Python数据分析numpy、pandas、matplotlib包
Python数据分析numpy、pandas、matplotlib
一、基础
1.1 notebook的一些配置
快捷键:
ctrl+enter 执行单元格程序并且不跳转到下一行
esc + L 可以显示行号
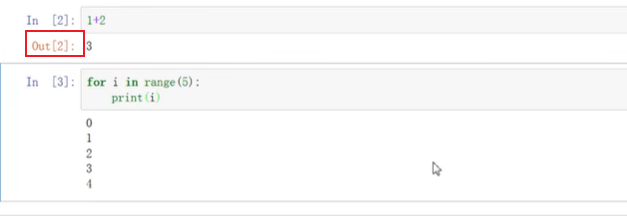
结果是打印的而没有返回任何的值就没有out
1.2 列表基础知识回顾
b=[1,2.3,'a','b']
b #列表中的元素允许各个元素不一样
list('abcde') #利用list生成列表
#[1, 2, 3, 4, 5, 1, 2.3, 'a', 'b']
a+b #将两个链表链接在一起
# [1, 2, 3, 4, 5, 1, 2.3, 'a', 'b']
| 方法 | 作用 | 举例 |
|---|---|---|
| append方法 | 在末尾增加一个数 | a.append(6) |
| insert方法 | insert(索引号,值) | a.insert(1,10) |
| pop | 1.pop方法,默认是删除最后一个元素,在里面写数字的话是写索引号2. | a.pop()/a.pop(1) |
b=[1,2,3,4,5,6,7,8,9]
#b=[a:b:i] #间隔取值,前面区间仍然是左闭右开,后面为步长,同样也适用于负数的情况
b[2:9:3]
#[3, 6, 9]
a[0:3] #数据切片,左闭右开区间
a[-1] #-1表示倒数第一个数
a[-3:-1] #负索引切片
a[:3]
a[-3:] #不写的话默认从左边第一个开始或者取到右边最后一个
1.3 元组基础知识回顾
另一种有序列表叫元组:tuple,用()来表示。tuple和list非常类似,但是tuple一旦初始化就不能修改,比如同样是列出演员的名字:
a = (1,2,3,4,5)
#a.pop() #报错,'tuple' object has no attribute 'pop'
a #用途:作为一个常量防止数据被篡改
(1, 2, 3, 4, 5)
1.4字典 dict
Python用{key:value}来生成Dictionary
字典里面的数据可以是任何数据类型,也可以是字典
mv = {"name":"肖申克的救赎","actor":"罗宾斯","score":9.6,"country":"USA"}
mv["name"]# '肖申克的救赎'
mv.keys()# dict_keys(['name', 'actor', 'score', 'country'])
mv.values() # dict_values(['肖申克的救赎', '罗宾斯', 9.6, 'USA'])
mv.items()# dict_items([('name', '肖申克的救赎'), ('actor', '罗宾斯'), ('score', 9.6), ('country', 'USA')])
1.5集合set
Python用{}来生成集合,集合不含有相同元素
s = {2,3,4,2}#自动删除重复数据
len(s)
s.add(1) #如果加入集合中已有元素没有任何影响
s1 = {2,3,5,6}
s & s1 #取交集 {2, 3}
s | s1 #取并集 {1, 2, 3, 4, 5, 6}
s - s1 #差集 {1, 4}
#s.remove(5) #删除集合s中一个元素,注意只能删除一次
#s.pop() #随机删除任意一个元素,删完后报错
#s.clear() #一键清空
1.6 可变与不可变对象
可变对象可以对其进行插入,删除等操作,不可变对象不可以对其进行有改变的操作。Python中列表,字典,集合等都是可变的,元组,字符串,整型等都是不可变的。
1.7 列表表达式
列表生成式即List Comprehensions,是Python内置的非常简单却强大的可以用来创建list的生成式
list(range(1,11)) #range(1,11)迭代器,左闭右开,只有一个参数从0开始,两个参数是区间,三个参数最后一个数是跨度,不写的时候默认跨度为1
# [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[x**2 for x in range(1,10)] #列表生成平方
[i for i in range(1,100) if i%10 == 0]
[str(x) for x in range(1,10)]
[int(x) for x in list("123456789")]
二、numpy
导入
NumPy是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多。NumPy(Numeric Python)提供了许多高级的数值编程工具。Numpy的一个重要特性是它的数组计算,是我们做数据分析必不可少的一个包。
导入python库使用关键字import,后面可以自定义库的简称,但是一般都将Numpy命名为np,pandas命名为pd。
导入的方法有以下几种:
import numpy
import numpy as np #推荐写法
from numpy import * #不是很建议这种写法,因为不用加前缀的话有可能会与其他函数名称起冲突,因而报错
2.1 Numpy的数组对象及其索引
数组上的数学操作
假设我们想将列表中的每个元素增加1,但列表不支持这样的操作:
a = [1,2,3,4]
#a+1 #报错
[x+1 for x in a] # [2, 3, 4, 5]
与另一个数组相加,得到对应元素相加的结果:
b = [2,3,4,5]
a+b #并不是我们想要的结果 [1, 2, 3, 4, 2, 3, 4, 5]
[x+y for(x,y) in zip(a,b)] #都需要利用到列表生成式
>>> a = [1,2,3] >>> b = [4,5,6] >>> c = [4,5,6,7,8] >>> zipped = zip(a,b) # 打包为元组的列表 [(1, 4), (2, 5), (3, 6)] >>> zip(a,c) # 元素个数与最短的列表一致 [(1, 4), (2, 5), (3, 6)] >>> zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式 [(1, 2, 3), (4, 5, 6)]
这样的操作比较麻烦,而且在数据量特别大的时候会非常耗时间。
如果我们使用Numpy,就会变得特别简单
产生数组
从列表产生数组:
l = [1,2,3,4]
a = np.array(l) # array([1, 2, 3, 4])
从列表传入:
a = np.array([1,2,3,4])
生成全0数组:
a = np.zeros(4) # 括号内传个数,默认浮点数 array([0., 0., 0., 0.])
生成全1的数组:
np.ones(5) #括号内传个数,默认浮点数
np.ones(5,dtype="bool") #可以自己指定类型,np.zeros函数同理
np.ones(5,dtype="bool") #可以自己指定类型,np.zeros函数同理 array([ True, True, True, True, True])
可以使用 fill 方法将数组设为指定值
a = np.array([1,2,3,4])
a.fill(5) #让数组中的每一个元素都等于5
与列表不同,数组中要求所有元素的 dtype 是一样的,如果传入参数的类型与数组类型不一样,需要按照已有的类型进行转换。
a.fill(2.5) #自动进行取整 array([2, 2, 2, 2])
如果非要全部fill成为浮点型的话,需要先进行类型转换
a = a.astype("float") #强制类型转换
a.fill(2.5)
a
还可以使用一些特定的方法生成特殊的数组
生成整数序列:
a = np.arange(1,10) #左闭右开区间,和range的使用方式同理
生成等差数列:
a = np.linspace(1,10,21) #右边是包括在里面的,从a-b一共c个数的等差数列,其实np.arange好像也可以做...
生成随机数
np.random.rand(10) # 括号内是需要的随机数个数
np.random.randn(10) #标准正态分布
np.random.randint(1,20,10) #生成随机整数,从1-20中随机10个
数组属性
查看数组中的数据类型:
a.dtype
查看形状,会返回一个元组,每个元素代表这一维的元素数目:
a.shape
或者使用:
np.shape(a)
要看数组里面元素的个数:
a.size
查看数组的维度:
a.ndim
索引和切片
和列表相似,数组也支持索引和切片操作。
索引第一个元素:
a = np.array([0,1,2,3])
a[0]
切片,支持负索引:
a = np.array([11,12,13,14,15])
a[1:3] #左闭右开,从0开始算 array([12, 13])
a[1:-2] #等价于a[1:3]
a[-4:3] #仍然等价a[1:3]
省略参数:
a[-2:] #从倒数第2个取到底
a[::2] #从头取到尾,间隔2
假设我们记录一部电影的累计票房:
ob = np.array([21000,21800,22240,23450,25000])
ob2 = ob[1:]-ob[:-1]
ob2

多维数组及其属性
array还可以用来生成多维数组:
a = np.array([[0,1,2,3],[10,11,12,13]])
事实上我们传入的是一个以列表为元素的列表,最终得到一个二维数组。
查看形状:
a.shape
查看总的元素个数:
a.size
多维数组索引
对于二维数组,可以传入两个数字来索引:
# array([[ 0, 1, 2, 3],
# [10, 11, 12, 13]])
a[1,3] # 第二行第四个
其中,1是行索引,3是列索引,中间用逗号隔开。事实上,Python会将它们看成一个元组(1,3),然后按照顺序进行对应。
可以利用索引给它赋值:
a[1,3] = -1
事实上,我们还可以使用单个索引来索引一整行内容:
# array([ 5, 6, 7, -1])
a[1]
Python会将这单个元组当成对第一维的索引,然后返回对应的内容。
a[:,1] # array([ 1, 11])
多维数组切片
多维数组,也支持切片操作:
a = np.array([[0,1,2,3,4,5],[10,11,12,13,14,15],[20,21,22,23,24,25],[30,31,32,33,34,35],[40,41,42,43,44,45],[50,51,52,53,54,55]])
# 得到第一行的第4和第5两个元素
a[0][3:5]
# 得到最后两行的最后两列
a[4:,4:]
# 得到第三列:
a[:,2]
每一维都支持切片的规则,包括负索引,省略
[lower:upper:step]
例如,取出3,5行的奇数列:
a[2:5:2,::2]
切片是引用
切片在内存中使用的是引用机制
引用机制意味着,Python并没有为b分配新的空间来存储它的值,而是让b指向了a所分配的内存空间,因此,改变b会改变a的值:

而这种现象在列表中并不会出现:

这样做的好处在于,对于很大的数组,不用大量复制多余的值,节约了空间。
缺点在于,可能出现改变一个值改变另一个值的情况。
一个解决方法是使用copy()方法产生一个复制,这个复制会申请新的内存:
花式索引
切片只能支持连续或者等间隔的切片操作,要想实现任意位置的操作。需要使用花式索引 fancy slicing。
一维花式索引
与range函数类似,我们可以使用arange函数来产生等差数组。
花式索引需要指定索引位置:

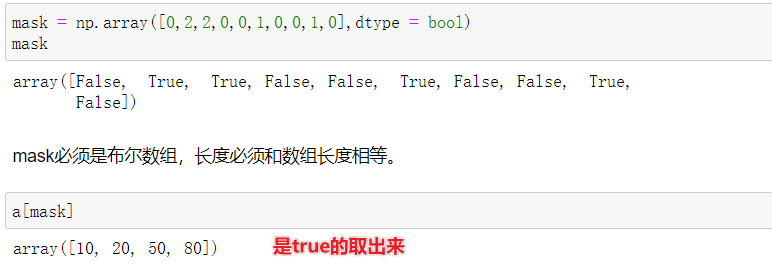
还可以用布尔数组来花式索引,mask必须是布尔数组,长度必须和数组长度相等。
二维花式索引
对于二维花式索引,我们需要给定行和列的值:
a = np.array([
[0,1,2,3,4,5],
[10,11,12,13,14,15],
[20,21,22,23,24,25],
[30,31,32,33,34,35],
[40,41,42,43,44,45],
[50,51,52,53,54,55]])
返回的是一条次对角线上的5个值。
a[(0,1,2,3,4),(1,2,3,4,5)]
行取01234行,列依次取第1,2,3,4,5个元素
返回的是最后三行的1,3,5列。
a[3:,[0,2,4]]
也可以使用mask进行索引:
mask = np.array([1,0,1,0,0,1],dtype = bool)
a[mask,2]
与切片不同,花式索引返回的是原对象的一个复制而不是引用。
“不完全”索引
只给定行索引的时候,返回整行:
y = a[:3]
# array([[ 0, 1, 2, 3, 4, 5],
# [ 1, 1, 1, 1, 1, 1],
# [20, 21, 22, 23, 24, 25]])
这时候也可以使用花式索引取出第2,3,5行:
con = np.array([0,1,1,0,1,0],dtype = bool)
a[con]
where语句
where(array)
where函数会返回所有非零元素的索引。
一维数组
先看一维的例子:
a = np.array([0,12,5,20])
判断数组中的元素是不是大于10:
a>10
# array([False, True, False, True])
数组中所有大于10的元素的索引位置:
np.where(a>10)
# (array([1, 3], dtype=int64),)
注意到where的返回值是一个元组。返回的是索引位置,索引[1,3]大于10的数
也可以直接用数组操作,这样可以得到具体的元素
a[np.where(a>10)]
# array([12, 20])
2.2数组类型
具体如下:

类型转换
a = np.array([1.5,-3],dtype = float)
# array([ 1.5, -3. ])
asarray 函数
a = np.array([1,2,3])
np.asarray(a,dtype = float)
# array([1., 2., 3.])
astype方法
astype 方法返回一个新数组:
a = np.array([1,2,3])
a.astype(float)
# array([1., 2., 3.])
a #a本身并没有发生变化--拷贝
2.3数组操作
我们以豆瓣10部高分电影为例
##电影名称
mv_name = ["肖申克的救赎","控方证人","美丽人生","阿甘正传","霸王别姬","泰坦尼克号","辛德勒的名单","这个杀手不太冷","疯狂动物城","海豚湾"]
##评分人数
mv_num = np.array([692795,42995,327855,580897,478523,157074,306904,662552,284652,159302])
##评分
mv_score = np.array([9.6,9.5,9.5,9.4,9.4,9.4,9.4,9.3,9.3,9.3])
##电影时长(分钟)
mv_length = np.array([142,116,116,142,171,194,195,133,109,92])
数组排序
sort函数
这个函数并不会改变原来的数组
np.sort(mv_num)
# array([ 42995, 157074, 159302, 284652, 306904, 327855, 478523, 580897,662552, 692795])
argsort函数
argsort返回从小到大的排列在数组中的索引位置:
order = np.argsort(mv_num)
# array([1, 5, 9, 8, 6, 2, 4, 3, 7, 0], dtype=int64)
查看评分人数最少的电影:
mv_name[order[0]]
求和
两种方式都可以:
np.sum(mv_num)
mv_num.sum()
最大值
np.max(mv_length)
mv_length.max()
最小值
np.min(mv_score)
mv_score.min()
均值
np.mean(mv_length)
mv_length.mean()
标准差
np.std(mv_length)
mv_length.std()
相关系数矩阵
np.cov(mv_score,mv_length)
2.4 多维数组操作
数组形状
a = np.arange(6)
# array([0, 1, 2, 3, 4, 5])
a.shape(n行,m列)可以生成一个n行m列的一个数组
a.shape=(2,3)
# array([[0, 1, 2],[3, 4, 5]])
与之对应的方法是reshape,但它不会修改原来数组的值,而是返回一个新的数组:
a.reshape(2,3)
# array([[0, 1, 2],[3, 4, 5]])
a #没变
转置
a = a.reshape(2,3)
#array([[0, 1, 2],[3, 4, 5]])
数组连接
有时候我们需要将不同的数组按照一定的顺序连接起来:
concatenate((a0,a1,...,aN),axis = 0)
注意,这些数组要用()包括到一个元组中去。
除了给定的轴外,这些数组其他轴的长度必须是一样的。
x = np.array([[0,1,2],[10,11,12]])
y = np.array([[50,51,52],[60,61,62]])
默认沿着第一维进行连接:
z = np.concatenate((x,y))
#array([[ 0, 1, 2],
# [10, 11, 12],
# [50, 51, 52],
# [60, 61, 62]])
沿着第二维进行连接:
z = np.concatenate((x,y),axis = 1)
#array([[ 0, 1, 2, 50, 51, 52],
# [10, 11, 12, 60, 61, 62]])
注意到这里x和y的形状是一样的,还可以将它们连接成三维的数组,但是concatenate不能提供这样的功能,不过可以这样:
z = np.array((x,y))
#array([[[ 0, 1, 2],
# [10, 11, 12]],
# [[50, 51, 52],
# [60, 61, 62]]])
事实上,Numpy提供了分别对应这三种情况的函数:
-
vstack
np.vstack((x,y)) #array([[ 0, 1, 2], # [10, 11, 12], # [50, 51, 52], # [60, 61, 62]]) -
hstack
np.hstack((x,y)) #array([[ 0, 1, 2, 50, 51, 52], # [10, 11, 12, 60, 61, 62]]) -
dstack
np.dstack((x,y)) '''array([[[ 0, 50], [ 1, 51], [ 2, 52]], [[10, 60], [11, 61], [12, 62]]])'''
2.5 Numpy内置函数
可以查阅:
https://blog.csdn.net/nihaoxiaocui/article/details/51992860?locationNum=5&fps=1
2.6 数组属性方法总结
| 调用方法 | 作用 |
|---|---|
| 1 | 基本属性 |
| a.dtype | 数组元素类型float32,uint8,... |
| a.shape | 数组形状(m,n,o,...) |
| a.size | 数组元素数 |
| a.itemsize | 每个元素占字节数 |
| a.nbytes | 所有元素占的字节 |
| a.ndim | 数组维度 |
| - | - |
| 2 | 形状相关 |
| a.flat | 所有元素的迭代器 |
| a.flatten() | 返回一个1维数组的复制 |
| a.ravel() | 返回一个一维数组,高效 |
| a.resize(new_size) | 改变形状 |
| a.swapaxes(axis1,axis2) | 交换两个维度的位置 |
| a.transpose(* axex) | 交换所有维度的位置 |
| a.T | 转置,a.transpose() |
| a.squeeze() | 去除所有长度为1的维度 |
| - | - |
| 3 | 填充复制 |
| a.copy() | 返回数组的一个复制 |
| a.fill(value) | 将数组的元组设置为特定值 |
| - | - |
| 4 | 转化 |
| a.tolist() | 将数组转化为列表 |
| a.tostring() | 转换为字符串 |
| a.astype(dtype) | 转换为指定类型 |
| a.byteswap(False) | 转换大小字节序 |
| a.view(type_or_dtype) | 生成一个使用相同内存,但使用不同的表示方法的数组 |
| - | - |
| 5 | 查找排序 |
| a.nonzero() | 返回所有非零元素的索引 |
| a.sort(axis=-1) | 沿某个轴排序 |
| a.argsort(axis=-1) | 沿某个轴,返回按排序的索引 |
| a.searchsorted(b) | 返回将b中元素插入a后能保持有序的索引值 |
| - | - |
| 6 | 元素数学操作 |
| a.clip(low,high) | 将数值限制在一定范围内 |
| a.round(decimals=0) | 近似到指定精度 |
| a.cumsum(axis=None) | 累加和 |
| a.cumprod(axis=None) | 累乘积 |
| - | - |
| 7 | 约简操作 |
| a.sum(axis=None) | 求和 |
| a.prod(axis=None) | 求积 |
| a.min(axis=None) | 最小值 |
| a.max(axis=None) | 最大值 |
| a.argmin(axis=None) | 最小值索引 |
| a.argmax(axis=None) | 最大值索引 |
| a.ptp(axis=None) | 最大值减最小值 |
| a.mean(axis=None) | 平均值 |
| a.std(axis=None) | 标准差 |
| a.var(axis=None) | 方差 |
| a.any(axis=None) | 只要有一个不为0,返回真,逻辑或 |
| a.all(axis=None) | 所有都不为0,返回真,逻辑与 |
2.7 作业
import numpy as np
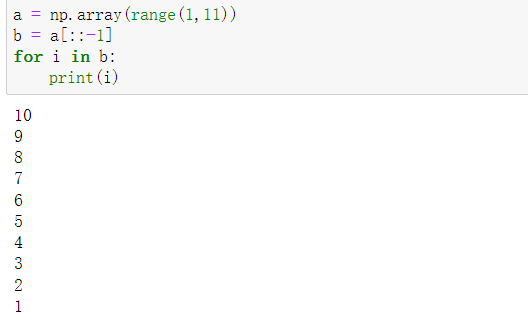
(1)创建一个1到10的数组,然后逆序输出。
a = np.array(range(1,11))
b = a[::-1]
for i in b:
print(i)
(2)创建一个长度为20的全1数组,然后变成一个4×5的二维矩阵并转置。
b =np.ones(20,dtype=int)
print(type(b))
b2 = b.reshape(4,5)
b2
b2.T
(3)创建一个3x3x3的随机数组。 (提示: np.random.random)

