python变量垃圾回收机制的入门使用
简介:
Python是一款高层次的解释性语言:Python对于初学者来说(易于学习)Python有相对较少的关键字,结构简单,和一个明确定义的语法,学习起来更加简单。学习Python的目的就是为了能够与计算机进行沟通\交流,在Python的语法中,每个语法存在的意义就是为了让计算机能够像人类一样直白的讲,就是让计算机具备我们人类的某一项技能。

## ### ## 一:注释的语法
1.注释的意思就是对代码的解释说明,注释不会影响程序的运行,只起到提示作用!
注释分为两种: 其中一种叫单行注释
单行注释可以加在你代码的正上方,用来对你代码做解释性的说明,#号与注释文本之间一定要有一个空格。
### ## eg:写代码要遵循代码规范
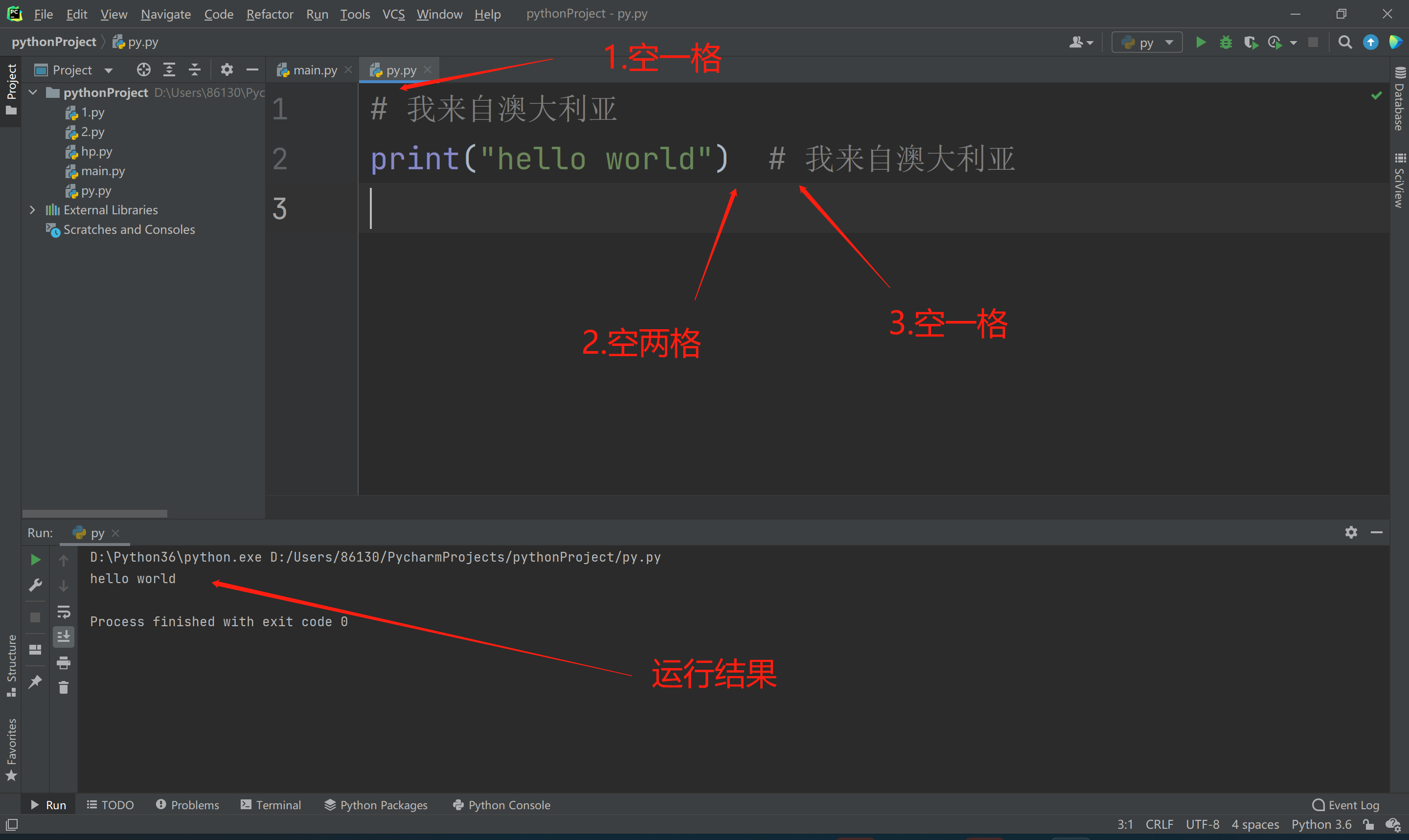
