
Caffeine缓存框架
Caffeine缓存框架
本篇博文涉及技术点:
-
FIFO、LRU、LFU、Guava
-
java引用
- 强引用(非垃圾不会被清除)
- 软引用SoftReference(内存不足时清除)
- 弱引用WeakReference(gc时删除)
- 虚引用PlatformQueue
-
W-TinyLFU算法(window cache、SLRU、TinyLFU)、Count-Min Sketch算法、布隆过滤器
-
时间轮(TimerWheel)算法,多层时间轮(hierarchical timing wheels )算法
-
编程思想:
- 数据库系统undolog、redolog的 WAL(Write-Ahead Logging)思想,即先写日志再执行操作
- MPSC(Multiple Producer / Single Consumer)思想多生产者,单个消费者
-
消除伪共享
学习这个Caffeine缓存框架还是很有意思的,可以同步学习到的知识点很多
1,概述
我们为了加快访问速度、提供性能,通常会使用到很多缓存机制,例如:mybatis一级缓存机制,MySQL自己的持久化缓存机制等等。
我们通常使用的redis也可以看做一种缓存,它可以大大的提高我们的访问并发性,但是在分布式系统中由于网络不可靠问题,我们也不能全部依赖redis缓存,为了进一步加快速度,我们还可以使用本地缓存。例如之前google的guava缓存,以及今天要着重介绍的caffeine缓存。
2,各种缓存综述
2.1, FIFO
Fist in first out 先进先出:最先进入的缓存被最先淘汰掉,这个基本不会有人用来做缓存
2.2,LRU
Least recently used 最近最少未使用:每次访问就把这个元素放到队列头部,队列满了淘汰队列尾的元素,也就是淘汰最长时间没有被访问的。
在HashMap的链式法增加新的引用形成一个双向链表,即是一个HashMap又是一个链表,这样输出即有序,也可以根据访问来动态调整顺序,HashMap+LinkedList(java容器中的LinkedHashMap就可以直接实现改功能)。
达到FIFO或者LRU的特点,可以明显看出这个存在的问题,线程不安全,需要额外加锁,功能结构单一,没有过期时间容易存在内存泄露。
缺点也是很明显的,某一时刻大量数据的到来容易把热点数据挤出缓存,而这些数据却是只访问了一次的,今后不会再访问了的或者访问频率极低的
2.3,LFU
Least frequently used 最不经常使用:也就是淘汰一定时期内被访问次数最少的页,这个和LRU区别是这个讲究的是一定时期中的次数也就是频率最低的被淘汰。
这个能避免LRU的缺点,因为是根据频率淘汰,不会出现大量进进来的挤压掉老的,如果在数据的访问的模式不随时间变化时候,LFU将会提供绝佳的命中率。但是如果访问模式随着时间而变化(即缓存元素随着时间增大访问次数越小),新进来的被快速淘汰,因为刚刚进来的频率最低,之前老缓存的频率太高。并且它需要额外空间维护频率这个属性,如果建立一个HashMap维护这个属性,当数据量大的情况下,那么这个HashMap也会十分大。
2.4,Guava
Guava是google公司开发的一款Java类库扩展工具包,内含了丰富的API,涵盖了集合、缓存、并发、I/O等多个方面。使用这些API一方面可以简化我们代码,使代码更为优雅,另一方面它补充了很多jdk中没有的功能,能让我们开发中更为高效。
