
进程(守护进程--互斥锁--IPC机制--生产者模型--僵尸进程与孤儿进程--模拟抢票--消息队列)
一:进程理论知识
- 顾名思义,进程即正在执行的一个过程。进程是对正在运行程序的一个抽象。
copy进程的概念起源于操作系统,是操作系统最核心的概念,也是操作系统提供的最古老也是最重要的抽象概念之 一。操作系统的其他所有内容都是围绕进程的概念展开的。

1.理论知识
copy1.操作系统的作用: 1:隐藏丑陋复杂的硬件接口,提供良好的抽象接口 2:管理、调度进程,并且将多个进程对硬件的竞争变得有序 2.多道技术: 1.产生背景:针对单核,实现并发 ps: 现在的主机一般是多核,那么每个核都会利用多道技术 有4个cpu,运行于cpu1的某个程序遇到io阻塞,会等到io结束再重新调度,会被调度到4个 cpu中的任意一个,具体由操作系统调度算法决定。 2.空间上的复用:如内存中同时有多道程序 3.时间上的复用:复用一个cpu的时间片 强调:遇到io切,占用cpu时间过长也切,核心在于切之前将进程的状态保存下来,这样 才能保证下次切换回来时,能基于上次切走的位置继续运行
二:什么是进程?
- 狭义定义:进程是正在运行的程序的实例
- 广义定义:进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。
三:僵尸进程与孤儿进程
1.僵尸进程
copy进程代码运行结束之后并没有直接结束而是需要等待回收子进程资源才能结束
copyfrom multiprocessing import Process import time def test(name): print('%s is running' % name) time.sleep(3) print('%s is over' % name) if __name__ == '__main__': p = Process(target=test, args=('jason',)) p.start() print('主')
- 孤儿进程
copy即主进程已经死亡(非正常)但是子进程还在运行 (子进程没有长辈)
copyfrom multiprocessing import Process import time def test(name): print('%s is running' % name) time.sleep(3) print('%s is over' % name) if __name__ == '__main__': while True: p = Process(target=test, args=('jason',)) p.start()
四:守护进程
1.什么是守护进程?
copy1.守护进程会随着主进程的结束而结束 2.主进程需要等待里面所有非守护进程的结束才能结束
copy主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束,
- 详细守护进程与守护线程区别:https://www.cnblogs.com/goOJBK/p/15806897.html
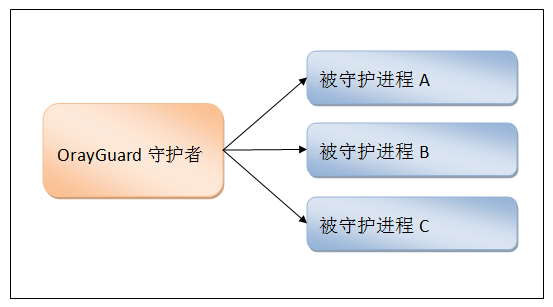
2.主进程创建守护进程
- 其一:守护进程会在主进程代码执行结束后就终止
- 其二:守护进程内无法再开启子进程,否则抛出异常:AssertionError: daemonic processes are not allowed to have children
- 守护进程:即守护着某个进程 一旦这个进程结束那么也随之结束
copy注意:进程之间是互相独立的,主进程代码运行结束,守护进程随即终止
3.守护进程
copyfrom multiprocessing import Process import time def test(name): print('总管:%s is running' % name) time.sleep(3) print('总管:%s is over' % name) if __name__ == '__main__': p = Process(target=test, args=('jason',)) p.daemon = True # 设置为守护进程(一定要放在start语句上方) p.start() print("皇帝jason寿终正寝") time.sleep(0.1)
五:互斥锁(模拟多人抢票)
1.什么是是锁?
copy锁就可以实现将并发变成串行的效果 行锁、表锁
2.什么是互斥锁?
copy互斥锁: 对共享数据进行锁定,保证同一时刻只能有一个线程去操作。 互斥锁是多个线程一起去抢,抢到锁的线程先执行,没有抢到锁的线程需要等待,等互斥锁使用完释放后,其它等待的线程再去抢这个锁。
3.为什么要使用互斥锁?
