Day03-基础篇(四)Pandas与数据清洗
一、基本介绍
1、Pandas之所以使用频率高的原因:
(1)Pandas提供的基础数据结构DataFrame和json的契合度高,转换起来方便。
(2)对于不复杂大数据清理工作采用Pandas可以快速对数据进行规整。
2、Series(创建一维序列)
(1)定义:定长的字典序列(相当于存储了两个ndarray)。
(2)基本属性:index和values,index默认为0,1,2...递增的整数序列,我们也可以自己指定索引。
import pandas as pd from pandas import Series,DataFrame #以默认index创建series x1 = Series([1,2,3,4]) #以规定index创建series x2 = Series(data = [1,2,3,4],index = ['a','b','c','d']) print(x1) print(x2)
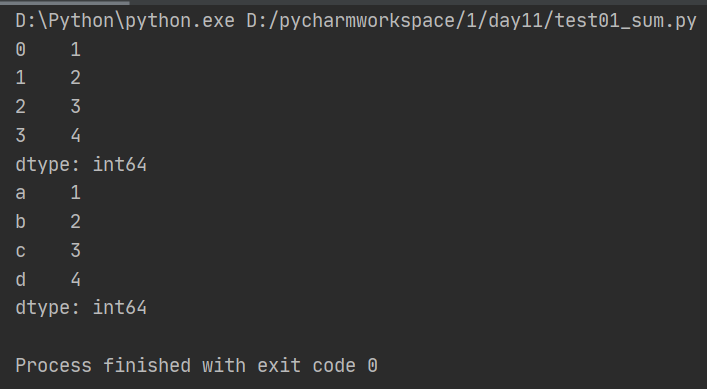
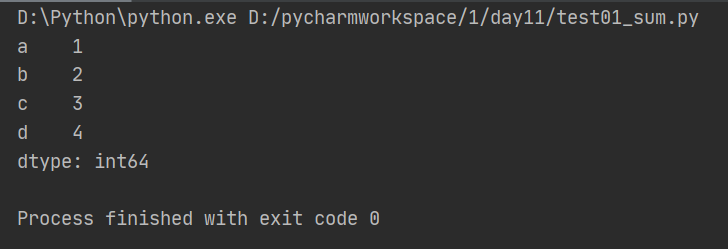
(3)采用字典的方式创建Series
import pandas as pd from pandas import Series,DataFrame #先创建数组,再用数组创建series d = {'a':1,'b':2,'c':3,'d':4} x3 = Series(d) print(x3)
3、DataFrame(二维表结构)
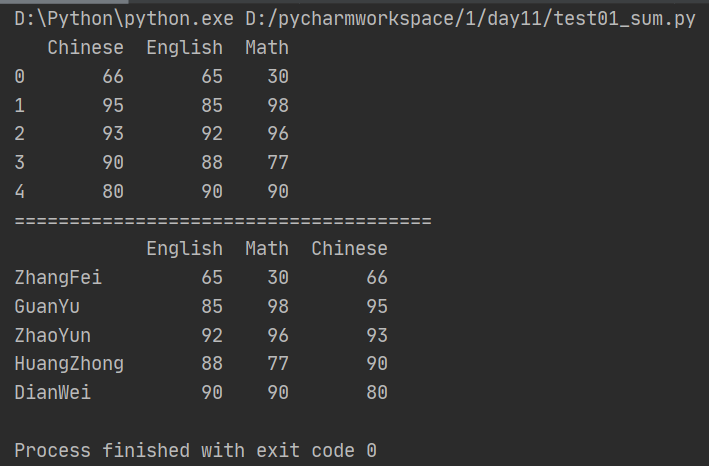
(1)定义:类似数据库表,包含行索引和列索引,可以看成是由相同索引的Series组成的字典类型。(一个索引对应多个数值)
import pandas as pd from pandas import Series,DataFrame data = {'Chinese':[66,95,93,90,80],'English':[65,85,92,88,90],'Math':[30,98,96,77,90]} #以字典的数据为基础创建df1表结构 df1 = DataFrame(data) #默认行索引为整数序列 #column可以规定字典设置的列索引 df2 = DataFrame(data,index=['ZhangFei','GuanYu','ZhaoYun','HuangZhong','DianWei'], columns=['English','Math','Chinese']) print(df1) print('======================================') print(df2)
