DataWhale八月组队学习-李宏毅深度学习Task06-卷积神经网络
Network架构设计
1 卷积神经网络(Convolutional Neural Network)
1.1 应用:
CNN多被用于图像处理领域
1.2 困难:如何将一张影像当作一个模型的输入
- 目的是让
model得出的y的预测值和测试集中y的值之间的交叉熵越小越好。 - 对于测试集中的
y label而言,其向量的长度决定了特征的数量
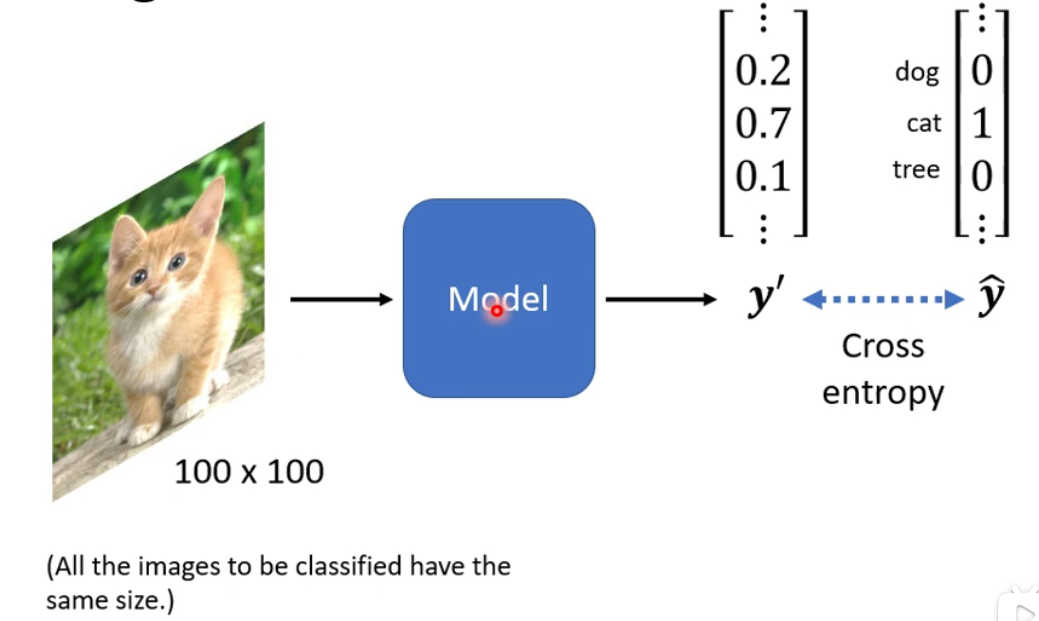
1.3 计算机眼中的图片:
-
计算机眼中的图片是一个三维tensor
-
长和宽代表了像素的大小,高代表通道数,也就是图片的组成要素的数量(
RGB三元素) -
将图片拉直变为一个向量,就可以将其作为
