HTML(前端web)
目录
一:HTML前端
1.什么是前端?
任何与操作系统打交道的界面都可以称之为"前端"
手机界面(app) 电脑界面(软件) 平板界面(软件)

2.什么是后端?
不直接与用户打交道,而是控制核心逻辑的运行
各种编程语言编写的代码(python代码、java代码、c++代码)
3.什么是HTML?
- 超文本标记语言(Hypertext Markup Language, HTML)是一种用于创建网页的标记语言。
- 本质上是浏览器可识别的规则,我们按照规则写网页,浏览器根据规则渲染我们的网页。对于不同的浏览器,* 对同一个标签可能会有不同的解释。(兼容性问题)
- 网页文件的扩展名:.html或.htm
4.HTML不是什么?
HTML是一种标记语言(markup language),它不是一种编程语言。
HTML使用标签来描述网页。

5.前端的学习流程
前端三剑客
HTML 网页的骨架(没有样式很丑)
CSS 网页的样式(给骨架美化)
JS 网页的动态效果(丰富用户体验)
6.BS架构
我们在编写TCP服务端的时候 针对客户端的选择可以是自己写的客户端代码也可以是浏览器充当客户端(bs架构本质也是cs架构)
7.搭建服务器 简易(浏览器访问)
- 服务端
import socket
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen()
while True:
sock, addr = server.accept()
while True:
data = sock.recv(1024)
if data == 0:break
print(data)
sock.send(b'hello big baby')
- 浏览器 客户端 访问测试

8.浏览器访问报错原因
我们自己编写的服务端发送的数据浏览器不识别 原因在于
每个人服务端数据的格式千差万别 浏览器无法自动识别
