Redis技术总结
Redis技术总结
1,Nosql概述
为什么要使用nosql
1.1,数据库发展史
1,单机mysql版
90年代,网站访问量很少,单个数据库就够了!更多使用的是静态网页

这种情况下整个网站的瓶颈:
1,数据量如果太大,一个机器放不下
2,数据的索引(B+Tree)300万就
3,访问量(读写混合),(万级别左右)一个服务器承受不了
当出现上面的情况,就必须要升级(晋级)!
2,Memcached(缓存kv)+Mysql+ 垂直拆分(读写分离)
网站80%的情况都是读数据,使用数据库去查询肯定很不方便,直接使用缓存来加快查询速度
发展过程:优化数据结构和索引->文件缓存(IO)->Memchached
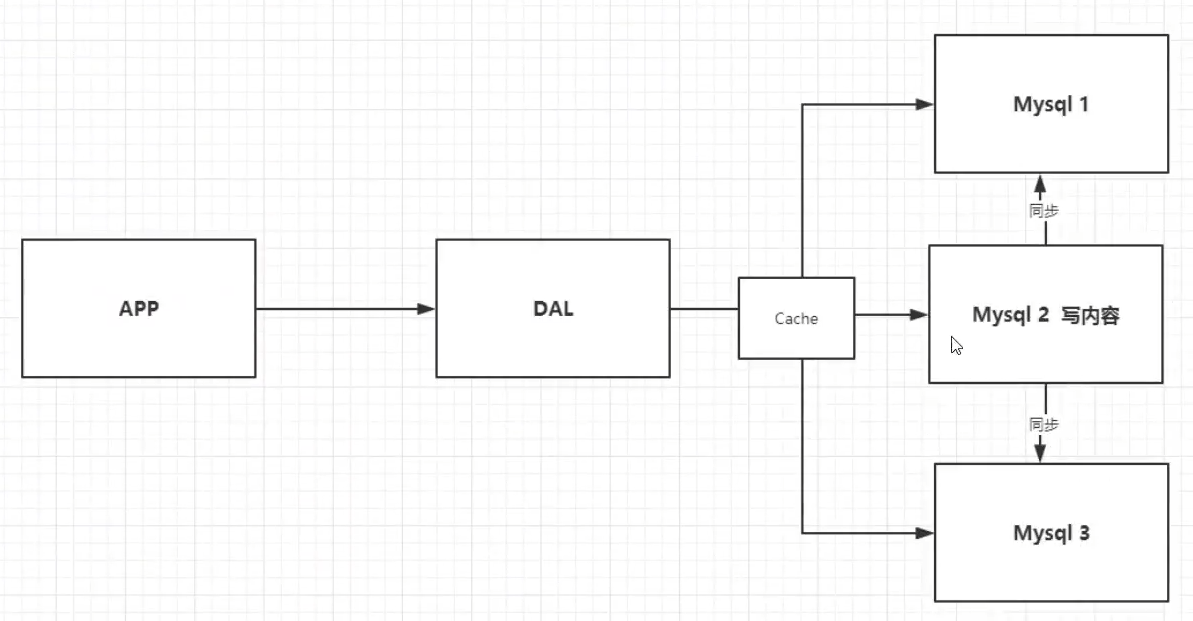
3,分库分表+水平拆分+Mysql集群
数据库的本质:读、写
MyISAM:表锁,十分影响效率!高并发下就好出现严重的锁问题
Innodb:行锁
后续慢慢使用分库分表来解决写的压力!MySql在那个时候推出了表分区(但是,没有多少人使用)
Mysql集群很好的满足了那个年代的所有需求
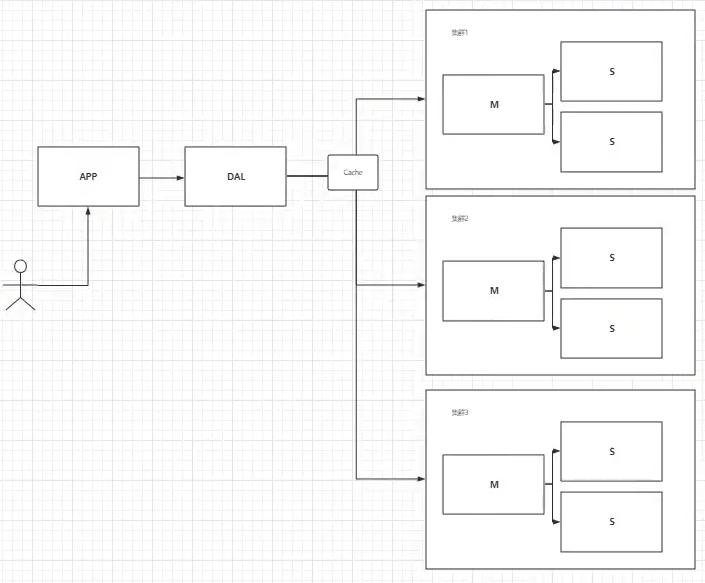
4,如今的现在
mysql等关系型数据库不够用了!各种各样的数据需求(视频、图片、位置、阅览量、用户日志等)
这个时候需要使用nosql
1.2,什么是NoSQL
关系型数据库:表格、行、列(POI)
not only SQL(不仅仅是SQL),泛指非关系型数据库,随着web2.0互联网诞生,尤其是超大规模的高并发社区.NoSQL在当前大数据时代发展十分迅速,redis是发展最快的一种!
很多类型的数据,社交网络、地理位置等!存储不需要一个固定的格式,不需要多余的操作即可横向扩展!例如Map<String,Object>使用键值对来控制!
NoSQL特点
解耦!
1,方便扩展(数据之间没有关系,很好扩展!)
2,大数据量高性能(Redis一秒写8万次,读取11万次,NoSQL的缓存记录级,是一种细粒度的缓存,性能会比较高)
3,数据类型多样!(不需要事先设计数据库!随取随用!如果是数据量十分大的表,无法设计了)
4,传统RDBMS和NoSQL的区别
传统的RDBMS
- 机构化组织
- SQL
- 数据和关系都存在单独的表中 row、column
- 严格的一致性
- 基础的事务
- ......
NoSQL
- 不仅仅是数据
- 没有固定的查询语言
- 键值对存储、列存储、文档存储、图形数据库(社交关系)
- 最终一致性
- CAP定理和BASE(异地多活)
- 高性能、高可扩展、高可用
了解:3V+3高
大数据时代的3V:主要是描述问题(海量volume数据量、多样variety种类、实时velocity速度)
大数据时代的3高:主要是对程序的要求(高并发、高可扩{随时水平拆分、扩展}、高性能)
实际实践中是NoSQL+RDBMS一起使用
1.3,阿里巴巴演进史


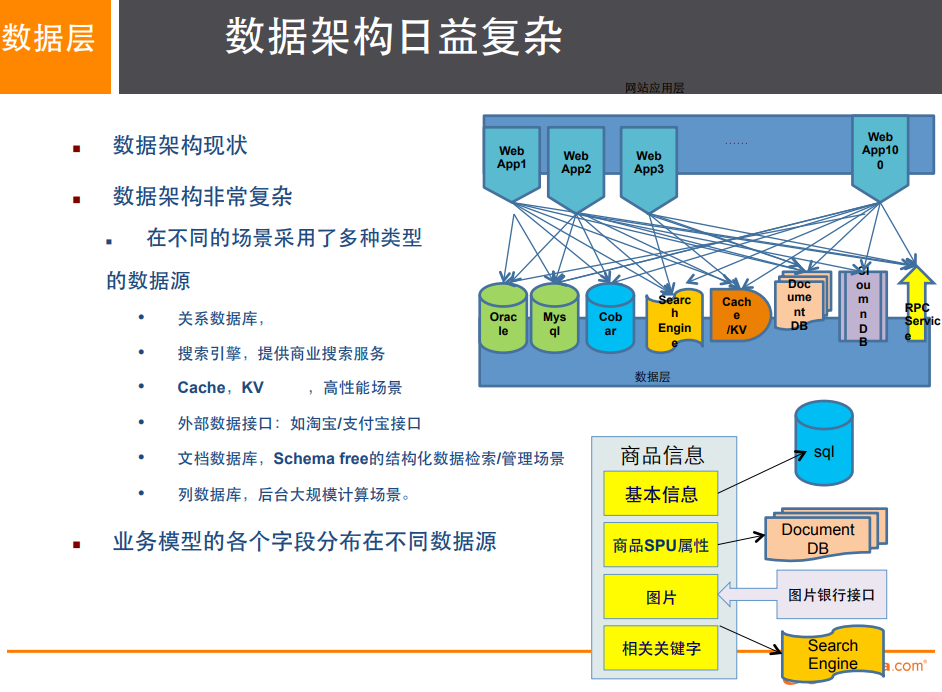
没有什么问题是加一层解决不了的!
1,商品的基本信息
名称、价格、商家信息(使用MySQL即可)
2,商品的描述、评论(文字比较多)
文档型数据库中,MongoDB
3,图片
分布式文件系统FastDFS
- 淘宝的 TFS
- GOOGLE的 GFS
- hadoop的 HDFS
- 阿里云的 OSS
- 开源的 MinIO
4,商品的关键字(搜索)
- 搜索引擎 solr elasticsearch
- ISearch:多隆
5,热门的波段信息
- 内存数据库
- redis、taur、memachached
6,商品的交易,外部的支付接口
- 三方应用
一个简单的网页背后-技术一定不是大家所想的那么简单!
大型互联网应用问题!
- 数据类型太多
- 数据源繁多,经常重构
- 数据需要改造,大面积改造
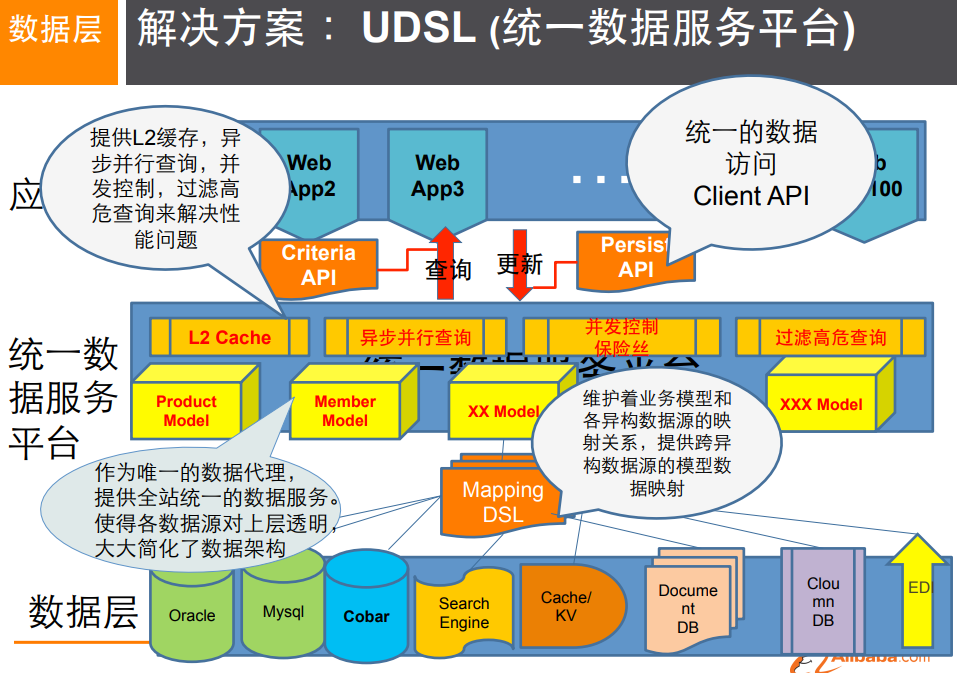
1.4,NoSQL的四大分类
①KV键值对
- 新浪:redis
- 美团:redis + tair
- 阿里、百度:redis+memecached
②文档数据库
(bson格式binary和json格式一样)
-
MongoDB(一般必须掌握)
- 基于分布式文件存储的数据库,C++编写,主要用于处理大量的文档
- 介于关系型数据库和非关系数据库中间的产品!交集
-
CountDB
③列存储数据库
- HBase
- 分布式文件系统
④图形关系数据库
不是存储图形的,存储的是关系,例如:朋友圈社交网络,广告推荐
Neo4j,InfoGrid:

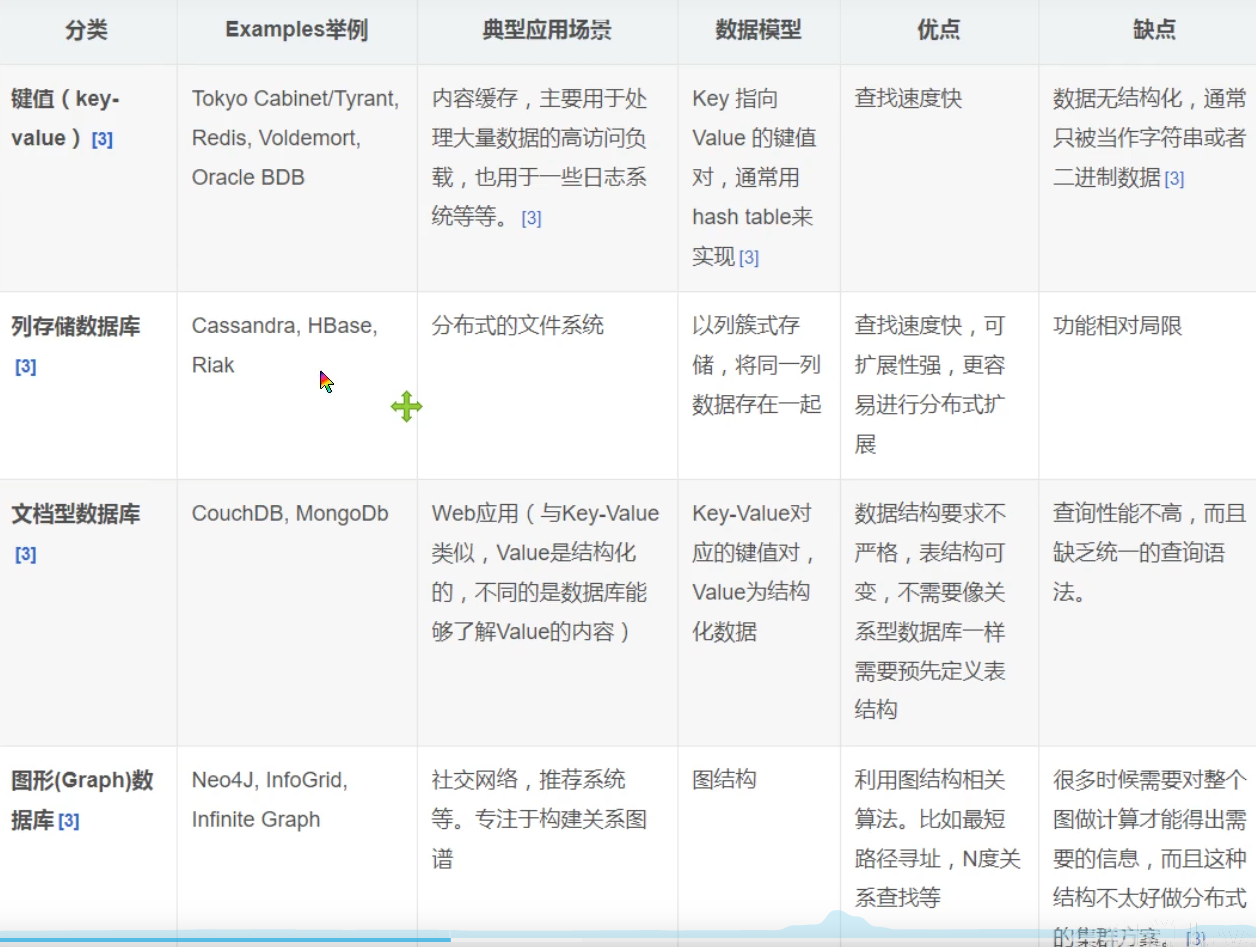
4种大类的粗略对比
2,redis入门
2.1,概述
是什么?
redis (remote dictionary server),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助。
能干什么?
1,内存存储、持久化,内存中是断电即丢,所以持久化很重要(rdb、aof)
2,效率高、可以用于高速缓存
3,发布订阅系统(pub/sub)
4,地图信息分析(geospatial数据类型)
5,计时器(做过期事件通知)、计数器(incr)
6,.......
特性
1,多样的数据类型
2,持久化
3,集群
4,事务
....
2.2,安装redis
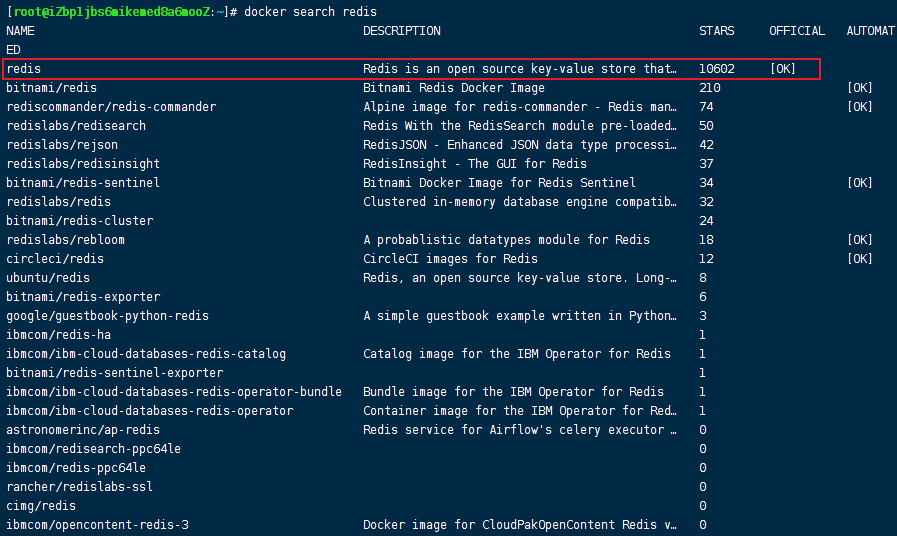
2.2.1,docker容器安装
安装最新的redis镜像(注意:redis镜像好像自己不带配置文件的,需要额外自己下载)
docker search redis
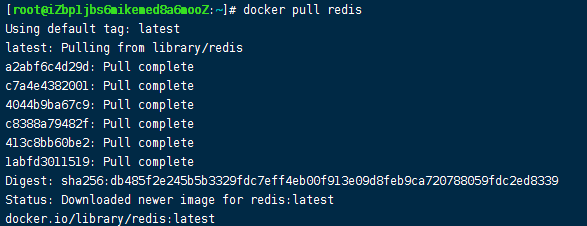
docker pull redis
# dockerhub官网直接运行样例
docker run -itd --name ac-redis -p 6379:6379 redis
# 我自己使用redis.conf配置文件挂载配置启动的命令
docker run -itd \
-p 6379:6379 \
-v /opt/docker/redis/conf/redis.conf:/usr/local/etc/redis/redis.conf \
-v /opt/docker/redis/data:/data \
--name ac-redis \
redis \
redis-server /usr/local/etc/redis/redis.conf
注意事项!redis.conf文件中有一个bind 配置项,该配置表示只接受绑定该ip的请求来源,当前我们使用docker启动的话,可以直接注释掉并且设置redis的密码配置requirepass 。否则,我们只能在docker镜像内访问redis服务,外部(其他主机)无法连接成功!
2.3,测试性能
redis-benchmark是官方自带的一个压力测试工具!redis-benchmark命令参数。

简单测试:
# 测试:100并非连接,100000请求
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
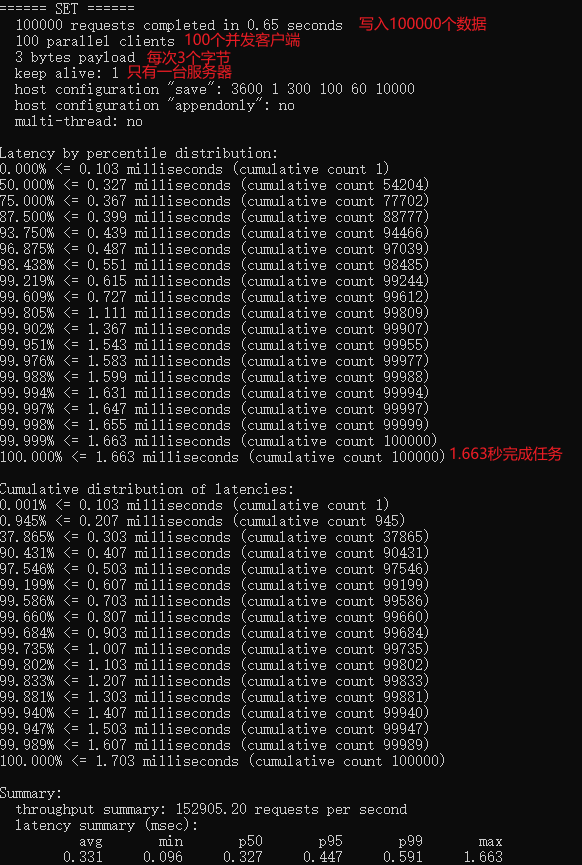
王婆卖瓜自卖自夸,redis自己测试自己有多强!
2.4,基础知识
redis默认有16个数据库(0-15),默认使用第0个库

127.0.0.1:6379> select 3 # 选择数据库
OK
127.0.0.1:6379[3]> DBSIZE # 查看当前库下数据情况
0
127.0.0.1:6379[3]> set hello world
OK
127.0.0.1:6379[3]> DBSIZE
1
127.0.0.1:6379[3]> keys * # 查看所有key
1) "hello"
127.0.0.1:6379> flushall # 清空所有数据库
OK
redis使用6379端口的原因-merz广告女的故事(6宫格键盘)
「MERZ」在 Antirez(redis作者) 的朋友圈语言中是「愚蠢」的代名词,它源于意大利广告女郎「Alessia Merz」在电视节目上说了一堆愚蠢的话。
mysql使用3306端口-女儿的名字
redis是单线程的!
redis是基于内存操作,cpu不是redis性能瓶颈,redis的瓶颈是根据机器的内存和网络带宽,既可以使用单线程来实现,就使用单线程!
redis是C语言写的,官方提供的数据为100000+的QPS,不比memecache(k-v的)差!
redis为什么单线程还这么快?
- 误区1:高性能的服务器一定是多线程的?
