日常使用awk方法总结
简介
awk命令在日常查看数据文件或者日志文件时非常有用。它可以根据筛选规则筛选出满足条件的行,加以处理并输出。比如我想知道系统中哪些用户名字以‘r’开头,UID小于10而且可以通过bash登陆,并以‘--’为分割符输出来。那么我们就可以用以下命令实现:
awk -F ":" '/^r/ && $3 < 10 && && /bash/ {print $1 " -- " $NF}' /etc/passwd

1 基本用法
awk pattern { actions }
命令参数分为2部分。pattern部分指明了筛选行的规则,如上述示例中就是从/etc/passwd中筛选出用户名以‘r’开头,且UID<10, 且可以使用bash登陆的行。actions 是对筛选出的行做哪些操作,上述例子中是输出每行的第一列和最后一列,并以‘--’连接。
awk对于筛选出来的每行会用分割符进行划分,默认是空格,可以使用-F进行设置。分割出的每一列都会用awk自己的变量存储,例如$1, $2..., $0表示一行的所有内容。
pattern和actions必须有一个,不能两个都没有。
2. pattern部分的使用
<1> 关系表达式
这个比较简单,直接使用列进行运算就可以。常用的运算符可以是 ==,> , <, >=, <=, != 等等。具体可以参考简介中的示例。
<2> 正则表达式
正则表达式需要写在两个斜线之间,如简介中的示例。再例如'/^(root|sys)/', 表示选出以root或者sys开头的行。
<3> 混合模式
使用&&, ||, ! 连接起来的关系表达式和正则表达式。简介中的示例很好地解释了这种方法的使用
<4> 区间模式
以逗号隔开的两个表达式。比如 awk '/^root/, $3==100' {print}' /etc/passwd,表示把/etc/passwd中,以root开头的那一行到UID为100那一行之间的行输出来。
<5> BEGIN模式和END模式
在处理筛选出的行之前输出某些内容或者处理后输出某些内容。在一次awk生命周期中,BEGIN和END只执行一次。
3. actions部分的使用
这部分内容比较多,我只了解到比较简单和常用的几种用法。在这里介绍一下。
<1> 使用 -F 来指定每行的分割符。比如简介的示例中,由于/etc/passwd中的每行中数据和数据之间是用 ‘:’连接的。所以使用 -F 来指定分割符。
<2> NF, 表示一行中分割出字段的个数。不加‘$’输出NF的值,加‘$’输出最后一个字段的值。比如 awk -F ":" '{print $NF}', 输出最后一个字段的值。
<3> NR, 行号,和NF的用法一样。比如 awk '{print NR " " $0}' /etc/passwd, 表示输出/etc/passwd的每一行并且在开头输出行号。
<4> FILENAME, 这个就比较好理解了,文件名。
<5> 我在action中使用的都是print,但是print输出的是原始内容,如果字段长短不一,比如命令,awk -F ":" '{print $(NF-3) " " $NF}' /etc/passwd, 就会输出这样的东西:
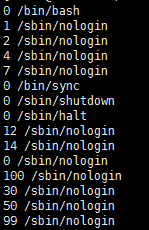
awk提供了printf函数,就像C语言的printf函数一样,可以进行格式化,比如我把刚才的命令修改一下,awk -F ":" '{print $(NF-3) " " $NF}' /etc/passwd, 就会这样输出。对于杂乱无章的日志文件,这样的输出更加清晰。
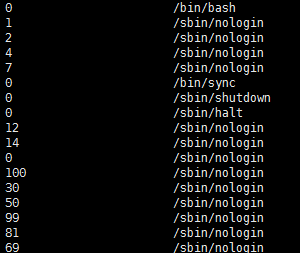
awk的格式控制符和C语言的格式控制符大同小异,这里就不在多做介绍。
<6> awk的action部分还支持各种循环结构,如for,do..whie, break。这些暂时没有用到,等用到了再总结补上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号