使用 Lucene.Net 进行全文索引,支持中文
2013-04-19 10:47 音乐让我说 阅读(1554) 评论(0) 编辑 收藏 举报Lucene.Net 对中文的支持不好这是不争的事实,即使能对中文分词也只是两两组合,即比如说一个字符串“我爱博客园,我爱编程”,那么使用 Lucene.Net 分词后变成 下面这些词:
我爱
爱博
博客
客园
我爱
爱编
编程
个人建议还是用 Lucene.Net 搭配 盘古 或其它开源组件来分词,毕竟 Lucene.Net 不懂中文,没有比较全的词库。可惜盘古最近不怎么更新了,最后一次更新还是 2010-08-18 号,也不知道是什么原因,我只知道最新版的 Lucene.Net (版本是:Lucene.Net 3.0.3)不能使用盘古最新的版本,只能用盘古最新版所搭配的 Lucene.Net,具体的可以去下载最新版的盘古,里面有示例代码,自己好好研究一下。
下面我贴出 Lucene.Net 所带的中文 Analysis,不过不是我自己写的,也是网上找的,大家看看就好。
解决方案:
Lucene.Net.Analysis.CJK 项目下的类 CJKAnalyzer.cs 和 CJKTokenizer.cs 代码分别如下:
 View Code
View Code

using System; using System.IO; using System.Collections; using Lucene.Net.Analysis; namespace Lucene.Net.Analysis.CJK { /* ==================================================================== * The Apache Software License, Version 1.1 * * Copyright (c) 2004 The Apache Software Foundation. All rights * reserved. * * Redistribution and use in source and binary forms, with or without * modification, are permitted provided that the following conditions * are met: * * 1. Redistributions of source code must retain the above copyright * notice, this list of conditions and the following disclaimer. * * 2. Redistributions in binary form must reproduce the above copyright * notice, this list of conditions and the following disclaimer in * the documentation and/or other materials provided with the * distribution. * * 3. The end-user documentation included with the redistribution, * if any, must include the following acknowledgment: * "This product includes software developed by the * Apache Software Foundation (http://www.apache.org/)." * Alternately, this acknowledgment may appear in the software itself, * if and wherever such third-party acknowledgments normally appear. * * 4. The names "Apache" and "Apache Software Foundation" and * "Apache Lucene" must not be used to endorse or promote products * derived from this software without prior written permission. For * written permission, please contact apache@apache.org. * * 5. Products derived from this software may not be called "Apache", * "Apache Lucene", nor may "Apache" appear in their name, without * prior written permission of the Apache Software Foundation. * * THIS SOFTWARE IS PROVIDED ``AS IS'' AND ANY EXPRESSED OR IMPLIED * WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES * OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE * DISCLAIMED. IN NO EVENT SHALL THE APACHE SOFTWARE FOUNDATION OR * ITS CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, * SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT * LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF * USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND * ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, * OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT * OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF * SUCH DAMAGE. * ==================================================================== * * This software consists of voluntary contributions made by many * individuals on behalf of the Apache Software Foundation. For more * information on the Apache Software Foundation, please see * <http://www.apache.org/>. * * $Id: CJKAnalyzer.java,v 1.2 2004/01/22 20:54:47 ehatcher Exp $ */ /// <summary> /// Filters CJKTokenizer with StopFilter. /// /// @author Che, Dong /// </summary> public class CJKAnalyzer : Analyzer { //~ Static fields/initializers --------------------------------------------- /** * An array containing some common English words that are not usually * useful for searching. and some double-byte interpunctions..... */ private static String[] stopWords = { "a", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it", "no", "not", "of", "on", "or", "s", "such", "t", "that", "the", "their", "then", "there", "these", "they", "this", "to", "was", "will", "with", "", "www" }; //~ Instance fields -------------------------------------------------------- /** stop word list */ private Hashtable stopTable; //~ Constructors ----------------------------------------------------------- /// <summary> /// Builds an analyzer which removes words in STOP_WORDS. /// </summary> public CJKAnalyzer() { stopTable = StopFilter.MakeStopTable(stopWords); } /// <summary> /// Builds an analyzer which removes words in the provided array. /// </summary> /// <param name="stopWords">stop word array</param> public CJKAnalyzer(String[] stopWords) { stopTable = StopFilter.MakeStopTable(stopWords); } //~ Methods ---------------------------------------------------------------- /// <summary> /// get token stream from input /// </summary> /// <param name="fieldName">lucene field name</param> /// <param name="reader">input reader</param> /// <returns>Token Stream</returns> public override sealed TokenStream TokenStream(String fieldName, TextReader reader) { return new StopFilter(new CJKTokenizer(reader), stopTable); } } }