在平常开发过程中,很多情况需要使用缓存来避免频繁SQL查询或者其他耗时操作,会采取缓存这些操作结果给下一次请求使用。如果我们的操作结果是一直不改变的,其实我们可以使用 ConcurrentHashMap 来存储这些数据;但是如果这些结果在随后时间内会改变或者我们希望存放的数据所占用的内存空间可控,这样就需要自己来实现这种数据结构了。
缺点:
- 使用谷歌提供的ConcurrentLinkedHashMap有个漏洞,那就是缓存的过期只会发生在缓存达到上限的情况,否则便只会一直放在缓存中。咋一看,这个机制没问题,是没问题,可是却不合理,举个例子,有玩家上线后加载了一堆的数据放在缓存中,之后便不再上线了,那么这份缓存便会一直存在,知道缓存达到上限。(缺点:浪费内存)
- ConcurrentLinkedHashMap没有提供基于时间淘汰时间的机制;
3,Caffeine
3.1,性能优势:
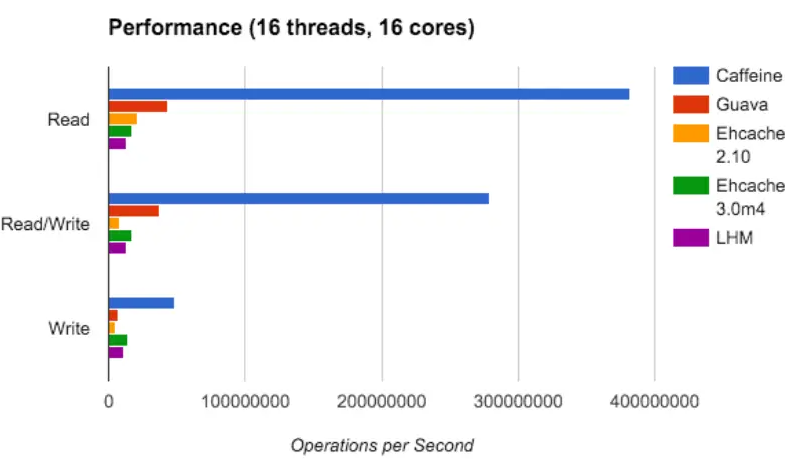
性能优势对比:
- Caffeine支持异步加载方式,直接返回CompletableFutures,相对于GuavaCache的同步方式,它不用阻塞等待数据的载入;
- GuavaCache是基于LRU的,而Caffeine是基于LRU和LFU的(W-TinyLFU算法),结合了两者的优点;
- Caffeine另外一个比较快的原因,就是很多操作都使用了异步操作,把这些事件提交到队列里。队列使用的RingBuffer;
- 目前Spring也在推荐使用,caffeine在springboot2.0开始替代guava

3.2,结构
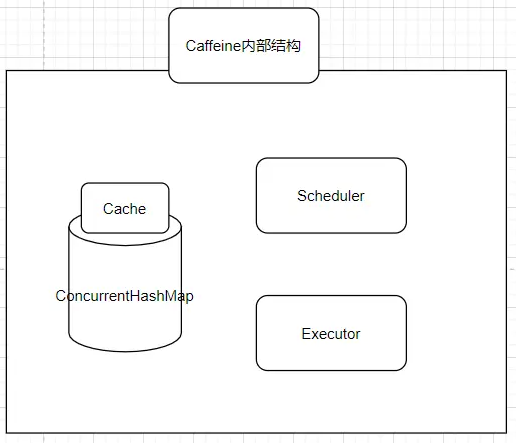
- Cache的内部包含着一个ConcurrentHashMap,这也是存放我们所有缓存数据的地方,众所周知,ConcurrentHashMap是一个并发安全的容器,这点很重要,可以说Caffeine其实就是一个被强化过的ConcurrentHashMap;
- Scheduler(定时器),定期清空数据的一个机制,可以不设置,如果不设置则不会主动的清空过期数据;
- Executor,指定运行异步任务时要使用的线程池。可以不设置,如果不设置则会使用默认的线程池,也就是ForkJoinPool.commonPool();
3.3,实现原理
caffeine底层架构图
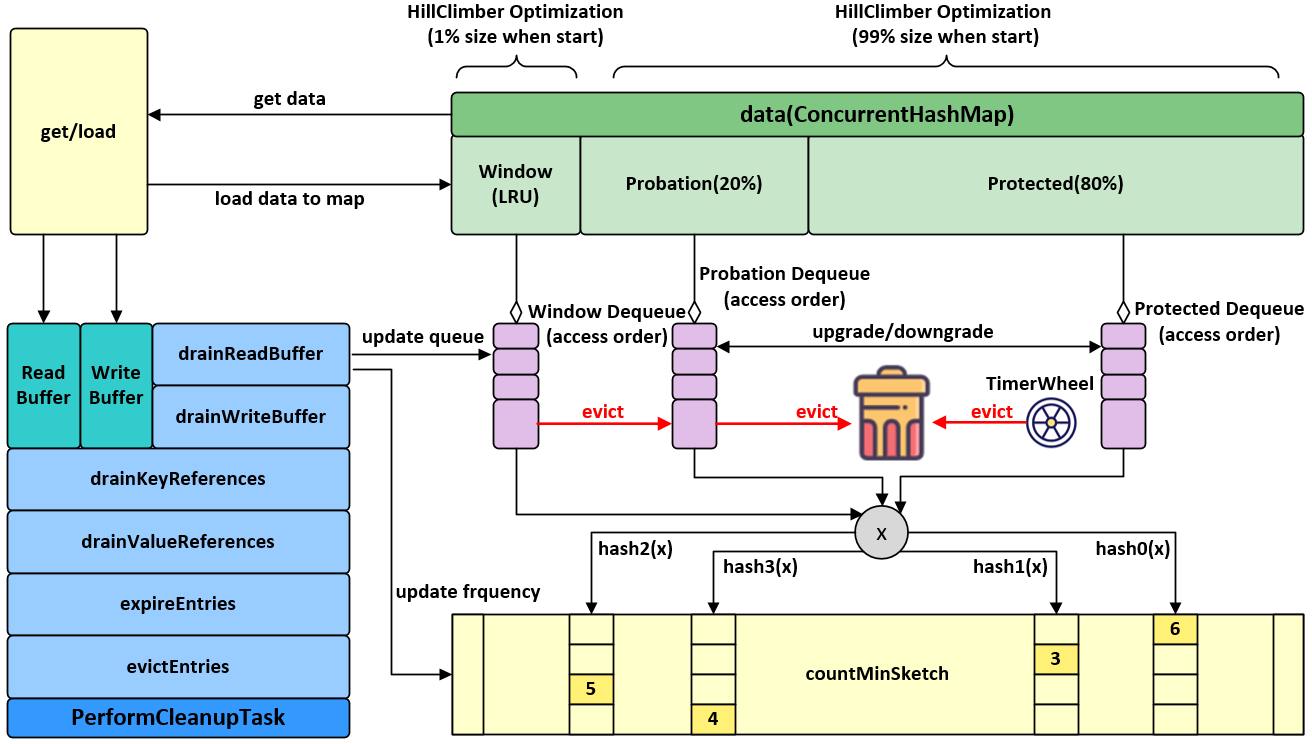
3.3.1,执行流程
- 通过put操作将数据放入data属性中(ConcurrentHashMap)
- 创建AddTask任务,放入(offer)写缓存:writeBuffer
- 从writeBuffer中获取任务,并执行其run方法,追加记录频率:frequencySketch().increment(key)
- 往window区写入数据
- 如果数据超过window区大小,将数据移到probation区
- 比较从window区晋升的数据和probation区的老数据的频率,输者被淘汰,从data中删除
3.3.2,cache内部结构

它包含如下的几个结构:
- TinyLFU模块,用于估算统计各个key值的请求频率
- SLRU(Segmented LRU,即分段 LRU)、包括一个名为 protected 和一个名为 probation 的缓存区,通过增加一个缓存区(即 Window Cache),当有新的记录插入时,会先在 window 区呆一下,就可以避免上述说的 sparse bursts 问题。
- window cache新手保护缓存(其本质就是一个LRU缓存)
上述结构结合就组成了我们下面要介绍的W-TinyLFU算法的核心部件!
