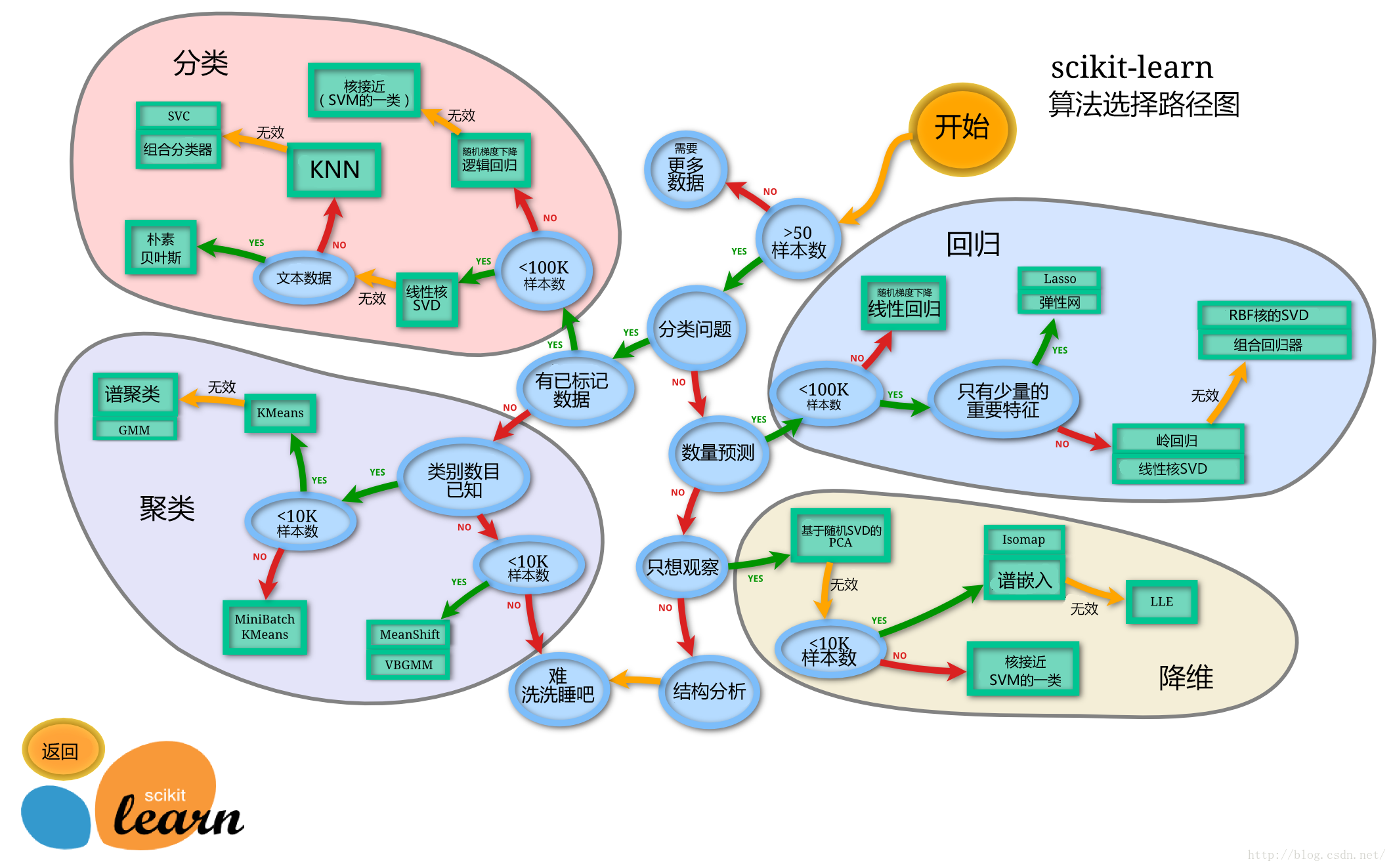
机器学习的介绍和Python机器学习安装包的介绍与使用
第一章 机器学习介绍
1.1 什么是机器学习
1、定义:即让计算机在没有被显式编程的情况下,具备自我学习的能力。
2、白话理解:机器学习是一个计算机程序,针对某个特定任务,从经验中学习,并且越做越好。
3、机器学习最重要的内容:
(1)数据:大量的经验
(2)模型:算法,对于新事件产生优质的输出
1.2 机器学习有什么用
1、语音识别:机器学习最早的应用领域 ,从最开始基于模式识别的算法演变成基于统计模型的算法,提高了语音识别的准确性。
2、自然语言处理:让机器理解文字,具有语音模型。
3、推荐系统:学习用户的使用习惯,,刻画出用户的画像,根据用户的画像去推荐用户感兴趣的商品和文章。
4、人脸识别系统
1.3 机器学习的分类
1、有监督的学习:从大量输入输出已经配对的数据中学习规律,对新输入进行输出预测。
(1)回归学习:输出结果是一个具体的数值,它的预测模型是一个连续的函数。例:通过不同特征房子对应的价格数据预测已知特征房子的价格。
(2)分类学习:输出结果是离散的数据(跳跃)。例:从已标记的邮件数据得出判断新邮件是否为垃圾邮件的模型。
2、无监督学习:学习大量无标记数据,分析数据内在的特点和结构。
1.4 机器学习应用开发的典型步骤
开发房价评估系统:对一个已知特征的房子价格进行评估预测,建立这样的系统主要包含以下几步。
1.4.1 数据采集和标记
1、训练样本(数据集):大量不同特征的房子和所对应的价格信息。尽量多收集特征。
2、数据标记:对于获取的数据担心不准确,需要去采集实际数据。
1.4.2 数据清洗
1、数据单位的统一
2、去重
3、结构化数据
1.4.3 特征选择
1、人工选择法:对逐个特征进行人工分析,然后选择合适的特征集合输入。
2、模型自动化法
1.4.4 模型选择
选择哪种模型和问题领域、数量大小、训练时长、模型的准确度等多方面有关。
1.4.5 模型训练和测试
通常按8:2或7:3来将数据集划分成训练数据集和测试数据集,用训练数据集训练模型,训练出模型参数之后用测试数据集测试模型的准确度。
1.4.6 模型性能评估和优化
1、训练时长体现了算法的训练性能。
2、判断数据集是否足够多。
3、判断模型的准确性(对于新数据是否能准确预测)
4、判断模型是否能满足应用场景的性能要求。
1.4.7 模型使用
第二章 Python机器学习安装包
2.1 开发环境搭建
1、下载Anaconda开发环境,访问其[官网](www ontinuum.io downloads)下载后直接安装即可。Anaconda中包含了所需要的所有工具包,包括IPython、Numpy、scipy、Matplotlib和scikit-learn等。
2、检查版本
(1)命令行输入ipython进入ipython环境
(2)导入库
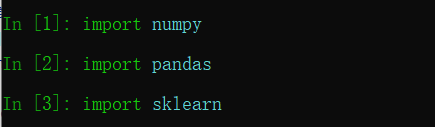
(3)版本检查

2.2 IPython简介
加强版的Python交互式命令行工具,与Python相比的明显特点:
(1)在IPython环境下可以直接执行Shell命令。
(2)具有可以直接绘图操作的Web GUI环境。
(3)更强大的交互功能,包括内省、Tab键自动完成、魔术命令等。
2.2.1 IPython基础