a = np.random.random(27)
a1 = a.reshape(3,3,3)
a1
或者
a = np.random.random((3,3,3))
(4)从1到10中随机选取10个数,构成一个长度为10的数组,并将其排序。获取其最大值最小值,求和,求方差。
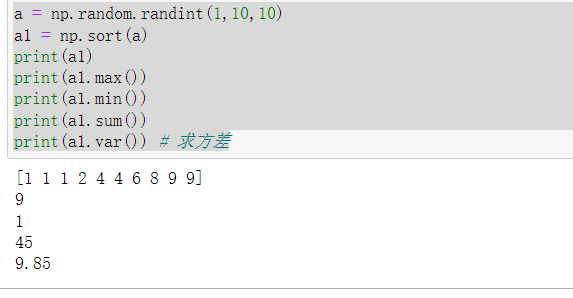
a = np.random.randint(1,10,10)
a1 = np.sort(a)
print(a1)
print(a1.max())
print(a1.min())
print(a1.sum())
print(a1.var()) # 求方差
(5)从1到10中随机选取10个数,构成一个长度为10的数组,选出其中的奇数。

a = np.random.randint(1,10,10)
print(a)
a1 = a[np.where(a%2==1)]
print(a1)
(6)生成0到100,差为5的一个等差数列,然后将数据类型转化为整数。
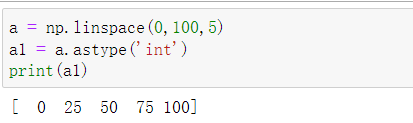
a = np.linspace(0,100,5)
a1 = a.astype('int')
print(a1)
(7)从1到10中随机选取10个数,大于3和小于8的取负数。

a = np.random.randint(1,10,10)
print(a)
index = np.where((a>3)&(a<8) )
a[index] = -a[index]
print(a)
(8)在数组[1, 2, 3, 4, 5]中相邻两个数字中间插入1个0。

a = np.array([1,2,3,4,5])
print(a)
# 插入之后1 0 2 0 3 0 4 0 5
b = np.zeros(len(a)*2-1)
print(b)
b[::2] = a
print(b)
或者

a = np.array([5,6,7,8,9])
np.insert(a,[1,2,3,4],[0,0,0,0])
在索引
[1, 2, 3, 4]的位置插入值[0, 0, 0, 0]
(9)新建一个5乘5的随机二位数组,交换其中两行?比如交换第一二行。
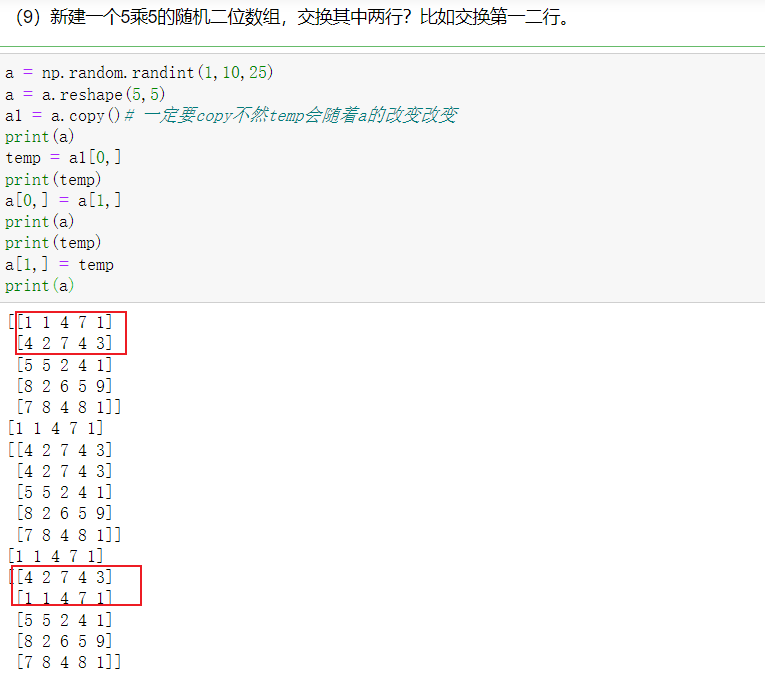
a = np.random.randint(1,10,25)
a = a.reshape(5,5)
a1 = a.copy()# 一定要copy不然temp会随着a的改变改变
print(a)
temp = a1[0,]
print(temp)
a[0,] = a[1,]
print(a)
print(temp)
a[1,] = temp
print(a)
或者

a = np.random.randint(1,10,(5,5))
a[[0,1],:] = a[[1,0],:]
a
(10)把一个10*2的随机生成的笛卡尔坐标转换成极坐标。
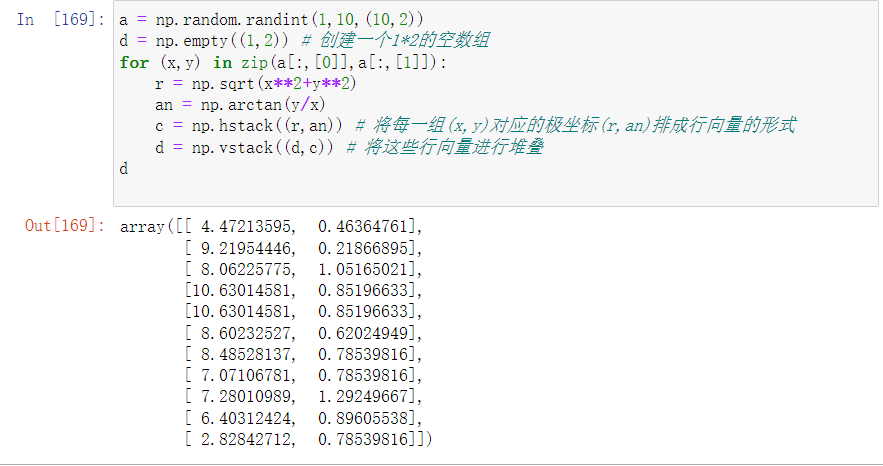
a = np.random.randint(1,10,(10,2))
d = np.empty((1,2)) # 创建一个1*2的空数组
for (x,y) in zip(a[:,[0]],a[:,[1]]):
r = np.sqrt(x**2+y**2)
an = np.arctan(y/x)
c = np.hstack((r,an)) # 将每一组(x,y)对应的极坐标(r,an)排成行向量的形式
d = np.vstack((d,c)) # 将这些行向量进行堆叠
d
(11)创建一个长度为10并且除了第五个值为1其余的值为2的向量。

a = np.ones(10,dtype='int')
a.fill(2)
a[4] = 1
a
(12)创建一个长度为10的随机向量,并求其累计和。
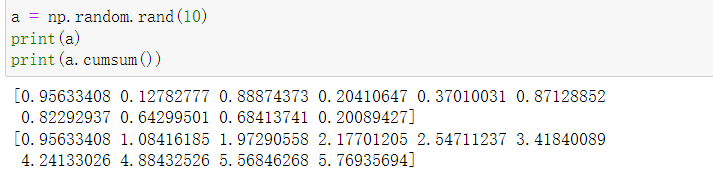
a = np.random.rand(10)
print(a)
print(a.cumsum())
(13)将数组中的所有奇数替换成-1。

a = np.arange(10)
print(a)
index = np.where(a%2==1)
a[index] = -1
print(a)
(14)构造两个4乘3的二维数组,按照3种方法进行连接?
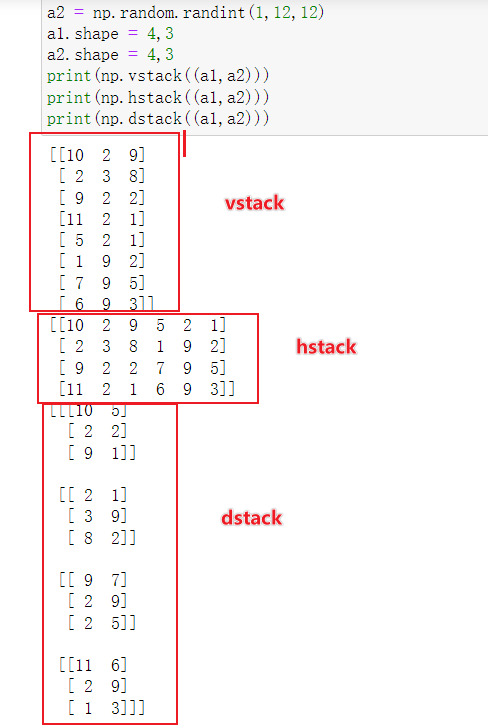
a1 = np.random.random(12)
a2 = np.random.random(12)
a1.shape = 4,3
a2.shape = 4,3
print(a1)
print(a2)
print(np.vstack((a1,a2)))
print(np.hstack((a1,a2)))
print(np.dstack((a1,a2)))
(15)获取数组 a 和 b 中的共同项(索引位置相同,值也相同)。 a = np.array([1,2,3,2,3,4,3,4,5,6]),b = np.array([7,2,10,2,7,4,9,4,9,8])
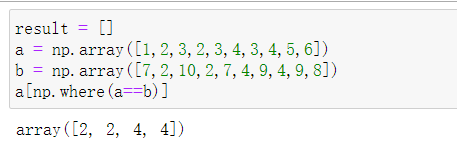
result = []
a = np.array([1,2,3,2,3,4,3,4,5,6])
b = np.array([7,2,10,2,7,4,9,4,9,8])
a[np.where(a==b)]
(16)从数组 a 中提取 5 和 10 之间的所有项。a=np.array([7,2,10,2,7,4,9,4,9,8])
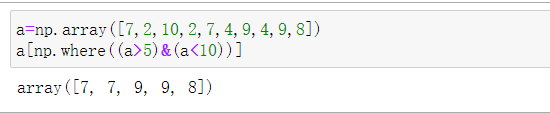
a=np.array([7,2,10,2,7,4,9,4,9,8])
a[np.where((a>5)&(a<10))]
三、pandas
3.1 pandas的基本介绍
Python Data Analysis Library 或 Pandas是基于Numpy的一种工具,该工具是为了解决数据分析任务而创建的。Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
import pandas as pd
import numpy as np
3.2 pandas的基本数据结构
pandas有两种常用的基本结构:
- Series
- 一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很接近。Series能保存不同种数据类型,字符串、boolean值、数字等都能保存在Series中。
- DataFrame
- 二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。以下的内容主要以DataFrame为主。
3.2.1 series类型
一维Series可以用一维列表初始化:
s = pd.Series([1,3,5,np.nan,6,8])#index = ['a','b','c','d','x','y'])设置索引,np.nan设置空值
print(s)
'''
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64
'''
默认情况下,Series的下标都是数字(可以使用额外参数指定),类型是统一的。
索引——数据的行标签
s.index #从0到6(不含),1为步长
# RangeIndex(start=0, stop=6, step=1)
值
s.values
# array([ 1., 3., 5., nan, 6., 8.])
s[3]
#nan
切片操作
s[2:5] #左闭右开
'''
2 5.0
3 NaN
4 6.0
dtype: float64
'''
s[::2]
'''
0 1.0
2 5.0
4 6.0
dtype: float64
'''
索引赋值
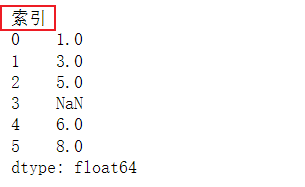
s.index.name = '索引'
s.index = list('abcdef')
'''
a 1.0
b 3.0
c 5.0
d NaN
e 6.0
f 8.0
dtype: float64
'''
s['a':'c':2] #依据自己定义的数据类型进行切片,不是左闭右开了
'''
a 1.0
c 5.0
dtype: float64
'''
3.2.2 DataFrame类型
DataFrame则是个二维结构,这里首先构造一组时间序列,作为我们第一维的下标:
date = pd.date_range("20180101", periods = 6)
print(date)
'''
DatetimeIndex(['2018-01-01', '2018-01-02', '2018-01-03', '2018-01-04','2018-01-05', '2018-01-06'],
dtype='datetime64[ns]', freq='D')
'''
然后创建一个DataFrame结构:
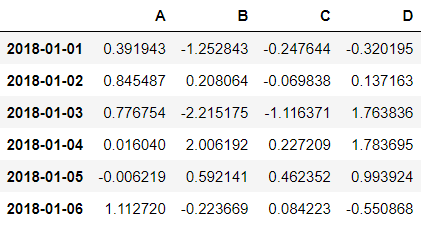
df = pd.DataFrame(np.random.randn(6,4), index = date, columns = list("ABCD")) # 结果如上图
默认情况下,如果不指定index参数和columns,那么它们的值将从用0开始的数字替代。
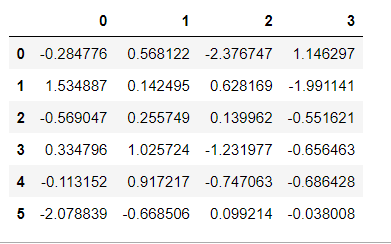
df = pd.DataFrame(np.random.randn(6,4)) # 结果如上图
除了向DataFrame中传入二维数组,我们也可以使用字典传入数据:
df2 = pd.DataFrame({'A':1.,'B':pd.Timestamp("20181001"),'C':pd.Series(1,index = list(range(4)),dtype = float),'D':np.array([3]*4, dtype = int),'E':pd.Categorical(["test","train","test","train"]),'F':"abc"}) #B:时间戳,E分类类型
'''
A B C D E F
0 1.0 2018-10-01 1.0 3 test abc
1 1.0 2018-10-01 1.0 3 train abc
2 1.0 2018-10-01 1.0 3 test abc
3 1.0 2018-10-01 1.0 3 train abc
'''
df2.dtypes #查看各个列的数据类型
'''
A float64
B datetime64[ns]
C float64
D int32
E category
F object
dtype: object
'''
字典的每个key代表一列,其value可以是各种能够转化为Series的对象。
与Series要求所有的类型都一致不同,DataFrame只要求每一列数据的格式相同。
查看数据
头尾数据
head和tail方法可以分别查看最前面几行和最后面几行的数据(默认为5):
df.head()
最后3行:
df.tail(3)
下标,列标,数据
下标使用index属性查看:
df.index
'''
DatetimeIndex(['2018-01-01', '2018-01-02', '2018-01-03', '2018-01-04','2018-01-05', '2018-01-06'],dtype='datetime64[ns]', freq='D')
'''
列标使用columns属性查看:
df.columns
'''
Index(['A', 'B', 'C', 'D'], dtype='object')
'''
数据值使用values查看:
df.values
'''
array([[ 0.39194344, -1.25284255, -0.24764423, -0.32019526],
[ 0.84548738, 0.20806449, -0.06983781, 0.13716277],
[ 0.7767544 , -2.21517465, -1.11637102, 1.76383631],
[ 0.01603994, 2.00619213, 0.22720908, 1.78369472],
[-0.00621932, 0.59214148, 0.46235154, 0.99392424],
[ 1.11272049, -0.22366925, 0.08422338, -0.5508679 ]])
'''
3.2.3 读取数据及其数据操作
我们将以豆瓣的电影数据作为我们深入了解Pandas的一个示例。
df = pd.read_excel(r"C:\Users\19127\Desktop\poststu\pre\python\课程中用到的数据\豆瓣电影数据.xlsx",index_col = 0)
#csv:read_csv;绝对路径或相对路径默认在当前文件夹下。r告诉编译器不需要转义
#具体其它参数可以去查帮助文档 ?pd.read_excel
行操作
df.iloc[0]
'''
名字 肖申克的救赎
投票人数 692795.0
类型 剧情/犯罪
产地 美国
上映时间 1994-09-10 00:00:00
时长 142
年代 1994
评分 9.6
首映地点 多伦多电影节
Name: 0, dtype: object
'''
df.iloc[0:5] #左闭右开
'''
名字 投票人数 类型 产地 上映时间 时长 年代 评分 首映地点
0 肖申克的救赎 692795.0 剧情/犯罪 美国 1994-09-10 00:00:00 142 1994 9.6 多伦多电影节
1 控方证人 42995.0 剧情/悬疑/犯罪 美国 1957-12-17 00:00:00 116 1957 9.5 美国
2 美丽人生 327855.0 剧情/喜剧/爱情 意大利 1997-12-20 00:00:00 116 1997 9.5 意大利
3 阿甘正传 580897.0 剧情/爱情 美国 1994-06-23 00:00:00 142 1994 9.4 洛杉矶首映
4 霸王别姬 478523.0 剧情/爱情/同性 中国大陆 1993-01-01 00:00:00 171 1993 9.4 香港
'''
也可以使用loc
df.loc[0:5] #不是左闭右开
'''
名字 投票人数 类型 产地 上映时间 时长 年代 评分 首映地点
0 肖申克的救赎 692795.0 剧情/犯罪 美国 1994-09-10 00:00:00 142 1994 9.6 多伦多电影节
1 控方证人 42995.0 剧情/悬疑/犯罪 美国 1957-12-17 00:00:00 116 1957 9.5 美国
2 美丽人生 327855.0 剧情/喜剧/爱情 意大利 1997-12-20 00:00:00 116 1997 9.5 意大利
3 阿甘正传 580897.0 剧情/爱情 美国 1994-06-23 00:00:00 142 1994 9.4 洛杉矶首映
4 霸王别姬 478523.0 剧情/爱情/同性 中国大陆 1993-01-01 00:00:00 171 1993 9.4 香港
5 泰坦尼克号 157074.0 剧情/爱情/灾难 美国 2012-04-10 00:00:00 194 2012 9.4 中国大陆
'''
添加一行
dit = {"名字":"复仇者联盟3","投票人数":123456,"类型":"剧情/科幻","产地":"美国","上映时间":"2018-05-04 00:00:00","时长":142,"年代":2018,"评分":np.nan,"首映地点":"美国"}
s = pd.Series(dit)
s.name = 38738
'''
名字 复仇者联盟3
投票人数 123456
类型 剧情/科幻
产地 美国
上映时间 2018-05-04 00:00:00
时长 142
年代 2018
评分 NaN
首映地点 美国
Name: 38738, dtype: object
'''
df = df.append(s) #覆盖掉原来的数据重新进行赋值
df[-5:]
'''
名字 投票人数 类型 产地 上映时间 时长 年代 评分 首映地点
38734 1935年 57.0 喜剧/歌舞 美国 1935-03-15 00:00:00 98 1935 7.6 美国
38735 血溅画屏 95.0 剧情/悬疑/犯罪/武侠/古装 中国大陆 1905-06-08 00:00:00 91 1986 7.1 美国
38736 魔窟中的幻想 51.0 惊悚/恐怖/儿童 中国大陆 1905-06-08 00:00:00 78 1986 8.0 美国
38737 列宁格勒围困之星火战役 Блокада: Фильм 2: Ленинградский ме... 32.0 剧情/战争 苏联 1905-05-30 00:00:00 97 1977 6.6 美国
38738 复仇者联盟3 123456.0 剧情/科幻 美国 2018-05-04 00:00:00 142 2018 NaN 美国
'''
删除一行
df = df.drop([38738])
df[-5:]
列操作
df.columns
# Index(['名字', '投票人数', '类型', '产地', '上映时间', '时长', '年代', '评分', '首映地点'], dtype='object')
df["名字"][:5] #后面中括号表示只想看到的行数,下同
'''
0 肖申克的救赎
1 控方证人
2 美丽人生
3 阿甘正传
4 霸王别姬
Name: 名字, dtype: object
'''
df[["名字","类型"]][:5]
'''
名字 类型
0 肖申克的救赎 剧情/犯罪
1 控方证人 剧情/悬疑/犯罪
2 美丽人生 剧情/喜剧/爱情
3 阿甘正传 剧情/爱情
4 霸王别姬 剧情/爱情/同性
'''
增加一列
df["序号"] = range(1,len(df)+1) #生成序号的基本方式
df[:5]
'''名字 投票人数 类型 产地 上映时间 时长 年代 评分 首映地点 序号
0 肖申克的救赎 692795.0 剧情/犯罪 美国 1994-09-10 00:00:00 142 1994 9.6 多伦多电影节 1
1 控方证人 42995.0 剧情/悬疑/犯罪 美国 1957-12-17 00:00:00 116 1957 9.5 美国 2
2 美丽人生 327855.0 剧情/喜剧/爱情 意大利 1997-12-20 00:00:00 116 1997 9.5 意大利 3
3 阿甘正传 580897.0 剧情/爱情 美国 1994-06-23 00:00:00 142 1994 9.4 洛杉矶首映 4
4 霸王别姬 478523.0 剧情/爱情/同性 中国大陆 1993-01-01 00:00:00 171 1993 9.4 香港 5
名字 投票人数 类型 产地 上映时间 时长 年代 评分 首映地点 序号
0 肖申克的救赎 692795.0 剧情/犯罪 美国 1994-09-10 00:00:00 142 1994 9.6 多伦多电影节 1
1 控方证人 42995.0 剧情/悬疑/犯罪 美国 1957-12-17 00:00:00 116 1957 9.5 美国 2
2 美丽人生 327855.0 剧情/喜剧/爱情 意大利 1997-12-20 00:00:00 116 1997 9.5 意大利 3
3 阿甘正传 580897.0 剧情/爱情 美国 1994-06-23 00:00:00 142 1994 9.4 洛杉矶首映 4
4 霸王别姬 478523.0 剧情/爱情/同性 中国大陆 1993-01-01 00:00:00 171 1993 9.4 香港 5
'''
删除一列
df = df.drop("序号",axis = 1) #axis指定方向,0为行1为列,默认为0
df[:5]
通过标签选择数据
df.loc[[index],[colunm]]通过标签选择数据
df.loc[1,"名字"]
# '控方证人'
df.loc[[1,3,5,7,9],["名字","评分"]] #多行跳行多列跳列选择
'''
名字 评分
1 控方证人 9.5
3 阿甘正传 9.4
5 泰坦尼克号 9.4
7 新世纪福音战士剧场版:Air/真心为你 新世紀エヴァンゲリオン劇場版 Ai 9.4
9 这个杀手不太冷 9.4
'''
条件选择
选取产地为美国的所有电影
df[df["产地"] == "美国"][:5] #内部为bool
'''
名字 投票人数 类型 产地 上映时间 时长 年代 评分 首映地点
0 肖申克的救赎 692795.0 剧情/犯罪 美国 1994-09-10 00:00:00 142 1994 9.6 多伦多电影节
1 控方证人 42995.0 剧情/悬疑/犯罪 美国 1957-12-17 00:00:00 116 1957 9.5 美国
3 阿甘正传 580897.0 剧情/爱情 美国 1994-06-23 00:00:00 142 1994 9.4 洛杉矶首映
5 泰坦尼克号 157074.0 剧情/爱情/灾难 美国 2012-04-10 00:00:00 194 2012 9.4 中国大陆
6 辛德勒的名单 306904.0 剧情/历史/战争 美国 1993-11-30 00:00:00 195 1993 9.4 华盛顿首映
'''
选取产地为美国的所有电影,并且评分大于9分的电影
df[(df.产地 == "美国") & (df.评分 > 9)][:5] #df.标签:更简洁的写法
选取产地为美国或中国大陆的所有电影,并且评分大于9分
df[((df.产地 == "美国") | (df.产地 == "中国大陆")) & (df.评分 > 9)][:5]
缺失值及异常值处理
缺失值处理方法:
| 方法 | 说明 |
|---|---|
| dropna | 根据标签中的缺失值进行过滤,删除缺失值 |
| fillna | 对缺失值进行填充 |
| isnull | 返回一个布尔值对象,判断哪些值是缺失值 |
| notnull | isnull的否定式 |
判断缺失值
df[df["名字"].isnull()][:10] # 判断名字列为空的
df[df["名字"].notnull()][:5] # 判断不为空
填充缺失值
df[df["评分"].isnull()][:10] #注意这里特地将前面加入的复仇者联盟令其评分缺失来举例
df["评分"].fillna(np.mean(df["评分"]), inplace = True) #使用均值来进行替代,inplace意为直接在原始数据中进行修改
df[-5:]
df1 = df.fillna("未知电影") #谨慎使用,除非确定所有的空值都是在一列中,否则所有的空值都会填成这个
#不可采用df["名字"].fillna("未知电影")的形式,因为填写后数据格式就变了,变成Series了
df1[df1["名字"].isnull()][:10]
删除缺失值
| df.dropna() 参数 |
|---|
| how = 'all':删除全为空值的行或列 |
| inplace = True: 覆盖之前的数据 |
| axis = 0: 选择行或列,默认是行 |
df2 = df.dropna()
df.dropna(inplace = True)
处理异常值
异常值,即在数据集中存在不合理的值,又称离群点。比如年龄为-1,笔记本电脑重量为1吨等,都属于异常值的范围。
df[df["投票人数"] < 0] #直接删除,或者找原始数据来修正都行
df[df["投票人数"] % 1 != 0] #小数异常值
df = df[df.投票人数 > 0]
df = df[df["投票人数"] % 1 == 0]
数据保存
数据处理之后,然后将数据重新保存到movie_data.xlsx
df.to_excel("movie_data.xlsx") #默认路径为现在文件夹所在的路径
3.2.4 作业三
import numpy as np
import pandas as pd
(1)Pandas基础知识
(1)用字典数据类型创建DataFrame。 data={'state':['a','b','c','d'], 'year':[1991,1992,1993,1994], 'pop':[6,7,8,9]}
df = pd.DataFrame({'state':['a','b','c','d'],'year':[1991,1992,1993,1994],'pop':[6,7,8,9]})
df
'''
state year pop
0 a 1991 6
1 b 1992 7
2 c 1993 8
3 d 1994 9
'''
(2)将创建的Dataframe的索引设置为,ABCD。并且命名为“索引”。
df.index = list('ABCD')
df.index.name = '索引'
'''
state year pop
索引
A a 1991 6
B b 1992 7
C c 1993 8
D d 1994 9
'''
(3)在下面新增一行。然后删除。
dit = {'state':'e','year':1995,'pop':10}
s = pd.Series(dit)
s.name = 'E' # 一定要写不然加不上
df = df.append(s)
df = df.drop('E')
或者:
s1 = pd.DataFrame(
{
'state':'e',
'year':1995,
'pop':4
},
index = ['E']
)
df = pd.concat([df,s1])
df.drop(index='E')
(4)增加新的属性列,列名设置为‘port’,值均为1。
df['port'] = np.ones(len(df))
'''
state year pop port
索引
A a 1991 6 1.0
B b 1992 7 1.0
C c 1993 8 1.0
D d 1994 9 1.0
'''
(5)取出1991和1994年的数据。
data1 = df[(df['year'] == 1991) | (df.year == 1994)]
'''
state year pop port
索引
A a 1991 6 1.0
D d 1994 9 1.0
'''
或者
df.loc[(df.year == 1991)|(df.year == 1994)]
(6)获取前‘state’和‘year’的数据。
df[['state','year']]
'''
state year
索引
A a 1991
B b 1992
C c 1993
D d 1994
'''
(7)查看每一列数据的数据格式,并且将‘pop’每个数据乘2。
df.dtypes
df['pop'] *= 2
(2)数据操作
(1)读取香港酒店数据。