3.3.3,W-TinyLFU算法
caffeine内部的核心算法是 W-TinyLFU,它是LFU的优化版本。
先说一下LFU的两个缺点:
- 需要给每个记录项维护频率信息,每次访问都需要更新,这是个巨大的开销
- 对突发性的稀疏流量响应迟钝,因为历史的数据已经积累了很多次计数,新来的数据肯定是排在后续的
上述2个的问题解决办法
1.针对第一个问题W-TinyLFU 采用了 Count–Min Sketch算法
Count–Min Sketch算法是一个频率估计算法,它思想类似于Bloom Filter布隆过滤器,只不过在布隆过滤器的基础上额外增加了一个计数的操作,它的流程如下
①选定d个hash函数,开一个 d & m 的二维整数数组作为哈希表
②对于每个元素,分别使用d个hash函数计算相应的哈希值,并对m取余,然后在对应的二维数组位置上增1,二维数组中的每个整数称为sketch
③要查询某个元素的频率时,只需要取出d个sketch, 返回最小的那一个(其实d个sketch都是该元素的近似频率,返回任意一个都可以,该算法选择最小的那个)
Count–Min Sketch算法原理图

Count–Min Sketch算法复杂度情况
- 空间复杂度
O(dm)。Count-Min Sketch 需要开一个dxm大小的二位数组,所以空间复杂度是O(dm) - 时间复杂度
O(n)。Count-Min Sketch 只需要一遍扫描,所以时间复杂度是O(n)
Count–Min Sketch算法优点:
- Caffeine认为统计频率达到 15 次的频率算是很高的了,那么只需要 4 个 bit 就可以满足数据统计,一个 long 有 64bit,可以存储 16 个这样的统计数,Caffeine 就是这样的设计,使得存储效率提高了 16 倍(节省内存)
Count–Min Sketch算法缺点:
- 对于出现次数比较少的元素,准确性很差,因为二维数组相比于原始数据来说还是太小,hash冲突比较严重,导致结果偏差比较大(很明显CM sketch对元素的频率只会高估而不会低估,且对于重复次数较多的元素的准确率比较高,但是对于出现次数较少的元素的准确率较低)
临时拓展知识:
1,这个Count–Min Sketch算法可以替代布隆过滤器,解决布隆过滤器不能删除记录的缺陷
