
热点数据多级缓存方案实现(进行中)
热点数据多级缓存方案实现
集成CountMinSketch过滤器+本地缓存caffeine+redis缓存+数据库的多级缓存方案
涉及技术点:
- caffeine本地缓存
- redis:lua脚本、redis事务的原子性
- CountMinSketch算法,原来已有相似技术 counting Bloom filter
- 设计思想:计算向数据端迁移
1,背景概述
我们系统在使用过程中,并非所有的数据都是时刻活跃的状态,一般情况下只有少部分的活跃数据占据大量的请求。所以,我们在将其他非活跃数据也存放于redis缓存或者本地缓存时,是非常浪费内存资源的一种方式(钱多、机器多的可以无视这个)。
所以为了解决上述浪费内存资源的情况,我们一般将热点数据(当前时间段访问频繁的数据)放入缓存中从而用于加快数据的响应速度,举一个生活中的实例:我们平时看视频网站中的视频,如果是当前热播的视频,我们点开后加载速度相对于那些冷门的视频速度快很多。这个就是因为这些视频网站,将热门视频数据也是放置在缓存中,冷门数据还是存储在磁盘中(节省费用)。
当前热点数据缓存主要有如下几个解决方案:
- 使用本地缓存,例如caffeine、guava、或者自定义缓存。
- 它们直接在单节点服务中使用堆内存进行热点数据的缓存;
- 优点:响应及时、读并发响应及时;
- 缺点:
- ①消耗堆内存;
- ②如果缓存中不存在需要查询数据库(缓存穿透),如果是多节点服务,每个节点都需要重复查询数据库,造成数据库查询并发量高;
- ③已删除数据不容易进行多节点同步;
- 使用redis缓存
- 直接使用redis中间件的内存操作功能实现热点数据缓存
- 优点:可以响应多节点请求与数据一致性同步
- 缺点:
- ①相较于本地缓存来说,此方案需要额外的网络通信耗时;
- ②由于redis的单线程数据操作,当有大key等耗时指令时,其他请求需要进行排序等待;
- ③需要依赖中间件;
- ④并发相对于本地缓存来说要低一些;
- ⑤如果缓存中不存在需要查询数据库(缓存穿透);
- ⑥热点数据的缓存策略算法没有caffeine等缓存框架优秀(redis只有单纯的LRU、LFU、TTL等简单驱逐策略),热点数据命中率低;
另外,在进行数据缓存时,我们还经常遇到缓存穿透的问题(查询不存在或者冷门的数据,这个操作会查询至数据库,并发量如果很高容易导致服务崩溃),一般情况下我们可以使用布隆过滤器来解决该问题,但是布隆过滤器也有自身的问题(只能新增数据,不能删除历史数据)。
因此总结上述常用缓存方案存在的问题:
- 两种方案都存在的缓存穿透问题,同时使用布隆过滤器解决缓存穿透又无法删除历史数据;
- 本地缓存与redis缓存各有优缺点;