df = pd.read_excel("香港酒店数据.xlsx")
df[:5]
(2)按照数据的内容,重新设置数据的索引,重新设置列名称为'名字','类型','城市','地区','地点','评分','评分人数','价格'。
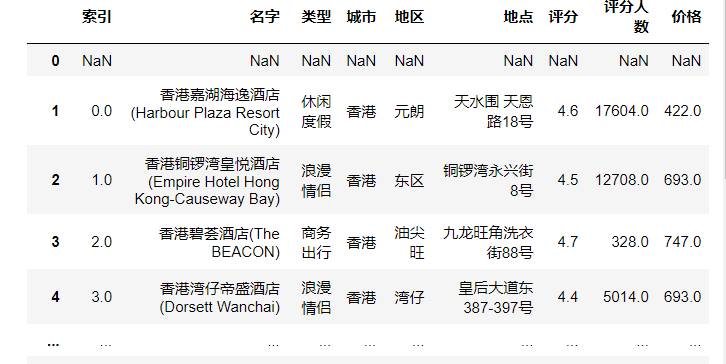
df.columns = ['索引','名字','类型','城市','地区','地点','评分','评分人数','价格']
df
(3)查看所有类型为“浪漫情侣”的酒店
df[df['类型']=='浪漫情侣']
(4)查看所有类型为“浪漫情侣”,地区在湾仔的酒店
df[(df['类型']=='浪漫情侣')&(df.地区 == '湾仔')]
(5)查看所有地址在观塘或者油尖旺,评分大于4的酒店
df[((df.地区 == '观塘')|(df.地区 == '油尖旺'))&(df.评分>4)]
(6)查看类型缺失的数据
df[df['类型'].isnull()]
(7)用“其他”填充类型和地区
df["类型"].fillna('其他', inplace = True)
df["地区"].fillna('其他', inplace = True)
df
或者
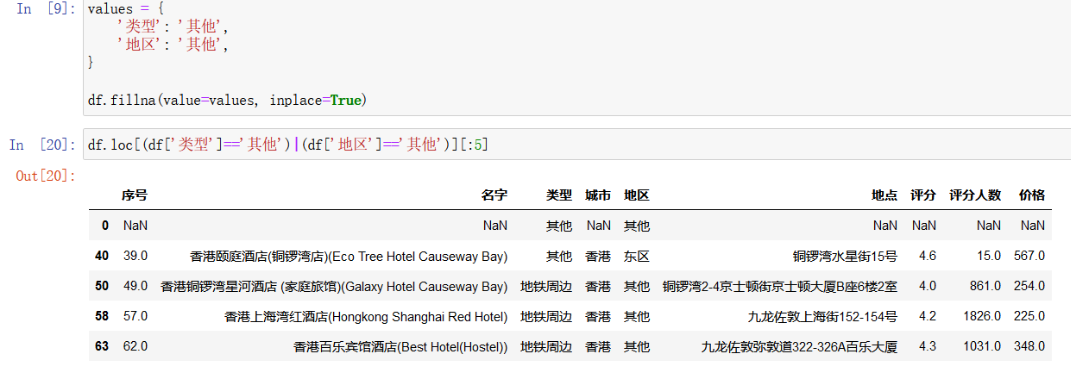
(8)用评分均值填充缺失值
df['评分'].fillna(np.mean(df['评分']),inplace=True)
df
(9)删除价格和评分人数的缺失值
df = df.dropna(subset=['价格','评分人数'])
df
(10)保存到“酒店数据1.xlsx”
df.to_excel("酒店数据1.xlsx")
3.2.5 数据格式转换
在做数据分析的时候,原始数据往往会因为各种各样的原因产生各种数据格式的问题。
数据格式是我们非常需要注意的一点,数据格式错误往往会造成很严重的后果。
并且,很多异常值也是我们经过格式转换后才会发现,对我们规整数据,清洗数据有着重要的作用。
首先:读入我们上节课保存的数据文件movie_data.xlsx
import pandas as pd
import numpy as np
df = pd.read_excel(r"C:\Users\Lovetianyi\Desktop\python\作业3\movie_data.xlsx",index_col = 0)
查看格式
df["投票人数"].dtype
df["投票人数"] = df["投票人数"].astype("int") #转换格式
将年份转化为整数格式
df["年代"] = df["年代"].astype("int") #有异常值会报错
df[df.年代 == "2008\u200e"] #找到异常数据
df[df.年代 == "2008\u200e"]["年代"].values #后面是unicode的控制字符,使得其显示靠左,因此需要处理删除
df.loc[[14934,15205],"年代"] = 2008
df.loc[14934]
df["年代"] = df["年代"].astype("int") # 这次将异常值修改之后就可以进行数据类型的转换了
排序
df.sort_values(by = "投票人数", ascending = False)[:5] #默认从小到大
df.sort_values(by = "年代")[:5]
# 多个值排序,先按照评分,再按照投票人数
df.sort_values(by = ["评分","投票人数"], ascending = False) #列表中的顺序决定先后顺序
基本统计分析
( 1 )描述性统计
dataframe.describe():对dataframe中的数值型数据进行描述性统计
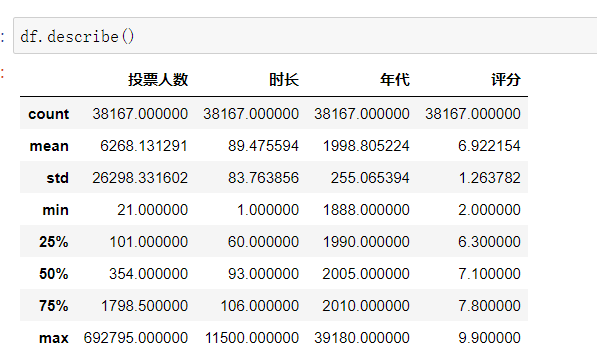
通过描述性统计,可以发现一些异常值,很多异常值往往是需要我们逐步去发现的。
df[df["年代"] > 2018] #异常值
df.drop(df[df["年代"] > 2018].index, inplace = True)
df.drop(df[df["时长"] > 1000].index, inplace = True) #删除异常数据
df.index = range(len(df)) #解决删除后索引不连续的问题
( 2 )最值
df["投票人数"].max()
df["投票人数"].min()
df["评分"].max()
df["评分"].min()
df["年代"].min()
( 3 )均值和中值
df["投票人数"].mean()
df["投票人数"].median()
( 4 )方差和标准差
df["评分"].var()
df["评分"].std()
( 5 )求和
df["投票人数"].sum()
( 6 )相关系数和协方差
df[["投票人数", "评分"]].corr() # 相关系数
df[["投票人数", "评分"]].cov() #协方差
( 7 )计数
df["产地"].unique() #指定唯一值
len(df["产地"].unique())
产地中包含了一些重复的数据,比如美国和USA,德国和西德,俄罗斯和苏联
我们可以通过数据替换的方法将这些相同国家的电影数据合并一下。
单个替换:
df["产地"].replace("USA","美国",inplace = True) #第一个参数是要替换的值,第二个参数是替换后的值
多个替换:
df["产地"].replace(["西德","苏联"],["德国","俄罗斯"], inplace = True) #注意一一对应
len(df["产地"].unique())
计算每一年电影的数量:

df["年代"].value_counts(ascending = True)[:10] #默认从大到小
电影产出前5的国家或地区:
df["产地"].value_counts()[:5]
数据透视
Excel中数据透视表的使用非常广泛,其实Pandas也提供了一个类似的功能,名为pivot_table。
pivot_table非常有用,我们将重点解释pandas中的函数pivot_table。
使用pandas中的pivot_table的一个挑战是,你需要确保你理解你的数据,并清楚地知道你想通过透视表解决什么问题。虽然pivot_table看起来只是一个简单的函数,但是它能够快速地对数据进行强大的分析。
1、基础形式
pd.set_option("max_columns",100) #设置可展示的行和列,让数据进行完整展示
pd.set_option("max_rows",500)
pd.pivot_table(df, index = ["年代"]) #统计各个年代中所有数值型数据的均值(默认)
2、也可以有多个索引。实际上,大多数的pivot_table参数可以通过列表获取多个值。
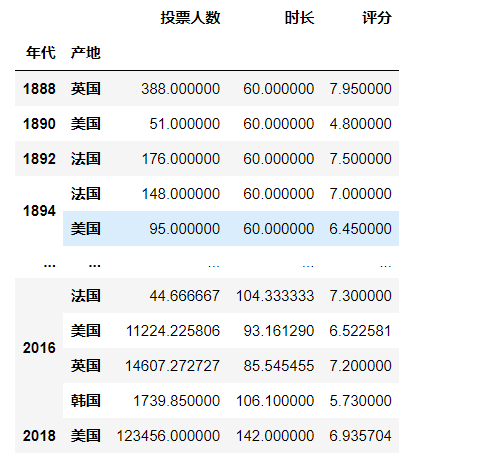
pd.pivot_table(df, index = ["年代", "产地"]) #双索引
3、也可以指定需要统计汇总的数据
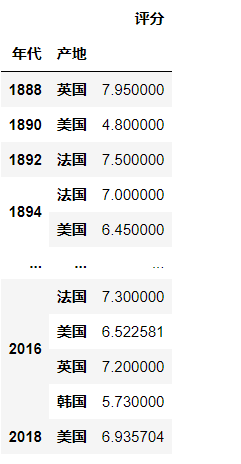
pd.pivot_table(df, index = ["年代", "产地"], values = ["评分"])
4、还可以指定函数,来统计不同的统计值
pd.pivot_table(df, index = ["年代", "产地"], values = ["投票人数"], aggfunc = np.sum)
通过将“投票人数”列和“评分”列进行对应分组,对“产地”实现数据聚合和总结。
pd.pivot_table(df, index = ["产地"], values = ["投票人数", "评分"], aggfunc = [np.sum, np.mean])
5、非数值(NaN)难以处理。如果想移除它们,可以使用“fill_value”将其设置为0。
pd.pivot_table(df, index = ["产地"], aggfunc = [np.sum, np.mean], fill_value = 0)
6、加入margins = True,可以在下方显示一些总和数据。
pd.pivot_table(df, index = ["产地"], aggfunc = [np.sum, np.mean], fill_value = 0, margins = True)
7、对不同值执行不同的函数:可以向aggfunc传递一个字典。不过,这样做有一个副作用,那就是必须将标签做的更加整洁才行。
pd.pivot_table(df, index = ["产地"], values = ["投票人数", "评分"], aggfunc = {"投票人数":np.sum, "评分":np.mean}, fill_value = 0)
对各个地区的投票人数求和,对评分求均值
对各个年份的投票人数求和,对评分求均值
pd.pivot_table(df, index = ["年代"], values = ["投票人数", "评分"], aggfunc = {"投票人数":np.sum, "评分":np.mean}, fill_value = 0, margins = True)
透视表过滤
table = pd.pivot_table(df, index = ["年代"], values = ["投票人数", "评分"], aggfunc = {"投票人数":np.sum, "评分":np.mean}, fill_value = 0)
type(table)
# pandas.core.frame.DataFrame
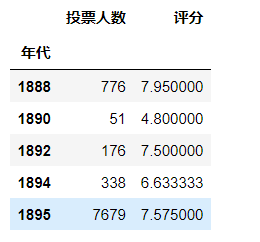
table[:5]
1994年被誉为电影史上最伟大的一年,但是通过数据我们可以发现,1994年的平均得分其实并不是很高。1924年的电影均分最高。
table[table.index == 1994]
table.sort_values("评分", ascending = False)
同样的,我们也可以按照多个索引来进行汇总。
pd.pivot_table(df, index = ["产地", "年代"], values = ["投票人数", "评分"], aggfunc = {"投票人数":np.sum, "评分":np.mean}, fill_value = 0)
3.2.6 作业四
import pandas as pd
import numpy as np
(1)读取上次作业保存的数据,酒店数据1.xlsx
df = pd.read_excel("酒店数据1.xlsx")
(2)查看“评分”的格式,并分别进行升序和降序排序

df['评分'].dtypes
df.sort_values(by="评分",ascending=True) # 升序
df.sort_values(by="评分",ascending=False) # 降序
(3)对酒店按照价格进行排名,计算“油尖旺”地区的均价。