- 误区2:多线程(CPU上下文切换)一定比单线程效率高
cpu>内存>硬盘的速度比较
核心:redis是将所有数据全部放在内存中,所以使用单线程去操作效率最高,多线程(cpu上下文切换-耗时1500nm-2000nm之间),对于内存系统来说,如果没有上下文切换效率就是最高的!多次内存读写都是在同一个线程上,这个就是最佳方案!(详情见redis 单线程的理解 )
2.5,使用场景
| 序号 | 场景 | 描述 | 关联技术 |
|---|---|---|---|
| 1 | 缓存 | 利用redis的高并发存储热点数据 | redis为什么这么快? |
| 2 | 数据共享 | session共享 | 将session存储redis |
| 3 | 分布式锁 | 单节点的set lock 1 nx ex 多节点的redLock |
其实本质还是数据共享的功能 |
| 4 | 分布式ID | 利用incr k1命令的原子性 ,获取分布式ID | 分布式ID的解决方案 |
| 5 | 计数器 | 还是利用incr 命令来进行数值统计 例如:请求数、调用次数等 |
incr命令,原子性,计算向数据迁移 |
| 6 | 限流 | 本质还是计数器的拓展 利用计数器统计访问次数,然后限制访问 |
限流与熔断 |
| 7 | 位统计 | 本质就是bitmap数据类型的特性 | bitmap数据结构特性 |
| 8 | 购物车 | 本质就是redis的hashMap数据结构的特性 可以存储对象数据 |
hashMap数据结构存储对象 |
| 9 | 用户消息时间线 timeline |
本质就是redis的list双向链表数据结构特性 可以记录消息的先后顺序 |
双向链表数据结构,FIFO、LIFO |
| 10 | 消息队列 | redis自己有一个消息队列的功能 不过现在基本上都没有人使用 |
|
| 11 | 抽奖 | redis set中的一个随机数功能 | |
| 12 | 点赞、签到、打卡 | redis set数据结构的记录与统计功能 | |
| 13 | 商品标签 | redis set数据结构的记录与统计功能 | |
| 14 | 商品筛选、互相关注 | redis set数据结构的交并集功能 | |
| 15 | 地理位置功能 | redis geography数据结构 | 地理位置数据结构 |
| 16 | 排行榜 | redis zset数据结构 | 跳表,丐版B+树 |
| 17 | 网站的阅历次数估算 | hyperloglog数据结构 | 底层伯努利概率分布 |
2.6,注意事项
| 序号 | 可能出现的问题 | 描述 |
|---|---|---|
| 1 | 数据一致性问题 | redis集群是一个弱一致性的缓存 想要实现强一致性,就需要使用类似qurom查询N/2+1个节点进行确认数据 例如:redLock |
| 2 | 大key问题 | 由于数据操作是单线程,所有的数据操作都是需要排队处理的 所以,遇见大key时,会有等待导致的并发降低 |
| 3 | 数据预热问题 | 我们使用缓存,如果不进行数据预热 系统初始化后的一段时间,基本上所有的请求都会打到DB |
| 4 | 缓存穿透 | 请求客观不存在的数据 如果不做响应的处理(布隆过滤器、存null值等),那么每次请求都会打到DB |
| 5 | 缓存击穿 | 某个缓存过期后,并发请求直接都打到DB中 使用分布式锁解决 |
| 6 | 雪崩 | 大量缓存同一时刻过期,导致大量DB查询 解决方案:①随机过期时间;②redis高可用(多节点备用);③限流降级(分布式锁);④数据预热 |
3,五大数据类型

Redis 是一个开源(BSD 许可)的内存数据结构存储,用作数据库、缓存和消息代理。Redis 提供数据结构,例如字符串(String)、散列(hashes)、列表(list)、集合(sets)、具有范围查询的排序集合(sorted sets)、位图(bitmaps)、超日志(hyperloglogs)、地理空间索引(geospatial indexes)和流(streams)。Redis 具有内置复制、Lua 脚本(Lua scripting)、LRU 驱逐(LRU eviction)、事务(transactions)和不同级别的磁盘持久性(different levels of on-disk persistence),并通过哨兵(Redis Sentinel) 和集群(Redis Cluster) 自动分区提供高可用性(high available)。
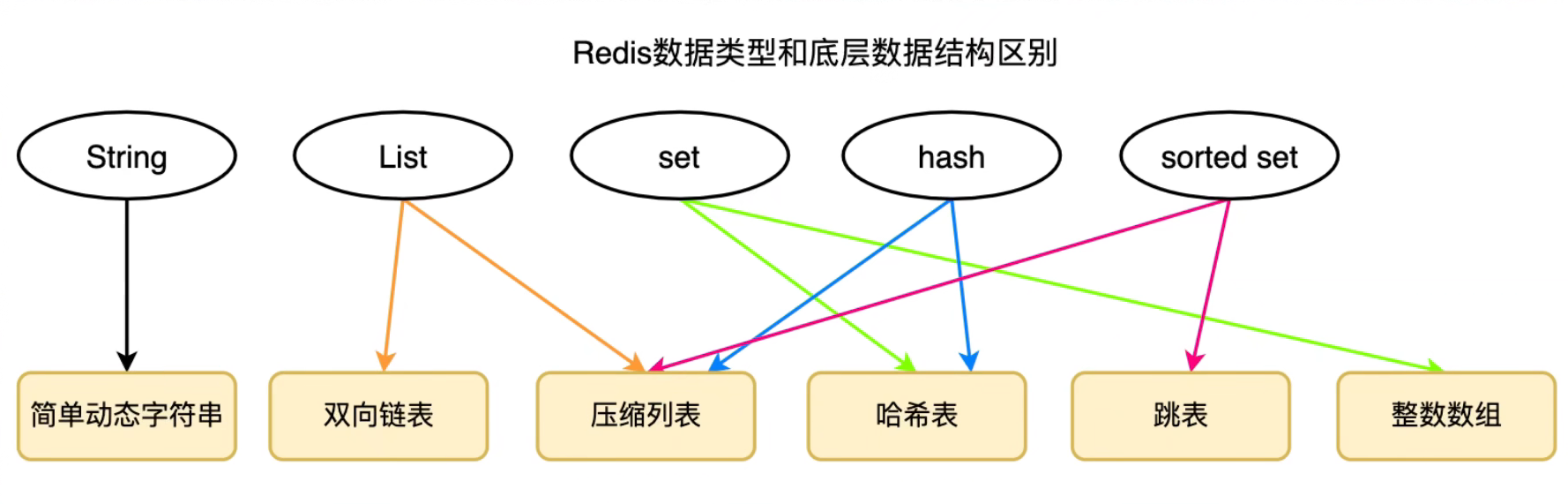
注意:redis不区分大小写命令
3.1,String
90%的程序员只会使用字符串类型!(自增可以用于我自己的fileserver浏览量统计)
命令
append(追加字符串,如果不存在则set)、strlen(查看长度)、keys *(查看所有的key)、
incr(自增1)、decr(自减1)、incrby(按照步长增加)、decrby(按照步长减少)、
getrange(字符串截取)、setrange(字符串替换)、
setex(设置过期时间)、setnx(如果不存在才设置-用于分布式锁)、
mset(设置多个值)、mget(批量获取多个值)、
msetnx(批量设置多个只有不存在才设置的值,msetnx保证原子性!)、msetex(不存在该命令!)
getset(先获取值然后设置值)
点击查看命令执行情况
127.0.0.1:6379> ping PONG 127.0.0.1:6379> 127.0.0.1:6379> 127.0.0.1:6379> flashdb (error) ERR unknown command `flashdb`, with args beginning with: 127.0.0.1:6379> flushdb OK 127.0.0.1:6379> keys * 1) "hello" 127.0.0.1:6379> append hello -wanyu (integer) 11 127.0.0.1:6379> get hello "world-wanyu" 127.0.0.1:6379> set k1 v1 OK 127.0.0.1:6379> append k1 -vvv (integer) 6 127.0.0.1:6379> get k1 "v1-vvv" 127.0.0.1:6379> strlen k1 (integer) 6 127.0.0.1:6379> set views 0 OK 127.0.0.1:6379> incr views (integer) 1 127.0.0.1:6379> incr views (integer) 2 127.0.0.1:6379> incrby views 10 (integer) 12 127.0.0.1:6379> decrby views 10 (integer) 2 127.0.0.1:6379> decrby views 10 (integer) -8 127.0.0.1:6379> getrange k1 0 -1 "v1-vvv" 127.0.0.1:6379> getrange k1 0 2 "v1-" 127.0.0.1:6379> set k2 abcdefg OK 127.0.0.1:6379> setrange k2 3 xxx (integer) 7 127.0.0.1:6379> get k2 "abcxxxg" 127.0.0.1:6379> setex k3 10 v3 OK 127.0.0.1:6379> ttl k3 (integer) 7 127.0.0.1:6379> ttl k3 (integer) 6 127.0.0.1:6379> ttl k3 (integer) 5 127.0.0.1:6379> ttl k3 (integer) 4 127.0.0.1:6379> ttl k3 (integer) 4 127.0.0.1:6379> ttl k3 (integer) 3 127.0.0.1:6379> ttl k3 (integer) 3 127.0.0.1:6379> ttl k3 (integer) 2 127.0.0.1:6379> ttl k3 (integer) -2 127.0.0.1:6379> ttl k3 (integer) -2 127.0.0.1:6379> setnx k4 v4 (integer) 1 127.0.0.1:6379> setnx k4 v4 (integer) 0 127.0.0.1:6379> setnx k4 v444 (integer) 0 127.0.0.1:6379> get k4 "v4" 127.0.0.1:6379> flushdb OK 127.0.0.1:6379> keys * (empty array) 127.0.0.1:6379> mset k1 v1 k2 v2 OK 127.0.0.1:6379> keys * 1) "k2" 2) "k1" 127.0.0.1:6379> get v2 (nil) 127.0.0.1:6379> get k2 "v2" 127.0.0.1:6379> mget k1 k2 1) "v1" 2) "v2" 127.0.0.1:6379> keys * 1) "k2" 2) "k1" 127.0.0.1:6379> msetnx k1 v1 k4 v4 (integer) 0 127.0.0.1:6379> msetnx k3 v3 k4 v4 (integer) 1 127.0.0.1:6379> msetex k5 v5 k6 v6 127.0.0.1:6379> mset user:1:name wanyu user:1:age 18 OK 127.0.0.1:6379> mget user:1:name user:1:age 1) "wanyu" 2) "18" 127.0.0.1:6379> mset view:1 1 view:2 10 OK 127.0.0.1:6379> get view:1 view:2 (error) ERR wrong number of arguments for 'get' command 127.0.0.1:6379> mget view:1 view:2 1) "1" 2) "10" 127.0.0.1:6379> getset db redis (nil) 127.0.0.1:6379> getset db mongodb "redis" 127.0.0.1:6379> get db "mongodb" 127.0.0.1:6379>
特殊用法:
# 批量设置用户信息
127.0.0.1:6379> mset user:1:name wanyu user:1:age 18
OK
127.0.0.1:6379> mget user:1:name user:1:age
1) "wanyu"
2) "18"
# 批量设置阅览量
127.0.0.1:6379> mset view:1 1 view:2 10
OK
127.0.0.1:6379> mget view:1 view:2
1) "1"
2) "10"
# getset语句
127.0.0.1:6379> getset db redis
(nil)
127.0.0.1:6379> getset db mongodb
"redis"
127.0.0.1:6379> get db
"mongodb"
string类似使用场景:
- 计数器
- 统计多单位的数量 set uid:4564456:follow 0,然后使用incr key统计!
- 粉丝数
- 对象缓存存储
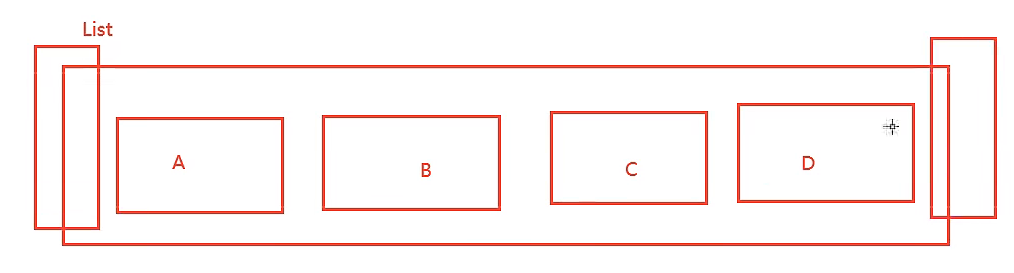
3.2,List
基本的数据类型(双端无环链表),列表可以当做栈(heap,单端、先入后出)、队列(queue、单向进入,反向输出、先入先出)、阻塞队列(两端都可以取阻塞队列)!
命令
lpush(将一个值插入列表头部,左)、rpush(将一个数据插入列表尾部,右)、
lpop(弹出左边的值)、rpop(弹出右边的值)、lrange(查看list数据)、
lindex(通过下标获取某个队列index下标的值,用于生产者和消费者模型)、
llen(查看list的长度)、lrem(移除指定个数的值)、ltrim(截取保留指定的长度)、
rpoplpush(移除列表最右边的元素,添加到新列表的最左边)、lset(给指定的下标设值-更新操作)、
linsert(将某个元素插入到某个已有元素的之前或之后)
点击查看命令执行情况
127.0.0.1:6379> flushdb OK 127.0.0.1:6379> keys * (empty array) 127.0.0.1:6379> lpush l1 1 (integer) 1 127.0.0.1:6379> lpush l1 2 (integer) 2 127.0.0.1:6379> lpush l1 3 (integer) 3 127.0.0.1:6379> keys (error) ERR wrong number of arguments for 'keys' command 127.0.0.1:6379> keys * 1) "l1" 127.0.0.1:6379> lrange l1 1 3 1) "2" 2) "1" 127.0.0.1:6379> lrange l1 1 2 1) "2" 2) "1" 127.0.0.1:6379> lrange l1 0 -1 1) "3" 2) "2" 3) "1" 127.0.0.1:6379> rpush 10 (error) ERR wrong number of arguments for 'rpush' command 127.0.0.1:6379> rpush l1 10 (integer) 4 127.0.0.1:6379> lrange 0 -1 (error) ERR wrong number of arguments for 'lrange' command 127.0.0.1:6379> lrange l1 0 -1 1) "3" 2) "2" 3) "1" 4) "10" 127.0.0.1:6379> lpop l1 "3" 127.0.0.1:6379> rpop l1 "10" 127.0.0.1:6379> lindex l1 1 "1" 127.0.0.1:6379> lindex l1 2 (nil) 127.0.0.1:6379> lindex l1 0 "2" 127.0.0.1:6379> llen l1 (integer) 2 127.0.0.1:6379> flushdb OK 127.0.0.1:6379> lpush l1 0 (integer) 1 127.0.0.1:6379> lpush l1 1 (integer) 2 127.0.0.1:6379> lpush l1 2 (integer) 3 127.0.0.1:6379> lpush l1 3 (integer) 4 127.0.0.1:6379> lpush l1 4 (integer) 5 127.0.0.1:6379> lpush l1 5 (integer) 6 127.0.0.1:6379> lpush l1 6 (integer) 7 127.0.0.1:6379> 127.0.0.1:6379> 127.0.0.1:6379> llen l1 (integer) 7 127.0.0.1:6379> lrange -1 0 (error) ERR wrong number of arguments for 'lrange' command 127.0.0.1:6379> lrange 0 -1 (error) ERR wrong number of arguments for 'lrange' command 127.0.0.1:6379> lrange l1 0 -1 1) "6" 2) "5" 3) "4" 4) "3" 5) "2" 6) "1" 7) "0" 127.0.0.1:6379> lrem l1 1 1 (integer) 1 127.0.0.1:6379> lrem l1 1 1 (integer) 0 127.0.0.1:6379> lrange l1 0 -1 1) "6" 2) "5" 3) "4" 4) "3" 5) "2" 6) "0" 127.0.0.1:6379> flushdb OK 127.0.0.1:6379> keys (error) ERR wrong number of arguments for 'keys' command 127.0.0.1:6379> keys * (empty array) 127.0.0.1:6379> rpush l1 1 (integer) 1 127.0.0.1:6379> rpush l1 2 (integer) 2 127.0.0.1:6379> rpush l1 3 (integer) 3 127.0.0.1:6379> rpush l1 4\ (integer) 4 127.0.0.1:6379> rpush l1 5 (integer) 5 127.0.0.1:6379> lrange l1 0 -1 1) "1" 2) "2" 3) "3" 4) "4\\" 5) "5" 127.0.0.1:6379> ltrim l1 4 5 OK 127.0.0.1:6379> lrange l1 0 -1 1) "5" 127.0.0.1:6379> flushdb OK 127.0.0.1:6379> rpush l1 1 (integer) 1 127.0.0.1:6379> rpush l1 2 (integer) 2 127.0.0.1:6379> rpush l1 3 (integer) 3 127.0.0.1:6379> rpush l1 4 (integer) 4 127.0.0.1:6379> lrange l1 0 -1 1) "1" 2) "2" 3) "3" 4) "4" 127.0.0.1:6379> ltrim l1 1 2 OK 127.0.0.1:6379> lrange l1 0 -1 1) "2" 2) "3" 127.0.0.1:6379> flushdb OK 127.0.0.1:6379> rpush l1 1 (integer) 1 127.0.0.1:6379> rpush l1 2 (integer) 2 127.0.0.1:6379> rpush l1 3 (integer) 3 127.0.0.1:6379> rpoplpush l1 l2 "3" 127.0.0.1:6379> lrange l1 0 -1 1) "1" 2) "2" 127.0.0.1:6379> lrange l2 0 -1 1) "3" 127.0.0.1:6379> flushdb OK 127.0.0.1:6379> exists l1 (integer) 0 127.0.0.1:6379> lset l1 0 0 (error) ERR no such key 127.0.0.1:6379> lpush l1 1 (integer) 1 127.0.0.1:6379> exists l1 (integer) 1 127.0.0.1:6379> lset l1 0 0 OK 127.0.0.1:6379> lrange l1 0 -1 1) "0" 127.0.0.1:6379> lset l1 1 0 (error) ERR index out of range 127.0.0.1:6379> flushdb OK 127.0.0.1:6379> rpush l1 1 (integer) 1 127.0.0.1:6379> rpush l1 2 (integer) 2 127.0.0.1:6379> rpush l1 3 (integer) 3 127.0.0.1:6379> rpush l1 4 (integer) 4 127.0.0.1:6379> rpush l1 5 (integer) 5 127.0.0.1:6379> linsert l1 before 3 33 (integer) 6 127.0.0.1:6379> lrange l1 0 -1 1) "1" 2) "2" 3) "33" 4) "3" 5) "4" 6) "5" 127.0.0.1:6379> linsert l1 after 3 333 (integer) 7 127.0.0.1:6379> lrange l1 0 -1 1) "1" 2) "2" 3) "33" 4) "3" 5) "333" 6) "4" 7) "5" 127.0.0.1:6379>
小结
- 其本质是一个链表,before node after,left 、right都可以插入值
- 如果key不存在,创建新的链表
- 如果key存在,新增内容
- 如果移除了所有制,空链表,也可以代表不存在!
- 在两边插入或者改动值,效率最高!中间元素,效率相对较低
- 使用:消息队列(lpush、rpop)、栈(lpush、lpop)
3.3,Set
set的值是不能重复的,set是无序不重复集合
命令
sadd(新加元素)、smembers(查看所有元素)、sismember(查看是否存在)、
scard(获取集合中元素个数)、srem(移除集合中的某个元素)、
srandmember(随机获取指定个数的元素)、spop(随机移除一个元素)、
smove(将某个集合中的元素移除,并添加到另一个集合)、
sdiff(差集!查看多个集合不同的元素)、sinter(交集!查看多个集合相同的元素)、
sunion(并集!获取多个集合合并后的结果)
点击查看命令执行情况
127.0.0.1:6379> ping PONG 127.0.0.1:6379> 127.0.0.1:6379> sadd s1 1 (integer) 1 127.0.0.1:6379> sadd s1 2 (integer) 1 127.0.0.1:6379> sadd s1 1 (integer) 0 127.0.0.1:6379> smembers s1 1) "1" 2) "2" 127.0.0.1:6379> sismember s1 3 (integer) 0 127.0.0.1:6379> sismember s1 2 (integer) 1 127.0.0.1:6379> sismember s2 2 (integer) 0 127.0.0.1:6379> set k1 v1 OK 127.0.0.1:6379> sismember k1 v1 (error) WRONGTYPE Operation against a key holding the wrong kind of value 127.0.0.1:6379> sadd k1 1 (error) WRONGTYPE Operation against a key holding the wrong kind of value 127.0.0.1:6379> scard s1 (integer) 2 127.0.0.1:6379> srem s1 1 (integer) 1 127.0.0.1:6379> srem s1 1 (integer) 0 127.0.0.1:6379> srandmember s1 "2" 127.0.0.1:6379> srandmember s1 "2" 127.0.0.1:6379> srandmember s1 "2" 127.0.0.1:6379> sadd s1 1 (integer) 1 127.0.0.1:6379> sadd s1 3 (integer) 1 127.0.0.1:6379> sadd s1 4 (integer) 1 127.0.0.1:6379> sadd s1 5 (integer) 1 127.0.0.1:6379> sadd s1 6 (integer) 1 127.0.0.1:6379> sadd s1 7 (integer) 1 127.0.0.1:6379> sadd s1 8 (integer) 1 127.0.0.1:6379> sadd s1 9 (integer) 1 127.0.0.1:6379> sadd s1 0 (integer) 1 127.0.0.1:6379> scard s1 (integer) 10 127.0.0.1:6379> srandmember s1 "3" 127.0.0.1:6379> srandmember s1 3 1) "6" 2) "9" 3) "1" 127.0.0.1:6379> srandmember s1 3 1) "3" 2) "0" 3) "8" 127.0.0.1:6379> srandmember s1 3 1) "5" 2) "3" 3) "9" 127.0.0.1:6379> srandmember s1 3 1) "7" 2) "4" 3) "8" 127.0.0.1:6379> srandmember s1 3 1) "3" 2) "9" 3) "4" 127.0.0.1:6379> srandmember s1 11 1) "0" 2) "1" 3) "2" 4) "3" 5) "4" 6) "5" 7) "6" 8) "7" 9) "8" 10) "9" 127.0.0.1:6379> srandmember s1 15 1) "0" 2) "1" 3) "2" 4) "3" 5) "4" 6) "5" 7) "6" 8) "7" 9) "8" 10) "9" 127.0.0.1:6379> smove s1 s2 9 (integer) 1 127.0.0.1:6379> smembers s1 1) "0" 2) "1" 3) "2" 4) "3" 5) "4" 6) "5" 7) "6" 8) "7" 9) "8" 127.0.0.1:6379> smembers s2 1) "9" 127.0.0.1:6379> smembers s1 1) "0" 2) "1" 3) "2" 4) "3" 5) "4" 6) "5" 7) "6" 8) "7" 9) "8" 127.0.0.1:6379> 127.0.0.1:6379> 127.0.0.1:6379> flushdb OK 127.0.0.1:6379> sadd s1 1 (integer) 1 127.0.0.1:6379> sadd s1 2 (integer) 1 127.0.0.1:6379> sadd s1 3 (integer) 1 127.0.0.1:6379> sadd s1 4 (integer) 1 127.0.0.1:6379> sadd s2 3 (integer) 1 127.0.0.1:6379> sadd s2 4 (integer) 1 127.0.0.1:6379> sadd s2 5 (integer) 1 127.0.0.1:6379> sadd s2 6 (integer) 1 127.0.0.1:6379> sdiff s1 s2 1) "1" 2) "2" 127.0.0.1:6379> sinter s1 s2 1) "3" 2) "4" 127.0.0.1:6379> 127.0.0.1:6379> sunion s1 s2 1) "1" 2) "2" 3) "3" 4) "4" 5) "5" 6) "6" 127.0.0.1:6379> sadd s3 4 6 (integer) 2 127.0.0.1:6379> sadd s3 4 6 7 8 (integer) 2 127.0.0.1:6379> sadd s3 4 6 7 8 9 9 9 (integer) 1 127.0.0.1:6379> sdiff s1 s2 s3 1) "1" 2) "2" 127.0.0.1:6379> sunion s1 s2 s3 1) "1" 2) "2" 3) "3" 4) "4" 5) "5" 6) "6" 7) "7" 8) "8" 9) "9" 127.0.0.1:6379>
样例:微博将A用户的所有关注的人放在一个集合中,将他的粉丝也放在另外一个集合中,可以查看共同关注的人!共同关注、共同爱好、二度好友、推荐好友!(六度分割理论)
3.4,Hash
Map集合,key-value键值对!
