决策树算法的Sklearn完整复现
1 算法原理
决策树是一个类似于流程图的树结构,分支节点表示对一个特征进行测试,根据测试结果进行分类,树叶节点代表一个类别。
例如:用决策树来决定下班后的安排。
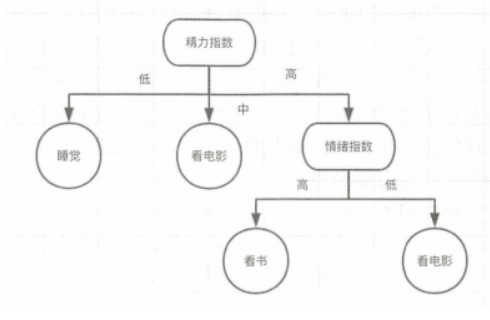
分别对经理指数和情绪指数两个特征进行测试,根据测试结果决定行为的类别。
每选择一个特征测试,数据集就被划分成多个子数据集。
接着继续在子数据集上选择特征,并进行数据集划分,直至创建出一个完整的决策树。
如何判断特征分裂的优先级?
1.1 信息增益
信息熵解决了信息量化的问题。一个问题的不确定性越大,要搞清楚问题需要了解的信息就越多,其信息熵就越大
信息熵计算公式:

如何判断特征分裂的优先级:遍历所有特征,分别计算,使用这个特征划分数据集前后信息熵的变化之值,然后选择信息熵变化幅度最大的特征进行数据集划分。即选择信息增益最大的特征作为分裂节点
1.2 决策树的创建
构建过程:从训练数据集中归纳出一组分类规则,使它与训练数据矛盾较小的同时具有较强的泛化能力。根据信息增益量化进行选择划分特征,
基本步骤为:
- 计算数据集划分前的信息熵。
- 遍历所有未作为划分条件的特征,分别计算根据每个特征划分数据集后的信息熵。
- 选择信息增益最大的特征,并使用该特征进行数据集划分。
- 递归地处理被划分后的所有子数据集。
终止条件:
- 所有特征都用完了
- 划分后的信息增益足够小了,需要事先选择信息增益的门限值作为结束递归地条件。
使用信息增益作为特征选择指标的决策树构建算法,称为ID3算法
1.2.1 离散化
如果一个特征是离散值,我们需要对其进行离散化处理,根据数据范围划分层级。
1.2.2 正则项
-
问题:如果产品具有唯一标识符,那么构建决策树的时候就一定会按照唯一标识符特征来划分特征,会导致每个叶子节点只有一个样本。
-
解决方法:
- 计算划分后的子数据集的信息熵时,加上一个与类别个数成正比的正则项,来作为最后的信息熵。
- 使用信息增益比来作为特征选择的标准。
1.2.3 基尼不纯度
- 作用:衡量信息不纯度的指标。
- 公式:
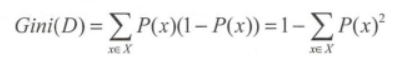
其函数关系的图像与信息熵形状基本一样。CART算法使用基尼不纯度作为特征选择标准,CART也是一种决策树构建算法。
1.3 剪枝算法
决策树模型拟合数据时,容易造成过拟合现象。需要进行剪枝操作:前剪枝和后剪枝。
1.3.1 前剪枝
在构造决策树的同时进行剪枝。
在决策树构建过程中无法进一步降低信息熵时,会停止创建分支。
避免过拟合:
- 设定对应阈值。信息熵减小的数量小于该阈值,就停止继续创建分支。
- 还可以限制叶子节点的样本个数,当样本个数小于一定的阈值时,停止创建分支。
1.3.2 后剪枝
在构造决策树完成后进行剪枝。
将拥有同样父节点的一组节点进行检查,判断如果将其合并,信息熵的增量是否会小于某一阈值。如果小于阈值,则这一组节点可以合并成一个节点,
后剪枝算法:
- 降低错误率剪枝法:自底向上,用子树的根节点代替子树,作为新的叶子节点。构建出简化版的决策树,然后使用交叉验证数据集测试简化版本的错误率是否降低,降低就可以使用简化版代替完全决策树,否则还是使用完全决策树。
2. 算法参数
scikit-learn使用sklearn.tree.DecisionTreeClassifier类实现决策树分类算法。
参数解释如下:
- criterion:特征选择算法,一种是基于信息熵,一种是基于基尼不纯度。这两种算法的差异不大,对模型的准确性没有大影响。信息熵运算效率会第一点,因为其具有对数运算。
- splitter:创建决策树分支的选项,一种是选择最优的分支创建原则。另一种是从排名靠前的特征中,随机选择一个特征来创建分支,与正则项的效果类似。
- max_depth:指定决策树的最大深度,解决过拟合问题。
- min_samples_split:指定能创建分支的数据集的大小,默认为2.如果一个节点的数据样本个数小于这个数值,则不再创建分支,是一种前剪枝方法。
- min_samples_leaf:创建分支后的节点样本数量必须大于等于这个数值,否则不再创建分支,也属于前剪枝方法。
- max_leaf_nodes:除了限制最小的样本节点个数,该参数可以限制最大的样本节点个数。
- min_impurity_split:可以使用该参数来指定信息增益的阈值,创建分支时信息增益必须大于这个阈值。