# 对酒店按照价格进行排名
df.sort_values(by='价格',ascending=False)
# 计算油尖旺地区均价
df[df['地区']=="油尖旺"].价格.mean()
pd.pivot_table(df,index=['名字','地区'],values='价格',aggfunc = np.mean)
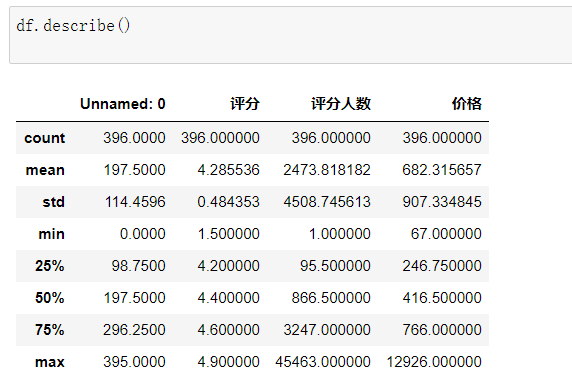
(4)对酒店数据进行描述性统计,并求所有价格的均值方差,最大最小值,中值。

(5)计算评分和价格之间的的相关系数,协方差


(6)按照评分降序排序,评分相同时按价格升序排序。

df.sort_values(by=['评分','价格'],ascending=[False,True])
(7)计算一下,评分小于3分的酒店数量和占比。
len(df[df['评分']<3])
pc = len(df[df['评分']<3])/ len(df)
#0.030303030303030304
(8)计算一下,酒店评分大于等于4分的酒店的价格均值。
df[df['评分']>=4]['价格'].mean()
(9)计算出每个地区的酒店占总酒店数量的比例。

(10)找出酒店评分人数排名前20的酒店,并计算他们的价格均值。
df.sort_values(by='评分',ascending = False)[:20]['价格'].mean()
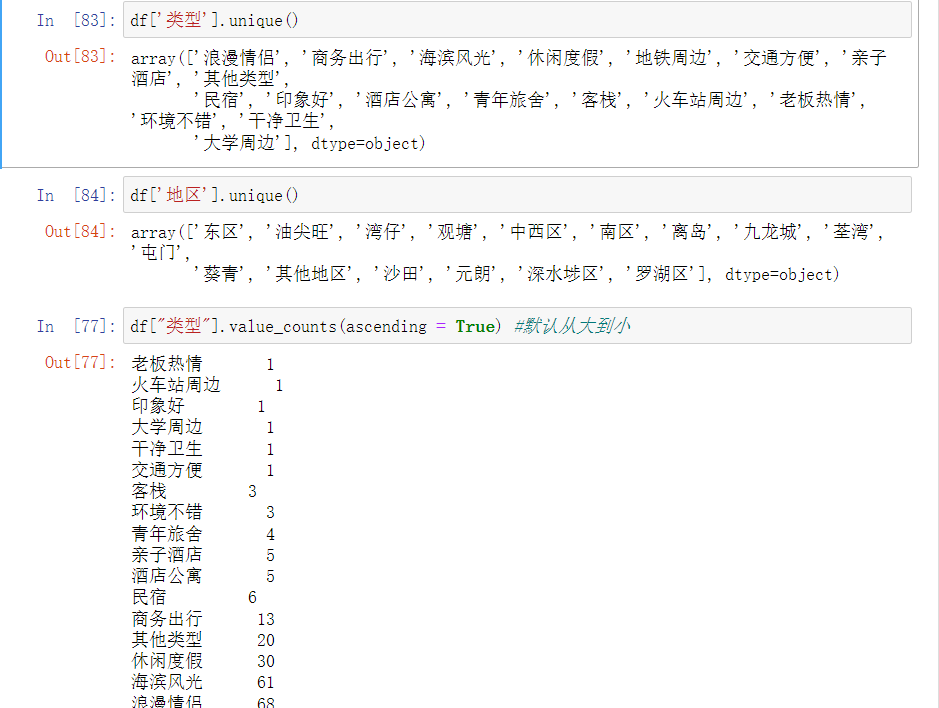
(11)查看酒店分布的类型数量和地区数量,并统计各个类型和地区包含的酒店数量。
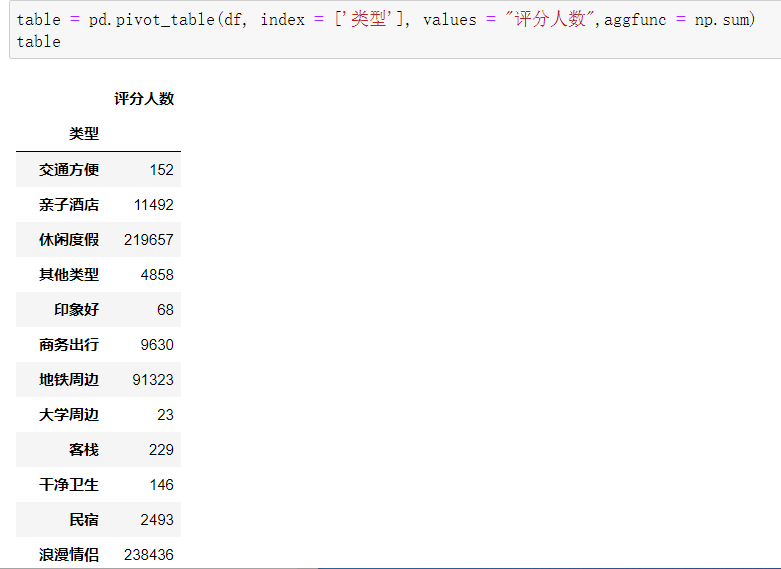
(12)用数据透视表,计算每个类型的酒店的评分人数总数量。
(13)用数据透视表,计算每个类型的酒店价格的均值和标准差
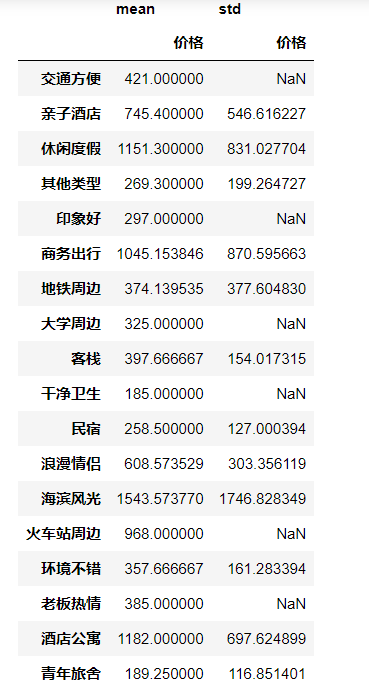
table = pd.pivot_table(df, index = ['类型'], values = "价格",aggfunc = [np.mean,np.std])
table
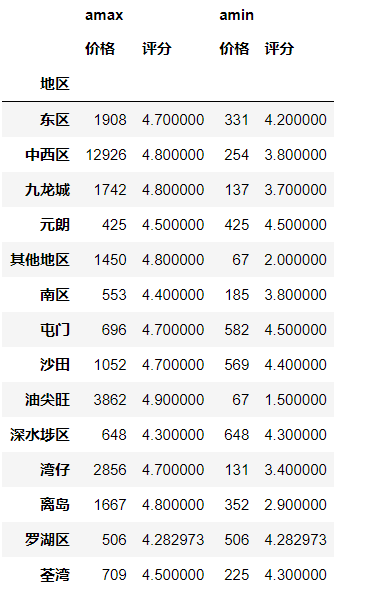
(14)用数据透视表,计算每个地区酒店价格和评分的最大值和最小值
table = pd.pivot_table(df, index = ['地区'], values = ["价格",'评分'],aggfunc = [np.max,np.min])
table
(15)用数据透视表,计算每个地区和类型的酒店的评分的均值和标准差
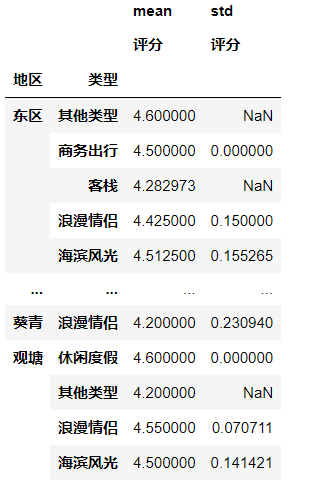
table = pd.pivot_table(df, index = ['地区','类型'], values = ['评分'],aggfunc = [np.mean,np.std])
table
3.2.6 数据重塑和轴向旋转
(1)层次化索引
层次化索引是pandas的一项重要功能,它能使我们在一个轴上拥有多个索引。
Series的层次化索引:
s = pd.Series(np.arange(1,10), index = [['a','a','a','b','b','c','c','d','d'], [1,2,3,1,2,3,1,2,3]])
s #类似于合并单元格

s.index

s['a'] #外层索引
'''
1 1
2 2
3 3
dtype: int32
'''
s['a':'c'] #切片
'''
a 1 1
2 2
3 3
b 1 4
2 5
c 3 6
1 7
dtype: int32
'''
s[:,1] #内层索引
'''
a 1
b 4
c 7
dtype: int32
'''
s['c',3] #提取具体的值
# 6
通过unstack方法可以将Series变成一个DataFrame

pandas 中读取和写入csv文件时候出现Unnamed:0的解决方案

s.unstack()
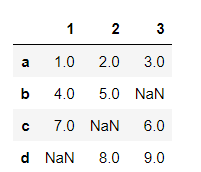
s.unstack().stack() #形式上的相互转换
'''
a 1 1.0
2 2.0
3 3.0
b 1 4.0
2 5.0
c 1 7.0
3 6.0
d 2 8.0
3 9.0
dtype: float64
'''
Dataframe的层次化索引:
对于DataFrame来说,行和列都能进行层次化索引。
data = pd.DataFrame(np.arange(12).reshape(4,3), index = [['a','a','b','b'],[1,2,1,2]], columns = [['A','A','B'],['Z','X','C']])
data
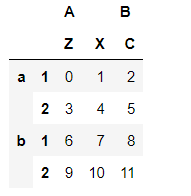
data['A']
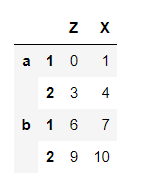
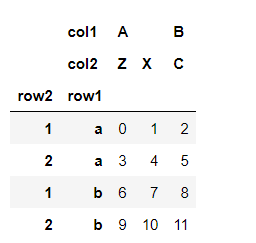
data.index.names = ["row1","row2"]
data.columns.names = ["col1", "col2"]
data

data.swaplevel("row1","row2") #位置调整
了解了层次化索引的基本知识之后,我们试着将电影数据也处理成一种多层索引的结构。
df.index #默认索引
'''
Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8,
9,
...
38153, 38154, 38155, 38156, 38157, 38158, 38159, 38160, 38161,
38162],
dtype='int64', length=38163)
'''
把产地和年代同时设成索引,产地是外层索引,年代为内层索引。
set_index可以把列变成索引
reset_index是把索引变成列
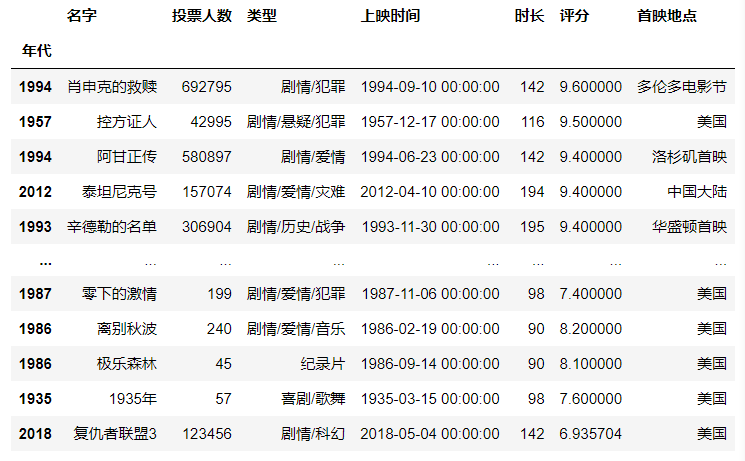
df = df.set_index(["产地", "年代"])
df

每一个索引都是一个元组
df.index[0]
获取所有的美国电影,由于产地信息已经变成了索引,因此要是用.loc方法。
df.loc["美国"] #行标签索引行数据,注意索引多行时两边都是闭区间
df.loc["中国大陆"]
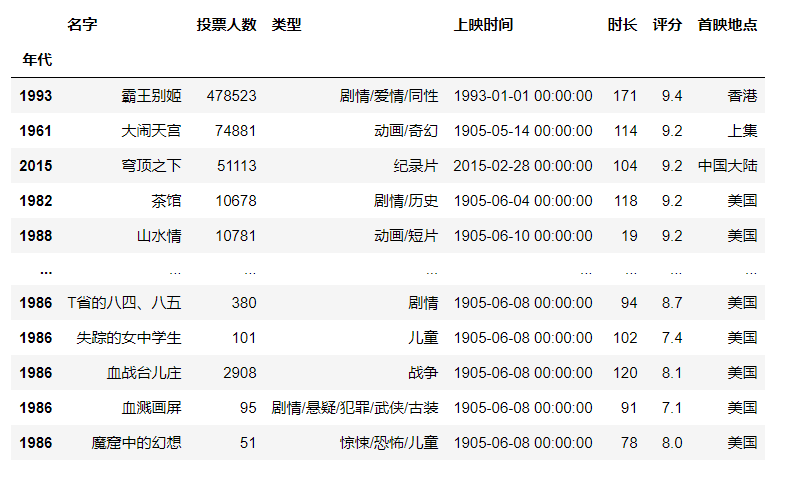
这样做的最大好处是我们可以简化很多的筛选环节
每一个索引是一个元组
df = df.swaplevel("产地", "年代") #调换标签顺序
df
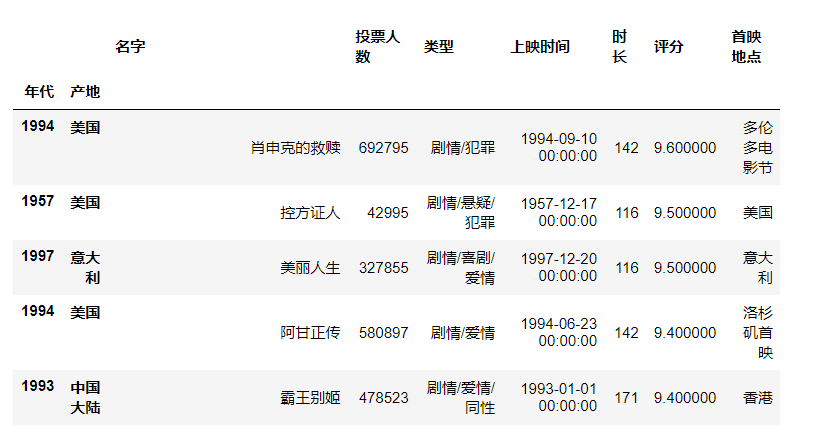
df.loc[1994]
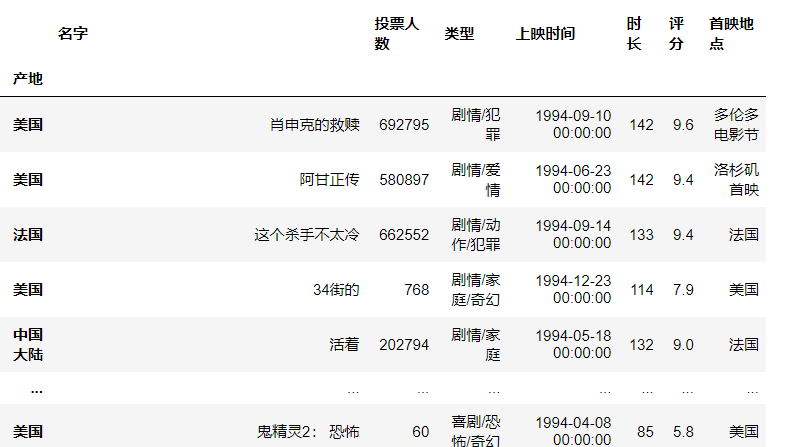
取消层次化索引
df = df.reset_index()
df[:5]
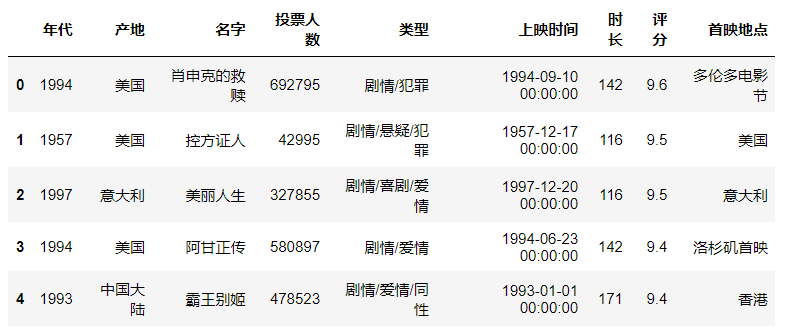
(2)数据旋转
行列转化:以前5部电影为例
data = df[:5]
data
.T可以直接让数据的行列进行交换
data.T

dataframe也可以使用stack和unstack,转化为层次化索引的Series
data.stack()

