字节序问题的简单理解
什么是字节序?
什么是字节序我就不再啰嗦了,这样的文章在网上一搜一大片,而且很多写的颇有水平。我主要参考了以下3篇文章:
字节序详解:https://blog.csdn.net/ce123_zhouwei/article/details/6971544
理解字节序:http://www.ruanyifeng.com/blog/2016/11/byte-order.html
一篇英文博客:https://blog.erratasec.com/2016/11/how-to-teach-endian.html#.XAID0JMzZsM
什么情况下需要使用到字节序相关的知识?
在常见的高级语言中,一定有和int相关的基础类型。以32位环境下的C语言为例,如果一个数字大于255就必须要使用2个以上的字节去存储,比如short(2字节)和int(4字节)。对于short 0x1234来说,人们为了描述方便,0x12被叫做高字节,0x34被叫做低字节。假设从左到右是内存增长的方向,那么小端环境下这个short的存储方式是“0x34 0x12”,低地址存放低字节,高地址存放高字节。在大端环境下,这个short的存放方式是“0x12 0x34”,低地址存放高字节,高地址存放低字节。
现在假设一个场景。比如机器A是小端环境,机器B是大端环境,A通过socket TCP协议想把0x1234(10进制为4660)这个short发给B。使用socket发送数据的原理就是指定一块数据的起始地址和这块数据的长度,然后socket从起始地址开始,把bit一位一位写入TCP流中。对于short 0x1234来说,在A的内存中就是“0x34 0x12”, 转换为二进制就为“0011 0100 0001 0010”。当TCP数据流到达B后,B会把这串bit从低地址开始存放。也就是说,这串bit到了B之后,在内存中也是“0011 0100 0001 0010”。按照大端的解析内存方式,低地址存放的是高字节,高地址存放的是低字节,这串bit在B将会被解析为0x3412(十进制为13330)。看到了吧,B把A想要传递的信息给解析错了。这就是大端小端之间传递数据由于架构不同而导致的问题。其实不光是socket,A和B通过文件交互也是一个道理,因为文件也是从内存的低地址开始,按顺序写入一定个数的bit。
