,并允许使用SQL查询实时生成分析报告,也是一个新的开源列式数据库。
随着业务的迅猛增长,Yandex.Metrica目前已经成为世界第三大Web流量分析平台,每天处理超过200亿个跟踪事件。能够拥有如此惊人的体量,在它背后提供支撑的ClickHouse功不可没。ClickHouse已经为Yandex.Metrica存储了超过20万亿行的数据,90%的自定义查询能够在1秒内返回,其集群规模也超过了400台服务器。虽然ClickHouse起初只是为了Yandex.Metrica而研发的,但由于它出众的性能,目前也被广泛应用于Yandex内部其他数十个产品上。
ClickHouse是一款MPP架构的列式存储数据库,并允许使用SQL查询实时生成分析报告,也是一个新的开源列式数据库。
随着业务的迅猛增长,Yandex.Metrica目前已经成为世界第三大Web流量分析平台,每天处理超过200亿个跟踪事件。能够拥有如此惊人的体量,在它背后提供支撑的ClickHouse功不可没。ClickHouse已经为Yandex.Metrica存储了超过20万亿行的数据,90%的自定义查询能够在1秒内返回,其集群规模也超过了400台服务器。虽然ClickHouse起初只是为了Yandex.Metrica而研发的,但由于它出众的性能,目前也被广泛应用于Yandex内部其他数十个产品上。  Spark SQL中用户自定义函数,用法和Spark SQL中的内置函数类似;是saprk SQL中内置函数无法满足要求,用户根据业务需求自定义的函数。 首先定义一个UDF函数: package com.udf; import org.apache.spark.sql.api.java.UDF1;