- 也可以加在你代码同一行的后方,如果单行注释跟在了一行代码的后方,需要先空两个再写,然后#号在空一格,注释对其做解释性的说明。
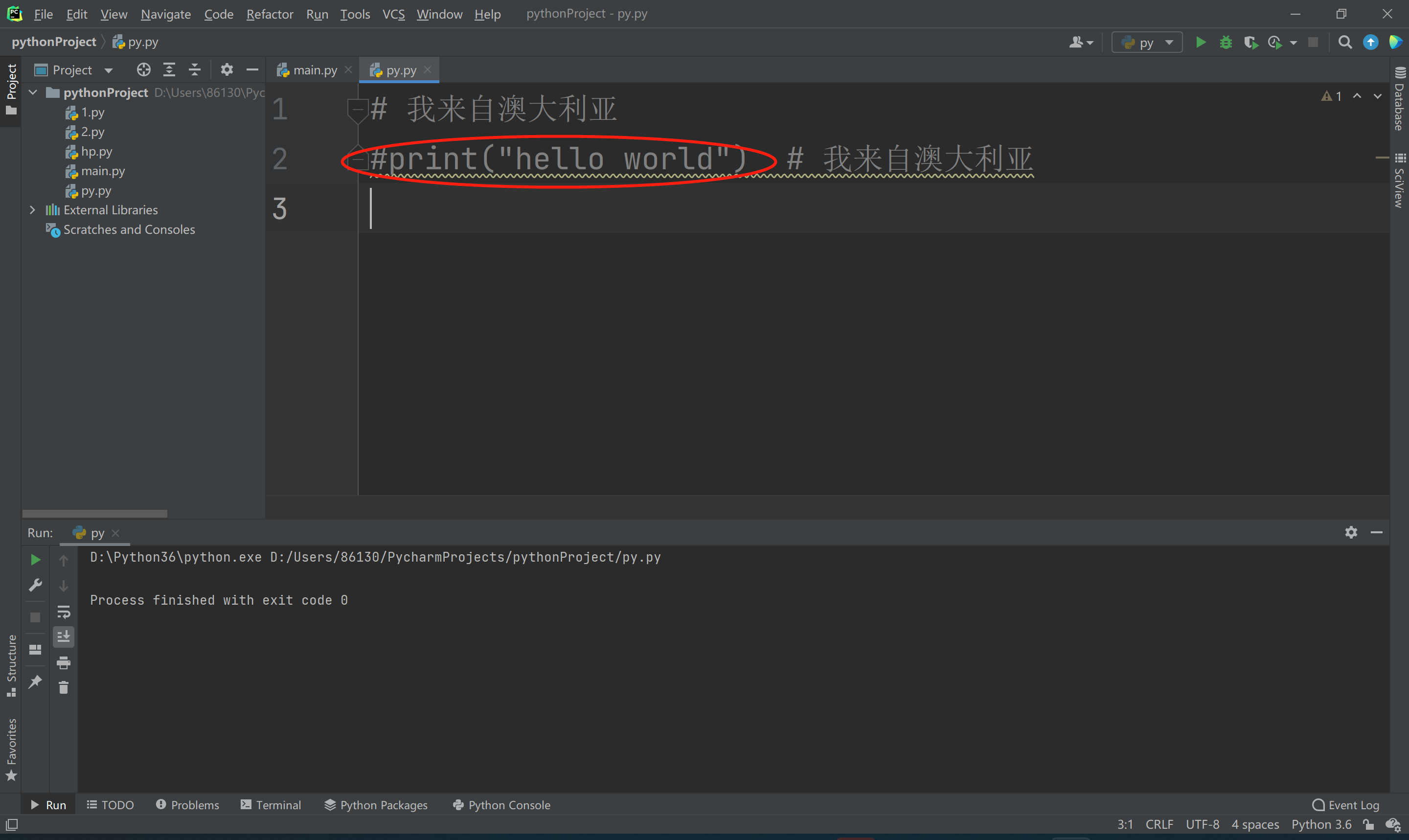
eg:pc:如果有一行代码我不想让它运行了,可以在代码前面加一个#号:如下图
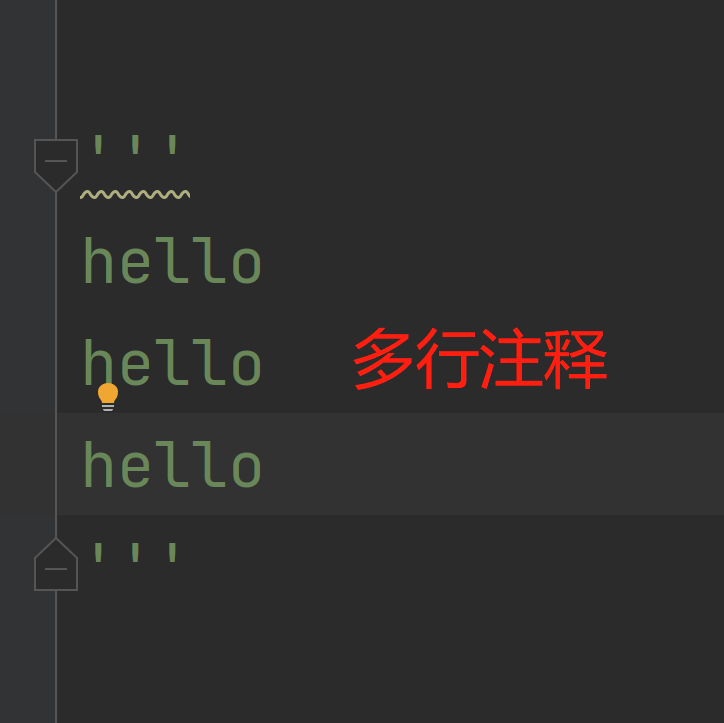
2.多行注释
可以用三对单引号,也可以是三对双引号,不会影响程序的运行,只起到提示作用
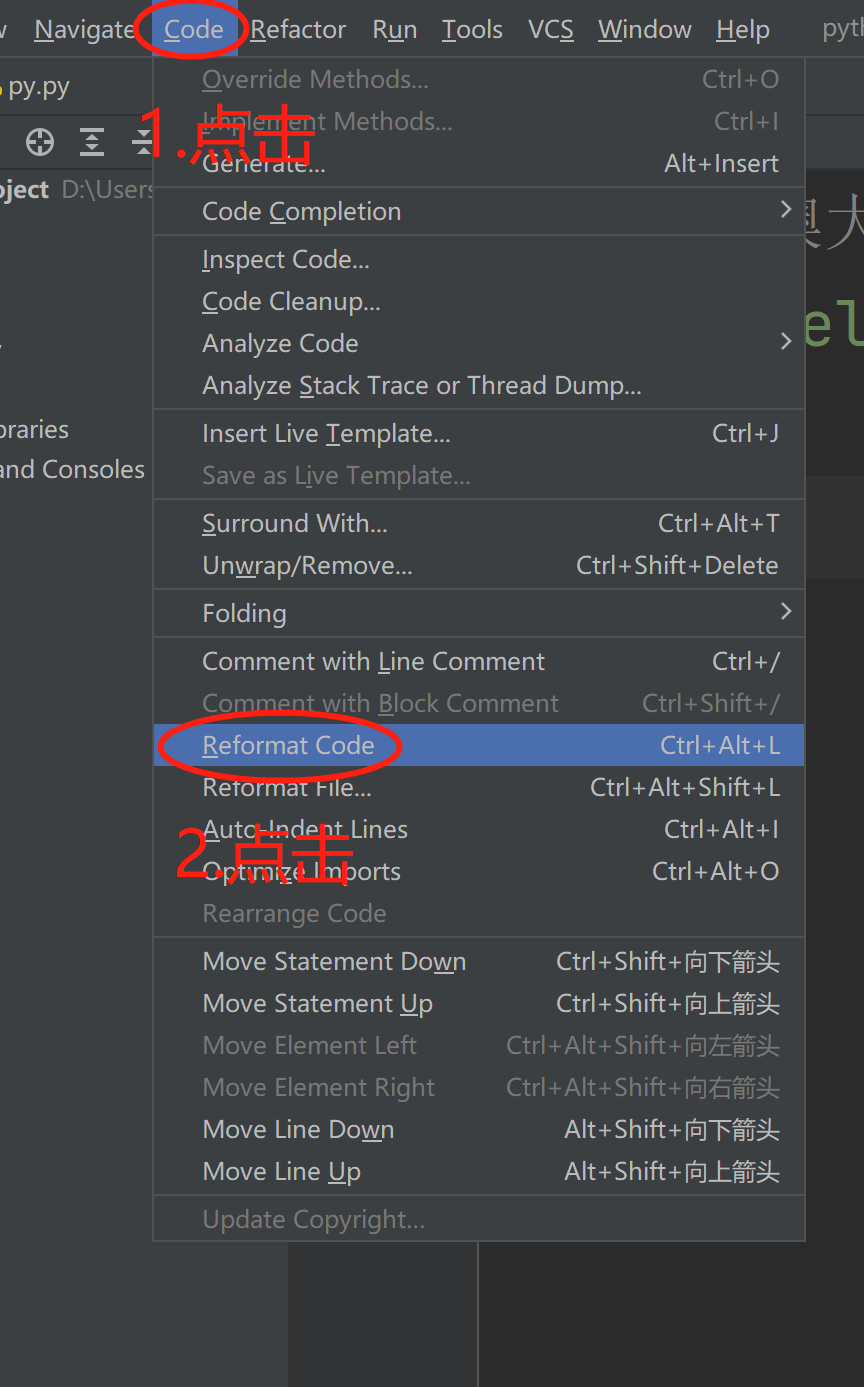
eg:pycharm也提供自动化格式代码的功能:
快捷键:Ctrl+Alt+L
eg:python代码编写规范 >>>: PEP8规范说明书 - 代码注释的原则
不用全部加注释,只需要为自己觉得重要或不好理解的部分加注释即可
注释可以用中文或英语,但不要用拼音
二:变量的定义

1.什么是变量?