2,对于频率统计算法,有如下几种思路:
①直接使用hashMap<Key值,count值>这种进行统计,缺点就是消耗堆内存;
②分片+hashMap其本质就和数据库的水平拆分一样;
③还有就是刚才的Count–Min Sketch算法;
2.针对第二个问题,解决办法是让记录尽量保持相对的“新鲜”(Freshness Mechanism)
① caffeine增加一个新手保护缓存区(即 Window Cache)来存储最新的数据(暂时待一下,新手保护机制),等其建立足够的频率,避免稀疏流量问题
② 当有新的记录插入时,可以让它跟老的记录进行“PK”,输者就会被淘汰,这样一些老的、不再需要的记录就会被剔除
3.3.4,淘汰策略
当 新增数据时,window cache 区满(上图中的LRU):
- 就会根据 LRU 把 candidate(即淘汰出来的元素)放到 probation 区
- 如果 probation 区也满了,就把 candidate 和 probation 将要淘汰的元素 victim,两个进行“PK”,胜者留在 probation,输者就要被淘汰了。
而且经过实验发现当 window 区配置为总容量的 1%,剩余的 99%当中的 80%分给 protected 区,20%分给 probation 区时,这时整体性能和命中率表现得最好,所以 Caffeine 默认的比例设置就是这个。
不过这个比例 Caffeine 会在运行时根据统计数据(statistics)去动态调整,
- 如果你的应用程序的缓存随着时间变化比较快的话,那么增加 window Cache区(新手保护区)的比例可以提高命中率;
- 相反缓存都是比较固定不变的话,增加 Main Cache 区(本质就是SLRU区,protected 区 +probation 区)的比例会有较好的效果。
3.3.5,异步读写策略
一般的缓存每次对数据处理完之后(读的话,已经存在则直接返回,不存在则 load 数据,保存,再返回;写的话,则直接插入或更新,同步操作),但是因为要维护一些淘汰策略,则需要一些额外的操作,诸如:
- 计算和比较数据的是否过期
- 统计频率(像 LFU 或其变种)