copy通过执行结果可以地址互斥锁能够保证多个线程访问共享数据不会出现数据错误问题 操作同一份数据不能并发,并发情况下操作同一份数据 极其容易造成数据错乱 互斥锁对共享数据进行锁定,保证同一时刻只能有一个线程去操作。
4.常见问题
copy问题:并发情况下操作同一份数据 极其容易造成数据错乱 解决措施:将并发变成串行 虽然降低了效率但是提升了数据的安全
5.注意
- 使用锁的注意事项:
copy在主进程中产生 交由子进程使用
- 1.一定要在需要的地方加锁 千万不要随意加
- 2.不要轻易的使用锁(死锁现象)
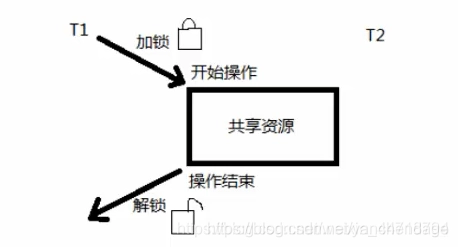
6.Lock模块
copyLock变量,这个变量本质上是一个函数,通过调用这个函数可以获取一把互斥锁
7.互斥锁(模拟多人抢票)
- 买票系统流程图
copy加上互斥锁多任务瞬间变成单任务,性能会下降,也就是说同一时刻只能有一个线程去执行
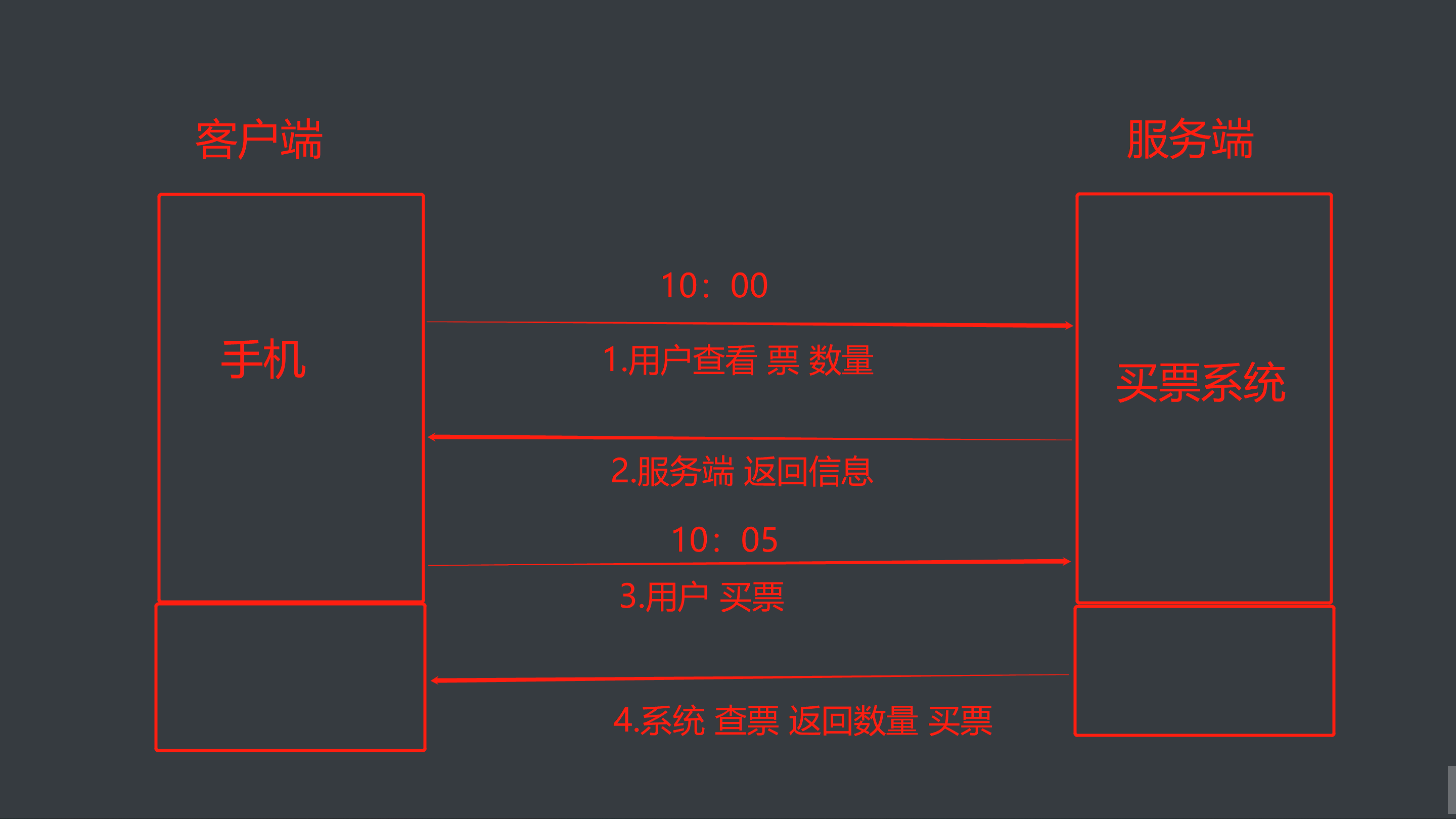
copyimport json from multiprocessing import Process, Lock import time import random # 查票 def search(name): with open(r'data.txt', 'r', encoding='utf8') as f: data_dict = json.load(f) ticket_num = data_dict.get('ticket_num') print('%s查询余票:%s' % (name, ticket_num)) # 买票 def buy(name): # 先查票 with open(r'data.txt', 'r', encoding='utf8') as f: data_dict = json.load(f) ticket_num = data_dict.get('ticket_num') # 模拟一个延迟(选座) 随机魔魁啊 time.sleep(random.random()) # 判断是否有票 if ticket_num > 0: # 买票 将余票减一 data_dict['ticket_num'] -= 1 # 重新写入数据库 with open(r'data.txt', 'w', encoding='utf8') as f: json.dump(data_dict, f) print('%s: 购买成功' % name) else: print('不好意思 没有票了!!!') def run(name,mutex): search(name) mutex.acquire() # 抢锁/上锁 (一次只有一个人可以通过) buy(name) mutex.release() # 释放锁 if __name__ == '__main__': # 创建互斥锁,赋值(串行) mutex = Lock() # 循环10次 模拟抢票 for i in range(1, 11): # 创建子进程 p = Process(target=run, args=('用户%s' % i,mutex)) # 执行子进程 p.start()
8.总结(抢票系统)解析
-
acquire和release方法之间的代码同一时刻只能有一个线程去操作
-
如果在调用acquire方法的时候 其他线程已经使用了这个互斥锁,那么此时acquire方法会堵塞,直到这个互斥锁释放后才能再次上锁。
-
提示:加上互斥锁,那个线程抢到这个锁我们决定不了,那线程抢到锁那个线程先执行,没有抢到的线程需要等待
六:IPC机制(进程间通信)--队列
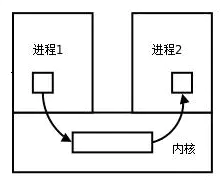
1.队列概况