View Code
using System; using System.IO; using System.Text; using Lucene.Net.Analysis; namespace Lucene.Net.Analysis.CJK { /* ==================================================================== * The Apache Software License, Version 1.1 * * Copyright (c) 2004 The Apache Software Foundation. All rights * reserved. * * Redistribution and use in source and binary forms, with or without * modification, are permitted provided that the following conditions * are met: * * 1. Redistributions of source code must retain the above copyright * notice, this list of conditions and the following disclaimer. * * 2. Redistributions in binary form must reproduce the above copyright * notice, this list of conditions and the following disclaimer in * the documentation and/or other materials provided with the * distribution. * * 3. The end-user documentation included with the redistribution, * if any, must include the following acknowledgment: * "This product includes software developed by the * Apache Software Foundation (http://www.apache.org/)." * Alternately, this acknowledgment may appear in the software itself, * if and wherever such third-party acknowledgments normally appear. * * 4. The names "Apache" and "Apache Software Foundation" and * "Apache Lucene" must not be used to endorse or promote products * derived from this software without prior written permission. For * written permission, please contact apache@apache.org. * * 5. Products derived from this software may not be called "Apache", * "Apache Lucene", nor may "Apache" appear in their name, without * prior written permission of the Apache Software Foundation. * * THIS SOFTWARE IS PROVIDED ``AS IS'' AND ANY EXPRESSED OR IMPLIED * WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES * OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE * DISCLAIMED. IN NO EVENT SHALL THE APACHE SOFTWARE FOUNDATION OR * ITS CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, * SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT * LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF * USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND * ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, * OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT * OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF * SUCH DAMAGE. * ==================================================================== * * This software consists of voluntary contributions made by many * individuals on behalf of the Apache Software Foundation. For more * information on the Apache Software Foundation, please see * <http://www.apache.org/>. */ /// <summary> /// <p> /// CJKTokenizer was modified from StopTokenizer which does a decent job for /// most European languages. and it perferm other token method for double-byte /// Characters: the token will return at each two charactors with overlap match.<br> /// Example: "java C1C2C3C4" will be segment to: "java" "C1C2" "C2C3" "C3C4" it /// also need filter filter zero length token ""<br> /// for Digit: digit, '+', '#' will token as letter<br> /// for more info on Asia language(Chinese Japanese Korean) text segmentation: /// please search <a /// href="http://www.google.com/search?q=word+chinese+segment">google</a> /// </p> /// /// @author Che, Dong /// @version $Id: CJKTokenizer.java,v 1.3 2003/01/22 20:54:47 otis Exp $ /// </summary> public sealed class CJKTokenizer : Tokenizer { //~ Static fields/initializers --------------------------------------------- /** Max word length */ private static int MAX_WORD_LEN = 255; /** buffer size: */ private static int IO_BUFFER_SIZE = 256; //~ Instance fields -------------------------------------------------------- /** word offset, used to imply which character(in ) is parsed */ private int offset = 0; /** the index used only for ioBuffer */ private int bufferIndex = 0; /** data length */ private int dataLen = 0; /** * character buffer, store the characters which are used to compose <br> * the returned Token */ private char[] buffer = new char[MAX_WORD_LEN]; /** * I/O buffer, used to store the content of the input(one of the <br> * members of Tokenizer) */ private char[] ioBuffer = new char[IO_BUFFER_SIZE]; /** word type: single=>ASCII double=>non-ASCII word=>default */ private String tokenType = "word"; /** * tag: previous character is a cached double-byte character "C1C2C3C4" * ----(set