data.stack().unstack() #转回来
3.2.7数据分组,分组运算
GroupBy技术:实现数据的分组,和分组运算,作用类似于数据透视表
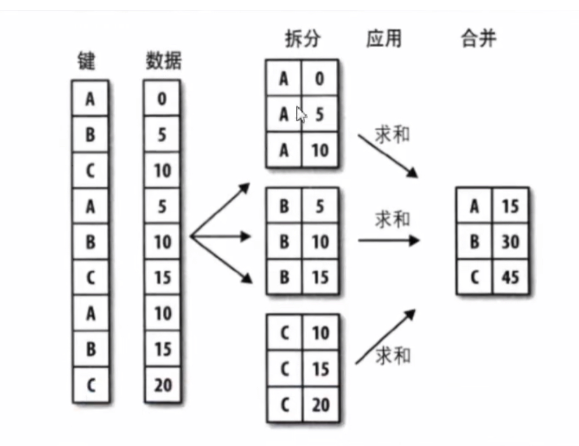
按照电影的产地进行分组
group = df.groupby(df["产地"])
先定义一个分组变量group
type(group)
'''
pandas.core.groupby.generic.DataFrameGroupBy
'''
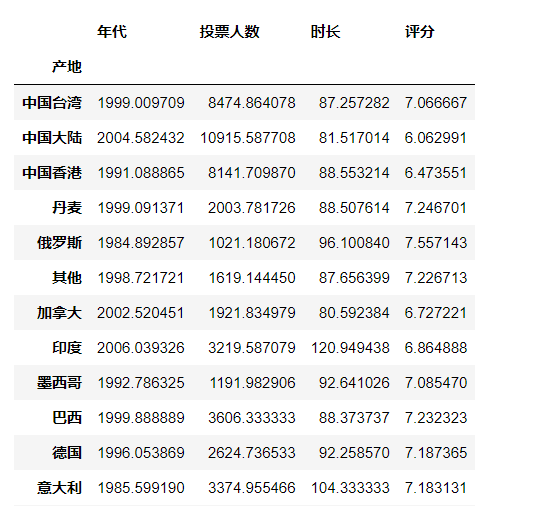
可以计算分组后各个的统计量
group.mean()
group.sum()
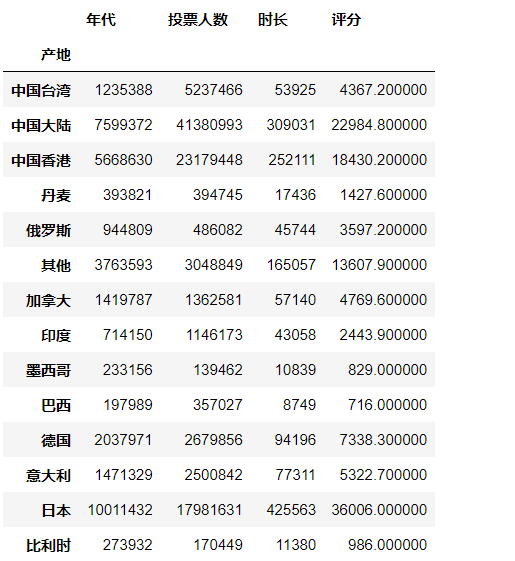
计算每年的平均评分
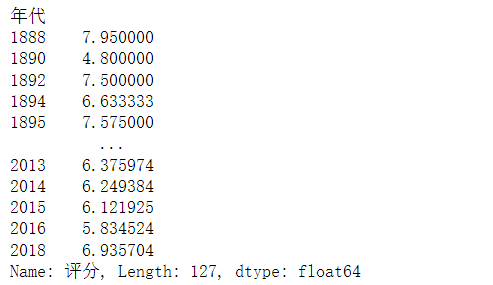
df["评分"].groupby(df["年代"]).mean()
只会对数值变量进行分组运算
df["年代"] = df["年代"].astype("str")
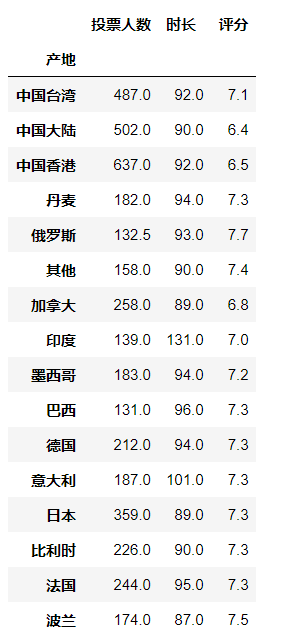
df.groupby(df["产地"]).median() #不会再对年代进行求取
我们也可以传入多个分组变量
df.groupby([df["产地"],df["年代"]]).mean() #根据两个变量进行分组
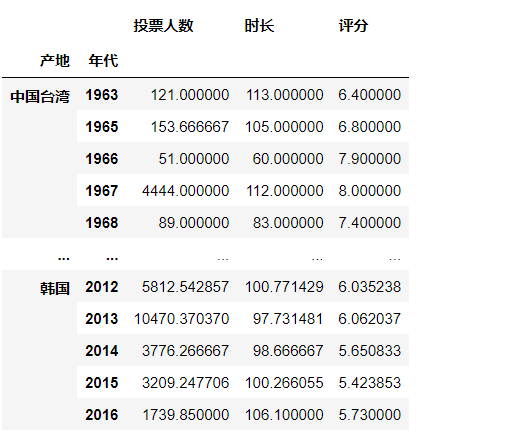
获得每个地区,每一年的电影的评分的均值
group = df["评分"].groupby([df["产地"], df["年代"]])
means = group.mean()
means
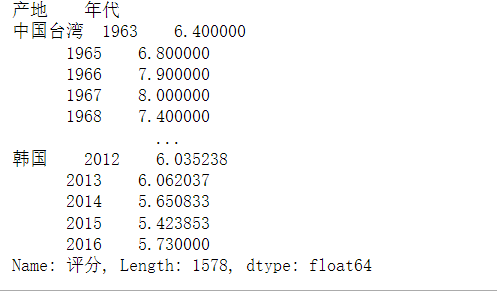
means = group = df["评分"].groupby([df["产地"], df["年代"]]).mean()
means
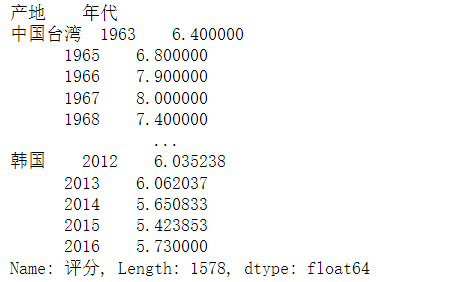
Series通过unstack方法转化为dataframe
会产生缺失值
means.unstack().T
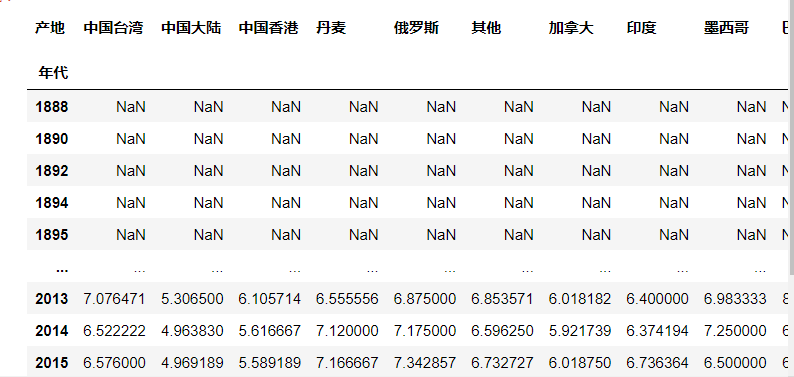
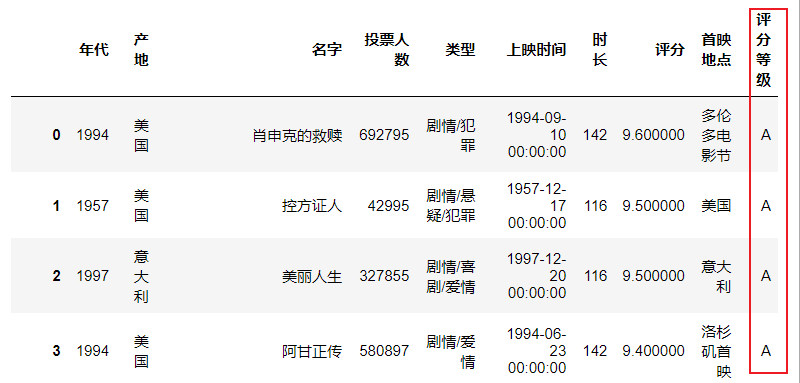
3.2.8 分散化处理
在实际的数据分析项目中,对有的数据属性,我们往往并不关注数据的绝对取值,只关心它所处的区间或者等级
比如,我们可以把评分9分及以上的电影定义为A,7到9分定义为B,5到7分定义为C,3到5分定义为D,小于3分定义为E。
离散化也可称为分组、区间化。
Pandas为我们提供了方便的函数cut():
pd.cut(x,bins,right = True,labels = None, retbins = False,precision = 3,include_lowest = False) 参数解释:
x:需要离散化的数组、Series、DataFrame对象
bins:分组的依据,right = True,include_lowest = False,默认左开右闭,可以自己调整。
labels:是否要用标记来替换返回出来的数组,retbins:返回x当中每一个值对应的bins的列表,precision精度。
df["评分等级"] = pd.cut(df["评分"], [0,3,5,7,9,10], labels = ['E','D','C','B','A']) #labels要和区间划分一一对应
df
同样的,我们可以根据投票人数来刻画电影的热门
投票越多的热门程度越高
bins = np.percentile(df["投票人数"], [0,20,40,60,80,100]) #获取分位数
df["热门程度"] = pd.cut(df["投票人数"],bins,labels = ['E','D','C','B','A'])
df[:5]
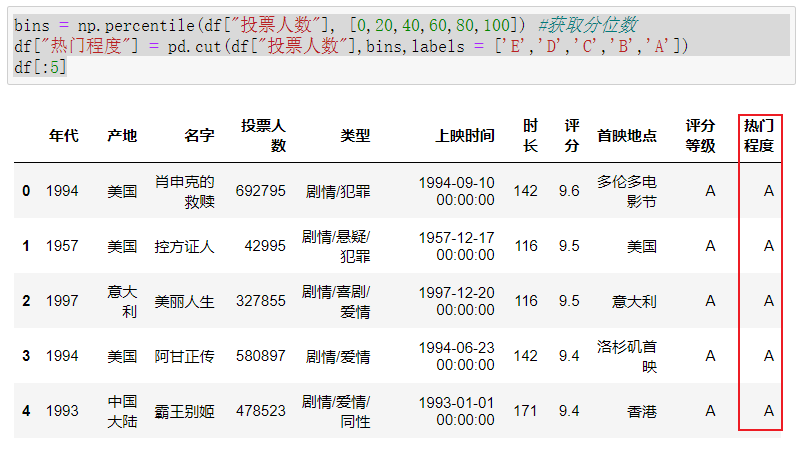
大烂片集合:投票人数很多,评分很低
遗憾的是,我们可以发现,烂片几乎都是中国大陆的
df[(df.热门程度 == 'A') & (df.评分等级 == 'E')]
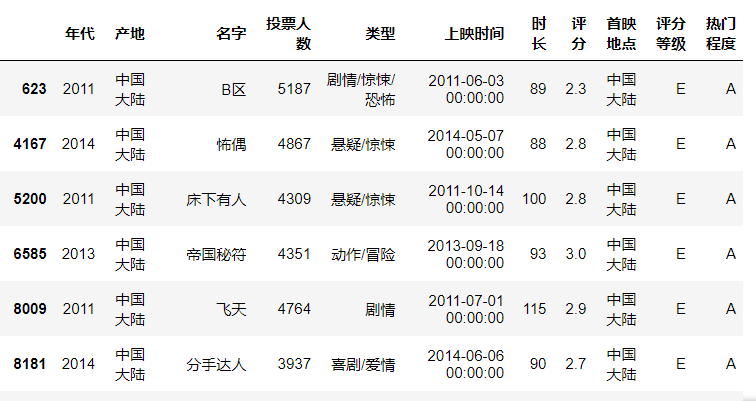
冷门高分电影
df[(df.热门程度 == 'E') & (df.评分等级 == 'A')]

3.2.9 合并数据集
( 1 )append
先把数据集拆分为多个,再进行合并
df_usa = df[df.产地 == "美国"]
df_china = df[df.产地 == "中国大陆"]
df_china.append(df_usa) #直接追加到后面,最好是变量相同的
将这两个数据集进行合并
( 2 )merge
我们选取6部热门电影
df1 = df.loc[:5]
df1
df2 = df.loc[:5][["名字","产地"]]
df2["票房"] = [123344,23454,55556,333,6666,444]
df2 = df2.sample(frac = 1) #打乱数据
df2.index = range(len(df2))
df2
现在,我们需要把df1和df2合并
我们发现,df2有票房数据,df1有评分等其他信息
由于样本的顺序不一致,因此不能直接采取直接复制的方法
pd.merge(df1, df2, how = "inner", on = "名字")
由于两个数据集都存在产地,因此合并后会有两个产地信息
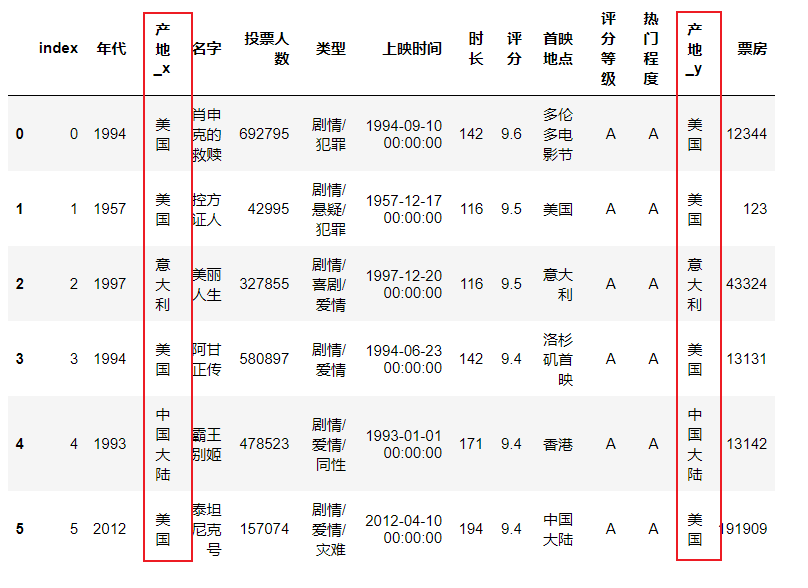
( 3 )concat
将多个数据集进行批量合并
df1 = df[:10]
df2 = df[100:110]
df3 = df[200:210]
dff = pd.concat([df1,df2,df3],axis = 0) #默认axis = 0,列拼接需要修改为1
dff
3.2.10 作业五
import pandas as pd
import numpy as np
(1)读取数据。读取之前作业保存的“酒店数据1.xlsx”
df = pd.read_excel(r"C:\Users\19127\Desktop\poststu\pre\python\作业4\酒店数据1.xlsx",index_col=0)
df
(2)将“类型”和“名字”设置为层次化索引,并交换索引的位置。然后将层次化索引取消。
df = df.set_index(['类型','名字'])
df = df.swaplevel('类型',"名字")
df
df = df.reset_index()
df
(3)将数据集转置,获取转制后的index和columns。
df.T

df.T.index
# Index(['名字', '类型', '城市', '地区', '地点', '评分', '评分人数', '价格'], dtype='object')
df.T.columns
# RangeIndex(start=0, stop=396, step=1)
(4)用Groupby方法来计算每个地区的评分人数的总和以及均值。
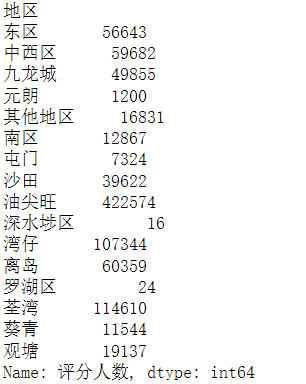
df['评分人数'].groupby(df['地区']).mean()
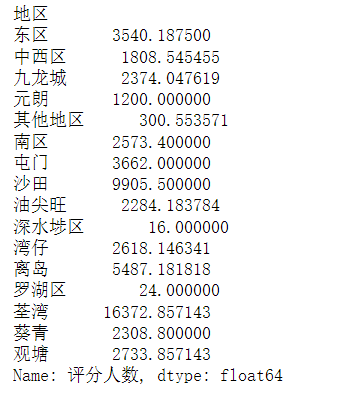
df['评分人数'].groupby(df['地区']).sum()
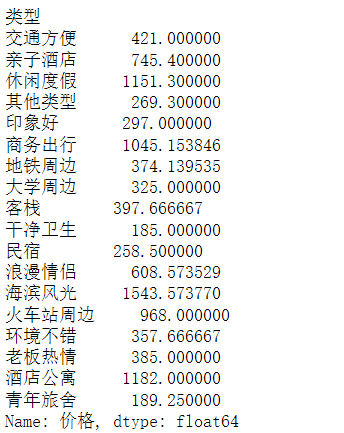
(5)用Grouby方法计算每个类型的平均价格,最高价和最低价。
df['价格'].groupby(df['类型']).max()
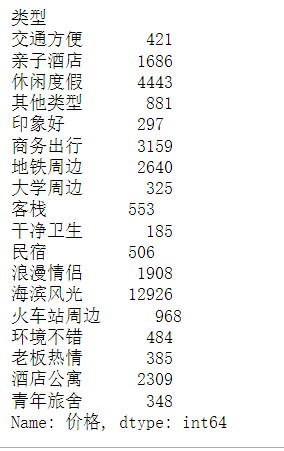
df['价格'].groupby(df['类型']).min()

df['价格'].groupby(df['类型']).mean()
(6)数据离散化,按照价格将酒店分为3个等级,0-500为C,500-1000为B,大于1000为A,列名设置为“价格等级”。
df["价格等级"] = pd.cut(df['价格'],[0,500,1000,df['价格'].max()],labels = ['C','B','A'])
df
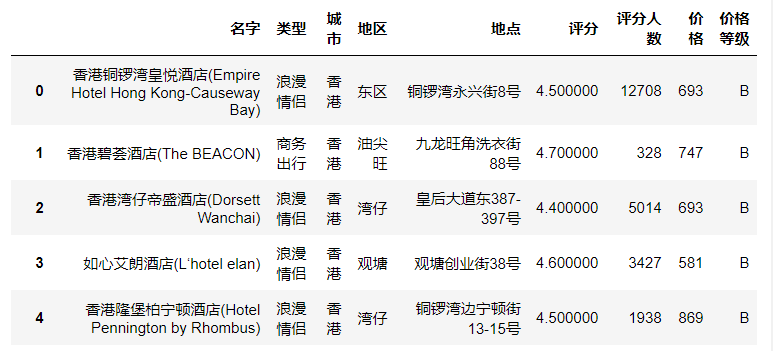
(7)获取评分均值最高和最低的地区的数据,分别使用append和concat方法将获取的两个数据集合并。
mean =df['评分'].groupby(df['地区']).mean()
mean # Series
# print(type(mean))

max_mean = mean.max()
print(mean[mean == max_mean])# 屯门
min_mean = mean.min()
print(mean[mean == min_mean])# 葵青
df_max = df[df.地区 == '屯门']
df_min = df[df.地区 == '葵青']

new_df = pd.concat([df_max,df_min],axis = 0)
print(new_df['地区'])