怎么解决字节序的问题?
所有的解决方式原理都是一样的,就是统一使用大端或者统一使用小端的方式去存取需要共享的int类数据。要么A在传输之前,把小端的bit转换为大端的bit。要么就是B在接到A的数据之后,自己做一下从小端bit到大端bit的转换操作。
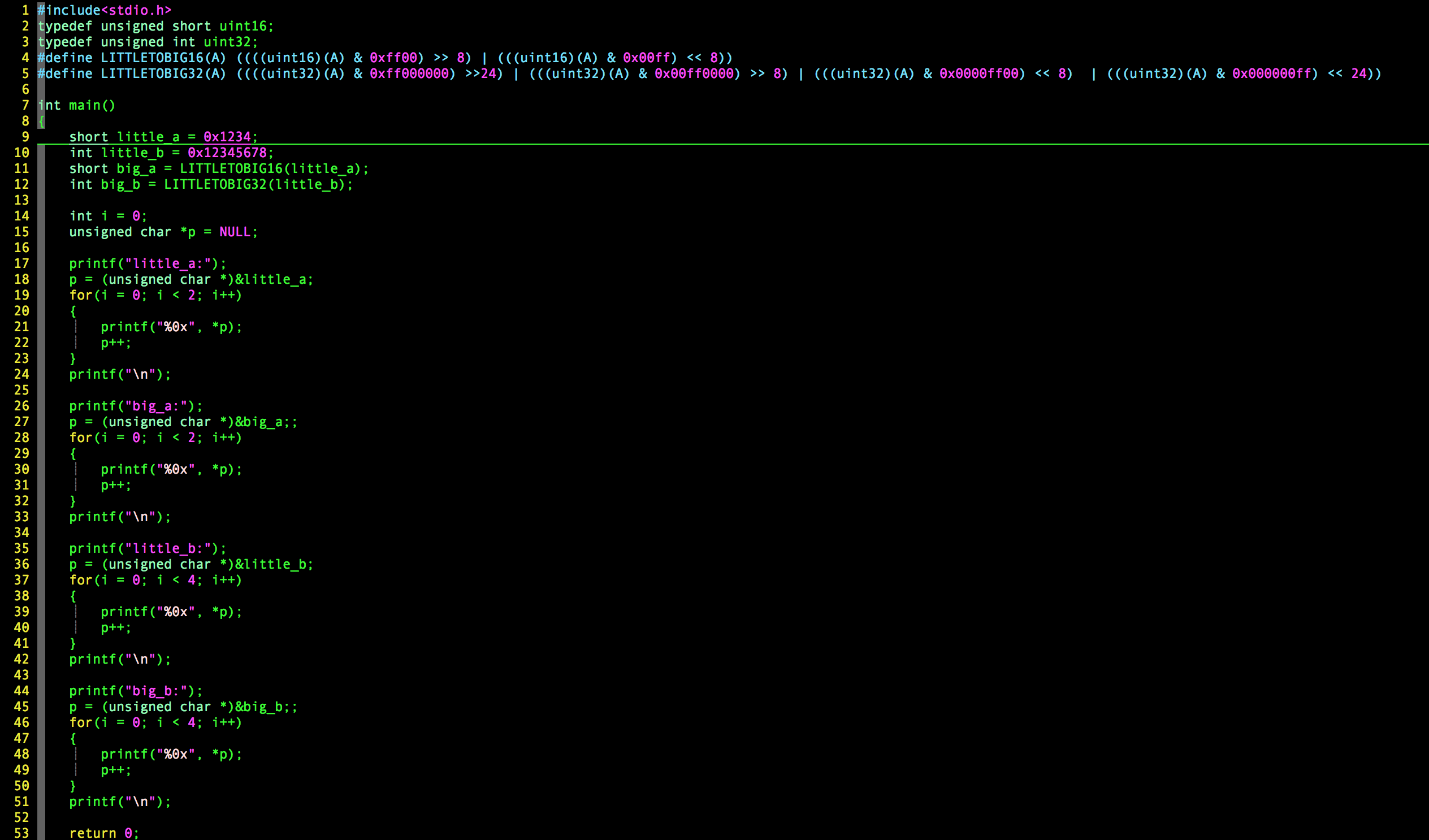
c语言给我们提供了ntohs,htons,ntohl,htonl来从本机字节序转换为大端字节序或者从大端字节序转换为本机字节序。其他大部分的语言也有相应的实现。
这几个函数的实现原理就是下图中的代码:
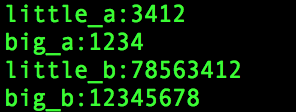
运行结果:
字节序引起问题的实例:
<1> 解析kafka的日志
kafka V1 日志格式如下:

8字节的offset + 4字节的size + 上图的结构
也就是说,如果我想要第一条消息,只需要跳过前0~25个字节,然后取第26~29字节,就是key的长度。然后跳过对应key的长度,再取4字节,就是payload的长度。
假设我生产的信息key="key", value="hello";
我编写代码的环境是小端字节序,那么我写以下代码来解析kafka的log:

运行结果:

可以看到,如果使用小端的方式解析这个文件,就会输出错误的结果。但是使用大端,则返回了期望的结果
也就是说,kafka在把数据写入文件时,是以大端方式的字节序列写入文件的,而我们读取的时候如果使用小端的方式解析这串字节序列,就会出现错误。
<2> 写代码得到zip压缩文件中某个文件的大小
zip包的格式可以参考这篇博文:https://blog.csdn.net/a200710716/article/details/51644421
有如下文件:

将其进行zip压缩:

写如下代码进行解析:

运行结果:

可以看到,zip格式在存储压缩大小时候是使用小端的方式存储的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号