命令
hset(新增元素)、hget(获取元素)、hdel(删除某个filed)
hmset(批量更新元素)、hmget(批量获取元素)、
hgetall(获取所有数据)、hlen(获取hash的长度)、
hexists(查看集合中某个key是否存在)、
hkeys(获取所有key)、hvals(获取所有value)、
hincrby(按照步长自增指定个数,可以负值)、hsetnx(如果没有则设置)
点击查看命令执行情况
127.0.0.1:6379> flushdb OK 127.0.0.1:6379> hset h1 f1 v1 (integer) 1 127.0.0.1:6379> hset h1 f2 v2 (integer) 1 127.0.0.1:6379> hget h1 f1 "v1" 127.0.0.1:6379> hget h1 f2 "v2" 127.0.0.1:6379> hget h1 f3 (nil) 127.0.0.1:6379> hmset h1 f3 v3 f4 v4 f5 v5 OK 127.0.0.1:6379> hmget h1 f2 f3 1) "v2" 2) "v3" 127.0.0.1:6379> get h1 (error) WRONGTYPE Operation against a key holding the wrong kind of value 127.0.0.1:6379> hget h1 f1 "v1" 127.0.0.1:6379> hdel h1 f1 (integer) 1 127.0.0.1:6379> hget h1 f1 (nil) 127.0.0.1:6379> hgetall h1 1) "f2" 2) "v2" 3) "f3" 4) "v3" 5) "f4" 6) "v4" 7) "f5" 8) "v5" 127.0.0.1:6379> hlen h1 (integer) 4 127.0.0.1:6379> hexists h1 f1 (integer) 0 127.0.0.1:6379> hexists h1 f2 (integer) 1 127.0.0.1:6379> hkeys h1 1) "f2" 2) "f3" 3) "f4" 4) "f5" 127.0.0.1:6379> hvals h1 1) "v2" 2) "v3" 3) "v4" 4) "v5" 127.0.0.1:6379> hset h2 f1 1 (integer) 1 127.0.0.1:6379> hincrby h2 f1 2 (integer) 3 127.0.0.1:6379> decrby h2 f1 5 (error) ERR wrong number of arguments for 'decrby' command 127.0.0.1:6379> hdecrby h2 f1 5 (error) ERR unknown command `hdecrby`, with args beginning with: `h2`, `f1`, `5`, 127.0.0.1:6379> hsetnx h3 f1 v1 (integer) 1 127.0.0.1:6379> hsetnx h3 f1 v1 (integer) 0 127.0.0.1:6379>
应用
hash变更的数据,尤其是用户信息类的,更加适合对象的存储
3.5,Zset
在set的基础上,增加了一个值,set k1 v1 ,zset k1 score1 v1
底层是压缩列表和跳表实现
命令
zadd(添加元素)、zrange(遍历所有)、zrevrange(反向遍历)、
zrangebyscore(获取筛选后的递增排序结果)、
zrevrangebyscore(获取筛选后的递减排序结果)、zrem(移除元素)、
zcard(获取个数)、zcount(计数)、其中符号(是开区间
点击查看命令执行情况
127.0.0.1:6379> flushdb OK 127.0.0.1:6379> zadd z1 1 1 2 2 3 3 (integer) 3 127.0.0.1:6379> zadd z2 100 wanyu (integer) 1 127.0.0.1:6379> zadd z2 60 zhangsan (integer) 1 127.0.0.1:6379> zadd z2 70 lisi (integer) 1 127.0.0.1:6379> zadd z2 20 wangwu (integer) 1 127.0.0.1:6379> zrangebyscore z2 (error) ERR wrong number of arguments for 'zrangebyscore' command 127.0.0.1:6379> zrangebyscore z2 -inf +inf 1) "wangwu" 2) "zhangsan" 3) "lisi" 4) "wanyu" 127.0.0.1:6379> zrangebyscore z2 +inf -inf (empty array) 127.0.0.1:6379> zrangebyscore z2 -inf +inf withscores 1) "wangwu" 2) "20" 3) "zhangsan" 4) "60" 5) "lisi" 6) "70" 7) "wanyu" 8) "100" 127.0.0.1:6379> zrangebyscore z2 -inf 70 withscores 1) "wangwu" 2) "20" 3) "zhangsan" 4) "60" 5) "lisi" 6) "70" 127.0.0.1:6379> zrevrange z2 (error) ERR wrong number of arguments for 'zrevrange' command 127.0.0.1:6379> zrevrange z2 0 -1 1) "wanyu" 2) "lisi" 3) "zhangsan" 4) "wangwu" 127.0.0.1:6379> zrange z2 0 -1 1) "wangwu" 2) "zhangsan" 3) "lisi" 4) "wanyu" 127.0.0.1:6379> zrangebyscore z2 -inf 70 withscores 1) "wangwu" 2) "20" 3) "zhangsan" 4) "60" 5) "lisi" 6) "70" 127.0.0.1:6379> zrangebyscore z2 -inf (70 withscores 1) "wangwu" 2) "20" 3) "zhangsan" 4) "60" 127.0.0.1:6379> zrevrangebyscore z2 +inf -inf withscores 1) "wanyu" 2) "100" 3) "lisi" 4) "70" 5) "zhangsan" 6) "60" 7) "wangwu" 8) "20" 127.0.0.1:6379> 127.0.0.1:6379> 127.0.0.1:6379> zrem lisi (error) ERR wrong number of arguments for 'zrem' command 127.0.0.1:6379> zrem z2 lisi (integer) 1 127.0.0.1:6379> zcard z2 (integer) 3 127.0.0.1:6379> zcount z2 40 70 (integer) 1 127.0.0.1:6379> zcount z2 40 (70 (integer) 1 127.0.0.1:6379> zcount z2 40 60 (integer) 1 127.0.0.1:6379> zcount z2 40 (60 (integer) 0 127.0.0.1:6379>
应用
set排序、班级成绩、工资,消息的优先级,排行榜应用!
拓展
压缩列表


跳表
可以把它理解为一个丐版的B+树
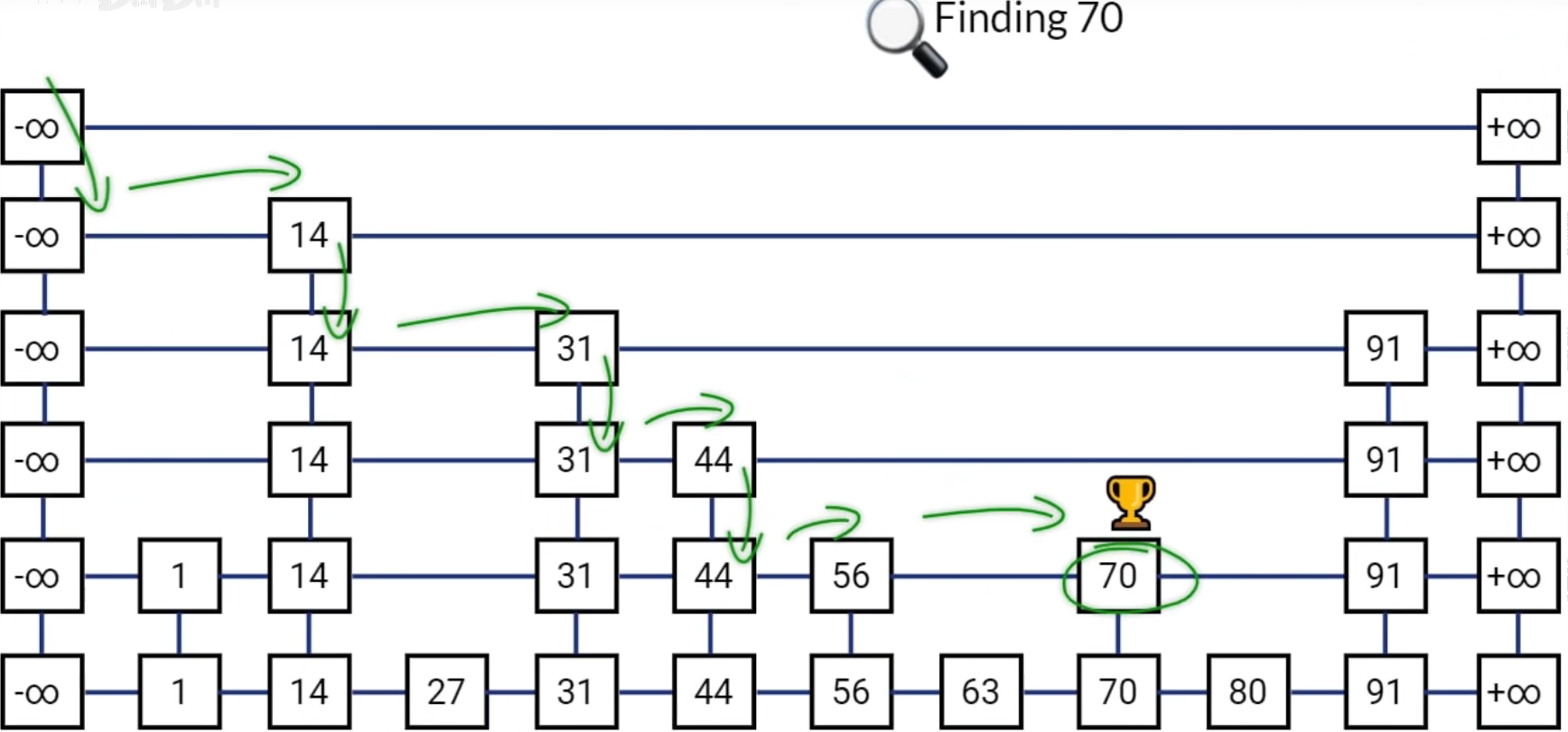
查找、删除、插入
时间复杂度O(logN),空间复杂度O(N)
相较于红黑树或者二叉树优点:
- 范围查询(直接找到2个节点然后直接返回中间数据)!
- 实现更加简单
4,三种特殊数据类型
4.1,Geospatial
地理位置类型,朋友定位、附件的人、打车距离,redis3.2版本已经推出了
命令
geoadd(添加地理位置)、geodist(查看两地距离)、
geopos(获取某个地点的经纬度)、georadius(查看方圆特定距离内的城市)、
georadiusbymember(查看方圆特定距离的元素成员)、geohash(将二维的坐标转为一维的,降维)、
点击查看命令执行情况
127.0.0.1:6379> flushdb OK 127.0.0.1:6379> 127.0.0.1:6379> 127.0.0.1:6379> geoadd china:city 116.408 39.904 beijing (integer) 1 127.0.0.1:6379> geoadd china:city 120.165 30.319 hangzhou (integer) 1 127.0.0.1:6379> geoadd china:city 114.279 30.573 wuhan (integer) 1 127.0.0.1:6379> geodist china:city wuhan hangzhou "565044.5982" 127.0.0.1:6379> geodist china:city wuhan hangzhou km "565.0446" 127.0.0.1:6379> geodist china:city wuhan hangzhou kmg (error) ERR unsupported unit provided. please use m, km, ft, mi 127.0.0.1:6379> 127.0.0.1:6379> 127.0.0.1:6379> geopos china:city hangzhou 1) 1) "120.16499966382980347" 2) "30.31899997732214302" 127.0.0.1:6379> georadius china:city 110 30 1000 km 1) "wuhan" 2) "hangzhou" 127.0.0.1:6379> georadius china:city 110 30 1000 km withcoord 1) 1) "wuhan" 2) 1) "114.27899926900863647" 2) "30.57299931525717795" 2) 1) "hangzhou" 2) 1) "120.16499966382980347" 2) "30.31899997732214302" 127.0.0.1:6379> georadius china:city 110 30 1000 km withcoord withdist 1) 1) "wuhan" 2) "415.8636" 3) 1) "114.27899926900863647" 2) "30.57299931525717795" 2) 1) "hangzhou" 2) "977.8811" 3) 1) "120.16499966382980347" 2) "30.31899997732214302" 127.0.0.1:6379> georadius china:city 110 30 1000 km withcoord withdist withhash 1) 1) "wuhan" 2) "415.8636" 3) (integer) 4052121270844835 4) 1) "114.27899926900863647" 2) "30.57299931525717795" 2) 1) "hangzhou" 2) "977.8811" 3) (integer) 4054135069633163 4) 1) "120.16499966382980347" 2) "30.31899997732214302" 127.0.0.1:6379> georadius china:city 110 30 1000 km withcoord withdist withhash count (error) ERR syntax error 127.0.0.1:6379> georadius china:city 110 30 1000 km count (error) ERR syntax error 127.0.0.1:6379> georadius china:city 110 30 1000 km count (error) ERR syntax error 127.0.0.1:6379> 127.0.0.1:6379> 127.0.0.1:6379> georadiusbymember china:city beijing 1000 km 1) "beijing" 127.0.0.1:6379> georadiusbymember china:city beijing 2000 km 1) "wuhan" 2) "hangzhou" 3) "beijing" 127.0.0.1:6379> georadiusbymember china:city beijing 1500 km 1) "wuhan" 2) "hangzhou" 3) "beijing" 127.0.0.1:6379> georadiusbymember china:city beijing 1300 km 1) "wuhan" 2) "hangzhou" 3) "beijing" 127.0.0.1:6379> georadiusbymember china:city beijing 1200 km 1) "beijing" 2) "wuhan" 3) "hangzhou" 127.0.0.1:6379> georadiusbymember china:city beijing 1100 km 1) "beijing" 2) "wuhan" 127.0.0.1:6379> geohash china:city (empty array) 127.0.0.1:6379> geohash china:city beijing 1) "wx4g0bm9xh0" 127.0.0.1:6379> geohash china:city beijing hangzhou 1) "wx4g0bm9xh0" 2) "wtmkqrmkzr0" 127.0.0.1:6379> zrange china:city 0 -1 1) "wuhan" 2) "hangzhou" 3) "beijing" 127.0.0.1:6379> zrangebyscore china:city 0 -1 withscores (empty array) 127.0.0.1:6379> zrangebyscore china:city -inf +inf withscores 1) "wuhan" 2) "4052121270844835" 3) "hangzhou" 4) "4054135069633163" 5) "beijing" 6) "4069885369376452"
geo的底层原理其实就是Zset,我们可以使用Zset命令来操作geo,可以通过zrange查看geo的数据
4.2,hyperloglog
什么是基数?
A{1,3,5,7,8,9},B{1,3,5,7,8},基数(不重复元素的个数)
redis 2.8.9版本推出更新hyperloglog数据结构!
网页的UV(一人访问一个网站多次,但是还是算作一个人)!
传统的使用set进行存储,但是会消耗大量的内存空间!
优点:2^64不同的元素统计,只需要耗费12kb的内存!(但是有0.81%的错误率)
命令
pfadd(新增元素)、pfmerge(合并到新对象)、pfcount(统计数据)
点击查看命令执行情况
127.0.0.1:6379> flushdb OK 127.0.0.1:6379> pfadd hy1 a b c d e f (integer) 1 127.0.0.1:6379> pfadd hy2 e f g h i j k (integer) 1 127.0.0.1:6379> pfmerge hy3 hy1 hy2 OK 127.0.0.1:6379> pfcount hy3 (integer) 11 127.0.0.1:6379> pfcount hy1 (integer) 6 127.0.0.1:6379> pfcount hy2 (integer) 7 127.0.0.1:6379> pfadd hy4 a a a b (integer) 1 127.0.0.1:6379> pfcount hy4 (integer) 2 127.0.0.1:6379>
如果允许容错,就直接使用hyperloglog;否则使用set即可!
4.3,bitmaps
位存储
统计疫情感染人数: 0 0 0 0 1 0 1
统计用户信息:活跃、不活跃!登录、未登录!打卡,365打卡(只有2个状态)
bitmaps位图,数据结构!操作二进制位来记录,就只有0和1两个状态
命令
setbit(设置元素)、getbit(获取元素)、bitcount(获取统计结果)
点击查看命令执行情况
127.0.0.1:6379> flushdb OK 127.0.0.1:6379> setbit b1 0 0 (integer) 0 127.0.0.1:6379> setbit b1 4 0 (integer) 0 127.0.0.1:6379> setbit b1 4 0 (integer) 0 127.0.0.1:6379> getbit b1 (error) ERR wrong number of arguments for 'getbit' command 127.0.0.1:6379> getbit b1 0 (integer) 0 127.0.0.1:6379> getbit b1 1 (integer) 0 127.0.0.1:6379> getbit b1 2 (integer) 0 127.0.0.1:6379> getbit b1 100 (integer) 0 127.0.0.1:6379> setbit b1 100 1 (integer) 0 127.0.0.1:6379> setbit b1 100 1 (integer) 1 127.0.0.1:6379> setbit b1 100 1 (integer) 1 127.0.0.1:6379> setbit b1 100 1 (integer) 1 127.0.0.1:6379> getbit b1 100 1 (error) ERR wrong number of arguments for 'getbit' command 127.0.0.1:6379> getbit b1 100 (integer) 1 127.0.0.1:6379> bitcount b1 (integer) 1
5,事务
一个事务中的所有命令会被序列化!会按照顺序执行!redis事务没有隔离的概念!
所有的命令在事务中,并没有被执行!只有发起执行命令的时候才会执行!
redis单条命令是保证原子性的,但是事务不保证原子性!
回顾事务:ACID原则-Atomicity原子性、consistency一致性、isolation隔离性、durability持久性。
- Atomicity(原子性):一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
- Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
- Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
redis事务:
- 开启事务(multi)
- 命令入队(普通redis命令)
- 执行事务(exec)
- 放弃事务(discard)
- 监视某个key(watch)
- 取消监控(unwatch)
5.1,命令
正常执行事务
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> set k1 1
QUEUED
127.0.0.1:6379(TX)> set k2 2
QUEUED
127.0.0.1:6379(TX)> set k3 3
QUEUED
127.0.0.1:6379(TX)> exec
1) OK
2) OK
3) OK
放弃事务
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> set k1 1
QUEUED
127.0.0.1:6379(TX)> set k2 1
QUEUED
127.0.0.1:6379(TX)> get k2
QUEUED
127.0.0.1:6379(TX)> discard
OK
127.0.0.1:6379> get k2
"2"
编译型异常(命令不对),所有的命令都不会执行!
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> set k1 v1
QUEUED
127.0.0.1:6379(TX)> set k2 v2
QUEUED
127.0.0.1:6379(TX)> getset k3
(error) ERR wrong number of arguments for 'getset' command
127.0.0.1:6379(TX)> getset k3 v3
QUEUED
127.0.0.1:6379(TX)> exec
(error) EXECABORT Transaction discarded because of previous errors.
运行时异常(1/0),如果事务队列中存在语法性,那么执行命令的时候,其他命令可以正常执行,错误命令会抛出异常!
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> set k1 "v1"
QUEUED
127.0.0.1:6379(TX)> incr k1
QUEUED
127.0.0.1:6379(TX)> set k2 v2
QUEUED
127.0.0.1:6379(TX)> get k2
QUEUED
127.0.0.1:6379(TX)> exec
1) OK
2) (error) ERR value is not an integer or out of range
3) OK
4) "v2"
5.2,监控(watch)
悲观锁:
- 很悲观,小心翼翼,认为什么时候都会出问题(效率很低,volatile、synchronized)
乐观锁:
- 很乐观,大大咧咧,认为什么时候都不会出问题。更新数据的时候去判断一下,在此期间是否有人修改过数据(version)
正常执行命令
127.0.0.1:6379> set money 100
OK
127.0.0.1:6379> set out 0
OK
127.0.0.1:6379> watch money # 监视期间数据没有发生变动
OK
127.0.0.1:6379> multi # 事务正常结束,期间没有数据发生变动
OK
127.0.0.1:6379(TX)> decrby money 20 #
QUEUED
127.0.0.1:6379(TX)> incrby out 20
QUEUED
127.0.0.1:6379(TX)> exec
1) (integer) 80
2) (integer) 20
127.0.0.1:6379>
异常执行结果!可以当做redis乐观锁操作!
线程1开启事务后,线程2修改money值,导致线程1exec失败!
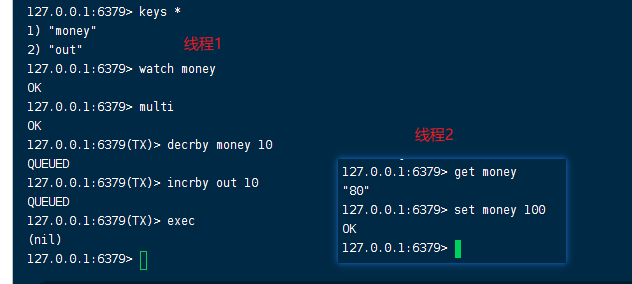
解决办法unwatch,如果执行失败就重新监控执行!
127.0.0.1:6379> unwatch
OK
127.0.0.1:6379> watch money
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> decrby money 10
QUEUED
127.0.0.1:6379(TX)> incrby out 10
QUEUED
127.0.0.1:6379(TX)> get money
QUEUED
127.0.0.1:6379(TX)> exec
1) (integer) 90
2) (integer) 30
3) "90"
watch和unwatch只在单个命令窗口有效!已经实际测试过!
6,Jedis
本质就是redis的命令执行器所有的命令都没有变化,redis官方推荐的java连接工具!使用java操作redis的中间件!