4、数据导入和输出
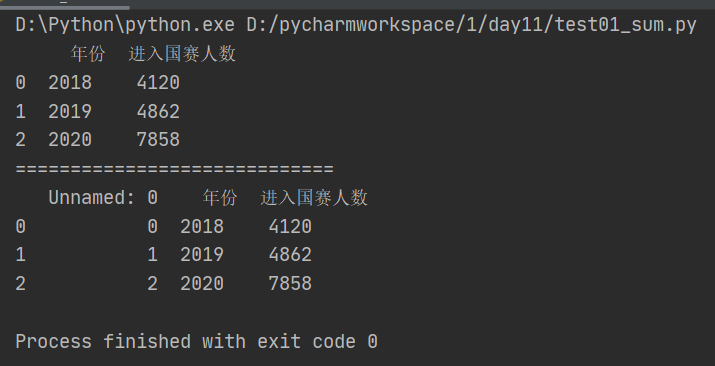
Pandas允许从xlsx,csv等文件中导入数据并输出。
import pandas as pd from pandas import Series,DataFrame score = DataFrame(pd.read_excel('D:\Personal\大一下学期\计算机\科研立项\进入国赛人数.xlsx')) score.to_excel('D:\Personal\大一下学期\计算机\科研立项\data.xlsx') print(score) score1 = DataFrame(pd.read_excel('D:\Personal\大一下学期\计算机\科研立项\data.xlsx')) print('=============================') print(score1)
5、数据清洗
(1)删除DataFrame中的不必要的列或者行,采用drop()函数即可快速删除
import pandas as pd from pandas import Series,DataFrame data = {'Chinese':[66,95,93,90,80],'English':[65,85,92,88,90],'Math':[30,98,96,77,90]} df2 = DataFrame(data,index=['ZhangFei','GuanYu','ZhaoYun','HuangZhong','DianWei'], columns=['English','Math','Chinese']) print(df2) #删除DataFrame中不必要的列或行 df2 = df2.drop(columns=['Chinese']) #删除语文列 df2 = df2.drop(index = ['ZhangFei']) #删除张飞行 print(df2)
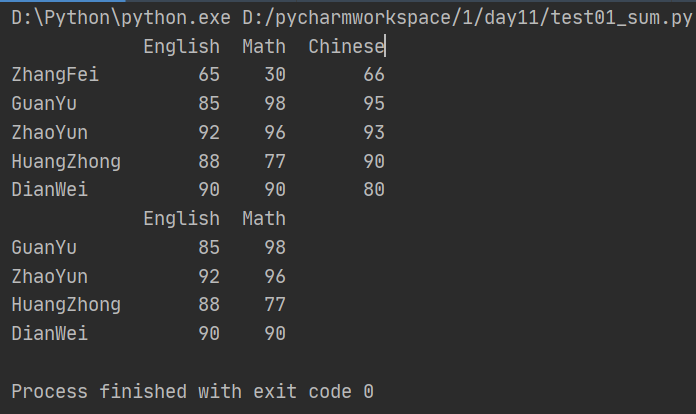
(2)重命名行或列(rename)
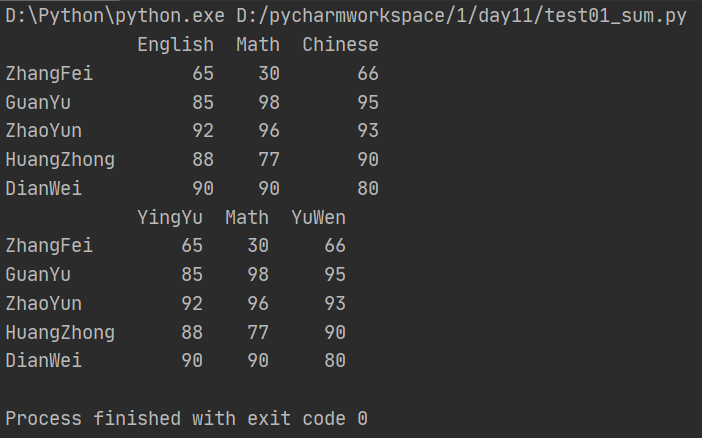
import pandas as pd from pandas import Series,DataFrame data = {'Chinese':[66,95,93,90,80],'English':[65,85,92,88,90],'Math':[30,98,96,77,90]} df2 = DataFrame(data,index=['ZhangFei','GuanYu','ZhaoYun','HuangZhong','DianWei'], columns=['English','Math','Chinese']) print(df2) #重命名列名 df2.rename(columns={'Chinese':'YuWen','English':'YingYu'},inplace = True) print(df2)
(3)去重复的值(drop_duplicates)
自动去除重复的行
df = df.drop_duplicates() #去除重复行
(4)更改数据格式(astype)
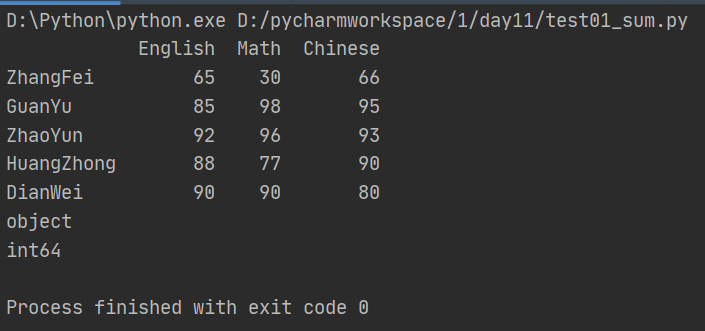
import numpy as np import pandas as pd from pandas import Series,DataFrame data = {'Chinese':[66,95,93,90,80],'English':[65,85,92,88,90],'Math':[30,98,96,77,90]} df2 = DataFrame(data,index=['ZhangFei','GuanYu','ZhaoYun','HuangZhong','DianWei'], columns=['English','Math','Chinese']) print(df2) #格式转换 df2['Chinese'] = df2['Chinese'].astype('str') print(df2['Chinese'].dtype) df2['Chinese'] = df2['Chinese'].astype(np.int64) print(df2['Chinese'].dtype)
(5)数据间空格的删除
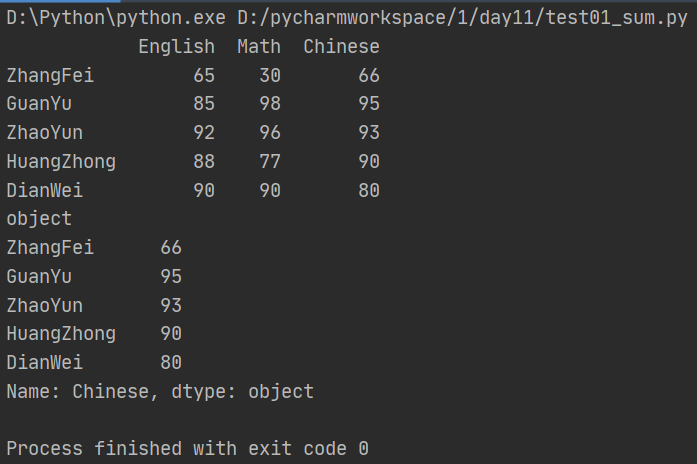
在把数据格式转化成str之后,是为了方便对数据进行操作,要删除数据间的空格,我们需要引入strip函数:(map的作用是将strip函数施加到Chinese字段的每一个数据上)
import numpy as np import pandas as pd from pandas import Series,DataFrame data = {'Chinese':[66,95,93,90,80],'English':[65,85,92,88,90],'Math':[30,98,96,77,90]} df2 = DataFrame(data,index=['ZhangFei','GuanYu','ZhaoYun','HuangZhong','DianWei'], columns=['English','Math','Chinese']) print(df2) #格式转换 