python自动化之unittest
一、官方文档:
https://docs.python.org/zh-cn/3/library/unittest.html
二、unittest使用
-
unittest 使用规范
需要导入unittest包 测试类必须继承unittest.TestCase类 测试方法必须要以test开头 测试用例名称不能相同,相同的情况可能出现用例遗漏执行的情况 ddt使用事项见下方-
unittest中提供了前置、后置处理,及用例跳过功能,直接见下面代码【新建Mytest1.py】
import unittest # 这个Mytest1 可以称为 test case(测试单元),包含测试前,测试,测试后的执行顺序 class Mytest1(unittest.TestCase): def setUp(self) -> None: """ 当前类下,每条用例的前置 """ print("====setUp") def tearDown(self) -> None: """ 当前类下,每条用例的后置 """ print("====tearDown") @classmethod def setUpClass(cls) -> None: """ 当前类下,第一个执行,只执行一次 """ print("====setUpClass") @classmethod def tearDownClass(cls) -> None: """ 当前类下,最后一个执行,只执行一次 """ print("====tearDownClass") def test_one(self): """ 测试用例,需要以test开头 """ print("测试用例-test_one") self.assertEqual(1, 2) def testTwo(self): """ 测试用例,需要以test开头 """ print("测试用例-testTwo") self.assertEqual(1, 1) def tthree(self): """ 未以test开头,无法加载 """ print("测试用例-tthree") @unittest.skip("直接跳过") def test_four(self): """ 需要跳过的用例 测试用例,需要以test开头 """ print("测试用例-test_one") self.assertEqual(1, 2) @unittest.skipIf(1 == 1, "条件为true跳过") def test_five(self): """ 需要跳过的用例 测试用例,需要以test开头 """ print("需要跳过的用例") self.assertEqual(1, 2) @unittest.skipUnless(1 > 2, "条件为false跳过") def test_six(self): """ 需要跳过的用例 测试用例,需要以test开头 """ print("需要跳过的用例") self.assertEqual(1, 2) if __name__ == '__main__': unittest.main(verbosity=2) """ 0 (静默模式): 你只能获得总的测试用例数和总的结果 比如 总共10个 失败2 成功8 1 (默认模式): 非常类似静默模式 只是在每个成功的用例前面有个“.” 每个失败的用例前面有个 “F” 2 (详细模式):测试结果会显示每个测试用例的所有相关的信息 """ # 命令行方式 # python -m unittest Mytest1.py点击查看运行结果
====setUpClass ====setUp 测试用例-testTwo ====tearDown ====setUp 测试用例-test_one ====tearDown ====tearDownClass testTwo (__main__.Mytest1) ... ok test_five (__main__.Mytest1) ... skipped '条件为true跳过' test_four (__main__.Mytest1) ... skipped '直接跳过' test_one (__main__.Mytest1) ... FAIL test_six (__main__.Mytest1) ... skipped '条件为false跳过' ====================================================================== FAIL: test_one (__main__.Mytest1) ---------------------------------------------------------------------- Traceback (most recent call last): File "D:/WorkSpace/PythonWorkSpace/test_unit/Mytest1.py", line 45, in test_one self.assertEqual(1, 2) AssertionError: 1 != 2 ---------------------------------------------------------------------- Ran 5 tests in 0.000s FAILED (failures=1, skipped=3)
-
关于跳过及断言的方法可以参考顶部官方文档

- 关于自动化代码运行有两种方式:编辑器 和 命令行(命令行更加详细的指令可以参考官方文档)
- 注意:前两张图是通过编辑器运行的,操作方式不同展示效果不同,注意区分


- 关于自动化代码运行有两种方式:编辑器 和 命令行(命令行更加详细的指令可以参考官方文档)
-
unittest 数据驱动(ddt)
-
上面的例子展示了unittest的基本使用,这里有一个问题,假如出现一千条数据,都想用test_one(),怎么办?