没有按照浏览器固定的格式发送
9.总结解决方法
x 浏览器可以访问很多服务端 如何做到无障碍的与这么多不同程序员开发的软件实现数据的交互1.浏览器自身功能强大 自动识别并切换(太过消耗资源)2.大家统一一个与浏览器交互的数据方式(统一思想) 统一标准 就是:HTTP协议
二:HTTP协议(重点)
1.什么是协议?
大家商量好的一个共同认可的结果

2.HTTP协议
1.规定了浏览器与服务端之间数据交互的方式及其他事项
2.如果我们开发的时候不遵循该协议 那么浏览器就无法识别我们的网站

三:四大特性
1.基于请求响应
服务端永远不会主动给客户端发消息 必须是客户端先发请求
如果想让服务端主动给客户端发送消息可以采用其他网络协议
2.基于TCP、IP作用于应用层之上的协议
应用层(HTTP)、传输层、网络层、数据链路层、物理链接层
3.无状态
不保存客户端的状态信息
早期的网站不需要用户注册 所有人访问的网页数据都是一样的
"纵使见她千百遍 我都当她如初见"
4.无连接/短连接
两者请求响应之后立刻断绝关系
四:数据格式
1.请求格式
浏览器给服务端发送数据(请求数据格式)
请求首行(网络请求的方法)
请求头(一堆k:v键值对)
(换行符 不能省略)
请求体(并不是所有的请求方法都有)
2.响应格式
服务端给浏览器发送数据(响应数据格式)
响应首行(响应状态码)
响应头(一堆k:v键值对)
(换行符 不能省略)
响应体(即将交给浏览器的数据)
五:响应状态码
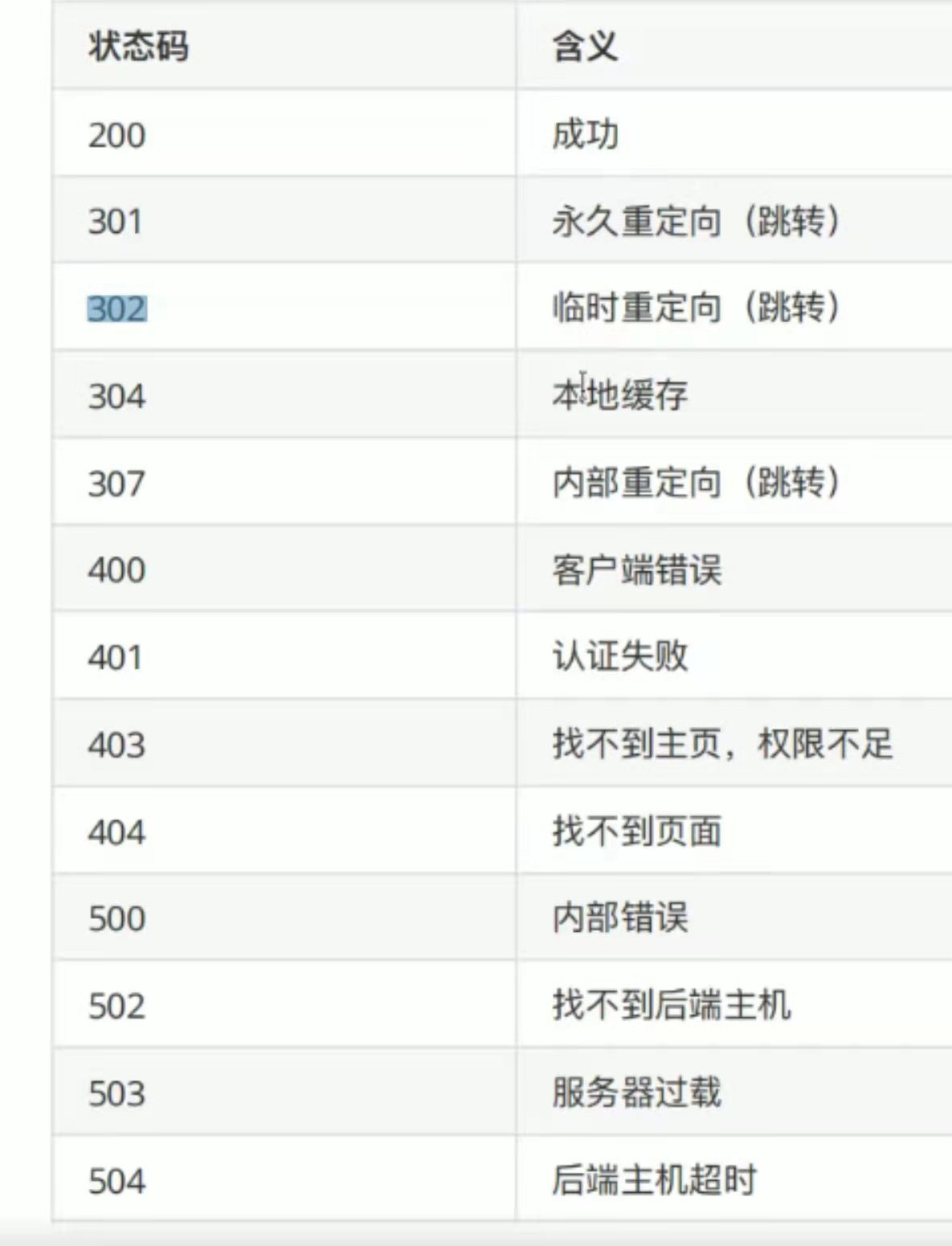
1.响应状态码
用数字来表示一串中文意思
1XX:服务端已经接受到了数据正在处理 你可以继续发送数据也可以等待
2XX:200 OK请求成功 服务端返回了相应的数据
3XX:重定向(原本想访问A页面 但是自动跳转到了B页面)
4XX:403没有权限访问 404请求资源不存在
5XX:服务器内部错误
