

Java容器汇总【红黑树需要再次学习】
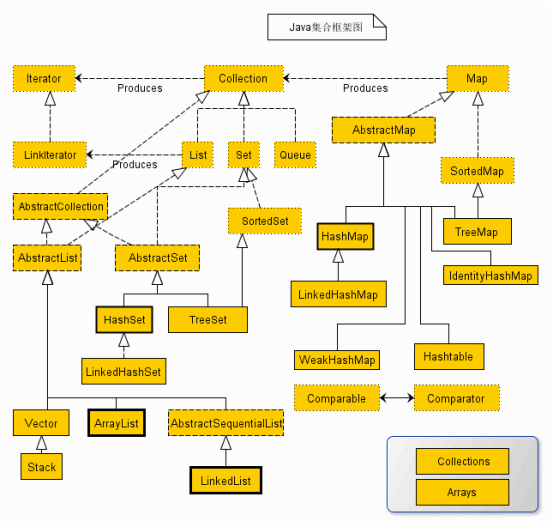
1,概述
2,Collection
2.1,Set【接触比较少】
2.1.1 TreeSet
底层由TreeMap实现
基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。
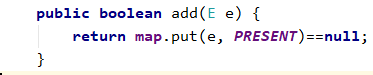
2.1.2 HashSet【完成】
基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息【由HashMap的数据存储行为有关系】,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
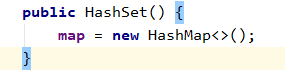
数据实现由hashmap实现, Key就是输入的变量。value是一个统一的Object数据

2.1.3 LinkedHashSet【完成】
具有 HashSet 的查找效率,且内部使用双向链表维护元素的插入顺序。【本质是不断的通过hash值计算来进行下一个数值的查找】
2.2,List
-
ArrayList:基于动态数组实现,支持随机访问【查找复杂度O(1),本质是一个数组】。
-
Vector:和 ArrayList 类似,但它是线程安全的【区别sychronized修饰,做了同步处理】。
-
LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。【普通for遍历每次都要重头开始,Iterator方法是有一个光标指向这里】不仅如此,LinkedList 还可以用作栈【LIFO】、队列和【FIFO,可以用来做生产者消费者设计模式】双向队列【集合前两种的功能】。https://www.cnblogs.com/ysocean/p/8657850.html
2.3,Queue【完成】
LinkedList:可以用它来实现双向队列【实现Deque 接口】。
PriorityQueue:基于堆结构---minHeap
一个基于优先级的无界优先级队列。优先级队列的元素按照其自然顺序进行排序,或者根据构造队列时提供的 Comparator 进行排序,具体取决于所使用的构造方法。该队列不允许使用 null 元素也不允许插入不可比较的对象(没有实现Comparable接口的对象)。
Java中PriorityQueue通过二叉小顶堆实现,可以用一棵完全二叉树表示(任意一个非叶子节点的权值,都不大于其左右子节点的权值)
public class PriorityQueue<E> extends AbstractQueue<E> implements java.io.Serializable {
1>PriorityQueue是一种无界的,线程不安全的队列
2>PriorityQueue是一种通过数组实现的,并拥有优先级的队列
3>PriorityQueue存储的元素要求必须是可比较的对象, 如果不是就必须明确指定比较器【可以插入相同数据】
需要理解堆这个数据结构就很好办了
leftNo = parentNo*2+1
rightNo = parentNo*2+2
parentNo = (nodeNo-1)/2
3,Map
3.1,TreeMap
基于红黑树实现。

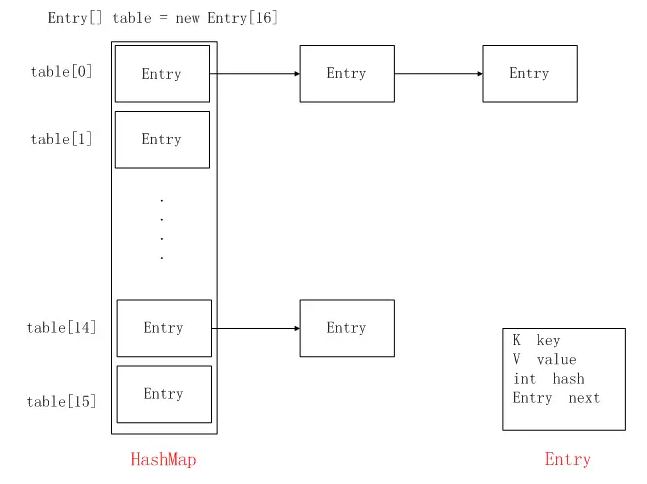
3.2,HashMap【非线程安全】【完成】
基于哈希表实现【这个详见Java-HashMap实现原理】
3.3,HashTable【遗留类,直接跳过它使用cocurrentHashMap】【完成】
和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程可以同时写入 HashTable 并且不会导致数据不一致。
它是遗留类,不应该去使用它。现在可以使用 ConcurrentHashMap 来支持线程安全,并且 ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
类似于:HashTable中的锁类似于MySQL中的表级锁Segments全部锁定、ConcurrentHashMap 类似于MySQL中的行级锁单个Segment锁定
3.4,ConcurrentHashMap【分段锁Segments并发高效、线程安全】
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因,是因为所有访问HashTable的线程都必须竞争同一把锁,那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。这里“按顺序”是很重要的,否则极有可能出现死锁,在ConcurrentHashMap内部,段数组是final的,并且其成员变量实际上也是final的,但是,仅仅是将数组声明为final的并不保证数组成员也是final的,这需要实现上的保证。这可以确保不会出现死锁,因为获得锁的顺序是固定的。