Spark SQL中用户自定义函数,用法和Spark SQL中的内置函数类似;是saprk SQL中内置函数无法满足要求,用户根据业务需求自定义的函数。 首先定义一个UDF函数: package com.udf; import org.apache.spark.sql.api.java.UDF1; 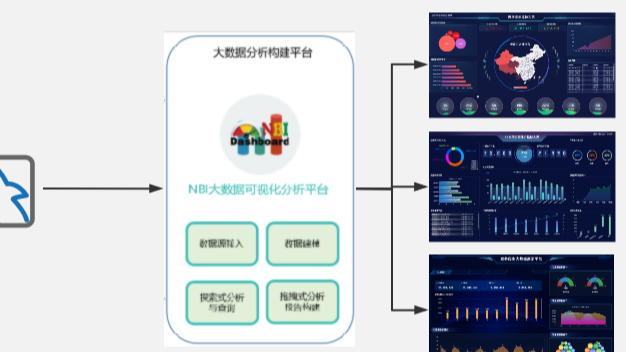 (1)sparkstreaming从kafka接入实时数据流最终实现数据可视化展示,我们先看下整体方案架构: (2)方案说明: 1)我们通过kafka与各个业务系统的数据对接,将各系统中的数据实时接到kafka; 2)通过sparkstreaming接入kafka数据流,定义时间窗口和计算窗口大小,
(1)sparkstreaming从kafka接入实时数据流最终实现数据可视化展示,我们先看下整体方案架构: (2)方案说明: 1)我们通过kafka与各个业务系统的数据对接,将各系统中的数据实时接到kafka; 2)通过sparkstreaming接入kafka数据流,定义时间窗口和计算窗口大小,  一、滚动窗口(Tumbling Windows) 滚动窗口有固定的大小,是一种对数据进行均匀切片的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。滚动窗口可以基于时间定义,也可以基于数据个数定义;需要的参数只有一个,就是窗口的大小(window size)。
