Detecting Unknown Encrypted Malicious Traffic in Real Time via Flow Interaction Graph Analysis
根据实时流交互图分析技术的未知加密有害流量检测
背景
现有技术的不足
目前的加密流量检测大多基于根据已知攻击的先验知识的监督学习,对于未知类型的攻击难以检测
加密性: DPI检测和传统的基于签名的方法失效
多样性: 现有机器学习方法无法检测未知模式攻击,泛化能力差
论文目的
设计并完成一种无监督(自监督)机器学习算法,完成对未知加密流量的检测
技术关键点
提出基于流量模式提取出紧凑内存图(compact in-memory graph)信息论模型证明图中信息接近理论界
用图形结构特征捕获流的交互模式(不基于已知攻击的先验知识)用图结构来代替加密数据流信息
开发无监督的图学习方法,来分析图(连通性,稀疏性和各种统计特性)的异常情况
技术基本思想
流量攻击涉及具有攻击者和受害者之间的不同流交互的多个攻击步骤,这与良性流交互模式不同
文章基于这一点计划利用各种流之间的交互模式进行恶意流量检测
通过建立图模型捕获并表示不同流的交互模式
设计自监督模型学习图信息完成 异常检测 开集识别?
建图
传统五元组
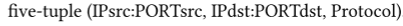
依赖爆炸问题
图表示流信息的问题
- 建图的复杂度;
- 建图和处理过程中的信息损失;
灵感
流的大小分别研究 study of the flow size distribution
tips:互联网上数据流大部分为短流,而同时大部分的数据包都与长流相关联
方案
采用两种不同策略分别记录并处理短流和长流的交互模式
短流:基于短流的相似性进行聚合 降低图的密度
长流:分布拟合 保留流交互信息
四步自监督学习: 利用图上保留的交互信息
自监督学习策略
- 分析图的连通性,通过提取图的连通分量; 识别异常,通过聚合高纬度的统计信息; 排除良性成分,减少学习开销
- 边的预聚合 根据边特征中的局部邻接; 减少特征处理开销,确保实时检测
一般根据图的局部邻接做边聚合的步骤:
- 遍历图中的每条边,计算每个节点的邻接节点集合。
- 根据节点的邻接节点集合,将图中的边进行聚合。聚合的方式可以根据具体需求来确定,例如可以将具有共同邻接节点的边聚合为一条新的边。
- 更新图的邻接矩阵或邻接表,将聚合后的边加入图中,同时删除被聚合的边。
- 提取关键节点 利用Z3 SMT解决节点覆盖问题,最小化聚类数量
- 聚合关键节点 通过关键节点所连的关键边(边预聚合) 获得异常边表示异常流量
设计目标
实时流量检测系统
检测路由器复制的流信息
发现异常后与路径上的其他防御技术合作抑制异常流量 并对异常流量进行载荷检测
实现通用检测 同时检测加密流量和非加密流量构成的攻击
实现实时高速流量处理 低延迟检测加密流量
实现自监督学习 有效处理未知模式的攻击
威胁模型
限定
本文仅关注于检测加密流量构造的主动攻击
不考虑不对被害者产生流量的被动攻击(窃听,流量分析)