df2['Chinese'] = df2['Chinese'].astype('str') print(df2['Chinese'].dtype) #删除左右两边的空格 df2['Chinese'] = df2['Chinese'].map(str.strip) #删除左边空格 df2['Chinese'] = df2['Chinese'].map(str.lstrip) #删除右边空格 df2['Chinese'] = df2['Chinese'].map(str.rstrip) print(df2['Chinese'])
(6)删除特殊符号的方法
df2['Chinese']=df2['Chinese'].str.strip('$')
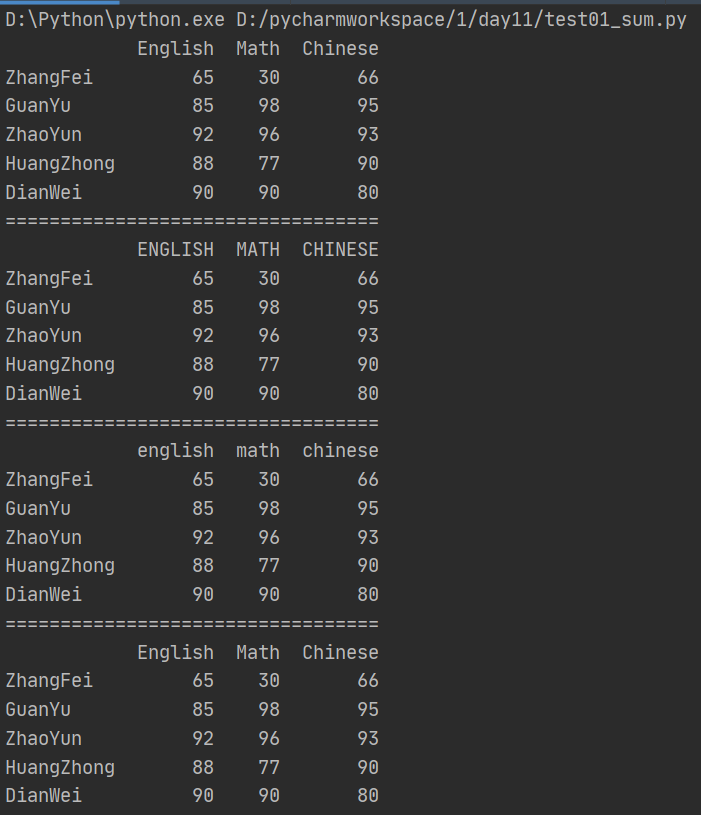
(7)大小写转换
import numpy as np import pandas as pd from pandas import Series,DataFrame data = {'Chinese':[66,95,93,90,80],'English':[65,85,92,88,90],'Math':[30,98,96,77,90]} df2 = DataFrame(data,index=['ZhangFei','GuanYu','ZhaoYun','HuangZhong','DianWei'], columns=['English','Math','Chinese']) print(df2) print('==================================') #全部大写 df2.columns = df2.columns.str.upper() print(df2) print('==================================') #全部小写 df2.columns = df2.columns.str.lower() print(df2) print('==================================') #首字母大写 df2.columns = df2.columns.str.title() print(df2) print('==================================')
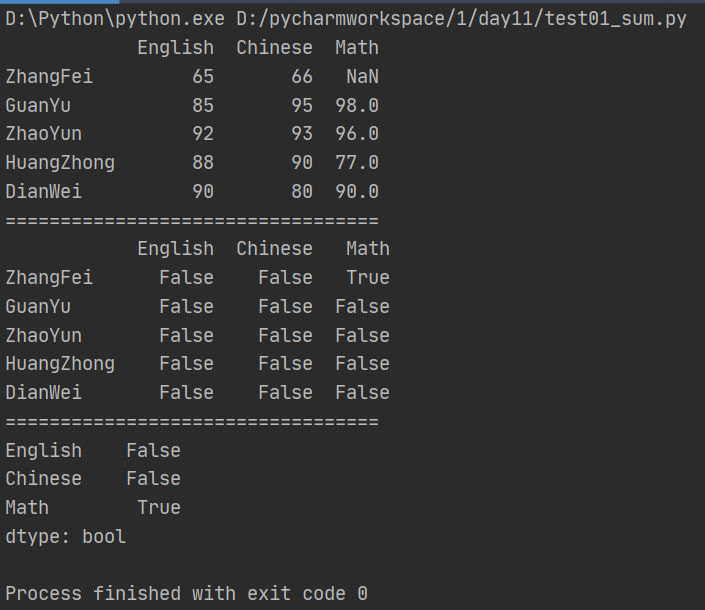
(8)查找空值
直接查看具体位置的空值采用isnull()方法,查看某列存在空值要采用isnull().any()方法