Network的输入。 -
使用全连接网络参数数量太大。虽然参数的增加可以增加模型的弹性,但是存在过拟合的风险。(是否需要这么多参数呢?)
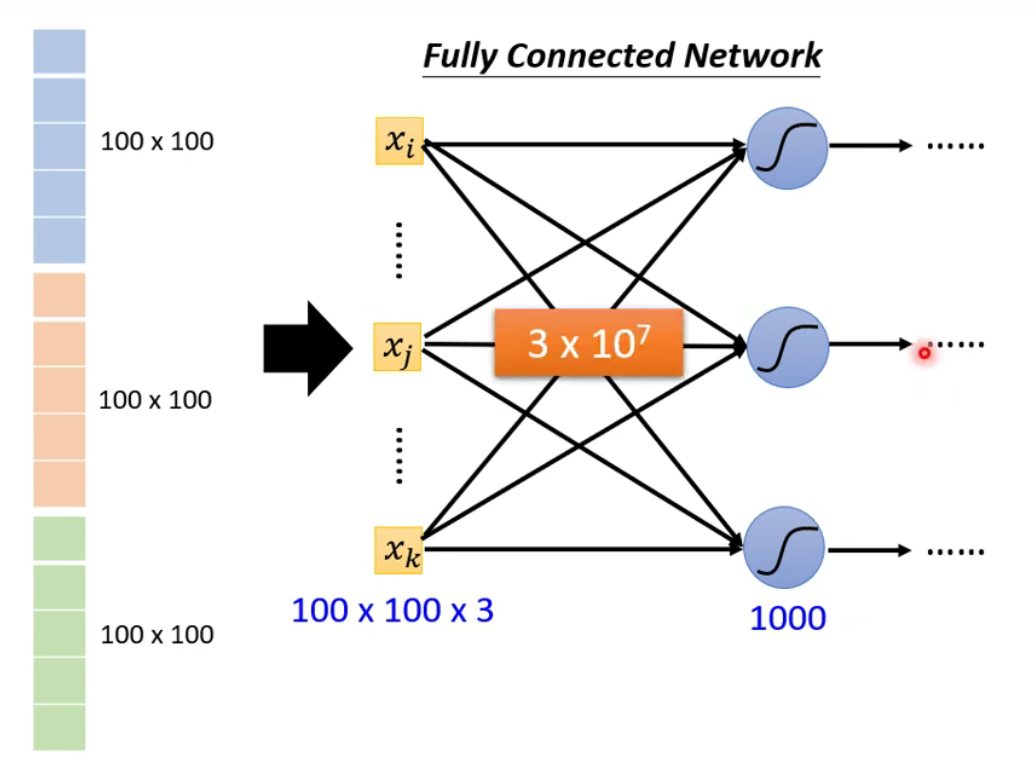
-
观察
-
根据一张图片中的关键特征来判断图片中的物种类别(或许根本没有必要将整张图片作为输入)

-
简化:在
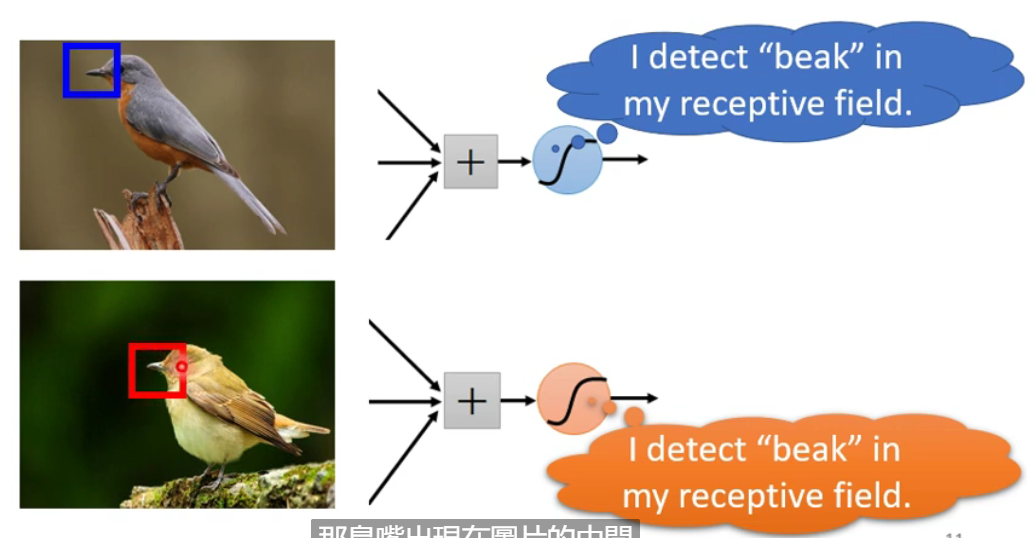
CNN中,设定一个区域为Receptive field,每一个神经元只用关心自己的划定的区域即可。(区域可以任意自定义化)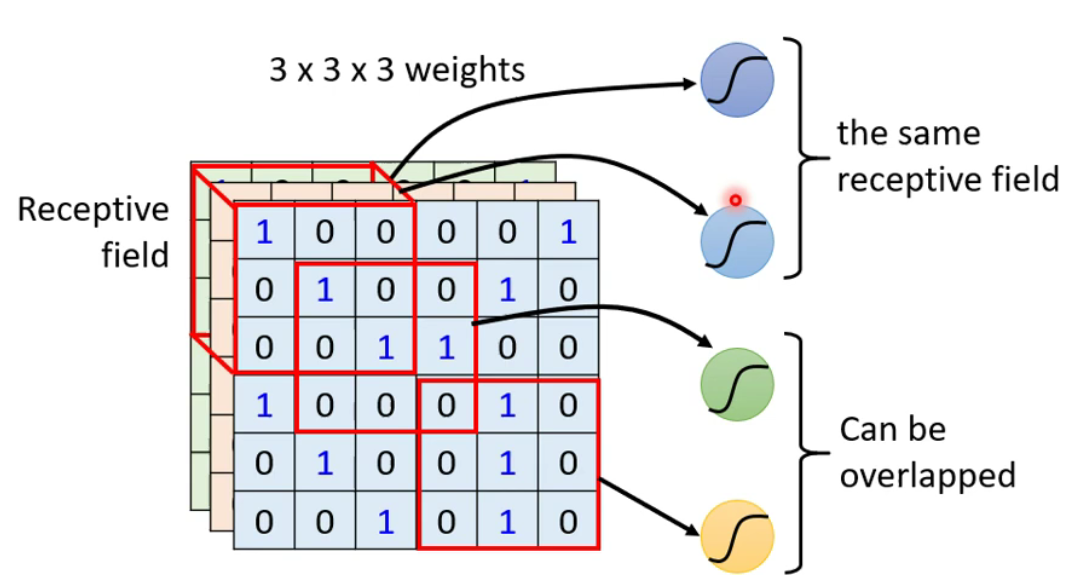
-
最经典的区域安排方式:考虑全部的