the C1 isTokened) C1C2 "C2C3C4" ----(set the C2 isTokened) * C1C2 C2C3 "C3C4" ----(set the C3 isTokened) "C1C2 C2C3 C3C4" */ private bool preIsTokened = false; //~ Constructors ----------------------------------------------------------- /// <summary> /// Construct a token stream processing the given input. /// </summary> /// <param name="_in">I/O reader</param> public CJKTokenizer(TextReader _in) { input = _in; } //~ Methods ---------------------------------------------------------------- /// <summary> /// Returns the next token in the stream, or null at EOS. /// </summary> /// <returns>Token</returns> public override Token Next() { /** how many character(s) has been stored in buffer */ int length = 0; /** the position used to create Token */ int start = offset; while (true) { /** current charactor */ char c; /** unicode block of current charactor for detail */ //Character.UnicodeBlock ub; offset++; if (bufferIndex >= dataLen) { dataLen = input.Read(ioBuffer, 0, ioBuffer.Length); bufferIndex = 0; } if (dataLen == -1) { if (length > 0) { if (preIsTokened == true) { length = 0; preIsTokened = false; } break; } else { return null; } } else { //get current character c = ioBuffer[bufferIndex++]; //get the UnicodeBlock of the current character //ub = Character.UnicodeBlock.of(c); } //if the current character is ASCII or Extend ASCII if (('\u0000' <= c && c <= '\u007F') || ('\uFF00' <= c && c <= '\uFFEF')) { if ('\uFF00' <= c && c <= '\uFFEF') { /** convert HALFWIDTH_AND_FULLWIDTH_FORMS to BASIC_LATIN */ int i = (int) c; i = i - 65248; c = (char) i; } // if the current character is a letter or "_" "+" "#" if (Char.IsLetterOrDigit(c) || ((c == '_') || (c == '+') || (c == '#')) ) { if (length == 0) { // "javaC1C2C3C4linux" <br> // ^--: the current character begin to token the ASCII // letter start = offset - 1; } else if (tokenType == "double") { // "javaC1C2C3C4linux" <br> // ^--: the previous non-ASCII // : the current character offset--; bufferIndex--; tokenType = "single"; if (preIsTokened == true) { // there is only one non-ASCII has been stored length = 0; preIsTokened = false; break; } else { break; } } // store the LowerCase(c) in the buffer buffer[length++] = Char.ToLower(c); tokenType = "single"; // break the procedure if buffer overflowed! if (length == MAX_WORD_LEN) { break; } } else if (length > 0) { if (preIsTokened == true) { length = 0; preIsTokened = false; } else { break; } } } else { // non-ASCII letter, eg."C1C2C3C4" if (Char.IsLetter(c)) { if (length == 0) { start = offset - 1; buffer[length++] = c; tokenType = "double"; } else { if (tokenType == "single") { offset--; bufferIndex--; //return the previous ASCII characters break; } else { buffer[length++] = c; tokenType = "double"; if (length == 2) { offset--; bufferIndex--; preIsTokened = true; break; } } } } else if (length > 0) { if (preIsTokened == true) { // empty the buffer length = 0; preIsTokened = false; } else { break; } } } } return new Token(new String(buffer, 0, length), start, start + length, tokenType ); } } }
Lucene.Net.Analysis.Cn 项目下的类 ChineseAnalyzer.cs 和 ChineseFilter.cs 和 ChineseTokenizer.cs 代码分别如下:
View Code
using System; using System.IO; using System.Text; using System.Collections; using Lucene.Net.Analysis; namespace Lucene.Net.Analysis.Cn { /* ==================================================================== * The Apache Software License, Version 1.1 * * Copyright (c) 2004 The Apache Software Foundation. All rights * reserved. * * Redistribution and use in source and binary forms, with or without * modification, are permitted provided that the following conditions * are met: * * 1. Redistributions of source code must retain the above copyright * notice, this list of conditions and the following disclaimer. * * 2. Redistributions in binary form must reproduce the above copyright * notice, this list of conditions and the following disclaimer in * the documentation and/or other materials provided with the * distribution. * * 3. The end-user documentation included with the redistribution, * if any, must include the following acknowledgment: * "This product includes software developed by the * Apache Software Foundation (http://www.apache.org/)." * Alternately, this acknowledgment may appear in the software itself, * if and wherever such third-party acknowledgments normally appear. * * 4. The names "Apache" and "Apache Software Foundation" and * "Apache Lucene" must not be used to endorse or promote products * derived from this software without prior written permission. For * written permission, please contact apache@apache.org. * * 5. Products derived