python利用openpyxl处理excel(应用案例一)
一前言
环境:win10 python3.8
二 应用案例
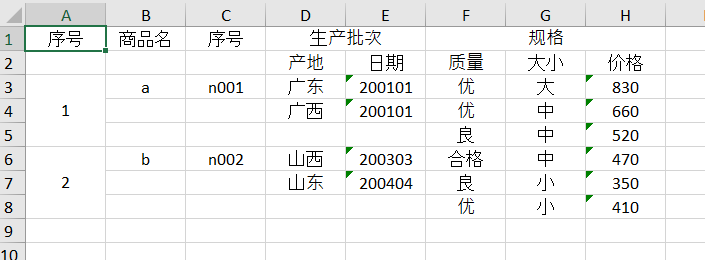
如上要实现这样一张表格,其中序号字段和值是临时添加的,其它字段和值在预先准备好的数据里
1分析
-
不能去指定在某个位置去插入某个字段,如在a1去插入序号,a2去插入商品。不能这样做,给出字段后,要自动挨个依次插入
-
如一级字段规格要与它下面的二级字段相对应,二级字段占据了三列,一级字段也要占3列,且要合并
-
序号字段要依据该条数据所占用的行来合并,每增加一条数据,其值+1
-
所有字段居中
2 代码
from openpyxl import Workbook,load_workbook
from openpyxl.styles import Alignment
from loguru import logger
# 新建一个excel文件
def new_workbook():
wb = Workbook()
return wb
# 在excel文件里新建一个excel表格
def new_worksheet(wb, name):
ws = wb.create_sheet(name)
return ws
def get_workbook(file):
# 根据文件名读取一个excel文件
wb = load_workbook(file)
return wb
def get_worksheet(wb,name):
#根据name获取一个worksheet
ws = wb[name]
return ws
def save_excel(wb,file):
# 保存内容到文件系统,没有这一步无法更新或保存文件
wb.save(file)
# 选择数据范围进行合并
def merge_cells(ws,start_row, start_column, end_row, end_column):
ws.merge_cells(start_row=start_row, start_column=start_column, end_row=end_row, end_column=end_column)
# 获取表格中数据范围的最大行
def get_max_row(ws):
return ws.max_row
# 获取表格中数据范围的最大列
def get_max_col(ws):
return ws.max_column
# 用append的方式在一行中一次性依次插入多个数据
def append_data(ws,data):
"""
data: list
eg :['data1','data2']
"""
ws.append(data)
# 把给定的数据在一行内的每一列依次写入
def write_data_excel_with_append(ws,datas):
"""
datas: list
eg: ['field1', 'field2']
"""
if datas:
append_data(ws, datas)
#选择范围,范围内所有数据居中
def fields_center(ws):
max_row = get_max_row(ws)
max_col = get_max_col(ws)
logger.info(f'max_row: {max_row}')
logger.info(f'max_col: {max_col}')
# 遍历数据范围内的所有数据,居中
for row in ws.iter_rows(min_row=1,max_row=max_row,min_col=1,max_col=max_col):
for cell in row:
cell.alignment = Alignment(horizontal='center', vertical='center')
# 获取一级字段和二级字段
def output_first_second_fields(data):
"""
data: list
eg: [
{'一级标题1':'v1', '一级标题2': 'v2',
'一级标题3':[{'二级标题_3_1':'v_3-1-1', '二级标题_3_2':'v3-2-1'},{'二级标题_3_1':'v_3-1-2', '二级标题_3_2':'v3-2-2'}]
},
{'一级标题1':'v100', '一级标题2': 'v200',
'一级标题3':[{'二级标题_3_1':'v_3-1-100', '二级标题_3_2':'v3-2-100'},{'二级标题_3_1':'v_3-1-200', '二级标题_3_2':'v3-2-200'}]
}
]
return : dict
eg: {'first_fields' : ['一级标题1','一级标题2','一级标题3'],
'second_fields' : {'一级标题3':['二级标题_3_1','二级标题_3_2'], '一级标题4':['二级标题xx1','二级标题xx12','二级标题xx3']}
}
"""
first_second_fields = {}
first_second_fields['first_fields'] = []
first_second_fields['second_fields'] = {}
if data:
for k,v in data.items():
if isinstance(v,list):
first_second_fields['second_fields'][k] = list(v[0].keys())
first_second_fields['first_fields'].append(k)
return first_second_fields
# 根据给定的字段,写入一级和二级字段到excel
def write_fields_to_excel(ws,first_fields,second_fields,col_strat=1):
"""
first_fields: list 一级字段名
eg: ['商品名','商品类型','批次信息','规格']
second_fields: dict k为一级字段, v为对应的二级字段
eg: {'批次信息':['产地','日期'], '规格':['质量','大小','价格']}
col_strat: 插入字段时的起始列,前面没有插入其它字段时,默认为1
"""
col = col_strat
for first_field in first_fields:
# 写入一级字段名
ws.cell(row=1,column=col,value=first_field)
# 一级字段
if first_field not in second_fields:
col += 1
#非一级字段
else:
#二级字段名
current_second_fields = second_fields[first_field]
if current_second_fields:
current_second_fields_num = len(current_second_fields) #二级字段数