channels,kernel size(高和宽的整合)常见的是3×3。通常同一个区域会有多个神经元去使用。 -
各个区域间的关系:区域移动的距离叫做
stride,要让区域之间具有高度的重叠。 -
如果区域移动后超出影像范围之外具有了
overlap,需要用0来替代overlap中的值。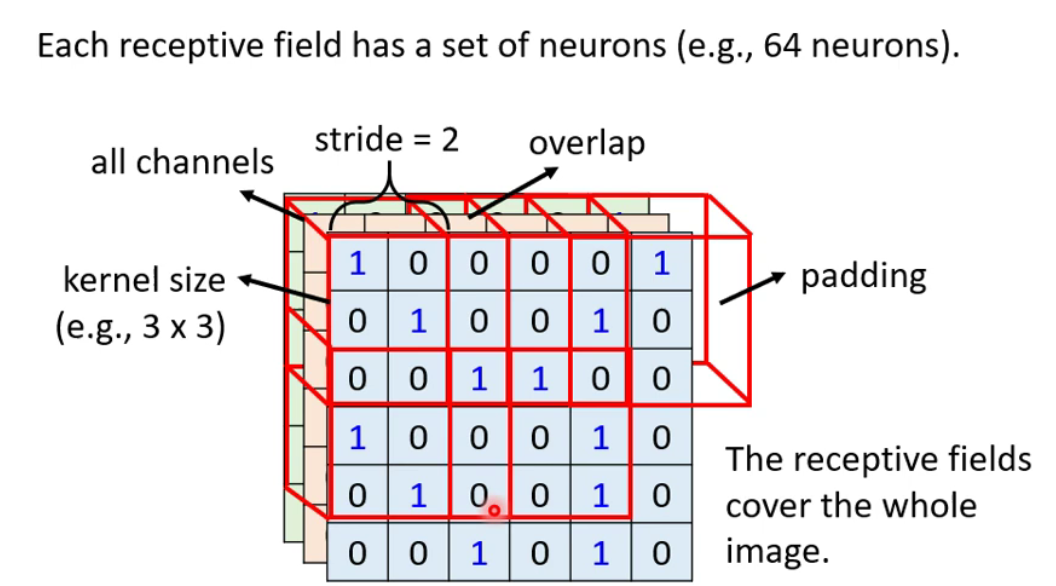
-
最后使得图片中的每一个位置都有神经元在侦测。
-
-
同样的关键特征可能出现在不同图片的不同区域:由第一个观察可以知道,图片中的每个位置都有神经元侦测,所以侦测鸟嘴的神经元做的事情是一样的,只是侦测的区域不同。如果不同的区域都需要侦测鸟嘴的神经元也会导致参数过多。
-
简化:让不同区域的神经元共享参数(所使用的参数相同,输入输出不同)

-
常见共享设定:每个区域都有自己特定的一组参数叫做