一、滚动窗口(Tumbling Windows) 滚动窗口有固定的大小,是一种对数据进行均匀切片的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。滚动窗口可以基于时间定义,也可以基于数据个数定义;需要的参数只有一个,就是窗口的大小(window size)。  Spark Streaming是构建在Spark Core的RDD基础之上的,与此同时Spark Streaming引入了一个新的概念:DStream(Discretized Stream,离散化数据流),表示连续不断的数据流。DStream抽象是Spark Streaming的流处理模型,在内部实现上,Spark Streaming会对输入数据按照时间间隔(如1秒)分段,每一段数据转换为Spark中的RDD,这些分段就是Dstream,并且对DStream的操作都最终转变为对相应的RDD的操作。
Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。Spark SQL 的前身是Shark,Shark是基于 Hive 所开发的工具,它修改了下图所示的右下角的内存管理、物理计划、执行三个模块,并使之能运行在 Spark 引擎上。
Spark Streaming是构建在Spark Core的RDD基础之上的,与此同时Spark Streaming引入了一个新的概念:DStream(Discretized Stream,离散化数据流),表示连续不断的数据流。DStream抽象是Spark Streaming的流处理模型,在内部实现上,Spark Streaming会对输入数据按照时间间隔(如1秒)分段,每一段数据转换为Spark中的RDD,这些分段就是Dstream,并且对DStream的操作都最终转变为对相应的RDD的操作。
Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。Spark SQL 的前身是Shark,Shark是基于 Hive 所开发的工具,它修改了下图所示的右下角的内存管理、物理计划、执行三个模块,并使之能运行在 Spark 引擎上。  本篇文章我们来模拟一个真实的风险识别场景,模拟XX平台上可能出现盗号行为。
技术实现方案:
(1)通过将xxx平台用户登录时的登录日志发送到kafka(本文代码演示用的socket);
(2)Flink CEP SQL规则引擎中定义好风控识别规则,接入kafka数据源,比如一个账号在5分钟内,在多个不同地区有登录行为,那我们认为该账号被盗;
(3)Flink CEP将识别到的风险数据可以进行下发,为数据应用层提供数据服务,如:风控系统,数据大屏,态势感知.....
本篇文章我们来模拟一个真实的风险识别场景,模拟XX平台上可能出现盗号行为。
技术实现方案:
(1)通过将xxx平台用户登录时的登录日志发送到kafka(本文代码演示用的socket);
(2)Flink CEP SQL规则引擎中定义好风控识别规则,接入kafka数据源,比如一个账号在5分钟内,在多个不同地区有登录行为,那我们认为该账号被盗;