概述
有害加密流量与正常流量比较
single-flow:相似
Interaction :区别很大
因此
构建图维护多种流之间的交互模式
学习图特征来检测异常模式
建图

-
收集网络流用于建图
-
将网络流量按照长短进行分类,并记录其中的交互关系 减少图的密度
-
聚合大量类似的短流形成与短流相关的边(降低图的密度)
-
拟合长流的分布特征形成与长流相关的边(高保真记录流量的交互模式)
-
使用不同的地址作为节点,连接上述与短流和长流相关的边
图预处理
![]()
-
提取连接组件
-
通过高纬度统计特征对连接组件进行聚类,并过滤只含有良性交互模式的组件
-
执行预聚类,并使用生成的聚类中心表示边
基于图的恶意流量检测
- 通过解决节点覆盖问题找出关键节点
- 对于每个选定的节点,根据代表流量交互模式的流特征和结构特征对所有连接的边聚类
- 计算聚类的损失函数,识别异常(与基于重建的异常处理相似)
实现细节
图构造
流量分类
由于短流和长流的分布特征(仅占比2.36%的长流包括了数据集中93.70%的数据包)
所以对长短流量应用不同的收集策略
收集信息: 常用的加密流量信息 一般性检测
- 源目的地址
- 源目的端口
- 数据包的协议
- 数据包的长度
- 数据包的到达间隔
分类算法

维护一个计时器 time_now 一个hash表 Hash(Src , Dst , Src_Port , Dst_Port )
将流表示为流的所有包的Hash序列 特征序列
每个间隔时间判断一次流是否结束,判断流大小和Flow_Line大小分类
短流聚合
目前问题
如果直接使用四元组作为边,图会非常稠密,复杂度高
解决方法
发现大部分短流具有几乎一样的特征序列
因此分类后使用一条边来聚合相似的短流
聚合算法

-
协议聚合
- 源地址聚合: 源地址相同且超过一定数量聚合并加入短流边(目的地址相同直接记录,目的地址不同记录所有地址)
- 目的地址聚合:目的地址相同且超过一定数量聚合加入短流边(记录所有出现源地址)
-
将未进行地址聚合的加入短流边
此时节点可能代表一个地址,也可能代表一组地址
长流拟合
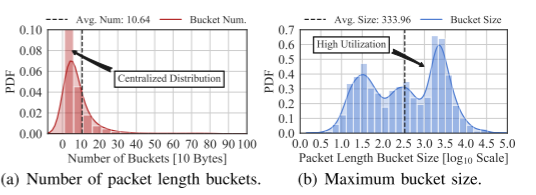
由于长流的特征是集中分布的,我们使用直方图来表示长流的各种特征分布
维护一个Hash表为每个长流中的特征序列构造直方图(多输入低输出)
根据实验权衡拟合精度和开销之间的关系
数据包大小拟合:数据包桶宽度选用10bytes
间隔时间拟合: 到达间隔选用1ms
协议拟合
以桶宽度来划分每个包的特征,并且增加以hash码索引的计数器的值
将hash码和相关计数器的值记录为直方图
我们确定了集中式的特征分布,即长流中的大部分数据包具有相似的数据包长度和到达间隔。
具体来说,在图中,我们平均只使用11个桶来拟合数据包长度的分布,而大多数桶收集的数据包都超过200个,这说明基于直方图的拟合是有效的,且存储开销较小。
由于协议类型有限,我们使用协议的掩码作为哈希码,并使用较小数量的桶来实现更有效的拟合。
图的预处理
目的