Filter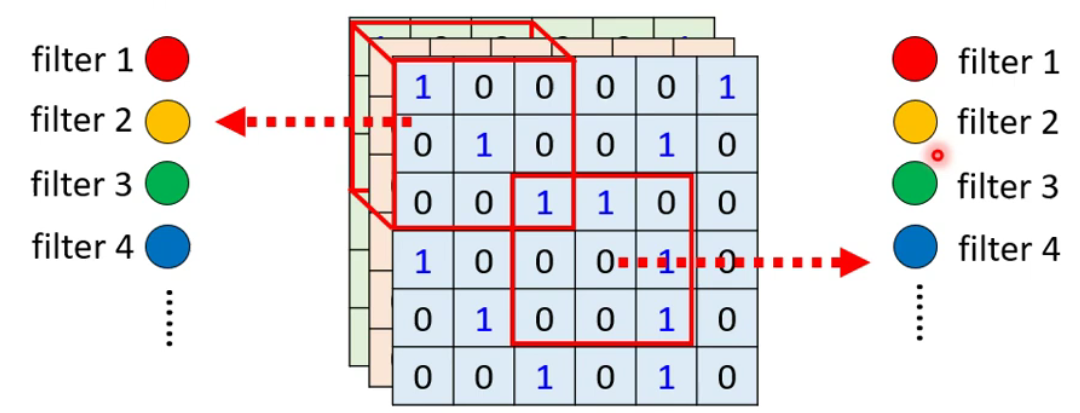
-
-
1.4 三者比较(卷积层的好处)
-
区域限制加上参数共享就是卷积层(相比于全连接层弹性会变小),使用卷积层的
Network叫做CNN(为影像设计而生) -
CNN具有较大的bias,并不一定是坏事,因为bias小的全连接层可能出现过拟合现象。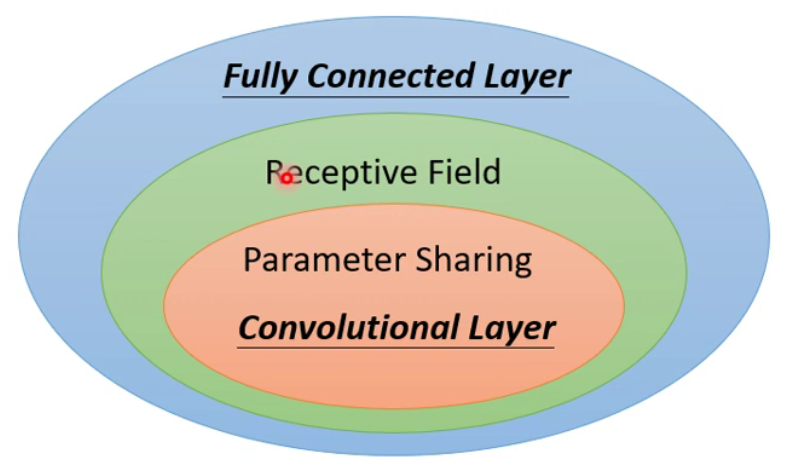
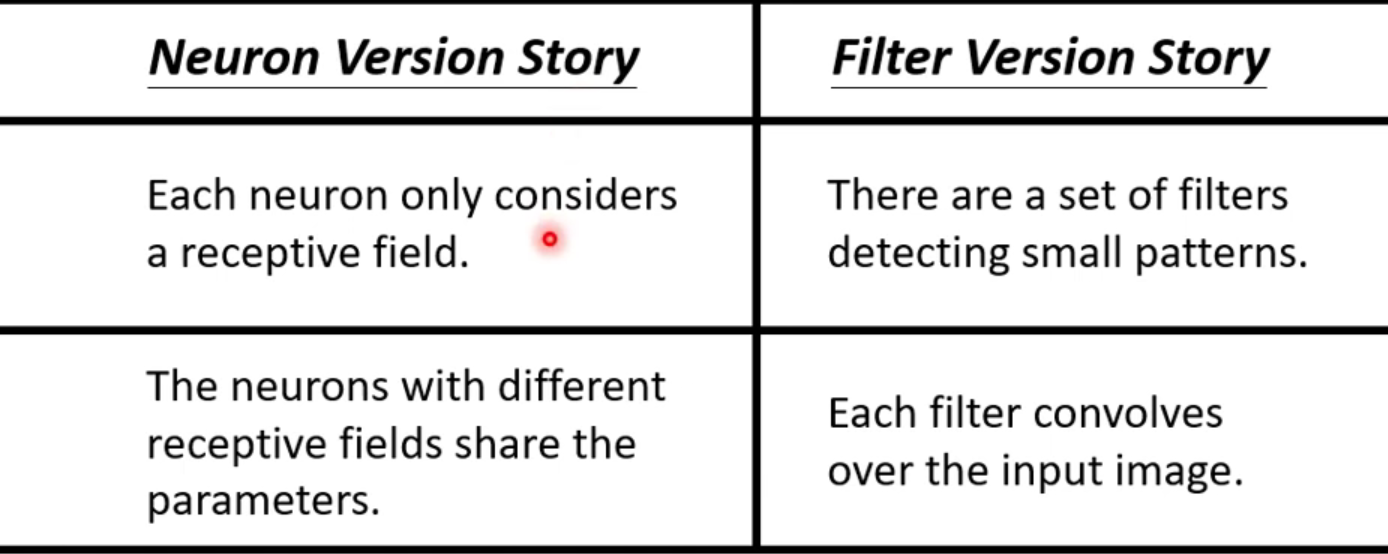
1.5 两个版本的CNN讲述
1.6 Pooling(池化)
-
对像素进行二次抽样将不会改变图片的类别

-
运作方式:每个
Filter都会产生一组数字,将数字划分为多个组别,每个组别选取一个代表(Max Pooling选择的是数值最大的数字作为代表)
