Python的多进程与多线程(上)
前言:
在我的印象中,如果想提高代码执行效率,首先想到的就是多线程
但是不久前看到了多进程的实现方式,便在多进程和多线程的选择上犯了难
在工作中只是去套用,却没有深入去了解这俩的区别,什么时间该用什么
所以今天就来正式的研究下(本文白话居多,专业术语移步其他文章!!!)
首先举个例子:
如果我们把程序比作夜市,那么进程就好比夜市中的各种小吃摊位,线程就是某个摊位中各种花样的小吃。
所以一个夜市至少得有一个摊位吧(一个摊位没有叫啥夜市)
一个摊位至少有一种小吃(种类多,生意才能好)
这样的话对应关系就显而易见了:
一个 夜市 至少有一个 摊位,而一个 摊位 至少有一种 小吃(特色菜)
一个 程序 至少有一个 进程,而一个 进程 至少有一个 线程(主线程)
我们在运行程序的时候:
会在电脑中创建一个进程(夜市),在这个进程中会默认创建一个线程(摊位,必须有的,一个摊位夜市可以叫夜市的,不能一个都没有)
线程是工作的单位,进程是为线程提供工作的单位
线程负责执行,数据会放到进程中保存(不知道这么说严不严谨)

那么多进程和多线程谁更快一些呢?我们该如何使用呢?
一、多进程与多线程的区别
-
多线程可以共享全局变量,多进程不能(一个摊位的调料是可以一直用的,但是不能用其他摊位的);
多线程中,所有子线程的进程号相同(一个摊位所有用具都是这个摊位的logo);
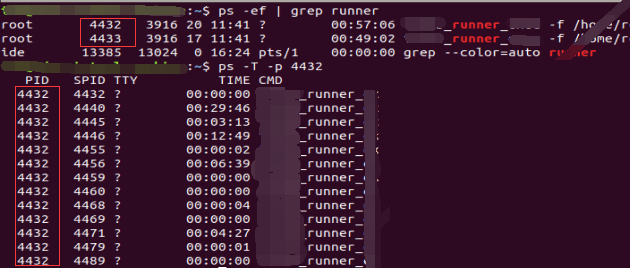
多进程中,不同的子进程进程号不同(不同的摊位有不同的特色,后厨不共用);我们可以通过 ps -ef | grep ** 的方式获取程序进程进程
通过 ps -T -p pid 来查看详细的线程
二、多进程与多线程谁更快
2.1、先补下如下的知识点
-
2.1.1、同步和异步
- 同步:一次只能执行一个任务,这个任务没结束,下个任务不能被执行,得等
- 异步:当一个任务开始后不用等它结束,可以直接发起下个任务,任务执行完毕后会按照各自的结束时间来返回结果,可以提高效率(nice)
- 举例子时间:
- 同步就相当于夜市新开了一家烧烤摊位,老板+服务员+传菜员+厨师+前台都是一个人,当来很多顾客吃饭时,就得等老板忙完、收拾完,才能顾得上你
- 异步就是刚才那个烧烤摊位老板生意越做越大,有了自己的店面,雇了员工,当你去吃饭时,就有人过来传菜单,有人给你烤串,无需等待,到那就能吃上(真好),哪桌吃完了就有人过来收拾卫生,不用一直等老板了
-
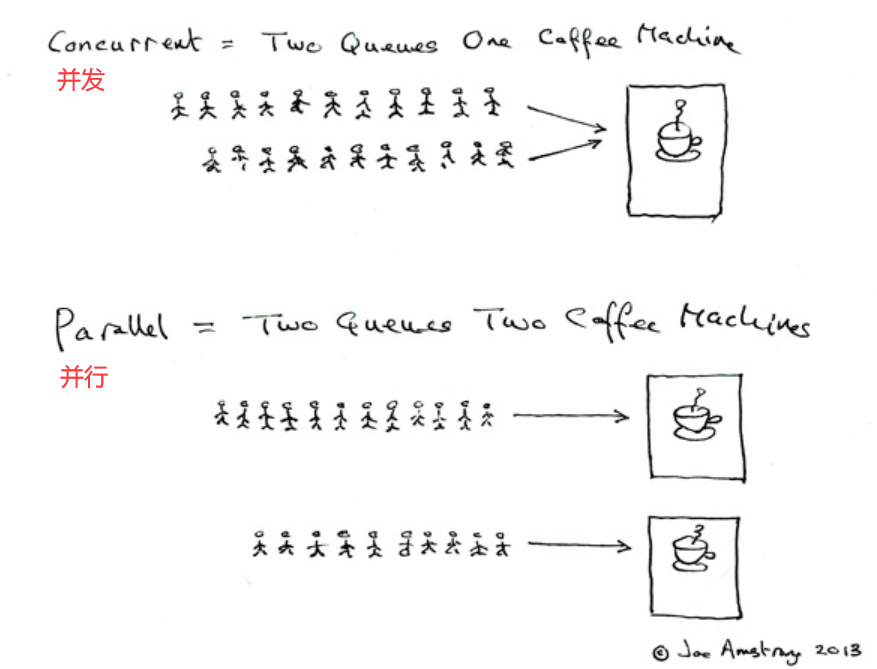
2.1.2、串行、并行、并发
-
串行:其实和刚才的同步很像,一次只能干一件事,上一件事没结束之前,下一件事不开始
-
并行:夜市中的蜜雪冰城店,好几个店员一起忙活,排了好几列的队,同一时间能卖出多杯
-
并发:还是刚才那个创业初期的烧烤店老板,日复一日的工作练就了老手,即使外面排了好几列的队,他也能一个人照看好(边烤串边结账,边擦桌子边招呼客人)
这里我总把并行和并发搞混!得着重记一下 并发其实只需要一个cpu就可以完成了,因为处理速度太快了,所以误以为是同时,截取某一时刻他还是串行(表面并行,背后快速轮流串行)。 并行的关键就是同时,真正意义上的同时,会调用多个cpu。
-
-
2.1.3、什么是GIL
结合代码去理解(可以最后阅读这里)
首先python中的多线程并不是真正的同时执行,因为GIL(全局解释器锁,关键词:CPython、GIL)这个玩应,使得一个进程在某一时刻只能有一个线程执行
如果想真正同时执行多个线程,那么就创建多进程就好了(进程被创建时会默认创建一个线程,让GIL无多余线程可锁),这样会消耗多个cpu进行调度,如果没有多个cpu调度的需求,用多线程就好了(一个cpu,疯狂快速切换执行,造成同时执行的假象)
-
2.2、多线程代码示例
先来看一下在未使用多线程的情况,执行需要6s的时间
可以看出这三个任务是依次执行完的,所以结束时间是所有任务时间之和
import time
run_list = [('t1', 2), ('t2', 1), ('t3', 3)]
# 起始时间
print(f'开始:{time.time()}')
def run(name, n):
print("当前运行:", name)
time.sleep(n)
# 当前执行完的时间
print(time.time())
for n, t in run_list:
run(n, t)
# 最终执行的时间
print(f'结束:{time.time()}')
"""
开始:1665372741.4817226
当前运行: t1
1665372743.4962828