copy每个进程各自有不同的用户地址空间,任何一个进程的全局变量在另一个进程中都看不到,所以进程之间要交换数据必须通过内核,在内核中开辟一块缓冲区,进程1把数据从用户空间拷到内核缓冲区,进程2再从内核缓冲区把数据读走,内核提供的这种机制称为进程间通信(IPC,InterProcess Communication)
2.Queue概念介绍
copy创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递。 底层队列使用管道和锁定实现。
3.注意
- 队列:先进先出
- 队列的数据放进去,取走就没了
4.(消息队列)代码搭建
copy1.full和get_nowait不能用于多进程情况下的精确使用 2.队列的使用就可以打破进程间默认无法通信的情况
- 队列:先进先出
copyfrom multiprocessing import Queue # 创建队列 不写默认2147483647 q = Queue(5) # 括号内可以填写最大等待数 # 存放数据 q.put(111) q.put(222) # print(q.full()) # False 判断队列中数据是否满了 q.put(333) q.put(444) q.put(555) # print(q.full()) # True # q.put(666) # 超出范围原地等待 直到有空缺位置 # 提取数据 print(q.get()) print(q.get()) print(q.get()) print(q.get()) print(q.get()) # print(q.get()) # 没有数据之后原地等待直到有数据为止 print(q.get_nowait()) # 没有数据立刻报错
七:(IPC消息队列)实现进程通信代码
1.主进程与子进程通信
copy进程间通信 相当于主进程与子进程通信 直白说是 存取数据
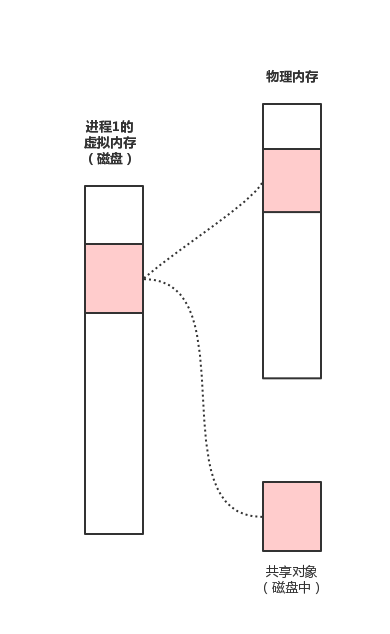
- 主进程与子进程代码实现通信