1、Tab键可以自动补齐函数,如果按Tab键没有作用请输入指令 pip install -U jedi0.17.2 parso0.7.1 将版本降低即可使用。
2、一些快捷键:
(1)Ctrl+A :移动光标到本行的开头:
(2)Ctrl+E :移动光标到本行的结尾:
(3)Ctrl+U :删除光标所在位置之前的所有字符;
(4)Ctrl+K :删除光标所在位置之后 的所有字符,包含当前光标所在的字符:
(5)Ctrl+L 清除当前屏幕上显示的内容;
(6)Ctr·l+P :以当前输入的字符作为命令的起始字符,在历史记录里向后搜索匹配的命令:
(7)Ctrl+N :以当前输入的字符作为命令的起始字符,在历史记录里向前搜索匹配的命令;
(8)Ctrl+C :中断当前脚本的执行。
3、在类、变量和函数后面加上一个"?"即可查看对应文档。''??"可直接查看源代码。"*?"查看命名空间下的所有函数和对象。
4、魔术命令(省略百分号请先使用指令 %automagic on):
(1)%run 文件名:即可直接运行当前目录下的文件,运行后这个文件定义的全局变量和函数就会自动引用到IPython空间中。
(2)%timeit:快速评估代码执行效率
(3)%who %whos:查看当前环境下的变量列表
(4)%quick.ref:显示 IPython 的快速参考文档
(5)%magic :显示所有的魔术命令及其详细文档;
(6)%reset :删除当前环境下的所有变量和导入的模块
(7)%logstart :开始记录 IPython 里的所有输入的命令,默认保存在当前工作目录的 ipython_log.py 中 ;
(8)%logstop:停止记录,并关闭log文件
2.2.2 IPthon图形界面
1、安装Andaconda后,Jupyter notbook会随之产生。运行后会出现一个网页版的图形编程界面(原因是jupyter在命令行中启动了一个轻量级的web服务器)。如果想要进行编程,只需创建一个python3的ipynb文件(基于json格式的文本文件)即可
例如:我们新建一个notebook画一个正弦函数。
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
# 在[0,2*PI]之间取100个点
x = np.linspace(0,2*np.pi,num=100)
# 计算这100个点的正弦值,并保存到变量y中
y = np.sin(x)
# 画出x,y,即正弦曲线
plt.plot(x,y)

2、一些快捷键
(1)Ctrl+M:在命令模式和编辑模式之间切换
命令模式下:
(1)J:焦点上移一个cell
(2)K:焦点下移一个cell
(3)A:在当前cell的上面插入一个新的cell
(4)B:在当前cell的下面插入一个新的cell
(5)DD:删除当前cell
编辑模式下:
(1)Ctrl+Enter:执行当前cell的代码。
(2)Shift+Enter:执行当前cell的代码,将焦点移动到下一个cell处,如果没有下一个cell则会自动创建一个新的cell。
2.3 Numpy简介
参考我写的博客即可:链接
2.4 Pandas简介
参考我写的博客即可:链接
2.5 Matplotlib简介
2.6 scikit-learn简介
1、定义:开源的Python语言机器学习工具包,涵盖几乎所有主流机器学习算法的实现。
2、优点:文档齐全、接口易用、算法全面。