只需要引入一个ddt模块就好了,无需重复写一千条test_one()
这里常见的数据驱动格式分为3种:json、yaml、excel,根据需要自己选择
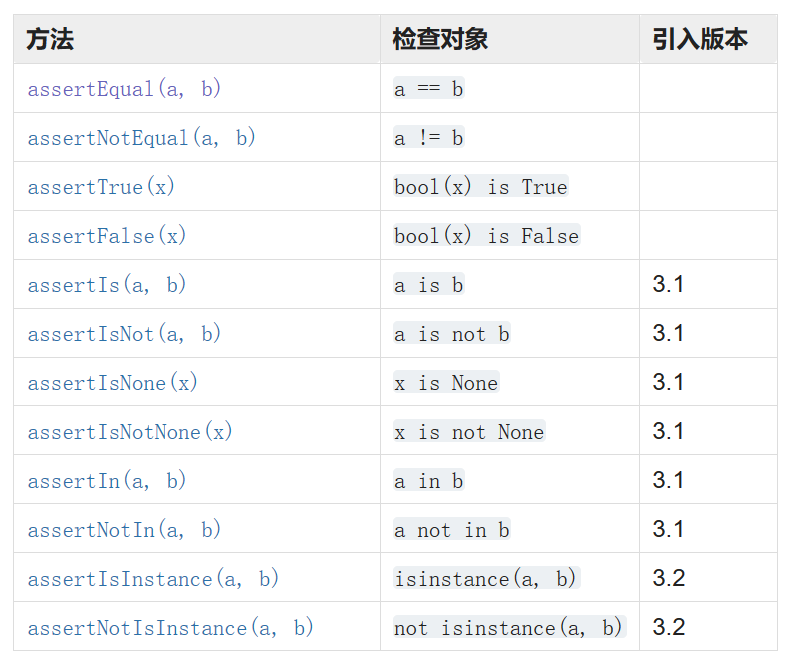
需要提前将三种数据拆成统一的数据格式【新建readdate.py】:# -*- coding: utf-8 -*-# import xlrd, os import json import yaml class ReadData: def __init__(self): # 提前加载数据 self.json_path = os.path.dirname(os.path.dirname(__file__)) + r"/testData/data.json" self.yaml_path = os.path.dirname(os.path.dirname(__file__)) + r"/testData/data.yaml" self.excel = os.path.dirname(os.path.dirname(__file__)) + r"/testData/data.xlsx" self.wb = xlrd.open_workbook(self.excel) # 找到第一个sheet页 self.sh = self.wb.sheet_by_index(0) self.rown = self.sh.nrows # 获取行 self.coln = self.sh.ncols # 获取列 def read_json(self): f = open(self.json_path, "r") testdata = json.load(f) f.close() return testdata def read_yaml(self): f = open(self.yaml_path, "r") # https://blog.csdn.net/weixin_43868406/article/details/125824271 testdata = yaml.load(f, Loader=yaml.FullLoader) f.close() return testdata def read_excel(self): """ 对于excel数据,不像json和yaml可以直接load,excel需要直接转换一下 :return: """ data = [] dict1 = {} for i in range(1, self.rown): # 从1开始,因为要排除第一行表头 keyList = self.sh.row_values(0) # 第一行作为数据的key valueList = self.sh.row_values(i) # 从excel的第二行开始才是真的数据 for j in range(len(keyList)): # 每轮训一次,就将数据组装成字典 dict1[keyList[j]] = valueList[j] data.append(dict1) # 每组装完一个字典数据就追加到list中 return data if __name__ == '__main__': re = ReadData() print(re.read_json()) print(re.read_yaml()) print(re.read_excel()) """ 下方数据中的[] 会被data(*)所拆解,而其中的内容会被unpack拆解 [{'name': 'Amy', 'age': 18}, {'name': 'Sam', 'age': 20}] [{'name': 'daming', 'age': 18}, {'name': 'lingling', 'age': 20}] [{'name': '李四', 'age': 20.0}, {'name': '李四', 'age': 20.0}] """ -
【新建Mytest2_ddt_data.py】