import numpy as np import pandas as pd from pandas import Series,DataFrame data = {'Chinese':[66,95,93,90,80],'English':[65,85,92,88,90],'Math':[None,98,96,77,90]} df2 = DataFrame(data,index=['ZhangFei','GuanYu','ZhaoYun','HuangZhong','DianWei'], columns=['English','Chinese','Math']) print(df2) print('==================================') print(df2.isnull()) print('==================================') print(df2.isnull().any())
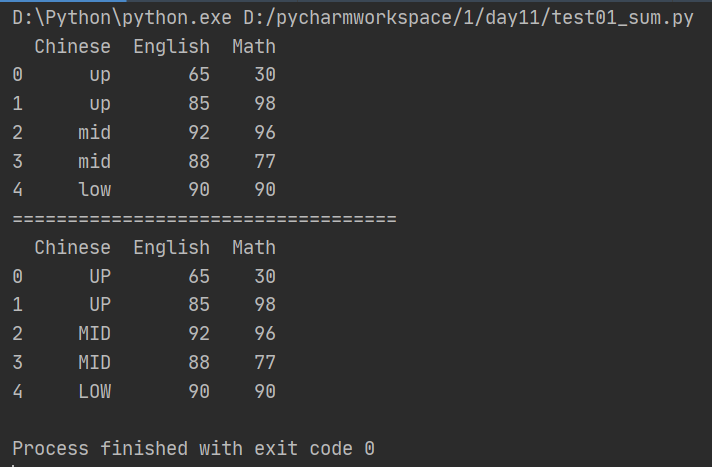
6、使用apply函数进行数据清洗。
(1)对name列所有数值进行大写转化
import pandas as pd from pandas import Series, DataFrame data = {'Chinese': ['up', 'up', 'mid', 'mid','low'],'English': [65, 85, 92, 88, 90],'Math': [30, 98, 96, 77, 90]} df= DataFrame(data) print(df) print('===================================') df['Chinese'] = df['Chinese'].apply(str.upper) print(df)
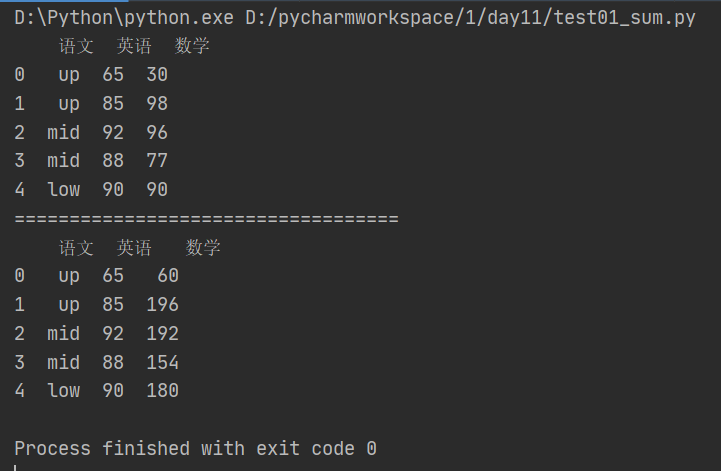
(2)也可以在apply函数中使用自定义函数对数据进行处理
import pandas as pd from pandas import Series, DataFrame data = {'语文': ['up', 'up', 'mid', 'mid','low'],'英语': [65, 85, 92, 88, 90],'数学': [30, 98, 96, 77, 90]} df= DataFrame(data) print(df) print('===================================') #定义一个可以将原数组*2的函数 def double_df(x): return 2*x df['数学'] = df['数学'].apply(double_df) print(df)