(3)Flink CEP将识别到的风险数据可以进行下发,为数据应用层提供数据服务,如:风控系统,数据大屏,态势感知.....  Flink CEP SQL中提供了四种匹配策略:
(1)skip to next row
从匹配成功的事件序列中的第一个事件的下一个事件开始进行下一次匹配
(2)skip past last row
从匹配成功的事件序列中的最后一个事件的下一个事件开始进行下一次匹配
(3)skip to first pattern Item
从匹配成功的事件序列中第一个对应于patternItem的事件开始进行下一次匹配
(4)skip to last pattern Item
从匹配成功的事件序列中最后一个对应于patternItem的事件开始进行下一次匹配
Flink CEP SQL中提供了四种匹配策略:
(1)skip to next row
从匹配成功的事件序列中的第一个事件的下一个事件开始进行下一次匹配
(2)skip past last row
从匹配成功的事件序列中的最后一个事件的下一个事件开始进行下一次匹配
(3)skip to first pattern Item
从匹配成功的事件序列中第一个对应于patternItem的事件开始进行下一次匹配
(4)skip to last pattern Item
从匹配成功的事件序列中最后一个对应于patternItem的事件开始进行下一次匹配  (4)Flink CEP SQL贪婪词量演示
(4)Flink CEP SQL贪婪词量演示  Flink CEP SQL宽松近邻代码演示
Flink CEP SQL宽松近邻代码演示  上一篇我们对Flink CEP做了简单介绍,这一篇我们通过代码来演示一下Flink CEP SQL中的严格近邻效果:
上一篇我们对Flink CEP做了简单介绍,这一篇我们通过代码来演示一下Flink CEP SQL中的严格近邻效果: 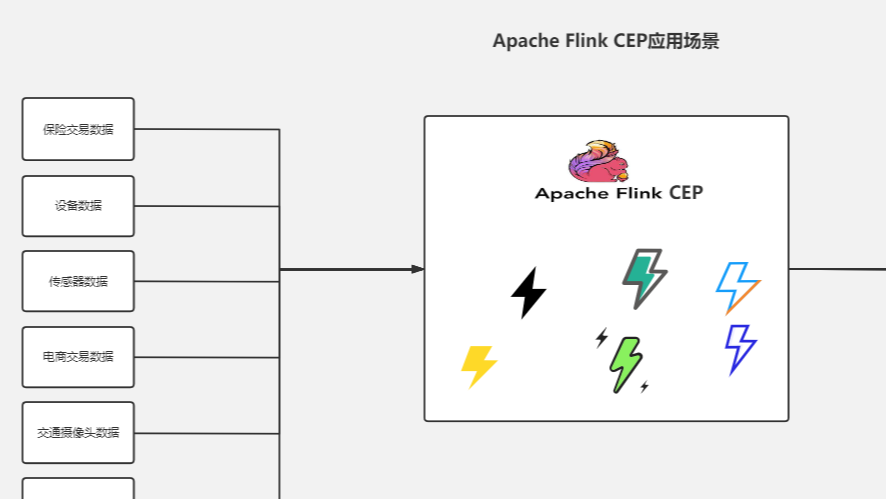 复杂事件处理(CEP)既是把不同的数据看做不同的事件,并且通过分析事件之间的关系建立起一套事件关系序列库。利用过滤,聚合,关联性,依赖,层次等技术,最终实现由简单关系产生高级事件关系。
复杂事件主要应用场景:主要用于信用卡欺诈检测、用户风险检测、设备故障检测、攻击行为分析等领域。
Flink CEP能够利用的场景较多,在实际业务场景中也有了广泛的使用案例与经验积累。比如
复杂事件处理(CEP)既是把不同的数据看做不同的事件,并且通过分析事件之间的关系建立起一套事件关系序列库。利用过滤,聚合,关联性,依赖,层次等技术,最终实现由简单关系产生高级事件关系。
复杂事件主要应用场景:主要用于信用卡欺诈检测、用户风险检测、设备故障检测、攻击行为分析等领域。
Flink CEP能够利用的场景较多,在实际业务场景中也有了广泛的使用案例与经验积累。比如  FlinkSQL的出现,极大程度上降低了Flink的编程门槛,更加容易理解和掌握使用。今天将自己的笔记分享出来,希望能帮助在这方面有需要的朋友。 (1)首先引入POM依赖: <properties> <flink.version>1.13.1</flink.version> <scala.binar