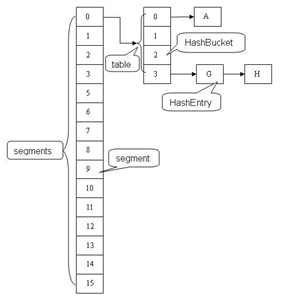
特色之处:
①可以看到ConcurrentHashMap会首先使用Wang/Jenkins hash的变种算法对元素的hashCode进行一次再哈希
② (hash >>> segmentShift) & segmentMask//向右无符号移动28位,意思是让高4位参与到hash运算中,
③Segment小锁锁定数据各个数据默认16个,读
④执行 size 操作时,先不加锁两次结果相同,就直接使用使用这个结果;否则对每一个Segment加锁统计各个count和;
JDK 1.7 使用分段锁机制来实现并发更新操作,核心类为 Segment,它继承自重入锁 ReentrantLock,并发度与 Segment 数量相等。
JDK 1.8 使用了 CAS 操作来支持更高的并发度,在 CAS 操作失败时使用内置锁 synchronized。
并且 JDK 1.8 的实现也在链表过长时会转换为红黑树。
3.4,LinkedHashMap【继承HashMap,添加前后索引】【完成】
使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。 https://www.jianshu.com/p/8f4f58b4b8ab
然后把accessOrder【LinkedHashMap特有的】设置为false,这就跟存储的顺序有关了,LinkedHashMap存储数据是有序的,而且分为两种:插入顺序【head-tail】和访问顺序【0-(size-1)遍历顺序】。
accessOrder设置为false,表示不是访问顺序而是插入顺序存储的,这也是默认值,表示LinkedHashMap中存储的顺序是按照调用put方法插入的顺序进行排序的
header是一个Entry类型的双向链表表头,本身不存储数据。
插入尾部、清楚头部
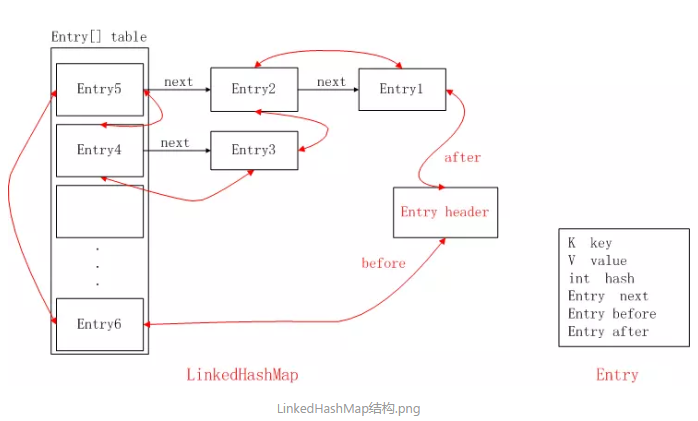
3.4.1 LinkedHashMap实现的LruCache【常用的数据缓存项】Android图片就是用的这个
Least Recently Used
package com.cnblogs.mufasa.Map; import java.util.LinkedHashMap; import java.util.Map; public class LRUCache<K, V> extends LinkedHashMap<K, V> { private int maxEntries;//设置的cache数据大小 public LRUCache(int maxEntries) { super(16, 0.75f, true); this.maxEntries = maxEntries; } @Override protected boolean removeEldestEntry(Map.Entry<K, V> eldest) { //插入新数据的时候判断是否超额 //是,清楚head-next数据,插入新数据在head-pre //否,插入head-pre就行 return size() > maxEntries; } }


package com.cnblogs.mufasa.Map; import org.w3c.dom.Node; import java.util.Comparator; import java.util.HashMap; import java.util.Map; import java.util.TreeMap; import java.util.concurrent.ConcurrentHashMap; public class Client { public static void main(String[] args) { // HashMap<Integer,String> hm=new HashMap<>(); // ConcurrentHashMap<Integer,String> chm=new ConcurrentHashMap<>(); //TreeMap // TreeMap<Integer,String> map =new TreeMap<>(); // map.put(3, "val"); // map.put(2, "val"); // map.put(1, "val"); // map.put(5, "val"); // map.put(4, "val"); // System.out.println(map); // Integer integer=new Integer(1); // System.out.println(Integer.parseInt("111",2)); // System.out.println(8^111); // String