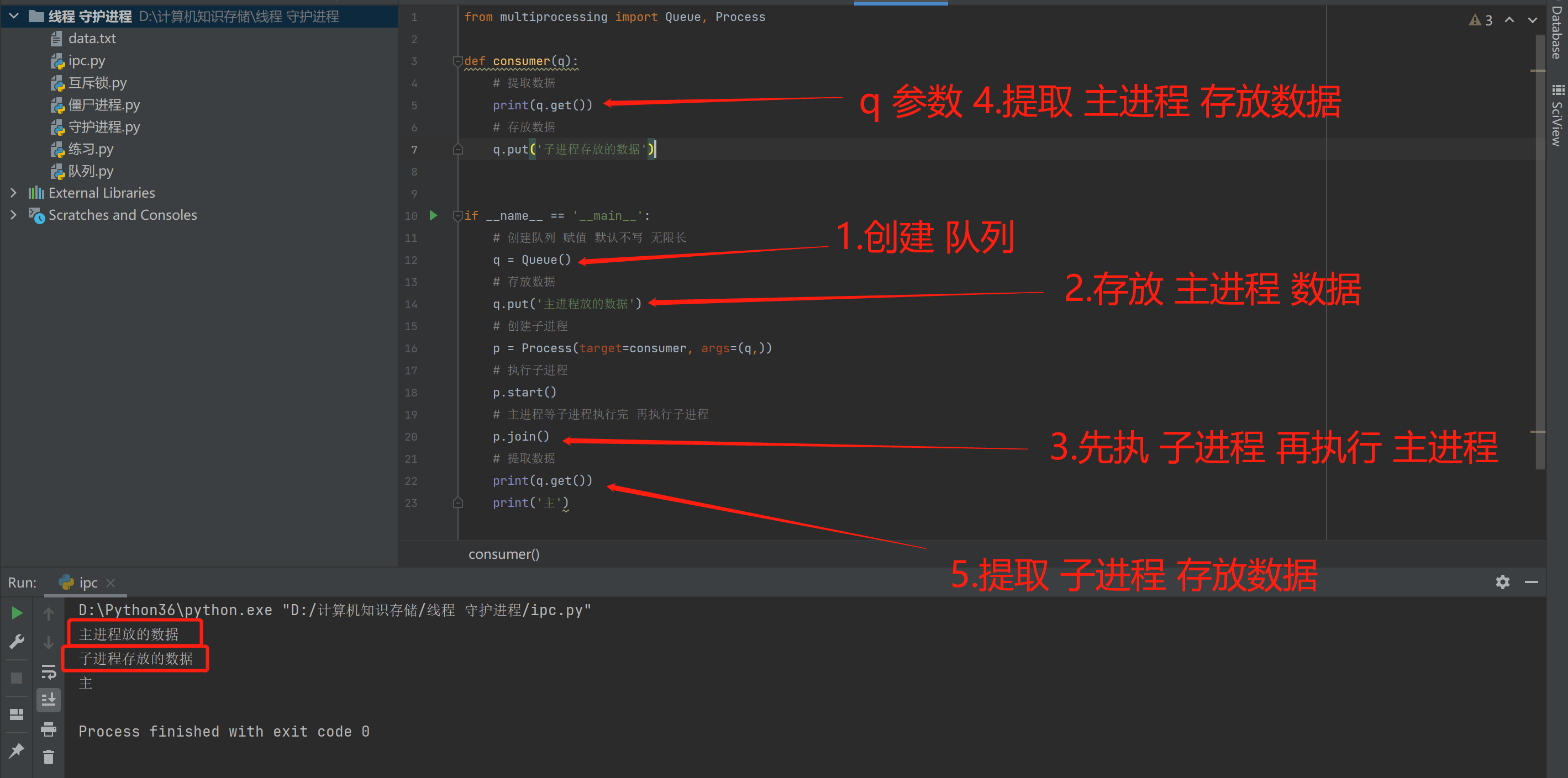
copyfrom multiprocessing import Queue, Process def consumer(q): # 提取数据 print(q.get()) # 存放数据 q.put('子进程存放的数据') if __name__ == '__main__': # 创建队列 赋值 默认不写 无限长 q = Queue() # 存放数据 q.put('主进程放的数据') # 创建子进程 p = Process(target=consumer, args=(q,)) # 执行子进程 p.start() # 主进程等子进程执行完 再执行子进程 p.join() # 提取数据 print(q.get()) print('主')
2.子进程与子进程通信
copy子进程与子进程之间通信
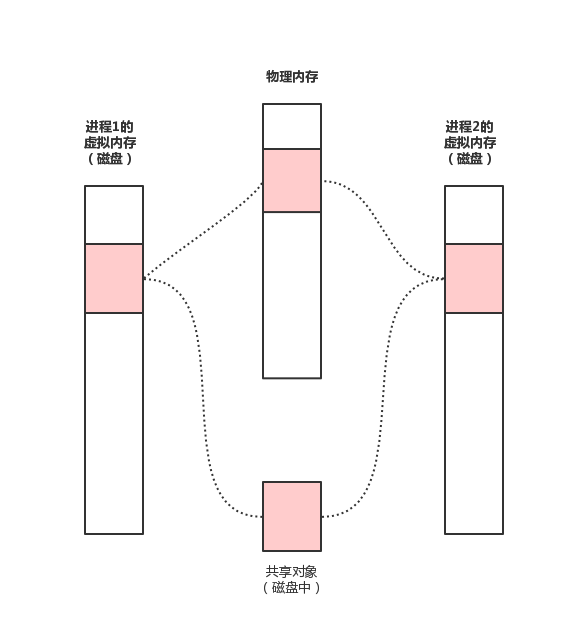
- 子进程与子进程之间通信代码实现
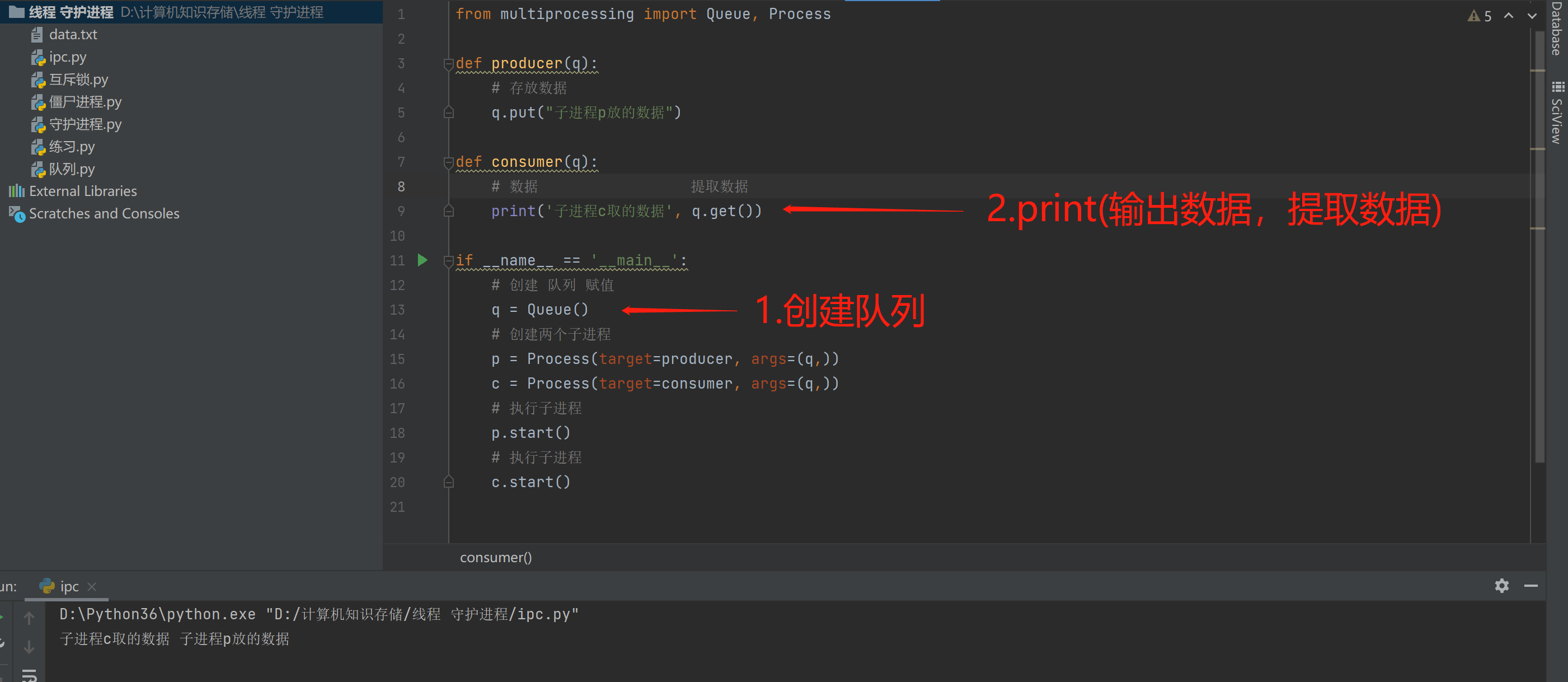
copyfrom multiprocessing import Queue, Process def producer(q): # 存放数据 q.put("子进程p放的数据") def consumer(q): # 数据 提取数据 print('子进程c取的数据', q.get()) if __name__ == '__main__': # 创建 队列 赋值 q = Queue() # 创建两个子进程 p = Process(target=producer, args=(q,)) c = Process(target=consumer, args=(q,)) # 执行子进程 p.start() # 执行子进程 c.start()
八:生产者消费者模型
- JoinableQueue队列实现生产者消费者模型