- 确定关键组件
- 边的预聚类
连通性分析
-
DFS获取连接组件
-
根据连接组件分割图
-
对每个连接组件的信息进行收集
- 长流数量
- 短流数量
- 长流字节数
- 短流字节数
- 预聚类后短流边数
-
归一化
-
DBSCAN聚类
-
计算据中心距离找出离群点
去除正常组件,仅保留异常组件等待下一步处理
边的预聚类
生成图的特征: 边的分布是稀疏的 大部分相似的边分布在一起
继续使用DBSCAN对边进行聚类
使用KD-Tree进行局部搜索,选择聚类中心来代表集群类中的所有边
分别为短流和长流关联的边提取结构特征
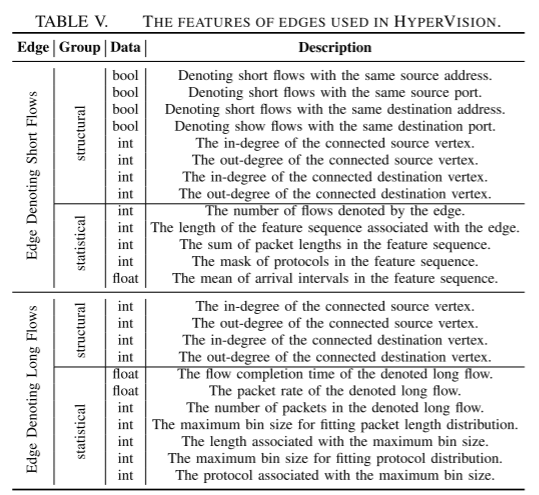
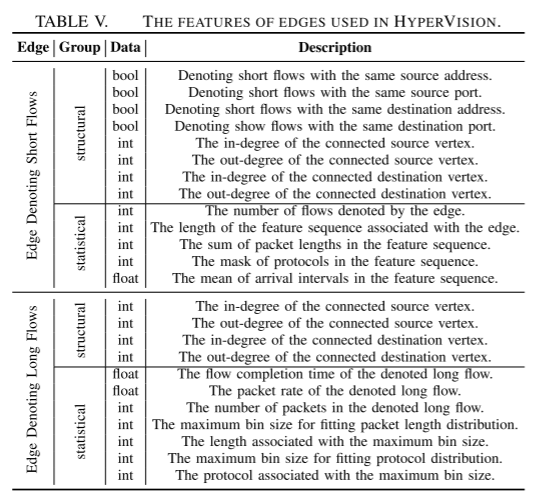
恶意流量的这些程度特征与良性流量明显不同
例如长流关联边的原顶点的入度
例如,表示垃圾邮件机器人的顶点比良性客户端有更高的超出度,因为它们与服务器的频繁交互。
对特征归一化
超参数选用问题

应该是采用较小容忍度,聚类后仍留下大量边,以避免错误错误代价问题
有些边不能聚类,应该作为离群值处理,这些离群值将被处理为只有一条边的聚类
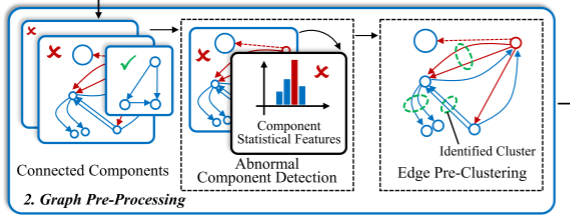
恶意流量识别
思路
识别图上的异常交互模式来检测加密的恶意流量
做法
通过聚类连接到相同关键节点的边,将其中的异常值检测为恶意流量
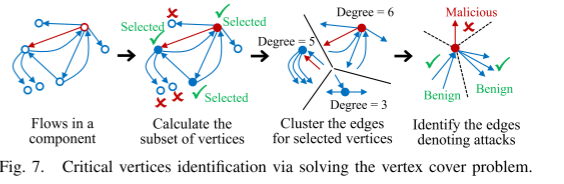
识别关键节点
为了有效地了解流量的交互模式,仅对连接到关键节点的边进行聚类
不大规模改变图结构,尽力保留流量信息
对于每个连通分量 选取连通分量中所有顶点的子集作为临界顶点
规则
-
组件中 源节点(和 / 或)目的节点都在子集(关键节点集)中
确保所有的边都连接到了至少一个关键节点,并且至少被聚合了一次
-
最小化关键点集的大小
最小化关键点集
等价于 最小顶点覆盖问题(vertex cover problem)NPC问题
利用每个部件中的所有边和顶点并将其改写为SMT(Satisfiability Modulo Theories)问题
并利用 Z3_SMT 求解器有效求解
边特征记录检测
思路
聚类连接到每个关键节点的边,计算聚类损失以识别异常交互 (类似于基于重建的异常检测)
当聚类损失达到一定阀值时判定异常
细节
聚类依据
- 短流的逐包特征序列 长流的拟合特征分布中提取的流特征
聚类算法
K-Means
利用聚类损失表示恶意程度
损失函数
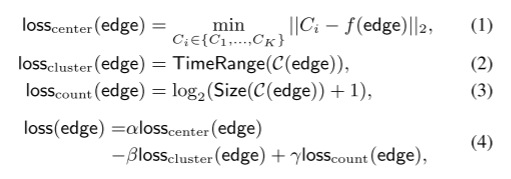
- 损失中心为到簇中心的欧氏距离,表示与连接到临界顶点的其他边的差值
- 预聚类所确定的簇所涵盖的时间范围 代表的流的持续时间
长期持续的交互模式往往时良性的- 边所表示的流的数量
大量流量的爆发一般情况会标志恶意行为的出现
方案总结
总思路
将网络流量处理后建图(点代表某个节点或某些节点的集合;边代表网络流量交互 有不同处理策略),通过聚类连接在同一节点上的边将图重建为一个个部件,并计算聚类损失来识别异常(当聚类时损失异常则判定流量异常)
