Beautiful Soup--在python中解析HTML或XML
关于beautifulsoup
Beautiful Soup 是一个python第三方库,用来从HTML或XML文件中提取数据
现在最新的版本是beautiful soup 3已经停止开发,现在最新推荐使用的是beautiful soup 4
安装
pip install beautifulsoup4
beautifulsoup要用起来还需要一个解析器的东西,官网列出了主要的一些解析器
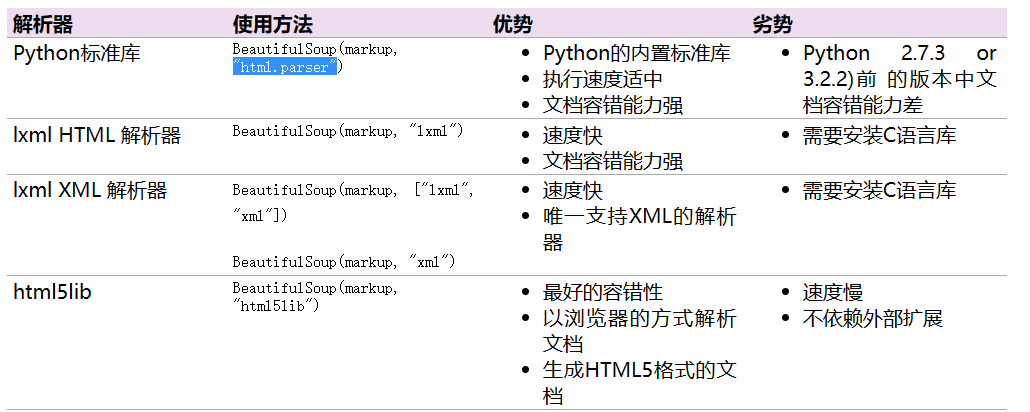
除了第一个标准库中的html.parser,其他几个都需要另外安装
个人常用的是lxml
pip install lxml
基本概念
beautifulsoup中基本的对象类型
在BeautifulSoup中有4种类型的数据,Tag, NavigableString, BeautifulSoup, and Comment
Tag对象
结合htmll的基础知识,通过名字就可以了解到,tag对象就是html或xml中的一个个tag(标签)
一个简单的例子
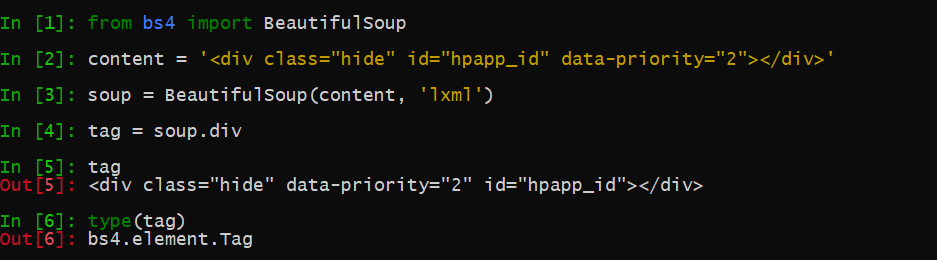
如上 整个div标签的内容就是一个tag对象,一个tag对象最重要的特征就是tag的 name和attributes
另外,一个tag对象有许多有许多的函数和属性,后面的函数部分会说到
name
每个tag对象都有一个name,可通过tag.name来得到。这里的name也就是html中的标签名

name可以修改,但只会在当前通过Beautiful Soup解析得到的文档内起作用,不会对改变原始的HTML或XML文档

Attributes
如 class id等都是tag的属性,'hide'是对应的属性值。可以把tag当作python中的字典,通过字典的访问形式来得到对应属性值
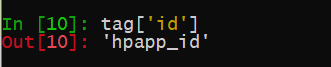
tag.attrs会得到tag的所有属性和对应的值,返回的类型是一个字段

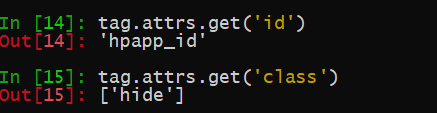
注意,像class这种html规定的多值属性,在返回属性值时,属性值会放在list中返回。其它类型的属性值则是直接返回
属性可以修改,属性值可以删除,这可以像操作一个dict一样去操作,tag是dict,属性是key,属性值是value。通常访问操作比较多,修改、删除比较少,具体可看官网
关于多值属性
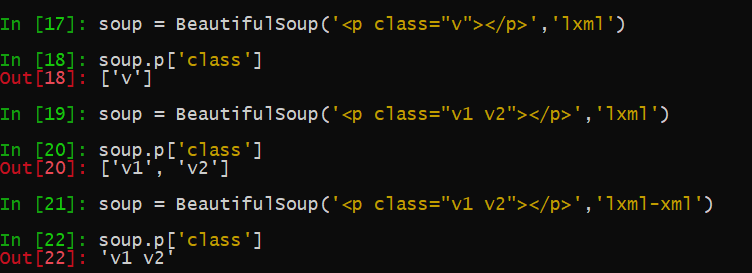
一个tag属性是否是多值属性是由html所规定的,不过,不同的html版本的规定也有差异。常见的多值属性有class、accept-charset、headers、rel等。多值属性有多个值时,通常会以空格隔开,返回到list中时,不同的值会成为list的不同的item
多只属性仅仅是对html而言,XML是没有多值属性的。因此,XML中,多值属性的值返回时并不会包裹在list中
NavigableString
即tag中显示的文本内容,通过tag.string来访问