copy生产者消费者模型需要用到JoinableQueue模块 跟queue功能一样,但更加完善
- JoinableQueue 这就像是一个Queue对象,但队列允许项目的使用者通知生成者项目已经被成功处理。通知进程是使用共享的信号和条件变量来实现的。
1.参数介绍
- maxsize是队列中允许最大项数,省略则无大小限制。
2.方法介绍
-
JoinableQueue的实例p除了与Queue对象相同的方法之外还具有:
-
q.task_done():使用者使用此方法发出信号,表示q.get()的返回项目已经被处理。如果调用此方法的次数大于从队列中删除项目的数量,将引发ValueError异常
-
q.join():生产者调用此方法进行阻塞,直到队列中所有的项目均被处理。阻塞将持续到队列中的每个项目均调用q.task_done()方法为止,也就是队列中的数据全部被get拿走了。
-
守护进程会随着主进程的结束而结束
3.场景规划
- 1.生产者
负责产生数据(做包子的) - 2.消费者
负责处理数据(吃包子的) - 该模型需要解决并发不平衡现象
4.生产者消费者模型(搭建)
copyfrom multiprocessing import Queue, Process, JoinableQueue import time import random def producer(name, food, q): for i in range(10): print('%s 生产了 %s' % (name, food)) q.put(food) # 制造延迟(随机) time.sleep(random.random()) # 消费者 def consumer(name, q): # 开启则循环 while True: # 等待 数据 并获取 data = q.get() print('%s 吃了 %s' % (name, data)) q.task_done() # 使用者使用此方法发出信号,表示q.get()的返回项目已经被处理。 