3. 实例:预测泰坦尼克号幸存者
#读取数据
import pandas as pd
def read_dataset(fname):
#指定第一列作为索引
data = pd.read_csv(fname,index_col = 0)
#丢弃无用数据
data.drop(['Name','Ticket','Cabin'],axis = 1,inplace = True)
#处理性别数据
data['Sex'] = data['Sex'].replace(['male','female'],[1,0])
#处理登船港口数据
labels = data['Embarked'].unique().tolist()
data['Embarked'] = data['Embarked'].apply(lambda n:labels.index(n))
#处理缺失数据
data = data.fillna(0)
return data
train = read_dataset('datasets/titanic/train.csv')
train
| Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | |
|---|---|---|---|---|---|---|---|---|
| PassengerId | ||||||||
| 1 | 0 | 3 | 1 | 22.0 | 1 | 0 | 7.2500 | 0 |
| 2 | 1 | 1 | 0 | 38.0 | 1 | 0 | 71.2833 | 1 |
| 3 | 1 | 3 | 0 | 26.0 | 0 | 0 | 7.9250 | 0 |
| 4 | 1 | 1 | 0 | 35.0 | 1 | 0 | 53.1000 | 0 |
| 5 | 0 | 3 | 1 | 35.0 | 0 | 0 | 8.0500 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 887 | 0 | 2 | 1 | 27.0 | 0 | 0 | 13.0000 | 0 |
| 888 | 1 | 1 | 0 | 19.0 | 0 | 0 | 30.0000 | 0 |
| 889 | 0 | 3 | 0 | 0.0 | 1 | 2 | 23.4500 | 0 |
| 890 | 1 | 1 | 1 | 26.0 | 0 | 0 | 30.0000 | 1 |
| 891 | 0 | 3 | 1 | 32.0 | 0 | 0 | 7.7500 | 2 |
891 rows × 8 columns
#模型训练:
#将Survived列提取出来作为标签,然后再原数据集中将其丢弃,同时把数据集分成训练数据集和交叉验证数据集
from sklearn.model_selection import train_test_split
y = train['Survived'].values
X = train.drop(['Survived'],axis = 1).values
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2)
print('train dataset:{0};test dataset:{1}'.format(
X_train.shape,X_test.shape))
train dataset:(712, 7);test dataset:(179, 7)
#利用决策树模型对数据进行拟合
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
clf.fit(X_train,y_train)
train_score = clf.score(X_train,y_train)
test_score = clf.score(X_test,y_test)
print('train score:{0};test score:{1}'.format(train_score,test_score))
train score:0.9873595505617978;test score:0.7262569832402235
3.1 优化模型参数
选择一系列参数的值,分别计算用指定参数训练出来的模型的评分数据,将两者关系画出来,只管看到参数值与模型准确度的关系。
