分布式锁(5种)
分布式锁
1,简介
传统的单体应用使用本地锁(synchronized、reentrantLock),随着分布式的快速发现者,本地锁无法解决并发问题,需要一种能跨微服务/跨虚拟机的锁机制->分布式锁
作用:
- 并发正确性(资源独占)
- 效率:避免重复处理
作用:
- 互斥性:基本功能,一个获取锁,另外一个就不能获取
- 可重入性能:一个线程获取到锁之后,可以再次获取(多次获取)
- 锁超时:持有锁的线程挂掉后,一定时间锁自动释放
- 高效:加锁/释放锁速度快
- 高可用:集群、容灾
- 支持阻塞和非阻塞
- 支持公平锁和非公平锁
常用的分布式锁中间件:
- mysql
- zookeeper
- redis
- etcd
- chubby
2,分布式锁
2.1,mysql
方案1:使用专用的数据表
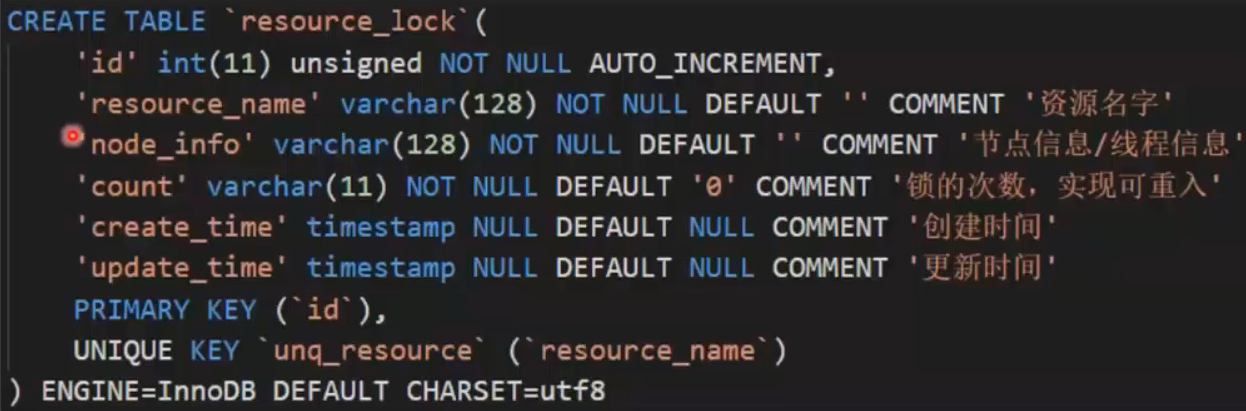
若需要加锁的资源恰好有对应的数据表,可以在数据表中增加响应的字段,达到服用数据的目的