这里为了解决上述的两个问题提出了如下的方案【集成CountMinSketch过滤器+本地缓存caffeine+redis缓存+数据库的多级缓存方案】:
- 利用Count-Min Sketch算法解决缓存穿透的问题:
- ①与布隆过滤器一样,解决查询客观不存在数据时,直接穿透缓存-查询数据库的问题;
- ②优化布隆过滤器中,不能删除历史数据的缺陷;
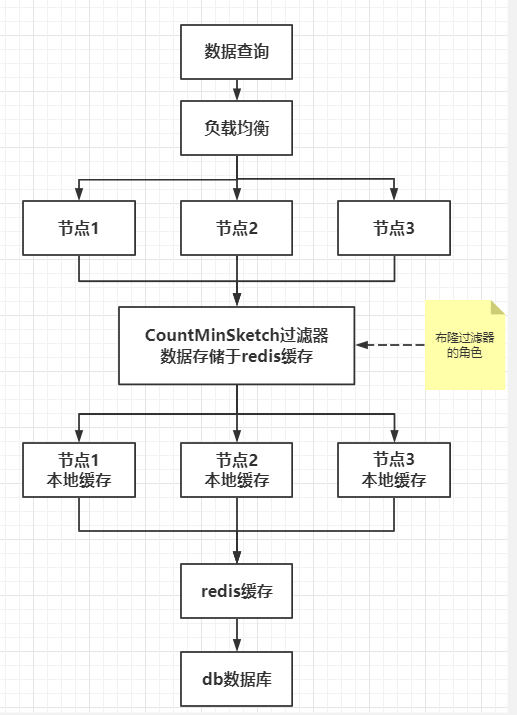
- 利用多级缓存解决之前2种缓存方案存在的缺陷:
- ①多节点查询客观存在的数据,如果本地缓存不存在该数据,现在是直接查询redis缓存,由redis缓存只查询一次数据库;
- ②由于存在redis用于存储CountMinSketch过滤器的key是否存在的数据信息,并且该过滤器中的历史数据可以被删除,所以保证了每个节点的本地缓存数据一致性;
- ③现在使用本地缓存消除了之前redis缓存需要额外网络通信的问题,并且继承了本地缓存的缓存算法优势,保证了缓存命中率;
同时,也需要额外说明该实现的方案的缺点:
- 实现相对复杂,逻辑依赖redis和数据库
- 解决方案:后续将Caffeine本地缓存和redis缓存的操作提取出来,然后利用AOP切面技术来代理,程序员使用该框架时只需要在dao层方法,加一个注解即可,无需大量代码逻辑改动
- 当前不支持数据的修改,只支持删除和新增
- 解决方案:后续可以通过RPC调用或者http调用的方式,实现单节点修改数据库中的value值后,先修改redis中的value值,然后同步删除其他节点本地缓存数据。从而当其他节点查询相同数据时,可以从redis中获取更新数据,同步更新至本地缓存
maven依赖:
<dependency>
<groupId>site.activeclub</groupId>
<artifactId>cache-multipe</artifactId>
<version>1.0.0-SNAPSHOT</version>
</dependency>
核心注解:
(将如下注解分别添加至dao层的对应的方法上,无需关注内部实现)
@ActiveclubCacheSelect // 查询
@ActiveclubCacheUpdate // 修改
@ActiveclubCacheDelete // 删除
核心配置:
activeclub.cache.local.enable=true # 默认值为true,false表示不使用本地缓存
activeclub.cache.redis.enable=true # 默认值为true,false表示不使用redis缓存
activeclub.cache.sync.enable=true # 修改操作是否进行数据同步