# 根据二级字段数选择具体的列, 合并二级字段对应的一级字段名
merge_cells(ws,start_row=1,start_column=col, end_row=1, end_column=col+current_second_fields_num-1)
# 根据列的起始列位置写入二级字段
second_field_col = col
for second_filed in current_second_fields:
ws.cell(row=2,column=second_field_col, value=second_filed)
second_field_col += 1
#下一个一级字段的所在列的位置
col += current_second_fields_num
def write_content_to_excel_auto(ws,data:dict,current_row_begin,current_col_begin=1):
"""
data: dict 每条数据
eg: {'商品名':'b', '序号': 'n002','生产批次':[{'产地':'山西', '日期':'200303'}
current_row_begin: 当条数据写入的起始行, 它应该是上条数据的结束行+1
current_col_begin=1: 当条数据写入的起始列,如果在data中的字段外有其它字段,应该是其它字段的结束列+1
"""
# 依次写入当条数据的所有字段值
for k,v in data.items():
# 写入一级字段的数据值
if not isinstance(v, list):
ws.cell(row=current_row_begin, column=current_col_begin,value=v)
current_col_begin += 1
#二级字段的数据值
else:
#二级字段数据值的起始写入列
second_field_value_start_row = current_row_begin
# v类型为list: 表示某一级字段下所有二级字段的数据值
# field_value: 某个一级字段下所有二级字段的部分数据值,这部分在同一行
# 一行一行地写入某一级字段下的所有二级字段的部分数据值
for field_value in v:
second_field_value_start_col = current_col_begin
values = list(field_value.values())
# field_value中的具体数据一列一列地写入
for v in values:
ws.cell(row=second_field_value_start_row, column=second_field_value_start_col,value=v)
second_field_value_start_col += 1
# 二级字段数据值当前行写入完毕 下一行的位置
second_field_value_start_row +=1
#下一个一级或二级字段的起始写入列
current_col_begin = second_field_value_start_col
# 写入完成后,第一列的数据进行合并(默认第一列为序号)
current_data_max_row = get_max_row(ws) #截至当前所占用的最大行
merge_cells(ws,start_row=current_row_begin,start_column=1, end_row=current_data_max_row, end_column=1)
执行
def main(myself_fields):
"""
myself_fields : list 这里默认只有一个序号
"""
myself_fields_length = len(myself_fields)
all_data = [{'商品名':'a', '序号': 'n001','生产批次':[{'产地':'广东', '日期':'200101'},{'产地':'广西', '日期':'200101'}],'规格':[{'质量':'优','大小':'大','价格':'830'},{'质量':'优','大小':'中','价格':'660'},{'质量':'良','大小':'中','价格':'520'}]},
{'商品名':'b', '序号': 'n002','生产批次':[{'产地':'山西', '日期':'200303'},{'产地':'山东', '日期':'200404'}],'规格':[{'质量':'合格','大小':'中','价格':'470'},{'质量':'良','大小':'小','价格':'350'},{'质量':'优','大小':'小','价格':'410'}]}]
#excel文件和表格
wb = new_workbook()
ws = new_worksheet(wb, 'test')
# 在首行写入自定义的字段
write_data_excel_with_append(ws, myself_fields)
# 获取预先准备好的all_data中的字段
first_second_fields = output_first_second_fields(all_data[0])
first_fields = first_second_fields['first_fields']
second_fields = first_second_fields['second_fields']
logger.info(f'first_fields: {first_fields}')
logger.info(f'second_fields: {second_fields}')
#获取的字段写入excel
write_fields_to_excel(ws,first_fields,second_fields,col_strat=myself_fields_length+1)
# 向excel写入all_data中的数据值
for index, data in enumerate(all_data,start=1):
#每行数据所在的起始行
current_row_begin = get_max_row(ws) + 1
# 自定义字段值的初始值为1 ,然后每增加一条数据+1
ws.cell(row=current_row_begin, column=1, value=index)
#写入数据值
write_content_to_excel_auto(ws, data,current_row_begin,current_col_begin=myself_fields_length+1)
# 所有字段居中
fields_center(ws)
#保存到文件系统,没有这一步无法生成excel文件
save_excel(wb=wb,file='test.xlsx')
main(['序号'])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号