阻塞式获取锁
循环调用lock()函数,直到返回true
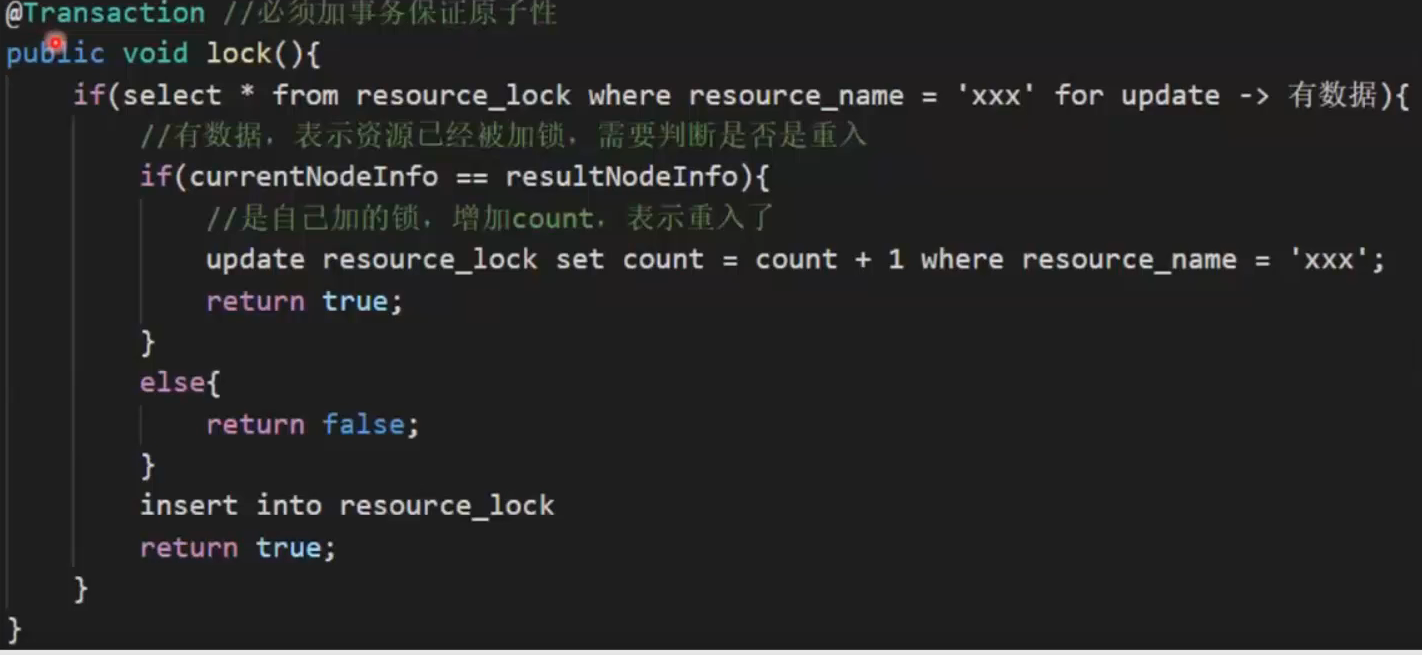
非阻塞式获取锁
循环调用lock()函数,直到返回true,或者超时
启动一个定时任务循环遍历锁,长时间未被释放的即为超时,直接删除
锁的释放
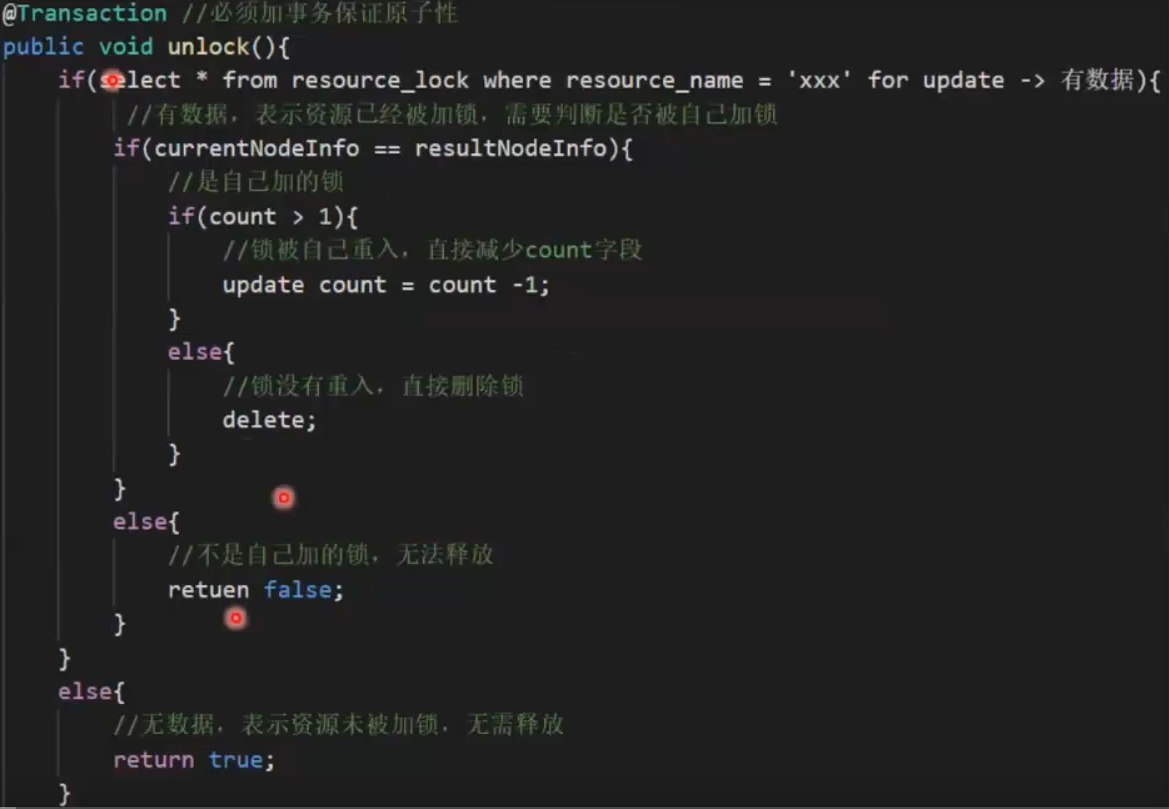
适用场景:没有其他中间件可以使用,需要加锁的资源恰好有对应的数据表
优点:理解起来简单,不需要维护其他中间件
缺点:需要自己实现加锁/解锁过程,性能较差
2.2,zookeeper
zookeeper是以paxos算法为基础分布式应用协调服务
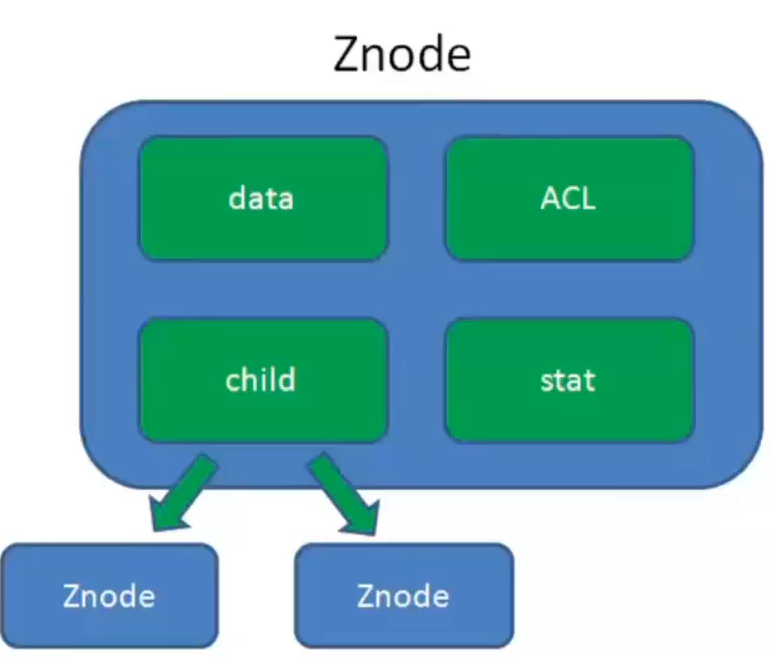
data:Znode存储的数据信息
ACL:记录Znode的访问权限
stat:包含Znode的各种元数据