- 维护 read queue 和 write queue
- 淘汰符合条件的数据
- 等等
以前的Guava针对上述操作使用的策略是利用JDK自带的ConcurrentHashMap(分段锁或者无锁CAS)来降低锁的粒度,达到高并发的目的。但是,对于一些热点数据(并发量比较高)还是避免不了频繁的锁竞争。
Caffeine借鉴了数据库系统中的WAL(Write-Ahead Logging)思想,即先写日志再执行操作,这种思想同样适合缓存的,执行读写操作时,先把操作记录在缓冲区,然后在合适的时机异步、批量地执行缓冲区中的内容。
3.3.6,过期策略
除了支持expireAfterAccess和expireAfterWrite之外(Guava Cache 也支持这两个特性),Caffeine 还支持expireAfter(本质就是自定义过期时间)。因为expireAfterAccess和expireAfterWrite都只能是固定的过期时间,这可能满足不了某些场景,譬如记录的过期时间是需要根据某些条件而不一样的,这就需要用户自定义过期时间。
而当使用了expireAfter特性后,Caffeine 会启用一种叫“时间轮”的算法来实现这个功能。
拓展知识:分层时间轮算法
分层时间轮算法是为了更高效的实现定时器而设计的一种数据格式,像 Netty 、ZooKeepr、Dubbo 这样的开源项目都有使用到时间轮的实现,其中kafka更进一步使用的是分层时间轮算法。
定时器的核心需求
- 新增(初始化一个定时任务)
- 移除(过期任务)
- 任务到期检测
定时器迭代历史
1,链表实现的定时器
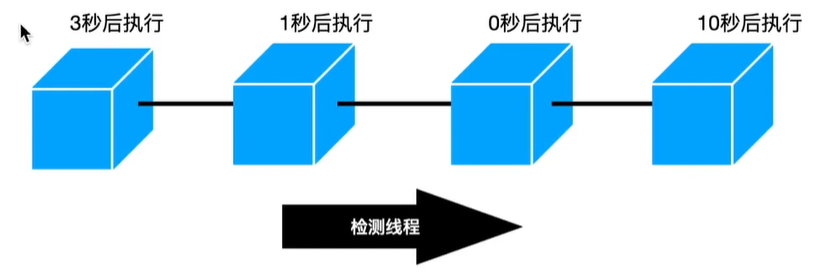
直接在一个链表中加入一个定时任务节点,每隔一个最小时间单位,开始从头向尾部检测,并将任务节点中的倒计时-1
- 如果倒计时变为0,那么说明该定时任务已经到期,就直接触发它的执行操作,并将它从链表中删除
- 如果倒计时还不为0,那么就继续往尾部遍历
时间复杂度:新增O(1),移除O(N),检测O(N)
缺点:时间复杂度高
2,排序链表实现的定时器
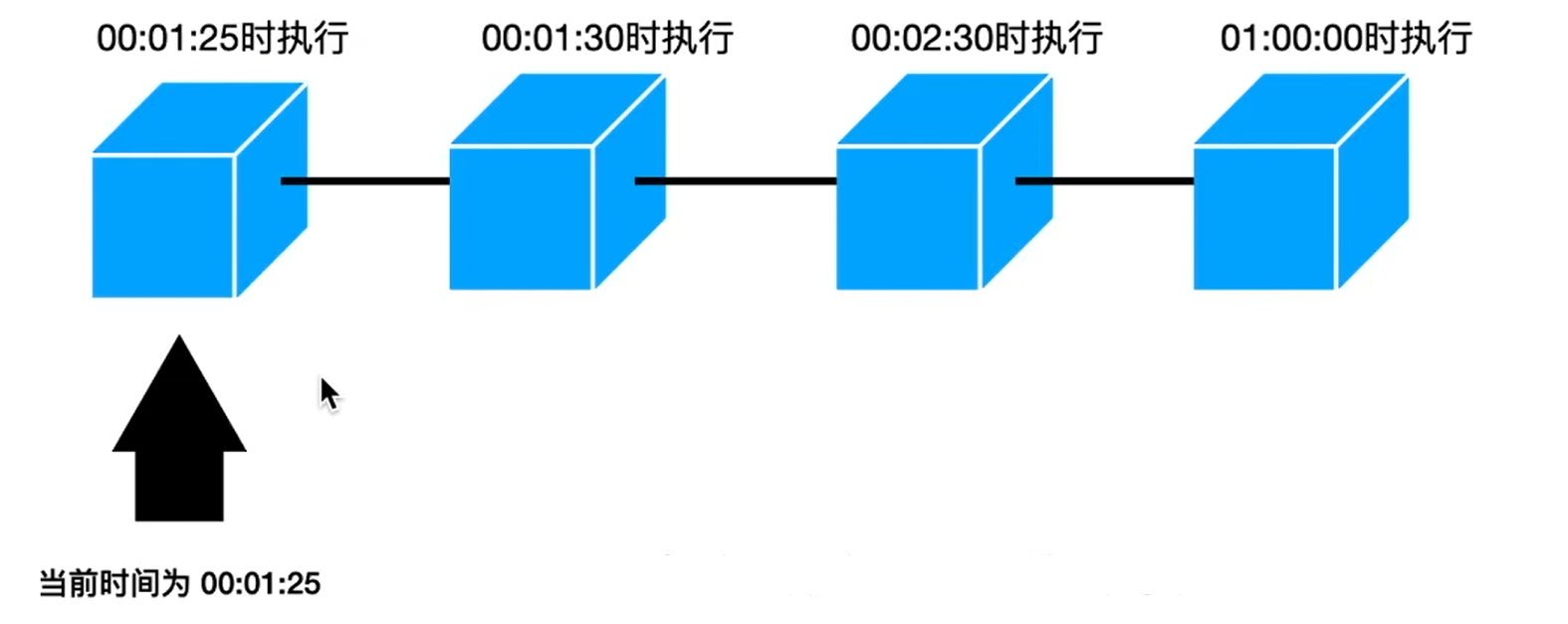