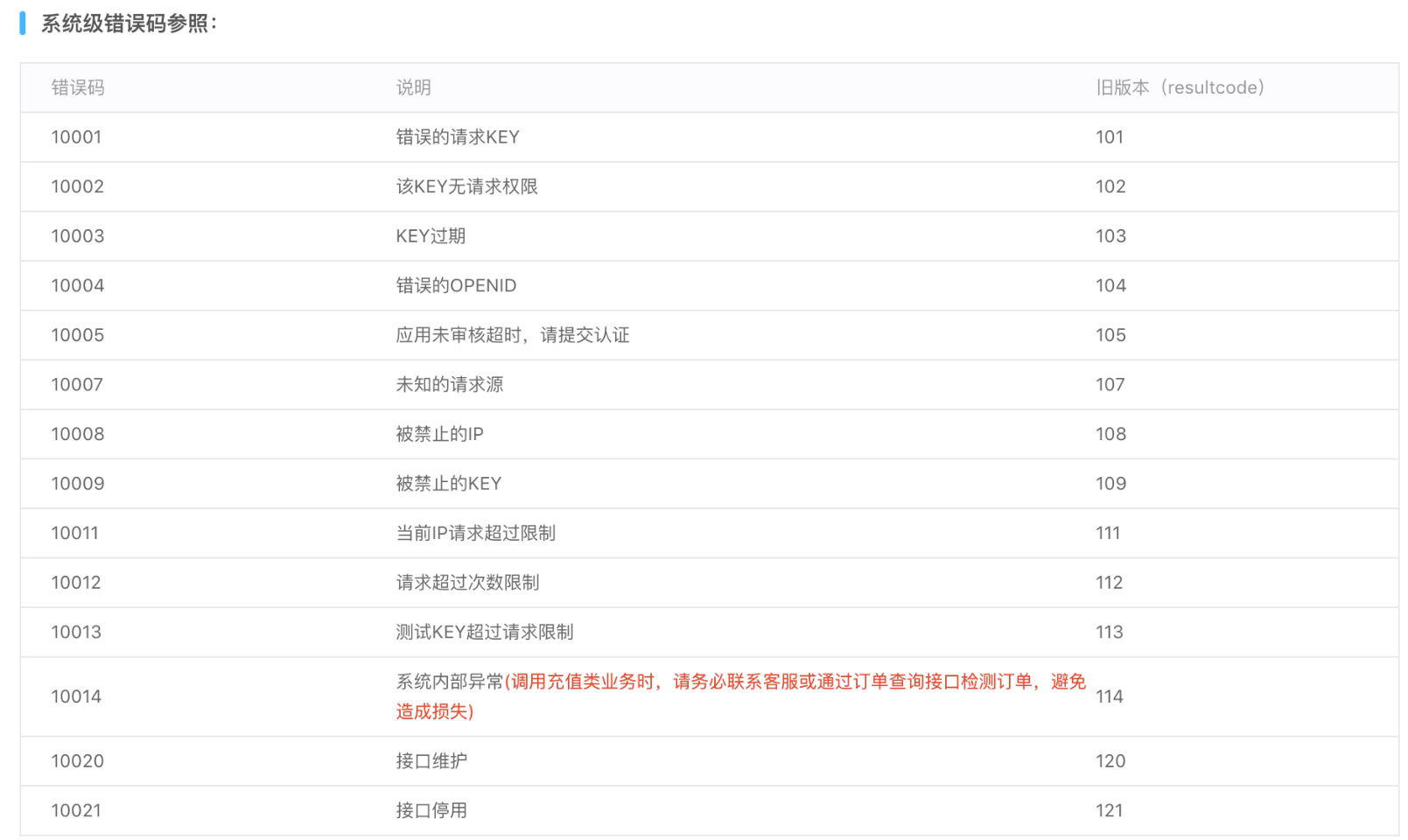
2.自定义状态码
公司还会自定义状态码 一般以10000开头
参考: 聚合数据 APL
作用:
后端写给前端的状态码
六:HTML本质(搭建)
1.简易版
import socket
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen()
'''
请求首行
b'GET / HTTP/1.1\r\n
请求头
Host: 127.0.0.1:8080\r\n
Connection: keep-alive\r\n
sec-ch-ua: "Chromium";v="94", "Google Chrome";v="94", ";Not A Brand";v="99"\r\nsec-ch-ua-mobile: ?0\r\nsec-ch-ua-platform: "Windows"\r\n
Upgrade-Insecure-Requests: 1\r\n
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36\r\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9\r\n
Sec-Fetch-Site: none\r\n
Sec-Fetch-Mode: navigate\r\n
Sec-Fetch-User: ?1\r\n
Sec-Fetch-Dest: document\r\n
Accept-Encoding: gzip, deflate, br\r\n
Accept-Language: zh-CN,zh;q=0.9\r\n
\r\n
请求体(当前为空)
'
'''
while True:
sock, addr = server.accept()
data = sock.recv(1024)