6.1,导入对应的依赖
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<!-- 2022.03.03 当前最新的依赖 -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.1.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.79</version>
</dependency>
6.2,编码测试
- 连接数据库
- 操作命令
- 断开连接
@Lazy
@Log4j2
@Service(value = "jedisImpl")
public class JedisImpl implements InitializingBean {
@Value("${redis.ip:127.0.0.1}")
private String redisIp;
@Value("${redis.port:6379}")
private Integer redisPort;
@Value("${redis.auth:123456}")
private String redisAuth;
Jedis jedis;
@Override
public void afterPropertiesSet() {
jedis = new Jedis(redisIp, redisPort);
log.info(jedis.auth(redisAuth));
log.info(jedis.ping());
// redis事务!
jedis.watch("k1");
Transaction multi = jedis.multi();
try {
multi.watch("k1");
multi.set("k1","v1");
multi.set("k2","v2");
int i = 1/0;
log.info(multi.get("k1"));
log.info(JSONObject.toJSONString(multi.exec()));
}catch (Exception e){
multi.discard();
multi.unwatch();
log.info("jedis 事务失败! ");
}
}
}
常用的api:五大基本类型、3大特殊类型
7,springBoot整合
Spring-data,在springBoot2.x之后,原来使用的jedis被替换为lettuce?
jedis:采用直连,多个线程直连的话是不安全的,如果想要避免不安全的,需要使用jedis pool!BIO
lettuce:采用netty,实例可以在读哟个线程中共享,不存在线程安全问题!可以减少线程安全问题,更想NIO模式!高级Redis客户端,用于线程安全同步,异步和响应使用,支持集群,Sentinel,管道和编码器。目前springboot默认使用的客户端(RedisTemplate)。
依赖包:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
如何查找redis相关配置
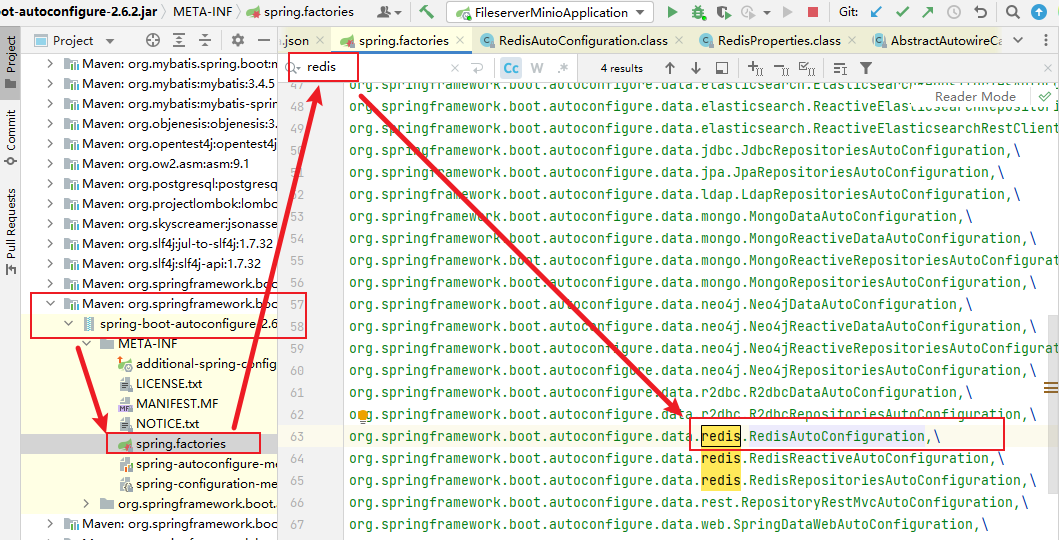
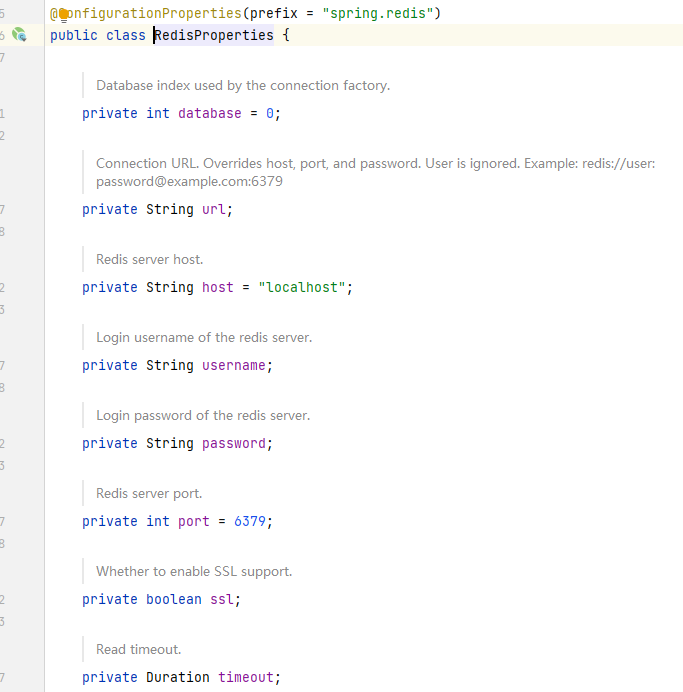
源码分析(RedisTemplate模板类):
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(RedisOperations.class)
@EnableConfigurationProperties(RedisProperties.class)
@Import({ LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class })
public class RedisAutoConfiguration {
@Bean
@ConditionalOnMissingBean(name = "redisTemplate") // 我们可以自己定义一个模板类
@ConditionalOnSingleCandidate(RedisConnectionFactory.class)
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
// 默认没有过多的设置
// 两个泛型都是object类型
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean // 最常使用的类
@ConditionalOnSingleCandidate(RedisConnectionFactory.class)
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory) {
return new StringRedisTemplate(redisConnectionFactory);
}
}

测试类:
@SpringBootTest
class RedisStudy001ApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
System.out.println("hello");
redisTemplate.opsForValue().set("name","wanyu");
System.out.println(redisTemplate.opsForValue().get("name"));
}
}
结果(被序列化):
127.0.0.1:6379[1]> keys *
1) "\xac\xed\x00\x05t\x00\x04name"
自定义RedisTemplate
@Configuration
public class RedisConfig {
// 自定义配置类
@Bean
@SuppressWarnings("all")
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> template = new RedisTemplate<String, Object>();
template.setConnectionFactory(redisConnectionFactory);
// jackson序列化
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper objecMapper = new ObjectMapper();
objecMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
objecMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(objecMapper);
// String序列化
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
// key采用String序列化
template.setKeySerializer(stringRedisSerializer);
template.setHashKeySerializer(stringRedisSerializer);
template.setValueSerializer(jackson2JsonRedisSerializer);
template.setHashValueSerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
8,配置解析
如果使用docker运行redis,则直接进入redis.conf的外部挂载卷文件查看即可
启动的时候通过配置文件来启动!
- 单位
# Redis configuration file example.
#
# Note that in order to read the configuration file, Redis must be
# started with the file path as first argument:
#
# ./redis-server /path/to/redis.conf
# Note on units: when memory size is needed, it is possible to specify
# it in the usual form of 1k 5GB 4M and so forth:
#
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
#
# units are case insensitive so 1GB 1Gb 1gB are all the same.
1,配置文件unit单位对大小写不敏感!
- 配置包含(INCLUDES)
################################## INCLUDES ###################################
# Include one or more other config files here. This is useful if you
# have a standard template that goes to all Redis servers but also need
# to customize a few per-server settings. Include files can include
# other files, so use this wisely.
#
# Note that option "include" won't be rewritten by command "CONFIG REWRITE"
# from admin or Redis Sentinel. Since Redis always uses the last processed
# line as value of a configuration directive, you'd better put includes
# at the beginning of this file to avoid overwriting config change at runtime.
#
# If instead you are interested in using includes to override configuration
# options, it is better to use include as the last line.
#
# include /path/to/local.conf
# include /path/to/other.conf
就好比Nginx、spring的配置包含
- 模块(MODULES)
- 网络(NETWORK)
# bing 绑定监听iP
# bind 192.168.1.100 10.0.0.1 # listens on two specific IPv4 addresses
# bind 127.0.0.1 ::1 # listens on loopback IPv4 and IPv6
# bind * -::* # like the default, all available interfaces
bind * -::* # 绑定监听iP,可以监听所有ip
protected-mode yes # 保护模式
port 6379 # 端口设置
tcp-backlog 511 #
timeout 0
- 通用配置
daemonize no #是否以守护进程运行,docker容器化没有必要设置该值,docker有自己的配置
pidfile /var/redis/run/redis_6379.pid # 如果上文配置了yes才需要写入pid到该文件
loglevel notice # 日志级别,notice适量日志信息,使用于生产环境
logfile /var/redis/log/redis_6379.log # 日志目录
databases 16 # 数据库个数默认16个,0-15db
always-show-logo no # 是否显示启动log
- 快照(SNAPSHOTTING)
持久化文件,在规定的时间与规则下进行持久化备份!(.rdb文件)
# 3600秒内有1个key修改就持久化一次
save 3600 1
# 300秒内 有100个key修改就持久化一次
save 300 100
# 60秒内 有10000个key修改就持久化一次
save 60 10000
stop-writes-on-bgsave-error yes # 持久化出错后,是否继续工作
rdbcompression yes # 是否压缩cpu的资源
rdbchecksum yes # 保存rdb文件的时候,进行错误校验
rdb-del-sync-files no #rdb文件是否删除同步锁
dbfilename dump.rdb # rdb文件名称
dir ./ # 保存路径
-
主从复制(REPLICATION)
-
(KEYS TRACKING)
-
安全(SECURITY)
requirepass xxxx # 设置密码
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) "xxxx"
- 客户端(CLIENTS)
maxclients 10000 # 最大连接数
-
内存限制(MEMORY MANAGEMENT)
maxmemory <bytes> # 内存限制
maxmemory-policy noeviction # 内存达到上限后的处理策略
1、volatile-lru:只对设置了过期时间的key进行LRU(默认值)
2、allkeys-lru : 删除lru算法的key
3、volatile-random:随机删除即将过期key
4、allkeys-random:随机删除
5、volatile-ttl : 删除即将过期的
6、noeviction : 永不过期,返回错误
- 延迟释放(LAZY FREEING)
lazyfree-lazy-eviction:针对redis内存使用达到maxmeory,并设置有淘汰策略时;在被动淘汰键时,是否采用lazy free机制;
因为此场景开启lazy free, 可能使用淘汰键的内存释放不及时,导致redis内存超用,超过maxmemory的限制。此场景使用时,请结合业务测试。
lazyfree-lazy-expire --todo 验证这类操作 同步到从库的是DEL还是UNLINK:针对设置有TTL的键,达到过期后,被redis清理删除时是否采用lazy free机制;此场景建议开启,因TTL本身是自适应调整的速度。
lazyfree-lazy-server-del:针对有些指令在处理已存在的键时,会带有一个隐式的DEL键的操作。如rename命令,当目标键已存在,redis会先删除目标键,如果这些目标键是一个big key,那就会引入阻塞删除的性能问题。 此参数设置就是解决这类问题,建议可开启。
slave-lazy-flush:针对slave进行全量数据同步,slave在加载master的RDB文件前,会运行flushall来清理自己的数据场景,
参数设置决定是否采用异常flush机制。如果内存变动不大,建议可开启。可减少全量同步耗时,从而减少主库因输出缓冲区爆涨引起的内存使用增长。
redis重度使用患者应该都遇到过使用 DEL 命令删除体积较大的键, 又或者在使用 FLUSHDB 和 FLUSHALL 删除包含大量键的数据库时,造成redis阻塞的情况;另外redis在清理过期数据和淘汰内存超限的数据时,如果碰巧撞到了大体积的键也会造成服务器阻塞。(前台线程逻辑删除、后台线程真实删除)
DEL命令 在删除单个集合类型的Key时,命令的时间复杂度是O(M),其中M是集合类型Key包含的元素个数。
DEL keyTime complexity: O(N) where N is the number of keys that will be removed. When a key to remove holds a value other
than a string, the individual complexity for this key is O(M) where M is the number of elements in the list, set, sorted set or hash.
Removing a single key that holds a string value is O(1).
为了解决以上问题, redis 4.0 引入了lazyfree的机制,它可以将删除键或数据库的操作放在后台线程里执行, 从而尽可能地避免服务器阻塞。
#define LAZYFREE_THRESHOLD 64
// 首先定义了启用后台删除的阈值,对象中的元素大于该阈值时才真正丢给后台线程去删除,如果对象中包含的元素太少就没有必要丢给后台线程,因为线程同步也要一定的消耗。
int dbAsyncDelete(redisDb *db, robj *key) {
if (dictSize(db->expires) > 0) dictDelete(db->expires,key->ptr);
//清除待删除key的过期时间
dictEntry *de = dictUnlink(db->dict,key->ptr);
//dictUnlink返回数据库字典中包含key的条目指针,并从数据库字典中摘除该条目(并不会释放资源)
if (de) {
robj *val = dictGetVal(de);
size_t free_effort = lazyfreeGetFreeEffort(val);
//lazyfreeGetFreeEffort来获取val对象所包含的元素个数
if (free_effort > LAZYFREE_THRESHOLD && val->refcount == 1) {
atomicIncr(lazyfree_objects,1);
//原子操作给lazyfree_objects加1,以备info命令查看有多少对象待后台线程删除
bioCreateBackgroundJob(BIO_LAZY_FREE ,val,NULL,NULL);
//此时真正把对象val丢到后台线程的任务队列中
dictSetVal(db->dict,de,NULL);
//把条目里的val指针设置为NULL,防止删除数据库字典条目时重复删除val对象
}
}
if (de) {
dictFreeUnlinkedEntry(db->dict,de);
//删除数据库字典条目,释放资源
return 1;
} else {
return 0;
}
}
以上便是异步删除的逻辑,首先会清除过期时间,然后调用dictUnlink把要删除的对象从数据库字典摘除,再判断下对象的大小(太小就没必要后台删除),如果足够大就丢给后台线程,最后清理下数据库字典的条目信息。
由以上的逻辑可以看出,当unlink一个体积较大的键时,实际的删除是交给后台线程完成的,所以并不会阻塞redis
- aof配置(APPEND ONLY MODE)
appendonly no # 默认不开启,默认使用rdb模式已经够了
appendfilename "appendonly.aof"
# appendfsync always
appendfsync everysec # 每秒执行一次
# appendfsync no
9,持久化
redis是内存数据库(RAM,随机存取存储器),一点掉电或者重启都会消失,只有进行持久化操作才能恢复!
9.1,rdb(redis database)
类似于阿里云ECS的的快照功能,它有自己的定时、阈值策略。生产环境需要进行备份
在主从复制中,rdb就是备用的,在从机上面
redis会单独创建(fork)一个子进程来进行持久化,先将数据写入一个临时文件,待持久化过程结束,再用这个临时文件替代上次的持久化文件!整个过程,主进程是不进行IO操作的,这就保证了极高的性能。如果需要进行大规模的数据恢复,且对于数据的完整性不是特别敏感,那么使用rdb比使用aof方式更加高效。rdb的缺点是最后一次持久化后的数据可能会丢失!(时间差!)
# 配置
# 3600秒内有1个key修改就持久化一次
save 3600 1
# 300秒内 有100个key修改就持久化一次
save 300 100
# 60秒内 有10000个key修改就持久化一次
save 60 10000
stop-writes-on-bgsave-error yes # 持久化出错后,是否继续工作
rdbcompression yes # 是否压缩cpu的资源
rdbchecksum yes # 保存rdb文件的时候,进行错误校验
dbfilename dump.rdb # rdb文件名称
dir ./ # 保存路径
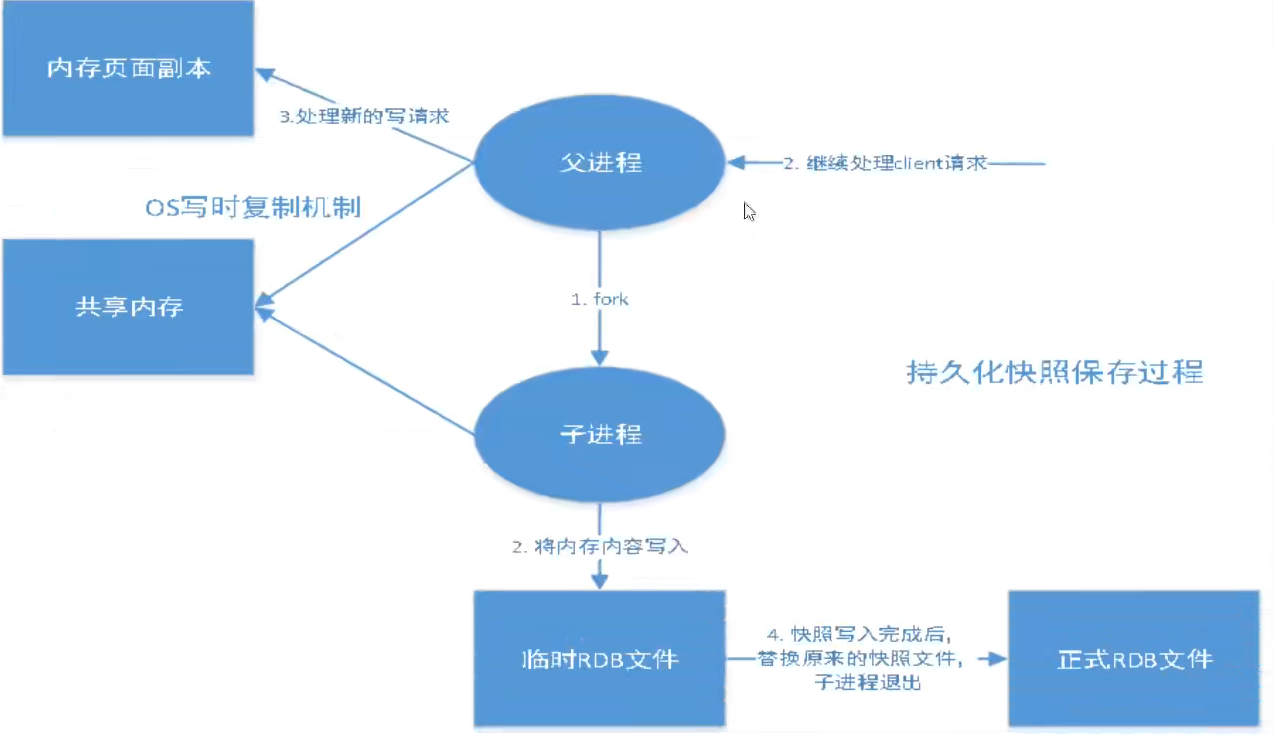
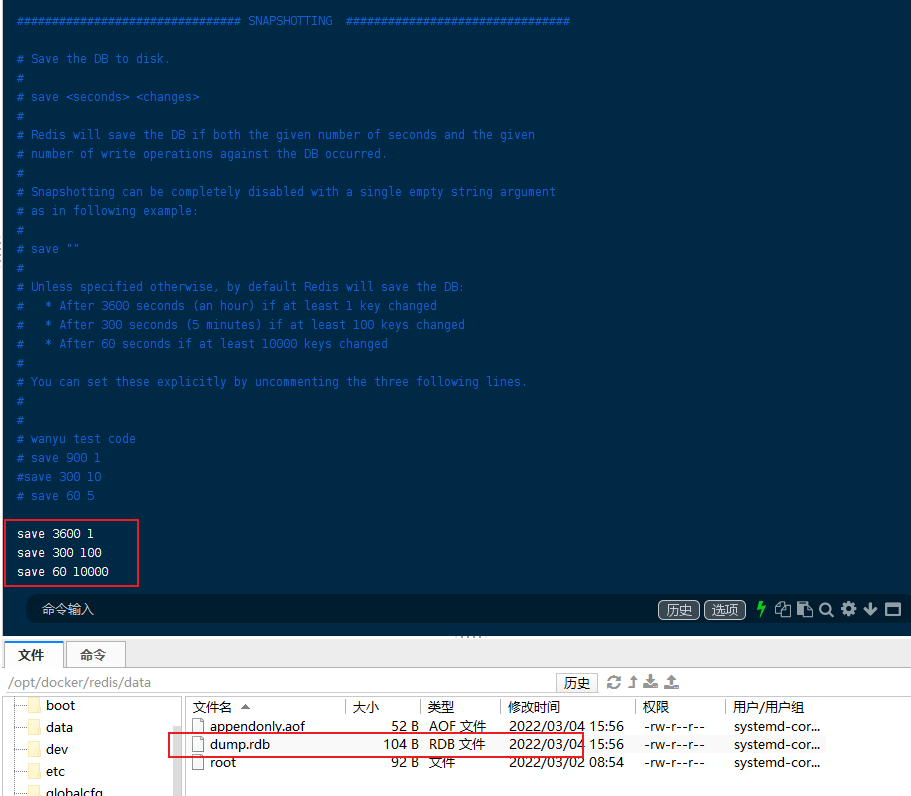
- 通过.rdb文件恢复数据
1,只需要将rdb文件放在我们redis的启动目录就可以,redis启动的时候会自动检查.rdb文件
2,config get dir查看放置的位置(几乎它自己的配置就够用了)
> config get dir #通过该命令查询放置的位置,如果使用docker数据卷挂载就直接放心外部相应的挂载点即可
dir
/data
优点:
1,适合大规模的数据恢复!
2,对数据的完整性不高!
缺点:
1,需要一定的时间间隔进程操作!如果redis意外宕机,这个最后一次修改的数据就没有了(2次快照间隔的时间点,即到未到的快照节点)
2,fork进程的时候,会占用一定的内容空间
9.2,aof(append only file)
将所有命令记录下来(history),恢复的时候把所有文件全部执行一遍!
以日志的形式记录每一个写操作,将redis执行过的所有命令记录,只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,redis重启会更加日志文件将写命令从前到后执行一次以完成数据的恢复!
