(3)sparkstreaming从kafka接入实时数据流,最终实现数据可视化分析展示
(1)sparkstreaming从kafka接入实时数据流最终实现数据可视化展示,我们先看下整体方案架构:
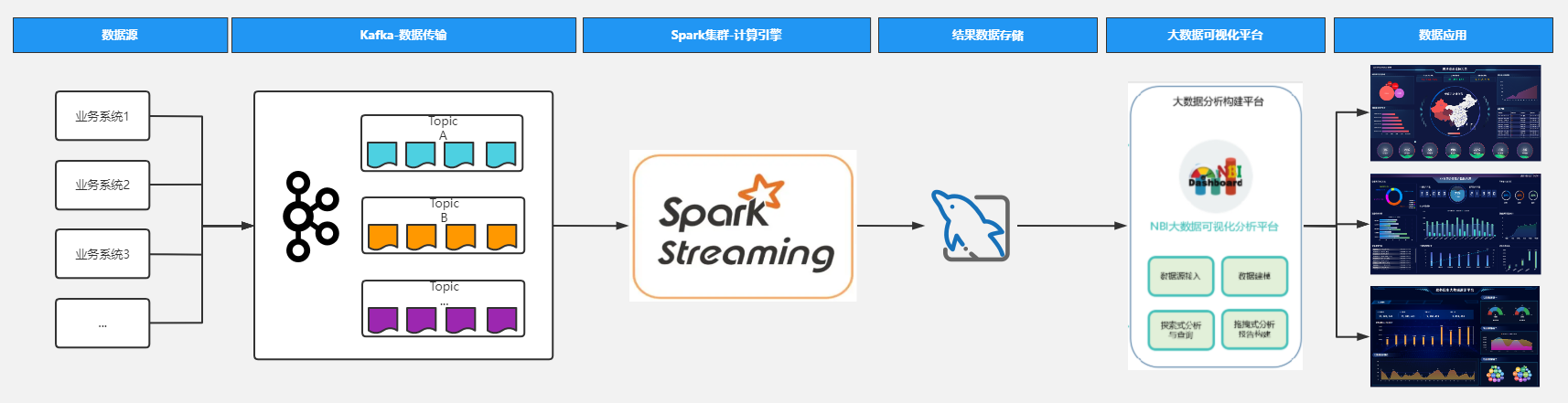
(2)方案说明:
1)我们通过kafka与各个业务系统的数据对接,将各系统中的数据实时接到kafka;
2)通过sparkstreaming接入kafka数据流,定义时间窗口和计算窗口大小,业务计算逻辑处理;
3)将结果数据写入到mysql;
4)通过可视化平台接入mysql数据库,这里使用的是NBI大数据可视化构建平台;
5)在平台上通过拖拽式构建各种数据应用,数据展示;
(3)代码演示:
定义一个kafka生产者,模拟数据源
package com.producers; import com.alibaba.fastjson.JSONObject; import com.pojo.WaterSensor; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import java.util.Properties; import java.util.Random; /** * Created by lj on 2022-07-18. */ public class Kafaka_Producer { public final static String bootstrapServers = "127.0.0.1:9092"; public static void main(String[] args) { Properties props = new Properties(); //设置Kafka服务器地址 props.put("bootstrap.servers", bootstrapServers); //设置数据key的序列化处理类 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); //设置数据value的序列化处理类 props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer<String, String> producer = new KafkaProducer<>(props); try { int i = 0; Random r=new Random(); String[] lang = {"flink","spark","hadoop","hive","hbase","impala","presto","superset","nbi"}; while(true) { Thread.sleep(2000); WaterSensor waterSensor = new WaterSensor(lang[r.nextInt(lang.length)]+"_kafka",i,i); i++; String msg = JSONObject.toJSONString(waterSensor); System.out.println(msg); RecordMetadata recordMetadata = producer.send(new ProducerRecord<>("kafka_data_waterSensor", null, null, msg)).get(); // System.out.println("recordMetadata: {"+ recordMetadata +"}"); } } catch (Exception e) { System.out.println(e.getMessage()); } } }
根据业务需要,定义各种消息对象