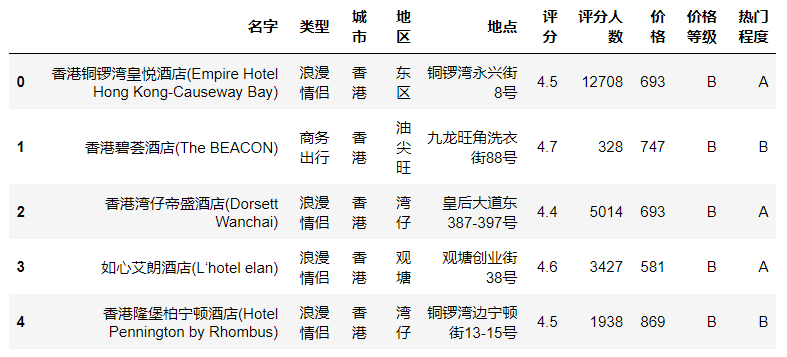
(8)数据离散化,按照评分人数将酒店平均分为3个等级,三个等级的酒店数量尽量保持一致。评分人数最多的为A,最少的为C。列名设置为“热门等级”。
bins = np.percentile(df["评分人数"],[0,100/3,100/3*2,100])
df['热门程度'] = pd.cut(df['评分人数'],bins,labels=['C','B','A'])
df[:5]
(9)选出评分人数为A,价格也为A的酒店数据,计算其平均评分。
df[(df.热门程度 == 'A')&(df.价格等级 == 'A')]['评分'].mean()
(10)取价格最高的5个酒店的数据,使用stack和unstack方法实现dataframe和Series之间的转换。
top5 = df.sort_values(by="价格",ascending=False)[:5]
type(top5) # DataFrame
type(top5.stack())# series
type(top5.stack().unstack()) # DataFrame
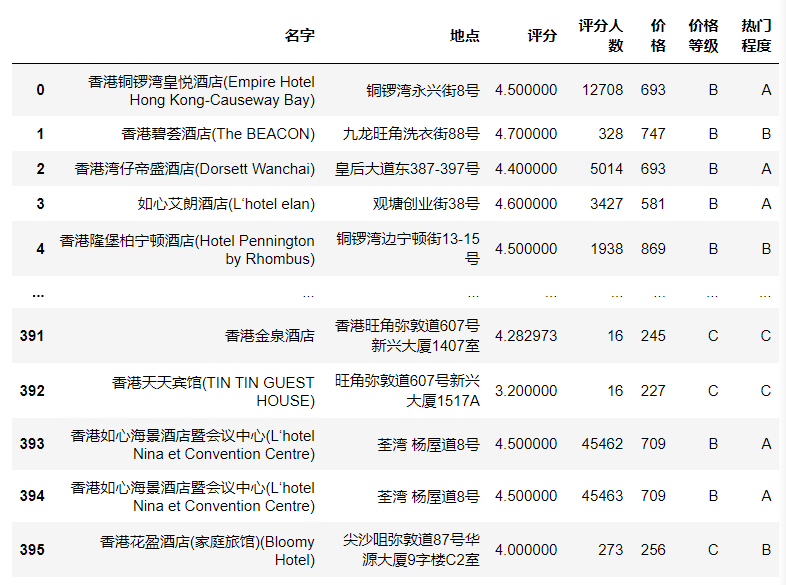
(11)纵向拆分数据集,分为df1和df2,df1包含名字,类型,城市,地区,df2包含名字,地点,评分,评分人数,价格,价格等级,热门等级。
df1 = df.loc[:][['名字','类型','城市','地区']]
df1

df2 = df.loc[:][['名字','地点','评分','评分人数','价格','价格等级','热门程度']]
df2
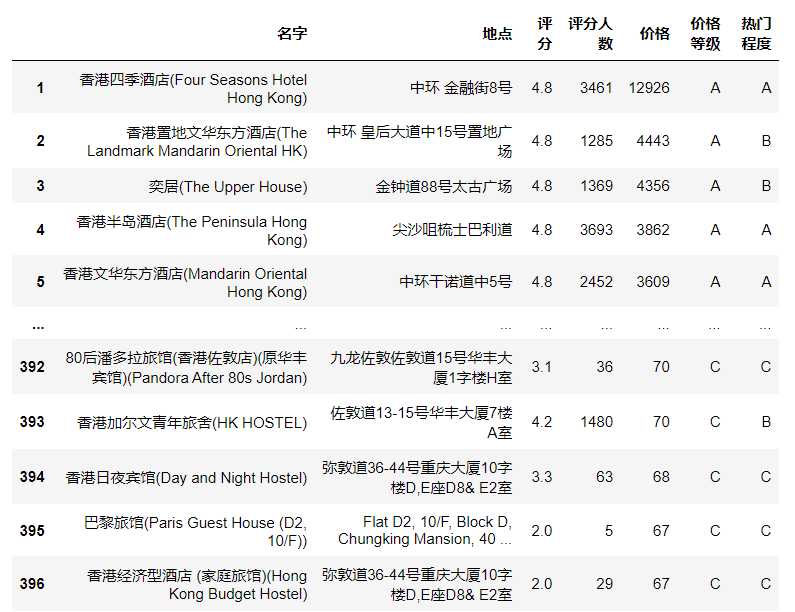
(12)将df2按照价格进行排序,重新设置df2的索引。索引值等于价格排名。
df2 = df2.sort_values(by='价格',ascending=False)
df2.index = range(1,len(df2)+1)
df2
(13)使用merge方法将df1和df2合并。
df_merge = pd.merge(df1,df2,how="inner",on = '名字')
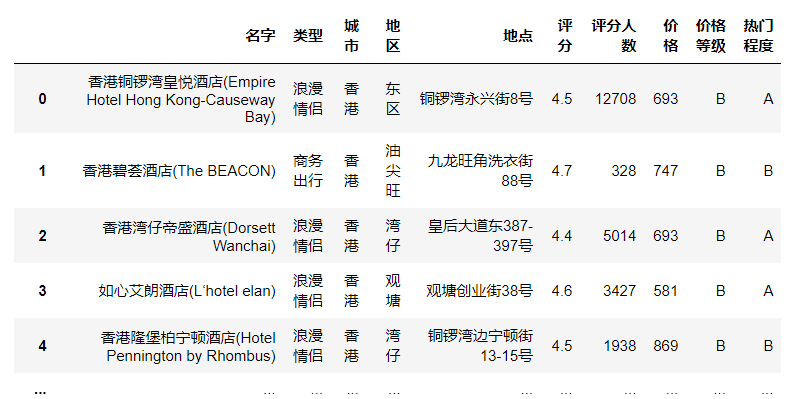
(14)将合并后的数据集保存数据到“酒店数据2.xlsx”。
df_merge.to_excel("酒店数据2.xlsx")
四、matplotlib
4.1 Matplotlib基础
matplotlib是一个Python的 2D 图形包。pyplot封装了很多画图的函数
导入相关的包:
import matplotlib.pyplot as plt
import numpy as np
matplotlib.pyplot包含一系列类似MATLAB中绘图函数的相关函数。每个matplotlib.pyplot中的函数对当前的图像进行一些修改,例如:产生新的图像,在图像中产生新的绘图区域,在绘图区域中画线,给绘图加上标记,等等......matplotlib.pyplot会自动记住当前的图像和绘图区域,因此这些函数会直接作用在当前的图像上。
在实际的使用过程中,常常以plt作为matplotlib.pyplot的省略。
plt.show()函数
默认情况下,matplotlib.pyplot不会直接显示图像,只有调用plt.show()函数时,图像才会显示出来。
plt.show()默认是在新窗口打开一幅图像,并且提供了对图像进行操作的按钮。
不过在ipython命令中,我们可以将它插入notebook中,并且不需要调用plt.show()也可以显示:
%matplotlib notebook%matplotlib inline
不过在实际写程序中,我们还是习惯调用plt.show()函数将图像显示出来。
plt.plot()函数
例子
plt.plot()函数可以用来绘线型图:
plt.plot([1,2,3,4]) #默认以列表的索引作为x,输入的是y
plt.ylabel('y')
plt.xlabel("x轴") #设定标签,使用中文的话后面需要再设定
基本用法
plot函数基本的用法:
指定x和y
plt.plot(x,y)
默认参数,x为0~N-1
plt.plot(y)
因此,在上面的例子中,我们没有给定x的值,所以其默认值为[0,1,2,3]
传入x和y:
plt.plot([1,2,3,4],[1,4,9,16])
plt.show() #相当于打印的功能,下面不会再出现内存地址

字符参数
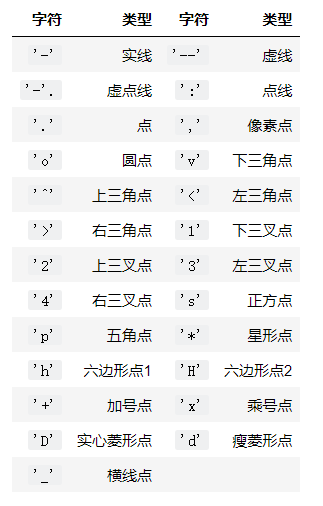
和MATLAB中类似,我们还可以用字符来指定绘图的格式:
表示颜色的字符参数有:

表示类型的字符参数有:
例如我们要画出红色圆点:
plt.plot([1,2,3,4],[1,4,9,16],"ro") #也可以是or,没顺序要求
plt.show()
可以看出,有两个点在图像的边缘,因此,我们需要改变轴的显示范围。
显示范围
与MATLAB类似,这里可以使用axis函数指定坐标轴显示的范围:
plt.axis([xmin, xmax, ymin, ymax])
plt.plot([1,2,3,4],[1,4,9,16],"g*")
plt.axis([0,6,0,20])
plt.show()
传入Numpy数组
之前我们传给plot的参数都是列表,事实上,向plot中传入numpy数组是更常用的做法。事实上,如果传入的是列表,matplotlib会在内部将它转化成数组再进行处理:
在一个图里面画多条线
t = np.arange(0.,5.,0.2) #左闭右开从0到5间隔0.2
plt.plot(t,t,"r--",
t,t**2,"bs",
t,t**3,"g^")
plt.show()
传入多组数据
事实上,在上面的例子中,我们不仅仅向plot函数传入了数组,还传入了多组(x,y,format_str)参数,它们在同一张图上显示。
这意味着我们不需要使用多个plot函数来画多组数组,只需要可以将这些组合放到一个plot函数中去即可。
线条属性
之前提到,我们可以用字符串来控制线条的属性,事实上还可以用关键词来改变线条的性质,例如linewidth可以改变线条的宽度,color可以改变线条的颜色:
x = np.linspace(-np.pi,np.pi)
y = np.sin(x)
plt.plot(x,y,linewidth = 4.0,color = 'r') #细节调整的两个方式
plt.show()
使用plt.plot()的返回值来设置线条属性
plot函数返回一个Line2D对象组成的列表,每个对象代表输入的一对组合,例如:
-
line1,line2 为两个 Line2D 对象
line1, line2 = plt.plot(x1, y1, x2, y2) -
返回3个 Line2D 对象组成的列表
lines = plt.plot(x1, y1, x2, y2, x3, y3)
我们可以使用这个返回值来对线条属性进行设置:
line = plt.plot(x,y,"r-",x,y+1,"g-")
line[1].set_antialiased(False) #列表
plt.show()
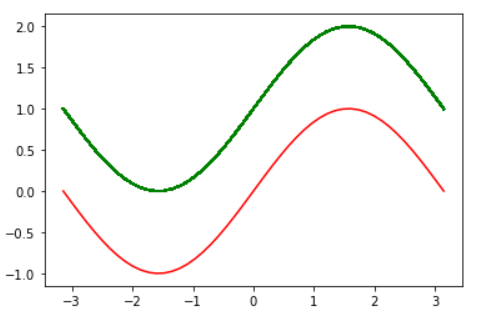
plt.setp() 修改线条性质
更方便的做法是使用plt的setp函数:
line = plt.plot(x,y)
#plt.setp(line, color = 'g',linewidth = 4)
plt.setp(line,"color",'r',"linewidth",4) #matlab风格
子图
figure()函数会产生一个指定编号为num的图:
plt.figure(num)
这里,figure(1)其实是可以省略的,因为默认情况下plt会自动产生一幅图像。
使用subplot可以在一幅图中生成多个子图,其参数为:
plt.subplot(numrows, numcols, fignum)
当numrows * numncols < 10时,中间的逗号可以省略,因此plt.subplot(211)就相当于plt.subplot(2,1,1)。
def f(t):
return np.exp(-t)*np.cos(2*np.pi*t)
t1 = np.arange(0.0,5.0,0.1)
t2 = np.arange(0.0,4.0,0.02)
plt.figure(figsize = (10,6))
plt.subplot(211)
plt.plot(t1,f(t1),"bo",t2,f(t2),'k') #子图1上有两条线
plt.subplot(212)
plt.plot(t2,np.cos(2*np.pi*t2),"r--")
plt.show()

4.2 电影数据绘图
在了解绘图的基础知识之后,我们可以对电影数据进行可视化分析。
import warnings
warnings.filterwarnings("ignore") #关闭一些可能出现但对数据分析并无影响的警告
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["SimHei"] #解决中文字符乱码的问题
plt.rcParams["axes.unicode_minus"] = False #正常显示负号
df = pd.read_excel(r"movie_data3.xlsx", index_col = 0)
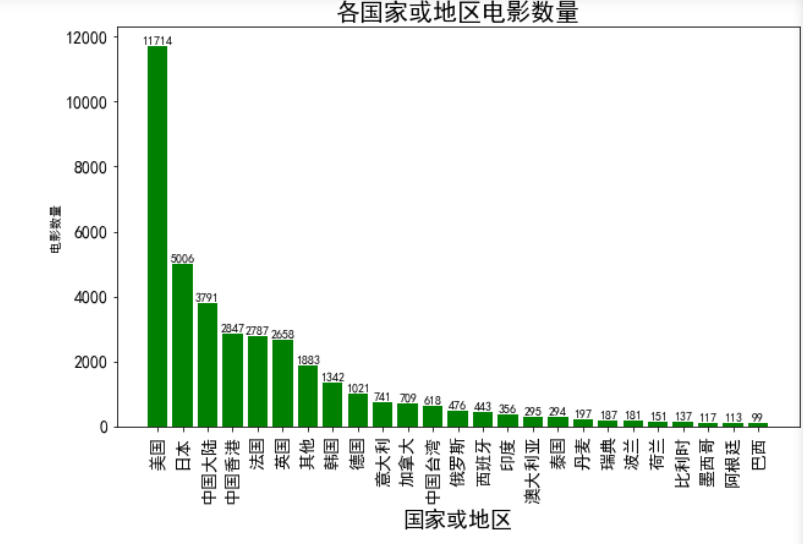
(1) 绘制每个国家或地区的电影数量的柱状图
柱状图(bar chart),是一种以长方形的长度为变量的表达图形的统计报告图,由一系列高度不等的纵向条纹表示数据分布的情况,用来比较两个或以上的价值(不同时间或者不同条件),只有一个变量,通常利用较小的数据集分析。柱状图亦可横向排列,或用多维方式表达。
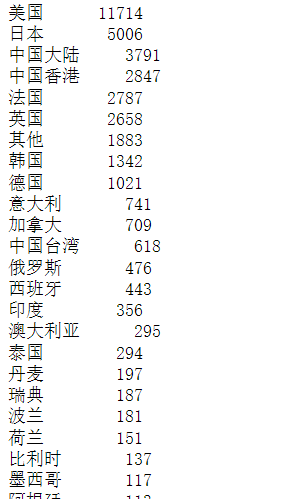
data = df["产地"].value_counts()
data
x = data.index
y = data.values
plt.figure(figsize = (10,6)) #设置图片大小
plt.bar(x,y,color = "g") #绘制柱状图,表格给的数据是怎样就怎样,不会自动排序
plt.title("各国家或地区电影数量", fontsize = 20) #设置标题
plt.xlabel("国家或地区",fontsize = 18)
plt.ylabel("电影数量") #对横纵轴进行说明
plt.tick_params(labelsize = 14) #设置标签字体大小
plt.xticks(rotation = 90) #标签转90度
for a,b in zip(x,y): #数字直接显示在柱子上(添加文本)
#a:x的位置,b:y的位置,加上10是为了展示位置高一点点不重合,
#第二个b:显示的文本的内容,ha,va:格式设定,center居中,top&bottom在上或者在下,fontsize:字体指定
plt.text(a,b+10,b,ha = "center",va = "bottom",fontsize = 10)
#plt.grid() #画网格线,有失美观因而注释点
plt.show()
(2) 绘制每年上映的电影数量的曲线图
曲线图又称折线图,是利用曲线的升,降变化来表示被研究现象发展趋势的一种图形。它在分析研究社会经济现象的发展变化、依存关系等方面具有重要作用。
绘制曲线图时,如果是某一现象的时间指标,应将时间绘在坐标的横轴上,指标绘在坐标的纵轴上。如果是两个现象依存关系的显示,可以将表示原因的指标绘在横轴上,表示结果的指标绘在纵轴上,同时还应注意整个图形的长宽比例。
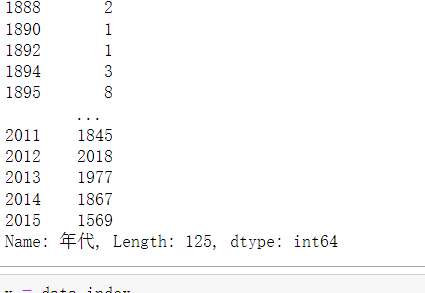
data = df["年代"].value_counts()
data = data.sort_index()[:-2] #排除掉2016年以后的数据,共两条
data
x = data.index
y = data.values
plt.plot(x,y,color = 'b')
plt.title("每年电影数量",fontsize = 20)
plt.ylabel("电影数量",fontsize = 18)
plt.xlabel("年份",fontsize = 18)
for (a,b) in zip(x[::10],y[::10]): #每隔10年进行数量标记,防止过于密集
plt.text(a,b+10,b,ha = "center", va = "bottom", fontsize = 10)
#标记特殊点如极值点,xy设置箭头尖的坐标,xytext注释内容起始位置,arrowprops对箭头设置,传字典,facecolor填充颜色,edgecolor边框颜色
plt.annotate("2012年达到最大值", xy = (2012,data[2012]), xytext = (2025,2100), arrowprops = dict(facecolor = "black",edgecolor = "red"))
#纯文本注释内容,例如注释增长最快的地方
plt.text(1980,1000,"电影数量开始快速增长")
plt.show()
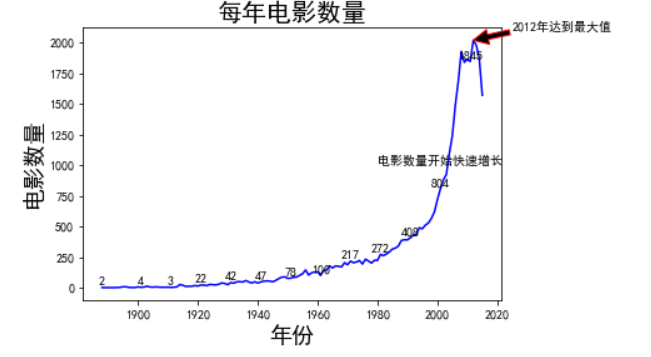
对于这幅图形,我们使用xlabel, ylabel, title, text方法设置了文字,其中:
xlabel: x轴标注ylabel: y轴标注title: 图形标题text: 在指定位置放入文字
输入特殊符号支持使用Tex语法,用$<some Text code>$隔开。
除了使用text在指定位置标上文字之外,还可以使用annotate进行注释,annotate主要有两个参数:
xy: 注释位置xytext: 注释文字位置
(3) 根据电影的长度绘制饼图
饼图英文学名为Sector Graph,又名Pie Graph。常用于统计学模块。2D饼图为圆形,手画时,常用圆规作图。
仅排列在工作表的一列或一行中的数据可以绘制到饼图中。饼图显示一个数据系列(数据系列:在图表中绘制的相关数据点,这些数据源自数据表的行或列。图表中的每个数据系列具有唯一的颜色或团并且在图表中的图例中表示。可以在图表中绘制一个或多个数据系列。饼图只有一个数据系列。)中各项的大小与各项总和的比例。饼图中的数据点(数据点:在图表中绘制的单个值,这些值由条形,柱形,折线,饼图或圆环图的扇面、圆点和其他被称为数据标记的图形表示。相同颜色的数据标记组成一个数据系列。)显示为整个饼图的百分比。
函数原型:
pie(x, explode = None, labels = None, colors = None, autopct = None, pctdistance = 0.6,
shadow = False, labeldistance = 1.1, startangle = None, radius = None)
参数:
- x: (每一块)的比例,如果sum(x)>1会使用sum(x)归一化
- labels: (每一块)饼图外侧显示的说明文字
- explode: (每一块)离开中心距离
- startangle: 起始绘制角度,默认图是从x轴正方向逆时针画起,如设定=90则从y轴正方向画起
- shadow: 是否阴影
- labeldistance: label绘制位置,相对于半径的比例,如<1则绘制在饼图内侧
- autopct: 控制饼图内百分比设置,可以使用format字符串或者format function
- '%1.1f': 指小数点前后位数(没有用空格补齐)
- pctdistance: 类似于labeldistance,指定autopct的位置刻度
- radius: 控制饼图半径
返回值:
如果没有设置autopct,返回(patches,texts)
如果设置autopct,返回(patches,texts,autotexts)
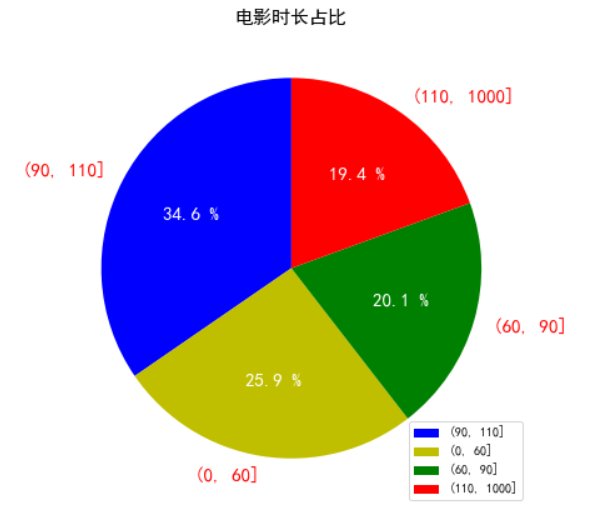
data = pd.cut(df["时长"], [0,60,90,110,1000]).value_counts() #数据离散化
data