(3)对定义函数中对原def进行修改后返回再重新应用,axis=1代表按列进行操作,args为传递的参数,对应def中传入的两个参数,从而生成新的def
import pandas as pd from pandas import Series, DataFrame data = {'语文': ['up', 'up', 'mid', 'mid','low'],'英语': [65, 85, 92, 88, 90],'数学': [30, 98, 96, 77, 90]} df= DataFrame(data) print(df) print('===================================') #定义一个可以增加新列的函数 def plus(df,m,n): df['new1'] = (df['数学']+df['英语'])*m df['new2'] = (df['数学']+df['英语'])*n return df df = df.apply(plus,axis = 1,args = (2,3,)) print(df)
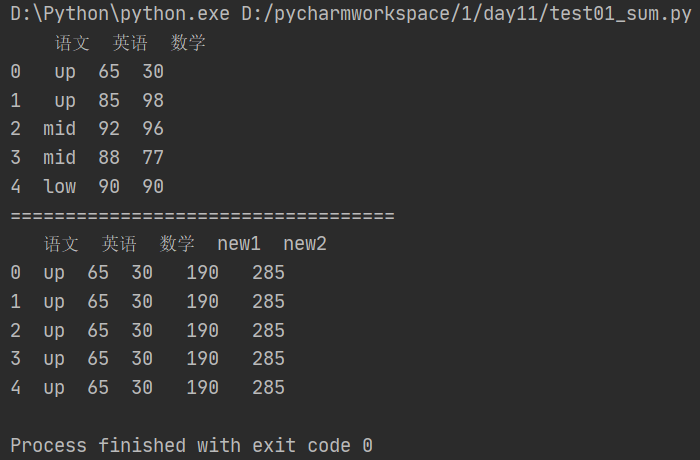
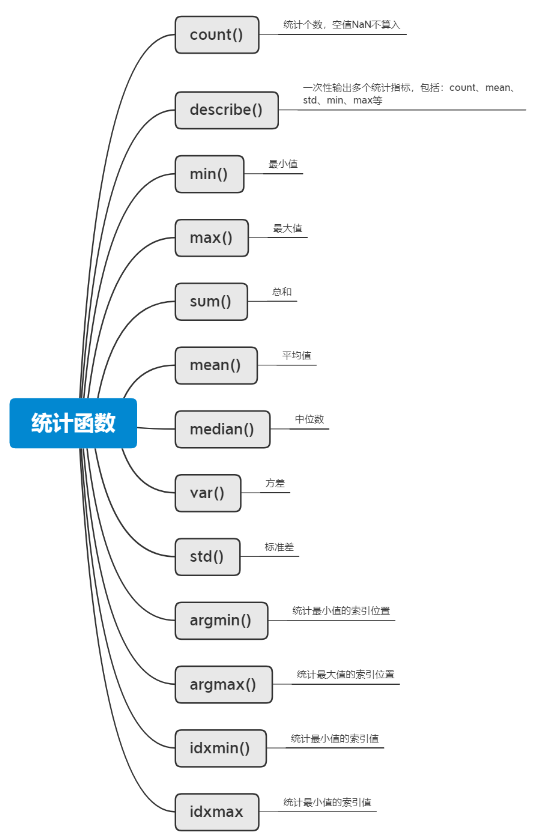
7、数据统计
(1)统计函数部分有很多和numpy库已知,只做简单介绍,具体操作请查看numpy进行辅助学习即可。包含的函数有:
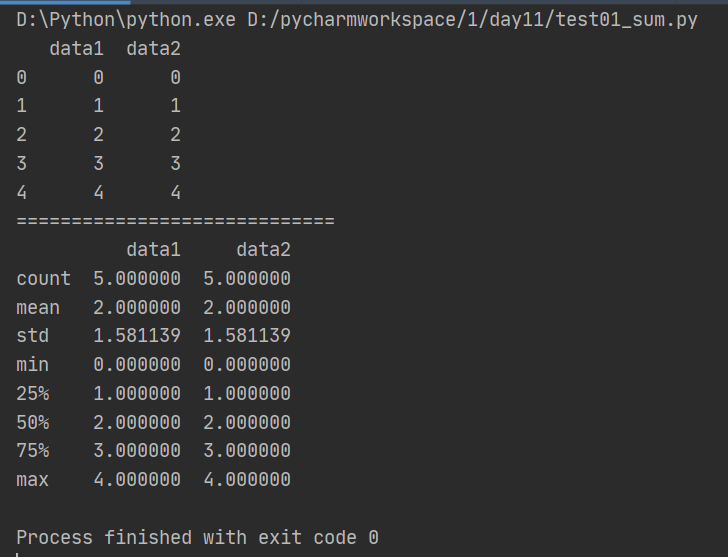
(2)describe()函数快速了解数据
import pandas as pd from pandas import Series, DataFrame df = DataFrame({'data1':range(5),'data2':range(5)}) print(df) print('=============================') print (df.describe())
8、数据表合并(merge()函数)
(1)创建两个数据表
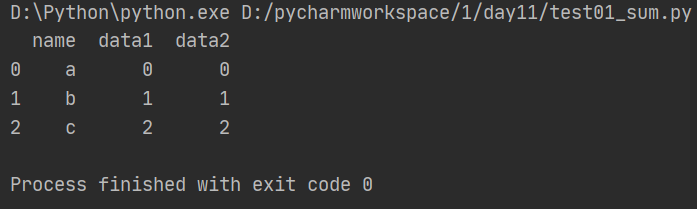
import pandas as pd from pandas import Series, DataFrame df1 = DataFrame({'name':['a','b','c','d','e'],'data1':range(5)}) df2 = DataFrame({'name':['A','B','C','D','E'],'data2':range(5)})