变=变化
量=计量,衡量,记录事物的状态,记忆事物的状态,比如说记录人,姓名,年龄,身高体重,记录英雄的等级,记录银行卡里面的余额,记录事物的状态,是会发生变化的: 这就是变量的一种概念。
2.为何要有变量呢?
因为一定是为了让计算机具备人的某一项技能,让计算机拥有人一样记录事物的状态的这种记忆功能。但是会发生变化的,这就叫变量。
- 比如:你玩王者荣耀,刚开始是别人写好的程序,刚开始是一个英雄,自己等级是1,然后去打野升了一级,在人类看来是升了一级,但是站在程序\程序员角度,(英雄升了一级)就是“变量的变化”变量原来等于0,然后变成1,就是参数的变化,程序的运行本质就是一系列状态的变化。
3.如何使用变量
1.变量的定义分成三个部分:
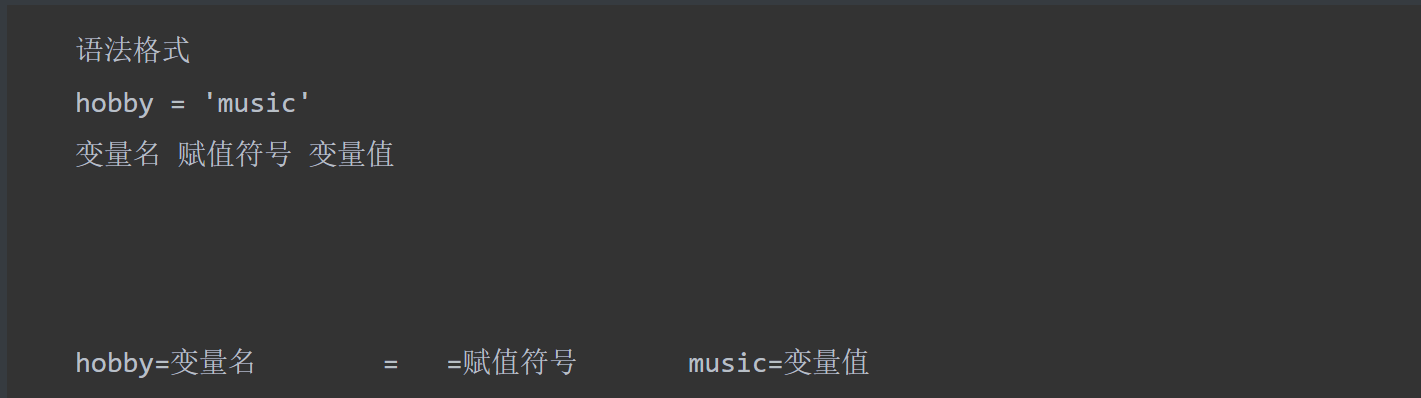
2.比喻:定义变量如下
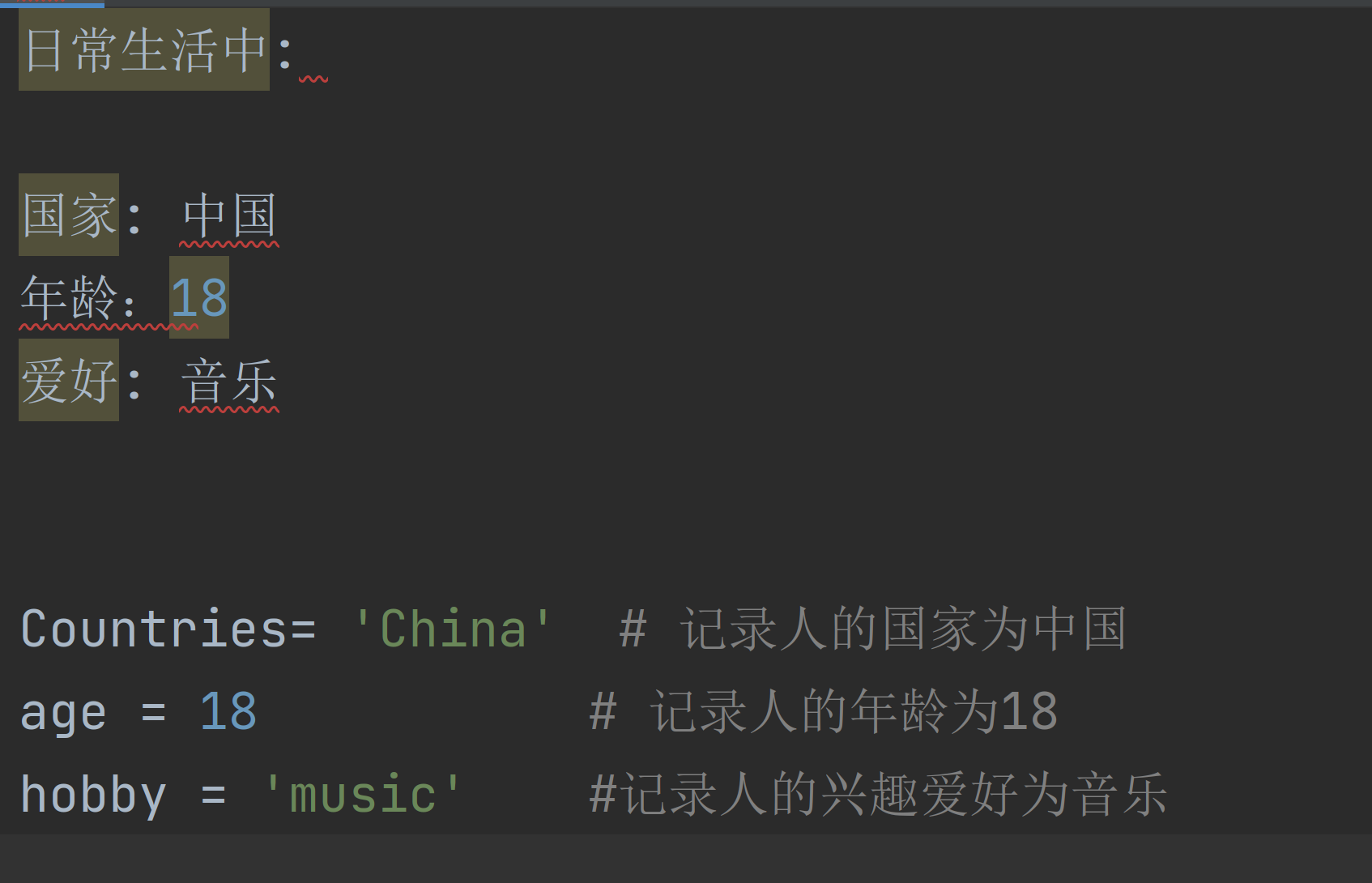
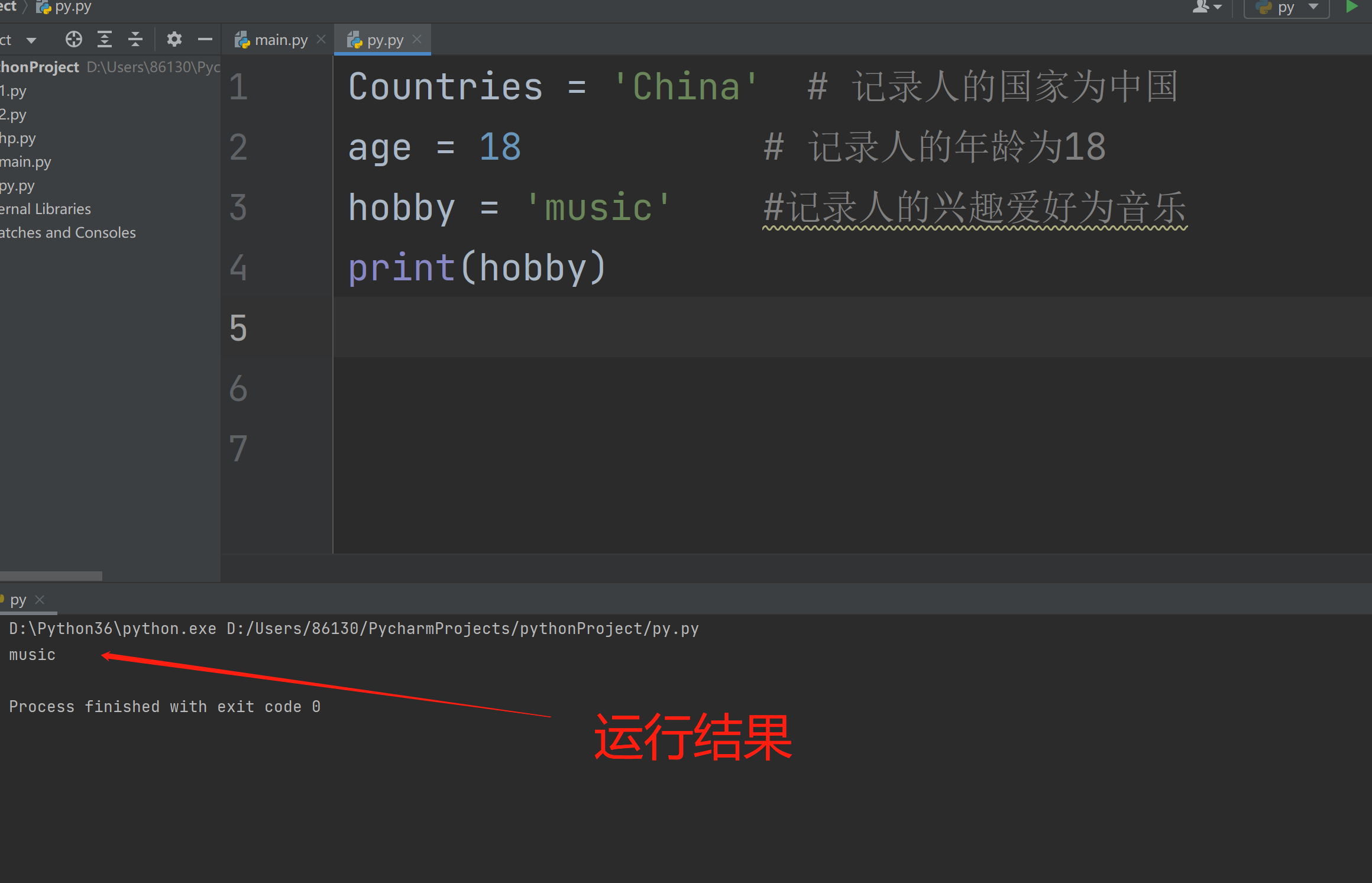