-
池化所作的事情就是将图片变小,通常在卷积后进行池化(用于减少运算量)。
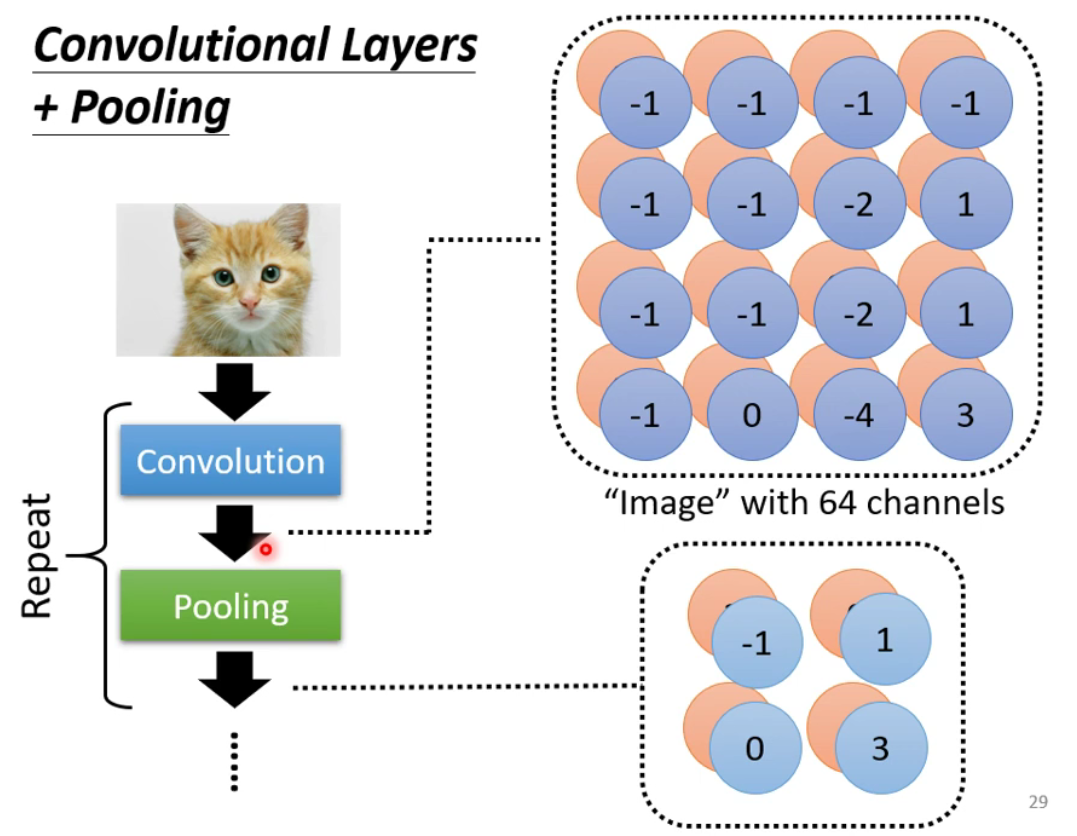
1.7 Flatten(扁平化)
-
作用:将影像中得到的矩阵的数值拉直形成一个向量,再将得到的向量送入全连接层当中。
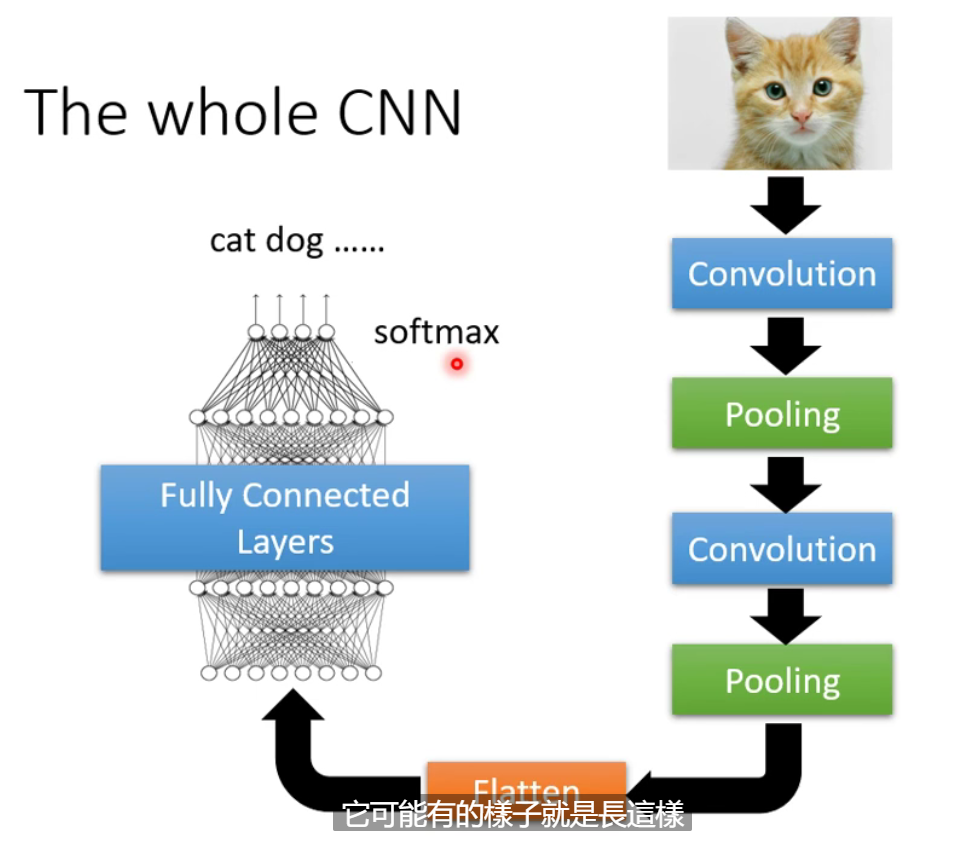
2 自注意力机制
2.1 背景
-
在
CNN模型中,输入模型的是一个向量。而某些情况下我们需要输入一组向量,并且每个向量的长度可能会改变,此时CNN无法解决。 -
例如:如果输入是一个句子,句子中的每个词语的长度都不一样。一个做法是将所有的词汇汇总起来形成一个无比巨大的向量。但这样处理无法识别词语的语义。所以出现了