package com.pojo; import java.io.Serializable; import java.util.Date; /** * Created by lj on 2022-07-13. */ public class WaterSensor implements Serializable { public String id; public long ts; public int vc; public WaterSensor(){ } public WaterSensor(String id,long ts,int vc){ this.id = id; this.ts = ts; this.vc = vc; } public int getVc() { return vc; } public void setVc(int vc) { this.vc = vc; } public String getId() { return id; } public void setId(String id) { this.id = id; } public long getTs() { return ts; } public void setTs(long ts) { this.ts = ts; } }
sparkstreaming数据流计算
package com.examples; import com.alibaba.fastjson.JSONObject; import com.pojo.WaterSensor; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.common.TopicPartition; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.function.Function; import org.apache.spark.api.java.function.VoidFunction2; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import org.apache.spark.sql.SparkSession; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.Time; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaInputDStream; import org.apache.spark.streaming.api.java.JavaReceiverInputDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import org.apache.spark.streaming.kafka010.ConsumerStrategies; import org.apache.spark.streaming.kafka010.KafkaUtils; import org.apache.spark.streaming.kafka010.LocationStrategies; import java.util.*; /** * Created by lj on 2022-07-18. */ public class SparkSql_Kafka { private static String appName = "spark.streaming.demo"; private static String master = "local[*]"; private static String topics = "kafka_data_waterSensor"; private static String brokers = "127.0.0.1:9092"; public static void main(String[] args) { //初始化sparkConf SparkConf sparkConf = new SparkConf().setMaster(master).setAppName(appName); //获得JavaStreamingContext JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, Durations.minutes(3)); /** * 设置日志的级别: 避免日志重复 */ ssc.sparkContext().setLogLevel("ERROR"); Collection<String> topicsSet = new HashSet<>(Arrays.asList(topics.split(","))); //kafka相关参数,必要!