a1="hello"; // String a2=new String("hello"); // System.out.println(a1==a2); // LRUCache<String,Object> cache = new LRUCache<>(3); cache.put("a","abstract"); cache.put("b","basic"); cache.put("c","call"); cache.put("e","hello"); cache.put("d",null); cache.put(null,"null"); cache.get("e"); cache.put("f","滴滴滴"); System.out.println(cache); // 输出为:{c=call, a=abstract, d=滴滴滴} } } /* {null=null, e=hello, f=滴滴滴} */
3.5,WeakHashMap
3.5.1 存储结构
WeakHashMap 的 Entry 继承自 WeakReference,被 WeakReference 关联的对象在下一次垃圾回收时会被回收。
WeakHashMap 主要用来实现缓存,通过使用 WeakHashMap 来引用缓存对象,由 JVM 对这部分缓存进行回收。
private static class Entry<K,V> extends WeakReference<Object> implements Map.Entry<K,V>
3.5.2 ConcurrentCache
Tomcat 中的 ConcurrentCache 使用了 WeakHashMap 来实现缓存功能。
ConcurrentCache 采取的是分代缓存:
- 经常使用的对象放入 eden 中,eden 使用 ConcurrentHashMap 实现,不用担心会被回收(伊甸园);
- 不常用的对象放入 longterm,longterm 使用 WeakHashMap 实现,这些老对象会被垃圾收集器回收。
- 当调用 get() 方法时,会先从 eden 区获取,如果没有找到的话再到 longterm 获取,当从 longterm 获取到就把对象放入 eden 中,从而保证经常被访问的节点不容易被回收。
- 当调用 put() 方法时,如果 eden 的大小超过了 size,那么就将 eden 中的所有对象都放入 longterm 中,利用虚拟机回收掉一部分不经常使用的对象。
核心源码:
public final class ConcurrentCache<K, V> { private final int size; private final Map<K, V> eden; private final Map<K, V> longterm; public ConcurrentCache(int size) { this.size = size; this.eden = new ConcurrentHashMap<>(size); this.longterm = new WeakHashMap<>(size); } public V get(K k) { V v = this.eden.get(k); if (v == null) { v = this.longterm.get(k); if (v != null) this.eden.put(k, v); } return v; } public void put(K k, V v) { if (this.eden.size() >= size) { this.longterm.putAll(this.eden); this.eden.clear(); } this.eden.put(k, v); } }
4,容器中的设计模式
4.1 适配器设计模式
java.util.Arrays#asList() 可以把数组类型转换为 List 类型。
A-适配器-B
@SafeVarargs public static <T> List<T> asList(T... a)
4.2 迭代器模式
让用户通过特定的接口访问容器的数据,不需要了解容器内部的数据结构
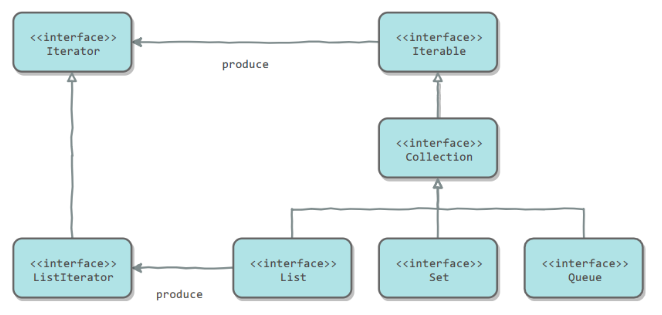
LinkedList<String> list = new LinkedList<>(); list.add("a"); list.add("b"); // for (String item : list) { // System.out.println(item); // } Iterator<String> iterator=list.iterator(); Iterator<String> iterator2=list.descendingIterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); }
4.3 引申-生产者消费者
Queue队列可以直接当做这个模式的数据结构