还是一个链表的数据格式,但是它这个是将各个定时任务的执行时间做了一个排序,然后每个最小时间间隔检测头节点
- 如果头结点的执行时间与当前时间一致,那么就开始执行该定时任务操作,并将头节点移动到next节点,同时也检测一下next节点
- 如果头节点的执行时间与当前时间不一致,那么就等待下一个时间节点再次检测
时间复杂度:新增O(N)需要额外排序操作,移除O(N),检测O(1)只用检测头结点
如果使用最小堆新增和移除的时间复杂度都为O(logN)
缺点:时间复杂度高
3,普通时间轮实现的定时器
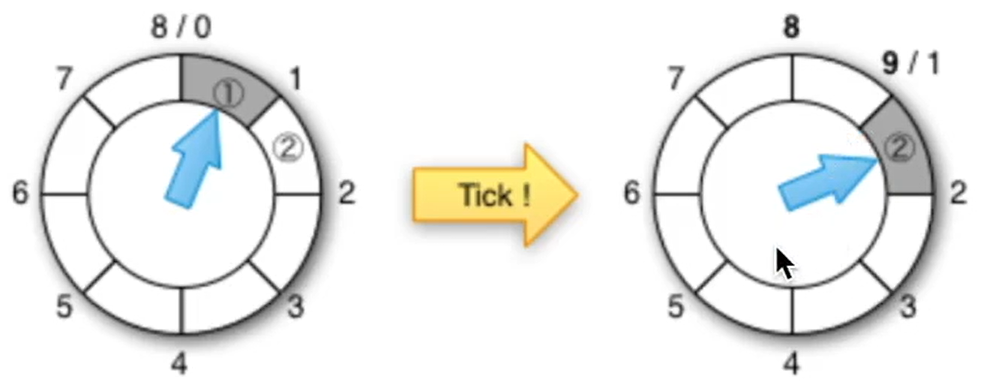
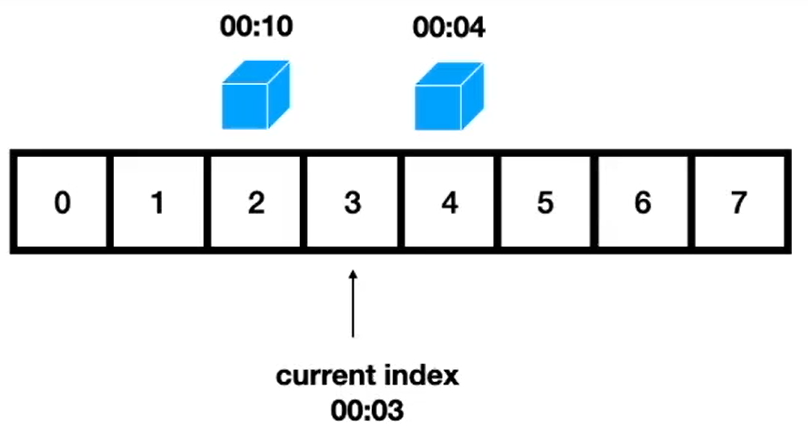
时间轮的本质就是一个数组,它的长度就是一个时间循环
以上图为例,该时间轮的时间循环周期为8个最小时间间隔,时钟轮询从0>8>0~>8开始每一个最小时间间隔步进一个单位,然后检查当前时间轮节点上是否有任务
- 如果有任务,就直接执行
- 没有任务就等待下一个时间间隔步进1重复进行检测
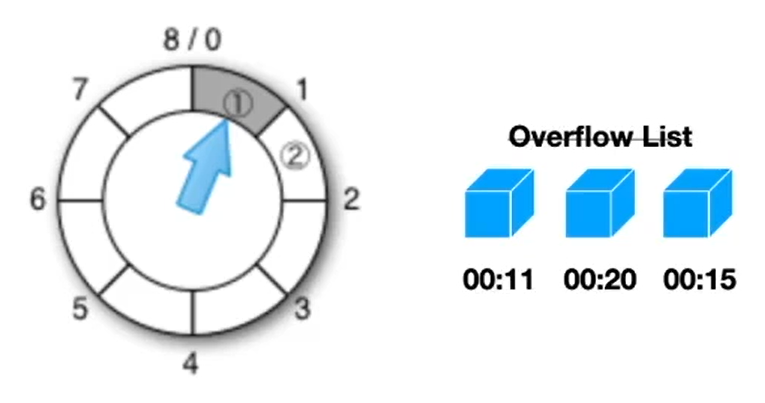
同时,它原版的会维护一个溢出列表(overflow list有序),因为定时任务有可能没有在这个时间周期内,那么就将这些未来需要执行的任务放在溢出列表中,每次时钟轮询的时候,检测一下是否可以添加到时间轮上
时间复杂度:纯粹的时间轮-新增O(1),移除O(1),检测O(1)
但是维护溢出列表需要额外资源,时间复杂度O(N)
缺点:时间复杂度高
4,分层时间轮实现定时器
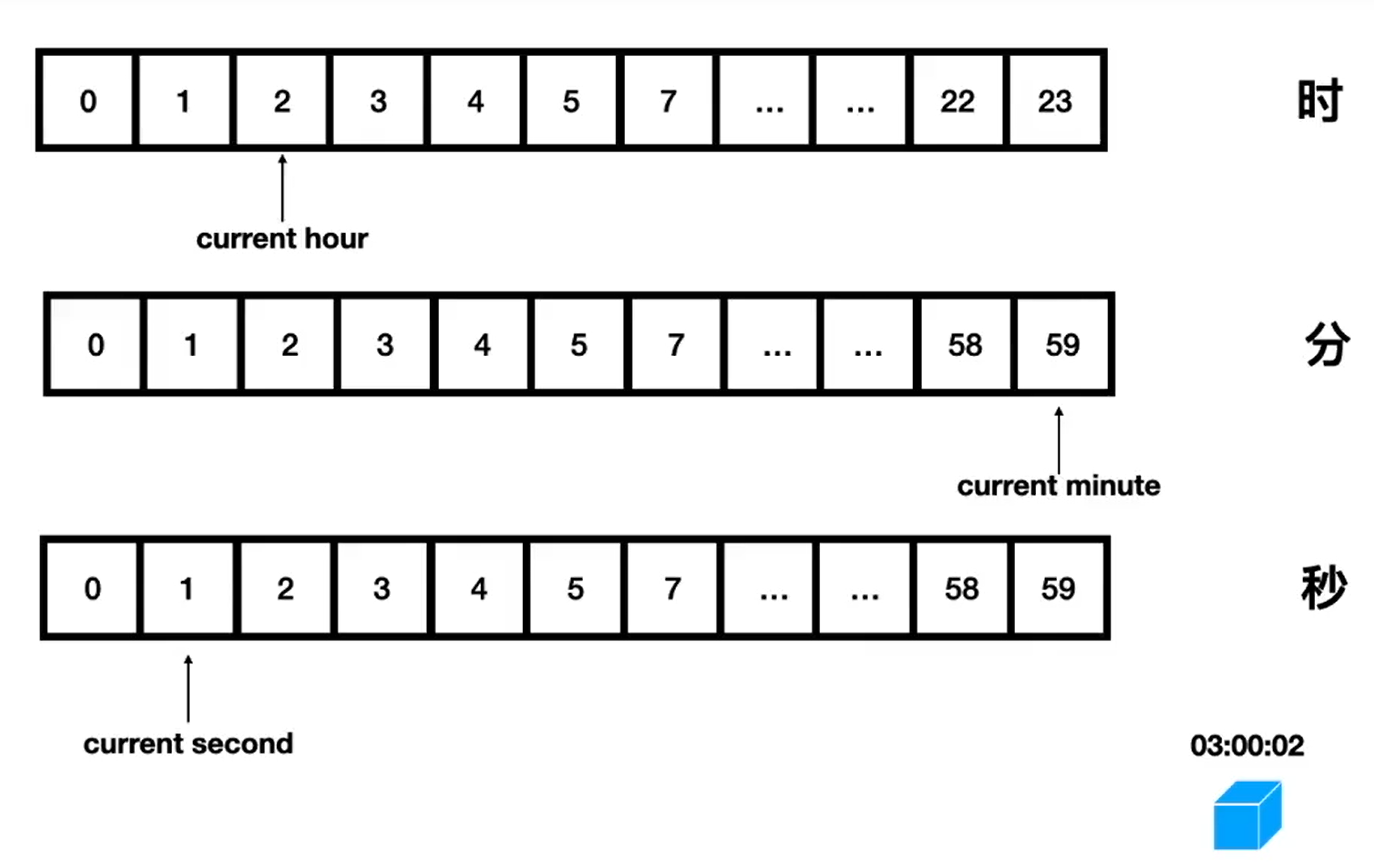
本质就是多个时间轮共同一起作用,分时间层级!
以上述图片为样例,当前时间为2时59分1秒,新建一个3时0分2秒的定时任务,先将定时任务存储在小时单位的时间轮上,存放位置为3时;
然后分层时间轮以秒进行驱动步进,秒驱动到59向0切换时,分钟时间轮也随之步进1,同理小时时间轮;
如果小时时间轮步进到3时,发现该节点上有一个定时任务,那么就将该任务转移到对应的分钟时间轮上,存放位置为0分;同理如果分钟时间轮发现当前的节点中有定时任务,那么就将其转移到秒时间轮上,存放位置为1;秒时间轮发现当前节点有任务,那么就直接执行!