child:子节点(树状结构,很像ldap数据仓库)
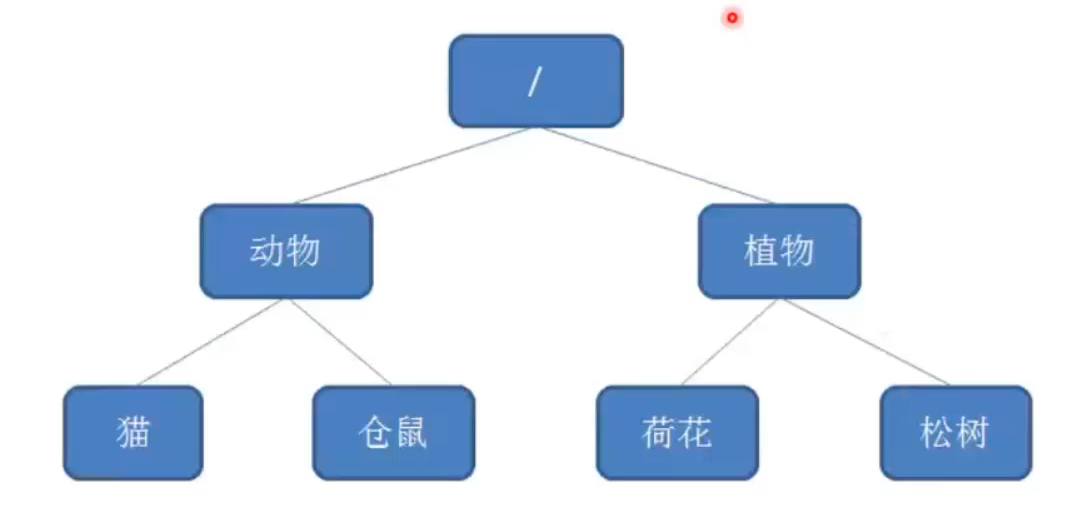
锁的实现原理:
线程去创建/resource_name子节点时会自动编号,第一个编号是/0000001。
第一个线程去创建锁成功并且发现编号是/0000001并且是最小编号,那就直接保留执行程序;
第二个线程再去获取锁时,创建的子节点会自动编号为/0000002,该线程会发现这个节点不是最小节点,就向上一个节点/0000001设置一个watcher监视器,待/0000001线程执行完毕释放的时候就直接触发/0000002执行程序;
第三个个线程再去获取锁时,创建的子节点会自动编号为/0000003,该线程会发现这个节点不是最小节点,就向上一个节点/000000x设置一个watcher监视器,待/000000x线程执行完毕释放的时候就直接触发/0000003执行程序;
天生的公平锁
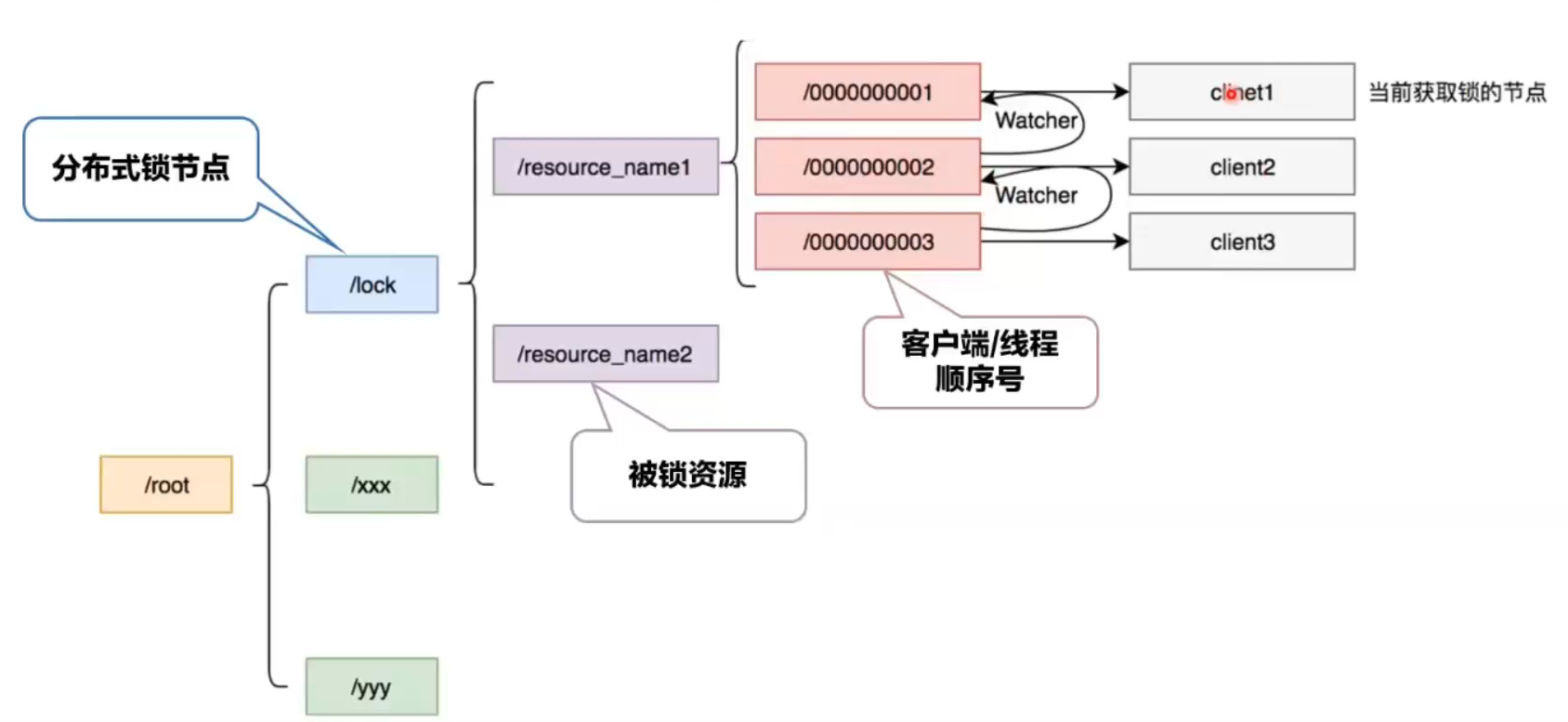