缺了会报错 Map<String, Object> kafkaParams = new HashMap<>(); kafkaParams.put("metadata.broker.list", brokers) ; kafkaParams.put("bootstrap.servers", brokers); kafkaParams.put("group.id", "group1"); kafkaParams.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); kafkaParams.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); kafkaParams.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); //通过KafkaUtils.createDirectStream(...)获得kafka数据,kafka相关参数由kafkaParams指定 JavaInputDStream<ConsumerRecord<Object,Object>> lines = KafkaUtils.createDirectStream( ssc, LocationStrategies.PreferConsistent(), ConsumerStrategies.Subscribe(topicsSet, kafkaParams) ); JavaDStream<WaterSensor> mapDStream = lines.map(new Function<ConsumerRecord<Object, Object>, WaterSensor>() { @Override public WaterSensor call(ConsumerRecord<Object, Object> s) throws Exception { WaterSensor waterSensor = JSONObject.parseObject(s.value().toString(),WaterSensor.class); return waterSensor; } }).window(Durations.minutes(9), Durations.minutes(6)); //指定窗口大小 和 滑动频率 必须是批处理时间的整数倍; mapDStream.foreachRDD(new VoidFunction2<JavaRDD<WaterSensor>, Time>() { @Override public void call(JavaRDD<WaterSensor> waterSensorJavaRDD, Time time) throws Exception { SparkSession spark = JavaSparkSessionSingleton.getInstance(waterSensorJavaRDD.context().getConf()); Dataset<Row> dataFrame = spark.createDataFrame(waterSensorJavaRDD, WaterSensor.class); // 创建临时表 dataFrame.createOrReplaceTempView("log"); Dataset<Row> result = spark.sql("select * from log"); System.out.println("========= " + time + "========="); //输出前20条数据 result.show(); //数据写入mysql writeDataToMysql(result); } }); //开始作业 ssc.start(); try { ssc.awaitTermination(); } catch (Exception e) { e.printStackTrace(); } finally { ssc.close(); } } }
NBI大数据可视化构建平台对接mysql,构建数据应用:
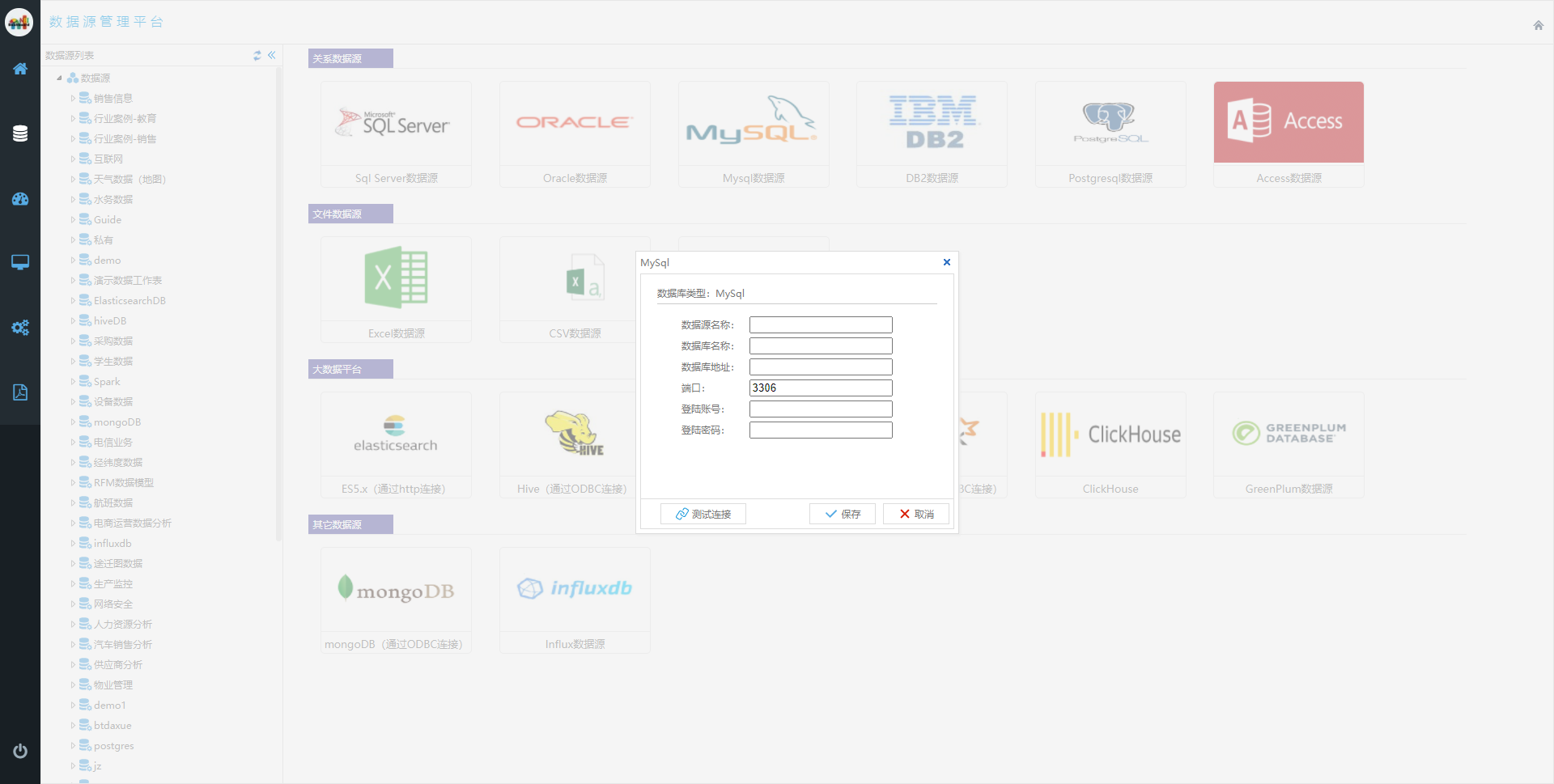

NBI可视化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号