但是网络流量复杂繁多,节点众多,复杂度过高
考虑将大部分的正常流量或网络中正常部分排除
将流量产生的边一步步聚类减少边密度
通过解决最小节点覆盖问题减少需要处理的节点
将连在同一关键节点上的边聚类
计算聚类损失判定异常
具体处理及作用
将流量分类收集信息后(由于短流和长流的分布特征)
对短流进行聚合(降低图密度)
对长流利用直方图方式拟合(信息聚合 降低储存压力)
对图进行预处理(进一步降低计算压力)
连通性分析
DFS获取连接部件
聚类排除良性部件(降低计算压力)
边的预聚类(降低计算压力)
节点覆盖问题(减少需要处理的点 降低计算压力)仅处理关键节点即可包括所有流
聚类关键节点连在上的边,计算损失检测异常
实验部分
编译环境 Ubuntu 20.04.2 (Linux 5.11.0), Docker 20.10.7 GCC 9.3.0 && CMake 3.16.3
数据平面数据包转发 DPDK 19.11.9
聚类算法模块 DBSCAN && K-Means from mlpack 3.4.2
节点覆盖问题模块 Z3-SMT Solver 4.8
数据集 vantage-G数据集 from 日本东京 2020年1月~6月 WIDE MAWI project
Kitsune CICDDoS2019 CIC-IDS2017
实验结果 结果与五种较先进的加密流量检测作为基线
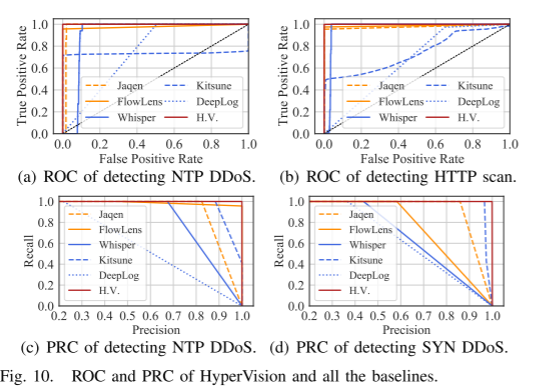
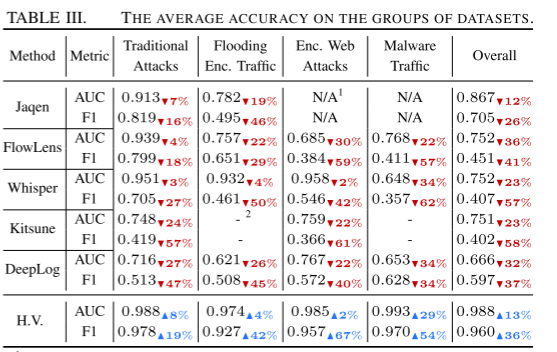
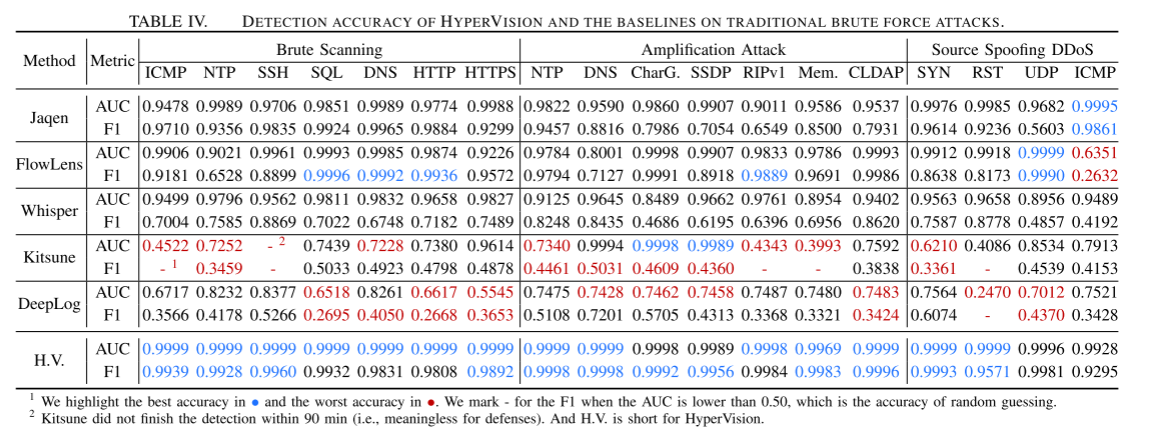
Demo
环境要求
It can be built on Clean Ubuntu
环境建立
git clone https://github.com/fuchuanpu/HyperVision.git
cd HyperVision
sudo ./env/install_all.sh
数据集建立
wget https://hypervision-publish.s3.cn-north-1.amazonaws.com.cn/hypervision-dataset.tar.gz
tar -xxf hypervision-dataset.tar.gz
rm $_
Build && Run
./script/rebuild.sh
./script/expand.sh
cd build && ../script/run_all_brute.sh && cd ..
Rebuild
Expand

Run
结果分析
cd ./result_analyze
./batch_analyzer.py -g brute
cat ./log/brute/*.log | grep AU_ROC
analyzer
AU_ROC


 浙公网安备 33010602011771号
浙公网安备 33010602011771号