(2)基于指定列进行连接
import pandas as pd from pandas import Series, DataFrame df1 = DataFrame({'name':['a','b','c','d','e'],'data1':range(5)}) df2 = DataFrame({'name':['a','b','c','D','E'],'data2':range(5)}) #基于'name'进行链接 df3 = pd.merge(df1,df2,on='name') print(df3)
(2)inner内连接
inner内链接使merge合并的默认情况,其就是键的交集,基于相同的键进行字段链接.
import pandas as pd from pandas import Series, DataFrame df1 = DataFrame({'name':['a','b','c','d','e'],'data1':range(5)}) df2 = DataFrame({'name':['a','b','c','D','E'],'data2':range(5)}) df3 = pd.merge(df1, df2, how='inner') print(df3)
(3)left左连接(右连接和左连接相反)
左连接是以第一个DataFrame为主进行的连接
import pandas as pd from pandas import Series, DataFrame df1 = DataFrame({'name':['a','b','c','d','e'],'data1':range(5)}) df2 = DataFrame({'name':['a','b','c','D','E'],'data2':range(5)}) df3 = pd.merge(df1, df2, how='left') print(df3)
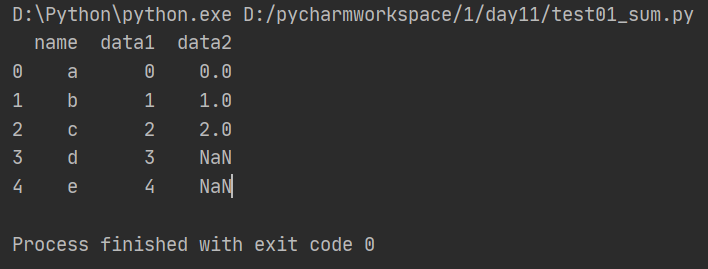
(4)outer外连接
外连接相同于求两个DataFrame的并集
import pandas as pd from pandas import Series, DataFrame df1 = DataFrame({'name':['a','b','c','d','e'],'data1':range(5)}) df2 = DataFrame({'name':['a','b','c','D','E'],'data2':range(5)}) df3 = pd.merge(df1, df2, how='outer') print(df3)