y = data.values
y = y/sum(y) #归一化,不进行的话系统会自动进行
plt.figure(figsize = (7,7))
plt.title("电影时长占比",fontsize = 15)
patches,l_text,p_text = plt.pie(y, labels = data.index, autopct = "%.1f %%", colors = "bygr", startangle = 90)
for i in p_text: #通过返回值设置饼图内部字体
i.set_size(15)
i.set_color('w')
for i in l_text: #通过返回值设置饼图外部字体
i.set_size(15)
i.set_color('r')
plt.legend() #图例
plt.show()
(4) 根据电影的评分绘制频率直方图
直方图(Histogram)又称质量分布图。是一种统计报告图。由一系列高度不等的纵向条纹或线段表示数据分布的情况。一般用横轴表示数据类型,纵轴表示分布情况。
直方图是数值数据分布的精确图形表示。这是一个连续变量(定量变量)的概率分布的估计,并且被卡尔·皮尔逊(Karl Pearson)首先引入。它是一种条形图。为了构建直方图,第一步是将值的范围分段,即将整个值的范围分成一系列间隔,然后计算每个间隔中有多少值。这些值通常被指定为连续的,不重叠的变量间隔。间隔必须相邻,并且通常是(但不是必须的)相等的大小。
直方图也可以被归一化以显示“相对频率”。然后,它显示了属于几个类别中每个案例的比例,其高度等于1。
plt.figure(figsize = (10,6))
plt.hist(df["评分"], bins = 20, edgecolor = 'k',alpha = 0.5)
plt.show()
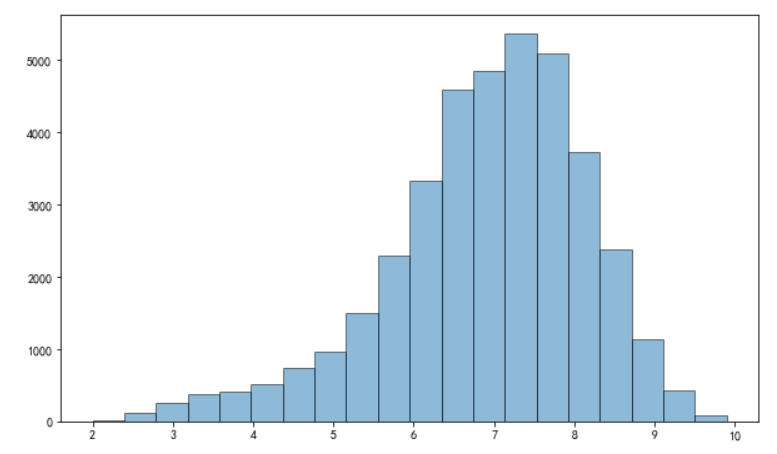
hist的参数非常多,但常用的就这六个,只有第一个是必须的,后面可选
- arr: 需要计算直方图的一维数组
- bins: 直方图的柱数,可选项,默认为10
- normed: 是否将得到的直方图向量归一化。默认为0
- facecolor: 直方图颜色
- edgecolor: 直方图边框颜色
- alpha: 透明度
- histtype: 直方图类型,"bar", "barstacked", "step", "stepfilled"
- 返回值:
- n: 直方图向量,是否归一化由参数normed设定
- bins: 返回各个bin的区间范围
- patches: 返回每一个bin里面包含的数据,是一个list
4.3 第六课作业
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
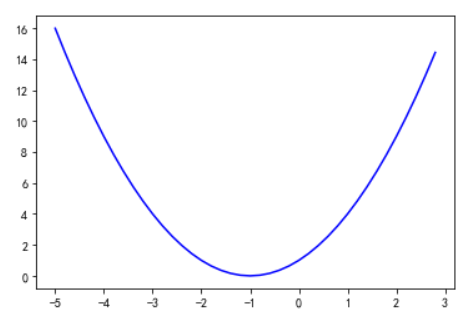
(1)画出𝑦=𝑥2+2𝑥+1𝑦=𝑥2+2𝑥+1在区间[-5,3]的函数图像。
t = np.arange(-5.,3.,0.2)
plt.plot(t,t**2+2*t+1,'b-')
(2)在同一张图中创建两个子图,分别画出sinx和cosx在[-3.14,3.14]上的函数图像。设置线条宽度为2.5.
t = np.arange(-3.14,3.14,0.1)
plt.subplot(211)
plt.plot(t,np.sin(t),"bo",linewidth=2.5)
plt.subplot(212)
plt.plot(t,np.cos(t),"r-",linewidth=2.5)
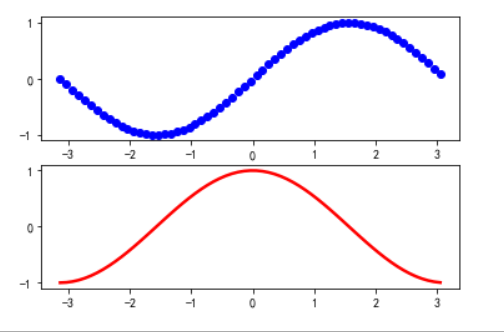
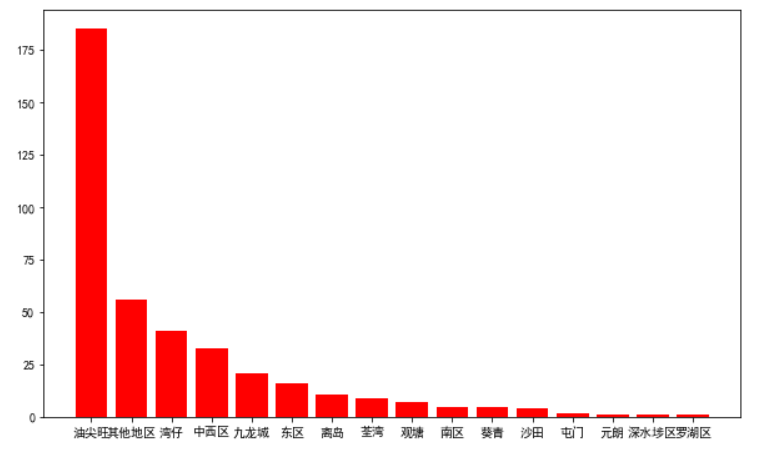
(3)读取上次作业保存的酒店数据,画出每个地区酒店数量的柱状图,柱状颜色为红色
import warnings
warnings.filterwarnings("ignore") #关闭一些可能出现但对数据分析并无影响的警告
plt.rcParams["font.sans-serif"] = ["SimHei"] #解决中文字符乱码的问题
plt.rcParams["axes.unicode_minus"] = False #正常显示负号
df = pd.read_excel("../作业5/酒店数据2.xlsx",index_col=0)
df[:5]
data = df['地区'].value_counts()
x = data.index
y = data.values
plt.figure(figsize=(10,6))
plt.bar(x,y,color = 'r')
(4)画出每个价格等级酒店数量的柱状图。
data = df['价格等级'].value_counts()
x = data.index
y = data.values
plt.figure(figsize=(6,6))
plt.title("每个价格等级酒店数量",fontsize=20)
plt.xlabel("等级",fontsize=18)
plt.ylabel("酒店数量",fontsize=15)
plt.tick_params(labelsize=14)
for a,b in zip(x,y):
plt.text(a,b+5,b,ha='center',va='bottom',fontsize=10)
plt.bar(x,y)

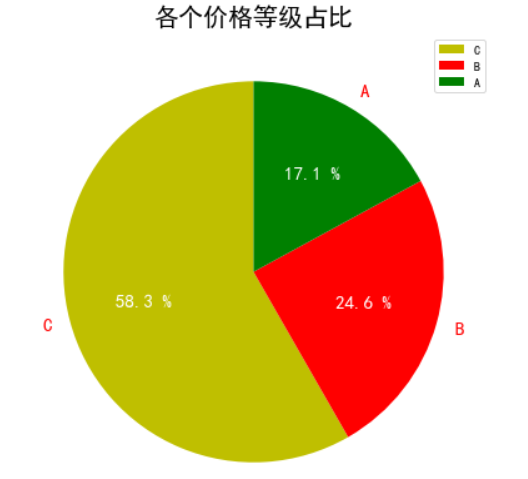
(5)画出各个价格等级占比的饼图。
data = df['价格等级'].value_counts()
y = data.values
plt.figure(figsize=(7,7))
plt.title("各个价格等级占比",fontsize=20)
patches,l_text,p_text = plt.pie(y, labels = data.index, autopct = "%.1f %%", colors = "yrg", startangle = 90)
for i in p_text: #通过返回值设置饼图内部字体
i.set_size(15)
i.set_color('w')
for i in l_text: #通过返回值设置饼图外部字体
i.set_size(15)
i.set_color('r')
plt.legend()
plt.show()
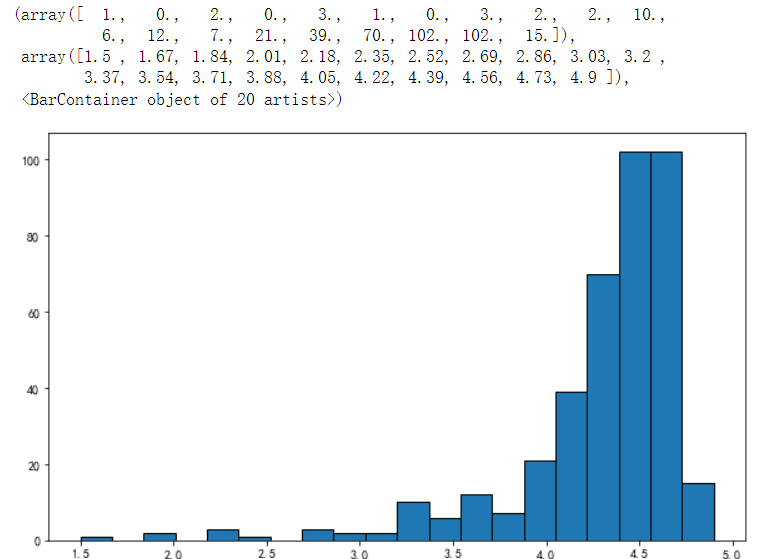
(6)画出酒店评分的直方图。
plt.figure(figsize=(10,6))
plt.hist(df['评分'],bins=20,edgecolor='k')
(7)画出每个热门等级酒店评分均值的柱状图。(按照评分均值从小到大排序。)
data = df['评分'].groupby(df['热门程度']).mean()
x = data.index
y = data.values
plt.figure(figsize=(9,9))
plt.title("每个热门等级酒店评分均值")
plt.tick_params(labelsize=13)
for a,b in zip(x,y):
plt.text(a,b+0.1,b,ha="center",va='bottom',fontsize=13)
plt.bar(x,y)
plt.show()
4.4 python数据展示
导入
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False #解决中文乱码等问题
df = pd.read_excel('movie_data3.xlsx')
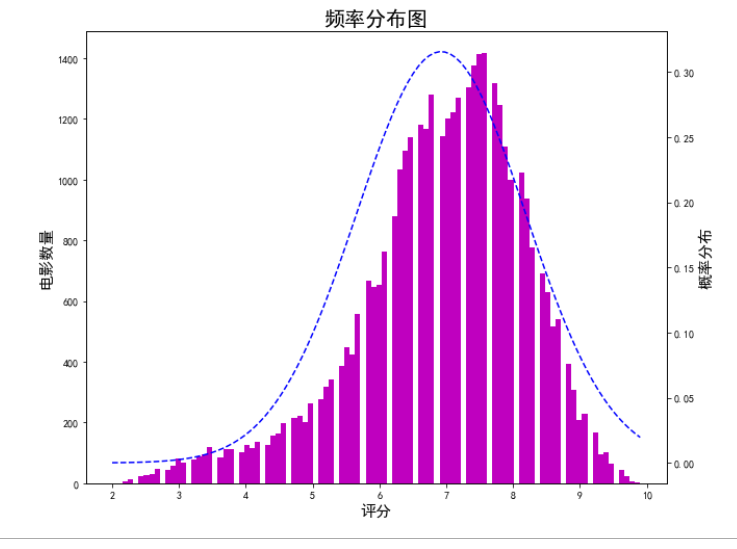
双轴图的画法
from scipy.stats import norm #获取正态分布密度函数
fig = plt.figure(figsize = (10,8))
ax1 = fig.add_subplot(111) #确认子图
n,bins,patches = ax1.hist(df["评分"],bins = 100, color = 'm') #bins默认是10
ax1.set_ylabel("电影数量",fontsize = 15)
ax1.set_xlabel("评分",fontsize = 15)
ax1.set_title("频率分布图",fontsize = 20)
#准备拟合
y = norm.pdf(bins,df["评分"].mean(),df["评分"].std()) #bins,mu,sigma
ax2 = ax1.twinx() #双轴
ax2.plot(bins,y,"b--")
ax2.set_ylabel("概率分布",fontsize = 15)
plt.show()
根据电影时长和电影评分绘制散点图
用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式。散点图将序列显示为一组点。值由点在图表中的位置表示。类别由图表中的不同标记表示。散点图通常用于比较跨类别的聚合数据。
x = df["时长"][::100]
y = df["评分"][::100] #解决数据冗杂的问题
plt.figure(figsize = (10,6))
plt.scatter(x,y,color = 'c',marker = 'p',label = "评分")
plt.legend() #图例
plt.title("电影时长与评分散点图",fontsize = 20)
plt.xlabel("时长",fontsize = 18)
plt.ylabel("评分",fontsize = 18)
plt.show()
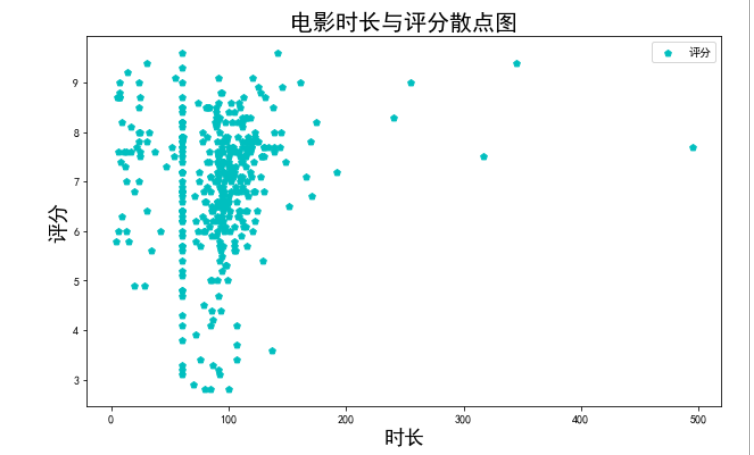
由于我们的数据量过大,所以画出来的图非常冗杂
可以发现,大部分的电影时长还是集中在100附近,评分大多在7分左右
marker属性
设置散点的形状
| marker | description | 描述 |
|---|---|---|
| "." | point | 点 |
| "," | pixel | 像素 |
| "o" | circle | 圈 |
| "v" | triangle_down | 倒三角形 |
| "^" | triangle_up | 正三角形 |
| "<" | triangle_left | 左三角形 |
| ">" | triangle_right | 右三角形 |
| "1" | tri_down | tri_down |
| "2" | tri_up | tri_up |
| "3" | tri_left | tri_left |
| "4" | tri_right | tri_right |
| "8" | octagon | 八角形 |
| "s" | square | 正方形 |
| "p" | pentagon | 五角 |
| "*" | star | 星星 |
| "h" | hexagon1 | 六角1 |
| "H" | hexagon2 | 六角2 |
| "+" | plus | 加号 |
| "x" | x | x号 |
| "D" | diamond | 钻石 |
| "d" | thin_diamon | 细钻 |
| "|" | vline | v线 |
| "_" | hline | H线 |
绘制各个地区的评分箱型图
箱型图(Box-plot)又称为盒须图,盒式图或箱型图,是一种用作显示一组数据分散情况资料的统计图。因形状如箱子而得名。在各种领域中也经常被使用,常见于品质管理。它主要用于反映原始数据分布的特征,还可以进行多组数据分布特征的比较。箱线图的绘制方法是:先找出一组数据的中位数,两个四分位数,上下边缘线;然后,连接两个四分位数画出箱子;再将上下边缘线与箱子相连接,中位数在箱子中间。