tag.string的值很像是python中的字符串,他们之间确实很像,但tag.string的值作为NavigableString类型支持Beautiful Soup定义部分函数和属性。
通过python的str()函数,可以把一个NavigableString对象变成真正的python字符串
BeautifulSoup
BeautifulSoup对象即BeautifulSoup(xxx,xxx)的返回值,这是我们使用BeautifulSoup的第一步,它包含了已被解析的文档中的所有内容,所有的tag tag.name Attributes等都是在它的基础之上展开,
可以像使用一个tag一样来使用BeautifulSoup对象,相当于一个最根上的tag
即
soup = BeautifulSoup(xxxx)
soup.name
soup.find(xxx)
示例代码
环境: python3.10
BeautifulSoup4.40
windows 10
soup = BeautifulSoup("<html>test</html>",'lxml')
如上,soup代表一个BeautifulSoup对象,
如果要解析一个xml文档,第2个参数要改下
soup = BeautifulSoup("<html>test</html>",'lxml-xml')
下面用官网的一个html例子来示范一些函数的用法


find_all()
find_all() 方法搜索当前tag的所有tag子节点

如上 找出所属有的p标签,结果如下

find_all也收受一个列表作为参数

find_all接受一个boolean值作为一个参数

如上会输出文档中的所有标签名,有意思的是传入False结果是一样的
在find_all中传入标签的属性的关键字参数,根据标签的属性值来查找目标
根据标签的单个属性来查找目标

属性值也可以是正则或者boolean的形式

如上,id属性值为boolean类型,只要有id属性,无论其值是什么,这种标签都会被找到
根据标签的多个属性来查找目标,

如上,在文档中根据属性href和id的值来找出标签,属性值为正则形式
标签的有些属性不能放在find_all中直接使用,如HTML5中的 data-xx 属性
将上面的html文档修改一下


如上,可以在find_all中的attrs参数定义一个dict来包含data-xx等特殊属性

标签的class属性搜索
html例子中的a标签有class属性,class标识CSS类名的关键字,但class在python中同样是规定的关键字,表示一个类。所以calss不能像上面的id属性一样直接可以使用,从Beautiful Soup的4.1.1版本开始,class在find函数中要写成class_

如上,找到所有的a便签,同时a标签的class属性值是sister
class_的值同样可以是正则表达式,boolean
多值属性的搜索
属性值中有空格时为多值属性,在Beautiful Soup中多值属性的返回类型是list,如下

在find函数中使用多值属性时,以空格为界,使用空格前或者空格后的都行



find_all中传入string 参数
string值即标签的文本内容,支持字符串、正则、boolean、list等形式,注意传入string时返回的并不是满足此string的标签

返回的结果是一个list,list内容好像是文本内容本身,注意,list内容的类型并不是python的string类型,这个内容是beautiful soup的一种对象,类型是NavigableString
一个 NavigableString 字符串与Python中的字符串相同,并且还支持一些beautiful soup的函数和属性. 通过 str() 方法可以直接将 NavigableString 对象转换成python字符串

string参数可以其他参数混用

如上,就得到了一个list,里面是满足此string的所有标签
另外需要注意的是,一个标签可能包含文本内容(string)和其他标签,这些都是这个标签的子节点。
所以一个标签如果没有其它标签的话,它唯一的子节点就是该标签的文本内容,通过content属性,可以得到一个标签所有的子节点

在string上应用parent属性,就可以得到该属性的父节点,即看起来是string所在的标签


find_all中的 recursive 参数
执行find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可以使用参数 recursive=False
find()
find和find_all的使用很类似,但find只会得到一个结果,find_all会得到所有的满足条件的结果
find_parents() 和 find_parent()
find_parents() 和 find_parent() 用来搜索当前节点的父辈节点
可以添加的参数同find find_all一样,除了 recursive参数


如图,和前面的string参数中的例子类似,返回了好像是标签的文本内容所在的标签
find_parent()返回当前标签或者string的直接父节点,而find_parent()还会返回直接父节点的兄弟节点和其他祖先节点,即大伯父 二伯父 各位列祖列宗等,如下


如上 find_parents()返回数据很多,通常,我们会传入一些参数来筛选想要的数据


find_next_siblings() and find_next_sibling()
对当前节点的后面寻找兄弟节点
可以添加的参数同find find_all一样,除了 recursive参数


find_previous_siblings() and find_previous_sibling()
在当前节点的前面寻找兄弟节点
可以添加的参数同find find_all一样,除了 recursive参数


find_all_next() and find_next()
返回当前节点后面所有的符合要求的节点或者string
find_all_next() 方法返回所有符合条件的, find_next() 方法返回第一个符合条件的:


如图,不仅返回了当前节点后面的兄弟节点,后面的非兄弟节点也返回了
可以添加的参数同find find_all一样,除了 recursive参数


find_all_previous() and find_previous()
和find_all_next() and find_next()相对应,返回前面的
get_text()
针对当前对象返回其文本


这和标签的string属性很像


不同的是,他们返回数据的类型是不同的,还有就是,string只能在用于一个节点的情况且该节点只有一个子节点(即文本内容)
还有很多很多其它函数及理解这些函数的一些基础概念,具体看官网
https://beautiful-soup-4.readthedocs.io/en/latest/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号