加锁流程:
- 进行重入的判断(利用ThreadLocal)
- 在被锁资源上建立EPHEMERAL_SEQUENTIAL节点
- 判断自己的节点是否位于第一个
- 若是第一个,则获取到锁,返回
- 若不是第一个,在前一个节点上注册watcher
- 进行阻塞等待
解锁流程:
- 进行重入的判断(利用ThreadLocal)
- 若为重入,在重入次数减1,返回
- 删除zookeeper上的有序节点
curator已经实现了上述的zookeeper分布式锁
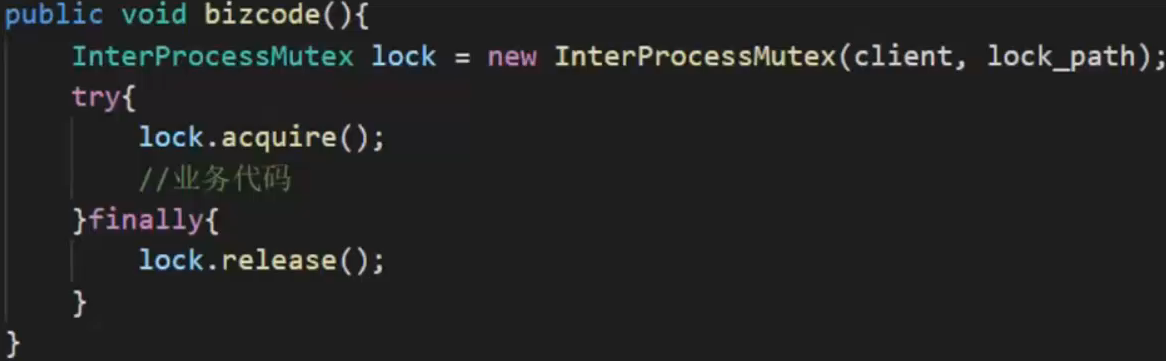
优点:
- 对于锁超时有现成的处理方法
- 天然的公平锁
- ZK集群保证高可用
缺点:
- 增加开发与维护成本
- 性能和MySQL想差不大,依然很差
2.3,chubby
chubby谷歌开发的分布式应用程序协调服务,功能上与zookeeper类似
优点:
- 创建序列号时,提供了API检查此序列号是否有效
- lock-delay,当客户端失联的时候,并不会立即释放锁(会去真实的确认是否真的失联)
缺点:
- 未开源,无法二次开发
2.4,Etcd
Etcd是一个高可用的分布式键值(key-value)数据库,内部采用raft协议作为一致性算法。
特性:
- lease机制,即租约机制,为存储的key-value对设置租约,当租约到期,k-v将失效删除
- revision机制:每个k带有revision号,每一次事务加一,全局唯一
- prefix机制,即前缀机制,也称为目录机制
- watcher机制,即监听机制,支持watch某个k,也支持watch一个范围(前缀机制)
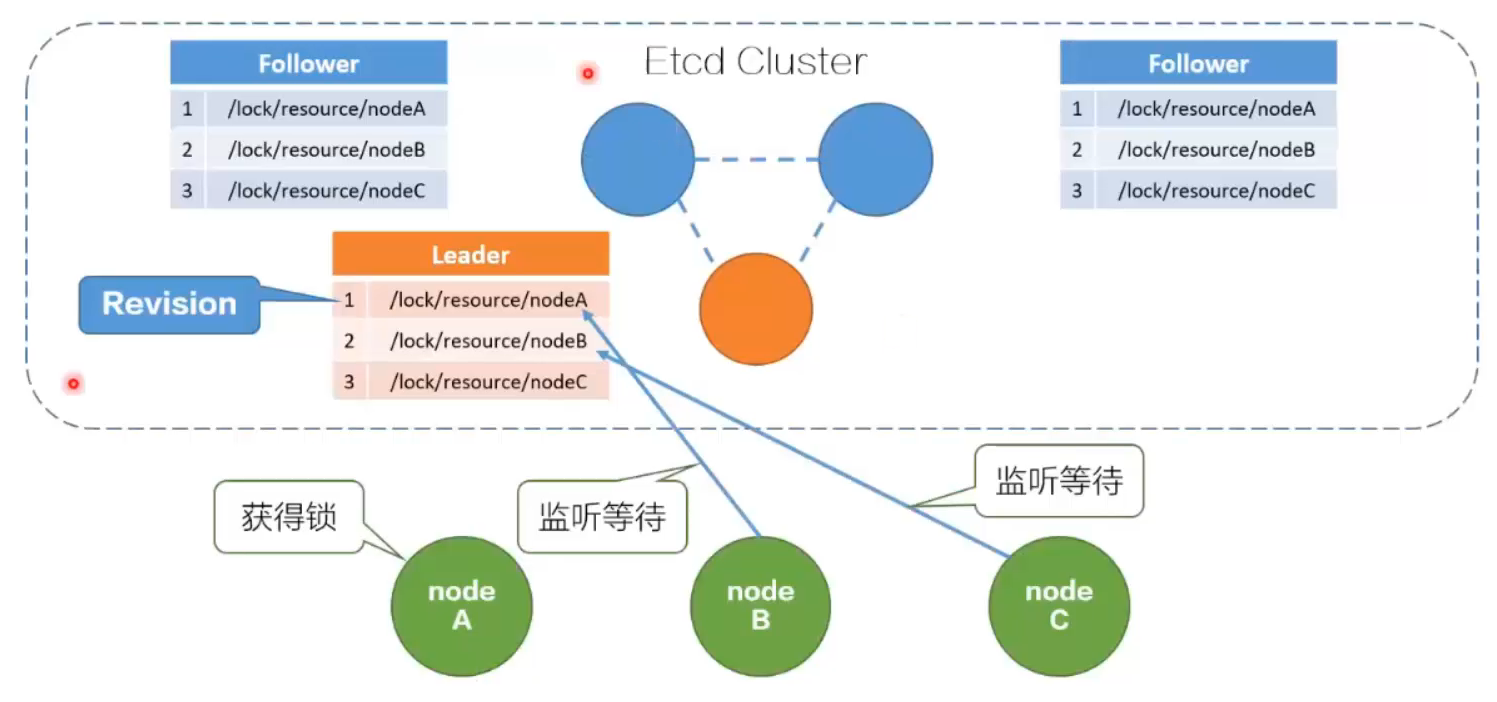
原理:
- /lock/resource为前缀创建key(/lock/resource/nodeX),并设置租约长度
- 客户端创建一个定时任务作为“心跳”,定时进行续约(看程序执行的时间,如果耗时长需要去续约)
- 将创建的key写入Etcd,获得revision号
- 获取/lock/resource下的所有key
- 若revision为最小,获取锁成功
- 若非最小,watch前一个revision号,待前面的释放才获取到
- 完成业务后,删除响应的key释放锁
etcdV3已经实现分布式锁

优点:
- V3接口提供现场的分布式锁实现
- 天然是公平锁(与zookeeper类似)
- Etcd集群保证了高可用
缺点:
- 性能一般
2.5,redis
redis(remote dictionary server)是一个k-v存储中间件。
实现操作:
redisV2.8之前:使用lua脚本实现,因为setnx命令不支持设置过期ex
redisV2.8之后:set resourceName value ex
(ex设置过期时间,ex做独占操作),这个命令可以保证原子性。以前的版本不能保证原子性!