一般计算过程
( 1 )计算上四分位数( Q3 ),中位数,下四分位数( Q1 )
( 2 )计算上四分位数和下四分位数之间的差值,即四分位数差(IQR, interquartile range)Q3-Q1
( 3 )绘制箱线图的上下范围,上限为上四分位数,下限为下四分位数。在箱子内部中位数的位置绘制横线
( 4 )大于上四分位数1.5倍四分位数差的值,或者小于下四分位数1.5倍四分位数差的值,划为异常值(outliers)
( 5 )异常值之外,最靠近上边缘和下边缘的两个值处,画横线,作为箱线图的触须
( 6 )极端异常值,即超出四分位数差3倍距离的异常值,用实心点表示;较为温和的异常值,即处于1.5倍-3倍四分位数差之间的异常值,用空心点表示
( 7 )为箱线图添加名称,数轴等
参数详解
plt.boxplot(x,notch=None,sym=None,vert=None,
whis=None,positions=None,widths=None,
patch_artist=None,meanline=None,showmeans=None,
showcaps=None,showbox=None,showfliers=None,
boxprops=None,labels=None,flierprops=None,
medianprops=None,meanprops=None,
capprops=None,whiskerprops=None,)
- x: 指定要绘制箱线图的数据;
- notch: 是否是凹口的形式展现箱线图,默认非凹口;
- sym: 指定异常点的形状,默认为+号显示;
- vert: 是否需要将箱线图垂直摆放,默认垂直摆放;
- whis: 指定上下须与上下四分位的距离,默认为为1.5倍的四分位差;
- positions: 指定箱线图的位置,默认为[0,1,2...];
- widths: 指定箱线图的宽度,默认为0.5;
- patch_artist: 是否填充箱体的颜色;
- meanline:是否用线的形式表示均值,默认用点来表示;
- showmeans: 是否显示均值,默认不显示;
- showcaps: 是否显示箱线图顶端和末端的两条线,默认显示;
- showbox: 是否显示箱线图的箱体,默认显示;
- showfliers: 是否显示异常值,默认显示;
- boxprops: 设置箱体的属性,如边框色,填充色等;
- labels: 为箱线图添加标签,类似于图例的作用;
- filerprops: 设置异常值的属性,如异常点的形状、大小、填充色等;
- medainprops: 设置中位数的属性,如线的类型、粗细等
- meanprops: 设置均值的属性,如点的大小,颜色等;
- capprops: 设置箱线图顶端和末端线条的属性,如颜色、粗细等;
- whiskerprops: 设置须的属性,如颜色、粗细、线的类型等
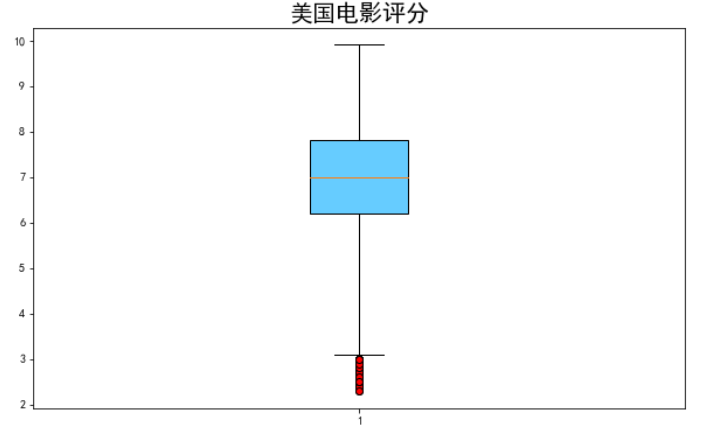
美国电影评分的箱线图
data = df[df.产地 == "美国"]["评分"]
plt.figure(figsize = (10,6))
plt.boxplot(data,
whis = 2,# 异常值默认1.5
flierprops = {"marker":'o',
"markerfacecolor":"r","color":'k'}# 这里color指的是边框线的颜色
,patch_artist = True,
boxprops = {"color":'k',"facecolor":"#66ccff"})#箱体颜色
plt.title("美国电影评分",fontsize = 20)
plt.show()
多组数据箱线图
data1 = df[df.产地 == "中国大陆"]["评分"]
data2 = df[df.产地 == "日本"]["评分"]
data3 = df[df.产地 == "中国香港"]["评分"]
data4 = df[df.产地 == "英国"]["评分"]
data5 = df[df.产地 == "法国"]["评分"]
plt.figure(figsize = (12,8))
plt.boxplot([data1,data2,data3,data4,data5],
labels = ["中国大陆","日本","中国香港","英国","法国"],
whis = 2,
flierprops = {"marker":'o',"markerfacecolor":"r","color":'k'} ,
patch_artist = True,
boxprops = {"color":'k',"facecolor":"#66ccff"},
vert = False # 将箱线图横过来
)
ax = plt.gca() #获取当时的坐标系get current axis
ax.patch.set_facecolor("gray") #设置坐标系背景颜色
ax.patch.set_alpha(0.3) #设置背景透明度
plt.title("电影评分箱线图",fontsize = 20)
plt.show()
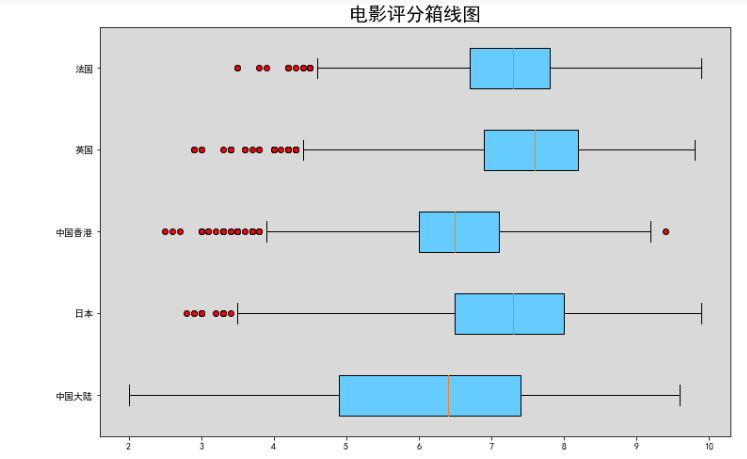
通过vert属性可以把图旋转过来
相关系数矩阵图--热力图
data = df[["投票人数","评分","时长"]]
data[:5]
pandas本身也封装了画图函数
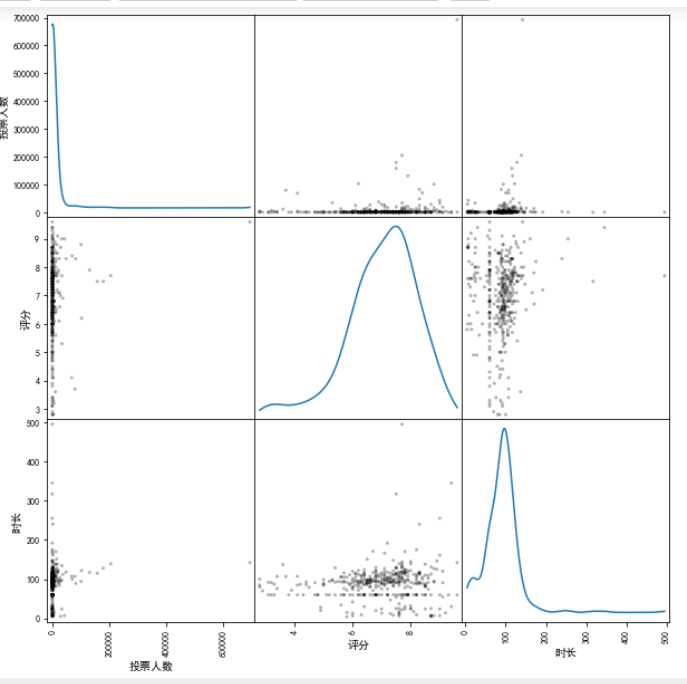
我们可以画出各个属性之间的散点图,对角线是分布图
%pylab inline
#魔术命令,让图像直接展示在notebook里面
result = pd.plotting.scatter_matrix(data[::100],diagonal = "kde",color = 'k',alpha = 0.3,figsize = (10,10))
#diagonal = hist:对角线上显示的是数据集各个特征的直方图/kde:数据集各个特征的核密度估计
现在我们来画电影时长,投票人数,评分的一个相关系数矩阵图
seaborn是一个精简的python库,可以创建具有统计意义的图表,能理解pandas的DataFrame类型
import seaborn as sns
corr = data.corr() #获取相关系数
corr = abs(corr) #取绝对值
fig = plt.figure(figsize = (10,8))
ax = fig.add_subplot(111)
ax = sns.heatmap(corr,vmax = 1,vmin = 0,annot = True,annot_kws = {"size":13,"weight":"bold"},linewidths = 0.05)
plt.xticks(fontsize = 15)
plt.yticks(fontsize = 15)
plt.show()
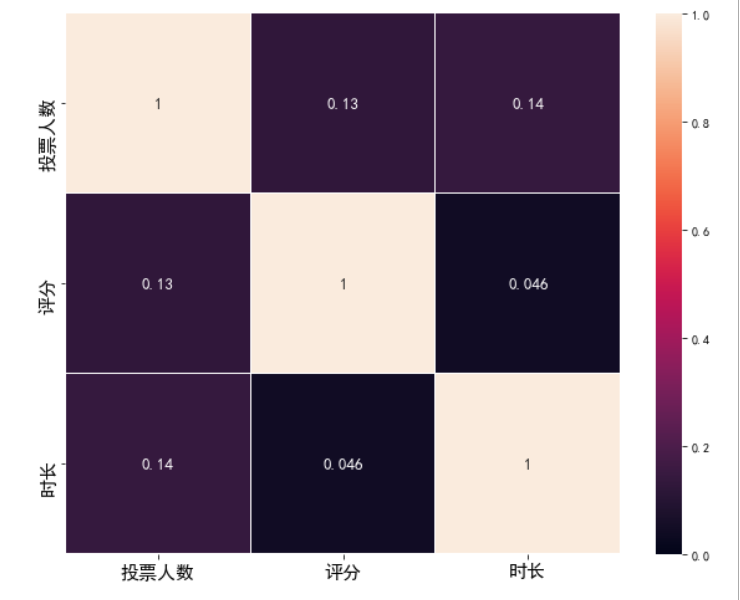
参数详解
sns.heatmap(data,vmin=None,vmax=None,cmap=None,center=None,robust=False,annot=None,fmt='.2g',annot_kws=None,linewidths=0,linecolor='white',cbar=True,cbar_kws=None,cbar_ax=None,square=False,xticklabels='auto',yticklabels='auto',mask=None,ax=None,**kwargs,)
( 1 )热力图输入数据参数:
data:矩阵数据集,可以是numpy的数组(array),也可以是pandas的DataFrame。如果是DataFrame,则df的index/column信息会分别对应到heatmap的columns和rows,即pt.index是热力图的行标,pt.columns是热力图的列标。
( 2 )热力图矩阵块颜色参数:
vmax,vmin:分别是热力图的颜色取值最大和最小范围,默认是根据data数据表里的取值确定。cmap:从数字到色彩空间的映射,取值是matplotlib包里的colormap名称或颜色对象,或者表示颜色的列表;改参数默认值:根据center参数设定。center:数据表取值有差异时,设置热力图的色彩中心对齐值;通过设置center值,可以调整生成的图像颜色的整体深浅;设置center数据时,如果有数据溢出,则手动设置的vmax、vmin会自动改变。robust:默认取值False,如果是False,且没设定vmin和vmax的值。
( 3 )热力图矩阵块注释参数:
annot(annotate的缩写):默认取值False;如果是True,在热力图每个方格写入数据;如果是矩阵,在热力图每个方格写入该矩阵对应位置数据。fmt:字符串格式代码,矩阵上标识数字的数据格式,比如保留小数点后几位数字。annot_kws:默认取值False;如果是True,设置热力图矩阵上数字的大小颜色字体,matplotlib包text类下的字体设置;
( 4 )热力图矩阵块之间间隔及间隔线参数:
linewidth:定义热力图里“表示两两特征关系的矩阵小块”之间的间隔大小。linecolor:切分热力图上每个矩阵小块的线的颜色,默认值是"white"。
( 5 )热力图颜色刻度条参数:
cbar:是否在热力图侧边绘制颜色进度条,默认值是True。cbar_kws:热力图侧边绘制颜色刻度条时,相关字体设置,默认值是None。cbar_ax:热力图侧边绘制颜色刻度条时,刻度条位置设置,默认值是None
( 6 )
square:设置热力图矩阵小块形状,默认值是False。xticklabels,yticklabels:xticklabels控制每列标签名的输出;yticklabels控制每行标签名的输出。默认值是auto。如果是True,则以DataFrame的列名作为标签名。如果是False,则不添加行标签名。如果是列表,则标签名改为列表中给的内容。如果是整数K,则在图上每隔K个标签进行一次标注。
4.5 第七课作业
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import warnings
warnings.filterwarnings("ignore") #关闭一些可能出现但对数据分析并无影响的警告
plt.rcParams["font.sans-serif"] = ["SimHei"] #解决中文字符乱码的问题
plt.rcParams["axes.unicode_minus"] = False #正常显示负号
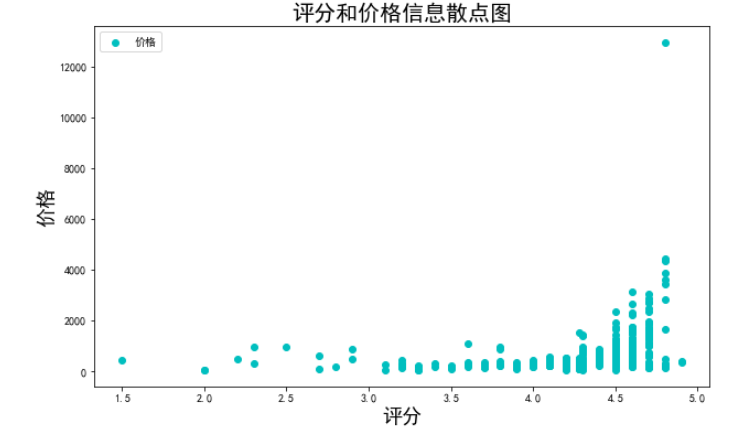
(1)读取酒店数据2.xlsx,根据评分和价格信息,绘制散点图。
df = pd.read_excel("酒店数据2.xlsx",index_col=0)
x = df['评分']
y = df['价格']
plt.figure(figsize=(10,6))
plt.scatter(x,y,color='c',marker='o',label='价格')
plt.legend()
plt.title("评分和价格信息散点图",fontsize=20)
plt.xlabel("评分",fontsize=18)
plt.ylabel("价格",fontsize=18)
plt.show()
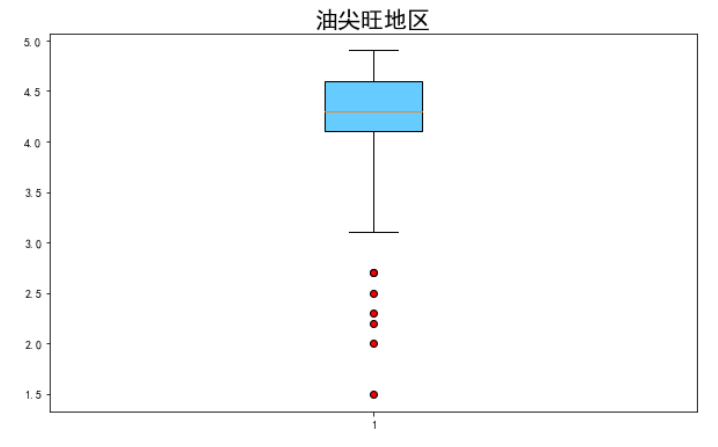
(2)画出油尖旺地区,评分的箱线图。
pic1 = df[df.地区=='油尖旺']['评分']
plt.figure(figsize=(10,6))
plt.boxplot(pic1,whis=2,
flierprops={
"marker":'o',
"markerfacecolor":"r",
"color":'k'
},patch_artist = True,
boxprops = {"color":'k',"facecolor":"#66ccff"})
plt.title("油尖旺地区",fontsize = 20)
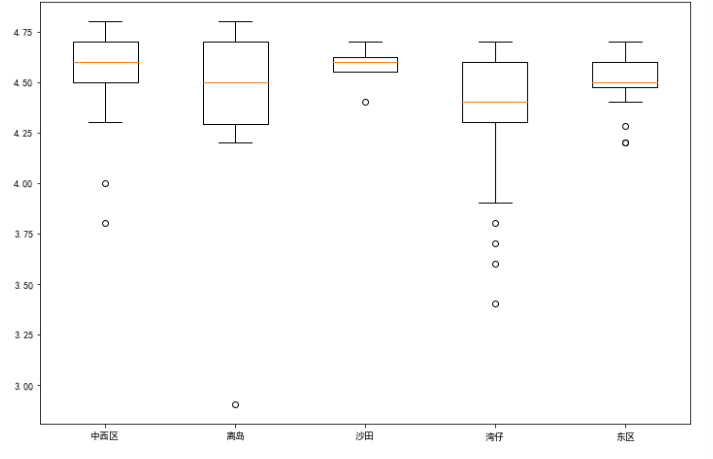
(3)选出平均价格前5的地区,画出这些地区的评分的箱线图。
data = df['价格'].groupby(df['地区']).mean().sort_values(ascending=False)[:5]
data

data1 = df[df.地区 == '中西区']['评分']
data2 = df[df.地区 == '离岛']['评分']
data3 = df[df.地区 == '沙田']['评分']
data4 = df[df.地区 == '湾仔']['评分']
data5 = df[df.地区 == '东区']['评分']
plt.figure(figsize=(12,8))
plt.boxplot([data1,data2,data3,data4,data5],
labels = ["中西区","离岛","沙田","湾仔","东区"])
plt.plot()
(4)将题目2,3的图像旋转90度。
plt.boxplot(pic1, whis=1.7, patch_artist=True, vert=False)
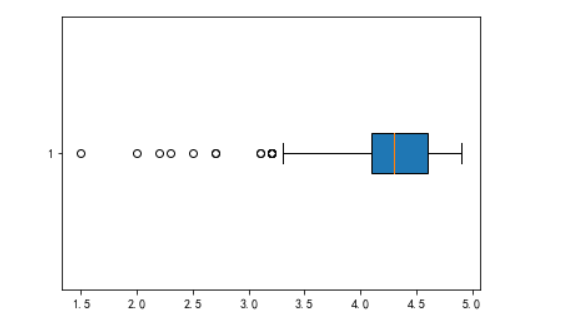
plt.boxplot((data1, data2, data3, data4, data5), labels=['中西区', '离岛', '沙田', '湾仔', '东区'], vert=False)
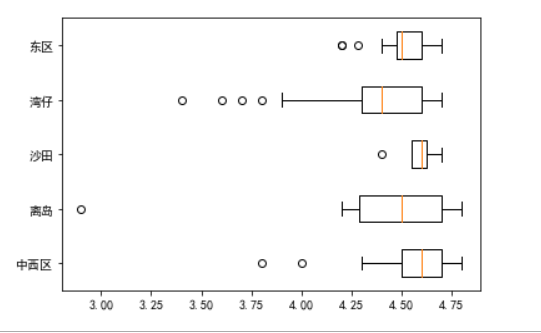
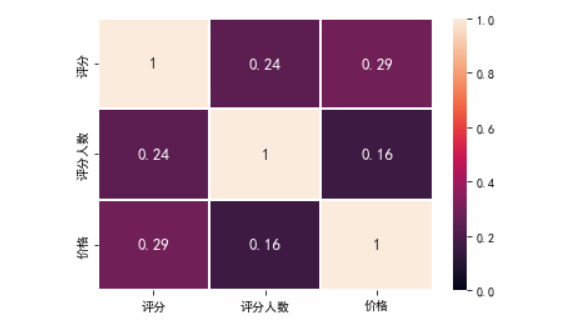
(5)绘制一个评分,评分人数和价格之间的相关系数图
import seaborn as sns
corr = df[['评分', '评分人数', '价格']].corr()
corr = abs(corr)
sns.heatmap(corr, vmax=1, vmin=0, annot=True, annot_kws={'size': 13, 'weight': 'bold'},linewidths=0.05)
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号