# -*- coding: utf-8 -*-# import unittest from ddt import ddt, data, unpack from readdata import ReadData reda = ReadData() rdj = reda.read_json() # json数据 rdy = reda.read_yaml() # yaml数据 rde = reda.read_excel() # excel数据 # print(rd) # 需要在顶部引入一个@ddt,表示当前class下会有数据注入 @ddt class Mytest2_ddt_data(unittest.TestCase): def setUp(self) -> None: """ 当前类下,每条用例的前置 """ print("----setUp----") def tearDown(self) -> None: """ 当前类下,每条用例的后置 """ print("----tearDown----") @classmethod def setUpClass(cls) -> None: """ 当前类下,第一个执行,只执行一次 """ print("========setUpClass") @classmethod def tearDownClass(cls) -> None: """ 当前类下,最后一个执行,只执行一次 """ print("========tearDownClass") @data(*rdj) @unpack def test_one(self, name, age): """ 测试用例,需要以test开头 """ print(name) print(age) @data(*rdy) @unpack def test_two(self, name, age): """ 测试用例,需要以test开头 """ print(name) print(age) @data(*rde) @unpack def test_three(self, name, age): """ 测试用例,需要以test开头 """ print(name) print(age) if __name__ == '__main__': unittest.main(verbosity=2) """ 0 (静默模式): 你只能获得总的测试用例数和总的结果 比如 总共10个 失败2 成功8 1 (默认模式): 非常类似静默模式 只是在每个成功的用例前面有个“.” 每个失败的用例前面有个 “F” 2 (详细模式):测试结果会显示每个测试用例的所有相关的信息 """ # 命令行方式 # python -m unittest Mytest1.py """ ====setUpClass ====setUp 测试用例-testTwo ====tearDown ====setUp 测试用例-test_one ====tearDown ====tearDownClass """点击查看运行结果
test_one_1 (__main__.Mytest2_ddt_json) ... ok test_one_2 (__main__.Mytest2_ddt_json) ... ok test_three_1 (__main__.Mytest2_ddt_json) ... ok test_three_2 (__main__.Mytest2_ddt_json) ... ok test_two_1 (__main__.Mytest2_ddt_json) ... ok test_two_2 (__main__.Mytest2_ddt_json) ... ok ---------------------------------------------------------------------- Ran 6 tests in 0.001s OK ========setUpClass ----setUp---- Amy 18 ----tearDown---- ----setUp---- Sam 20 ----tearDown---- ----setUp---- 张三 18.0 ----tearDown---- ----setUp---- 李四 20.0 ----tearDown---- ----setUp---- daming 18 ----tearDown---- ----setUp---- lingling 20 ----tearDown---- ========tearDownClass
补充:
为什么@data(*)中会存在*呢?