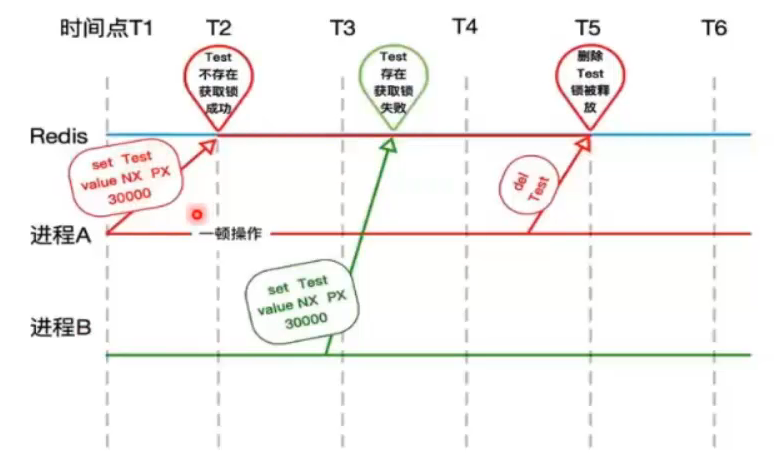
加锁问题:
-
进程A未续约(设置有效期),导致B获取了锁
-
复杂操作需要及时续约:expire resourceName

解锁问题:
-
进程B解锁时,key已经被A删除,导致B异常
-
解锁时需要判断是否是自身持有的锁

使用业务代码判断,判断和删除非原子操作,有安全问题(前面判断在了,后面就删除,但是这两个操作之间有可能就被其他线程B获取到锁了!!!)

使用lua脚本判断,判断和删除是原子操作
redisson封装了锁的实现
继承了java.util.concurrent.locks.Lock接口
实现3种:阻塞式的(lock),非阻塞式(tryLock),异步非阻塞式的(tryLockAsync)

实现原理:
尝试加锁,首先会尝试进行加锁,由于保证操作是原子性,那么就只能使用lua脚本,相关的lua脚本如下:
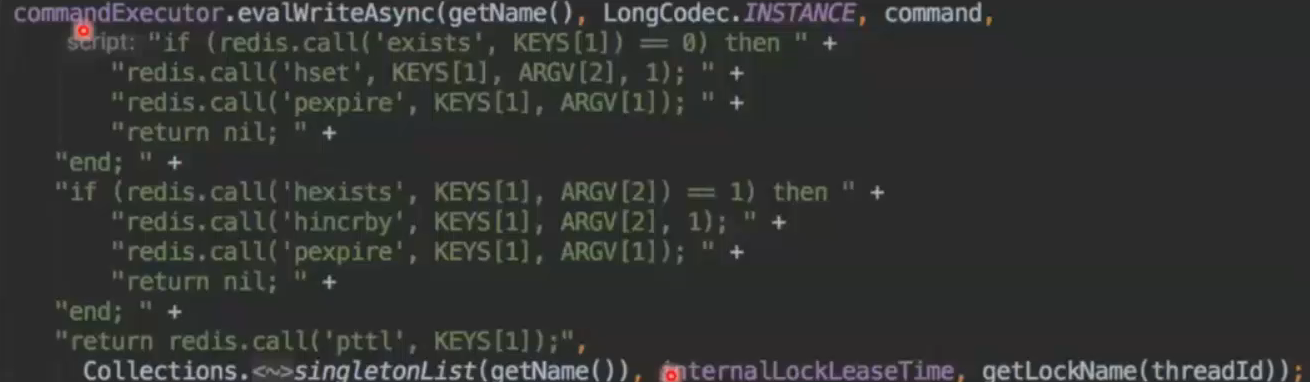
redisson并没使用set nx,而是使用hash结构
原理:
- 如果尝试获取锁失败,判断是否超时,如果超时则返回false
- 如果加锁失败之后,没有超时,那么需要在名字为redissopnm_name_channel+lockName的channel上进行订阅,用于订阅解锁消息,然后一直阻塞直到超时,或者有解锁消息
- 重试上述步骤,直到最后获取到锁,或者某一步获取锁超时
- 解锁时通过lua脚本,如果是可重入锁,只是减1;如果是非加锁线程解锁,那么解锁失败

redLock红锁
redis主从与集群并不是强一致性的,所以在极端情况下,会有一致性问题,若redis未及时持久化,重启会丢失数据。为了解决上述问题,redis作者提出了RedLock红锁算法。