#参数选择max_depth
def cv_score(d):
clf = DecisionTreeClassifier(max_depth = d)
clf.fit(X_train,y_train)
tr_score = clf.score(X_train,y_train)
cv_score = clf.score(X_test,y_test)
return (tr_score,cv_score)
#构造参数范围,在范围内分别计算模型评分,找出评分最高的模型对应参数
depths = range(2,15)
scores = [cv_score(d) for d in depths]
tr_scores = [s[0] for s in scores]
cv_scores = [s[1] for s in scores]
#找出交叉验证数据集评分最高的索引
import numpy as np
best_score_index = np.argmax(cv_scores)
best_score = cv_scores[best_score_index]
best_param = depths[best_score_index] #找出对应的参数
print('best param:{0};best score:{1}'.format(best_param,best_score))
best param:5;best score:0.7821229050279329
#绘制模型参数和模型评分
import matplotlib.pyplot as plt
plt.figure(figsize = (6,4),dpi = 144)
plt.grid()
plt.xlabel('max depth of decision tree')
plt.ylabel('score')
plt.plot(depths,cv_scores,'.g-',label='cross-validation score')
plt.plot(depths,tr_scores,'.r--',label = 'training score')
plt.legend()
<matplotlib.legend.Legend at 0x1c8c9d15ee0>

使用同样的方法考察参数min_impurity_split,这个参数用来指定信息熵或基尼不纯度的阈值。
决策树分裂后,其信息增益低于这个阈值则不再分裂。
import warnings
warnings.filterwarnings("ignore") # 忽略版本问题
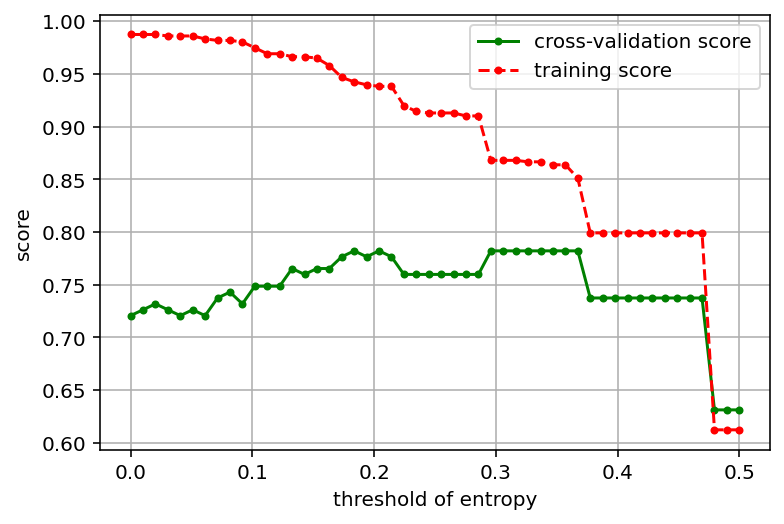
#训练模型并计算评分(基尼不纯度)
def cv_score(val):
clf = DecisionTreeClassifier(criterion='gini',min_impurity_split = val)
clf.fit(X_train,y_train)
tr_score = clf.score(X_train,y_train)
cv_score = clf.score(X_test,y_test)
return (tr_score,cv_score)
#指定参数范围,分别训练模型并计算评分
values = np.linspace(0,0.5,50)
scores = [cv_score(v) for v in values]
tr_scores = [s[0] for s in scores]
cv_scores = [s[1] for s in scores]
#找出评分最高的模型参数
best_score_index = np.argmax(cv_scores)
best_score = cv_scores[best_score_index]
best_param = values[best_score_index]
print('best param:{0};best score:{1}'.format(best_param,best_score))
#画出模型参数与模型评分的关系
plt.figure(figsize = (6,4),dpi = 144)
plt.grid()
plt.xlabel("threshold of entropy")
plt.ylabel('score')