这里不得不说一下ddt的详细使用及其注意事项:
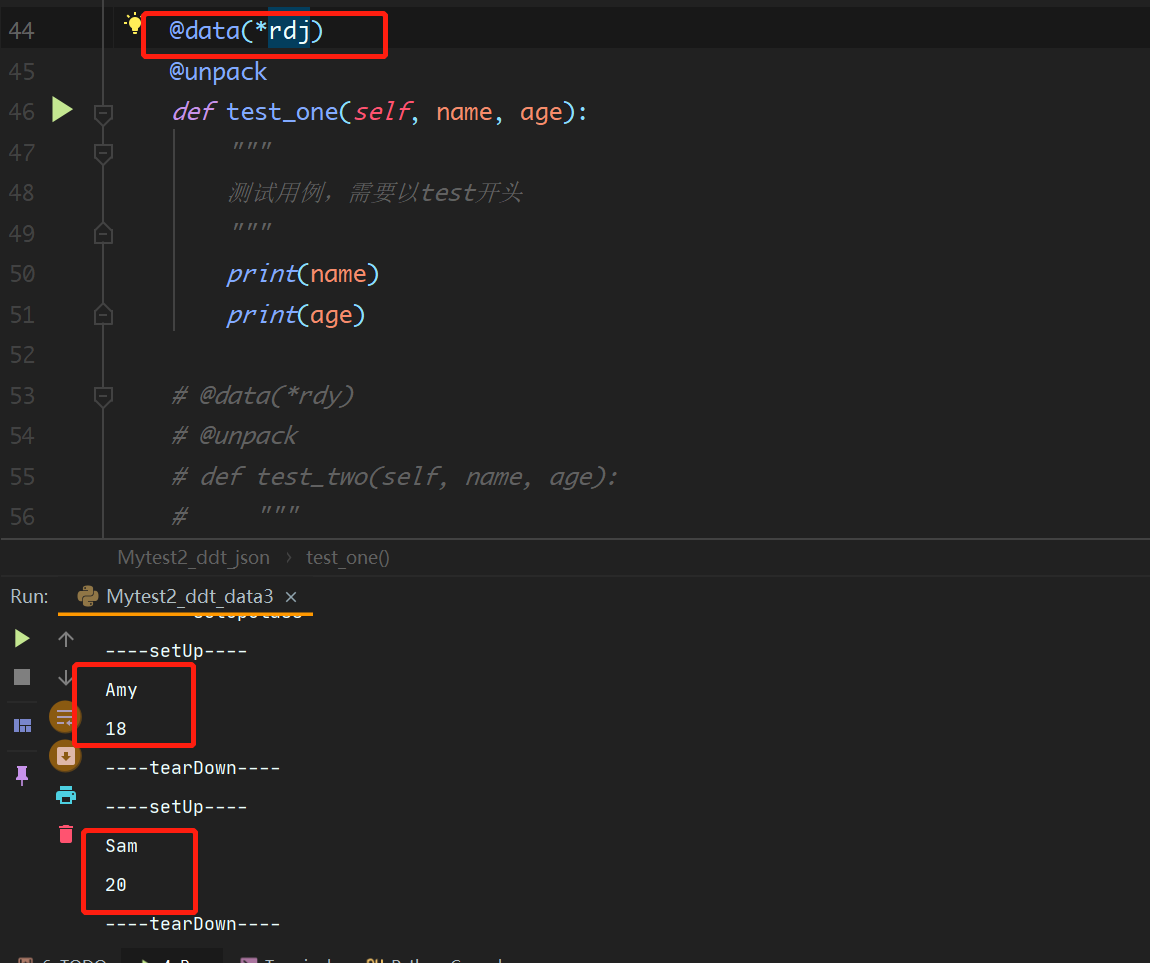
ddt初步探路,点我查看
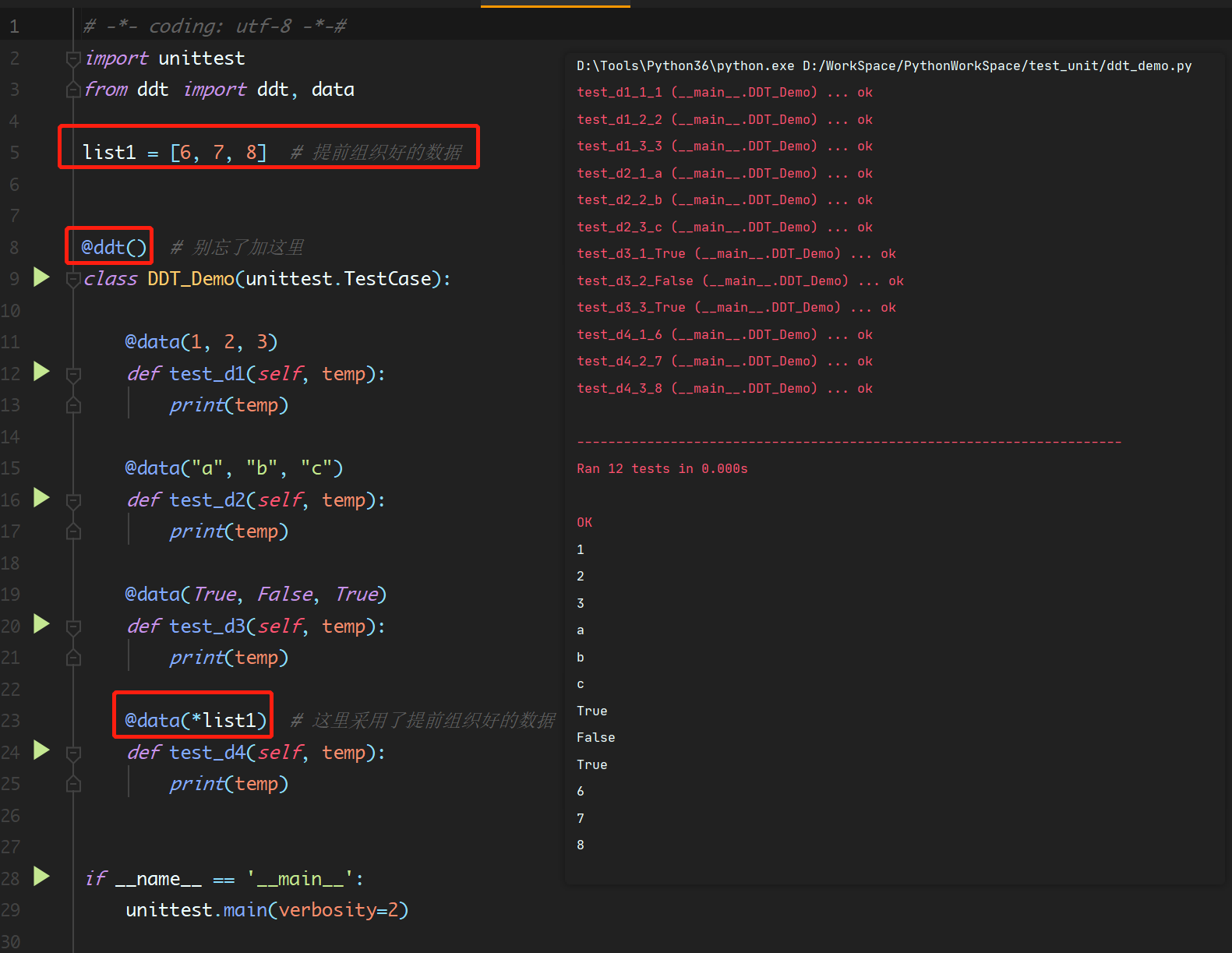
# -*- coding: utf-8 -*-# def param_demo(*args): """ 不定长传参 :param args: """ print(args) if __name__ == '__main__': aa = [1, 2, 3] param_demo(aa) # ([1, 2, 3],) ,直接传无法拆分,只会整体当做元组中的一个元素 param_demo(*aa) # 加星号会把列表拆解后传入进去 bb = {1, 2, 3} param_demo(*bb) """ 运行结果: ([1, 2, 3],) (1, 2, 3) (1, 2, 3) """
ddt进阶使用,点我查看代码
这里新导入了一个包 unpack,目的是将多维的数据格式拆解成可解析的格式。复杂的数据格式就需要引用这个装饰器了
所以在上方案例中,数据源是从另外的模块中引入的,并通过 * 来进行拆包处理
看完上面ddt的使用(折叠区域),可以发现ddt提高了代码的复用率,相同操作不同数据用一个testCase就可以了
但引用了ddt也是有一个缺陷:并不是一份testCase就可以驱动所有数据的,这样就会带来一个问题
每次执行用例时都需要找到相应文件进行手动运行,虽然比未添加数据驱动要少执行几次,但是这样仍然很费时费力这时就非常需要一个管理者,将所有测试用例管理起来,一键执行
- 需要我们在文件夹的根目录中【新建main.py】,当做整个程序的入口(叫run.py也行)
- 实例化TestLoader并调用discover方法,找到符合条件的用例组合成test suite(测试套件)
- 最后通过runner来运行该测试集
- (结果出现错误是符合预期的,因为是故意写的错误用例)