原理:
- 首先生成多个redis集群的Rlock,并将其构造程RedLock
- 依次循环对三个集群进行加锁,加锁方式和redission一致
- 如果循环加锁的过程中加锁失败,那么需要判断加锁失败的次数是否超出了最大值(要多数成功)
- 加锁的过程中需要判断是否加锁超时
- 若失败,向所有节点请求解锁
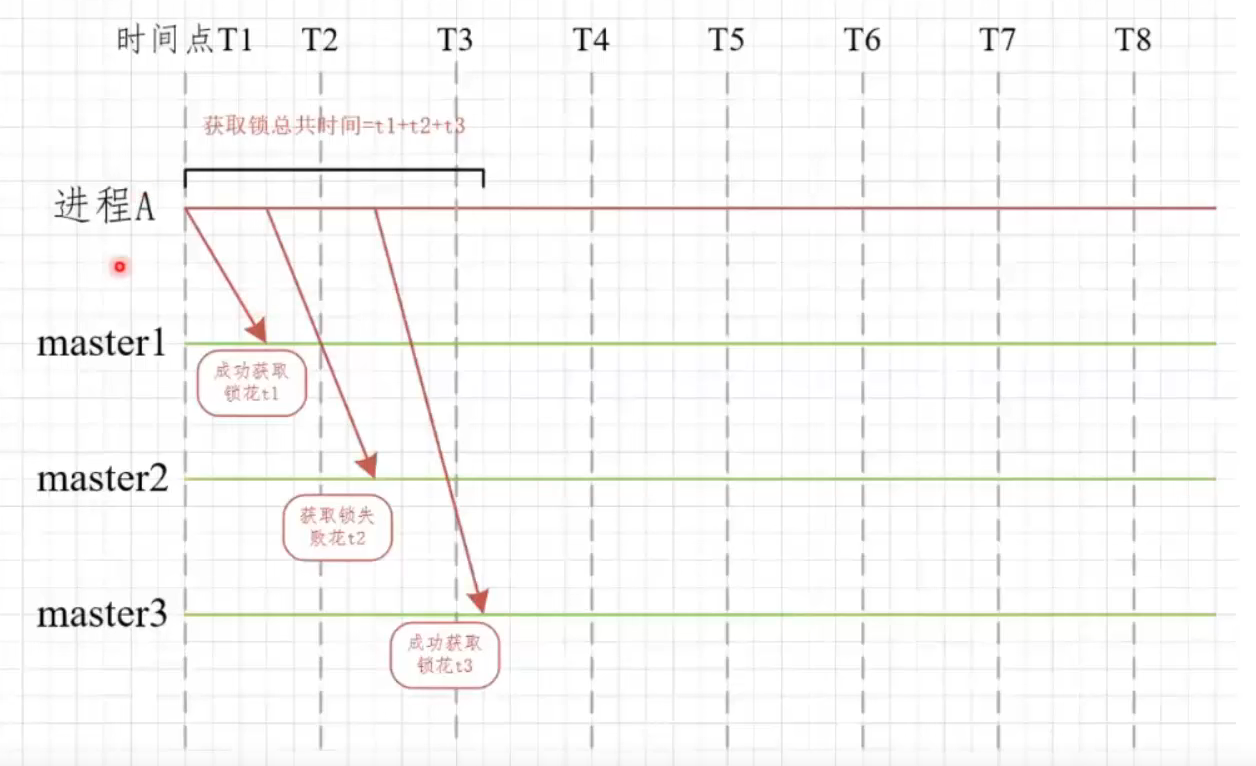
进程A依次向master1,master2,master3获取锁
优点:
- redis在项目中很常见
- 容易取得可靠性和性能的平衡
缺点:
- RedLock算法需要多套redis实例,资源耗费
3,安全问题
3.1,GC导致锁超时
线程A获取到锁,正常情况下程序1秒执行完毕,然后释放锁;但是突然系统来了一个stop-the-world GC pause耗时2秒钟,此时锁已经自动释放,线程A恢复运行;这时线程B是可以获取到锁!(线程不安全)

chubby lock-delay:当客户端失联的时候,并不会立即释放锁,而是在一定时间内(默认1min)阻止其他客户端拿到这个锁
3.2,网络I/O导致锁超时
与上面的GC类似,网络不稳定,请求某些接口耗时特别长导致这个事务整体耗时变长,分布式锁超时释放了!

chubby:提供API,供storage服务在收到请求时校验当前序号,如果查询获取到当前释放的锁已经被过期了那么就直接拒绝!
3.3,时钟跳跃导致的锁超时
从NTP服务收到了一个大的时钟更新,导致一大批锁直接过期!
解决办法:少量多次更新时间,例如更新时间是10分钟,我们分为10次,每次更新1分钟,来逐步更新系统时间,这样相对会好一些

 浙公网安备 33010602011771号
浙公网安备 33010602011771号