plt.plot(values,cv_scores,'.g-',label = 'cross-validation score')
plt.plot(values,tr_scores,'.r--',label = 'training score')
plt.legend()
best param:0.18367346938775508;best score:0.7821229050279329
<matplotlib.legend.Legend at 0x1c8ca939f10>
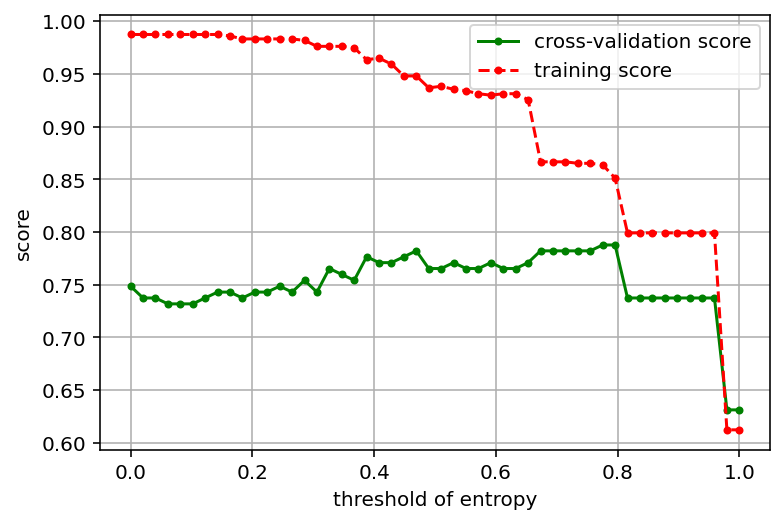
import warnings
warnings.filterwarnings("ignore") # 忽略版本问题
#训练模型并计算评分(信息熵)
def cv_score(val):
clf = DecisionTreeClassifier(criterion='entropy',min_impurity_split = val)
clf.fit(X_train,y_train)
tr_score = clf.score(X_train,y_train)
cv_score = clf.score(X_test,y_test)
return (tr_score,cv_score)
#指定参数范围,分别训练模型并计算评分
values = np.linspace(0,1,50)
scores = [cv_score(v) for v in values]
tr_scores = [s[0] for s in scores]
cv_scores = [s[1] for s in scores]
#找出评分最高的模型参数
best_score_index = np.argmax(cv_scores)
best_score = cv_scores[best_score_index]
best_param = values[best_score_index]
print('best param:{0};best score:{1}'.format(best_param,best_score))
#画出模型参数与模型评分的关系
plt.figure(figsize = (6,4),dpi = 144)
plt.grid()
plt.xlabel("threshold of entropy")
plt.ylabel('score')
plt.plot(values,cv_scores,'.g-',label = 'cross-validation score')
plt.plot(values,tr_scores,'.r--',label = 'training score')
plt.legend()
best param:0.7755102040816326;best score:0.7877094972067039
<matplotlib.legend.Legend at 0x1c8caabe130>
3.2 模型参数选择工具包
模型参数优化方法具有两个问题:
- 数据不稳定
- 不能一次选择多个参数
问题一的产生原因:
- 每次吧数据集划分为训练样本和交叉验证样本时,是随机划分的,导致每次的训练数据集是有差异的,训练出来的模型也有差异。
问题一解决方式:
- 针对模型的某个特定参数值,多次划分数据集,多次训练模型,计算出参数值对应的最高评分、最低评分及平均评分。
问题二解决方式:
- 优化代码,处理多参数组合问题。
scikit-learn在sklearn.model_selection包中提供了大量模型选择和评估的工具,以上问题可以使用GridSearchCV类来解决。
#使用GridSearchCV类选择一个参数的最优值
from sklearn.model_selection import GridSearchCV
thresholds = np.linspace(0,0.5,50)
#设置参数矩阵
param_grid = {'min_impurity_split':thresholds}
clf = GridSearchCV(DecisionTreeClassifier(),param_grid,cv=5,return_train_score=True)
clf.fit(X,y)
print("best param:{0}\nbest score:{1}".format(clf.best_params_,clf.best_score_))
