DataWhale八月组队学习-李宏毅深度学习Task02-回归
回归
- 应用领域
- 股票市场预测
stock Market Forecast - 无人驾驶汽车
Self-driving Car - 推荐
Recommendation
- 股票市场预测
1 具体步骤
-
寻找
Model
-
b和w是参数,可以取任意值 -
由于有无穷无尽的参数值可供挑选,自然会衍生出无穷无尽的函数。
-
用上述的一个式子就可以表示无穷无尽的函数,这个式子被称之为
Model -
而这个
Model被称为Linear model-
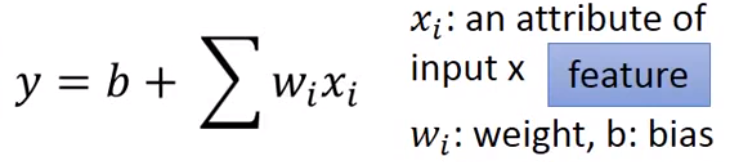
-
一个线性模型可能具有多个特征(
feature)和多个权重系数(weight)
-
-
-
得出损失函数
-
收集10个数据样本,将样本中
x与y的关系进行图形绘制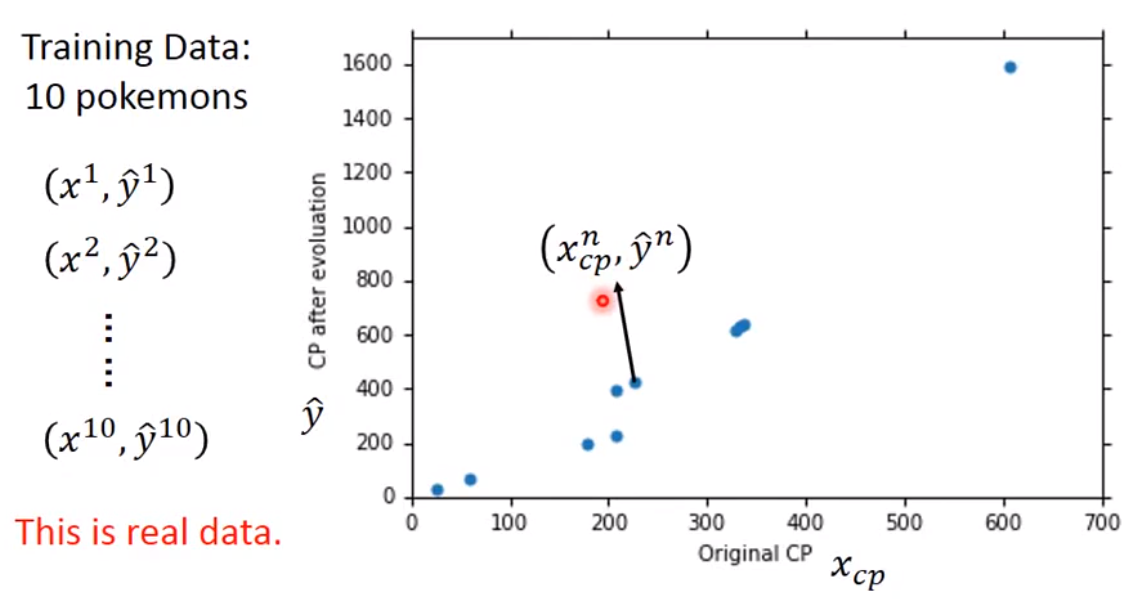
-
定义损失函数