3.解释器执行到变量定义的代码时会申请内存空间存放变量值,然后将变量值的内存地址绑定给变量名,以变量的定义habby='music'为例:
定义变量申请内存 - music相当于存放到内存空间里面,存到了内存相当于人类的短期记录,'music'\变量值'相当于存到内存里面的一个(房间里面)'hobby'相当于是找到(music\变量值)的门牌号码地址。
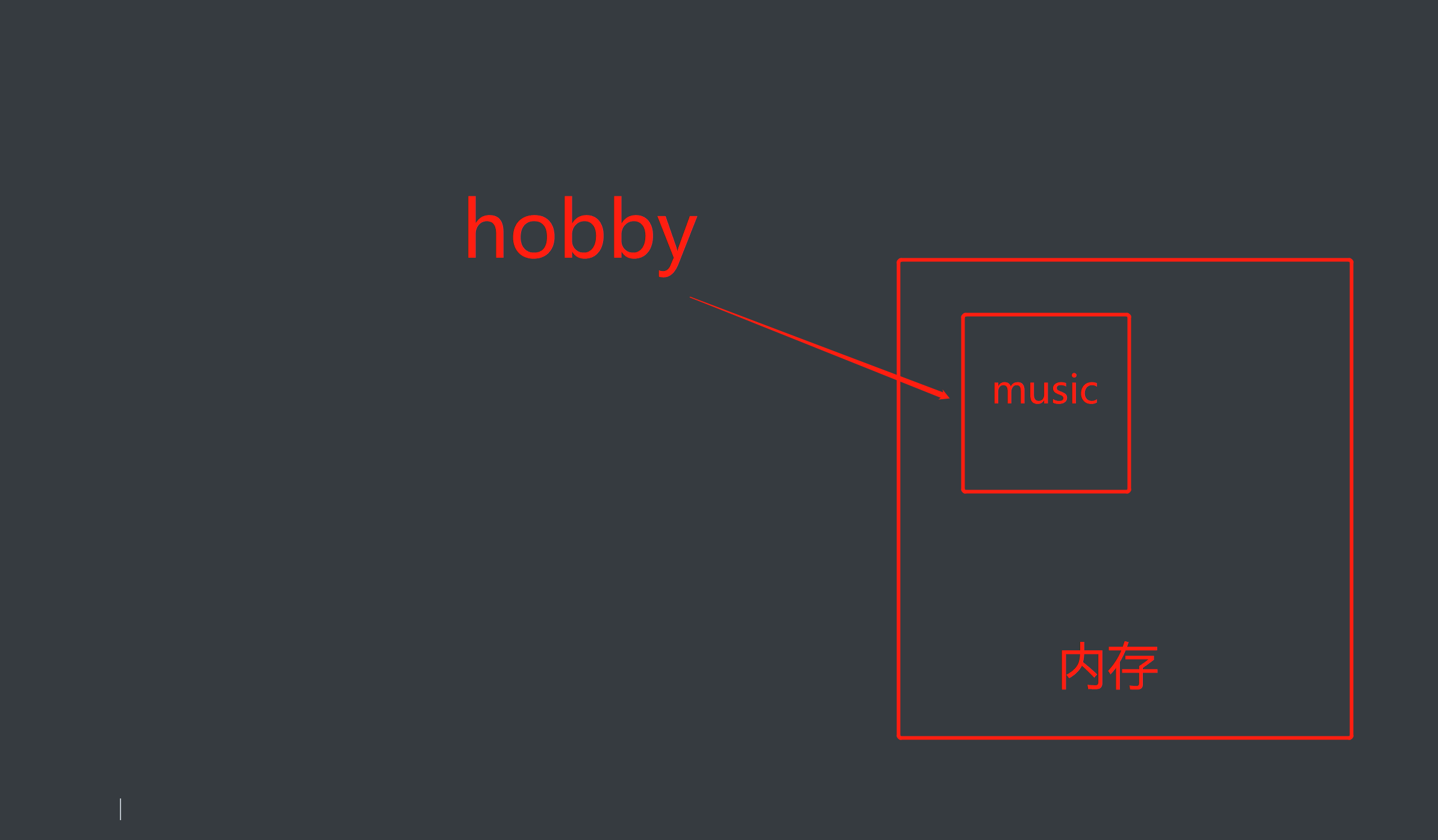
- 通过变量名即可引用到值,我们可以结合print()功能将其打印出来
- print(habby)通过变量名habby找到值music,然后执行print(music),输出\打印:music
三:变量名的命名规范
1.变量名只能是,字母,数字或下划线的任意组合
2.变量名的第一个字符不能是数字,下划线建议不要开头因为有特殊含义
3.关键字不能声明为变量名,常用关键字如下:
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from','global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
- 错误示范:
*a=123
$b=456
c$=789
2_name='lili'
123='lili'
and=123
年龄=18 # 强烈建议不要使用中文命名
4.命名风格
1.驼峰体
大驼峰 # 所有单词首字母大写
UserNameFromDb
第一首字母小写其余首字母大写
userNameFromDB
JavaScript推荐使用驼峰体
2.下划线 # 单词与单词之间下划线隔开
user_name_from_db
python推荐使用下划线"""
四:常量
1.变量就是变化的量,常量就是不变的量,主要用于记录一些不变的状态
python语法中没有常量的概念,在python定义不了常量,但是在程序开发过程中会涉及到常量的概念,我们墨守成规的将全大写的变量看成是常量
HOST = '127.0.0.1' # 一般情况下在配置文件中使用较多
在其他编程语言中存在真正意义上常量定义了就无法修改
const pi = 3.14 # 定义常量
pi = 4 # 不支持修改
四:变量三大要素
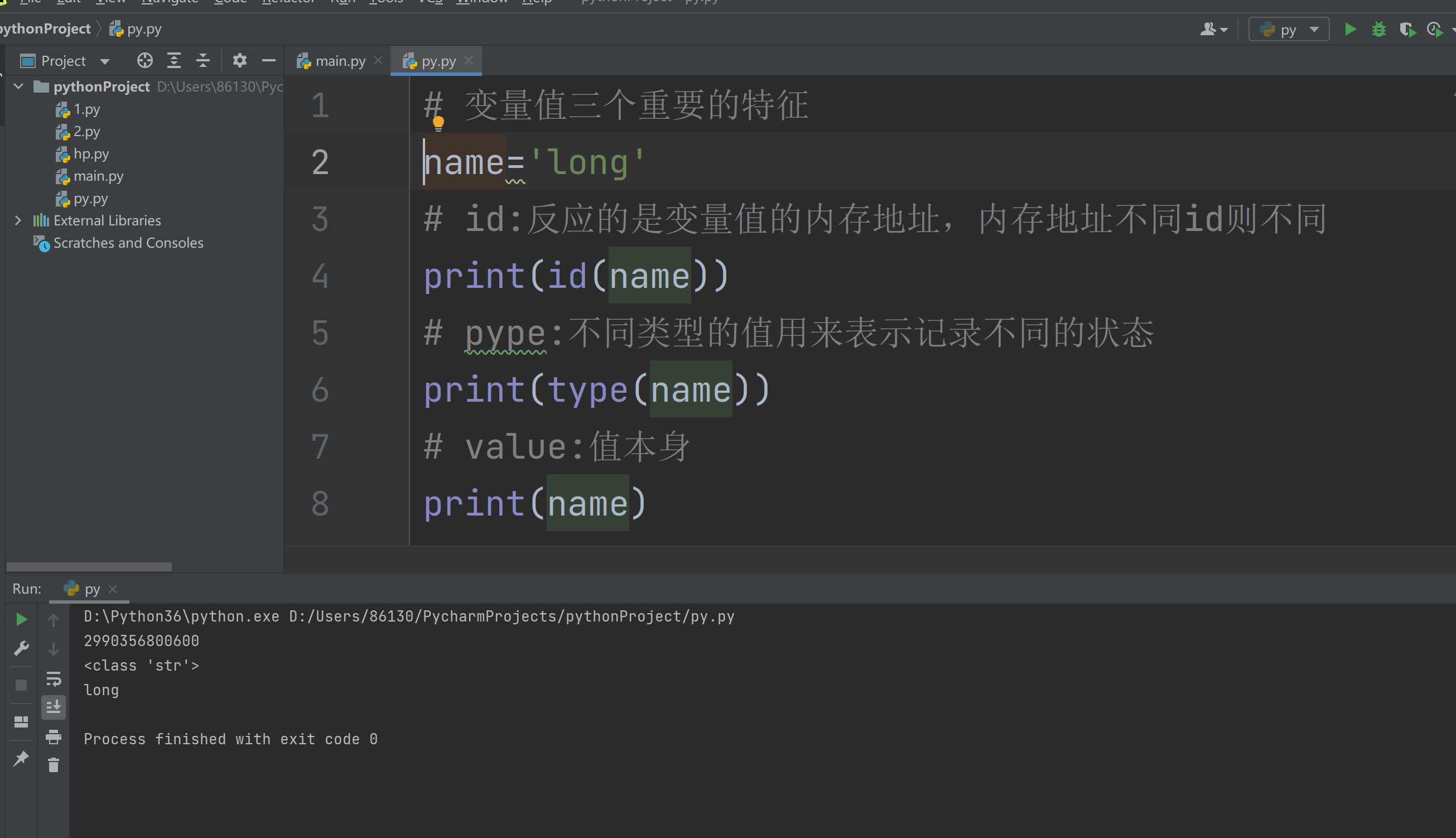
id:根据 变量值的内存地址,计算出的id号码,它不是内存地址,它是根据内存地址计算出的一串号码,可以把它想象成内存地址的一种映射,从某种程度代表了内存地址
type:事物的状态是分多种多样的 ,而变量值又是用来记录状态的,所以说,对应着,变量值也应该分多种类型,用来记录多种不同的事物状态,类型的状态。
print(name):值本身
五:python底层优化
当值数据量很小的时候 如果有多个变量名需要使用 那么会指向同一块地址
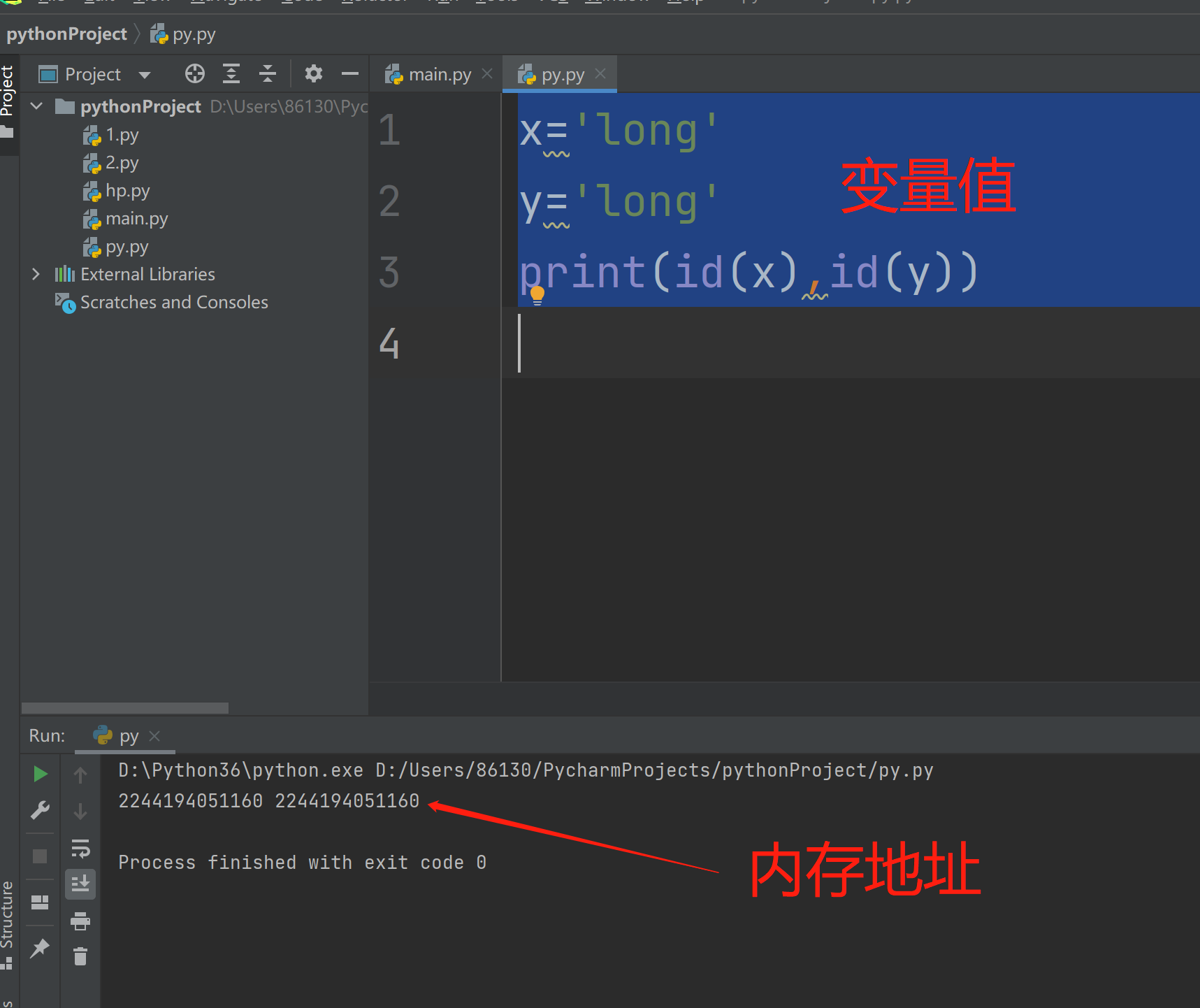
一个变量名只能指向一个内存地址
一个内存地址可以有多个变量名指向