if __name__ == '__main__': # q = Queue() q = JoinableQueue() # 生产者 p1 = Process(target=producer, args=('大厨jason', '玛莎拉', q)) p2 = Process(target=producer, args=('印度阿三', '飞饼', q)) p3 = Process(target=producer, args=('泰国阿人', '榴莲', q)) c1 = Process(target=consumer, args=('阿飞', q)) p1.start() p2.start() p3.start() # 设置为守护进程(一定要放在start语句上方) c1.daemon = True c1.start() # 调整所有进程的优先级优于主进程, 这样就能保证主进程最后执行完毕, 确保生产者进程全都结束了 # 我要确保你的生产者进程结束了,生产者进程的结束标志着你生产的所有的人任务都已经被处理完了 p1.join() p2.join() p3.join() # 生产完毕,使用此方法进行阻塞,直到队列中所有项目均被处理。 q.join() # 等待队列中所有的数据被取干净 print('主')
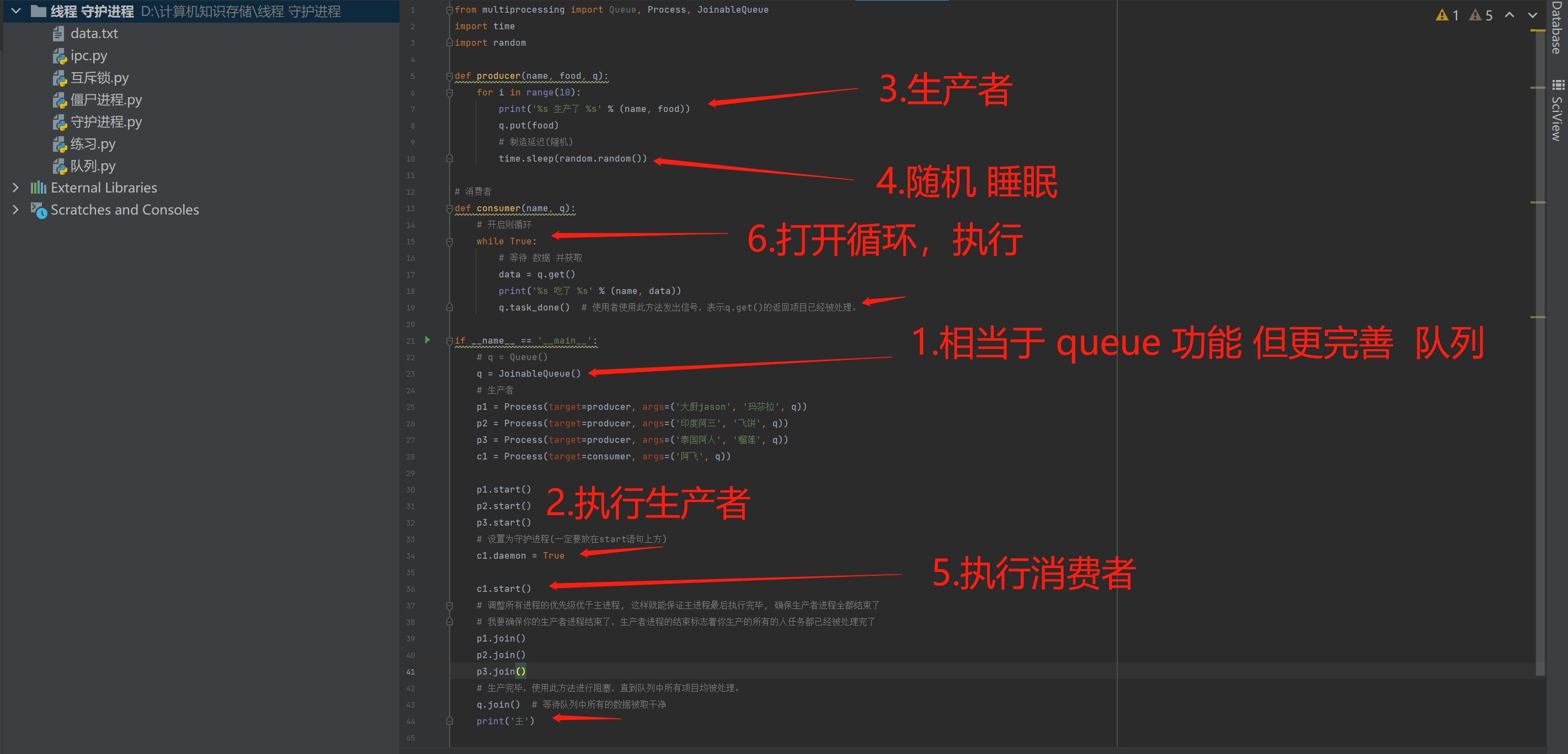
5.总结(生产者消费模型)
- 1.等待逻辑顺序:主进程等--->p1,p2,p3等---->c1
- 2.p1,p2,p3结束了,证明c1肯定全都收完了p1,p2,p3发到队列的数据
- 3.因而c1也没有存在的价值了,不需要继续阻塞在进程中影响主进程了。应该随着主进程的结束而结束,所以设置成守护进程就可以了


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步