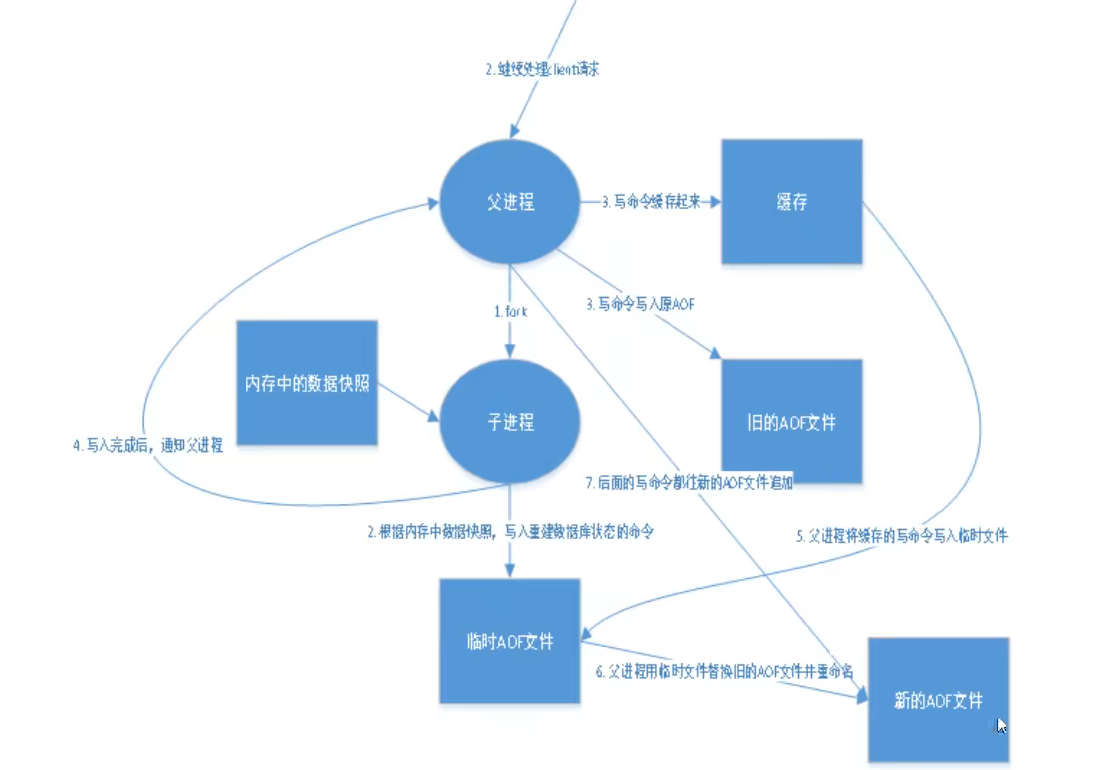
配置
appendonly no # 默认不开启,默认使用rdb模式已经够了
appendfilename "appendonly.aof"
# appendfsync always
appendfsync everysec # 每秒执行一次
# appendfsync no
no-appendfsync-on-rewrite no # 是否进行重新
# 重写规则!
auto-aof-rewrite-percentage 100 # aof就是无限默认追加
auto-aof-rewrite-min-size 64mb # 如果文件大于64mb,fork一个新的进程来将我们的文件重写
随着命令不断写入AOF,文件会越来越大==redis如何控制AOF大小,为了解决这个问题,redis引入了AOF重写机制压缩文件。文件能缩小的原因是:
1.旧文件中的无效命令不会保留,如del key1,sort。
2.多条合并成一条,如lplush list a,lplush list b转换为lplush a b,也可以合并重复项。
- 如果出现手动篡改的值导致恢复失败
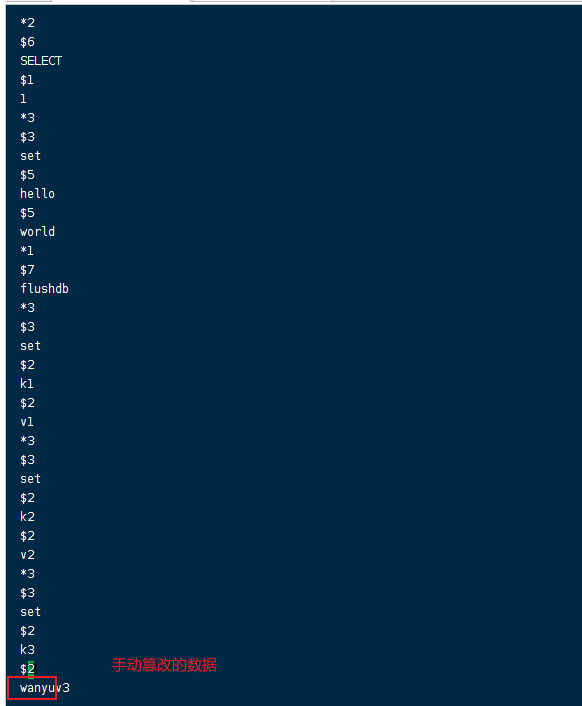
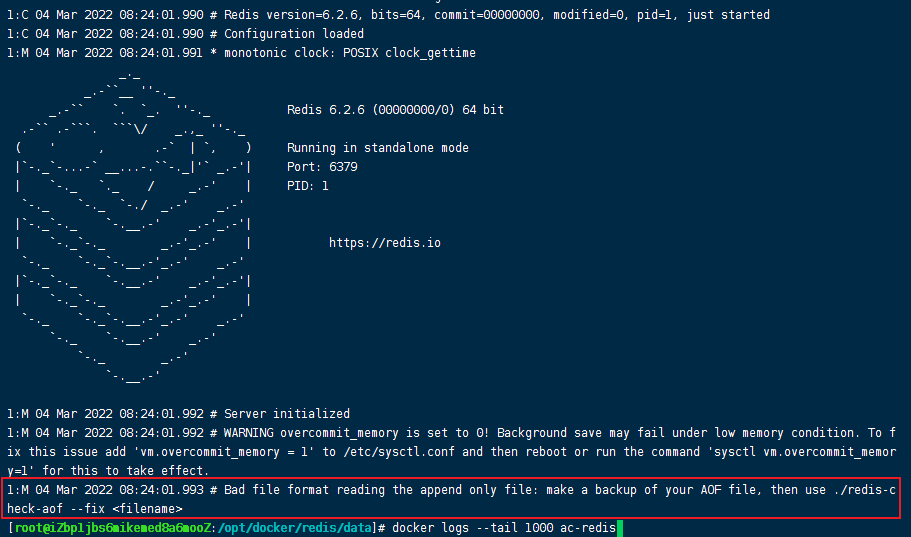
解决办法:
- 因为我这边使用的docker启动redis,redis容器启动不了,我这边使用不了里面的redis-check-aof工具,所以我这边先把这个坏掉的appendonly.aof改名为appendonly.aof-bak!
- 然后正确无数据恢复的情况下启动redis容器,之后进入redis容器内部,/usr/local/bin目录下使用redis-check-aof工具修复我的appendonly.aof-bak文件
- 最后,修改appendonly.aof-bak文件为appendonly.aof,如果文件修复好了就可以重启容器即可完成!!

优点:
- 每一次修改都同步,文件的完整性会更好
- 每秒同步一次,可能会丢失一秒数据
- 从不同步,效率最高
缺点:
- 相对于数据文件来说,aof远远大于rdb,恢复的速度也比rdb慢
- aof的运行效率比rdb慢,所以我们一般都是使用redis默认的rdb即可
扩展:
- rdb持久化能够在指定时间和策略下对数据进行快照存储
- aof持久化方式每次对服务器写的操作进行记录,redis重启时通过执行命令来恢复数据,aof每次追加保存写的操作到文件末尾,redis还能对aof文件进行后台重写,使得aof体积不至于过大!
- 如果只做缓存,就没有必要开启持久化
- 同时开启2种持久化,优先载入aof文件原因是aof数据更加完整!要不要只使用aof来进行持久化呢?不建议因为rdb更适合进行备份数据库(aof在不断变化不好备份),快速重启,而且aof可能会有一些bug,留作备用
- 性能建议:rdb一般只用作备份建议只在slave上进行持久化rdb文件,而且只需要15分钟备份一次即可只保留save 900 1;如果开启aof,好处是最恶劣的情况数据丢失不会超过2秒,启动脚本简单只load自己的aof文件即可,代价是带来持续的io,并且aof rewrite过程中将新数据写入新文件造成的阻塞几乎是必须的。只要硬盘许可,应该尽量减少aof rewrite的评论,两个重写的配置往大调节;如果不开启aof,仅靠master-slave repllcation实现该可用,能够省掉一大笔io,也减少了rewrite带来的系统性能波动。代价是如果master/slave都同时坏掉(断电),会丢失几十分钟的数据,启动脚本也要比较两个master、slave的rdb文件,载入那个较新(或者最大),微博就是这种架构!
10,发布订阅
redis发布订阅(pub/sub)是一种消息通信模式:发布者(pub)发送消息,订阅者(sub)接收消息!
redis客户端可以订阅任意数量的频道!
被广泛应用于即时通讯应用,比如网络聊天室(chartroom)和实时广播、实时提醒等。微信、微博、关注系统
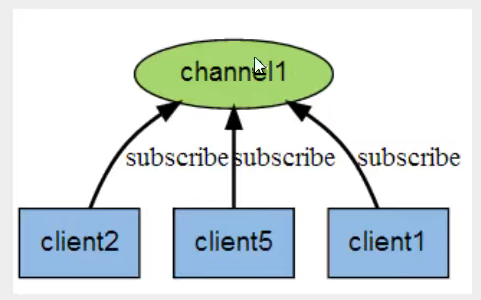
订阅/发布消息图:
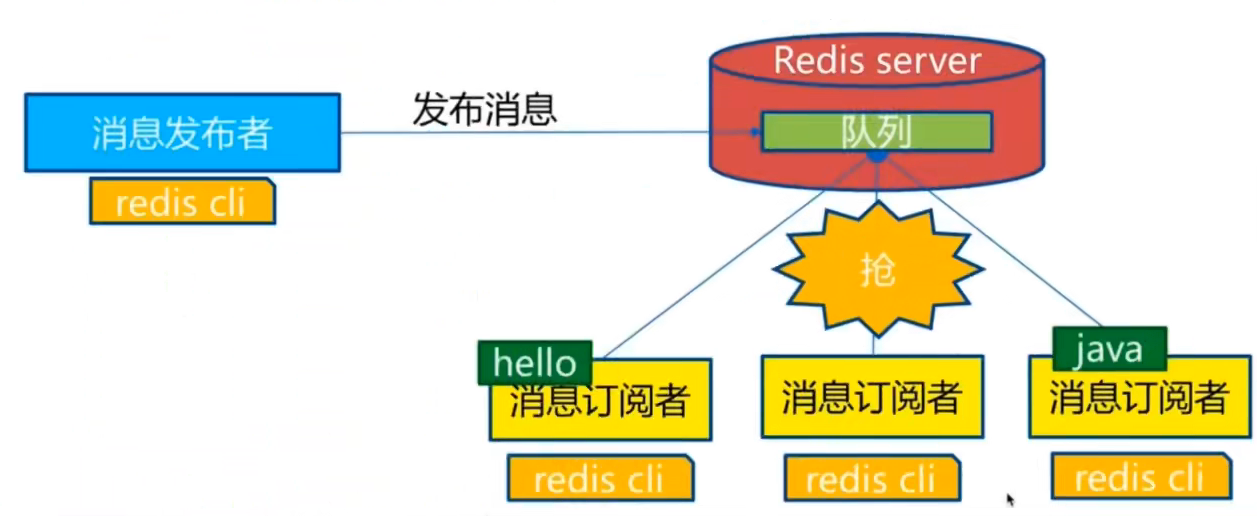
channel1有3个订阅者(消息接收者)
当有消息发送者发布消息时,就会自动给这个channel发送消息
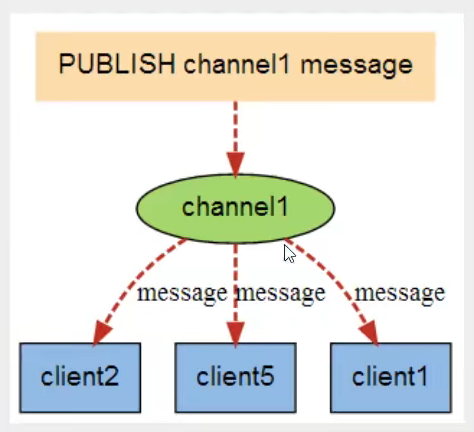
命令
- publish(消息发布)、psubscribe(订阅频道)
- punsubscribe(退订频道)
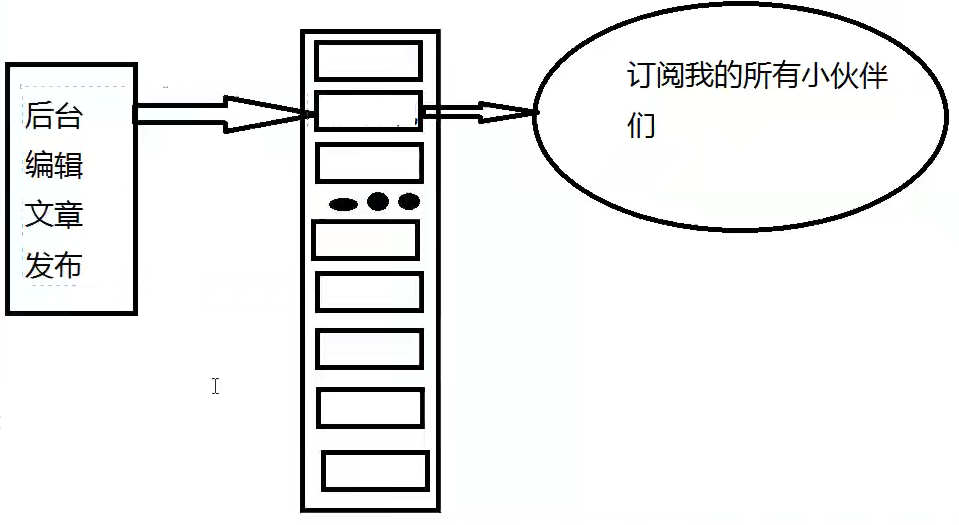
原理
通过subscribe命令订阅某个频道后,redis-server会维护一个字典,字典里面就是一个个频道,而字典的值则是一个链表,链表中保存了所有订阅这个频道的客户端。subscribe命令的核心是将客户端添加给特定channel的订阅链表中。
通过publish命令发送消息。redisserver会使用给定的频道作为关键字,在它维护的channel字典中查找记录了订阅这个频道的所有客户端的链表,遍历这个链表将消息发布给所有订阅者!
使用场景
- 实时消息系统
- 实时聊天
- 订阅关注系统
稍微复杂的逻辑就会使用消息中间件来实现(rabbitmq、rocketmq、activemq)
11,主从复制
11.1,概念
主从复制是指将一台redis服务器的数据,复制到其他的redis服务器。前者称为主节点(master/leader),后者称为从节点(slave/follower);数据的复制是单向的,只能由主节点到从节点。master以写为主,slave以读为主。
默认情况下,每台redis服务器都是主节点;且一个主节点可以由多个从节点(或者没有从节点)。但一个从节点只能由一个主节点。
主从复制的作用:
- 数据冗余:主从复制实现的数据的热备份,是持久化之外的一种数据冗余方式(备份机!备胎)
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;服务冗余(备胎)
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写redis数据时应用链接到主节点,读取数据时链接到从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高redis服务器的并发量!
- 高可用(集群)基石:除了上述作用以为,主从复制还是哨兵和集群能够与实施的基础,因此说主从复制是redis高可用的基础。
生产环境中要将redis运用于工程项目中,只使用1台redis服务器保障性不够:
- 从结构上,单个redis服务器会发生单点故障,并且只有一台服务器需要处理所有的请求负载,压力较大
- 从容量上,单个redis服务器内存容量有限,就算一台redis的内存容量为256G,也不能将所有内存作为redis存储内存,一般来讲,单台redis使用最大内存不应该超过20G
电商网站上面的商品,一般都是一次上传,无数次浏览,就是专业点的“多读少写”的数据!对于这种场景,我们可以使用如下架构:
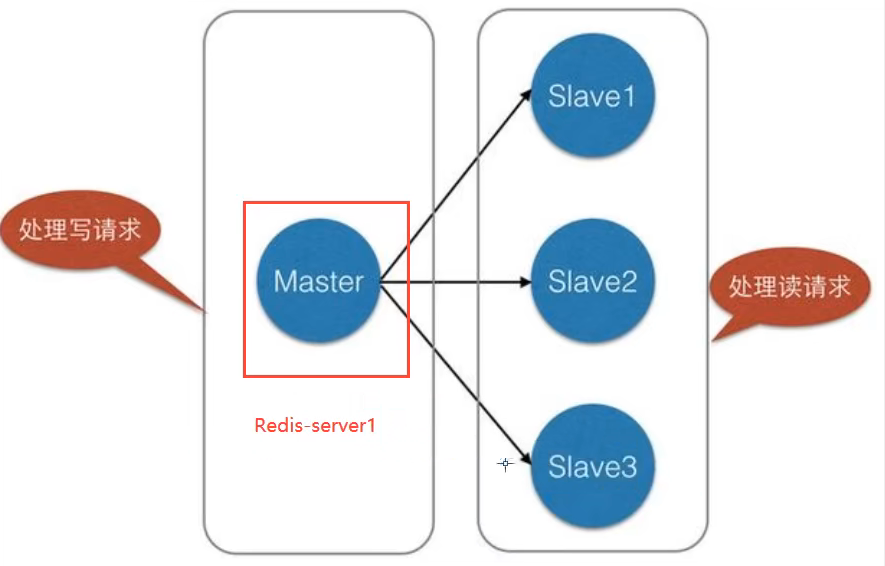
主从复制,读写分离!80%情况下都是读的操作!减缓服务器的压力,构架中经常使用!1主2从,后面还有哨兵模式会自己选举!
只要在公司中,主从复制是必用的
11.2,配置
只修改从库,不用配置主库!
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:70860adb239f32bc6521d8eaace9959e5cbefb40
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
复制3个配置,修改对应的信息(对应docker镜像好像只用修改对外暴露的端口即可)
- 端口
- pid名称(docker没有必要修改)
- log日志文件
- dump.rdb文件
# 6380从机
docker run -it \
-p 6380:6380 \
-v /opt/docker/redis/conf/redis6380.conf:/usr/local/etc/redis/redis.conf \
-v /opt/docker/redis/data:/data \
--name ac-redis6380 \
redis \
redis-server /usr/local/etc/redis/redis.conf
# 6381从机
docker run -itd \
-p 6381:6381 \
-v /opt/docker/redis/conf/redis6381.conf:/usr/local/etc/redis/redis.conf \
-v /opt/docker/redis/data:/data \
--name ac-redis6381 \
redis \
redis-server /usr/local/etc/redis/redis.conf
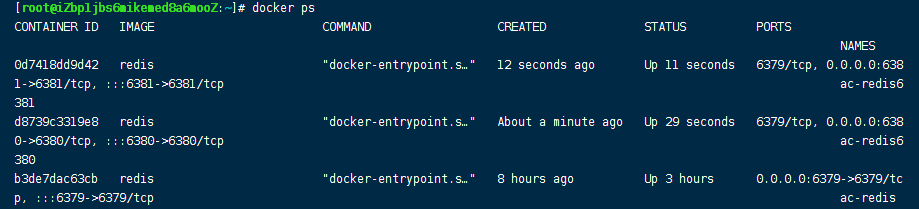
11.3,一主二从
默认三台都是主节点,我们只用配置从机配置即可
命令
slaveof(配置从机中的主节点,也可以直接在配置中修改)
info replication(查看当前redis的主从角色信息)
slaveof no one(取消主从设置)
# 6380、6380从节点
slaveof ip 端口
# 注意如果主节点有设置密码,需要在配置中的masterauth配置一下,否则从节点链接不上
> info replication
# Replication
role:slave
master_host:47.98.35.29
master_port:6379
master_link_status:up
master_last_io_seconds_ago:9
master_sync_in_progress:0
slave_read_repl_offset:14
slave_repl_offset:14
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:9d65bf62f55d047a65a39288e0d1f28eef640eb9
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:14
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:14
# 主节点
> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=47.98.35.29,port=6380,state=online,offset=84,lag=0
slave1:ip=47.98.35.29,port=6381,state=online,offset=84,lag=0
master_failover_state:no-failover
master_replid:9d65bf62f55d047a65a39288e0d1f28eef640eb9
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:84
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:84
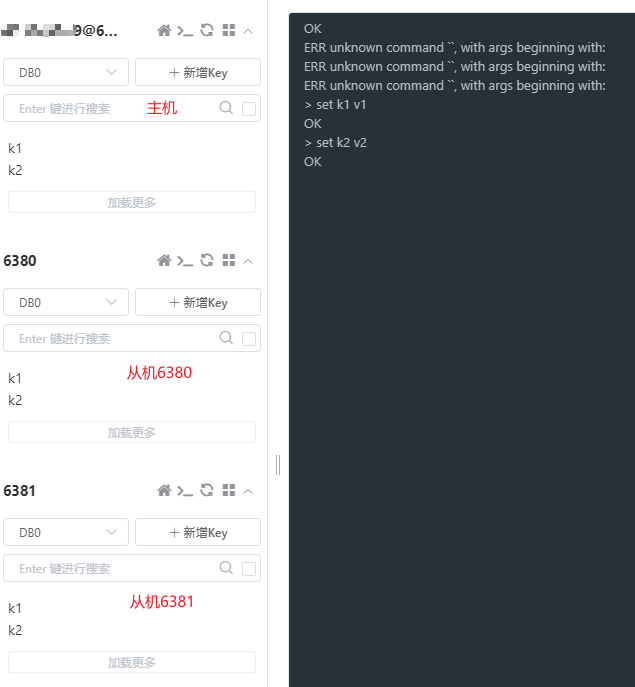
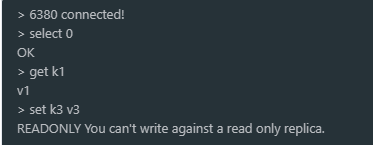
细节
主机可以读写,从机只能读(好像可以配置)!
主机断开连接,从机依然连接到主机,但是没有写操作,这时主机恢复,从机依旧可以直接获取主机写的数据!如果从机使用的命令设置自己的主节点信息,重启后需要重新设置从机的角色!
只要设置了从机角色,数据立马会从主机中写入进从机!
复杂原来
slave启动成功后连接到master后悔发送一条sync同步命令
master接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集的命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步!
全量复制:slave服务在接收到数据库文件(rdb)后,将其存盘并加载到内存中
增量复制:master继续将新的所有收集到的修改命令依次传给slave,完成同步
只要是重新连接master,一次全量同步就会自动执行!
全量复制流程
如果从服务器以前没有复制过任何主服务器,或者之前执行过SLAVEOF no one命令,那么从服务器在开始一次新的复制时将向主服务器发送PSYNC ? -1命令,主动请求主服务器进行完整重同步(因为这时不可能执行部分重同步);
相反地,如果从服务器已经复制过某个主服务器,那么从服务器在开始一次新的复制时将向主服务器发送PSYNC <runid> <offset>命令:其中runid是上一次复制的主服务器的运行ID,而offset则是从服务器当前的复制偏移量,接收到这个命令的主服务器会通过这两个参数来判断应该对从服务器执行哪种同步操作,如何判断已经在介绍runid时进行详细说明。
根据情况,接收到PSYNC命令的主服务器会向从服务器返回以下三种回复的其中一种:
如果主服务器返回+FULLRESYNC <runid> <offset>回复,那么表示主服务器将与从服务器执行完整重同步操作:其中runid是这个主服务器的运行ID,从服务器会将这个ID保存起来,在下一次发送PSYNC命令时使用;而offset则是主服务器当前的复制偏移量,从服务器会将这个值作为自己的初始化偏移量;
如果主服务器返回+CONTINUE回复,那么表示主服务器将与从服务器执行部分同步操作,从服务器只要等着主服务器将自己缺少的那部分数据发送过来就可以了;
如果主服务器返回-ERR回复,那么表示主服务器的版本低于Redis 2.8,它识别不了PSYNC命令,从服务器将向主服务器发送SYNC命令,并与主服务器执行完整同步操作。
由此可见psync也有不足之处,当从库重启以后runid发生变化,也就意味者从库还是会进行全量复制,而在实际的生产中进行从库的维护很多时候会进行重启,而正是有由于全量同步需要主库执行快照,以及数据传输会带不小的影响。因此在4.0版本,psync命令做了改进,以下说明。

11.4,层层链路
上一个M链接下一个S,下一个S又链接一个S
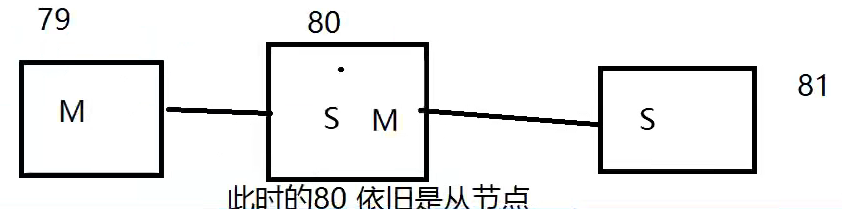
如果老大没有了,那能不能选择一个新master出来?---哨兵模式!