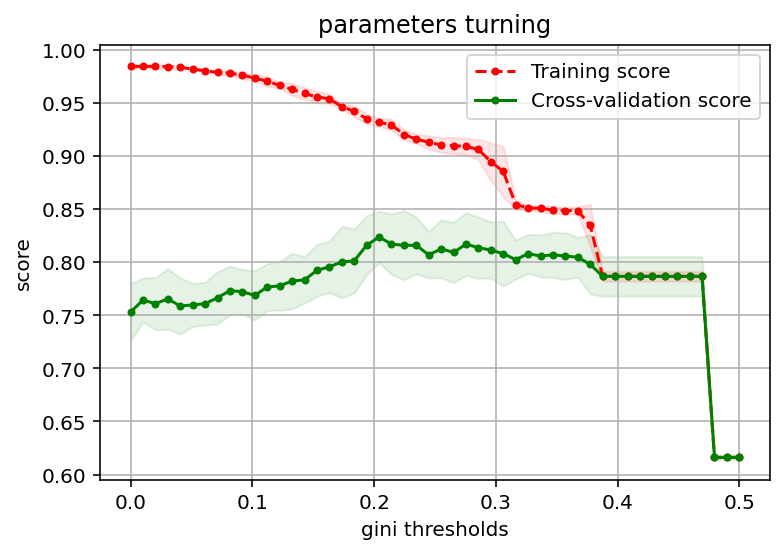
best param:{'min_impurity_split': 0.2040816326530612}
best score:0.823821480133074
-
param_grid:它是一个字典,值对应是一个列表,GridSearchCV会枚举列表里所有值用来构建模型,多次计算训练模型并计算模型评分,最后得出指定参数值的平均评分及标准差。 -
cv:用来指定交叉验证数据集的生成规则,cv = 5表示每次计算都把数据集分成5份,拿其中一份作为交叉验证数据集,其他作为训练数据集,最终得出的最优参数及最优评分保存在clf.best_params_和clf.best_score_里,clf.cv_results保存了计算过程的所有中间结果,可以利用中间结果绘制模型参数和模型评分的关系图
def plot_curve(train_sizes,cv_results,xlabel):
train_scores_mean = cv_results['mean_train_score']
train_scores_std = cv_results['std_train_score']
test_scores_mean = cv_results['mean_test_score']
test_scores_std = cv_results['std_test_score']
plt.figure(figsize = (6,4),dpi = 144)
plt.title('parameters turning')
plt.grid()
plt.xlabel(xlabel)
plt.ylabel('score')
plt.fill_between(train_sizes,
train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std,
alpha = 0.1,color = 'r')
plt.fill_between(train_sizes,
test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std,
alpha = 0.1,color = 'g')
plt.plot(train_sizes,train_scores_mean,'.--',color ='r',label='Training score')
plt.plot(train_sizes,test_scores_mean,'.-',color = 'g',label = 'Cross-validation score')
plt.legend(loc = 'best')
plot_curve(thresholds,clf.cv_results_,xlabel = 'gini thresholds')
#在多组参数之间选择最优参数
from sklearn.model_selection import GridSearchCV
entropy_thresholds = np.linspace(0,1,50)
gini_thresholds = np.linspace(0,0.5,50)
#设置参数矩阵
param_grid = [{'criterion':['entropy'],
'min_impurity_split':entropy_thresholds,},
{'criterion':['gini'],
'min_impurity_split':gini_thresholds},
{'max_depth':range(2,10)},
{'min_samples_split':range(2,30,2)}]
clf = GridSearchCV(DecisionTreeClassifier(),param_grid,cv = 5)
clf.fit(X,y)
print('best param:{0}\nbest score:{1}'.format(clf.best_params_,
clf.best_score_))
best param:{'criterion': 'entropy', 'min_impurity_split': 0.5306122448979591}
best score:0.8238340342728014