Word Embedding(会给每一个词汇一个向量),进行它得出的向量具备语义,相同类别的词汇会汇集在一起。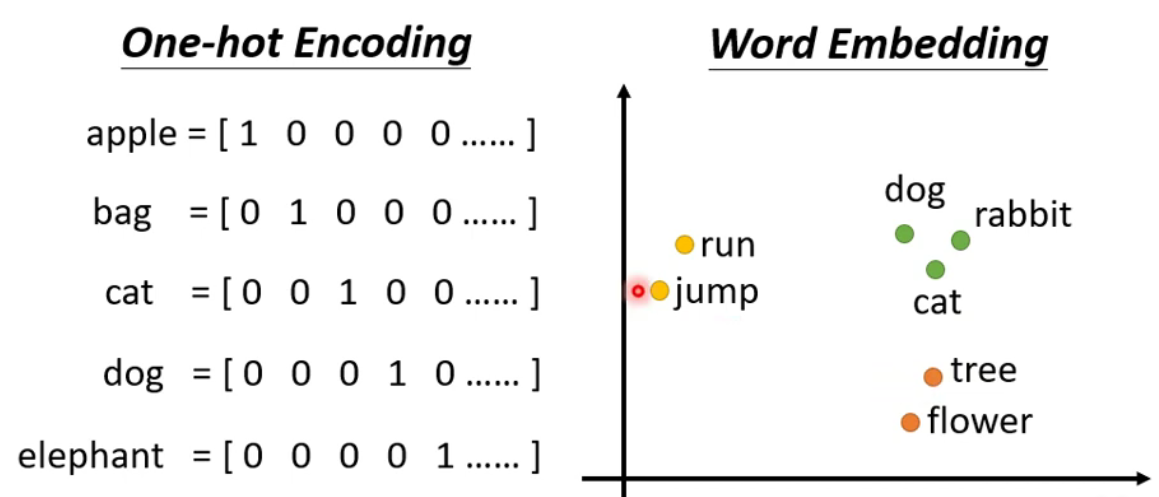
-
三种可能的输出
-
输入的每一个向量都有对应的输出
label。例如:词性分析
-
所有的输入向量只对应一个输出。例如:情感分析、语音识别

-
机器自己决定需要输出的数量(seq2seq)。例如:翻译

-
2.2 输入和输出一样多的情况(序列标签Sequence Labeling)
-
初始想法:将每一个向量都输入到
fully-connected中,可是对于相同的向量无法得到不同的输入,比如:一个句子可能出现相同词汇可是词性不同。如果想要做到,就需要将多个向量组合起来一起加入到network中才可以实现。 -