# -*- coding: utf-8 -*-# import os import unittest if __name__ == '__main__': case_dir = os.path.dirname(__file__) + r"/" print(case_dir) # 1 实例化TestLoader loader = unittest.defaultTestLoader # 2 调用discover方法生成测试套件,所有为Mytest开头的py文件都会执行 suite = loader.discover(start_dir=case_dir, pattern="Mytest*.py") # 3 验证测试套件 # print(suite) # 4 运行 # runner = unittest.TextTestRunner(verbosity=2) # runner.run(suite)
-
-
测试报告
测试报告作为测试要素之一是不可缺少的,没有报告的测试是不完整的
下面就来引入测试报告- 下载测试报告模板(链接另存为...) http://tungwaiyip.info/software/HTMLTestRunner.html
- 注意:常规操作是这样的,但是它非中文,而且展示效果普通(主要是我没整通),所以下面的报告模板用了网友分享的汉化版(这个整通了),下图方法作为参考
- 将HTMLTestRunner模块导入,注释掉3、4,写法见 5
# -*- coding: utf-8 -*-# import os import time import unittest from testCase.HTMLTestRunner import HTMLTestReportCN if __name__ == '__main__': case_dir = os.path.dirname(__file__) + r"/" print(case_dir) # 1 实例化TestLoader loader = unittest.defaultTestLoader # 2 调用discover方法生成测试套件 suite = loader.discover(start_dir=case_dir, pattern="Mytest*.py") # 3 验证测试套件 # print(suite) # 4 运行 # runner = unittest.TextTestRunner(verbosity=2) # runner.run(suite) # 5 生成报告 cur_time = time.strftime("%Y_%m_%d_%H_%M_%S", time.localtime()) # print(type(cur_time)) # 创建报告文件名及路径 report_file = os.path.dirname(__file__) + r"/testReport/" + cur_time + "report.html" print(report_file) # 打开文件并写入信息 with open(report_file, "wb") as rf: # 实例化HTMLTestReportCN得到一个runner(HTMLTestReportCN是报告模板里的方法) runner = HTMLTestReportCN(stream=rf, title='接口自动化测试报告', description='接口测试结果', verbosity=2, tester='马大哈') # 执行测试套件 runner.run(suite)
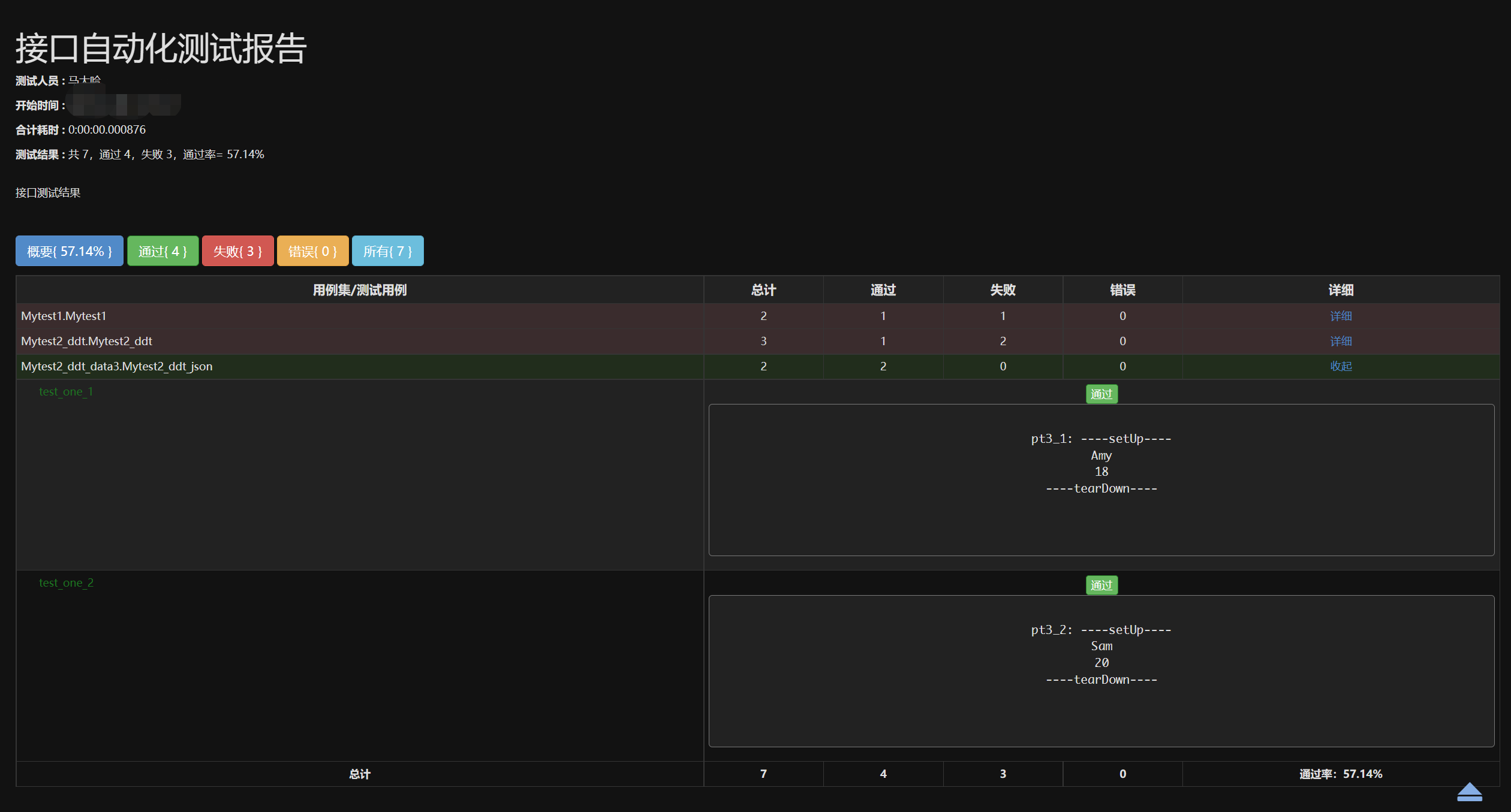
- 下载测试报告模板(链接另存为...) http://tungwaiyip.info/software/HTMLTestRunner.html
-
项目优化
基础的流程写完了,回头来看项目结构,惨不忍睹。所有的文件都在同一级下,这样是不符合要求的
自动化测试框架需要有个固定的文件结构:
|- testCase :测试用例(以test开头的且符合unittest加载逻辑的)