六:垃圾回收机制
- 程序运行的过程中会申请大量的内存空间,而对于一些,无用的内存空间如果不及时清理的话会导致内存使用殆尽(内存溢出),导致程序奔溃,因此管理内存是一件重要且繁杂的事情,而python解释器自带的垃圾回收机制把程序员从繁杂的内存管理中解放出来

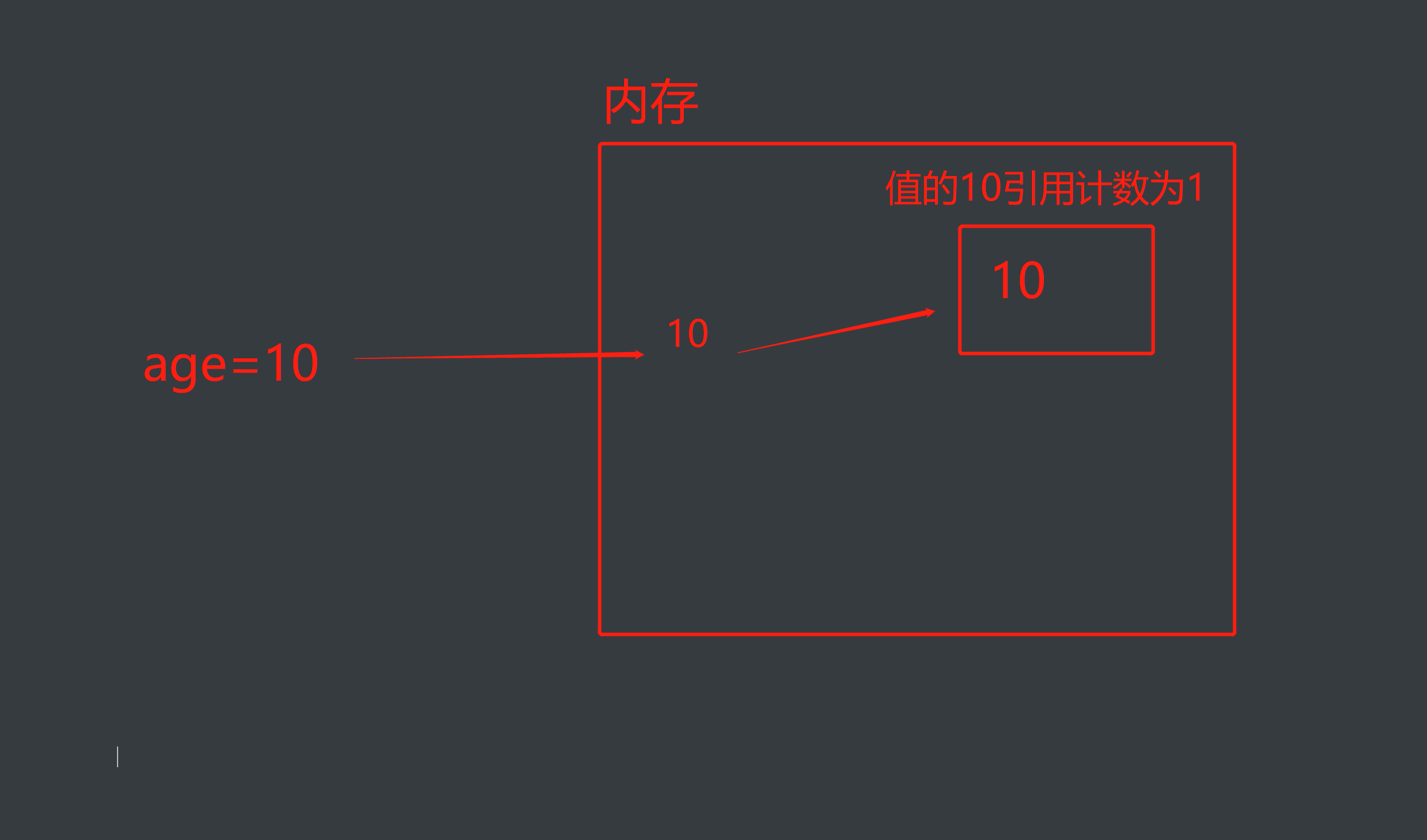
1.引用计数
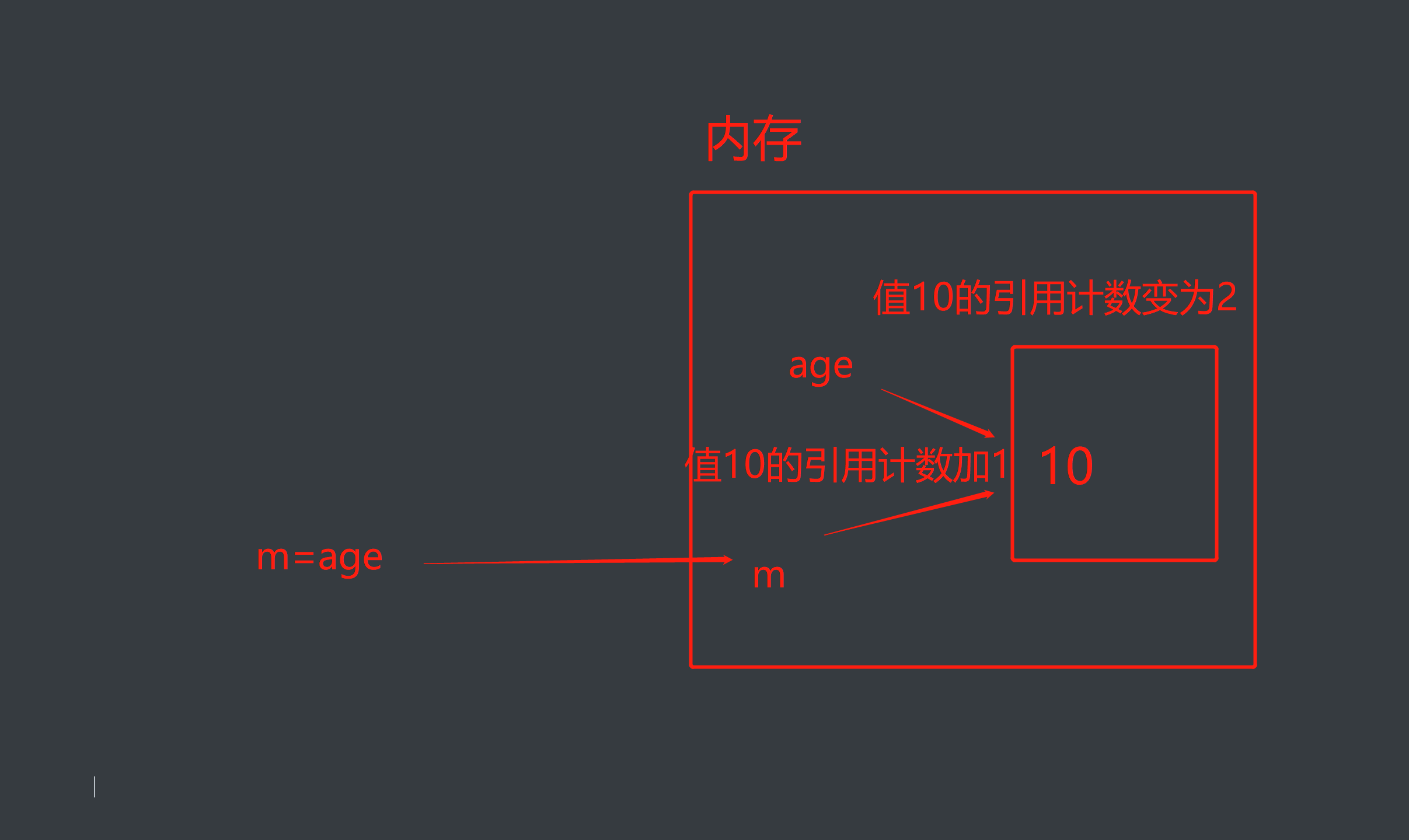
如:age=10
变量值10被关联了一个变量名age,称之为引用计数为1
引用计数增加:
age=10 (此时,变量值10的引用计数为1)
m=age (把age的内存地址给了m,此时,m,age都关联了10,所以变量值10的引用计数为2)
引用计数减少:
age=8(名字age先与值10解除关联,再与3建立了关联,变量值10的引用计数为1)
del m(del的意思是解除变量名x与变量值10的关联关系,此时,变量10的引用计数为0)