当前运行: t2
1665372744.5042088
当前运行: t3
1665372747.5144725
结束:1665372747.5144725
"""
再来看一下使用多线程的情况,执行需要3s的时间
使用多线程记得导入threading包
这里的结束时间的打印之所以很快,是因为我们只计算了3个指令发送的时间,并没有将实际运行时间进行计算,执行run()的指令发送出去后就不需要我们进行等待了,这样大大缩短等待时间,提高了效率
import threading # 导包
import time
run_list = [('t1', 2), ('t2', 1), ('t3', 3)]
# 起始时间
print(f'开始:{time.time()}')
def run(name, n):
print("当前运行:", name)
time.sleep(n)
# 当前执行完的时间
print(time.time())
# 多线程的方式
for n, t in run_list:
# 创建线程,让每个线程去执行run
thread = threading.Thread(target=run, args=(n, t)) # run不写(),args代表传的参数
thread.start()
# 最终执行的时间(此处并非整体时间)
print(f'结束:{time.time()}') # 这里计算的并非程序整体时间,因为无需我们等待上一个任务结束,所以看结果会发现很快
"""
开始:1665380440.085015
当前运行: t1
当前运行: t2
当前运行: t3
结束:1665380440.0860703
1665380441.0920136
1665380442.1007667
1665380443.0925868
"""
-
2.3、多进程代码示例
多进程同样也可以提升效率
使用多进程记得导入multiprocessing包
用法其实和多线程差不多,也是3S的时间执行完毕(每个进程里面会默认创建一个主线程的)
至于为什么代码的写法变了,是因为python内部机制的原因,这个可以自行百度(关键词:fork、spawn)
import multiprocessing
import time
run_list = [('t1', 2), ('t2', 1), ('t3', 3)]
def run(name, num):
print("当前运行:", name)
time.sleep(num)
# 当前执行完的时间
print(f'{name}:{time.time()}')
if __name__ == '__main__':
# 起始时间
print(f'开始:{time.time()}')
# 多进程的方式
for n, t in run_list:
# 创建进程,让每个进程去执行run
thread = multiprocessing.Process(target=run, args=(n, t)) # run不写(),args代表传的参数
thread.start()
# 最终执行的时间
print(f'结束:{time.time()}')
"""
开始:1665383310.4989989
结束:1665383310.5069683
当前运行: t3
当前运行: t1
当前运行: t2
t2:1665383311.7177815
t1:1665383312.7080626
t3:1665383313.7146847
"""
多线程和多进程会发现他们都很快,只是针对不同的场景,需要作出不同选择
三、多进程与多线程的选择
- 思考?通过上面的代码也能看出多进程的开销比较大,是不是所有的业务都用多线程就好了
- 首先,多进程和多线程都能将原本的串行变为并行,需要不同业务不同分析,选择最优解
-
3.1、CPU 和 IO密集型
- CPU密集型代码(各种循环处理、计数等等)
- 涉及到计算,cpu一直都闲不下来,处理的快慢完全和cpu挂钩
- IO密集型代码(文件处理、网络爬虫等)
- 爬虫,文件下载啥的,就发请求的时候用到了cpu,其他时间全看网速和磁盘大小啥的了,cpu消耗极低
- 判断方法:
- 查看CPU占用率, 查看硬盘IO读写速度
- 代码中涉及的计算处理多时————CPU密集型:多进程效果比较好
- 代码中涉及等待时长较多时————IO密集型:多线程效果比较好
- 当然,创建进程后,在进程后创建线程的操作也是可以的,但是这个骚操作我还没在工作中遇到过(不给自己找麻烦)

- CPU密集型代码(各种循环处理、计数等等)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程