12,哨兵模式
12.1,概念
主从切换技术的方法是:当主机宕机后,需要手动把一台从机切换为服务器,这个需要人工手动干预,费事费力,还会造成一段时间的服务不可用。这不是一种推荐的方式,更多的时候,我们优先考虑哨兵模式。redis从2.8开始正式提供了sentinel架构来解决这个问题。
能够监控主机是否故障,如果发生故障根据投票数自动将从库转为master库。
redis提供sentinel的命令,是一个独立的进程。其原理是哨兵通过发送命令,等待redis服务器响应,从而监控运行的多个redis实例。
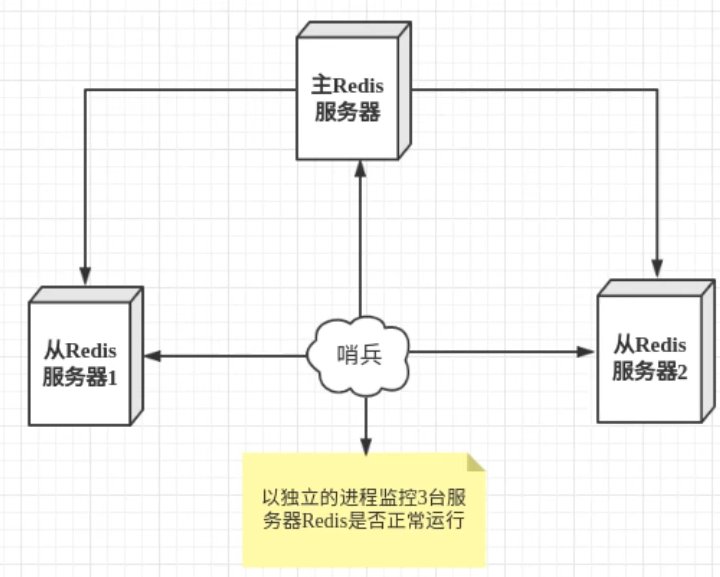
这里的哨兵有2个作用
- 通过发送命令,让redis服务器返回监控其运行状态,包括主服务器和从服务器
- 当哨兵检测到master宕机,会自动将slave切换为master,然后通过发布订阅模式通知其他从服务器,修改配置文件,让它们切换主机
然而一个哨兵进程对redis服务器进行监控也有弊端,如果该哨兵进程崩了?为此我们可以使用多个哨兵进行监控,各个哨兵之间还会进行监控,这样就形成了多哨兵模式,如下图所示:
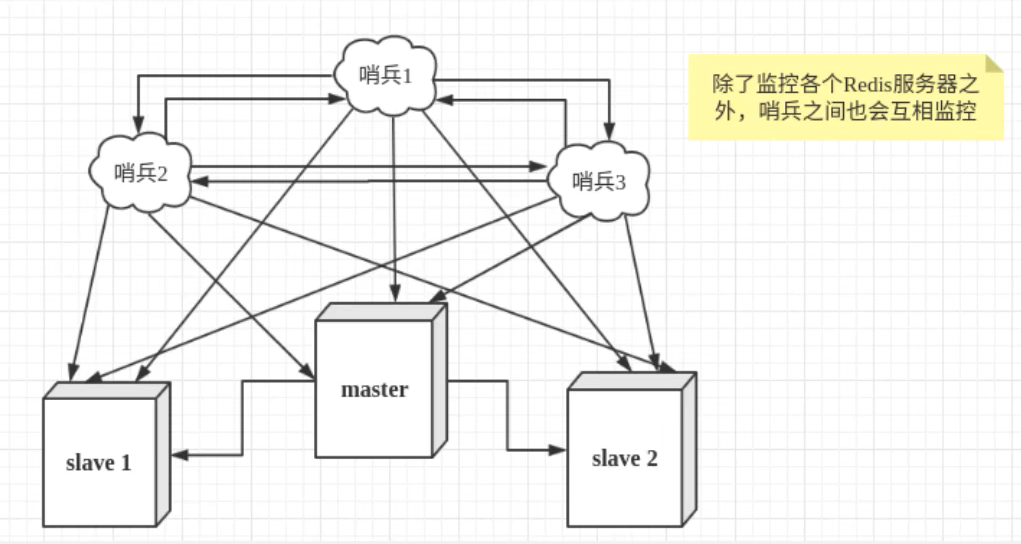
假设主服务器宕机,哨兵1先检查到这个结果,系统并不会马上进行故障转移(failover)过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观线下。当后面的哨兵也检测到主服务器宕机,并且数量达到一定值时,那么哨兵之间会进行一次投票,投票结果由一个哨兵发起,进行failover操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程成为客观下线。
12.2,测试
我们现在的状态是一主二从
- 配置哨兵配置文件sentinel.conf文件
# 被监控的名称 host port 后面的数字1是,代表主机挂了,slave投票看让谁接替成为主机,票数多的成为主机
sentinel monitor ac-redis 127.0.0.1 6379 1
sentinel auth-pass ac-redis 密码
哨兵日志
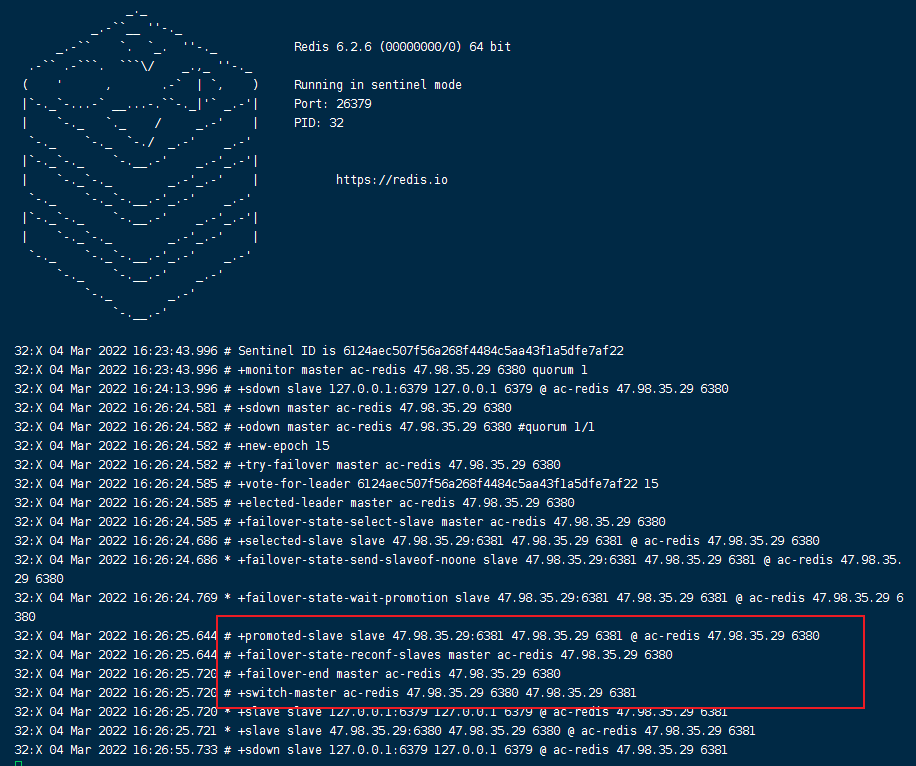
如果主机宕机后,之后又恢复了,它也只能自动转为从机!
优点:
- 哨兵模式,基于主从复制模式,所有的主从配置节点,他全有
- 主从可以切换,故障可以转移failover,系统的可用性更好
- 哨兵模式就是主从模式的升级版本,手动到自动,更加健壮
缺点:
- redis不好在线扩容,集群容量一旦达到上限,在线扩容很麻烦
- 实现哨兵模式的配置很麻烦,里面的选择很多
哨兵模式的全部配置
port 26379 # sentinel 运行端口
dir /tmp # 工作目录
sentinel monitor <master-name> <ip> <port> <quorum> # quorum配置多少个哨兵统一任务主节点失联?那么就认为客观失联
sentinel auth-pass <mysater-name> <password>
sentinel down-after-milliseconds <mysater-name> <milliseconds> # 主观上认为主节点下线
sentinel parallel-syncs <mysater-name> <numslaves> #发生failover时,同时有多少个从节点对新的master进行数据同步
sentinel failover-timeout <mysater-name> <milliseconds>
# 编写sh脚本进行扩展操作
sentinel notification-script <mysater-name> <script-path>
13,docker搭建集群
13.1,部署
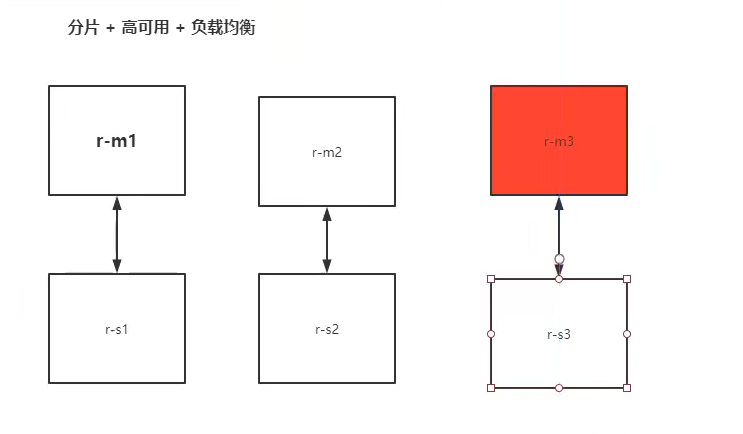
# 创建网卡
docker network create redis-cluster --subnet 172.38.0.0/16
# 批量创建配置文件
for port in $(seq 1 6); \
do \
mkdir -p /opt/docker/redis/cluster/node-${port}/conf
mkdir -p /opt/docker/redis/cluster/node-${port}/data
touch /opt/docker/redis/cluster/node-${port}/conf/redis.conf
cat <<EOF>> /opt/docker/redis/cluster/node-${port}/conf/redis.conf
port 6379
bind 0.0.0.0
masterauth passwd123
requirepass passwd123
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.38.0.1${port}
cluster-announce-port 6379
cluster-announce-bus-port 16379
appendonly no
EOF
done
# 批量启动
for port in $(seq 1 6); \
do \
docker run -d -p 637${port}:6379 -p 1637${port}:16379 \
--name redis-${port} \
-v /opt/docker/redis/cluster/node-${port}/data:/data \
-v /opt/docker/redis/cluster/node-${port}/conf/redis.conf:/usr/local/etc/redis/redis.conf \
--net redis-cluster --ip 172.38.0.1${port} \
redis redis-server /usr/local/etc/redis/redis.conf
done
# 进入任意一个容器配置集群
[root@iZbp1jbs6mikemed8a6mooZ:~]# docker exec -it redis-1 /bin/bash
root@b518b77d2f00:/data# ls
dump.rdb nodes.conf
root@b518b77d2f00:/data# redis-cli -a passwd123 --cluster create 172.38.0.11:6379 172.38.0.12:6379 172.38.0.13:6379 172.38.0.14:6379 172.38.0.15:6379 172.38.0.16:6379 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 127.38.0.15:6379 to 127.38.0.11:6379
Adding replica 127.38.0.16:6379 to 127.38.0.12:6379
Adding replica 127.38.0.14:6379 to 127.38.0.13:6379
M: 782f6a0992ca7ef58438797aad9482e8e8ad054e 127.38.0.11:6379
slots:[0-5460] (5461 slots) master
M: 782f6a0992ca7ef58438797aad9482e8e8ad054e 127.38.0.12:6379
slots:[5461-10922] (5462 slots) master
M: 782f6a0992ca7ef58438797aad9482e8e8ad054e 127.38.0.13:6379
slots:[10923-16383] (5461 slots) master
S: 782f6a0992ca7ef58438797aad9482e8e8ad054e 127.38.0.14:6379
replicates 782f6a0992ca7ef58438797aad9482e8e8ad054e
S: 782f6a0992ca7ef58438797aad9482e8e8ad054e 127.38.0.15:6379
replicates 782f6a0992ca7ef58438797aad9482e8e8ad054e
S: 782f6a0992ca7ef58438797aad9482e8e8ad054e 127.38.0.16:6379
replicates 782f6a0992ca7ef58438797aad9482e8e8ad054e
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
>>> Performing Cluster Check (using node 127.38.0.11:6379)
M: 782f6a0992ca7ef58438797aad9482e8e8ad054e 127.38.0.11:6379
slots:[0-16383] (16384 slots) master
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
root@b518b77d2f00:/data#
# 进入查询信息
root@b518b77d2f00:/data# redis-cli -c
127.0.0.1:6379> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:1
cluster_size:1
cluster_current_epoch:1
cluster_my_epoch:1
cluster_stats_messages_pong_sent:1
cluster_stats_messages_meet_sent:1
cluster_stats_messages_sent:2
cluster_stats_messages_pong_received:1
cluster_stats_messages_meet_received:1
cluster_stats_messages_received:2
127.0.0.1:6379>
127.0.0.1:6379> get k2
-> Redirected to slot [449] located at 172.38.0.11:6379
"v2"
# 在其他机器上面处理数据,会自动跳转!!!(牛皮)
172.38.0.11:6379> get k3
"v3"
172.38.0.11:6379> set k4 v4
-> Redirected to slot [8455] located at 172.38.0.12:6379
OK
172.38.0.12:6379> set k5 v5
-> Redirected to slot [12582] located at 172.38.0.13:6379
OK
# 强行关闭之前的node1,在其他节点上查看
172.38.0.13:6379> cluster nodes
50b403f66e12068200d3c92e9a2c13537d85a3ed 172.38.0.12:6379@16379 master - 0 1646446787860 2 connected 5461-10922
a45fade1226aac38c4d4da1e1da6d5b7b08b38a6 172.38.0.14:6379@16379 slave a4ed284eb6675c3da8b3fb94105068bc87d999fc 0 1646446787000 3 connected
a4ed284eb6675c3da8b3fb94105068bc87d999fc 172.38.0.13:6379@16379 myself,master - 0 1646446786000 3 connected 10923-16383
9cabfe0fe2b9a0ce9ba1ebc5db5e4913c4718c7f 172.38.0.11:6379@16379 master,fail - 1646446780530 1646446778016 1 connected
563c7bc98645a09f3456bab96257f29255f4cba0 172.38.0.15:6379@16379 master - 0 1646446787559 7 connected 0-5460
bc042914377512247baabad9963eaf9fc59e59de 172.38.0.16:6379@16379 slave 50b403f66e12068200d3c92e9a2c13537d85a3ed 0 1646446786856 2 connected
# 如果最后想要删除所有redis集群容器,并且删除目录 可以执行如下脚本
for port in $(seq 1 6); \
do \
docker rm -f redis-${port}
rm -rf /opt/docker/redis/cluster/node-${port}
done
集群优点:
- Redis 集群的分片特征在于将键空间分拆了16384个槽位,每一个节点负责其中一些槽位(数据分片)。
- Redis提供一定程度的可用性,可以在某个节点宕机或者不可达的情况下继续处理命令.
- Redis 集群中不存在中心(central)节点或者代理(proxy)节点, 集群的其中一个主要设计目标是达到线性可扩展性(linear scalability)。
特点:
- 所有的节点相互连接;
- 集群消息通信通过集群总线通信,,集群总线端口大小为客户端服务端口+10000,这个10000是固定值;
- 节点与节点之间通过二进制协议进行通信;
- 客户端和集群节点之间通信和通常一样,通过文本协议进行;
- 集群节点不会代理查询;
13.2,投票机制
- 故障节点主观下线
- 故障节点客观下线
- Sentinel集群选举Leader
- Sentinel Leader决定新主节点
与raft算法相似
13.3,动态扩容和删减节点
添加后执行如下命令进行重新分配槽
删除之前,先把历史的数据槽转移到其他主节点
../redis-trib.rb reshard 192.168.230.129:6379
14,缓存穿透、击穿和雪崩
redis缓存的使用,极大的提升了应用的性能和效率,特别是查询数据性能(redis-benchmark)。高可用的关键!
14.1,缓存穿透
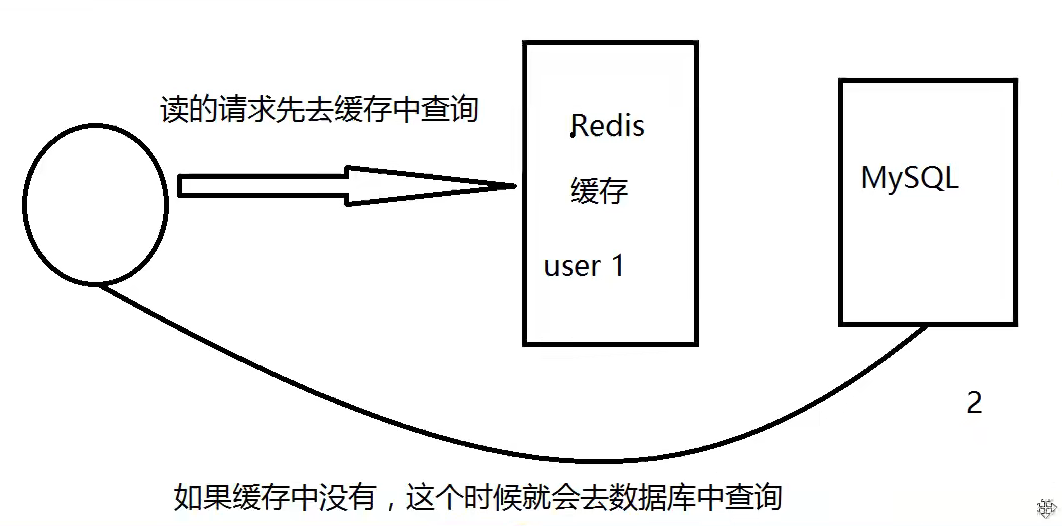
概念
用户想要查询某个数据,但是缓存没有命中,于是向持久层(sql)查询。发现也没有,于是本次查询失败。当很多这样的缓存没有命中(例如秒杀场景)的请求过来时,会给持久层造成很大的压力。
解决方案
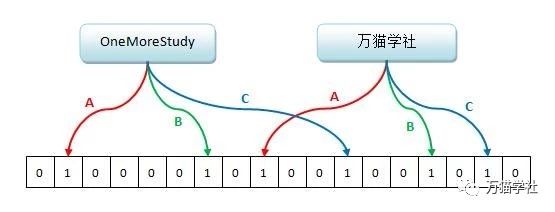
1,布隆过滤器(Bloom Filter)
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
布隆过滤器我的理解:
- 初始化一个bitmap空间(大小为n)
- 将已有的所有key使用多个hash函数进行计算,并将结果index=hashCode%n,在上述bitmap空间对应的index标记为1(这样就粗略的记录了相关key值是否可能存在的信息,当然也有可能多个不同key值,他们的index是一样的~这个就是误差,如果想要减少误差就需要,把bitmap的值扩容)
- 来了一条key查询
- 如果按照上述步骤计算index,且在bitmap空间中数值为1,那么说明:这个key有可能存在(除非是该key与我之前记录的key的index一样导致的误差),后续我在查询redis库
- 如果按照上述步骤计算index,且在bitmap空间中数值为1,那么说明:这个key我这边根本没有记录,绝对不可能存在,就无需查询redis库了
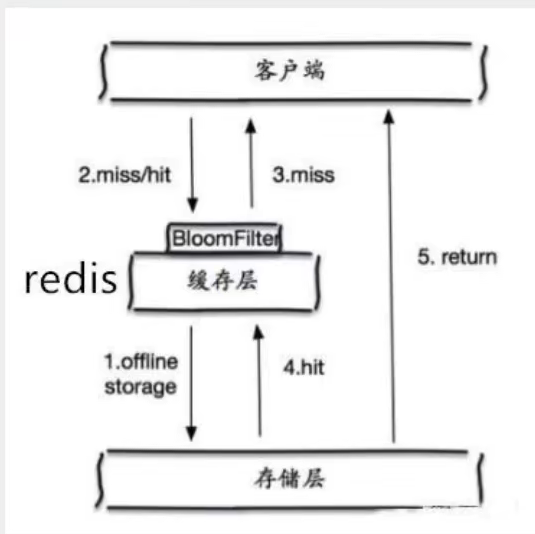
redis4.0之后就自己实现了布隆过滤器,使用样例见github链接
# 127.0.0.1:6379> BF.ADD newFilter foo
(integer) 1
# 127.0.0.1:6379> BF.EXISTS newFilter foo
(integer) 1
# 127.0.0.1:6379> BF.EXISTS newFilter bar
(integer) 0
2,缓存空对象
当存储层不命中后,即使返回的空对象将其缓存起来,同时设置一个过期时间,之后在访问这个数据将会从缓存中获取,保护后端数据!
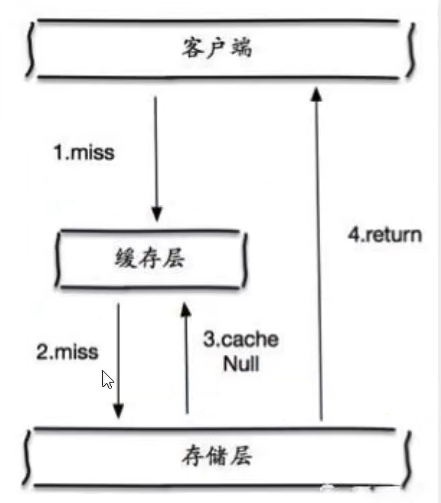
但是缓存空对象会存在问题:
- 如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键;
- 即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口不一致,这对于保持一致性的业务会有影响!