3、缺点:不支持分布式计算,无法处理超大型数据。
2.6.1 scikit-learn示例
举例:手写数字识别(有监督学习)
数据来源:标记过的手写数字的图片。
目的:通过收集足够多手写数字样本数据,选择合适模型进行训练后验证了准确性的数据
1、数据采集和标记
(1)从scikit-learn中自带的数据集中加载手写数字识别图片的数据。
from sklearn import datasets`
digits = datasets.load_digits()
#把数据所代表的图片显示出来
images_and_labels = list(zip(digits.images,digits.target)) #标签对应图片序号打包
plt.figure(figsize = (20,5),dpi =200)
for index,(image,label) in enumerate(images_and_labels[:8]):
plt.subplot(2,4,index+1)
plt.axis('off') #去掉绘图线和轴
plt.imshow(image,cmap=plt.cm.gray_r,interpolation='nearest') #绘制灰度图,camap控制灰度参数
plt.title('Digit:%i'%label,fontsize = 20)
新知识提醒:zip(迭代器1,迭代器2),分别迭代1和2匹配打包为元组的列表,如果两个迭代器长度不一致根据短的长度为准。

2、特征选择
在正常情况下我们需要将数据保存为样本个数×特征个数格式的array对象中。
查看此数据集的数据格式。
print("shape of raw image data:{0}".format(digits.images.shape))
print("shape of data:{0}".format(digits.data.shape))
print('*'*100)
可以看到,总共有1797个训练样本,其中原始数据为8×8的图片,用来训练的数据把图片中的64个像素点全部转换为特征。接下来使用digits.data作为训练数据。
shape of raw image data:(1797, 8, 8)
shape of data:(1797, 64)
****************************************************************************************************
3、数据清洗
8×8分辨率的图片不足以让人写上数字,所以我们需要在大图片(200×200)上让人们写数字然后压缩至8×8,把收集到的不适合用来进行机器学习训练的数据进行预处理转换为适合机器学习的数据的过程就是数据清洗。
4、模型选择
后面会提到不同模型对应的效率问题,此处使用支持向量机作为手写识别算法的模型。
5、模型训练
(1)训练模型前,将数据集分为训练数据集和测试数据集(此处采用八二分制),关于变量的区别和联系,建议看链接
(2)使用训练集Xtrain和Ytrain来训练模型
(3)将训练出的模型参数保存到clf对象中,之后用其进行预测。
#数据集划分,采用cross_validation模块中的train_test_split函数
from sklearn.model_selection import train_test_split