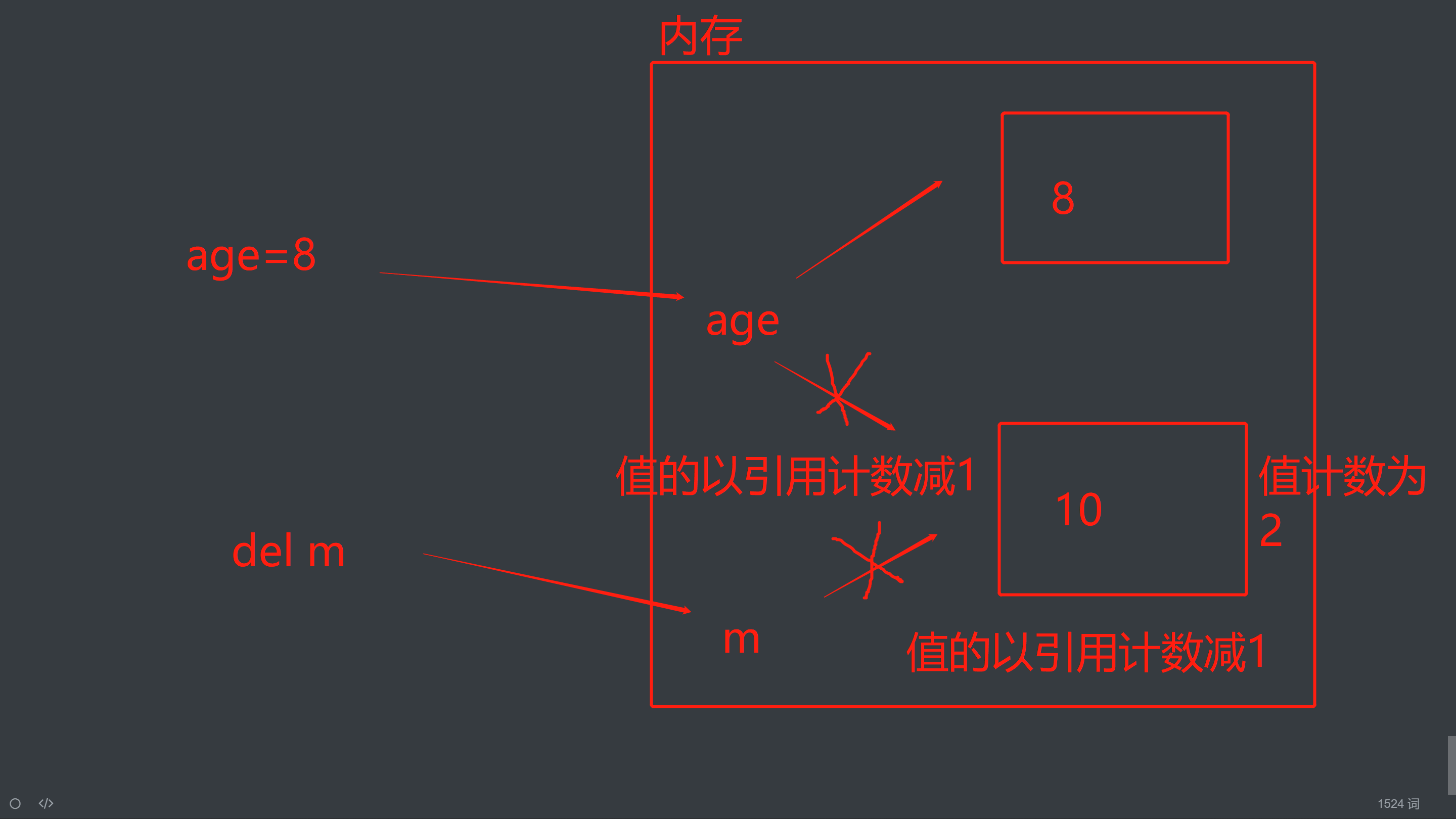
值18的引用计数一旦变为0,其占用的内存地址就应该被解释器的垃圾回收机制回收
2.标记清除
当内存即将沾满的时候 python会自动暂停程序的执行 从头到尾将内存中数据进行扫描
并打上标记 之后一次性清除掉标记的数据
3.分代回收
基于引用计数的回收机制,每次回收内存,都需要把所有对象的引用计数都遍历一遍,这是非常消耗时间的,于是引入了分代回收来提高回收效率,分代回收采用的是用“空间换时间”的策略
分代:
分代回收的核心思想是:在历经多次扫描的情况下,都没有被回收的变量,gc机制就会认为,该变量是常用变量,gc对其扫描的频率会降低,具体实现原理如下:

回收:
回收依然是使用引用计数作为回收的依据

虽然分代回收可以起到提升效率的效果,但也存在一定的缺点:
例如一个变量刚刚从新生代移入青春代,该变量的绑定关系就解除了,该变量应该被回收,但青春代的扫描频率低于新生代,所以该变量的回收就会被延迟。