时间复杂度:新增O(1),移除O(1),检测O(1)
3.3.7,消除伪共享
拓展知识:伪共享
1,什么是伪共享
CPU 缓存系统中是以缓存行(cache line)为单位存储的。目前主流的 CPU Cache 的 Cache Line 大小都是 64 Bytes。在多线程情况下,如果需要修改“共享同一个缓存行的变量”,就会无意中影响彼此的性能,这就是伪共享(False Sharing)。
本质就是在内存中,每个最小存储单元是64 字节为单位的块(chunk)进行存取,例如需要缓存long类型数据(8字节),那么就是一个最小内存单元中存储8个long类型数据成为一个chunk,如果我这边有8个线程并发分别修改这一个chunk中的8个long类型数据,就会出现性能影响的问题,必须是一个修改完另外一个再重新载入修改!否则,就会出现并发数据覆盖问题。
2,cpu的三级缓存
一、二级缓存属于各核心独享,而三级缓存是核心共享的,所有三级缓存的容量相对于一二级缓存要大得多
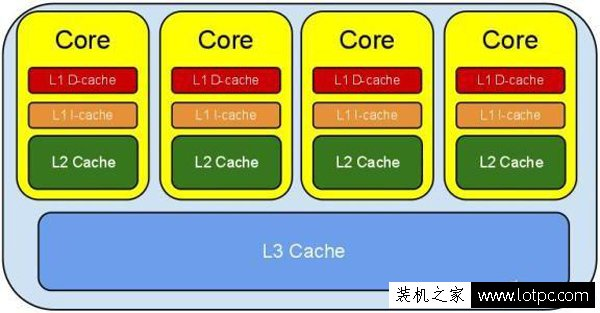
由于 CPU 的速度远远大于内存速度,所以 CPU 设计者们就给 CPU 加上了缓存(CPU Cache)。 以免运算被内存速度拖累。(就像我们写代码把共享数据做Cache不想被DB存取速度拖累一样),CPU Cache 分成了三个级别:L1,L2,L3。越靠近CPU的缓存越快也越小。L1 缓存很小但很快,并且紧靠着在使用它的 CPU 内核。L2 大一些,也慢一些,并且仍然只能被一个单独的 CPU 核使用。L3 在现代多核机器中更普遍,仍然更大,更慢,并且被单个插槽上的所有 CPU 核共享。最后,你拥有一块主存,由全部插槽上的所有 CPU 核共享。
当 CPU 执行运算的时候,它先去L1查找所需的数据,再去L2,然后是L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要确保数据在L1缓存中。
3.4,特性
Caffeine提供了多种灵活的构造方法,从而可以创建多种特性的本地缓存。
- 自动把数据加载到本地缓存中,并且可以配置异步;
- 基于数量剔除策略;
- 基于失效时间剔除策略,这个时间是从最后一次操作算起【访问或者写入】;
- 异步刷新;
- Key会被包装成Weak引用;
- Value会被包装成Weak或者Soft引用,从而能被GC掉,而不至于内存泄漏;
- 数据剔除提醒;
- 写入广播机制;
- 缓存访问可以统计;
3种加载方式
- 手动加载 cache.put(key1, value1);
- 同步加载 cache.get(key1) --> load(key1)
- 异步加载 cache.get(key1) --> CompletableFuture.supplyAsync(() -> {return oldValue;},executorService);
4种淘汰机制
- 基于大小
- 设置方式:maximumSize(个数),这意味着当缓存大小超过配置的大小限制时会发生回收
- 基于权重
- 设置方式:maximumWeight(个数),意味着当缓存大小超过配置的权重限制时会发生回收
- 例如设置最大权重为2,权重的计算方式是直接用key,当put 1 进来时总权重为1,当put 2 进缓存是总权重为3,超过最大权重2,因此会触发淘汰机制,回收后个数只为1
- 基于时间
- 访问后到期,时间节点从最近一次读或者写,也就是get或者put开始算起。
- 写入后到期,时间节点从写开始算起,也就是put。
- 自定义策略,自定义具体到期时间。
- 基于引用
- .weakKeys() // 设置Key为弱引用,生命周期是下次gc的时候
- .weakValues() // 设置value为弱引用,生命周期是下次gc的时候
目前数据被淘汰的原因不外有以下几个:
- EXPLICIT:如果原因是这个,那么意味着数据被我们手动的remove掉了。
- REPLACED:就是替换了,也就是put数据的时候旧的数据被覆盖导致的移除。
- COLLECTED:这个有歧义点,其实就是收集,也就是垃圾回收导致的,一般是用弱引用或者软引用会导致这个情况。
- EXPIRED:数据过期,无需解释的原因。
- SIZE:个数超过限制导致的移除。
4,使用
4.1,java样例
4.1.1,逻辑流程图
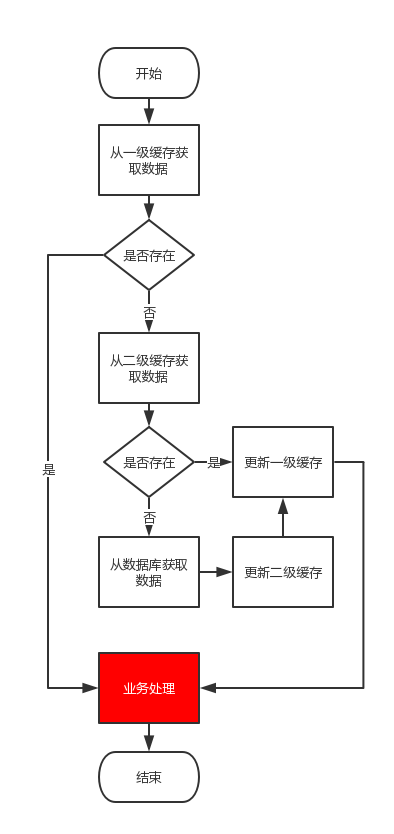
4.1.2,maven依赖
<!-- caffeine缓存框架 -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.8.8</version>
</dependency>
4.1.3,java代码
模拟memoryCache、redis二级缓存
package com.springcloud.test;
import com.github.benmanes.caffeine.cache.CacheLoader;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.LoadingCache;
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import org.springframework.lang.NonNull;
import org.springframework.lang.Nullable;
import java.util.HashMap;
import java.util.concurrent.*;
/**
* @author zjk
* @date 2022/3/11
* @descript
* @since V1.0.0
*/
public class CaffeineTest {
// 模拟redis缓存
private static HashMap<String, String> redisLike = new HashMap<>();
static {
redisLike.put("k1","v1");
redisLike.put("k2","v2");
}
// 模拟数据库
private static HashMap<String, String> dbLike = new HashMap<>();
static {
dbLike.put("k1", "v1");
dbLike.put("k2", "v2");
dbLike.put("k3", "v3");
dbLike.put("k4", "v4");
}
public static String getValue(String key) {
return localCache.get(key);
}
private static ThreadPoolExecutor executorService = new ThreadPoolExecutor(2,
4,
2,
TimeUnit.MINUTES,
new LinkedBlockingDeque<>(), new ThreadFactoryBuilder().build());
// 注意,注意 这里为了方便模拟实际使用过程中可能遇到的情况,参数设置比较极端
private static LoadingCache<String, String> localCache = Caffeine.newBuilder()
.maximumSize(1) // 最大缓存容量个数