FlinkSQL的出现,极大程度上降低了Flink的编程门槛,更加容易理解和掌握使用。今天将自己的笔记分享出来,希望能帮助在这方面有需要的朋友。 (1)首先引入POM依赖: <properties> <flink.version>1.13.1</flink.version> <scala.binar  NBI可视化平台快速入门教程(五)编辑器功能操作介绍
NBI可视化平台快速入门教程(五)编辑器功能操作介绍  NBI可视化平台快速入门教程(四)数据可视化编辑器介绍
NBI可视化平台快速入门教程(四)数据可视化编辑器介绍 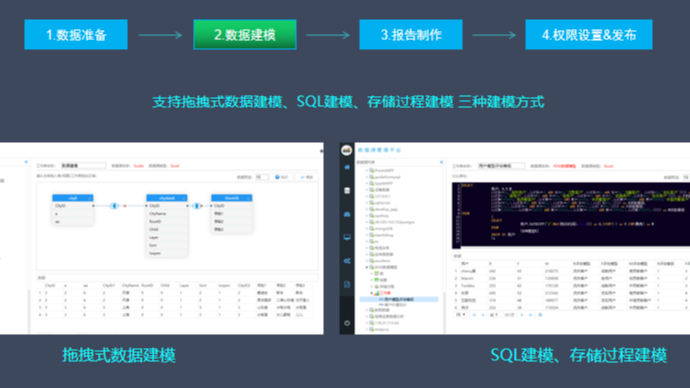 NBI一站式大数据分析平台作为新一代自助式、探索式分析工具,在产品设计理念上始终从用户的角度出发,一直围绕简单、易用,强调交互分析为目的的新型产品。我们将数据分析的各环节(数据准备、自服务数据建模、探索式分析、权限管控)融入到系统当中,让企业有序的、安全的管理数据和分析数据。
NBI一站式大数据分析平台作为新一代自助式、探索式分析工具,在产品设计理念上始终从用户的角度出发,一直围绕简单、易用,强调交互分析为目的的新型产品。我们将数据分析的各环节(数据准备、自服务数据建模、探索式分析、权限管控)融入到系统当中,让企业有序的、安全的管理数据和分析数据。 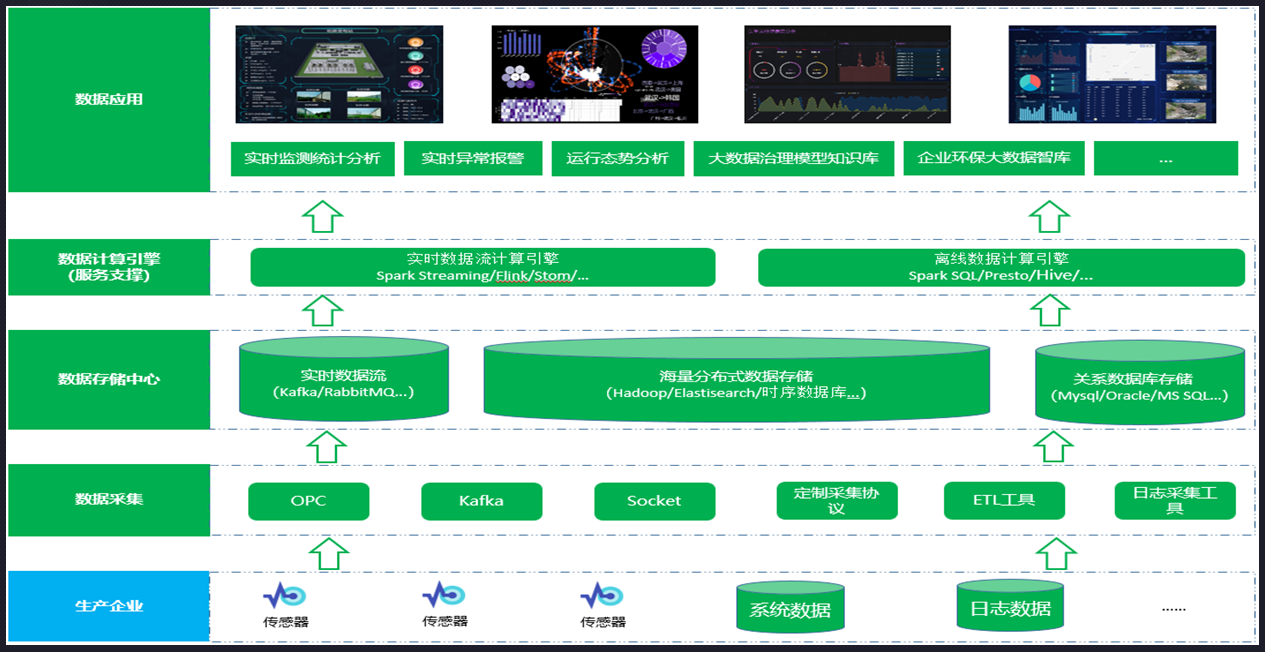 什么是时序数据库
先来介绍什么是时序数据。时序数据是基于时间的一系列的数据。在有时间的坐标中将这些数据点连成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析,机器学习,实现预测和预警。