from sklearn import svm
Xtrain,Xtest,Ytrain,Ytest = train_test_split(digits.data,digits.target,test_size = 0.20,random_state=2)
#使用支持向量机1来训练模型
clf = svm.SVC(gamma = 0.001,C=100.)
clf.fit(Xtrain,Ytrain)
clf.score(Xtest,Ytest)
0.9777777777777777
6、模型测试
(1)一旦我们拥有独立的训练集和测试集,我们就可以使用 fit 方法学习机器学习模型。 我们将使用 score 方法来测试模型,通过准确度指标比较模型的好坏。
(2)除此之外,还可以直接把测试数据集里的部分图片显示出来,并且在图片的左下角显示预测值,右下角显示真实值。
#查看预测的情况
Ypred = clf.predict(Xtest)
fig,axes = plt.subplots(4,4,figsize =(8,8))
fig.subplots_adjust(hspace = 0.1,wspace=0.1)
for i,ax in enumerate(axes.flat):
ax.imshow(Xtest[i].reshape(8,8),cmap = plt.cm.gray_r,interpolation = 'nearest')
ax.text(0.05,0.05,str(Ypred[i]),fontsize = 32,transform=ax.transAxes,color='green' if Ypred[i]==Ytest[i] else 'red')
ax.text(0.8,0.05,str(Ytest[i]),fontsize = 32,transform = ax.transAxes,color = 'black')
ax.set_xticks([])
ax.set_yticks([])

7、模型的保存与加载
当对准确性满意后就可以将模型保存以便下次预测。
# 保存模型参数
import joblib
joblib.dump(clf,'digits_svm.pkl')
# 导入模型参数,直接进行预测
clf1 = joblib.load('digits_svm.pkl')
clf1.score(Xtest,Ytest)
0.9777777777777777
2.6.2 scikit-learn 一般性原理和通用规则
1、评估模型对象
scikit-learn所有算法都以一个评估模型对象来对外提供接口。创建评估对象的时候可以指定不同的参数,其直接影响评估模型训练时的效率以及准确性。(例如在上面程序中的SVC函数中添加参数)
2、模型接口(将不同算法抽象出来,对外提供一致接口)
(1)fit()接口:scikit-learn中所有评估模型对象都具有。
(2)pridict()接口:针对所有的有监督机器学习算法,可以预测经过训练的模型,用来输出一个待预测的数据,属于各种类型的可能性,针对分类问题直接返回可能性最高的类别。无监督的机器学习算法中主要用来进行聚类分析,即把新数据归入某个聚类中。
(3)score()接口:几乎所有模型都提供,用来评价一个模型的好坏,得分越高越好。
3、模型检验
检测经过训练后的模型,出了模型提供的score()接口外,还有一系列检测模型性能的方法。
4、模型选择