L-
输入:是
Model中的一个Function -
输出:当前这个
Function有多糟糕 -
公式流程(红色下划线表示的是预测值):

-
-
-
挑选最好的
Function-
将
Model中的每一组Function带入到损失函数的计算公式中,找出能使得损失函数计算结果最小的w和b
-
-
梯度下降
-
初始不引入参数
b,仅关注参数w-
具体步骤
-
随机取定
w值 -
进行偏导数计算,导数值为负则增加
w,导数值为正则减小w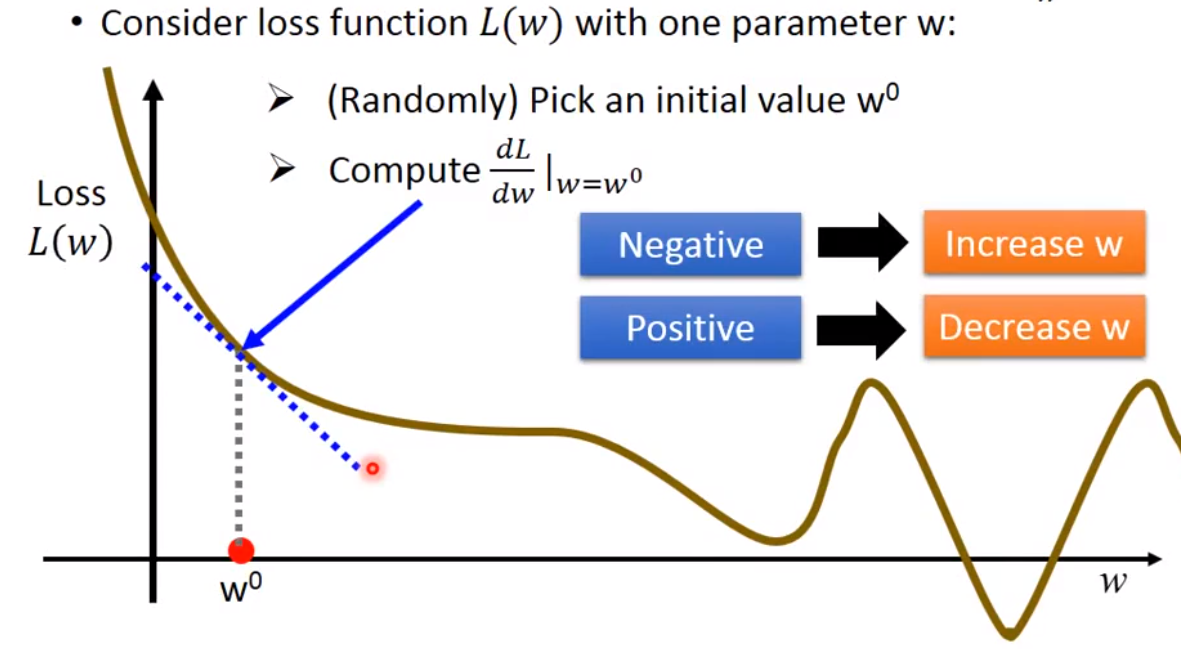
-
增加或者减小
w的幅度还取决于学习率(红色字体符号)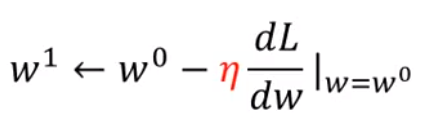
-
-
重复上述步骤直到偏导数的值为零
-
-
同时引入两个参数
-
具体步骤(图中最后一列有问题,需要将0全部换为1)

-
移动过程

-
令人担心之处:可能走到不同的谷底(偏导数为0之处),谷底的深度会不一样。
