(4)SparkSQL中如何定义UDF和使用UDF
Spark SQL中用户自定义函数,用法和Spark SQL中的内置函数类似;是saprk SQL中内置函数无法满足要求,用户根据业务需求自定义的函数。
首先定义一个UDF函数:
package com.udf; import org.apache.spark.sql.api.java.UDF1; import org.apache.spark.sql.api.java.UDF2; import org.apache.spark.sql.catalyst.expressions.GenericRowWithSchema; import scala.collection.mutable.WrappedArray; /** * Created by lj on 2022-07-25. */ public class TestUDF implements UDF1<String, String> { @Override public String call(String s) throws Exception { return s+"_udf"; } }
使用UDF函数:
package com.examples; import com.pojo.WaterSensor; import com.udf.TestUDF; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.function.Function; import org.apache.spark.api.java.function.VoidFunction2; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import org.apache.spark.sql.SparkSession; import org.apache.spark.sql.types.DataTypes; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.Time; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaReceiverInputDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; /** * Created by lj on 2022-07-25. */ public class SparkSql_Socket_UDF { private static String appName = "spark.streaming.demo"; private static String master = "local[*]"; private static String host = "localhost"; private static int port = 9999; public static void main(String[] args) { //初始化sparkConf SparkConf sparkConf = new SparkConf().setMaster(master).setAppName(appName); //获得JavaStreamingContext JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, Durations.minutes(3)); /** * 设置日志的级别: 避免日志重复 */ ssc.sparkContext().setLogLevel("ERROR"); //从socket源获取数据 JavaReceiverInputDStream<String> lines = ssc.socketTextStream(host, port); JavaDStream<WaterSensor> mapDStream = lines.map(new Function<String, WaterSensor>() { private static final long serialVersionUID = 1L; public WaterSensor call(String s) throws Exception { String[] cols = s.split(","); WaterSensor waterSensor = new WaterSensor(cols[0], Long.parseLong(cols[1]), Integer.parseInt(cols[2])); return waterSensor; } }).window(Durations.minutes(6), Durations.minutes(9)); //指定窗口大小 和 滑动频率 必须是批处理时间的整数倍 mapDStream.foreachRDD(new VoidFunction2<JavaRDD<WaterSensor>, Time>() { @Override public void call(JavaRDD<WaterSensor> waterSensorJavaRDD, Time time) throws Exception { SparkSession spark = JavaSparkSessionSingleton.getInstance(waterSensorJavaRDD.context().getConf()); spark.udf().register("TestUDF", new TestUDF(), DataTypes.StringType); Dataset<Row> dataFrame = spark.createDataFrame(waterSensorJavaRDD, WaterSensor.class); // 创建临时表 dataFrame.createOrReplaceTempView("log"); Dataset<Row> result = spark.sql("select *,TestUDF(id) as udftest from log"); System.out.println("========= " + time + "========="); //输出前20条数据 result.show(); } }); //开始作业 ssc.start(); try { ssc.awaitTermination(); } catch (Exception e) { e.printStackTrace(); } finally { ssc.close(); } } }
代码说明:
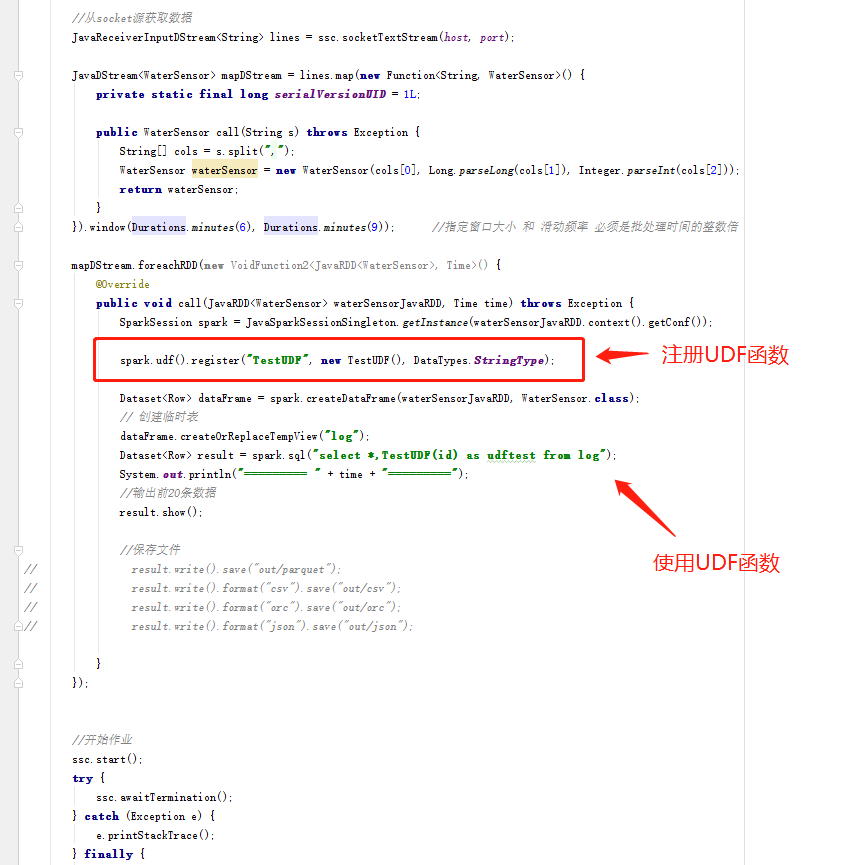
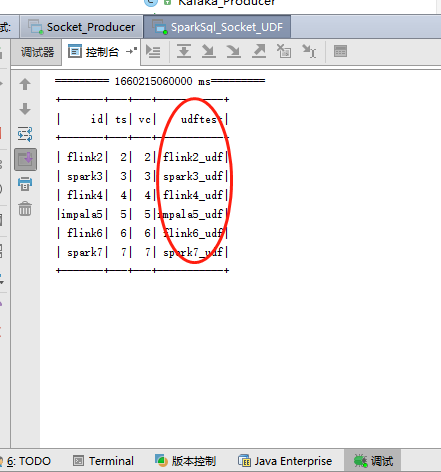
应用效果展示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号