activeclub.cache.sync.type=http # 默认使用http请求方式,如果选择rpc需要额外依赖dubbo
2,技术原理
本处的多级缓存方案的结构图如下:
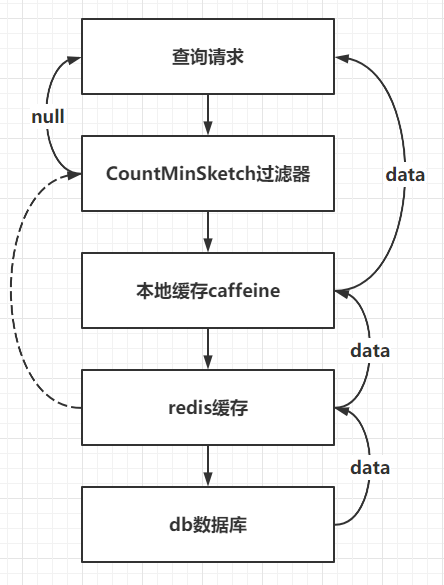
逻辑流程图:
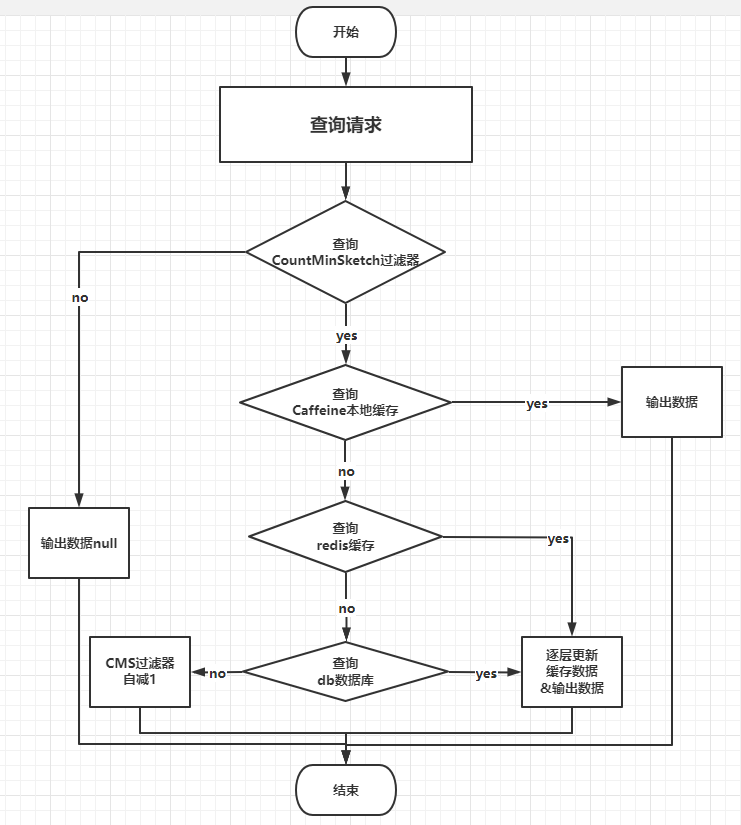
流程描述:
-
外部查询请求进入,先查询CountMinSketch过滤器
- 如果过滤器中,不存在该数据,直接返回null,然后结束流程
- 如果过滤器中,存在该数据,直接进入第2步
-
查询caffeine本地缓存
- 如果本地缓存中,存在该数据,直接返回数据,然后结束流程
- 如果本地缓存中,不存在该数据,则进行第3步进行查询,
- 查询结果为null,则直接返回给调用方
- 查询结果不为null,则更新至本地缓存后,返回结果数据,然后结束流程
-
查询redis缓存
- 如果redis缓存中,存在该数据,重置过期时间,返回该数据
- 如果redis缓存中,不存在该数据,则进入第4步进行查询,
- 查询结果为null,直接返回给调用方
- 查询结果不为null,则更新至redis缓存后,返回给数据调用方
-
查询db数据库
- 如果db数据库中,存在该数据,则直接返回给调用方
- 如果db数据库中,不存在该数据,则将该key值对应于CountMinSketch过滤器中数据自减1,然后将null值返回给调用方
3,代码实现
4,注意事项
5,疑问解答
- 之前面试的时候,有面试官认为查询CountMinSketch过滤器的时候,都已经查询过redis,那么为什么不在这次查询的时候直接把数据返回?反而搞这么复杂的逻辑呢?
- ①首先,我们已经简述过本地缓存caffeine相对于redis缓存的优势,这个是我们为什么尽量使用caffeine本地缓存,而将redis缓存作为辅助的原因。
- caffeine的缓存算法更优,命中率更高,并发量也更高(算法优势)
- 本地缓存查询数据直接使用的堆内存数据,无需额外网络通信消耗,响应更快(类比于计算机CPU的三级缓存机制)
- ②其次,我们查询redis中的CountMinSketch过滤器时是将运算向数据迁移,最终只需要获取redis返回的该key值是否存在的布尔值即可,网络消耗很少(后续还可以进一步在redis中自定义查询函数,更加精简查询命令传输)
- ①首先,我们已经简述过本地缓存caffeine相对于redis缓存的优势,这个是我们为什么尽量使用caffeine本地缓存,而将redis缓存作为辅助的原因。
参考链接
探究未知是最大乐趣


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)