14.2,缓存击穿
概念
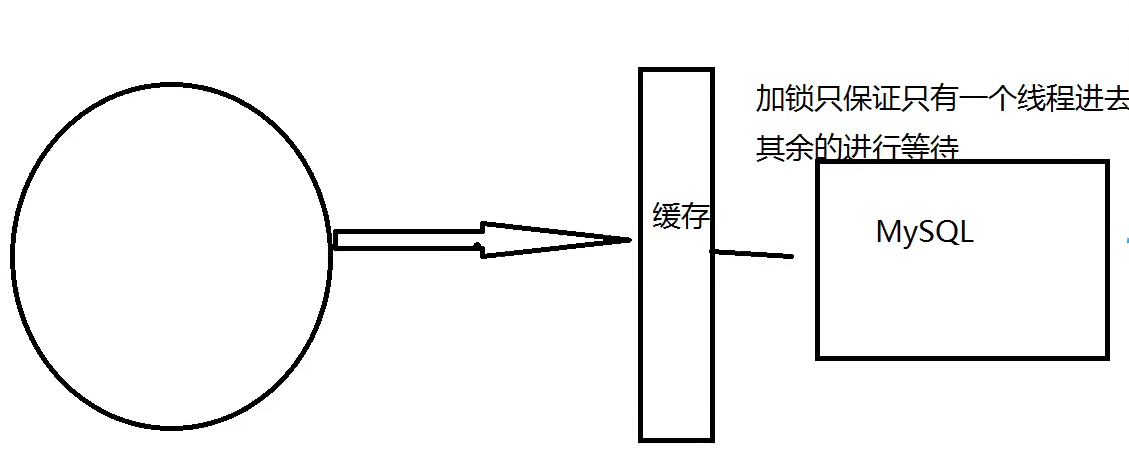
这里需要注意和穿透的区别,缓存击穿是指一个key非常热点,在不停的进行大并发,大并发集中对着这一个点进行访问,当这个key在失效的瞬间,持续的大并发就会击穿缓存层,直接请求到存储层。
当某个key在过期的瞬间,有大量的请求并发访问,这类数据一般都是热点数据,由于缓存过期,会同时访问数据来查询数据,并且写入缓存层,导致数据库压力暴增!
解决方案
1,设置热点数据永不过期
从缓存层面来看,没有设置过期时间,所以不会出现热点key过期的问题(但是耗费资源)
2,分布式锁:使用分布式锁,保证对于每个key同时只有一个线程去查询后端的服务,其他线程没有获取分布式锁的权限,因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁,因此对分布式锁的考验很大!
14.3,缓存雪崩
概念
在某个时刻,缓存集中过期失效,redis宕机!
产生的原因之一,比如双十一写入数据的时候,定点瞬间写入一批订单信息(过期时间可能一样),到期时这一批的订单全部同时过期。而对这一批订单进行查询的时候就全部会穿透缓存层-直击存储层。对于数据库而言就会有周期性压力波峰,严重的时候会把数据库搞崩!
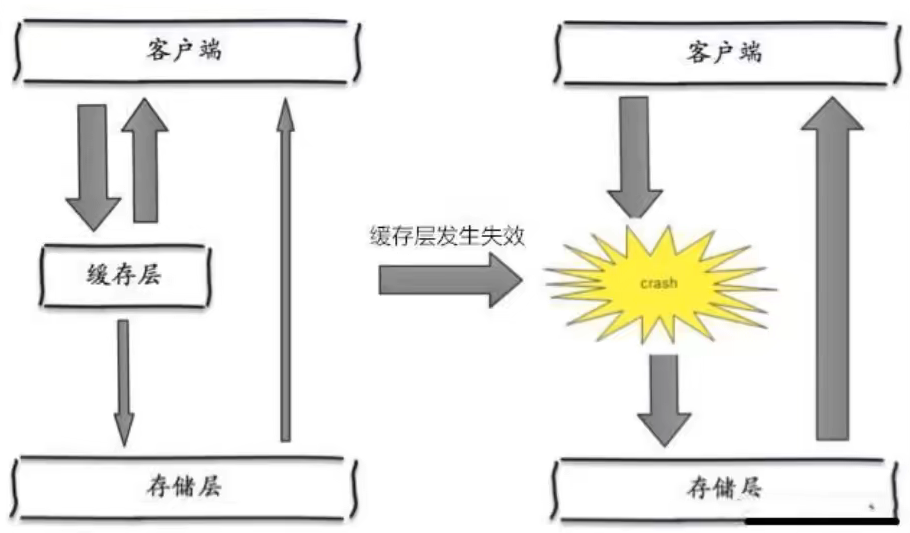
其实集中过期不是最为致命的,比较致命的是某个缓存服务器节点宕机或者断网。因为自然形成的缓存雪崩,一定是在某个时间段集中创建缓存,这个时候数据库压力也是可以顶住压力的。无法就是对于数据的周期性压力而已。而缓存服务节点的宕机,对于数据库服务器造成的压力是不可预知的,很有可能瞬间就把数据库压垮!
例子:双十一,停掉一些服务(保证主要服务可用)
解决方案
- redis高可用,既然redis可以挂掉,那么就多设置几台redis服务器,这样一台挂掉,其他的可以继续工作,本质就是搭建集群(异地多活!)
- 限流降级(springCloud必须学习!),在缓存失效后,通过加锁或者队列来控制读取数据库写入缓存的线程数量。比如某个key只允许一个线程查询数据和写入数据,其他线程等待!
- 数据预热,在正式部署之前,先把可能的数据预先访问一遍(假设这些数据是热点数据),这样部分可能大量访问的数据就会加载到缓存中。在即将发生的大并发访问前,手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间尽量均匀一些!
15,性能调优
主要可从内存、命令处理数、延迟时间、内存碎片率、回收key这几个方面来进行性能调优!
可以通过info命令查询相关数据信息(server ,clients ,memory ,persistence ,stats ,replication ,cpu ,commandstats ,cluster ,keyspace)
15.1,内存
127.0.0.1:6379> info memory
# Memory
used_memory:2682624
used_memory_human:2.56M
used_memory_rss:7704576
used_memory_rss_human:7.35M
used_memory_peak:2763288
used_memory_peak_human:2.64M
used_memory_peak_perc:97.08%
used_memory_overhead:2558112
used_memory_startup:1468416
used_memory_dataset:124512
used_memory_dataset_perc:10.25%
allocator_allocated:2744432
allocator_active:3035136
allocator_resident:5451776
total_system_memory:7976460288
total_system_memory_human:7.43G
used_memory_lua:37888
used_memory_lua_human:37.00K
used_memory_scripts:0
used_memory_scripts_human:0B
number_of_cached_scripts:0
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
allocator_frag_ratio:1.11
allocator_frag_bytes:290704
allocator_rss_ratio:1.80
allocator_rss_bytes:2416640
rss_overhead_ratio:1.41
rss_overhead_bytes:2252800
mem_fragmentation_ratio:2.92
mem_fragmentation_bytes:5062976
mem_not_counted_for_evict:0
mem_replication_backlog:1048576
mem_clients_slaves:20512
mem_clients_normal:20496
mem_aof_buffer:0
mem_allocator:jemalloc-5.1.0
active_defrag_running:0
lazyfree_pending_objects:0
lazyfreed_objects:0
内存使用率是Redis服务最关键的一部分。如果Redis实例的内存使用率超过可用最大内存 (used_memory > 可用最大内存),那么操作系统开始进行内存与swap空间交换,把内存中旧的或不再使用的内容写入硬盘上(硬盘上的这块空间叫Swap分区),以便留出新的物理内存给新页或活动页(page)使用。
如果Redis进程上发生内存交换,那么Redis和依赖Redis上数据的应用会受到严重的性能影响。 通过查看used_memory指标可知道Redis正在使用的内存情况,如果used_memory>可用最大内存,那就说明Redis实例正在进行内存交换或者已经内存交换完毕。
- 假如缓存数据小于4GB,就使用32位的Redis实例。因为32位实例上的指针大小只有64位的一半,它的内存空间占用空间会更少些。 这有一个坏处就是,假设物理内存超过4GB,那么32位实例能使用的内存仍然会被限制在4GB以下。 要是实例同时也共享给其他一些应用使用的话,那可能需要更高效的64位Redis实例,这种情况下切换到32位是不可取的。 不管使用哪种方式,Redis的dump文件在32位和64位之间是互相兼容的, 因此倘若有减少占用内存空间的需求,可以尝试先使用32位,后面再切换到64位上。
- 尽可能的使用Hash数据结构。因为Redis在储存小于100个字段的Hash结构上,其存储效率是非常高的。所以在不需要集合(set)操作或list的push/pop操作的时候,尽可能的使用Hash结构。比如,在一个web应用程序中,需要存储一个对象表示用户信息,使用单个key表示一个用户,其每个属性存储在Hash的字段里,这样要比给每个属性单独设置一个key-value要高效的多。 通常情况下倘若有数据使用string结构,用多个key存储时,那么应该转换成单key多字段的Hash结构。 如上述例子中介绍的Hash结构应包含,单个对象的属性或者单个用户各种各样的资料。Hash结构的操作命令是HSET(key, fields, value)和HGET(key, field),使用它可以存储或从Hash中取出指定的字段。
- 设置key的过期时间。一个减少内存使用率的简单方法就是,每当存储对象时确保设置key的过期时间。倘若key在明确的时间周期内使用或者旧key不大可能被使用时,就可以用Redis过期时间命令(expire,expireat, pexpire, pexpireat)去设置过期时间,这样Redis会在key过期时自动删除key。 假如你知道每秒钟有多少个新key-value被创建,那可以调整key的存活时间,并指定阀值去限制Redis使用的最大内存。
- 回收key。在Redis配置文件中(一般叫Redis.conf),通过设置“maxmemory”属性的值可以限制Redis最大使用的内存,修改后重启实例生效。 也可以使用客户端命令config set maxmemory 去修改值,这个命令是立即生效的,但会在重启后会失效,需要使用config rewrite命令去刷新配置文件。 若是启用了Redis快照功能,应该设置“maxmemory”值为系统可使用内存的45%,因为快照时需要一倍的内存来复制整个数据集,也就是说如果当前已使用45%,在快照期间会变成95%(45%+45%+5%),其中5%是预留给其他的开销。 如果没开启快照功能,maxmemory最高能设置为系统可用内存的95%。
15.2,命令处理数
127.0.0.1:6379> info stats
# Stats
total_connections_received:16
total_commands_processed:4833
instantaneous_ops_per_sec:1
total_net_input_bytes:238021
total_net_output_bytes:131153
instantaneous_input_kbps:0.04
instantaneous_output_kbps:0.01
rejected_connections:0
sync_full:1
sync_partial_ok:0
sync_partial_err:1
expired_keys:0
expired_stale_perc:0.00
expired_time_cap_reached_count:0
expire_cycle_cpu_milliseconds:97
evicted_keys:0
keyspace_hits:0
keyspace_misses:0
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:348
total_forks:2
migrate_cached_sockets:0
slave_expires_tracked_keys:0
active_defrag_hits:0
active_defrag_misses:0
active_defrag_key_hits:0
active_defrag_key_misses:0
tracking_total_keys:0
tracking_total_items:0
tracking_total_prefixes:0
unexpected_error_replies:0
total_error_replies:11
dump_payload_sanitizations:0
total_reads_processed:4830
total_writes_processed:561
io_threaded_reads_processed:0
io_threaded_writes_processed:0
在Redis实例中,跟踪命令处理总数是解决响应延迟问题最关键的部分,因为Redis是个单线程模型,客户端过来的命令是按照顺序执行的。比较常见的延迟是带宽,通过千兆网卡的延迟大约有200μs。倘若明显看到命令的响应时间变慢,延迟高于200μs,那可能是Redis命令队列里等待处理的命令数量比较多。 如上所述,延迟时间增加导致响应时间变慢可能是由于一个或多个慢命令引起的,这时可以看到每秒命令处理数在明显下降,甚至于后面的命令完全被阻塞,导致Redis性能降低。要分析解决这个性能问题,需要跟踪命令处理数的数量和延迟时间。
比如可以写个脚本,定期记录total_commands_processed的值。当客户端明显发现响应时间过慢时,可以通过记录的total_commands_processed历史数据值来判断命理处理总数是上升趋势还是下降趋势,以便排查问题。
通过与记录的历史数据比较得知,命令处理总数确实是处于上升或下降状态,那么可能是有2个原因引起的:
- 命令队列里的命令数量过多,后面命令一直在等待中
- 几个慢命令阻塞Redis
解决办法:
- 使用多参数命令:若是客户端在很短的时间内发送大量的命令过来,会发现响应时间明显变慢,这由于后面命令一直在等待队列中前面大量命令执行完毕。有个方法可以改善延迟问题,就是通过单命令多参数的形式取代多命令单参数的形式。举例来说,循环使用LSET命令去添加1000个元素到list结构中,是性能比较差的一种方式,更好的做法是在客户端创建一个1000元素的列表,用单个命令LPUSH或RPUSH,通过多参数构造形式一次性把1000个元素发送的Redis服务上。下面是Redis的一些操作命令,有单个参数命令和支持多个参数的命令,通过这些命令可尽量减少使用多命令的次数。
- 管道命令:另一个减少多命令的方法是使用管道(pipeline),把几个命令合并一起执行,从而减少因网络开销引起的延迟问题。因为10个命令单独发送到服务端会引起10次网络延迟开销,使用管道会一次性把执行结果返回,仅需要一次网络延迟开销。Redis本身支持管道命令,大多数客户端也支持,倘若当前实例延迟很明显,那么使用管道去降低延迟是非常有效的。
- 避免操作大集合的慢命令:如果命令处理频率过低导致延迟时间增加,这可能是因为使用了高时间复杂度的命令操作导致,这意味着每个命令从集合中获取数据的时间增大。 所以减少使用高时间复杂的命令,能显著的提高的Redis的性能。
15.3,延迟时间
Redis的延迟数据是无法从info信息中获取的。可以用 Redis-cli工具加 --latency参数运行,如:

Redis之所以这么流行的主要原因之一就是低延迟特性带来的高性能,所以说解决延迟问题是提高Redis性能最直接的办法。拿1G带宽来说,若是延迟时间远高于200μs,那明显是出现了性能问题。 虽然在服务器上会有一些慢的IO操作,但Redis是单核接受所有客户端的请求,所有请求是按良好的顺序排队执行。因此若是一个客户端发过来的命令是个慢操作,那么其他所有请求必须等待它完成后才能继续执行。
解决办法:
- 使用slowlog查出引发延迟的慢命令:Redis中的slowlog命令可以让我们快速定位到那些超出指定执行时间的慢命令,默认情况下命令若是执行时间超过10ms就会被记录到日志。slowlog只会记录其命令执行的时间,不包含io往返操作,也不记录单由网络延迟引起的响应慢。通常1gb带宽的网络延迟,预期在200μs左右,倘若一个命令仅执行时间就超过10ms,那比网络延迟慢了近50倍。 想要查看所有执行时间比较慢的命令,可以通过使用Redis-cli工具,输入slowlog get命令查看,返回结果的第三个字段以微妙位单位显示命令的执行时间。假如只需要查看最后10个慢命令,输入slowlog get 10即可;还可以通过设置config set slowlog-log-slower-than 5000 在日志中记录慢命令信息
- 监控客户端的连接:因为Redis是单线程模型(只能使用单核),来处理所有客户端的请求, 但由于客户端连接数的增长,处理请求的线程资源开始降低分配给单个客户端连接的处理时间,这时每个客户端需要花费更多的时间去等待Redis共享服务的响应。这种情况下监控客户端连接数是非常重要的,因为客户端创建连接数的数量可能超出预期的数量,也可能是客户端端没有有效的释放连接。在Redis-cli工具中输入info clients可以查看到当前实例的所有客户端连接信息。Redis默认允许客户端连接的最大数量是10000。若是看到连接数超过5000以上,那可能会影响Redis的性能。倘若一些或大部分客户端发送大量的命令过来,这个数字会低的多。
- 限制客户端连接数:自Redis2.6以后,允许使用者在配置文件(Redis.conf)maxclients属性上修改客户端连接的最大数,也可以通过在Redis-cli工具上输入config set maxclients 去设置最大连接数。根据连接数负载的情况,这个数字应该设置为预期连接数峰值的110到150之间,若是连接数超出这个数字后,Redis会拒绝并立刻关闭新来的连接。通过设置最大连接数来限制非预期数量的连接数增长,是非常重要的。另外,新连接尝试失败会返回一个错误消息,这可以让客户端知道,Redis此时有非预期数量的连接数,以便执行对应的处理措施。 上述二种做法对控制连接数的数量和持续保持Redis的性能最优是非常重要的,
- 加强内存管理:较少的内存会引起Redis延迟时间增加。如果Redis占用内存超出系统可用内存,操作系统会把Redis进程的一部分数据,从物理内存交换到硬盘上,内存交换会明显的增加延迟时间。关于怎么监控和减少内存使用,可查看used_memory介绍章节。
- 性能数据指标:分析解决Redis性能问题,通常需要把延迟时间的数据变化与其他性能指标的变化相关联起来。命令处理总数下降的发生可能是由慢命令阻塞了整个系统,但如果命令处理总数的增加,同时内存使用率也增加,那么就可能是由于内存交换引起的性能问题。对于这种性能指标相关联的分析,需要从历史数据上来观察到数据指标的重要变化,此外还可以观察到单个性能指标相关联的所有其他性能指标信息。这些数据可以在Redis上收集,周期性的调用内容为Redis info的脚本,然后分析输出的信息,记录到日志文件中。当延迟发生变化时,用日志文件配合其他数据指标,把数据串联起来排查定位问题。
15.4,内存碎片
info信息中的mem_fragmentation_ratio给出了内存碎片率的数据指标,它是由操系统分配的内存除以Redis分配的内存得出(mem_fragmentation_ratio = used_memory_rss / used_memory):
127.0.0.1:6379> info memory
# Memory
used_memory:2707680
used_memory_human:2.58M
used_memory_rss:7372800
used_memory_rss_human:7.03M
used_memory_peak:2767696
used_memory_peak_human:2.64M
used_memory_peak_perc:97.83%
used_memory_overhead:2592088
used_memory_startup:1481872
used_memory_dataset:115592
used_memory_dataset_perc:9.43%
allocator_allocated:2752632
allocator_active:3096576
allocator_resident:5496832
total_system_memory:7976460288
total_system_memory_human:7.43G
used_memory_lua:37888
used_memory_lua_human:37.00K
used_memory_scripts:0
used_memory_scripts_human:0B
number_of_cached_scripts:0
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
allocator_frag_ratio:1.12
allocator_frag_bytes:343944
allocator_rss_ratio:1.78
allocator_rss_bytes:2400256
rss_overhead_ratio:1.34
rss_overhead_bytes:1875968
mem_fragmentation_ratio:2.76
mem_fragmentation_bytes:4706136
mem_not_counted_for_evict:0
mem_replication_backlog:1048576
mem_clients_slaves:0
mem_clients_normal:61496
mem_aof_buffer:0
mem_allocator:jemalloc-5.1.0
active_defrag_running:0
lazyfree_pending_objects:0
lazyfreed_objects:0
倘若内存碎片率mem_fragmentation_ratio 超过了1.5,那可能是操作系统或Redis实例中内存管理变差的表现。下面有3种方法解决内存管理变差的问题,并提高Redis性能:
- 重启Redis服务器:如果内存碎片率超过1.5,重启Redis服务器可以让额外产生的内存碎片失效并重新作为新内存来使用,使操作系统恢复高效的内存管理。额外碎片的产生是由于Redis释放了内存块,但内存分配器并没有返回内存给操作系统,这个内存分配器是在编译时指定的,可以是libc、jemalloc或者tcmalloc。 通过比较used_memory_peak, used_memory_rss和used_memory_metrics的数据指标值可以检查额外内存碎片的占用。从名字上可以看出,used_memory_peak是过去Redis内存使用的峰值,而不是当前使用内存的值。如果used_memory_peak和used_memory_rss的值大致上相等,而且二者明显超过了used_memory值,这说明额外的内存碎片正在产生。 在Redis-cli工具上输入info memory可以查看上面三个指标的信息。在重启服务器之前,需要在Redis-cli工具上输入shutdown save命令,意思是强制让Redis数据库执行保存操作并关闭Redis服务,这样做能保证在执行Redis关闭时不丢失任何数据。 在重启后,Redis会从硬盘上加载持久化的文件,以确保数据集持续可用。
- 限制内存交换: 如果内存碎片率低于1,Redis实例可能会把部分数据交换到硬盘上。内存交换会严重影响Redis的性能,所以应该增加可用物理内存或减少实Redis内存占用。 可查看used_memory章节的优化建议。
- 修改内存分配器:Redis支持glibc’s malloc、jemalloc11、tcmalloc几种不同的内存分配器,每个分配器在内存分配和碎片上都有不同的实现。不建议普通管理员修改Redis默认内存分配器,因为这需要完全理解这几种内存分配器的差异,也要重新编译Redis。这个方法更多的是让其了解Redis内存分配器所做的工作,当然也是改善内存碎片问题的一种办法。
15.5,回收key
info信息中的evicted_keys字段显示的是,因为maxmemory限制导致key被回收删除的数量。回收key的情况只会发生在设置maxmemory值后,不设置会发生内存交换。 当Redis由于内存压力需要回收一个key时,Redis首先考虑的不是回收最旧的数据,而是在最近最少使用的key或即将过期的key中随机选择一个key,从数据集中删除。
这可以在配置文件中设置maxmemory-policy值为“volatile-lru”或“volatile-ttl”,来确定Redis是使用lru策略还是过期时间策略。 倘若所有的key都有明确的过期时间,那过期时间回收策略是比较合适的。若是没有设置key的过期时间或者说没有足够的过期key,那设置lru策略是比较合理的,这可以回收key而不用考虑其过期状态。
- 增加内存限制:倘若开启快照功能,maxmemory需要设置成物理内存的45%,这几乎不会有引发内存交换的危险。若是没有开启快照功能,设置系统可用内存的95%是比较合理的,具体参考前面的快照和maxmemory限制章节。如果maxmemory的设置是低于45%或95%(视持久化策略),通过增加maxmemory的值能让Redis在内存中存储更多的key,这能显著减少回收key的数量。 若是maxmemory已经设置为推荐的阀值后,增加maxmemory限制不但无法提升性能,反而会引发内存交换,导致延迟增加、性能降低。 maxmemory的值可以在Redis-cli工具上输入config set maxmemory命令来设置。需要注意的是,这个设置是立即生效的,但重启后丢失,需要永久化保存的话,再输入config rewrite命令会把内存中的新配置刷新到配置文件中。
- 对实例进行分片:分片是把数据分割成合适大小,分别存放在不同的Redis实例上,每一个实例都包含整个数据集的一部分。通过分片可以把很多服务器联合起来存储数据,相当于增加总的物理内存,使其在没有内存交换和回收key的策略下也能存储更多的key。假如有一个非常大的数据集,maxmemory已经设置,实际内存使用也已经超过了推荐设置的阀值,那通过数据分片能明显减少key的回收,从而提高Redis的性能。 分片的实现有很多种方法,下面是Redis实现分片的几种常见方式:
- a. Hash分片:一个比较简单的方法实现,通过Hash函数计算出key的Hash值,然后值所在范围对应特定的Redis实例。
- b. 代理分片:客户端把请求发送到代理上,代理通过分片配置表选择对应的Redis实例。 如Twitter的Twemproxy,豌豆荚的codis。
- c. 一致性Hash分片
- d. 虚拟桶分片
15.6,redis大key情景
安装使用大key工具rdb_bigkeys,亲测可行!