|- testData :测试数据(.json、.yaml、excel)
|- testReport :测试报告(.html)
|- testLog :测试日志(.log)
|- common/utils :公共方法(可复用的)
|- config... :配置文件(ini、yaml等)
|- main.py :测试入口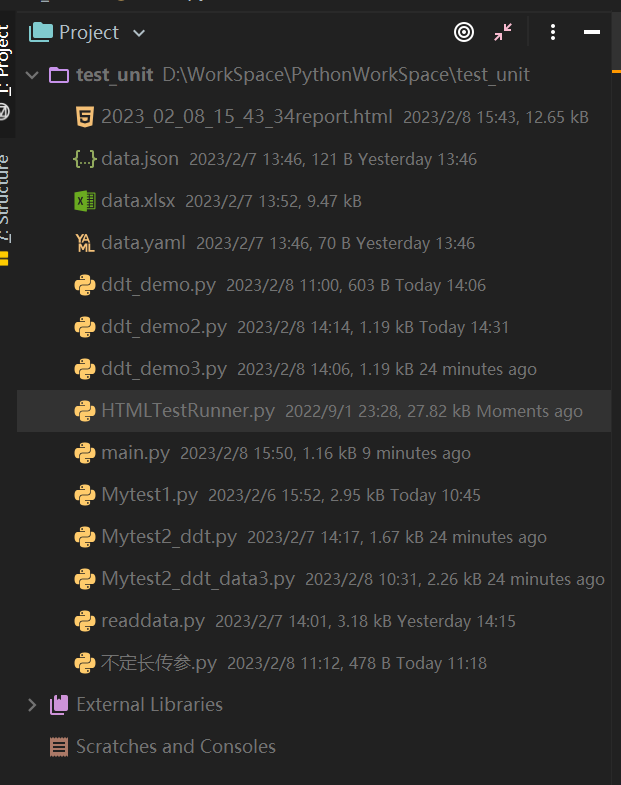

-
至此,unittest框架结束,可以在当前框架进行优化升级,相应的文件放置对应的文件夹下即可。
- 如:如果想进行接口测试,就在common中添加request操作的模块
- 如:如果想进行系统测试,就在common中添加ssh操作的模块,进行指令的发送与接收
- 如:如果想进行 ui 测试,就在common中封装元素定位操作的模块(po模式)
三、总结:unittest和pytest你更倾向谁?
unittest和pytest都是Python中用于编写单元测试的测试框架,它们有许多相同点和不同点。
1. 测试用例命名规则
- unittest的测试用例命名规则是test开头,后面跟着下划线和测试用例名称,如test_addition、test_subtraction等。
- pytest的测试用例命名规则更加灵活,可以是任意可调用对象的名称,只需要在函数或方法上使用@pytest.mark.test标记即可识别为测试用例,如def test_addition()、def test_subtraction()等。
2. 断言方法
- unittest的断言方法包括assertEqual、assertNotEqual、assertTrue、assertFalse、assertIs、assertIsNone等,可以用于比较值、判断真假、判断对象是否相同等。
- pytest的断言方法则是使用python的assert语句来实现,比如assert a == 1、assert b is not None等,也可以使用pytest中提供的assert关键字来进行断言,如assert a == 1、assert b is not None等。