Self-attention-
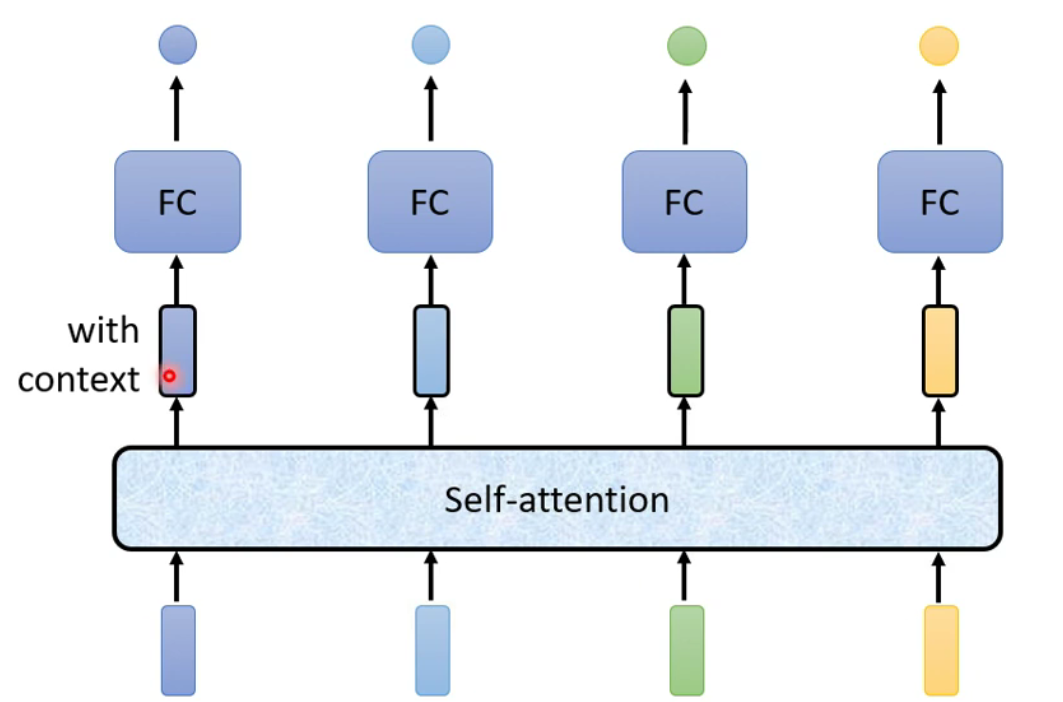
-
两者交替使用

-
运作原理:
-
输入可能是整个
network的input,也可能是某个隐藏层的output。考虑了所有的输入才得到了最后的输出。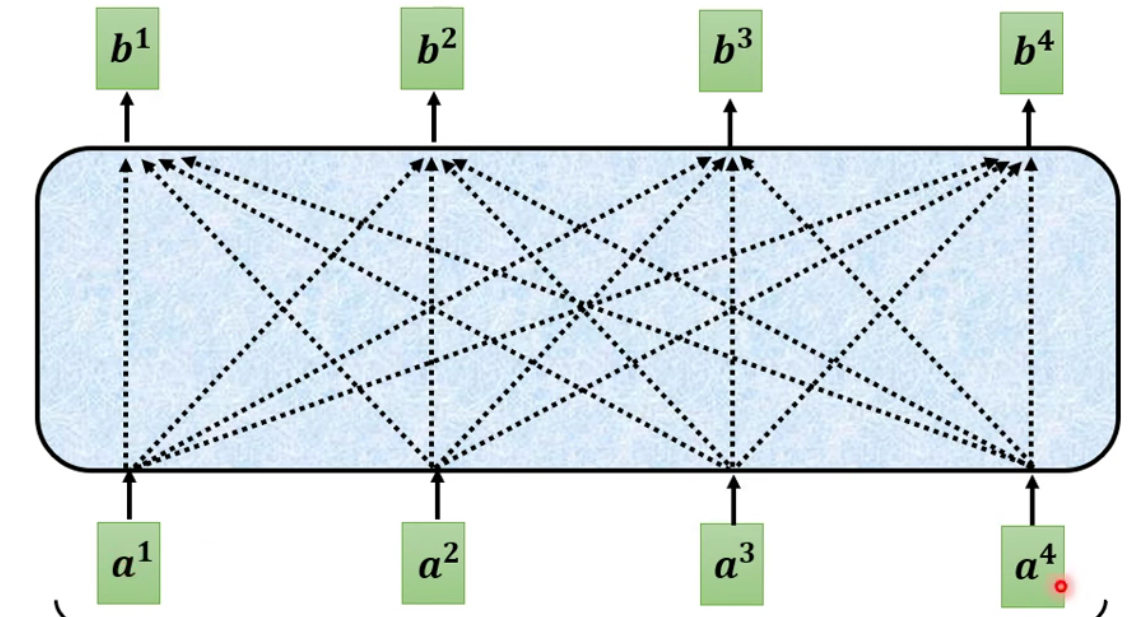
-
产生
b1向量的步骤-
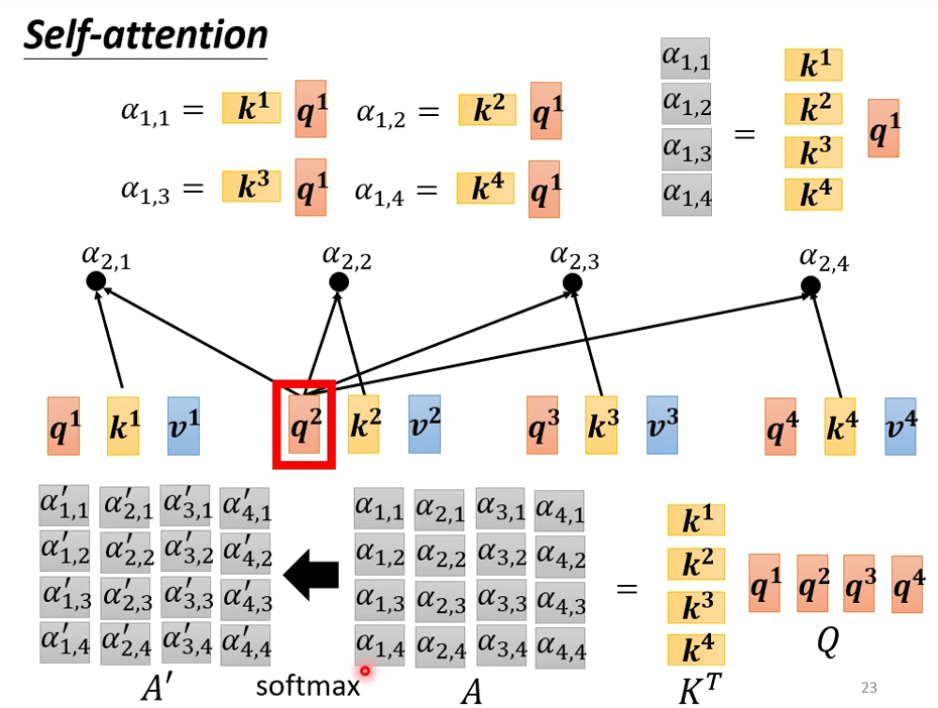
根据
a1找到句子中跟a1相关的其它向量。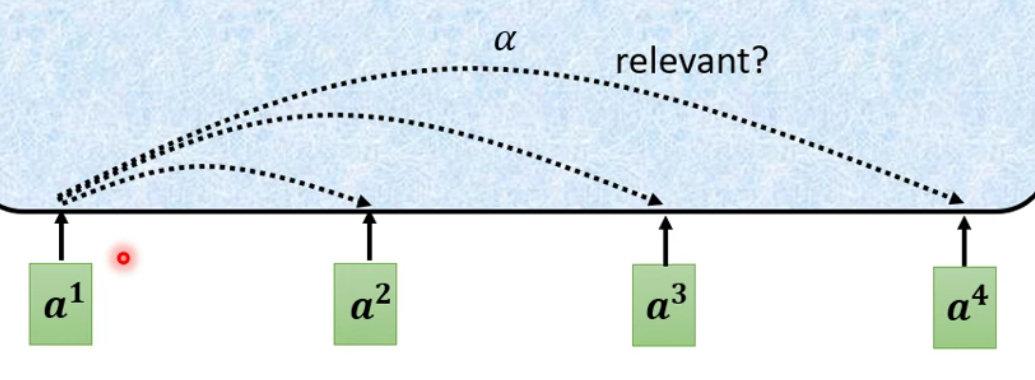
-
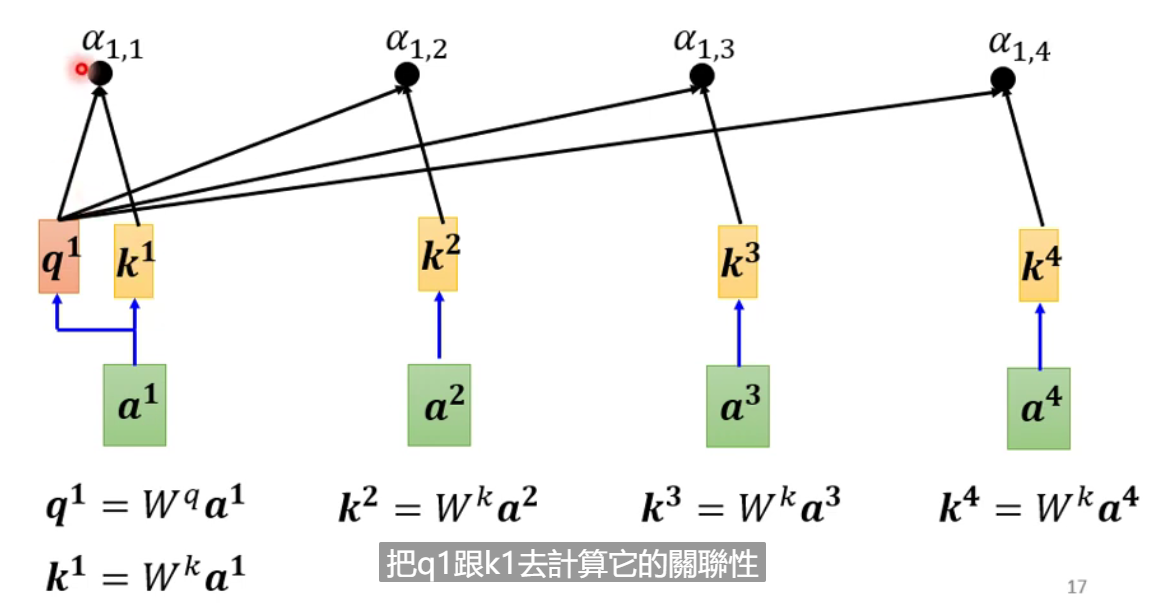