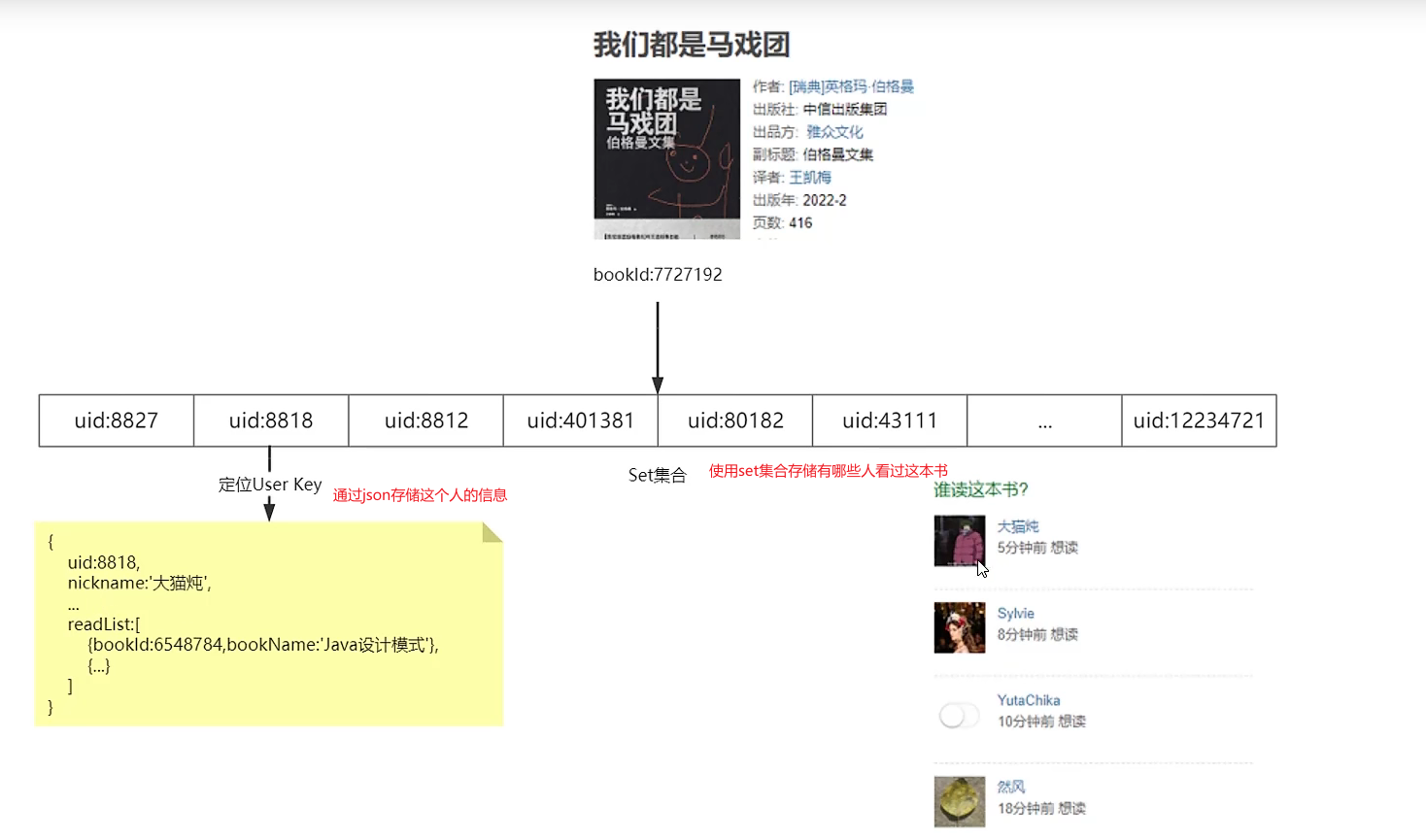
随着用户量积累300w,查询的这些信息的QPS从1100骤降至200,多方查找后发现是大key(超512kb)的数据导致。
问题分析:
- redis内存浪费严重,频繁LRU清除(io操作),导致缓存穿透
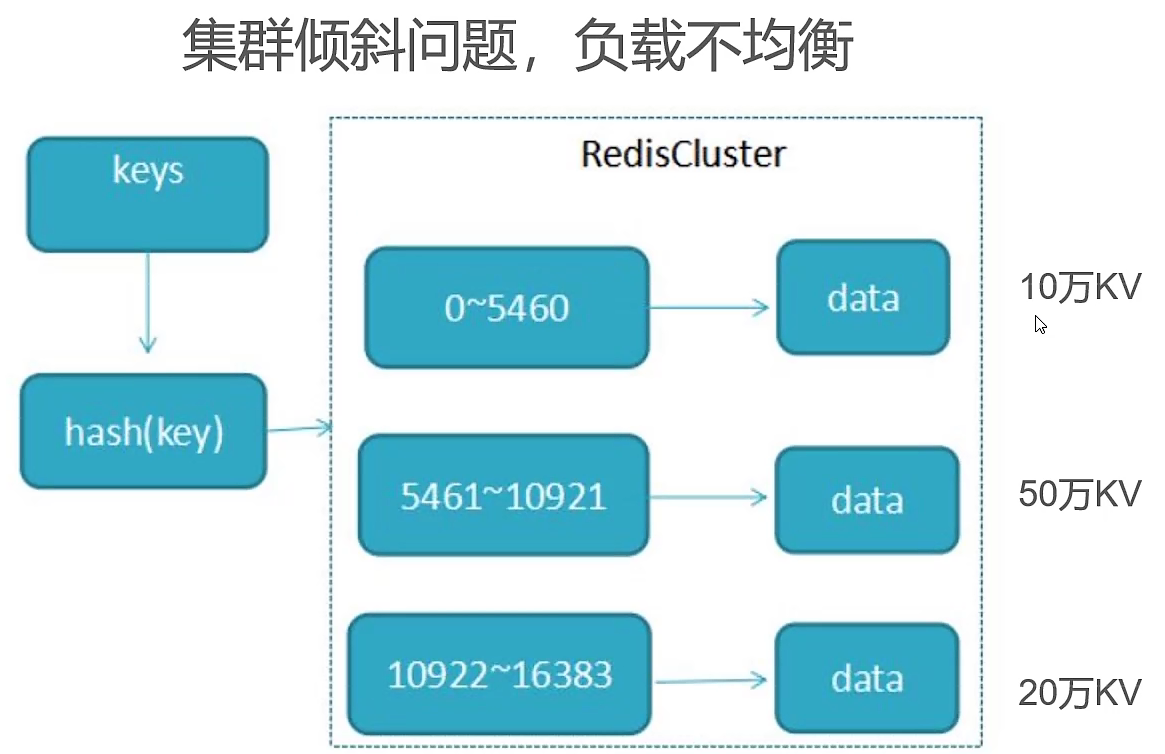
- 集群倾斜问题,由于各种key的耗费内存不一样,导致不同数据槽里面的数据量不一致,提取慢
- 单线程提取慢,指令队列挤压严重(redis6.0后提供多线程支持,6.0版本以前严格来说也是多线程,不过执行用户命令的请求时是单线程模型,没有多数据线的程竞争关系,效率依然很高,还有一些线程来执行后台任务,例如unlink删除大key,rdb持久化等)
./rdb_bigkeys --bytes 0 --file bigkeys.csv --sep 0 --sorted --threads 4 /opt/docker/redis/data/dump6379.rdb
优化策略:
- 对于大key数据进行裁剪(将无意义信息删除)
- 业务优化,减少set长度(实际业务场景中,没有必要保留全量的数据,只需要前100就已经绰绰有余)
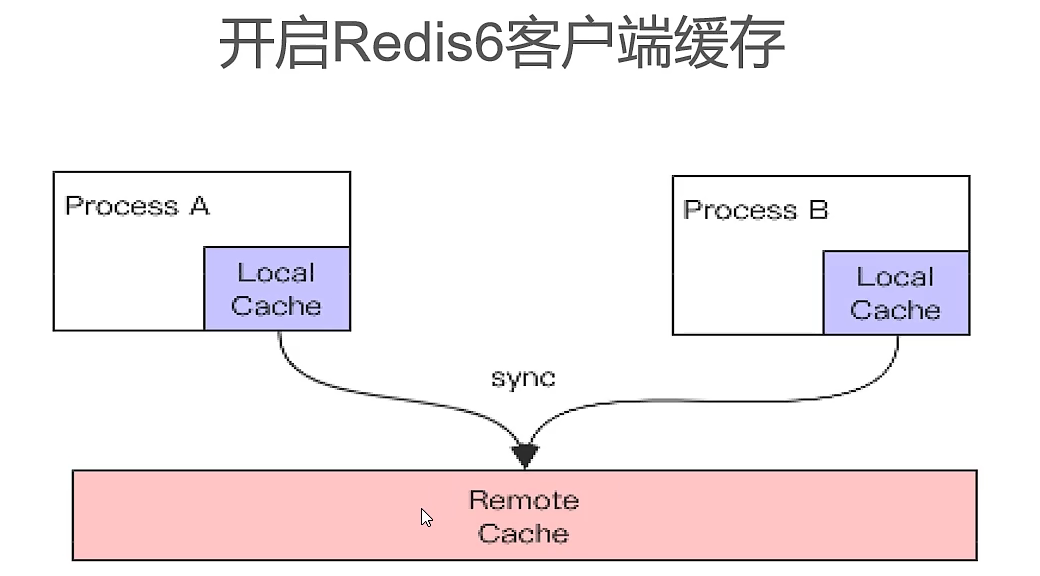
- 开启redis客户端缓存(相当于额外加了一层缓存,如果已经有相关数据,就不用去查询redis,套娃!!)
- 定时扫描发现大key,手动清理(rdb_bigkeys工具手动查询rdb持久化文件中是否有大key数据,也可以使用redis-cli提供的bigkeys参数扫描大key)
15.7,压缩列表
压缩列表是Redis为了节约内存而开发的,由一系列特殊编码的连续内存块组成的顺序型数据结构。一个压缩列表可以包含任意多个节点,每个节点可以保存一个字节数组或者一个整数值。
15.7.1,压缩列表结构
1.压缩列表结构:

参数说明:
zlbytes:记录整个压缩列表占用的内存字节数。
zltail:记录压缩列表表尾节点距离压缩列表起始地址有多少字节。
zllen:记录了压缩列表包含的节点数量。
entryN:压缩列表的节点,节点长度由节点保存的内容决定。
zlend:特殊值0xFF(十进制255),用于标记压缩列表的末端。
- 压缩列表节点结构:

参数说明:
previous_entry_length:记录压缩列表中前一个节点的长度。previous_entry_length属性的长度可以是1字节或者5字节:如果前一节点的长度小于 254 字节,那么previous_entry_length属性的长度为1字节,前一节点的长度就保存在这一个字节里面。如果前一节点的长度大于等于254字节,那么previous_entry_length属性的长度为5字节,其中属性的第一字节会被设置为0xFE(十进制值 254),而之后的四个字节则用于保存前一节点的长度。因为节点的previous_entry_length属性记录了前一个节点的长度,所以程序可以通过指针运算,根据当前节点的起始地址来计算出前一个节点的起始地址,缩列表的从表尾向表头遍历操作就是使用这一原理实现的。
encoding:记录节点的contents属性所保存数据的类型以及长度。分两种情况:(1)一字节、两字节或者五字节长,值的最高位为00 、01或者10的是字节数组编码,这种编码表示节点的content属性保存着字节数组,数组的长度由编码除去最高两位之后的其他位记录;(2)一字节长,值的最高位以11开头的是整数编码,这种编码表示节点的content属性保存着整数值,整数值的类型和长度由编码除去最高两位之后的其他位记录。
contents:保存节点的值,可以是一个字节数组或整数,类型和长度由节点的'encoding'属性决定。
16,分布式
16.1,分布式锁
16.1.1,普通版本
加锁:
@Override
public boolean getLock(String key, long timeSeconds) {
return redisTemplate.opsForValue().setIfAbsent(key, "lock", timeSeconds, TimeUnit.SECONDS);
}
@Override
public boolean getLock(String key) {
return redisTemplate.opsForValue().setIfAbsent(key, "lock", 300, TimeUnit.SECONDS);
}
解锁:
/** 释放锁lua脚本 */
private static final String RELEASE_LOCK_LUA_SCRIPT = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
@Override
public boolean releaseLock(String key) {
Object lockValue = redisTemplate.opsForValue().get(key);
if(lockValue == null){
return true;
}
String value = lockValue.toString();
Object[] objects = new Object[]{value};
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>(RELEASE_LOCK_LUA_SCRIPT,Long.class);
Long result = (Long)redisTemplate.execute(redisScript, Collections.singletonList(key),objects);
if(result==1L){
return true;
}else {
return false;
}
}
事实上这类琐最大的缺点就是它加锁时只作用在一个Redis节点上,即使Redis通过sentinel保证高可用,如果这个master节点由于某些原因发生了主从切换,那么就会出现锁丢失的情况:
- 在Redis的master节点上拿到了锁;
- 但是这个加锁的key还没有同步到slave节点;
- master故障,发生故障转移,slave节点升级为master节点;
- 导致锁丢失。
16.1.2,RedLock
antirez提出的redlock算法大概是这样的:
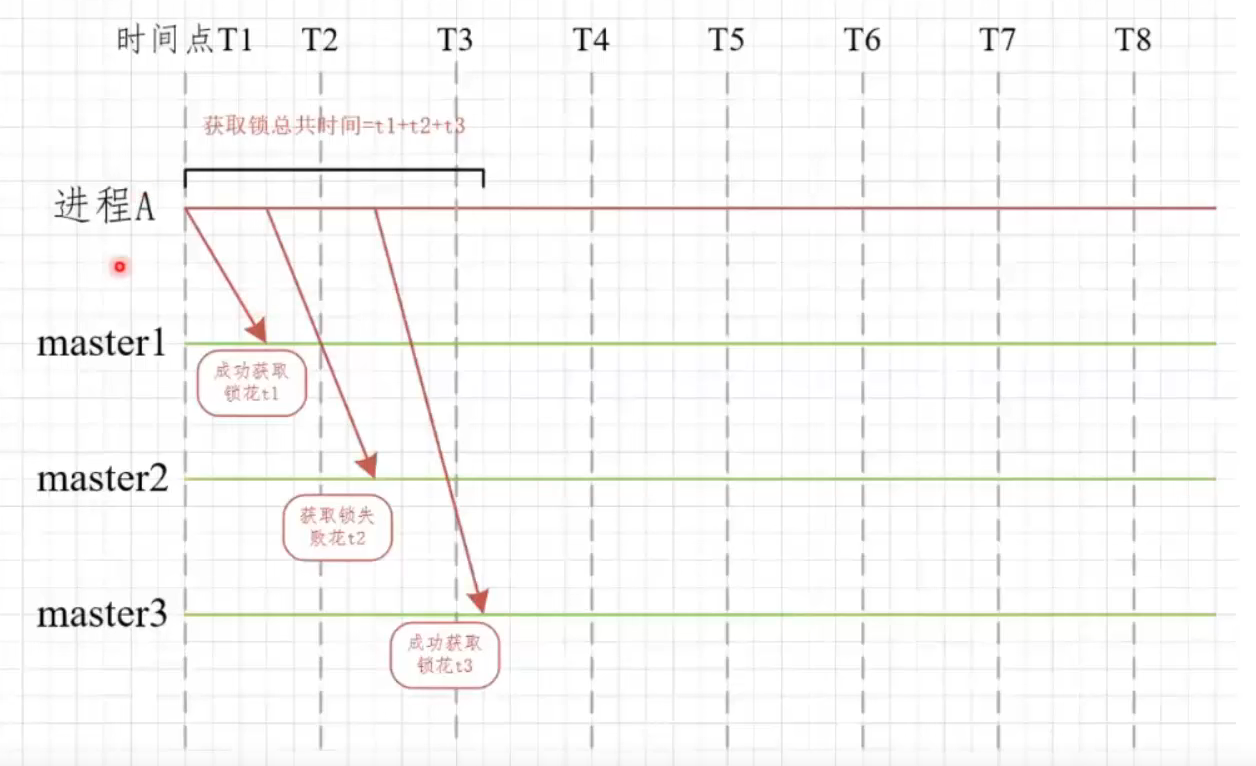
在Redis的分布式环境中,我们假设有N个Redis master。这些节点完全互相独立,不存在主从复制或者其他集群协调机制。我们确保将在N个实例上使用与在Redis单实例下相同方法获取和释放锁。现在我们假设有5个Redis master节点,同时我们需要在5台服务器上面运行这些Redis实例,这样保证他们不会同时都宕掉。
原理:
- 首先生成多个redis集群的Rlock,并将其构造程RedLock
- 依次循环对三个集群进行加锁,加锁方式和redission一致
- 如果循环加锁的过程中加锁失败,那么需要判断加锁失败的次数是否超出了最大值(要多数成功)
- 加锁的过程中需要判断是否加锁超时
- 若失败,向所有节点请求解锁
优点:
- redis在项目中很常见
- 容易取得可靠性和性能的平衡
缺点:
- RedLock算法需要多套redis实例,资源耗费
实现:
maven依赖:
<!-- https://mvnrepository.com/artifact/org.redisson/redisson -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.3.2</version>
</dependency>
加锁
Config config1 = new Config();
config1.useSingleServer().setAddress("redis://192.168.0.1:5378")
.setPassword("a123456").setDatabase(0);
RedissonClient redissonClient1 = Redisson.create(config1);
Config config2 = new Config();
config2.useSingleServer().setAddress("redis://192.168.0.1:5379")
.setPassword("a123456").setDatabase(0);
RedissonClient redissonClient2 = Redisson.create(config2);
Config config3 = new Config();
config3.useSingleServer().setAddress("redis://192.168.0.1:5380")
.setPassword("a123456").setDatabase(0);
RedissonClient redissonClient3 = Redisson.create(config3);
String resourceName = "REDLOCK_KEY";
RLock lock1 = redissonClient1.getLock(resourceName);
RLock lock2 = redissonClient2.getLock(resourceName);
RLock lock3 = redissonClient3.getLock(resourceName);
// 向3个redis实例尝试加锁
RedissonRedLock redLock = new RedissonRedLock(lock1, lock2, lock3);
boolean isLock;
try {
// isLock = redLock.tryLock();
// 500ms拿不到锁, 就认为获取锁失败。10000ms即10s是锁失效时间。
isLock = redLock.tryLock(500, 10000, TimeUnit.MILLISECONDS);
System.out.println("isLock = "+isLock);
if (isLock) {
//TODO if get lock success, do something;
}
} catch (Exception e) {
} finally {
// 无论如何, 最后都要解锁
redLock.unlock();
}
源码(加锁):
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
internalLockLeaseTime = unit.toMillis(leaseTime);
// 获取锁时需要在redis实例上执行的lua命令
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
// 首先分布式锁的KEY不能存在,如果确实不存在,那么执行hset命令(hset REDLOCK_KEY uuid+threadId 1),并通过pexpire设置失效时间(也是锁的租约时间)
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
// 如果分布式锁的KEY已经存在,并且value也匹配,表示是当前线程持有的锁,那么重入次数加1,并且设置失效时间
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
// 获取分布式锁的KEY的失效时间毫秒数
"return redis.call('pttl', KEYS[1]);",
// 这三个参数分别对应KEYS[1],ARGV[1]和ARGV[2]
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}
源码(解锁):
protected RFuture<Boolean> unlockInnerAsync(long threadId) {
// 释放锁时需要在redis实例上执行的lua命令
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
// 如果分布式锁KEY不存在,那么向channel发布一条消息
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; " +
"end;" +
// 如果分布式锁存在,但是value不匹配,表示锁已经被占用,那么直接返回
"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +
"return nil;" +
"end; " +
// 如果就是当前线程占有分布式锁,那么将重入次数减1
"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +
// 重入次数减1后的值如果大于0,表示分布式锁有重入过,那么只设置失效时间,还不能删除
"if (counter > 0) then " +
"redis.call('pexpire', KEYS[1], ARGV[2]); " +
"return 0; " +
"else " +
// 重入次数减1后的值如果为0,表示分布式锁只获取过1次,那么删除这个KEY,并发布解锁消息
"redis.call('del', KEYS[1]); " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; "+
"end; " +
"return nil;",
// 这5个参数分别对应KEYS[1],KEYS[2],ARGV[1],ARGV[2]和ARGV[3]
Arrays.<Object>asList(getName(), getChannelName()), LockPubSub.unlockMessage, internalLockLeaseTime, getLockName(threadId));
}
16.2,存储与获取
16.2.1,存储
首先,在redis的每一个节点上,都有这么两个东西,一个是插槽(slot)可以理解为是一个可以存储两个数值的一个变量这个变量的取值范围是:0-16383。还有一个就是cluster我个人把这个cluster理解为是一个集群管理的插件。当你往Redis Cluster中加入一个Key时,redis会根据crc16的算法得出一个结果,然后把结果对 16384 求余数,计算这个key应该分布到哪个hash slot中。
说明:
1.一个hash slot中会有很多key和value。你可以理解成表的分区。使用单节点时的redis时只有一个表,所有的key都放在这个表里;2.改用Redis Cluster以后会自动为你生成16384个分区表,你insert数据时会根据上面的简单算法来决定你的key应该存在哪个分区,每个分区里有很多key。)这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
2.一个hash slot可以存多少数据:摘自Redis官网的Data type章节,意思是内存允许的情况下,可以存超过40亿数据
3.redis cluster哈希槽数量能改变吗?
不能,因为代码算法写死了,固定是2的14次方这个数字上
16.2.2,获取
当client向redis cluster中的任意一个节点发送与数据库key有关的命令时,
接收命令的节点会计算出要处理的key属于哪个哈希槽(hash slot),
并且先检查这个hash slot是否属于自己(管辖):
-
如果key所在的槽正好属于自己(管辖),节点会直接执行这个key相关命令。
-
如果key所在的槽不属于自己(管辖),那么节点会给client返回一个MOVED错误,
-
指引client转向负责对应槽的节点,并客户端需要再次发送想要执行的和key相关的命令。
总结:针对redis集群如果缓存的业务数据没那么重要redis可以不做备份,例如有3个节点的集群,3个全都是主节点master,如果数据比较重要那么就要对这3个节点都增加一个备份节点slave,判断一个节点是否挂掉是通过投票来决定的,投票过程是集群中所有master参与,如果半数以上master节点与master节点通信超时(cluster-node-timeout),认为当前master节点挂掉.
如果redis集群没有备份,那么当master挂掉之后那么这个节点上的数据因为没有salve备份和替换有可能会丢失,所以一般集群都会有备份的,一般是3主3从的配置,开始3个主节点是确定好的,当有一个主节点宕机,并且它有多个从节点那么这多个从节点就开始竞争选举master(为什么设置为多主多从)
参考链接
9,HyperLogLog 算法的原理讲解以及 Redis 是如何应用它的(待学习)
11,@Import注解的作用
14,大数据分析常用去重算法分析『HyperLogLog 篇』
待完成
zset原理
hyperloglog原理
redis多线程
redis多路复用网络epoll
集群动态扩容缩容~2022.03.25 删除前,先迁移数据槽;添加后,迁移数据槽
投票算法~2022.03.25 Raft算法
布隆过滤器~2022.03.25 与jrg午休交流知道其原理!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号