T-SQL 小记
2010-07-26 20:59 音乐让我说 阅读(460) 评论(0) 收藏 举报- 一款类似于 SQL Server Profiler 的免费的、绿色版、轻巧的工具:ExpressProfiler 我本地的下载
- SQL Server 示例数据库 Northwind 和 pubs 下载:
https://files.cnblogs.com/Music/SqlServer_Northwind_pubs_db.zip
- 查询一个数据库表中,不包含userRemark字段的T-SQL语句:
declare @str varchar(8000) set @str='select ' select @str=@str+name+',' from sys.columns where object_id=object_id('UserInfo') and name<>'userRemark' set @str=left(@str,len(@str) - 1) + ' from UserInfo' exec(@str) - 动态修改SQL Server 中的一张表,比如:
alter table UserInfo add userXXX varchar(100) null constraint DF_UserInfo_userXXX default('0') alter table UserInfo drop column userXXX alter table UserInfo drop constraint DF_UserInfo_userXXX - 几个常用的sql server系统表的使用:
--查看表的属性 select * from sysObjects where [Name] = 'section' --用法 if exists ( select * from sysObjects where [Name] = 'section' and xtype='U' ) Drop Table table1 go Create table1 ( ) --获取所有用户表 select Name from sysobjects where xtype='u' and status>=0 --查看表的字段 select * from sysColumns c where c.id=object_id('section') select name from syscolumns where id=object_id('表名') --查看用户 select * From sysusers where status<>0 --查看谁引用了bbs_hits表(包括视图、存储过程、函数) Select distinct object_name(d.id) as 'program', o.xtype from sysdepends d inner join sysobjects o on d.id=o.id where object_name(depid)='bbs_hits' --查看与某一个表相关的视图、存储过程、函数 select a.* from sysobjects a, syscomments b where a.id = b.id and b.text like '%表名%' --查看当前数据库中所有存储过程 select name as 存储过程名称 from sysobjects where xtype='P' --查询某一个表的字段和数据类型 select column_name,data_type from information_schema.columns where table_name = '表名' [n].[标题]: Select * From TableName Order By CustomerName 其中xtype分别对应: C = CHECK 约束 D = 默认值或 DEFAULT 约束 F = FOREIGN KEY 约束 FN = 标量函数 IF = 内嵌表函数 K = PRIMARY KEY 或 UNIQUE 约束 L = 日志 P = 存储过程 R = 规则 RF = 复制筛选存储过程 S = 系统表 TF = 表函数 TR = 触发器 U = 用户表 V = 视图 X = 扩展存储过程 - 关于exec sp_executesql:
--用参数化查询Unit表包含的记录数 declare @result int declare @num int declare @sqls nvarchar(4000) set @sqls='select @a=count(*) from Unit ' exec sp_executesql @sqls,N'@a int output',@result output select @result
- 删除重复记录:
Delete from roomtype where typeId not in (select min(typeId) from roomtype group by typeName,typePrice,typeAddBed,addbed,typeDesc)
- 创建一个SQL自定义函数,如果返回值是一个“table”,则这个函数属于“表值函数”,像下面这样调用:select * from dbo.dnt_split('自,由,王,者',',')。否则如果只是普通的返回值,比如“Int”、“varchar” 等则属于“标量值函数”,像这样调用:select dbo.HowLongTimesBefore(getDate(),'2010-08-14 18:00:00')。
- "SELECT @@identity" 与 “select SCOPE_IDENTITY()” 区别:
在有触发器时,@@identity 总是返回最后一次插入的被触发的插入语句,而 SCOPE_IDENTITY()则不会,而返回当前插入返回的自动增长的值 在.NET 程序中调用,一般用:SELECT CONVERT(Int,SCOPE_IDENTITY()) AS [value]
- 给自动增长的ID显示插入值:
SET IDENTITY_INSERT [t_IDNotContinuous] ON INSERT INTO [t_IDNotContinuous] ([ID],[ValuesString]) VALUES ( 1,'test') SET IDENTITY_INSERT [t_IDNotContinuous] OFF
- 启用 SQL Server 的 sa 登录模式
ALTER LOGIN sa ENABLE ; GO ALTER LOGIN sa WITH PASSWORD = '123456' ; GO
- 插入 Guid 类型的主键插入一个随机的 Guid 值。
insert into Article
values(NEWID(),'ccc','cccccc',1,GETDATE(),1,null) - sql server 还原数据库的命令
use master go RESTORE DATABASE myTestDB FROM DISK='D:\Databases\myTestDB.bak' WITH REPLACE
- 附加数据库的 SQL 语句
sp_attach_db 'TestDB','D:\TestDB.mdf','D:\TestDB_log.ldf' go
- SQL Server 删除所有用户表
DECLARE c1 cursor for select 'alter table ['+ object_name(parent_obj) + '] drop constraint ['+name+']; ' from sysobjects where xtype = 'F' open c1 declare @c1 varchar(8000) fetch next from c1 into @c1 while(@@fetch_status=0) begin exec(@c1) fetch next from c1 into @c1 end close c1 deallocate c1 go declare @tname varchar(8000) set @tname='' select @tname=@tname + Name + ',' from sysobjects where xtype='U' select @tname='drop table ' + left(@tname,len(@tname)-1) exec(@tname) go
- partition by:
-
很高兴为你解答, 相信group by你一定用过吧, 先对比说下
partition by关键字是oracle中分析性函数的一部分,它和聚合函数不同的地方在于它能返回一个分组中的多条记录,
而聚合函数一般只有一条反映统计值的记录,partition by用于给结果集分组,如果没有指定那么它把整个结果集作为一个分组,
它有一部分函数既是聚合函数也是分析函数,比如avg、max,也有一部分是特有的,
比如first、rank,除了order by子句外,分析函数在一个查询中优先级最低。至于partition by和group by谁的性能更好,
要看具体情况而定,partition by的作用仅用于分组,那么性能可能比不上group by 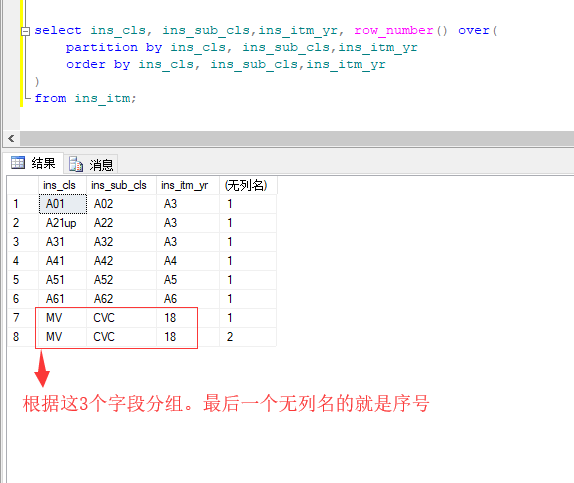
- 、谢谢浏览...
作者:音乐让我说(音乐让我说 - 博客园)
出处:http://music.cnblogs.com/
文章版权归本人所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号