如何决定两向量之间的相关度
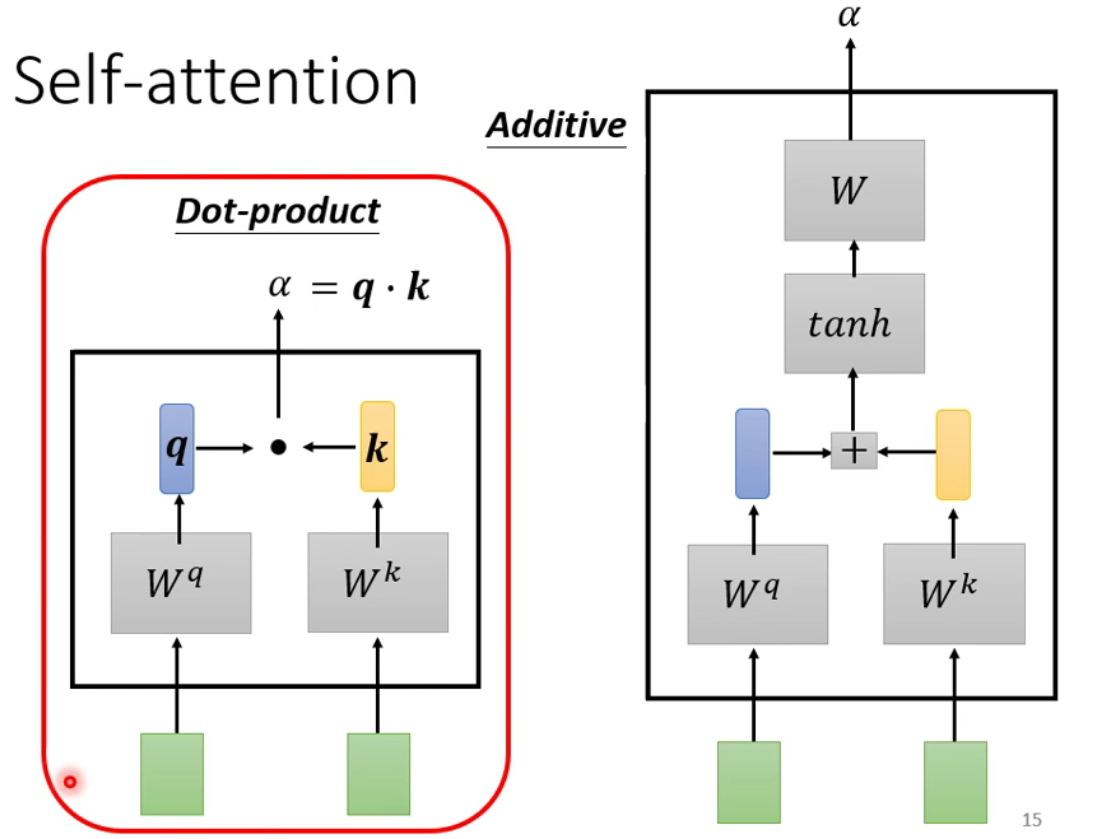
-
最终进行
soft-max,也可以其使用其它函数。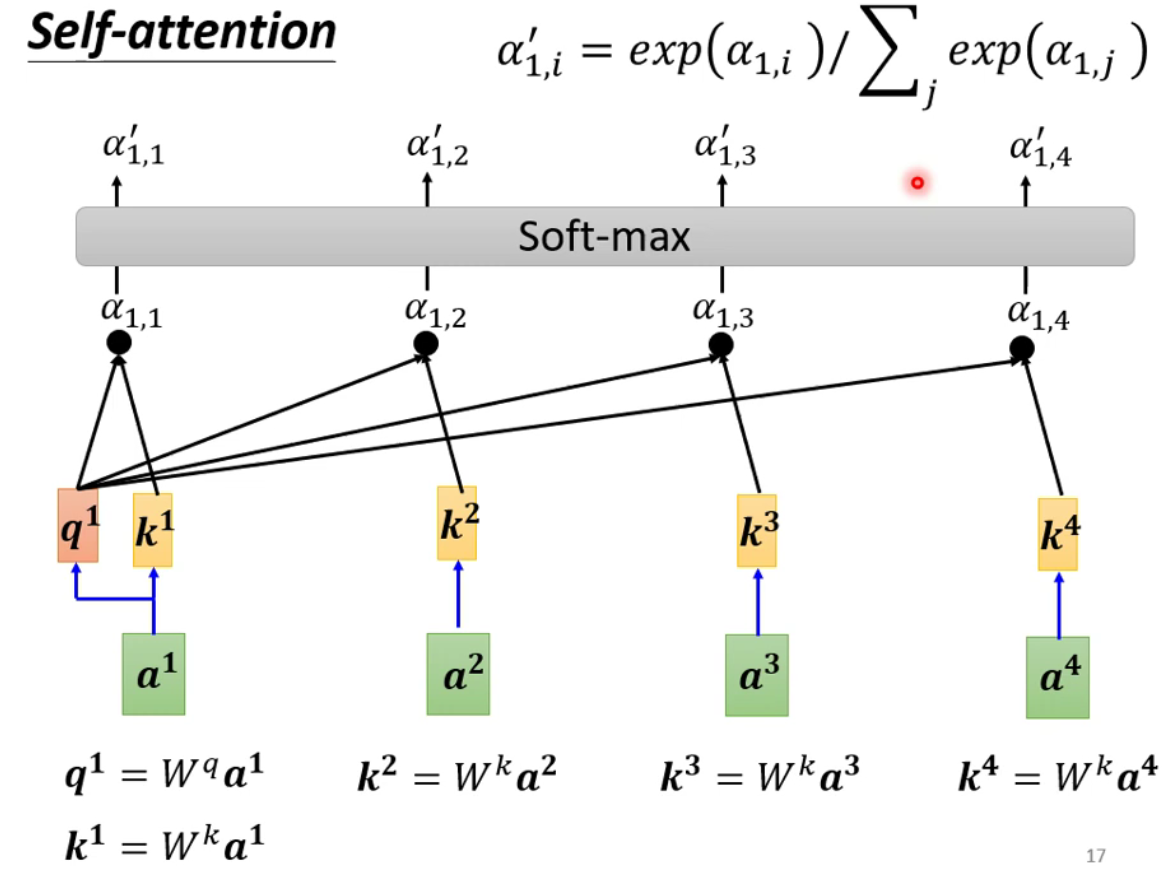
-
根据上述得到的数据去抽取出句子中的重要信息
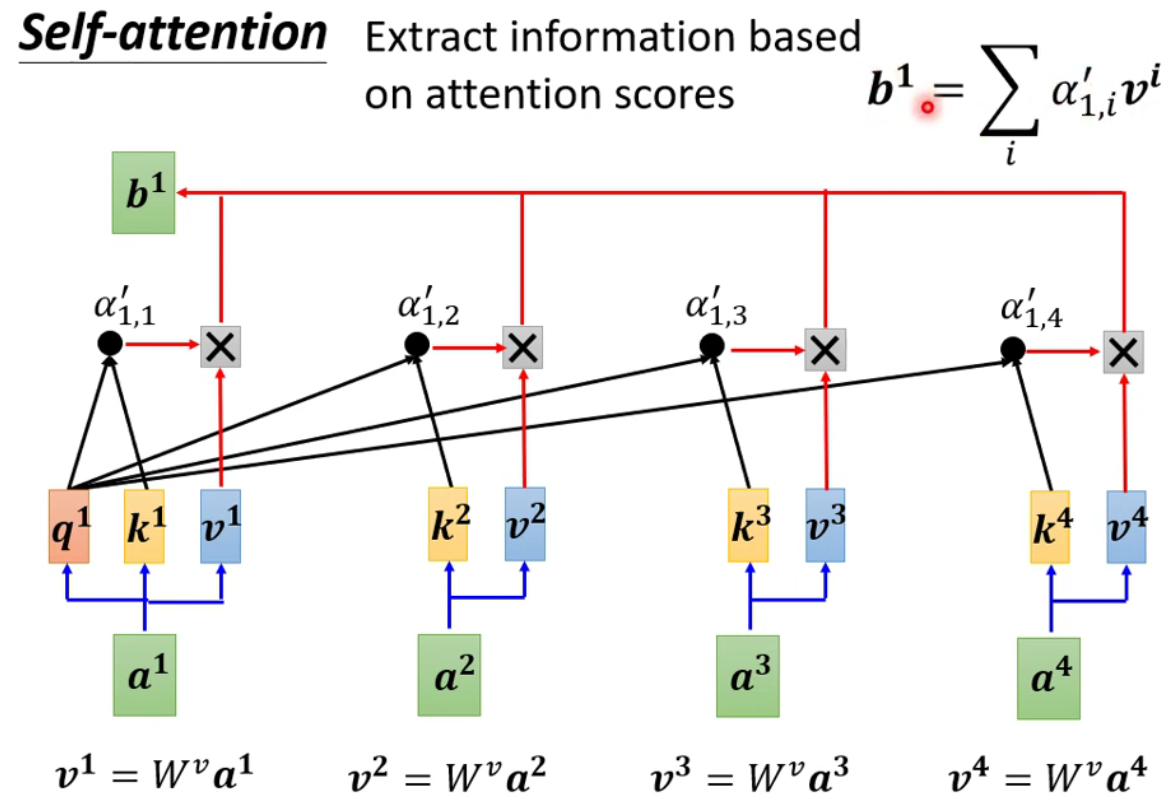
-
-
-
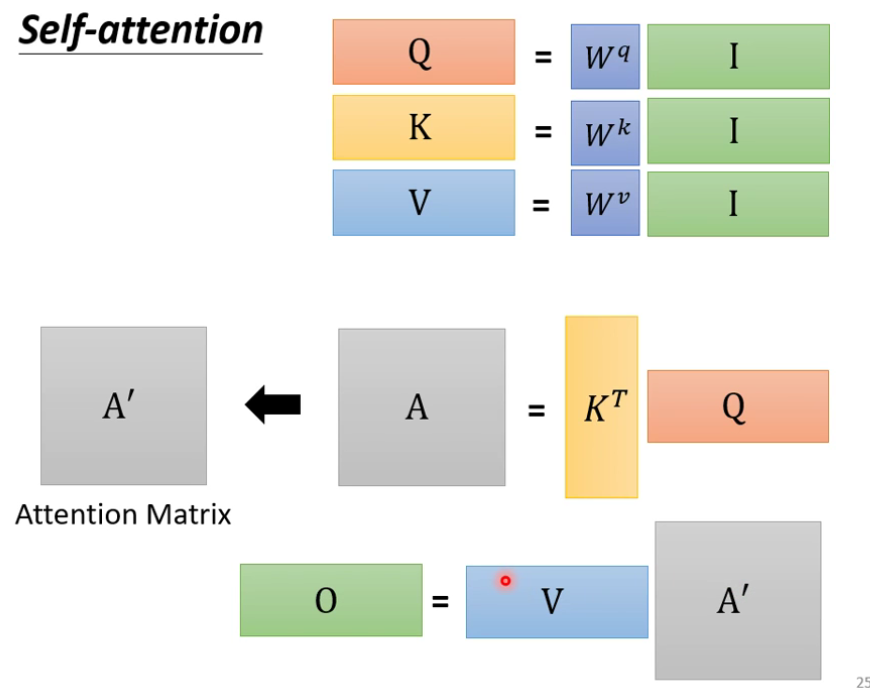
从矩阵乘法的角度重新梳理运行原理
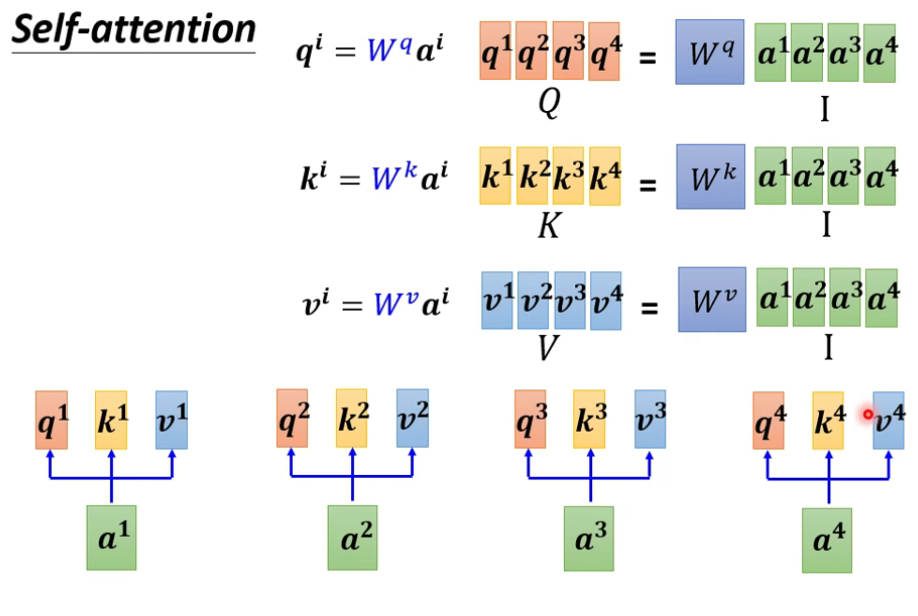
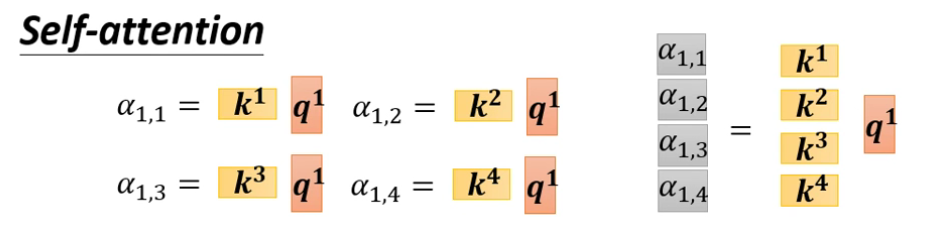

-
需要去学习的参数只有
Wq、Wk、Wv
-