- 不用担心,在线性回归中,损失函数找出的最佳参数始终都是同一组参数。因为
w和b绘制出的是同一幅等高线,等高线找到的谷底都是同一个谷底
- 不用担心,在线性回归中,损失函数找出的最佳参数始终都是同一组参数。因为
-
-
-
结果
-
结果的关键不在于对已有数据偏差的估测,而在于对新数据(
testing data)的误差的估测。 -
新增加10个数据样本,绘制拟合情况图像

-
2 新的模型
为了达到更好地预测效果需要引入另一个模型
-
二次函数
-
公式:

-
拟合情况:
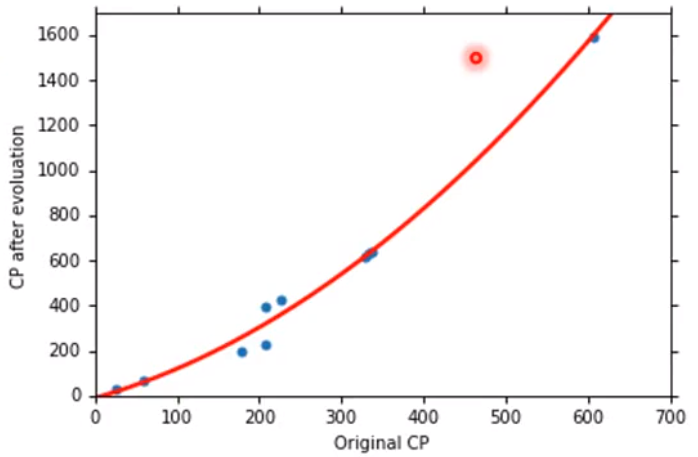
-
数据展示:

-
-
其它更加复杂的模型,发现误差下降不明显。这是明显的过拟合现象(已经提前了解,不做赘述记录)
-
越复杂的模型,越能够更好地拟合训练数据,越不一定能很好拟合测试数据。
-
上述的理论用例子来阐述:越依赖你的父母,你就越安于现状,越不能很好的为自己的未来做好准备。
-