from this software may not be called "Apache", * "Apache Lucene", nor may "Apache" appear in their name, without * prior written permission of the Apache Software Foundation. * * THIS SOFTWARE IS PROVIDED ``AS IS'' AND ANY EXPRESSED OR IMPLIED * WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES * OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE * DISCLAIMED. IN NO EVENT SHALL THE APACHE SOFTWARE FOUNDATION OR * ITS CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, * SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT * LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF * USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND * ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, * OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT * OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF * SUCH DAMAGE. * ==================================================================== * * This software consists of voluntary contributions made by many * individuals on behalf of the Apache Software Foundation. For more * information on the Apache Software Foundation, please see * <http://www.apache.org/>. */ /// <summary> /// Title: ChineseAnalyzer /// Description: /// Subclass of org.apache.lucene.analysis.Analyzer /// build from a ChineseTokenizer, filtered with ChineseFilter. /// Copyright: Copyright (c) 2001 /// Company: /// @author Yiyi Sun /// @version $Id: ChineseAnalyzer.java, v 1.2 2003/01/22 20:54:47 ehatcher Exp $ /// </summary> public class ChineseAnalyzer : Analyzer { public ChineseAnalyzer() { } /// <summary> /// Creates a TokenStream which tokenizes all the text in the provided Reader. /// </summary> /// <returns>A TokenStream build from a ChineseTokenizer filtered with ChineseFilter.</returns> public override sealed TokenStream TokenStream(String fieldName, TextReader reader) { TokenStream result = new ChineseTokenizer(reader); result = new ChineseFilter(result); return result; } } }
View Code
using System; using System.IO; using System.Collections; using System.Globalization; using Lucene.Net.Analysis; namespace Lucene.Net.Analysis.Cn { /* ==================================================================== * The Apache Software License, Version 1.1 * * Copyright (c) 2004 The Apache Software Foundation. All rights * reserved. * * Redistribution and use in source and binary forms, with or without * modification, are permitted provided that the following conditions * are met: * * 1. Redistributions of source code must retain the above copyright * notice, this list of conditions and the following disclaimer. * * 2. Redistributions in binary form must reproduce the above copyright * notice, this list of conditions and the following disclaimer in * the documentation and/or other materials provided with the * distribution. * * 3. The end-user documentation included with the redistribution, * if any, must include the following acknowledgment: * "This product includes software developed by the * Apache Software Foundation (http://www.apache.org/)." * Alternately, this acknowledgment may appear in the software itself, * if and wherever such third-party acknowledgments normally appear. * * 4. The names "Apache" and "Apache Software Foundation" and * "Apache Lucene" must not be used to endorse or promote products * derived from this software without prior written permission. For * written permission, please contact apache@apache.org. * * 5. Products derived from this software may not be called "Apache", * "Apache Lucene", nor may "Apache" appear in their name, without * prior written permission of the Apache Software Foundation. * * THIS SOFTWARE IS PROVIDED ``AS IS'' AND ANY EXPRESSED OR IMPLIED * WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES * OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE * DISCLAIMED. IN NO EVENT SHALL THE APACHE SOFTWARE FOUNDATION OR * ITS CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, * SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT * LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF * USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND * ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, * OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT * OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF * SUCH DAMAGE. * ==================================================================== * * This software consists of voluntary contributions made by many * individuals on behalf of the Apache Software Foundation. For more * information on the Apache Software Foundation, please see * <http://www.apache.org/>. */ /// <summary> /// Title: ChineseFilter /// Description: Filter with a stop word table /// Rule: No digital is allowed. /// English word/token should larger than 1 character. /// One Chinese character as one Chinese word. /// TO DO: /// 1. Add Chinese stop words, such as \ue400 /// 2. Dictionary based Chinese word extraction /// 3. Intelligent Chinese word extraction /// /// Copyright: Copyright (c) 2001 /// Company: /// @author Yiyi Sun /// @version $Id: ChineseFilter.java, v 1.4 2003/01/23 12:49:33 ehatcher Exp $ /// </summary> public sealed class ChineseFilter : TokenFilter { // Only English now, Chinese to be added later. public static String[] STOP_WORDS = { "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it", "no", "not", "of", "on", "or", "such", "that", "the", "their", "then", "there", "these", "they", "this", "to", "was", "will", "with" }; private Hashtable stopTable; public ChineseFilter(TokenStream _in) : base (_in) { stopTable = new Hashtable(STOP_WORDS.Length); for (int i = 0; i < STOP_WORDS.Length; i++) stopTable[STOP_WORDS[i]] = STOP_WORDS[i]; } public override Token Next() { for (Token token = input.Next(); token != null; token = input.Next()) { String text = token.TermText(); // why not key off token type here assuming ChineseTokenizer comes first? if (stopTable[text] == null) { switch (Char.GetUnicodeCategory(text[0])) { case UnicodeCategory.LowercaseLetter: case UnicodeCategory.UppercaseLetter: // English word/token should larger than 1 character. if (text.Length > 1) { return token; } break; case UnicodeCategory.OtherLetter: // One Chinese character as one Chinese word. // Chinese word extraction to be added later here. return token; } } } return null; } } }
View Code
using System; using System.IO; using System.Text; using System.Collections; using System.Globalization; using Lucene.Net.Analysis; namespace Lucene.Net.Analysis.Cn { /* ==================================================================== * The Apache Software License, Version 1.1 * * Copyright (c) 2004 The Apache Software Foundation. All rights * reserved. * * Redistribution and use in source and binary forms, with or without * modification, are permitted provided that the following conditions * are met: * * 1. Redistributions of source code must retain the above copyright * notice, this list of conditions and the following disclaimer. * * 2. Redistributions in binary form must reproduce the above copyright * notice, this list of conditions and the following disclaimer in * the documentation and/or other materials provided with the * distribution. * * 3. The end-user documentation included with the redistribution, * if any, must include the following acknowledgment: * "This product includes software developed by the * Apache Software Foundation (http://www.apache.org/)." * Alternately, this acknowledgment may appear in the software itself, * if and wherever such third-party acknowledgments normally appear. * * 4. The names "Apache" and "Apache Software Foundation" and * "Apache Lucene" must not be used to endorse or promote products * derived from this software without prior written permission. For * written permission, please contact apache@apache.org. * * 5. Products derived from this software may not be called "Apache", * "Apache Lucene", nor may "Apache" appear in their name, without * prior written permission of the Apache Software Foundation. * * THIS SOFTWARE IS PROVIDED ``AS IS'' AND ANY EXPRESSED OR IMPLIED * WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES * OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE * DISCLAIMED. IN NO EVENT SHALL THE APACHE SOFTWARE FOUNDATION OR * ITS CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, * SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT * LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF * USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND * ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, * OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT * OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF * SUCH DAMAGE. * ==================================================================== * * This software consists of voluntary contributions made by many * individuals on behalf of the Apache Software Foundation. For more * information on the Apache Software Foundation, please see * <http://www.apache.org/>. */ /** * Title: ChineseTokenizer * Description: Extract tokens from the Stream using Character.getType() * Rule: A Chinese character as a single token * Copyright: Copyright (c) 2001 * Company: * * The difference between thr ChineseTokenizer and the * CJKTokenizer (id=23545) is that they have different * token parsing logic. * * Let me use an example. If having a Chinese text * "C1C2C3C4" to be indexed, the tokens returned from the * ChineseTokenizer are C1, C2, C3, C4. And the tokens * returned from the CJKTokenizer are C1C2, C2C3, C3C4. * * Therefore the index the CJKTokenizer created is much * larger. * * The problem is that when searching for C1, C1C2, C1C3, * C4C2, C1C2C3 ... the ChineseTokenizer works, but the * CJKTokenizer will not work. * * @author Yiyi Sun * @version $Id: ChineseTokenizer.java, v 1.4 2003/03/02 13:56:03 otis Exp $ * */ public sealed class ChineseTokenizer : Tokenizer { public ChineseTokenizer(TextReader _in) { input = _in; } private int offset = 0, bufferIndex=0, dataLen=0; private static int MAX_WORD_LEN = 255; private static int IO_BUFFER_SIZE = 1024; private char[] buffer = new char[MAX_WORD_LEN]; private char[] ioBuffer = new char[IO_BUFFER_SIZE]; private int length; private int start; private void Push(char c) { if (length == 0) start = offset-1; // start of token buffer[length++] = Char.ToLower(c); // buffer it } private Token Flush() { if (length > 0) { //System.out.println(new String(buffer, 0, length)); return new Token(new String(buffer, 0, length), start, start+length); } else return null; } public override Token Next() { length = 0; start = offset; while (true) { char c; offset++; if (bufferIndex >= dataLen) { dataLen = input.Read(ioBuffer, 0, ioBuffer.Length); bufferIndex = 0; }; if (dataLen == -1) return Flush(); else c = ioBuffer[bufferIndex++]; switch(Char.GetUnicodeCategory(c)) { case UnicodeCategory.DecimalDigitNumber: case UnicodeCategory.LowercaseLetter: case UnicodeCategory.UppercaseLetter: Push(c); if (length == MAX_WORD_LEN) return Flush(); break; case UnicodeCategory.OtherLetter: if (length>0) { bufferIndex--; return Flush(); } Push(c); return Flush(); default: if (length>0) return Flush(); break; } } } } }
Program.cs 的代码如下:
View Code
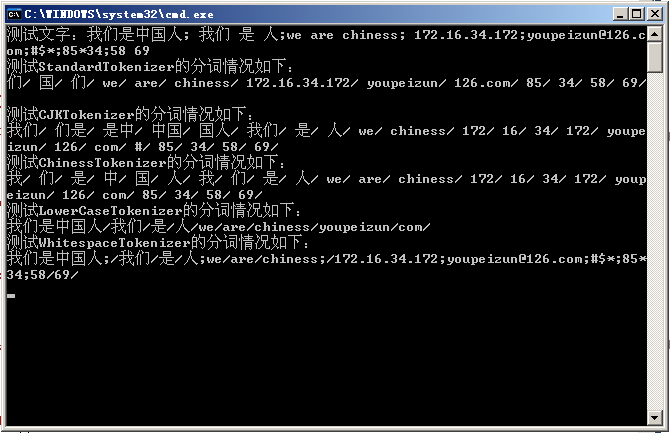
using System; using System.Collections.Generic; using System.Text; using Lucene.Net.Analysis.Standard; using Lucene.Net.Analysis; using Lucene.Net.Index; using Lucene.Net.Documents; using System.IO; using Lucene.Net.Analysis.Cn; using Lucene.Net.Analysis.CJK; //date:11-02-2007 //home page:http://www.cnblogs.com/xuanfeng //author:peizunyou namespace DearBruce.LuceneSimpleChineses.ConApp { class TokenizerTest { static void Main(string[] args) { string testText = "我们是中国人; 我们 是 人;we are chiness; 172.16.34.172;youpeizun@126.com;#$*;85*34;58 69"; Console.WriteLine("测试文字:"+testText); Console.WriteLine("测试StandardTokenizer的分词情况如下:"); TestStandardTokenizer(testText); Console.WriteLine("测试CJKTokenizer的分词情况如下:"); TestCJKTokenizer(testText); Console.WriteLine("测试ChinessTokenizer的分词情况如下:"); TestChinessTokenizer(testText); Console.WriteLine("测试LowerCaseTokenizer的分词情况如下:"); TestLowerCaseTokenizer(testText); Console.WriteLine("测试WhitespaceTokenizer的分词情况如下:"); TestWhitespaceTokenizer(testText); Console.Read(); } static void TestStandardTokenizer(string text) { TextReader tr = new StringReader(text); StandardTokenizer st = new StandardTokenizer(tr); while (st.Next() != null) { Console.Write(st.token.ToString()+"/ "); } Console.WriteLine(); } static void TestCJKTokenizer(string text) { TextReader tr = new StringReader(text); int end = 0; CJKAnalyzer cjkA = new CJKAnalyzer(); TokenStream ts = cjkA.TokenStream(tr); while(end<text.Length) { Lucene.Net.Analysis.Token t = ts.Next(); end = t.EndOffset(); Console.Write(t.TermText()+"/ "); } Console.WriteLine(); } static void TestChinessTokenizer(string text) { TextReader tr = new StringReader(text); ChineseTokenizer ct = new ChineseTokenizer(tr); int end = 0; Lucene.Net.Analysis.Token t; while(end<text.Length) { t = ct.Next(); end = t.EndOffset(); Console.Write(t.TermText()+"/ "); } Console.WriteLine(); } static void TestLowerCaseTokenizer(string text) { TextReader tr = new StringReader(text); SimpleAnalyzer sA = new SimpleAnalyzer(); //SimpleAnalyzer使用了LowerCaseTokenizer分词器 TokenStream ts = sA.TokenStream(tr); Lucene.Net.Analysis.Token t; while((t=ts.Next())!=null) { Console.Write(t.TermText()+"/"); } Console.WriteLine(); } static void TestWhitespaceTokenizer(string text) { TextReader tr = new StringReader(text); WhitespaceAnalyzer sA = new WhitespaceAnalyzer(); TokenStream ts = sA.TokenStream(tr); Lucene.Net.Analysis.Token t; while ((t = ts.Next()) != null) { Console.Write(t.TermText() + "/"); } Console.WriteLine(); } } }
运行结果如下:
代码下载:下载
谢谢浏览!
作者:音乐让我说(音乐让我说 - 博客园)
出处:http://music.cnblogs.com/
文章版权归本人所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