3. 测试收集和运行机制
- unittest的测试收集和运行机制比较简单,需要手动创建测试套件、测试用例,并使用TestLoader和TestRunner来执行测试。
- pytest的测试收集和运行机制更加灵活和智能化,可以自动发现测试文件和测试函数,并自动运行测试,支持参数化、fixture等高级用法,使测试编写更加简单和高效。
4. Fixture
- Fixture是pytest中的一个重要概念,可以用于管理测试用例的前置和后置条件,比如创建数据库连接、创建测试文件、关闭文件等。
- unittest也提供了setUp和tearDown方法来管理测试用例的前置和后置条件,但相对来说不如pytest的Fixture灵活和易用。
总的来说,unittest和pytest都是Python中优秀的测试框架,可以用于编写各种类型的测试,但pytest更加灵活和易用,已经成为Python中的主流测试框架之一。
四、参考指路
官方文档:
https://docs.python.org/zh-cn/3/library/unittest.html参考链接:
https://blog.csdn.net/tlqwanttolearnit/article/details/124410245
https://blog.csdn.net/weixin_43868406/article/details/125824271
https://www.cnblogs.com/buchi-baicai/p/15979901.html
https://www.cnblogs.com/wsy0202/p/12853757.html
https://blog.csdn.net/BJ1599449/article/details/116980658代码地址:
-


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程