综上所述,要选择最合适的模型
-
3 同特征不同种类的影响
-
模型相同时,针对不同的物种(相同特征类别不同),得到的
Function可能不一样。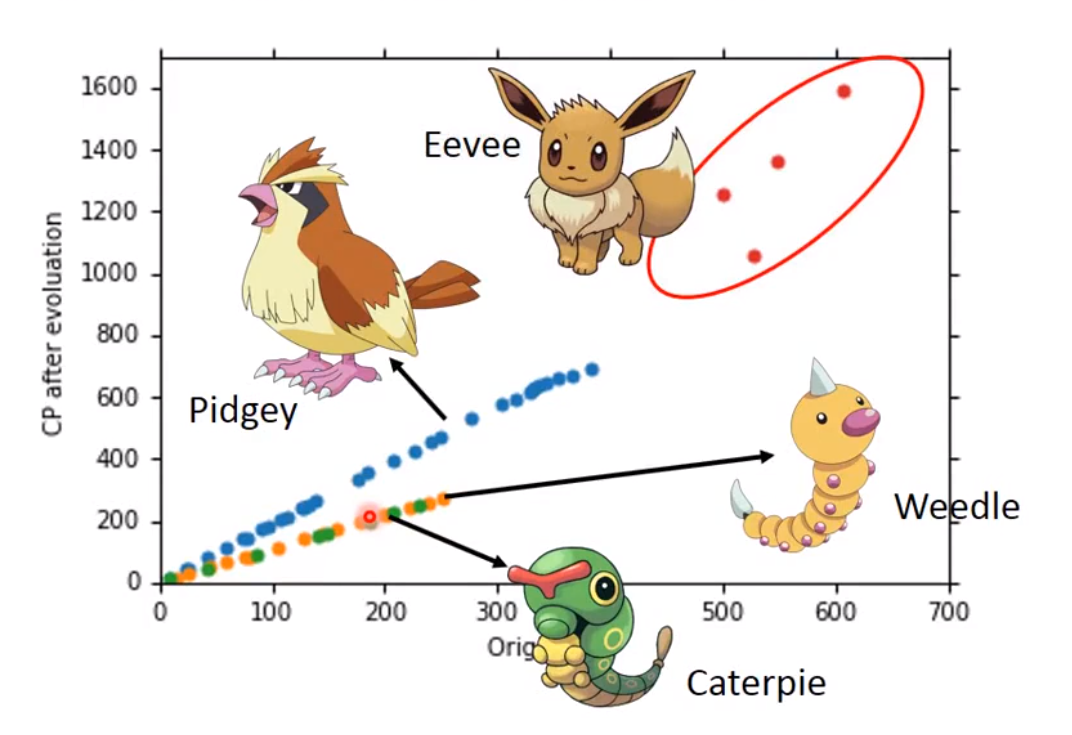
-
具体公式表示
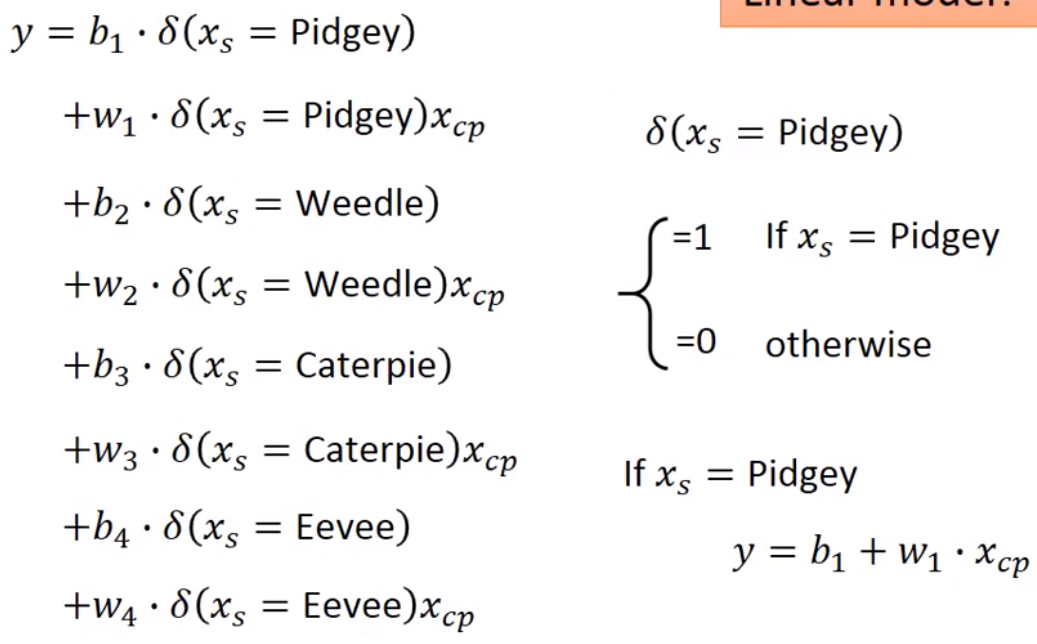
不同特征的影响-正则化
-
针对不同特征的影响,比如宝可梦除了种类,可能还有升高,体重等特征,将这些特征引入,得到的对测试集的拟合结果的误差大概率会很大,此时我们需要正则化。
-
具体公式:
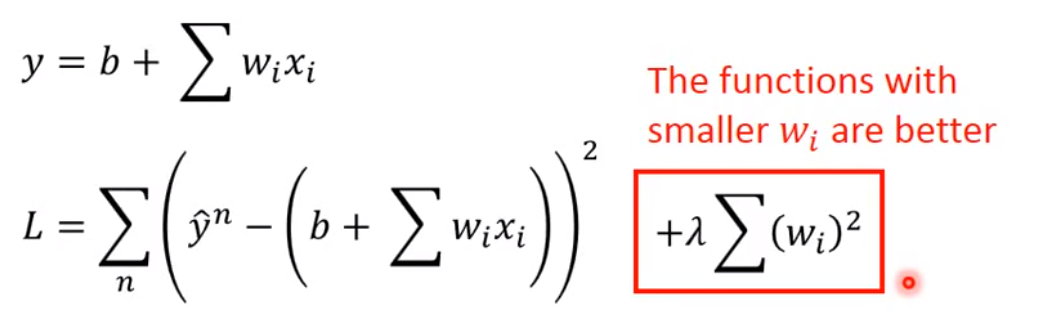
-
解释:如果
Wi越小,那么输入对输出的影响就会越小,输出结果就会更加的平滑(这个给第一个式子中的x加上一个增量,分离得到的常数项就可以看出来影响) -
函数越平滑,对于
噪音输入的影响就会更小,输出结果收到的波及就会更小 -
公式中惩罚项不引入
b的原因是b与曲线的平滑程度无关