时序数据库就是存放时序数据的数据库,并且需要支持时序数据的快速写入、持久化、多纬度的聚合查询等基本功能。
什么是时序数据库
先来介绍什么是时序数据。时序数据是基于时间的一系列的数据。在有时间的坐标中将这些数据点连成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析,机器学习,实现预测和预警。
时序数据库就是存放时序数据的数据库,并且需要支持时序数据的快速写入、持久化、多纬度的聚合查询等基本功能。 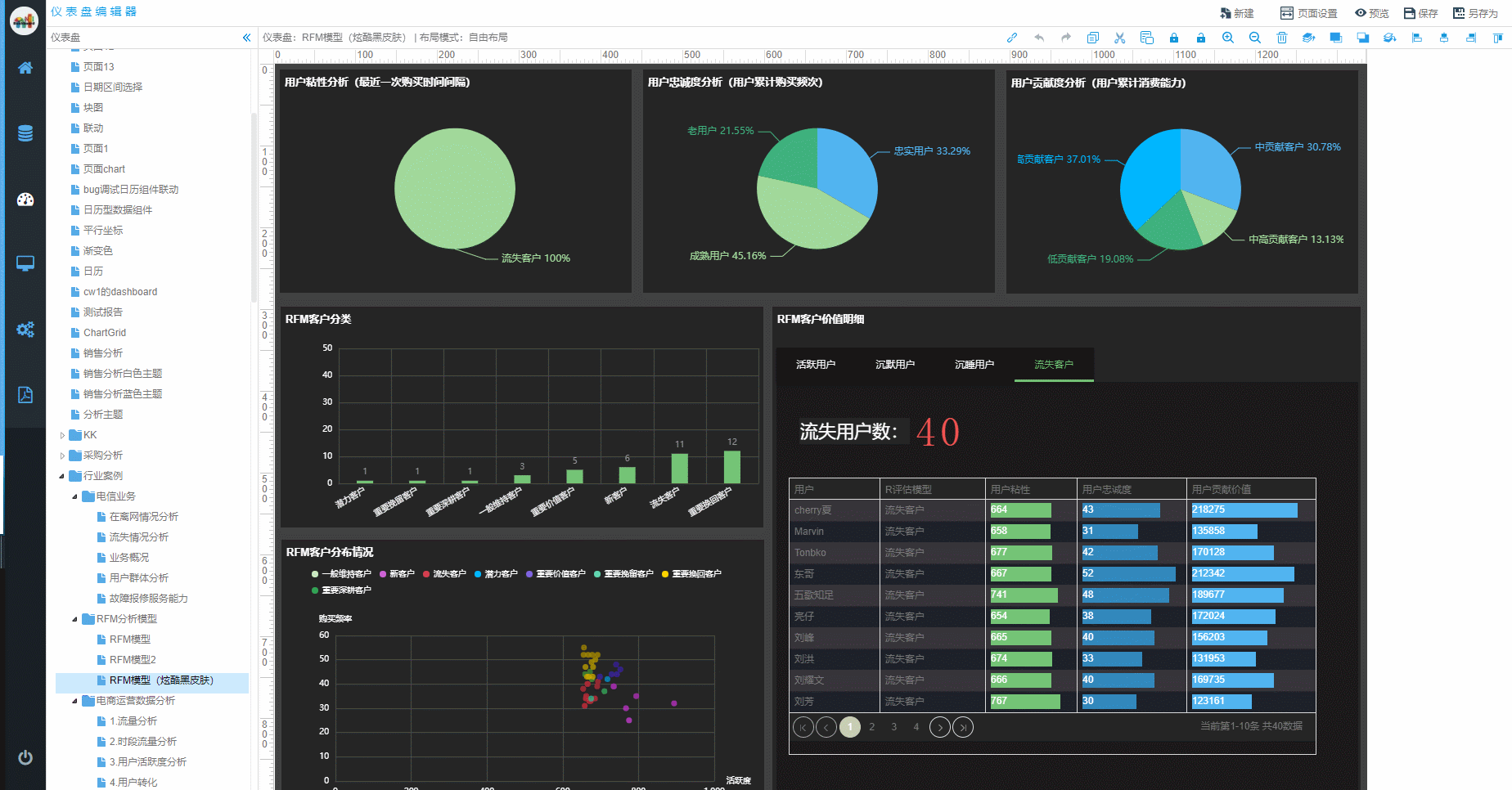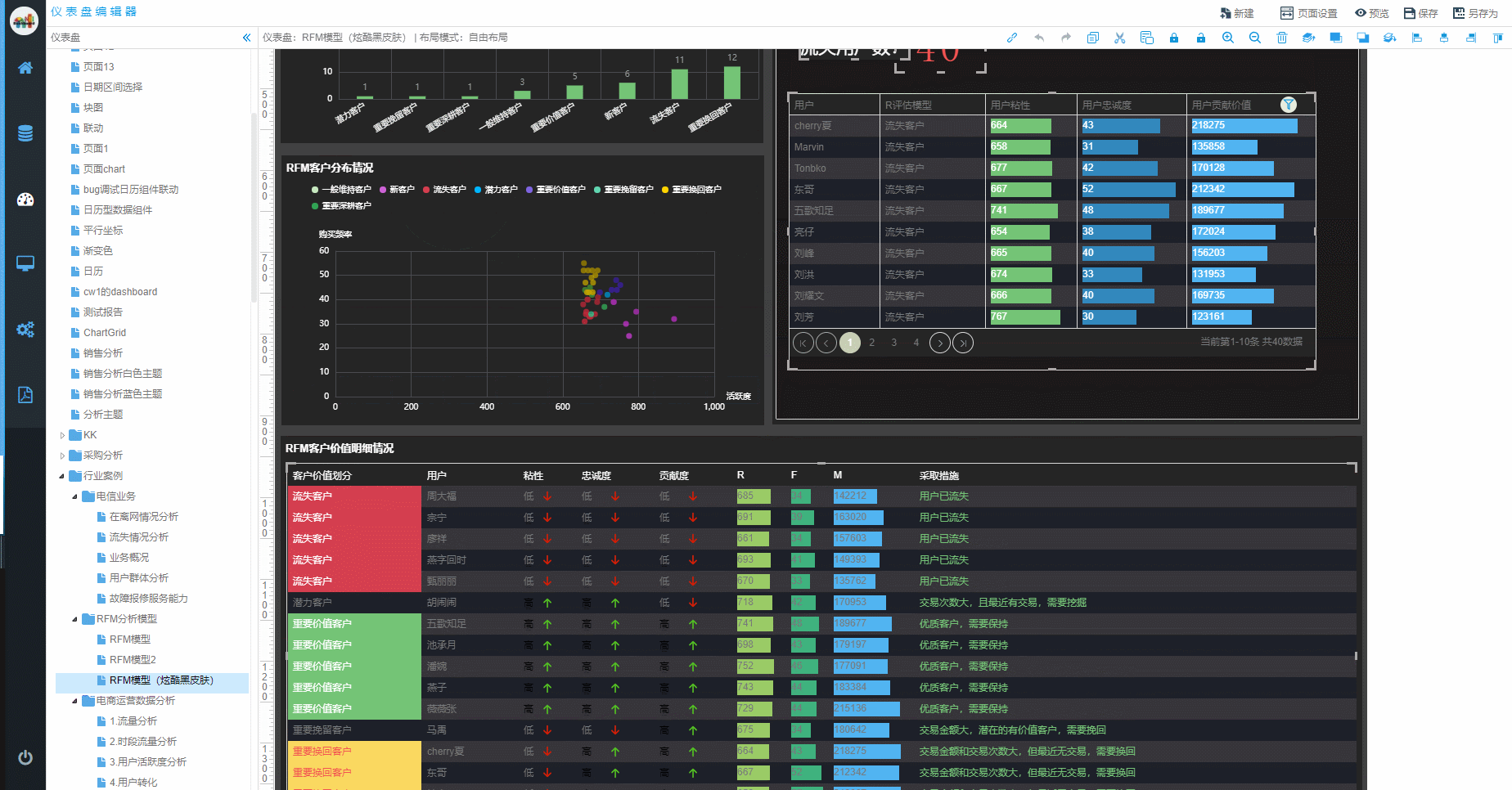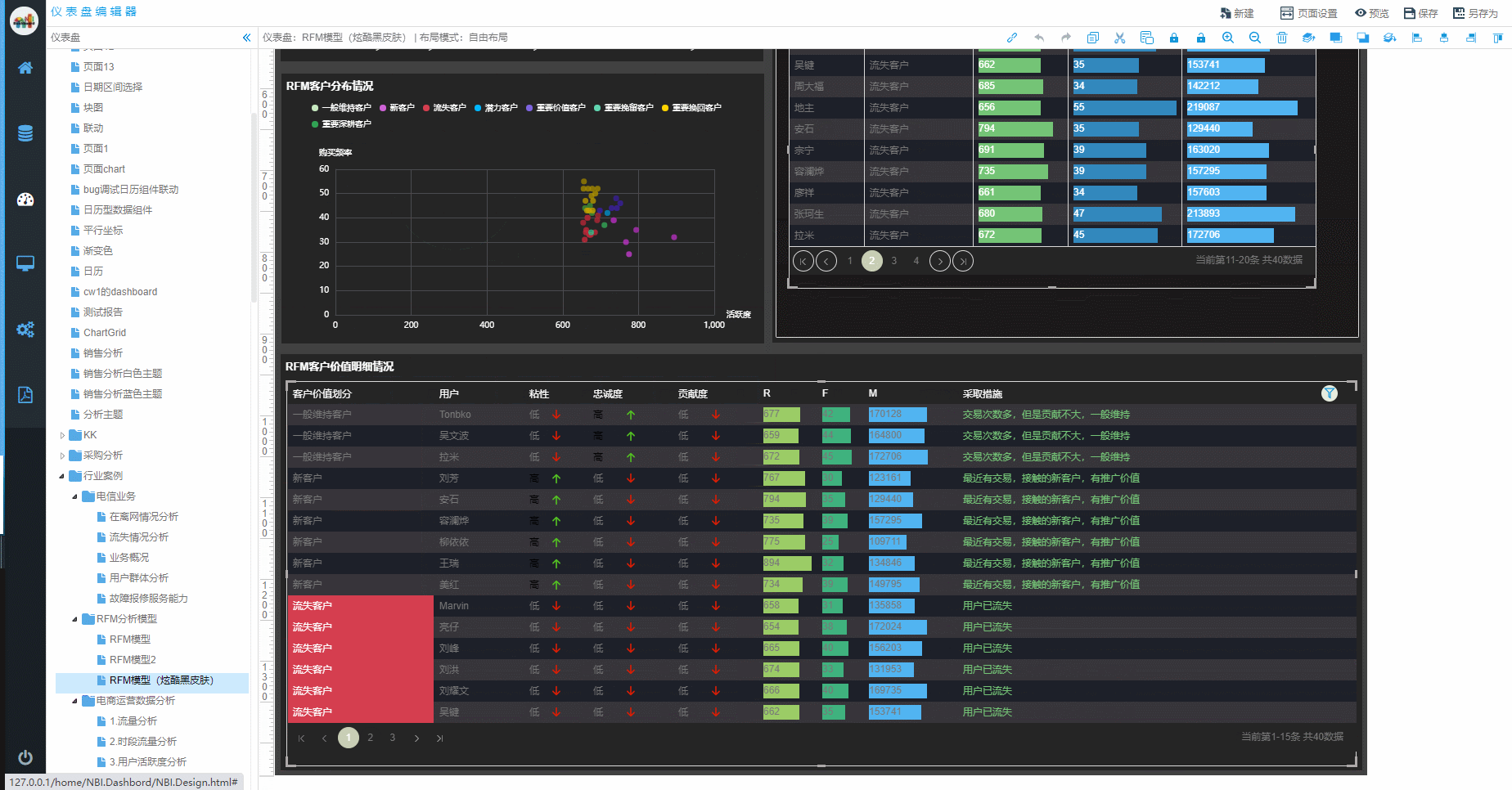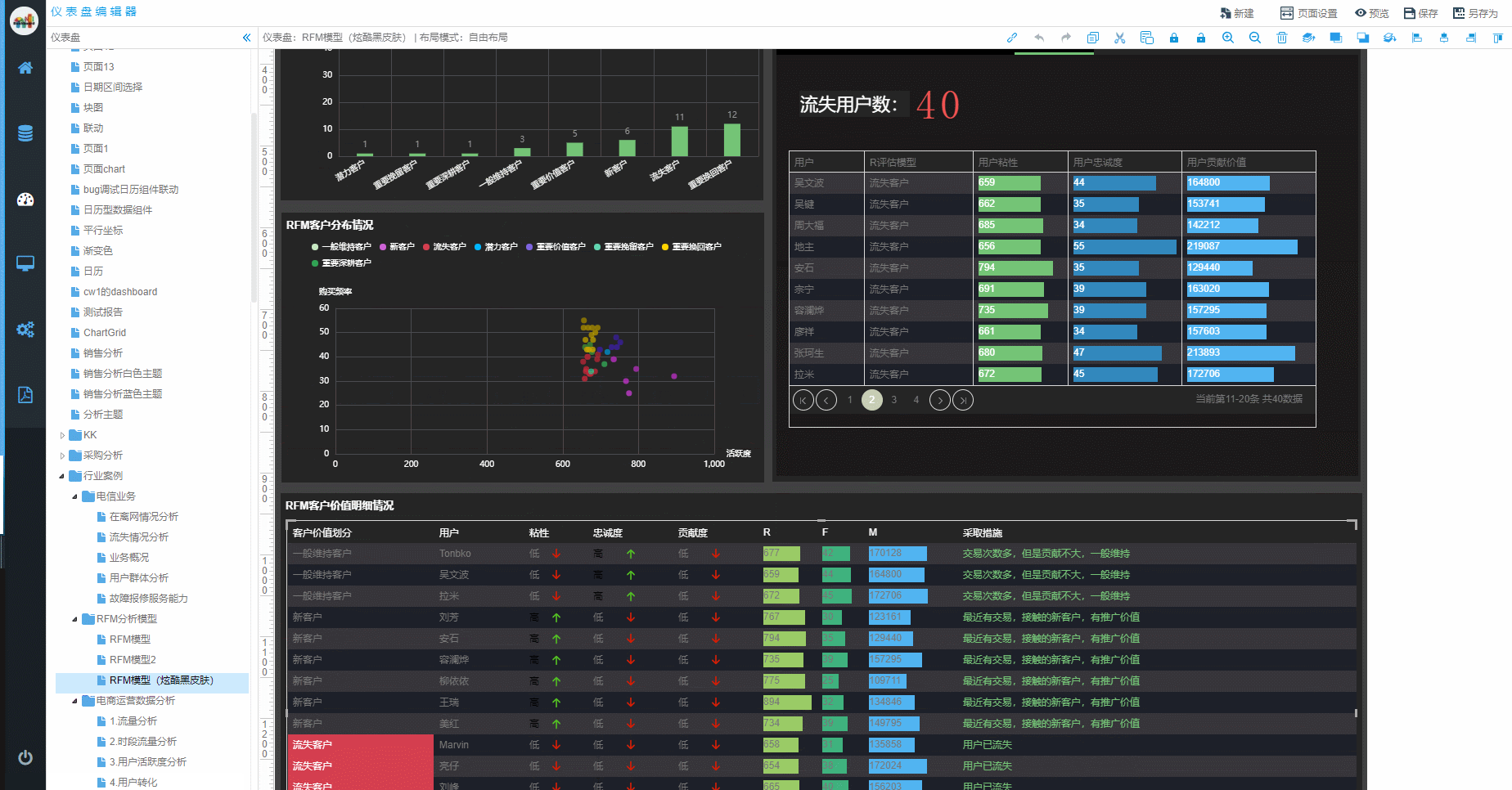 我们先来了解一下什么是RFM模型:
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。在众多的客户关系管理的分析模式中,RFM模型是被广泛提到的。该数据模型通过一个客户的近期购买行为、购买的总体频率以及花了多少钱3项指标来描述该客户的价值状况。
我们先来了解一下什么是RFM模型:
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。在众多的客户关系管理的分析模式中,RFM模型是被广泛提到的。该数据模型通过一个客户的近期购买行为、购买的总体频率以及花了多少钱3项指标来描述该客户的价值状况。