# 遵循HTTP响应格式
sock.send(b'HTTP/1.1 200 OK\r\n\r\n')
# 格式化字体
sock.send(b'<h1>hello world baby<h1>')
2.网址实现web
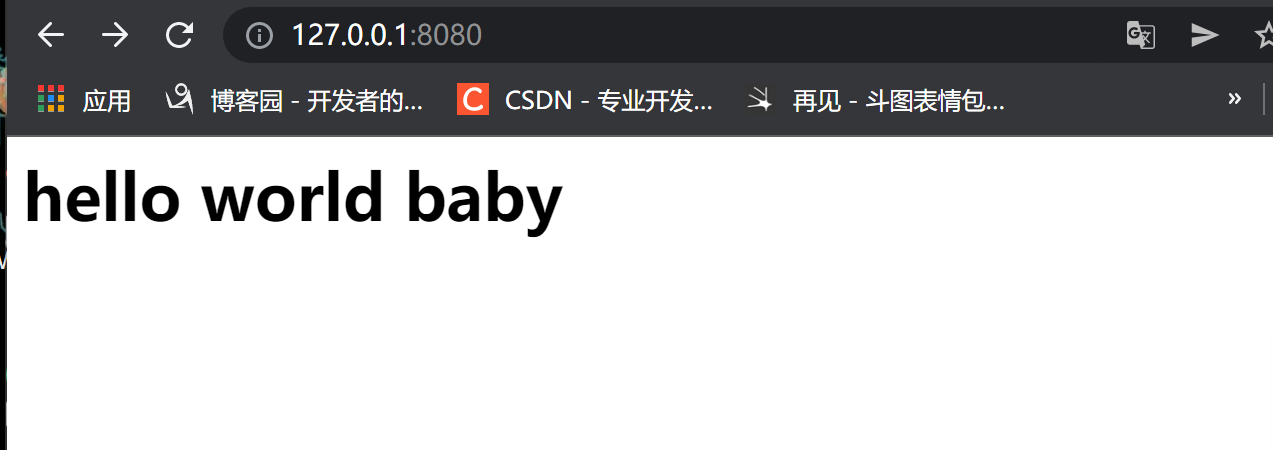
- 浏览器发请求 --> HTTP协议 --> 服务端接收请求 --> 服务端返回响应 --> 服务端把HTML文件内容发给浏览器 --> 浏览器渲染页面
七:HTML 进阶版 WEB页面搭建
1.代码实现
import socket
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen()
while True:
sock, addr = server.accept()
data = sock.recv(1024)
# 遵循HTTP响应格式
sock.send(b'HTTP/1.1 200 OK\r\n\r\n')
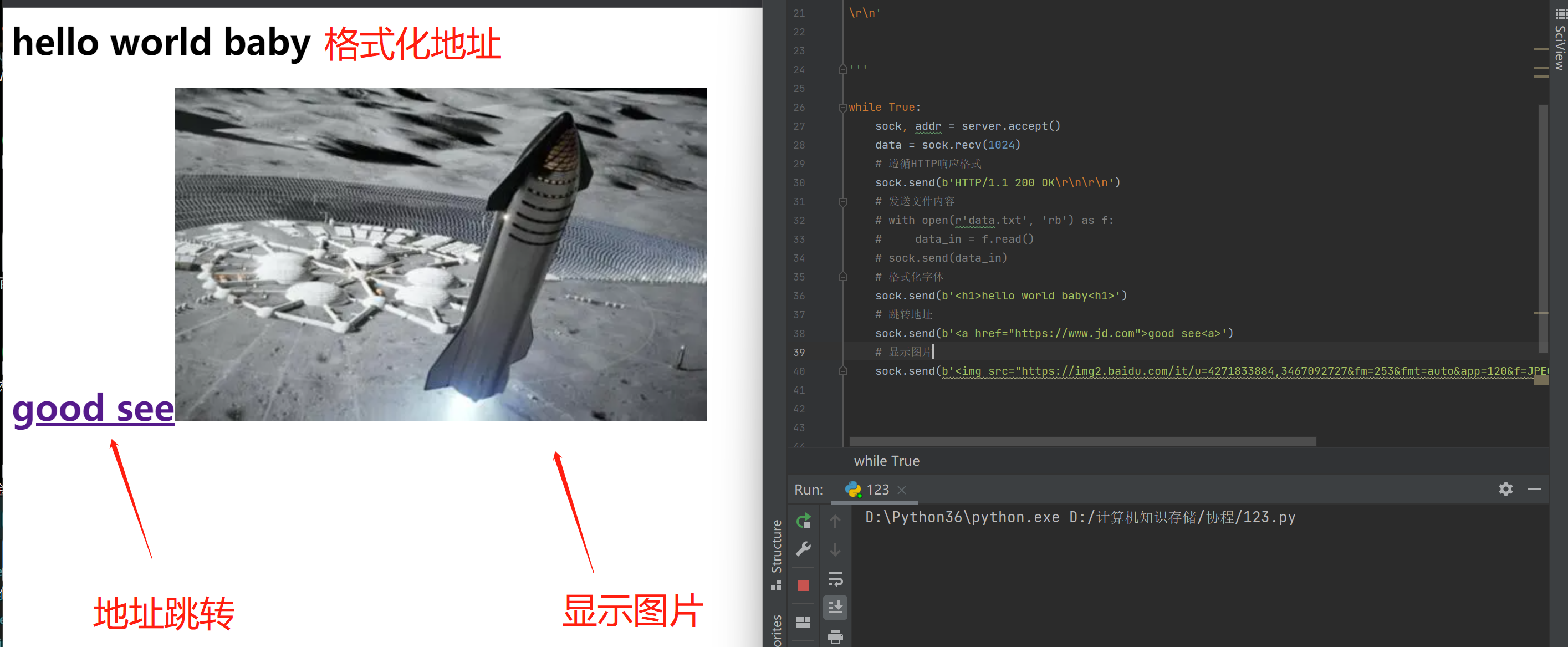
# 格式化字体
sock.send(b'<h1>hello world baby<h1>')
# 跳转地址
sock.send(b'<a href="https://www.jd.com">good see<a>')
# 显示图片
sock.send(b'<img src="https://img2.baidu.com/it/u=4271833884,3467092727&fm=253&fmt=auto&app=120&f=JPEG?w=480&h=300"/>')
# 发送文件内容
# with open(r'data.txt', 'rb') as f:
# data_in = f.read()
# sock.send(data_in)
2.网址测试 实现基础WEB页面

 浙公网安备 33010602011771号
浙公网安备 33010602011771号