.expireAfterWrite(50, TimeUnit.SECONDS) // 过期时间
.refreshAfterWrite(1, TimeUnit.SECONDS) // 写入后多久进行缓存刷新
.build(new CacheLoader<String, String>() {
@Nullable
@Override
public String load(@NonNull String token) {
// 模拟三级缓存刷入数据
String value = null;
if (redisLike.containsKey(token)) {
System.out.println("从redis中获取数据");
value = redisLike.get(token);
} else if (dbLike.containsKey(token)) {
System.out.println("从db中获取数据");
value = dbLike.get(token);
redisLike.put(token, value); // 需要给redis缓存设置过期时间,防止内存满了
} else {
System.out.printf("获取到%s的数据为空%n", token);
}
return value;
}
@Override
public @NonNull
CompletableFuture<String> asyncReload(@NonNull String key, @NonNull String oldValue, @NonNull Executor executor) {
// System.out.println("自动刷新缓存,key:" + key +",value:"+ oldValue);
return CompletableFuture.supplyAsync(() -> {
// System.out.println("执行异步刷新");
return oldValue;
},executorService);
}
});
public static void main(String[] args) throws InterruptedException {
System.out.println("value:"+localCache.get("k0"));
Thread.sleep(300);
System.out.println("value:"+localCache.get("k0"));
dbLike.put("k0","v0"); // 模拟中途刷新数据
Thread.sleep(300);
System.out.println("value:"+localCache.get("k0"));
System.out.println("value:"+localCache.get("k1"));
Thread.sleep(300);
System.out.println("value:"+localCache.get("k1"));
Thread.sleep(300);
System.out.println("value:"+localCache.get("k1"));
System.out.println("value:"+localCache.get("k3"));
Thread.sleep(1000);
System.out.println("value:"+localCache.get("k3"));
Thread.sleep(1000);
System.out.println("value:"+localCache.get("k3"));
localCache.refresh("k4");// 模拟主动刷新数据
System.out.println("主动刷新数据k4数据");
System.out.println("value:"+localCache.get("k4"));
localCache.put("k4","v004");
System.out.println("主动刷新数据k4数据");
Thread.sleep(1000);
System.out.println("value:"+localCache.get("k4"));
Thread.sleep(1000);
System.out.println("value:"+localCache.get("k4"));
Thread.sleep(2000);// k0过期后重新获取
System.out.println("value:"+localCache.get("k0"));
}
}
执行结果:
获取到k0的数据为空
value:null
获取到k0的数据为空
value:null
从db中获取数据
value:v0
从redis中获取数据
value:v1
value:v1
value:v1
从db中获取数据
value:v3
value:v3
value:v3
从db中获取数据
主动刷新数据k4数据
value:v4
主动刷新数据k4数据
value:v004
value:v004
从redis中获取数据
value:v0
4.1.4,结果分析
由上述代码可以完美的模拟(memoryCache、redis、db三级缓存)三级缓存操作,先去memoryCache中查询数据,没有再去redis中查询数据(有就直接返回),如果还没有(就去db里面查询,如果有就刷新redis并直接返回),如果还没有就直接返回null。
分析获取k0:
获取到k0的数据为空
value:null
获取到k0的数据为空
value:null
从db中获取数据
value:v0
....(最后一段逻辑获取k0)
从redis中获取数据
value:v0
// 由于redis和db中都没有目标数据,所以没有刷新数据直接返回空
// 在某一时刻,db中刷入数据,获取到数据直接刷新至memoryCache和redis
// 最后一段逻辑获取k0,可以直接在redis中获取k0数据
分析获取k1、k3:由于redis、db中有相关数据所以直接刷新至memoryCache即可
分析获取k4:主动预热数据操作、刷新k4-v004
实际使用过程中的配置(根据实际情况修改):
Caffeine.newBuilder()
.maximumSize(1000) // 最大缓存容量个数
.expireAfterWrite(10, TimeUnit.MINUTES) // 过期时间,10分钟后过期
.refreshAfterWrite(1, TimeUnit.SECONDS) // 写入后多久进行缓存刷新
.build();
4.2,结合Spring使用
4.3,从Guava迁移
参考链接
- 为什么Caffeine比Guava好?
- Caffeine与Guava对比
- caffeine配置及注意事项
- CacheManager与配置文件
- SpringBoot+SpringCache实现两级缓存(Redis+Caffeine)
- Guava cacha 机制及源码分析
- 全网最权威的Caffeine教程
- Caffeine的Window TinyLfu算法分析
- java引用
- 聊聊MyBatis缓存机制
- SpringBoot + Caffeine本地缓存
- 从 Kafka 看时间轮算法设计
- 【EP02】超级好玩的数据结构:定时器,时间轮,分层时间轮 Timer, Timing Wheel, Hierarchical Timing Wheel
- Java 中的伪共享详解及解决方案
- Caffaine-github

